
Del básico al intermedio: Unión (II)

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final, cuyo objetivo no sea el estudio de los conceptos mostrados aquí.
En el artículo anterior, Del básico al intermedio: Unión (I), comenzamos a hablar sobre qué sería una unión, siendo que, en realidad, este tema ya viene preparándose para ser tratado desde el primer artículo, ya que todo lo que está, y será, expuesto aquí y en los próximos artículos está, de alguna forma, correlacionado entre sí. De cualquier modo, lo que se vio en el artículo anterior es apenas la parte inicial de lo que está directamente relacionado con lo que sería una unión. Este tema, de hecho, es un tema bastante extenso, así como lo que está vinculado a la cuestión sobre arrays.
Pues bien, en este artículo, veremos un poco más sobre uniones, pero también ampliaremos un poco más nuestro conocimiento respecto a arrays. Así que, ponte cómodo y vamos al primer tema de este artículo.
Arrays y uniones
Las uniones son un tema realmente interesante que abre diversas puertas hacia temas mucho más elaborados en el ámbito de la programación. Sin embargo, debemos tener ciertos cuidados para no caer en el error de imaginar que ya entendemos un tema solo por haber visto su base.
El motivo es que muchos ignoran el concepto y se aferran únicamente a una idea frágil y poco productiva, creyendo que, al declarar una unión, estamos limitándolo todo a ese modelo simple que se creó durante la declaración, cuando, en realidad, podemos hacer muchas más cosas si aplicamos correctamente el concepto de una herramienta determinada.
En el artículo anterior, mencioné que, al declarar cómo se montaría una unión, estaríamos creando un tipo especial de dato similar a una cadena de caracteres. Sin embargo, es posible que muchos se muestren algo desconfiados, o incluso recelosos ante ciertas construcciones que utilizan este tipo de dato creado.
Para demostrar cómo esto puede llegar a ser interesante, y por qué alguien haría algo así, es necesario entender un pequeño detalle. Como una unión es, de hecho, un tipo nuevo y especial, podemos utilizarla de diversas formas, tanto en la declaración como en la forma de usar este tipo de dato, especialmente creado para una situación determinada. A continuación, veremos un primer ejemplo de esto.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits; 07. uchar u8_bits[4]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info[2]; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. for (uchar c = 0; c < info.Size(); c++) 20. info[c] = Swap(info[c]); 21. View(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg[], ulong value) 25. { 26. arg[0].u32_bits = (uint)(value >> 32); 27. arg[1].u32_bits = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg[]) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg[c].u32_bits); 35. } 36. //+------------------------------------------------------------------+ 37. un_01 Swap(const un_01 &arg) 38. { 39. un_01 info = arg; 40. 41. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = info.u8_bits[i]; 44. info.u8_bits[i] = info.u8_bits[j]; 45. info.u8_bits[j] = tmp; 46. } 47. 48. return info; 49. } 50. //+------------------------------------------------------------------+
Código 01
Cuando ejecutamos este código 01, podremos ver, en el terminal de MetaTrader 5, la siguiente salida que se muestra justo abajo.
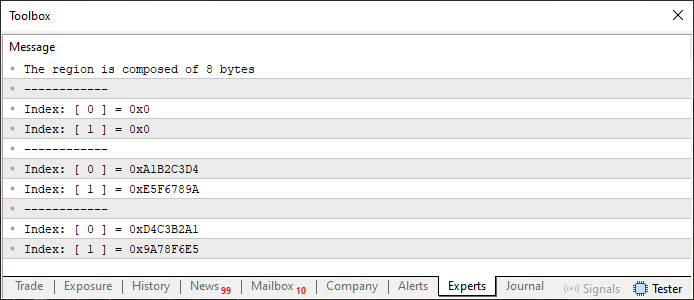
Imagen 01
En este código 01 aplicamos todo lo visto anteriormente, tanto en relación con el esquema y la forma de trabajar con arrays, como con la forma de trabajar y manejar una unión. Fíjate que en la línea 12 declaramos un array de tipo estático. Esto puede parecer extraño, ya que hasta ahora podrías pensar que solo se pueden utilizar tipos discretos en arrays. Pero aquí estamos usando un tipo especial, que se declaró en la línea 4. Es algo bien básico.
Sin embargo, al ejecutar la línea 14, se observa que la primera información impresa es la que indica que la variable info está compuesta por 8 bytes. Pero esto no tiene sentido a primera vista. Bien, mi querido lector, si tuviste esta sensación, te sugiero que regreses y estudies el artículo anterior, porque, de hecho, la variable info está compuesta por 8 bytes, ya que tenemos, como mayor ancho posible, la variable u32_bits, que es del tipo uint. Entonces, en realidad, sería como si estuviéramos declarando algo parecido a lo que se ve justo abajo.
. . . 12. uint info[2]; . . .
