
Von der Grundstufe bis zur Mittelstufe: Überladen

Einführung
Im vorigen Artikel mit dem Titel „Von der Grundstufe bis zur Mittelstufe: Fließkommazahlen“ haben wir die Grundlagen der Arbeit mit Fließkommazahlen besprochen. Ich habe dieses Material zunächst als Ausgangspunkt vorgestellt, weil es äußerst wichtig ist. Meiner Meinung nach ist das Verständnis der Funktionsweise von Float- und Double-Typen absolut notwendig, um sich mit komplexeren Problemen auseinandersetzen zu können.
Obwohl der Inhalt des Artikels nur einen grundlegenden Teil dessen abdeckt, was jeder wirklich beherrschen muss, wenn er ein guter Programmierer werden will, reicht dies bereits aus, um zu anderen Themen überzugehen. Es ist jedoch gut möglich, dass wir irgendwann zu Fließkommazahlen zurückkehren müssen, allerdings auf einem fortgeschritteneren Niveau. Aber alles hat seine Zeit.
Nichtsdestotrotz hat dieser Artikel meiner Meinung nach bereits vielen Menschen geholfen zu verstehen, dass wir nicht nach absoluter Genauigkeit in unseren Berechnungen streben können, wenn wir es mit einem Programm oder besser gesagt mit einer Handelsplattform zu tun haben, bei der ein Fehler den Verlust von Geld bedeutet. Das liegt daran, dass die Natur von Fließkommazahlen es uns nicht erlaubt, absolut genau und präzise zu sein. Alles, was wir tun können, ist zu versuchen, so nahe wie möglich an den Wert heranzukommen, den wir für akzeptabel oder vernünftig halten, damit wir in der Lage sind, eine Entscheidung über den Kauf oder Verkauf eines bestimmten Vermögenswerts oder Finanzinstruments zu treffen.
Diese Probleme betreffen jedoch eher die Betreiber oder Nutzer der Plattform als unsere Haupttätigkeit, die in diesem Fall die Programmierung ist. Als Programmierer müssen wir die Nutzer unserer Anwendungen darauf hinweisen, dass die Berechnungen ein gewisses Risiko bergen. Darüber hinaus muss der Nutzer oder Händler selbst die Daten anpassen und analysieren, inwieweit sie für ihn zum Zeitpunkt der Kauf- oder Verkaufsentscheidung sinnvoll sind.
Allerdings sehe ich immer noch nicht, dass wir über eine ausreichend solide und gut ausgebaute Basis verfügen, sodass wir anfangen können, darüber zu sprechen, wie man einen Indikator oder einen Trading Expert Advisor, auch Roboter genannt, programmiert oder implementiert. Obwohl wir bereits eine gute Vorstellung davon haben, was notwendig ist und was getan werden kann, können uns meiner Meinung nach in bestimmten Momenten die Hände gebunden sein. Das liegt daran, dass es Dinge gibt, die noch nicht geklärt sind. Und sie sind in verschiedenen Situationen und für verschiedene Zwecke wirklich notwendig. Sie ermöglichen es uns oft, Dinge zu tun, die ohne entsprechendes Wissen unmöglich zu realisieren wären.
Und da ich mich nicht über die Aussicht freue, in künftigen Artikeln zu sehr in langwierige und umständliche Details zu gehen, möchte ich eine vollständige und wirklich solide Grundlage für die Präsentation fortgeschrittenerer Materialien schaffen. Dies macht die Artikel nicht nur interessanter, sondern trägt auch zur Verbesserung der Qualität des Inhalts bei. Wenn ich keine Zeit mit der Erläuterung solcher Details verliere, kann ich mich auf die Vermittlung von noch mehr Wissen in künftigen Materialien konzentrieren.
Es gibt noch ein paar Dinge, die erklärt werden müssen und die für viele Anfänger recht schwierig sein können. Und es ist wirklich notwendig, Zeit auf sie zu verwenden, bevor wir zu einer höheren Ebene übergehen.
Genau wie bei den Arrays und Strings, wo ich gezeigt habe, dass das eine zum anderen führt, muss auch hier ein Mechanismus geklärt werden, bevor man zu etwas Komplexerem übergeht. Der Grund dafür ist einfach: Es wird viel klarer, wie ein scheinbar verwirrender Mechanismus die Umsetzung eines anderen Mechanismus ermöglicht, den viele Anfänger nicht nutzen, weil sie ihn nicht verstehen. Und sie sind gezwungen, eine Reihe von Routinen, Funktionen und Prozeduren zu erstellen, die in einem anspruchsvolleren Code oft völlig unnötig sind. Oder besser gesagt, in Code, der von einem Programmierer geschrieben wurde, der genau weiß, wie man etwas in einer bestimmten Sprache implementiert. In unserem Fall - in MQL5.