Creo que esto no es algo que te resulte confuso al verlo. Sin embargo, existe una declaración oculta en esta misma línea, que otro programador más observador también podría ver. Esta es la que vemos justo abajo.
. . . 12. uchar info[2][4]; . . .
¡Hombre! Espera un momento, ¿qué historia me estás contando? ¿Cómo que tenemos dos maneras de ver el mismo código, y dos formas de escribir lo mismo? Ahora sí que estoy bastante confundido, porque esto no tiene ningún sentido para mí.
Pues bien, querido lector, por eso insisto en que estudies y practiques lo que se muestra en cada artículo. El gran problema que veo en casi todos los principiantes es que se apegan mucho a la forma y a los modelos de programación, en realidad, no busca entender el concepto que se está creando y aplicando, sino que se aferra a lo que se está programando.
En el artículo anterior, mencioné que, cuando creamos una unión, en realidad estamos compartiendo y dividiendo las cosas en bloques más pequeños. Por tanto, puedes tomar un bloque de memoria, que sería bastante largo, y dividirlo en bloques más pequeños con el objetivo de manipular su contenido. Por esta razón, podemos girar, cambiar o intercambiar un punto específico sin utilizar ciertos operadores. No se debe a que una unión sea algo mágico, sino a que lo que estamos creando puede interpretarse de diversas maneras al mismo tiempo.
A pesar de no haber mencionado esto antes, tanto una como la otra forma de escribir la línea 12, que podemos ver arriba, representan lo mismo, solo que dividido de una manera diferente. En el primer caso, tenemos un array con dos elementos, donde cada elemento está compuesto por cuatro bytes. En el segundo caso, tenemos los mismos dos elementos, solo que esta vez cada elemento está compuesto por cuatro bytes. Mucha gente considera que los arrays multidimensionales son complicados de entender. Sin embargo, un array multidimensional, como el que se ve en la segunda forma de escribir la línea 12, no es más que el mismo array visto antes, solo que escrito de una manera diferente.
Los arrays multidimensionales son muy útiles para manejar diversas situaciones, pero se comprenden mejor cuando vayamos a hablar de otro tema en el futuro: las matrices. Hasta entonces, no veo motivo para hablar o explicar arrays multidimensionales. Así que, ten calma, querido lector, y céntrate en lo que se muestra aquí y ahora. Es decir, vive el presente y no te preocupes por el futuro.
Muy bien, una vez superado este primer contacto, y explicado lo que puede resultar algo confuso sobre el funcionamiento del código 01, podemos ver otra cosa en acción.
Una observación importante: no entraré en detalles sobre cómo funciona el código 01, porque ya se ha visto y explicado en otros artículos, y todo lo que se ha hecho allí se ha mostrado y explicado anteriormente. Si no lo estás comprendiendo, te recomiendo que primero estudies lo que se ha mostrado anteriormente, ya que no pretendo que te apegues al código o a la forma en que se está implementando. Lo que quiero es que entiendas lo que se está haciendo, y que logres crear tu propia solución, para obtener un resultado idéntico al mostrado en las imágenes. No un resultado parecido, sino IDÉNTICO.
Una vez hecha esta observación, podemos avanzar hacia nuestro próximo ejemplo, que se muestra justo a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. info = Swap(info); 20. View(info); 21. } 22. //+------------------------------------------------------------------+ 23. void Set(un_01 &arg, ulong value) 24. { 25. arg.u32_bits[0] = (uint)(value >> 32); 26. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 27. } 28. //+------------------------------------------------------------------+ 29. void View(const un_01 &arg) 30. { 31. Print("------------"); 32. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 33. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 34. } 35. //+------------------------------------------------------------------+ 36. un_01 Swap(const un_01 &arg) 37. { 38. un_01 info = arg; 39. 40. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = info.u8_bits[i]; 43. info.u8_bits[i] = info.u8_bits[j]; 44. info.u8_bits[j] = tmp; 45. } 46. 47. return info; 48. } 49. //+------------------------------------------------------------------+
Código 02
A continuación, veremos un código que, cuando se ejecuta, genera un resultado diferente. Este es el que podemos observar en el código 02. Parece muy similar al código 01, ¿no te parece, mi querido lector? Sin embargo, cuando se ejecuta, nos muestra algo que se ve justo abajo.
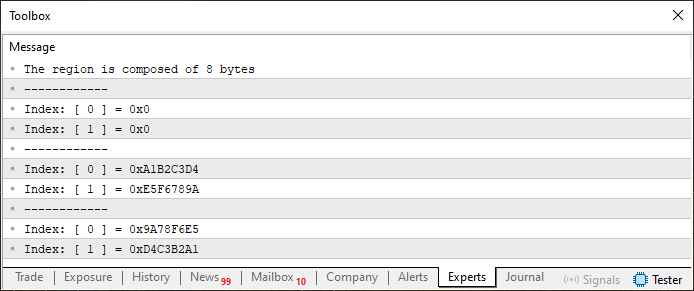
Imagen 02
Puede que estés pensando: «Pero es lo mismo que se obtuvo y se mostró en la imagen 1». Bien, míralo de nuevo, pero esta vez observa con aún más atención la imagen 2 y compárala con la imagen 1. ¿Todavía te parecen iguales, incluso tras observar atentamente cada valor? Pues, de hecho, son diferentes. Y el motivo es precisamente la declaración de la unión. Observa que ahora tenemos dos arrays dentro de la unión, ambos de tipo estático. Pero hay algo ahí que no parece tener mucho sentido. En el código 01, teníamos el array de la línea siete con cuatro elementos, pero ahora tenemos ocho. ¿Por qué? ¿No podríamos mantener los mismos cuatro elementos?
Bien, para entender esto correctamente, vamos por partes. Primero, veamos por qué hay que cambiar el número de elementos, y qué efectos tiene esto en la unión. Por esta razón, y para no complicar inútilmente el código, cambiaremos el valor que se pone como el número de elementos en el array declarado en la línea siete, de modo que este número sea siempre PAR. Si es impar, dará lugar a un pequeño problema que dificultará la comprensión de los resultados. Así que usa siempre un número par. Supongamos que, en lugar de poner ocho elementos, pongamos seis. Todo el resto del código deberá permanecer sin cambios. Así, tendremos algo como lo que se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[6]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Fragmento 01
Mira que solo cambié el número en la línea siete, y, al ejecutar el código 02 con este cambio visto arriba, el resultado es el que puedes observar justo abajo.
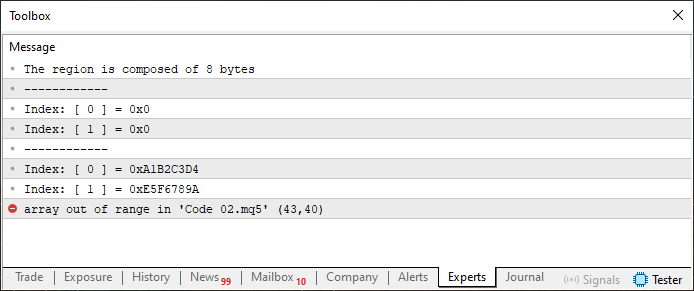
Imagen 03
Hum, esto no fue agradable. Pero, ahora vamos a cambiar el valor de la línea siete para que el número de elementos sea igual a diez. Así, tendremos lo que se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[10]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Fragmento 02
Al ejecutar el código, verás, como resultado, lo que se muestra en la imagen a continuación.
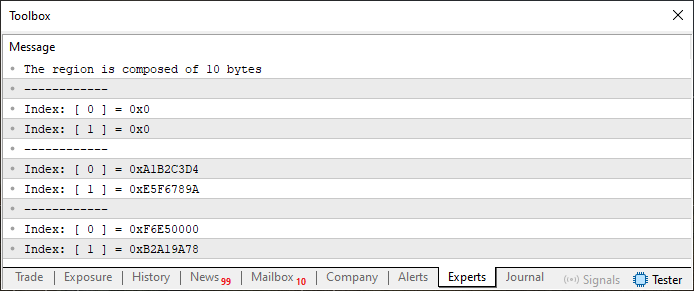
Imagen 04
No fue muy agradable, ya que, al parecer, algunos valores simplemente desaparecieron. Realmente no logré entender por qué ocurrió esto. Bien, mi querido lector, por eso estamos aquí, para ayudarte a entender algo que, a primera vista, no tiene mucho sentido. Pero, a medida que ganes experiencia y practiques, acabarás entendiendo mejor cómo y por qué funcionan las cosas. Pero lo principal es entender siempre el concepto que se está aplicando.
En el primer caso, donde se mostró la imagen 03 con un error que indicaba que el código habría fallado por intentar acceder a una región fuera del rango, el error ocurrió precisamente debido al hecho de que la variable info está compuesta por ocho bytes. Pero, presta atención, tú tienes la variable u8_bits, presente en la unión, que contiene seis elementos, o seis bytes, ya que cada elemento está compuesto por un byte, debido al ancho del tipo uchar. Por tanto, cuando usamos la variable j, que en ese momento apunta al octavo elemento de u8_bits, se produce un fallo en la ejecución de la línea 43. Por esta razón, el código falló. Sin embargo, no falló por usar más o menos elementos en u8_bits. Antes de mostrar cómo se haría la corrección para poder utilizar seis elementos en u8_bits, veamos qué ocurrió en el segundo caso, donde el resultado es el que podemos ver en la imagen 04.
En este caso, puedes observar que info contiene diez bytes o diez elementos, precisamente porque u8_bits contiene esos mismos diez elementos. Así, cuando hagamos el giro usando la función Swap presente en la línea 36, parte de esos valores se intercambiarán por valores inicializados por el procedimiento de la línea 15. Es decir, ceros, ya que ZeroMemory limpiará todo el bloque de la variable info.