Um also das eine vom anderen zu trennen, sollten wir uns einem neuen Thema zuwenden.
Was bedeutet Überladen?
Wenn es etwas gibt, das unerfahrene Programmierer oder sogar Amateurprogrammierer völlig verwirren und es unmöglich machen kann, zumindest etwas in einem Codeschnipsel zu verstehen, dann ist es, wenn es zwei Funktionen oder Prozeduren mit demselben Namen im selben Code gibt. Ja, das kommt vor, und wenn es passiert, ist ein weniger erfahrener oder weniger versierter Programmierer völlig verwirrt und nicht in der Lage, den Code zu korrigieren, zu verbessern oder sogar einen eigenen Code auf der Grundlage des Codes zu erstellen.
Obwohl dies für Unwissende äußerst verwirrend und völlig unlogisch erscheinen mag, ist dies durchaus möglich, zulässig und für den Compiler akzeptabel, sofern bestimmte einfache Regeln befolgt werden.
Ich verstehe und weiß, dass viele Leute wahrscheinlich sagen werden, dass ich den Verstand verloren oder den Faden der Erzählung völlig verloren habe, weil sie einfach keine Ahnung haben, wie man zwei Anrufe mit unterschiedlichen Zwecken, die aber gleichzeitig denselben Namen enthalten, verwenden kann. Nehmen wir ein einfaches Beispiel - wirklich sehr einfach - nur um zu zeigen, wovon ich spreche und was ich erklären werde.
Schauen wir uns nun den folgenden Code an.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
Code 01
Also, lieber Leser, ich möchte, dass Sie sich den Code 01 ansehen und so ehrlich wie möglich sagen, noch bevor Sie das Ergebnis sehen: Wie genau wird dieser Code laufen? Oder, um es deutlicher zu machen, sollten Sie bereits wissen, dass wir, wenn wir Print im Code verwenden, einen Wert auf dem MetaTrader 5 Terminal ausgeben wollen. Und hier haben wir vier Aufrufe von Print.
Um also die oben gestellte Frage umzuformulieren: Können Sie mir sagen, was auf dem Terminal angezeigt werden wird? Sie können sich natürlich die Zeilen sechs und sieben ansehen und sagen: „Nun, Wert 35 und Wert 15 werden gedruckt“. Und dies ist der offensichtlichste Teil der Operation. Mich interessiert, welche der beiden Funktionen ausgeführt werden soll: Summenfunktion in Zeile zehn oder Summenfunktion in Zeile sechzehn? Hm, lassen Sie mich nachdenken. Ups, aber es wird nicht kompiliert, weil wir zwei Funktionen mit demselben Namen haben - sowohl in Zeile zehn als auch in Zeile sechzehn. Haben Sie daran gedacht, mich dabei zu erwischen?
Nun, mein lieber Leser, eigentlich, und da haben Sie völlig recht, könnte es hier einen Haken geben, denn zwei Funktionen oder Prozeduren DÜRFEN NICHT DEN GLEICHEN NAMEN HABEN. Das ist eine Tatsache, und jeder, der etwas anderes behauptet, lügt oder verheimlicht zumindest etwas. Dies trifft jedoch nicht auf diesen Fall zu, so seltsam es auch klingen mag. Die beiden in den Zeilen zehn und sechzehn gezeigten Summenfunktionen sind NICHT DIESELBE FUNKTION. Obwohl sie beide die gleiche Aufgabe erfüllen und diese auch korrekt ausführen, behandelt der Compiler sie nicht als eine, sondern als zwei verschiedene Funktionen, obwohl sie den gleichen Namen haben.
Aber jetzt bin ich wirklich verwirrt, denn soweit ich weiß, dürfen zwei Funktionen oder Prozeduren nicht denselben Namen haben, wenn wir sie in demselben Code verwenden wollen. Und das ist wahr - es darf nicht sein. Hier handelt es sich jedoch um ein so genanntes Überladen von Funktionen oder Prozeduren.