Por esta razón, algunos valores aparentemente desaparecieron. Pero, en realidad, no desaparecieron, solo se colocaron en otro lugar. Para comprobarlo, vamos a hacer un pequeño cambio en el código. Para evitar el mismo resultado que se ve en las imágenes 03 y 04, mostramos justo abajo el nuevo código que vamos a usar.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. Set(info, 0xA1B2C3D4E5F6789A); 17. View(info); 18. Debug(info); 19. info = Swap(info); 20. View(info); 21. Debug(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg, ulong value) 25. { 26. arg.u32_bits[0] = (uint)(value >> 32); 27. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 35. } 36. //+------------------------------------------------------------------+ 37. void Debug(const un_01 &arg) 38. { 39. string sz = ""; 40. 41. Print("*************"); 42. for(uchar c = 0; c < (uchar)arg.u8_bits.Size(); c++) 43. sz = StringFormat("%s0x%X ", sz, arg.u8_bits[c]); 44. PrintFormat("Number of elements in %cinfo.u8_bits.Size()%c is %d\nInternal content is [ %s ]", 34, 34, arg.u8_bits.Size(), sz); 45. Print("*************"); 46. } 47. //+------------------------------------------------------------------+ 48. un_01 Swap(const un_01 &arg) 49. { 50. un_01 info = arg; 51. 52. for (uchar i = 0, j = (uchar)(info.u8_bits.Size() - 1), tmp; i < j; i++, j--) 53. { 54. tmp = info.u8_bits[i]; 55. info.u8_bits[i] = info.u8_bits[j]; 56. info.u8_bits[j] = tmp; 57. } 58. 59. return info; 60. } 61. //+------------------------------------------------------------------+
Código 03
Vale, al ejecutar este código, verás algo parecido con la imagen vista justo abajo.
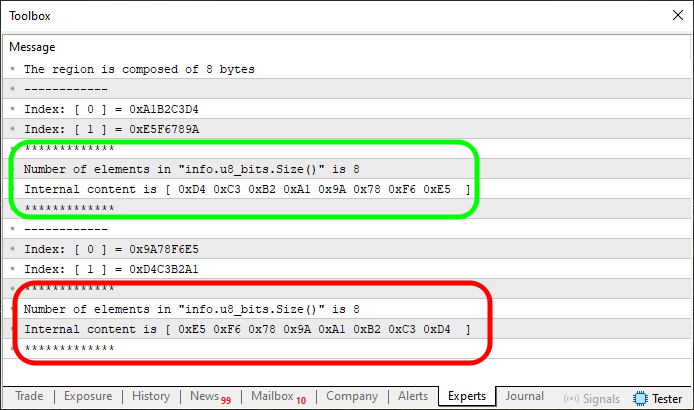
Imagen 05
Aquí tenemos algo que hará que toda la explicación sea mucho más fácil de comprender. Fíjate en que estoy marcando dos regiones en esta imagen 05. Pero observa que este código 03 es una modificación del código 02, donde la línea siete es lo que nos interesa aquí. Como necesitamos una ejecución para poder estandarizar las cosas y entenderlas, estamos usando el mismo valor en la línea siete de este código 03 que en el código 02, de modo que el resultado final sea lo que vemos en la imagen 05.
Ahora, presta mucha atención, querido lector, para que logres reproducir lo que se hará aquí de manera local. Observa que, en la línea 52 del código 03, he realizado un cambio para que el fallo observado en la imagen 03 no se repita. De esta forma, ahora podemos hacer lo que se intentó anteriormente.
Primero, vamos a usar el fragmento 01 en este código 03, y, al hacerlo, el resultado obtenido se muestra justo abajo.
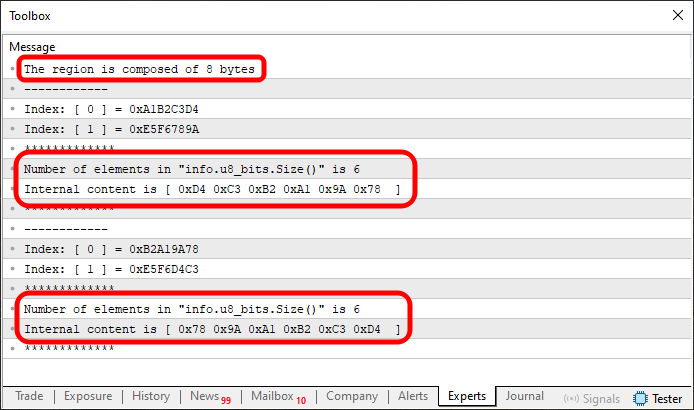
Imagen 06
En este caso, estoy marcando más puntos de interés, porque es muy importante que entiendas lo que se está haciendo dentro del código. Observa que, a pesar de tener un número menor de elementos en u8_bits, la operación se ha llevado a cabo. Sin embargo, observa el contenido del índice uno, percibe que parte de él continúa intacta. ¿Por qué? Bien, antes de responder, vamos a ver qué ocurre cuando usamos el fragmento 02 en este código 03.
Al hacerlo, tendremos como resultado lo que se muestra justo abajo.
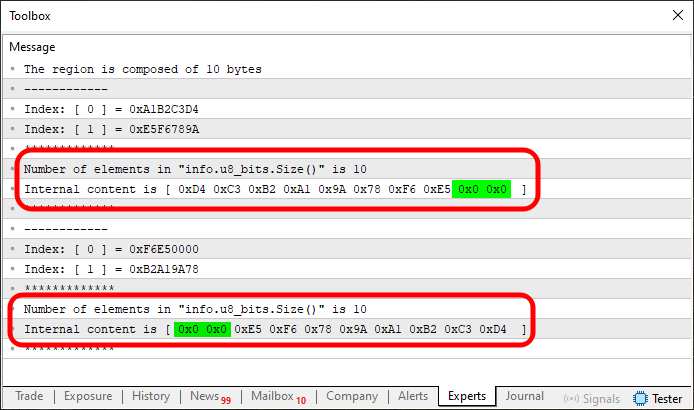
Imagen 07
Sí, de hecho, las cosas no son tan simples como había pensado. Calma, mi querido lector, calma. Todo aquí es muy sencillo y práctico. Basta con que prestes atención y practiques para entender cómo funcionan las cosas. No basta con leer el artículo y ya está. Es necesario practicar. Como puedes ver en las imágenes 06 y 07, la memoria se está girando o reflejando, como era de esperar. Sin embargo, el resultado observado en los índices del array, cuando accedemos directamente a los elementos en u32_bits, puede no corresponder a lo que habías imaginado. Y el motivo es precisamente que tenemos diferentes composiciones realizándose en la memoria.
En el caso de que la composición del array declarado en la memoria cubra completamente todos los bytes presentes en esa región, se obtiene una modelación perfecta. Por eso, vemos la imagen 05 mostrándose y mostrándonos exactamente lo que imaginábamos encontrar. Sin embargo, cuando dejamos algún byte sin cubrir o llegamos a cubrir una cantidad mayor de la necesaria, obtenemos un resultado completamente diferente y disperso. Esto se muestra en las imágenes 06 y 07, donde, en una, estamos cubriendo una región menor y, en la otra, una región mayor.
¿Entendiste ahora por qué fue necesario cambiar el valor del número de elementos en la línea siete? Si no se hace de manera adecuada, se termina con una cobertura inadecuada en algunas situaciones. Por eso, es necesario practicar y probar nuevas formas de hacer las cosas. Los archivos están en el anexo, no para adornar el artículo, sino para que los utilices y aprendas qué ocurre cuando cambiamos algo en nuestra forma de implementar algún tipo de solución. Úsalos para aprender y desarrollar conceptos adecuados sobre cada elemento de programación que se muestra en estos artículos. Solo así te convertirás en un programador excelente, y no en uno más del «copiar y pegar».
Muy bien, creo que ya se ha dado una buena base sobre cómo deberás estudiar lo que se muestra aquí en los artículos. Siendo así, imagino que ya estás listo para resolver una cuestión que se mostró en el artículo Del básico al intermedio: Array (IV). En realidad, vamos a hacer que aquel código sea mucho más interesante. Para explicarlo, iremos a un nuevo tema.
Hacer que lo que era bueno sea aún mejor
Vamos a hacer algo muy divertido y bueno. Sin embargo, para comprender perfectamente lo que se va a hacer aquí, es necesario que hayas dominado lo que se vio en el tema anterior. Si no has alcanzado este requisito previo, podrías quedar muy confundido y perdido con lo que se mostrará en este tema. Así que no tengas prisa. Estudia con calma y paciencia lo que se ha mostrado hasta ahora, y, solo después, atrévete a jugar con MQL5.
Dado este pequeño aviso, vamos a nuestra cuestión principal de este tema. Para esto, vamos a ver el código que fue mostrado en otro artículo que mencioné hace poco. Este se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Código 04
Cuando se ejecuta, este código 04 nos reportará el siguiente resultado, visto en la imagen justo abajo.