Das Problem der Überladung ist eines der Dinge, die mir beim Programmieren am meisten Freude bereiten. Denn wenn die Überladung richtig geplant ist, können wir damit einen viel lesbareren Code implementieren. Obwohl es effektivere Wege gibt, um das Gleiche zu erreichen, ist es fast - wenn nicht sogar unmöglich - einen anderen Mechanismus in der MQL5-Sprache zu verstehen, ohne zu verstehen, was die Überladung ist, die Sie in Code 01 sehen. Aber lassen wir das für später. Lassen Sie uns zunächst klären, was Überladung ist und wie sie funktioniert.
Die Überladung ist genau das, was Sie in den Zeilen zehn und sechzehn dieses Codes 01 sehen. Sobald Sie das Formular ausgefüllt haben, wird die nachstehende Abbildung angezeigt.
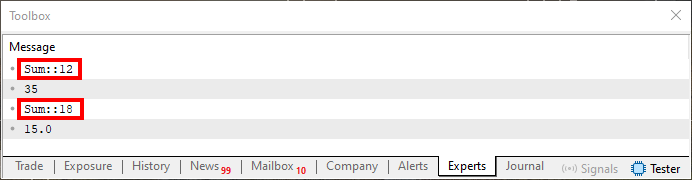
Abbildung 01
Wir interessieren uns hier nicht für den Wert, der in den Zeilen sechs und sieben gedruckt wird, sondern für die Werte, die im Bild hervorgehoben sind. Das sind die Daten, die uns im Moment wirklich interessieren. Beachten Sie, dass wir uns in einem Fall auf die Zeile 12 und im anderen Fall auf die Zeile 18 beziehen. Warum ist das so?
Der Grund liegt in der Art des Wertes, der in den Aufrufen in den Zeilen sechs und sieben übergeben wird. Wenn der Compiler versucht, eine ausführbare Datei zu erzeugen, wird er sich diese Werte ansehen und sagen: OK, dieser Wert entspricht dem erwarteten Parameter dieser Funktion; dieser Wert entspricht dem anderen Parameter. Dadurch werden die Anrufe zugelassen, sodass wir mehrere Anrufe mit demselben Namen haben.
Allerdings, und das ist wichtig, dürfen die Argumente oder erwarteten Parameter NICHT DIESELBEN SEIN. Sie können zwar Ähnlichkeiten aufweisen, müssen sich aber in ihrer Anzahl unterscheiden, oder zumindest eine von ihnen muss von einem anderen Typ sein. Andernfalls ist der Compiler nicht in der Lage zu verstehen, wohin der Code geleitet werden soll, und dies wird als Fehler gewertet.
Beachten Sie, dass in diesem Fall sowohl die Summe in Zeile zehn als auch die Summe in Zeile sechzehn unterschiedliche Typen verwenden. Da sich das zweite Argument in Zeile 7 vom Typ her von einer ganzen Zahl unterscheidet, versteht der Compiler, dass in diesem Fall eine Funktion aufgerufen werden muss, in der ein Fließkomma-Argument erwartet wird.
Um dieses Wissen zu festigen, wollen wir einen weiteren Fall betrachten.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum((char)-10, 25)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(int arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(char arg1, ulong arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return (double)(arg1 + arg2); 20. } 21. //+------------------------------------------------------------------+
Code 02
Seien Sie jetzt vorsichtig, denn Code 02 führt zum gleichen Ergebnis wie in Abbildung 01 gezeigt. Allerdings haben wir es hier mit etwas nicht so Einfachem zu tun wie zuvor. Dies ist die Art von Code, die viele unerfahrene Programmierer als zu verwirrend empfinden und daher versuchen, ihn zu ändern, um die daraus resultierende Verwirrung zu beseitigen. Damit schaffen sie sich jedoch selbst ein Problem, weil das Ergebnis nicht dem entspricht, was sie erwartet oder was der Autor des Codes beabsichtigt hat.
Bevor Sie also versuchen, einen unbekannten Code zu ändern, liebe Leserin, lieber Leser, versuchen Sie zu studieren, wie er funktioniert. Wenn möglich, lassen Sie es in einer kontrollierten Umgebung laufen, damit Sie den Fortschritt nachvollziehen können. Es ist möglich, dass Sie etwas übersehen haben, und der Versuch, etwas zu ändern, ohne es zu bemerken, ist einer der größten Fehler, den Programmieranfänger machen.