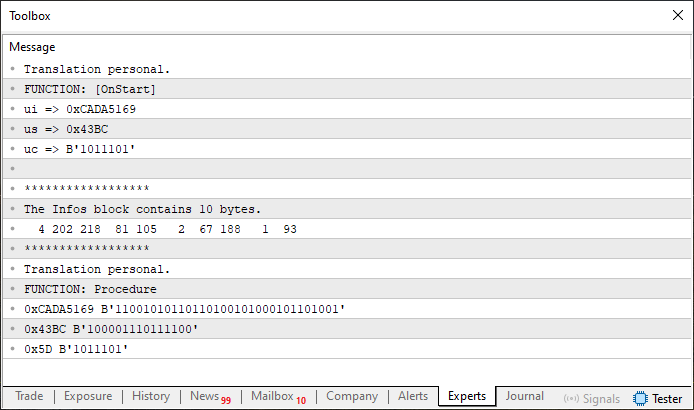
Imagen 08
El juego y el desafío que hay que afrontar aquí es precisamente convertir este código 04 en algo más fácil de implementar, de manera que utilice los recursos vistos hasta ahora. Bien, es posible que estés pensando: «Este tipo está muy loco. ¿Cómo puedo yo, que estoy aprendiendo a programar, usar lo visto hasta ahora para hacer que este código sea aún mejor?». Esto es una locura. Bien, mi querido lector, quien no practica y no se desafía de vez en cuando acaba quedándose atrás, ya que surgen cosas nuevas y conceptos más adecuados para hacer el mismo tipo de actividad.
Y, a medida que van surgiendo estos nuevos conceptos, nuestro trabajo disminuye, aumenta nuestra productividad y, al mismo tiempo, se dificulta que personas estáticas, del tipo «copiar y pegar», puedan seguirnos. Porque, en cada momento, vemos nuevas formas de obtener el mismo resultado, pero de manera más sencilla. Entonces, aprenderemos a usar los conocimientos adquiridos hasta ahora para mejorar este código 04. Para ello, primero debemos analizar lo que se está haciendo.
Básicamente, se observa que tenemos algunas variables y que estas se colocan en una cierta secuencia; el mayor ancho está dado por el tipo uint, presente en la línea ocho y utilizado entre las líneas 28 y 35, y todos los demás tipos son menores. Muy bien, siendo así, podemos pensar en una solución en la que el array Infos, declarado en la línea 12, reciba la información de manera que produzca el mismo contenido interno en su región de memoria. Pero, ¿cuál es ese contenido? Bien, necesitamos saberlo, de lo contrario, ¿cómo podremos estar seguros de que la implementación es correcta?
Observa la imagen 08 y verás que, en un determinado punto, se muestra el contenido exacto del array Info. Por tanto, todo lo que necesitamos es replicar ese mismo resultado, de una forma que el código sea más agradable de utilizar.
Perfecto. Ya tenemos por dónde empezar. Y, como se ha mostrado aquí y en el artículo anterior, podemos utilizar uniones para estructurar mejor los datos. Pero ¿cómo? Lo primero que necesitas hacer, querido lector, es crear una declaración de unión adecuada para colocar los valores dentro de ella. Como necesitaremos valores del tipo uint, ushort y uchar —esto debido a las líneas 28 hasta 48, donde accedemos a las variables y constantes declaradas en las líneas 8, 9 y 10—, probablemente imaginarás que necesitaremos declarar tres uniones. Sin embargo, bastará con declarar una, como puedes ver en el fragmento de abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { . . .
Fragmento 03
Muy bien, observa en este fragmento 03 que, en la línea seis, estamos creando una unión, y declarando un tipo discreto en cada una de las líneas para usarlo después. Esto tal vez pueda resultar un poco confuso a primera vista, pero lo realmente importante es la línea once, ya que es precisamente ahí donde se permite el acceso a toda la región perteneciente a la unión de los tipos. Fíjate que ahí estoy declarando un array estático con el número de elementos igual al mayor tipo discreto existente dentro de la unión. Este tipo de cosa se puede hacer siempre que te quede duda de cuántos bytes son necesarios dentro de la unión.
Ahora, puedes estar pensando: «Pero espera un momento... Si he entendido bien, cuando modificamos un valor —o, mejor dicho, una variable— presente en una unión, no estamos modificando solo una variable específica, sino todas las demás, pues forman parte de una misma región de memoria». ¿Estoy en lo cierto? Sí, mi querido lector, estás en lo cierto. Entonces, ¿no podemos usar esta unión declarada en este fragmento porque, en cuanto asignemos un valor a una de las variables, el valor de las demás también se verá afectado? De hecho, estás nuevamente en lo cierto, mi querido lector. Sin embargo, hay algo que todavía no he mencionado sobre las uniones y que precisamente vamos a utilizar aquí.
Lo que nos interesa es el valor que se le asignará a una de las variables. Lo que nos interesa es el contenido del array. Esto es lo que nos importa para poder construir el sistema deseado. Si has comprendido bien lo explicado en todos los artículos anteriores y te has esforzado por practicar, habrás notado que podemos copiar un array dentro de otro array. Entonces, sabiendo la cantidad de elementos que queremos copiar y teniendo el array que queremos copiar, podemos mejorar enormemente el código que está entre las líneas 28 y 48. ¿Cómo? Muy sencillo: copiando arrays. Para ello, utilizaremos el código que puede verse justo debajo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Código 05
Al ejecutar este código 05, verás el resultado que se muestra justo abajo.
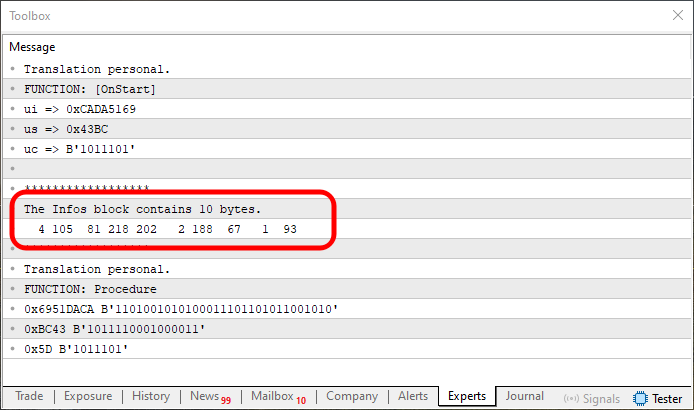
Imagen 09
Parece que funcionó. Bien, no es exactamente lo que ocurrió, mi querido lector. Si observas la región que marqué en esta imagen 09 y la comparas con la imagen 08, verás que los valores están rotados o reflejados. No es un problema para nosotros, ya que mostré cómo podemos reflejar los valores. Sin embargo, antes de hacer esto, quiero mostrarte otra solución, que, dependiendo del caso, puede ser suficiente.
Observa que los valores mostrados en la imagen 09 también están reflejados entre lo que se mostró en OnStart y lo que se mostró en Procedure. Sin embargo, dependiendo de la situación —y es importante que esto quede claro—, podemos ignorar el hecho de que el array está reflejado y utilizar la información que se ve justo abajo.
. . . 62. //+------------------------------------------------------------------+ 63. void Procedure(const uchar &arg[]) 64. { 65. un_Model data; 66. 67. Print("Translation personal.\n" + 68. "FUNCTION: ", __FUNCTION__); 69. 70. for (uchar c = 0; c < arg.Size(); ) 71. { 72. ZeroMemory(data.array); 73. c += (uchar)(ArrayCopy(data.array, arg, 0, c + 1, arg[c]) + 1); 74. Print("0x", ValueToString(data.u32, FORMAT_HEX), " B'", ValueToString(data.u32, FORMAT_BINARY), "'"); 75. } 76. } 77. //+------------------------------------------------------------------+
Fragmento 04
Si — y que esto quede muy claro — es posible utilizar este fragmento 04 en el código 05, el resultado final es el que se muestra justo abajo.
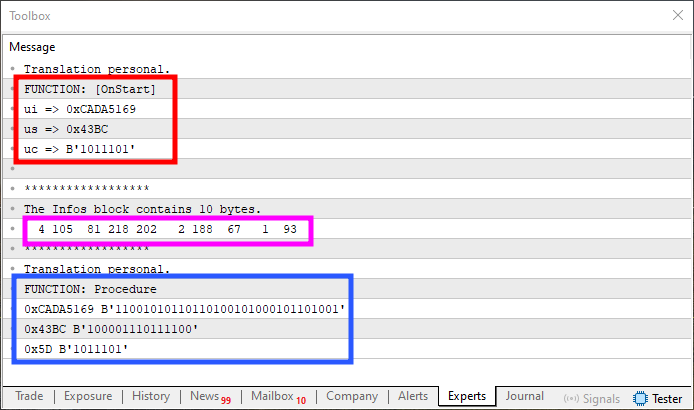
Imagen 10
Ahora, presta mucha atención, querido lector. Observa que, en la región roja de esta imagen 10, tenemos los valores originales. En la región de color azul, tenemos los valores de salida. Como puedes ver, no están reflejados en relación con los valores originales, como ocurría en la imagen 09. Sin embargo, la región en rosa, que representa exactamente el contenido presente en la memoria, se encuentra reflejada o desordenada, tal como se mostraba en la imagen 09. El resultado de salida y entrada de la imagen 10 es el mismo que el de la imagen 08.
Así, si el contenido presente en la memoria puede ignorarse, y el objetivo es lograr la entrada y salida con valores correctos, como se ve en la imagen 10, la solución vista en el fragmento 4 podría adoptarse. Pero, dependiendo del caso, este tipo de solución no se adapta a lo que realmente queremos o podemos utilizar, por lo que es necesario reflejar los datos para obtener el resultado final mostrado en la imagen 8.