Lassen Sie uns nun Folgendes herausfinden: Die Funktion Summe, wie sie in den Zeilen zehn und sechzehn von Code 02 dargestellt ist, gibt immer noch denselben Werttyp zurück. Beachten Sie, dass wir in Zeile 19 eine explizite Konvertierung verwenden, damit der Compiler sich nicht über Typ-Inkongruenzen beschwert.
Aber jetzt ist der folgende Punkt wichtig: Beachten Sie, dass der Unterschied zwischen der Funktion Summe in Zeile 10 und der Funktion Summe in Zeile 16 in der Art des ersten Arguments liegt, das sie annehmen. Normalerweise verwirrt dies viele Leute, da es auf den ersten Blick sinnlos erscheint, einen 4-Byte-Typ für eine Funktion aus Zeile zehn und einen 1-Byte-Typ für eine Funktion aus Zeile sechzehn zu verwenden.
In diesem Beispiel ist dies sogar völlig unnötig. Aus irgendeinem Grund kann es jedoch vorkommen, dass ein Programmierer innerhalb von Funktionen so arbeiten möchte, dass die Funktion in Zeile sechzehn wirklich einen Wert vom Typ char annehmen sollte, da der Typ int nicht geeignet ist. Ich möchte Sie daran erinnern, dass wir dieses Problem auch auf andere Weise lösen können, aber das wird in einem anderen Artikel behandelt. Wir gehen hier davon aus, dass Sie nicht wissen, wie man das macht, also beschließen Sie, es wie in Code 02 gezeigt zu implementieren.
Frage: Ist das schlecht? Nein, liebe Leserin, lieber Leser, das Erstellen, Schreiben und Implementieren von Code, wie in Code 02 gezeigt, ist keine schlechte Sache. Es bedeutet nur, dass Sie ein wenig mehr über die Programmierung in MQL5 lernen sollten. Aber es ist definitiv nicht schlecht.
Es handelte sich also um einfache Formen des Überladens. Es gibt noch eine andere Form, bei der statt der Deklaration von Parametern unterschiedlichen Typs eine unterschiedliche Anzahl von Parametern verwendet wird. Dieser Fall ist wahrscheinlich der häufigste, denn im Gegensatz zu C und C++, wo wir eine fast unendliche Anzahl von Parametern implementieren können, ohne die Deklaration einer Funktion oder Prozedur zu ändern, können wir das hier in MQL5 nicht tun. Nun, dies ist im Testmodus, denn es gibt eine Möglichkeit, dies zu implementieren. Im vorigen Artikel habe ich gezeigt, wie das geht, auch wenn dies nur eine Einführung war, was tatsächlich möglich ist, wenn bestimmte Mechanismen erklärt werden.
Aber lassen Sie uns noch einmal bedenken, dass Sie, lieber Leser, wirklich studieren und richtig studieren wollen. Wie sieht nun diese andere Form der Überladung aus? Sie können es gleich unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25, 4)); 08. } 09. //+------------------------------------------------------------------+ 10. long Sum(long arg1, long arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. long Sum(long arg1, long arg2, long arg3) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2 + arg3; 20. } 21. //+------------------------------------------------------------------+
Code 03
In diesem Fall sieht das Ergebnis wie in der folgenden Abbildung dargestellt aus.
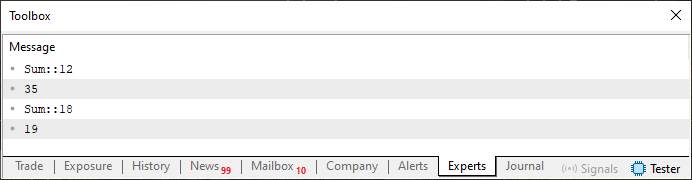
Abbildung 02
Soweit ich festgestellt habe, ist diese Art von Code für die meisten Anfänger leichter zu verstehen als andere, wie in Beispiel 03, weil es einfacher ist zu verstehen, welche Funktion oder Prozedur in jedem spezifischen Fall aufgerufen wird. Viele Menschen betrachten diese Art der Implementierung (die in Code 03 vorgestellt wird) nicht als eine Form der Überladung. In der Literatur wird dies jedoch von vielen Autoren tatsächlich als eine Art Überladung angesehen, da der Funktionsname gleich bleibt.
Okay, ich denke, es ist jetzt klar, was Überladen ist und was nicht. Es bleibt jedoch eine Frage: Warum funktioniert das, und wie gelingt es dem Compiler, zwischen diesen beiden Implementierungen zu unterscheiden, nur weil unterschiedliche Typen verwendet werden? Zumindest auf den ersten Blick erscheint dies nicht sehr logisch.
Eigentlich, lieber Leser, ist das nicht ganz logisch, denn wenn wir eine Funktion verwenden, rufen wir sie unter dem Namen auf, unter dem sie deklariert wurde, und nicht unter einem anderen Namen. Warum funktioniert es also? Der Grund dafür ist, dass der Compiler wissen muss, wie er den Ausführungsfluss richtig lenken kann, damit der Code tatsächlich ausführbar wird. Und wenn Überladung verwendet wird, in diesem Fall von Funktionen und Prozeduren, erstellt der Compiler einen eindeutigen internen Namen. Ich sage „intern“, weil man nicht genau weiß, wie er gebildet wird, obwohl er im Allgemeinen nach einigen einfachen Regeln gebildet wird.
Ein Beispiel: Bei Code 03 kann der Compiler in Zeile 10 die Funktion Sum als Sum_long_long aufrufen, während er die Funktion ab Zeile 16 Sum_long_long_long nennen kann. Bitte beachten Sie, dass dies trotz der scheinbaren Einfachheit bereits einen großen Unterschied macht, da es dem Erstellen einer Funktion mit dem eindeutigen Namen sehr ähnlich ist.
Das Gleiche gilt für Code 02. Dort kann der Compiler die Funktion aus Zeile zehn als Sum_int_ulong und die aus Zeile sechzehn als Sum_char_ulong interpretieren. Bitte beachten Sie, dass nun alles einen Sinn ergibt, und daraus folgt, dass der Compiler in der Lage ist zu verstehen, wohin der Ausführungsfluss zu einem bestimmten Zeitpunkt gelenkt werden soll.
Wichtiger Hinweis: Ich verwende diese Nomenklatur hier nur zu didaktischen Zwecken, denn je nach der Implementierung und den Absichten der Compiler-Entwickler kann diese Nomenklatur völlig anders aussehen. Denken Sie nur daran, dass der Compiler intern etwas Ähnliches tut.
Großartig, wir sind fast fertig mit dem Thema der Nutzung der Überladung. Es fehlen nur zwei Beispiele, die meiner Meinung nach sehr interessant zu zeigen sind. Die erste ist unten abgebildet.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int v = -5; 07. 08. Sum(v, Sum(10, 25)); 09. Print(v); 10. } 11. //+------------------------------------------------------------------+ 12. long Sum(long arg1, long arg2) 13. { 14. Print(__FUNCTION__, "::", __LINE__); 15. return arg1 + arg2; 16. } 17. //+------------------------------------------------------------------+ 18. void Sum(int &arg1, long arg2) 19. { 20. Print(__FUNCTION__, "::", __LINE__); 21. 22. arg1 += (int)arg2; 23. } 24. //+------------------------------------------------------------------+
Code 04
In diesem Fall haben wir die Möglichkeit, die überladene Funktion zusammen mit der Prozedur zu verwenden. Beachten Sie, dass sie die gleichen Namen haben, aber aufgrund der unterschiedlichen Typen können Sie den Ausführungsfluss in die eine oder andere Richtung umleiten. Je nachdem, wie dieser 04-Code implementiert ist, welche Arten von Argumenten verwendet wurden und wie der Code selbst strukturiert ist, kann er das eine oder andere Ergebnis liefern. Und das alles nur, weil wir eine Kleinigkeit in den Deklarationen geändert haben: sei es der Typ oder die Art und Weise, wie Zeile acht interpretiert wird.
Beachten Sie die folgende Tatsache: Obwohl sich Zeile 8 auf die in Zeile 12 angegebene Funktion zu beziehen scheint, wird allein durch die Verwendung einer Variablen als erstes Argument deutlich, dass wir beabsichtigen, Zeile 18 aufzurufen. Wenn jedoch der in Zeile 8 deklarierte Typ nicht mit dem in Zeile 18 erwarteten Typ kompatibel ist, können wir Zeile 18 tatsächlich nie aufrufen, da alle Aktionen in Zeile 12 ausgeführt werden. Aus diesem Grund ist es nicht empfehlenswert, das Überladen von Funktionen und Prozeduren unsachgemäß oder unvorsichtig zu verwenden, da dies zu Ergebnissen führen kann, die sich von den erwarteten stark unterscheiden.
In der Form, in der der Code 04 dargestellt ist, werden wir jedoch bei seiner Ausführung das in der folgenden Abbildung dargestellte Ergebnis sehen.
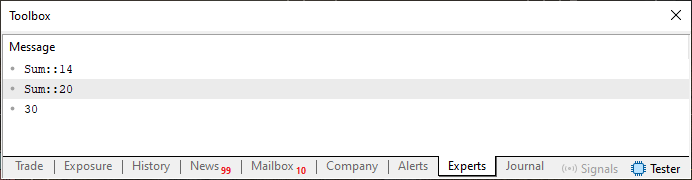
Abbildung 03
Auch hier ist anzumerken, dass dieses Ergebnis nur deshalb zustande kam, weil die Typen perfekt übereinstimmten und der Compiler in der Lage war, unsere Absicht richtig zu verstehen. Wenn jedoch ein Programmierer, ohne den Code zu studieren und zu verstehen, beschließt, dass er den Typ long in seinem Code nicht verwenden möchte (da er 64-Bit ist) und beschließt, nur den Typ int zu verwenden (da er 32-Bit ist), dann sehen Sie, was passiert. Nach den beschriebenen Änderungen wird aus dem Code 04 der Code 05, der unten zu sehen ist.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int v = -5; 07. 08. Sum(v, Sum(10, 25)); 09. Print(v); 10. } 11. //+------------------------------------------------------------------+ 12. int Sum(int arg1, int arg2) 13. { 14. Print(__FUNCTION__, "::", __LINE__); 15. return arg1 + arg2; 16. } 17. //+------------------------------------------------------------------+ 18. void Sum(int &arg1, int arg2) 19. { 20. Print(__FUNCTION__, "::", __LINE__); 21. 22. arg1 += (int)arg2; 23. } 24. //+------------------------------------------------------------------+
Code 05
Bitte beachten Sie, dass eine völlig unschuldige Änderung vorgenommen wurde, ohne die Absicht, Probleme zu verursachen, aber beim Versuch, eine ausführbare Datei zu erstellen, stellt sich heraus, dass der Compiler nicht versteht, was genau implementiert wird. Die Meldung, die in der Compiler-Ausgabe ausgegeben wird, ist unten zu sehen.

Abbildung 04
Das heißt, ein völlig unschuldiger Versuch, den Code in etwas zu ändern, das nach Meinung des Programmierers besser geeignet ist, führte schließlich dazu, dass der Code völlig unverständlich wurde, da der Compiler nicht weiß, ob er die Zeile 12 oder die Zeile 18 ansprechen soll, wenn die Zeile 8 ausgeführt werden soll.
Aber, mein lieber Leser, ich möchte, dass Sie eines verstehen: Der Fehler liegt nicht in Zeile 8. Der Fehler liegt eigentlich darin, dass wir zwei Aufrufe haben, die nach dem Verständnis des Compilers genau gleich sind. Ein Programmierer mit wenig Erfahrung wird schnell denken, dass das Problem in Zeile 8 liegt, obwohl es in Wirklichkeit in Zeile 12 oder 18 liegt, wie oben erklärt, da der Compiler einen eindeutigen internen Namen erzeugen kann, wenn er versucht, die endgültige ausführbare Datei zu erzeugen.
Dieser Ansatz, der hier einfach zu sein scheint, kann in der Praxis äußerst schwierig sein. Denn einer der Aufrufe kann sich in einer Header-Datei befinden und der andere in einer völlig anderen Header-Datei, die mit dem ersten Aufruf überhaupt nichts zu tun hat. Das macht die Situation noch komplizierter und verwirrender.
Und als letztes Beispiel wollen wir einen weiteren Anwendungsfall für Überladung betrachten. Sie ist im folgenden Code dargestellt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long v = -16, 07. m[]; 08. bool b; 09. 10. Add(m, Sum(10, 25)); 11. Print("Return: ", b = Sum(v, m)); 12. if (b) Print("Value: ", v); 13. ArrayFree(m); 14. } 15. //+------------------------------------------------------------------+ 16. void Add(long &arg[], long value) 17. { 18. ArrayResize(arg, arg.Size() + 1); 19. arg[arg.Size() - 1] = value; 20. } 21. //+------------------------------------------------------------------+ 22. long Sum(long arg1, long arg2) 23. { 24. Print(__FUNCTION__, "::", __LINE__); 25. return arg1 + arg2; 26. } 27. //+------------------------------------------------------------------+ 28. bool Sum(long &arg1, const long &arg2[]) 29. { 30. Print(__FUNCTION__, "::", __LINE__); 31. 32. if (arg2.Size() == 0) 33. return false; 34. 35. for (uchar c = 0; c < arg2.Size(); c++) 36. arg1 += arg2[c]; 37. 38. return true; 39. } 40. //+------------------------------------------------------------------+
Code 06
Dieser Fall ist wirklich sehr interessant und hat viele praktische Auswirkungen. Denn oft, zumindest in der MQL5-Umgebung, wo das Ziel darin besteht, Mechanismen für die grafische Interpretation von Preisen und Handelsgeschäften zu schaffen, implementieren wir Code, dessen Hauptaufgabe oder -zweck darin besteht, eine Faktorisierung mit mehreren Kursen durchzuführen. Normalerweise ist diese Art der Faktorisierung in irgendeiner Weise mit der Entwicklung eines spezifischen Indikators oder Handelsmodells verbunden, das für die Verwendung im Expert Advisor vorgesehen ist, um ein visuelles grafisches Signal zu bilden und die Aufmerksamkeit eines Händlers oder eines Nutzers der MetaTrader 5-Plattform auf die Eröffnung oder Schließung einer Position oder zumindest auf eine bestimmte Bewegung zu lenken, die zu einem bestimmten Zeitpunkt stattfinden kann.
Ich verstehe, dass viele Menschen, vor allem Anfänger, gerne etwas schaffen und sofort sehen wollen, wie es ausgeführt wird. Bevor wir dies tun können, ist es jedoch notwendig, die Art von Dingen, die wir derzeit in diesen Artikeln betrachten, gründlich zu untersuchen. Hier ist das Material grundlegender und zielt darauf ab, eine solide Grundlage zu schaffen, damit Sie später mit etwas Komplexerem und Aufgabenorientiertem arbeiten können. Da ich in Zukunft nicht viel Zeit damit verbringen möchte, einfache Details zu erklären, erstelle ich diese Wissensdatenbank jetzt. So können Sie, lieber Leser, das, was Sie in Artikeln mit speziellerem Inhalt sehen, anpassen oder sogar verbessern, und zwar nicht nur bei mir, sondern auch bei jedem anderen Programmierer, dessen Idee oder Code Sie verwenden möchten.
In diesem Code 06 haben wir also nur ein Beispiel für eine Überladung, bei der wir in einem Fall einen diskreten Wert auf sehr interessante Weise verwenden und im anderen Fall eine Reihe von Werten, die in einem Datenarray enthalten sind. Trotz der äußerlichen Einfachheit haben wir jedoch oft Probleme bei der Ausführung von Berechnungen, weil wir einige grundlegende Konzepte nicht richtig verstanden haben. Zu diesen Fehlern gehört die Tatsache, dass wir oft nicht auf die Anfangswerte der Parameter achten, die der Funktion übergeben werden sollen. Diese Art von Fehlern ist manchmal schwer aufzuspüren und zu beheben, zumindest solange, bis wir den wahren Grund für den Fehler verstehen.
Aber solche Dinge sind in der Praxis leichter zu verstehen, und mit zunehmender Erfahrung werden Sie solche Fehler immer seltener machen. Und wenn sie dennoch auftreten, dann nur aufgrund mangelnder Sorgfalt bei der Umsetzung.
Sehen wir uns nun an, was wir hier in Code 06 haben. Wenn Sie den oben gezeigten Code ausführen, erhalten Sie das unten dargestellte Ergebnis.
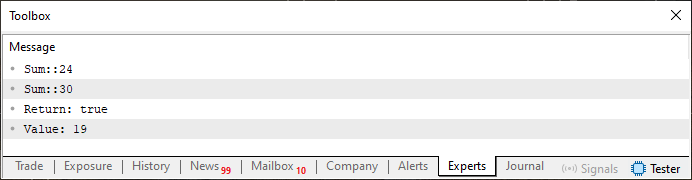
Abbildung 05
Verstehen Sie das, mein lieber Leser. Wie bereits erwähnt, gibt es oft Probleme bei der Ausführung der Mehrfachfaktorisierung. Das liegt daran, dass wir beim Faktorisieren die falsche Anzahl von Elementen verwenden. Um dies zu vermeiden, weigern wir uns, einen Wert aus der Funktion zurückzugeben und geben stattdessen ein Merkmal zurück. Sie gibt an, ob der faktorisierte Wert akzeptiert werden soll oder nicht. Deshalb überprüfen wir in Zeile 32 genau dies. Beachten Sie, dass die Funktion Summe immer noch überladen ist, da sie in Zeile 22 denselben Namen hat wie in Zeile 28. Die Tatsache, dass der Rückgabewert einen anderen Zweck hat, ändert jedoch nichts daran, dass die Funktion ohnehin überladen ist.
Das kann oft verwirrend sein, vor allem wenn man nur die Zeilen betrachtet, in denen die Funktion verwendet wird. Schauen Sie sich die Zeilen zehn und elf an - Sie werden feststellen, dass das, was zurückgegeben wird, nicht ganz logisch ist. Wenn Sie also Zweifel an der Funktionsweise des Codes haben, sollten Sie versuchen, ihn im Detail zu studieren. Glauben Sie nicht, dass eine Funktion oder Prozedur, nur weil sie denselben Namen hat wie eine andere, die Sie bereits kennen, zwangsläufig auf dieselbe Weise funktioniert. Das ist nicht immer der Fall.
Schließlich können wir noch eine kleine Änderung an Code 06 vornehmen. Dies wird im folgenden Ausschnitt gezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long v = -16, 07. m[]; 08. bool b; 09. 10. // Add(m, Sum(10, 25)); 11. Print("Return: ", b = Sum(v, m)); 12. if (b) Print("Value: ", v); 13. ArrayFree(m); 14. } 15. //+------------------------------------------------------------------+ . . .
Schnipsel 01
Bitte beachten Sie, dass ich in diesem Ausschnitt eine Zeile aus dem Code entferne und sie in einen Kommentar umwandle. In diesem Fall ist dies die Zeile zehn. Aber diese einfache Änderung, die scheinbar nur bedeutet, dass wir nicht die richtige Anzahl von Elementen für die Faktorisierung hinzugefügt haben, führt zu dem unten dargestellten Ergebnis.
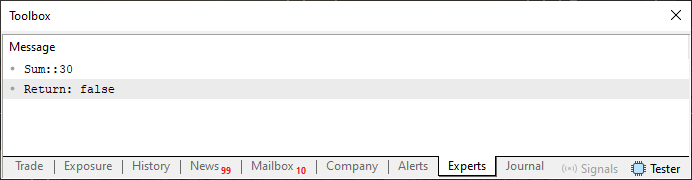
Abbildung 06
Versuchen Sie, andere Änderungen am Code 06 vorzunehmen, um andere Erkenntnisse zu gewinnen, denn das wird Ihnen in Zukunft sehr helfen.
Abschließende Überlegungen
Dieser Artikel hat sich vielleicht als der verwirrendste für Programmieranfänger herausgestellt, weil ich hier gezeigt habe, dass in ein und demselben Code nicht immer alle Funktionen und Prozeduren eindeutige Namen haben werden. Ja, wir können problemlos Funktionen und Prozeduren mit demselben Namen verwenden - und das nennt man Überladen. Auch wenn dies akzeptabel ist, sollte man bei dieser Praxis Vorsicht walten lassen. Denn dadurch wird der Code oft nicht nur schwierig zu implementieren, sondern auch später schwer zu korrigieren.
Ich hoffe, dass dieser Artikel als Erklärung für Sie dient und Sie dazu anregt, nicht automatisch davon auszugehen, dass sich eine bereits bekannte Funktion oder Prozedur notwendigerweise genauso verhält wie eine andere Funktion oder Prozedur, die mittels Überladung implementiert wurde.
Im Anhang finden Sie Auszüge aus dem Code, der in diesem Artikel besprochen wird. Versuchen Sie, dieses Material zu studieren und Änderungen an den Codes der Anwendung vorzunehmen, um zu verstehen, wie sich das Überladen sowohl auf Ihr Verständnis des Codes als auch auf die potenziellen Fehler auswirken kann, die durch den Missbrauch des Überladens entstehen können. Es ist besser, zu lernen, wie man mit Fehlern umgeht, solange die Mechanismen noch einfach sind, als zu versuchen, einen Fehler in einem komplexeren System zu beheben. Daher sollten Sie sich jetzt mit dem Thema Überladung befassen, wenn alles noch relativ einfach ist. Schließlich wird alles nur noch komplizierter, wenn wir weitermachen.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15642
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.


- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.