Así, necesitamos hacer un pequeño añadido al código, para reflejar los valores antes de colocarlos en la memoria que se transferirá. Esto es sencillo: basta con cambiar el código por lo que se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { 16. const uint ui = 0xCADA5169; 17. ushort us = 0x43BC; 18. uchar uc = B'01011101'; 19. 20. uchar Infos[], 21. counter = 0; 22. 23. PrintFormat("Translation personal.\n" + 24. "FUNCTION: [%s]\n" + 25. "ui => 0x%s\n" + 26. "us => 0x%s\n" + 27. "uc => B'%s'\n", 28. __FUNCTION__, 29. ValueToString(ui, FORMAT_HEX), 30. ValueToString(us, FORMAT_HEX), 31. ValueToString(uc, FORMAT_BINARY) 32. ); 33. 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(uc)); 51. } 52. 53. Print("******************"); 54. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 55. ArrayPrint(Infos); 56. Print("******************"); 57. 58. Procedure(Infos); 59. 60. ArrayFree(Infos); 61. } 62. //+------------------------------------------------------------------+ 63. un_Model Swap(const un_Model &arg) 64. { 65. un_Model info = arg; 66. 67. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 68. { 69. tmp = info.array[i]; 70. info.array[i] = info.array[j]; 71. info.array[j] = tmp; 72. } 73. 74. return info; 75. } 76. //+------------------------------------------------------------------+ 77. void Procedure(const uchar &arg[]) 78. { 79. Print("Translation personal.\n" + 80. "FUNCTION: ", __FUNCTION__); 81. 82. ulong value; 83. 84. for (uchar c = 0; c < arg.Size(); ) 85. { 86. value = 0; 87. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 88. value = (value << 8) | arg[c]; 89. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 90. } 91. } 92. //+------------------------------------------------------------------+
Código 06
Bien, mi querido lector, el cambio se ha realizado. Sin embargo, a pesar de eso, mira el resultado justo abajo.
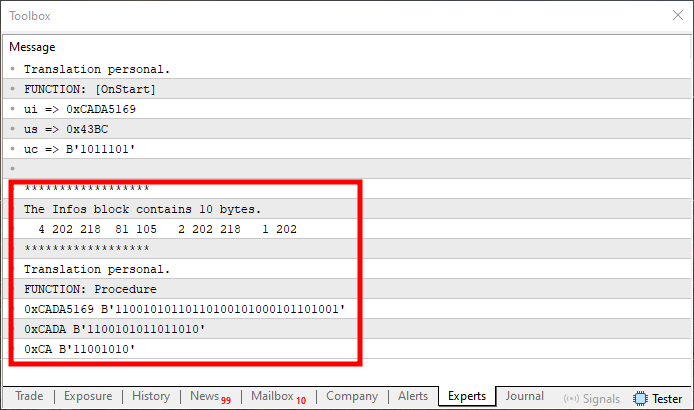
Imagen 11
Esto suele «matar» a muchos principiantes. Esto se debe a que solo el primer valor es correcto, tal y como se muestra en la imagen 08. Sin embargo, los demás están equivocados. ¿Por qué? El motivo está precisamente en la cuestión del valor de start, que necesita configurarse de la manera correcta, mi querido lector, esto se encuentra en las líneas 45 y 50. Como el valor de start es igual a cero, la posición inicial es incorrecta, y solo se copia el primer elemento del array presente en la unión. Y, como viste en el tema anterior, el array se ha rotado, de modo que este primer elemento, ahora, en realidad, es el último.
Entonces, para corregir esto, necesitamos cambiar las líneas 45 y 50 por lo que se muestra justo abajo.
. . . 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(us), sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(uc), sizeof(uc)); 51. } . . .
Fragmento 05
Al ejecutar el código 06 con estos cambios, mostrados en el fragmento 05, el resultado es el que se observa en la imagen 12, es decir, igual al que se esperaba debido a la imagen 08. Es decir, funciona perfectamente. Sin embargo, al observar este fragmento 05, pronto se nota que podemos meterlo dentro de un bucle, esto se debe a que hay muchas partes que se repiten. Entonces, el código final, que tendrás en el anexo para poder estudiar, se muestra justo abajo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Código 07
Consideraciones finales
En este artículo, abordamos varios puntos muy interesantes con el objetivo claro de entender cómo se colocan los datos en la memoria y cómo se trabajan. Aunque lo que se ha visto aquí pueda exigir que tú, mi querido y estimado lector, te esfuerces un poco más allá de lo que muchos están dispuestos a esforzarse, cualquier avance que logres hacer para comprender lo que se ha mostrado aquí te beneficiará enormemente en el futuro.
Esto se debe a que, sin necesidad de hablar de ciertas cosas, aquí podemos ver que no todo es tan complicado como parece a primera vista, y que no todo es tan simple que, con una breve lectura, podamos entenderlo todo. Es necesario practicar y estudiar constantemente. Pero, sobre todo, es necesario esforzarse por entender los conceptos involucrados en el desarrollo de cualquier aplicación.
Aceptar simplemente que un código u otro, creado por otro programador, te parece más adecuado, no te ayudará en absoluto a crear algo adecuado. Puede que te parezca adecuado en ese momento, pero, cuando se ponga en funcionamiento, terminará decepcionándote debido a fallos y problemas que no lograrás resolver por falta de conocimiento. Así que diviértete con los códigos del anexo y procura practicar y estudiar lo que se ha visto aquí. Nos vemos en el próximo artículo.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15503
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Del básico al intermedio: Unión (I)
Del básico al intermedio: Unión (I)
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso