MQL5 中的范畴论 (第 16 部分):多层感知器函子
概述
到目前为止,该系列已经展示了如何在 MQL5 代码中表示和使用范畴论中的一些基本概念,从而帮助交易者开发更强壮的交易系统。范畴论的主题有很多层面,但按理说两个关键方面可能是函子和性质变换。故此,通过再次讨论函子(就像我们之前的两篇文章一样),我们强调了该主题的顶端思路之一。
本文的重点是,即使我们仍然坚持使用函子,也会探索生成进场和出场信号的应用,不像过去我们只关注尾随止损的调整。这并不意味着附带代码中会有圣杯,而应当是读者根据他如何看待市场来改进和修改的思路。
回顾:MQL5 中的函子和图论
函子是范畴之间的映射,它不仅捕获跨越两个范畴中对象之间的关系,还捕获跨越这些范畴的态射之间的关系。这意味着在进行预测时,我们在代码中将它们实现为这两种映射之一,因为交叉对象的映射会有效地检查交叉态射,反之亦然。
在系列的第 11 篇文章概述了图论可视作用箭头和顶点相互连接来表述的系统。在我们的上一篇文章中,尽管我们曾利用 MetaQuotes 的 MetaTrader 5 终端提供的经济日历数据来概括它们,并用一个简单的假设把构成时间序列一部分的 4 个不同数据点链接起来。如本文所示,该图形本身实际上就是一个范畴。
我们在上一篇文章中曾通览过函子,可由一个简单的线性方程映射两个范畴。共享的代码中有一些选项可以将其扩展到二次方程,不过那篇文章只是承担测试任务,故并未实现这样功能。故此,函子的映射本质上是将域范畴中的对象值乘以系数,然后添加一个常量来获得协域中的对象值。它是线性的,因为系数和常数实际上是简单线性方程的斜率和 y 截距。
来自财经日历数据的范畴论函子
通过运用图论达成财经日历数据重新格式化,并作为一个范畴,适合得出日历数据复杂的相互关联性。从 MetaTrader 5 终端的日历选项卡中可以看出,有大量不同类型的财经数据。这个问题在之前的文章中已经强调过,需要将这些数据配对,鉴于货币对的特殊性,针对货币对制定交易决策会很困难。对于预期的证券,尽管在上一篇文章和本文中,没有必要将数据配对,但仍然应当考虑其中一些数据依赖于其它财经数据的概念,特别是考虑到我们的证券普适性,标普 500 指数。故此,为了定位这个问题,我们在上一篇文章中提出了一个简单的假设,即 CPI 数据依赖于 PMI 数据,PMI 又依赖于最新的 10 年期竞卖收益率,竞卖收益率又受到零售销售的影响。因此,时间序列并非只有其中一个经济数据点,而是针对标准普尔 500 指数波动,我们得到由多个点形成的系列基础。
不过,在这篇文章中,我们对标普 500 指数更感兴趣,不仅仅是因为它的波动性,就像上一篇文章的情况,还有它的趋势。我们希望对其短期(月度)趋势进行预测,并在我们的智能系统中使用这些预测开仓。这意味着我们与智能信号类打交道,而不是智能尾随类,就像该系列到目前为止的情况一样。那么,依据财经日历数据图形实现基于函子的变换将导致标普 500 指数的预测变化。这种实现将在多层感知器的帮助下达成。
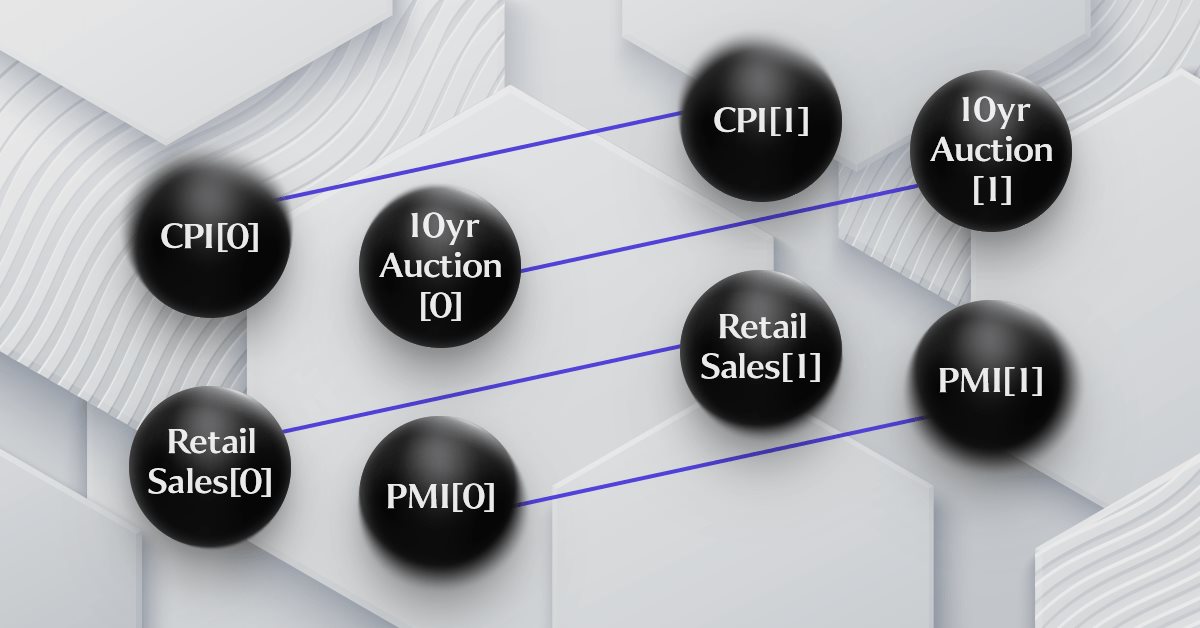
在上一篇文章中,我们确实有一个简单假设的制程表述,它链接了所考虑的四个财经数据点,不过它被过度简化了,并没有将其显示为时间序列图形。下面的示意图尝试达成这一点:

如您从示意图中所见,添加时间序列对象确实增加了一些复杂性,这清晰地支持了这是图形的情况。该假设的依据是值得商榷的,举例,人们可能会认为 CPI 是零售销售的结果,而零售销售又受到 PMI 的影响,而 PMI 又由货币供应量决定,货币供应量又以 10 年期竞卖业绩来衡量。诸如此类。甚至还有许多其它具有不同、或更多财经数据点的排列组合,这些大概在影响预测标普 500 指数增量方面更为关键。好消息是,尽管存在所有这些可能的排列和假设,终端中的策略测试器可以平息所有这些争议,这就是为什么按照某种格式清楚地罗列出您的想法,有助于有效测试。
为了助力这一点,MQL5 向导能够只需点击几下即可轻松组装智能交易系统,编写好的一体化代码都在一个信号文件之中。
标准普尔 500 指数值的范畴论函子
在信号文件内,将标普 500 指数值表述为图形相当于一个范畴,因为正如上一篇文章所分享的,每个图形顶点(数据点)等价于一个对象,因此顶点之间的箭头可以被视为态射。一个对象可以有一个元素,但在这种情况下,数据点不仅包含我们感兴趣的数值,还有我们的范畴未考虑的额外数据包括:财经数据发布日期、该数据发布前的预测共识、以及 MetaTrader 终端的日历选项卡中列出的其它数据。此链接指向一个包含日历事件类型的页面,列举的每个属性都适用于我们的对象。然后,所有这些数据将在财经日历范畴中形成一个对象,或我们所说的集合。
若要利用函子来分析和预处理历史财经日历数据,不幸的是,这在策略测试器中只能通过第三方完成,而不能直接从 MetaQuotes 的服务器完成。这当然是一个瓶颈问题,我们已经通过脚本将数据导出到 csv,然后像上一篇文章一样在策略测试器中读取该 csv。于此的区别在于,我们在执行此操作时,针对的是智能信号类实例,而非尾随类。由于我们正在与两个函子打交道,因此所用脚本在两个文件写入,其一前缀为 “true”,意即函子交叉对象,另一个前缀为 “false”,意即交叉态射。写入文件附在文章末尾。
上面的示意图中共享了转换后的标普 500 指数值的基于图形的表示。
基于函子的神经网络架构
在本文中,函子作为多层感知器(神经网络)比我们之前跨范畴、甚至范畴内对象(因为两个元素之间的态射关系可以用相同的方式定义)映射时所用的线性或二次关系更进一步。如前强调的,函子的使用不仅意味着两个范畴中的对象交叉映射,还意味着它们各自交叉态射。因此,彼此能够互查,即如果您知道协域范畴中的对象,则隐含态射,反之亦然。这意味着我们将与范畴之间的两个感知器打交道。
本文也不会提供关于感知器的入门知识,因为已有太多文章,不仅有发表在本网站上的文章,也有普遍的在线文章,故邀请好奇的读者自行去背景研究,这将有助于澄清这里讲述的内容。此处实现的网络架构很大程度上要归功于 Alglib,它可从 MetaTrader 的 IDE 中的 “Include\Math” 文件夹下访问。这是如何使用函数库执行感知器初始化:
//+------------------------------------------------------------------+ //| Function to train Perceptron. | //+------------------------------------------------------------------+ bool CSignalCT::Train(CMultilayerPerceptron &MLP) { CMLPBase _base; CMLPTrain _train; if(!ReadPerceptron(m_training_profit)) { _base.MLPCreate1(__INPUTS,m_hidden,__OUTPUTS,MLP); m_training_profit=0.0; } else { printf(__FUNCSIG__+" read perceptron, with profit: "+DoubleToString(m_training_profit)); } ... return(false); }
该函数库中所用的感知器非常基本,它们由三层组成。输入层、隐藏层和输出层。我们的财经数据范畴一次有四个数据点(基于我们的假设),故隐藏层中的输入数量将为四个。隐藏层上的数据点数量是为数不多的可优化参数之一,但我们的默认值是 7。最后,输出层中有一个输出,即标普 500 指数的预测变化。权重、背离和激活函数的知识是理解感知器前馈工作的关键。再次邀请读者在必要时自行研究这些知识点。
训练基于函子的神经网络
历史财经日历数据的训练过程将采用 Levenberg-Marquardt 算法完成。与前馈和反向验算一样,该编码由 AlgLib 函数处理。我们将据函数库实现以下训练:
int _info=0; CMatrixDouble _xy; CMLPReport _report; TrainingLoad(m_training_stop,_xy,m_training_points,m_testing_points); // if(m_training_points>0) { _train.MLPTrainLM(MLP,_xy,m_training_points,m_decay,m_restarts,_info,_report); if(_info>0){ return(true); } }
此处的关键部分是从共用目录中 csv 文件中读取输入数据,并填充 XY 矩阵。每当生成新柱线(或计时器)时,矩阵都会获取每个数据行上定义的四个数据点作为历史数据,并用它来训练网络,从而生成其权重和背离。由 “TrainingLoad” 函数处理 XY 输入矩阵的填充,如下所示:
//+------------------------------------------------------------------+ //| Function Get Training Points and Initialize Training Matrix. | //+------------------------------------------------------------------+ void CSignalCT::TrainingLoad(datetime Date,CMatrixDouble &XY,int &TrainingPoints,int &TestingPoints) { TrainingPoints=0; TestingPoints=0; ResetLastError(); string _file="_s_"+m_currency+"_"+m_symbol.Name()+"_"+EnumToString(m_period)+"_"+string(m_objects)+".csv"; int _handle=FileOpen(_file,FILE_SHARE_READ|FILE_ANSI|FILE_COMMON,"\n",CP_ACP); if(_handle!=INVALID_HANDLE) { string _line=""; int _line_length=0; while(!FileIsLineEnding(_handle)) { //--- find out how many characters are used for writing the line _line_length=FileReadInteger(_handle,INT_VALUE); //--- read the line _line=FileReadString(_handle,_line_length); string _values[]; ushort _separator=StringGetCharacter(",",0); if(StringSplit(_line,_separator,_values)==6) { datetime _date=StringToTime(_values[0]); _d_economic.Let(); _d_economic.Cardinality(4); //printf(__FUNCSIG__+" initializing for: "+TimeToString(Date)+" at: "+TimeToString(_date)); if(_date<Date) { TrainingPoints++; // XY.Resize(TrainingPoints,__INPUTS+__OUTPUTS); for(int i=0;i<__INPUTS;i++) { XY[TrainingPoints-1].Set(i,StringToDouble(_values[i+1])); } // XY[TrainingPoints-1].Set(__INPUTS,StringToDouble(_values[__INPUTS+1])); } else { TestingPoints++; } } } FileClose(_handle); } else { printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError())); } }
值得注意的是,经过训练后,神经网络之所以起作用并流行,原因在于它们能够开发和重用权重和背离。对于本文,这些权重和背离的存储由一个自定义函数处理,作者目前不愿意共享该函数,因此在清单中它作为 ex5 函数库的引用出现,但不提供其代码。
通常,在训练网络时,会涉及数据预处理,其着眼于将数据常规化为可比较值,并将其拆分为训练集和测试集。不过,出于我们的训练目的,我们在智能系统初始化时加载历史数据集,然后使用单独的 csv 数据部分对其进行测试,该部分与训练数据按输入日期定义拆分。由于我们唯一可优化的参数是隐藏层中的权重数字(从 5 到 12),并在每次优化验算结束时,仅当该次验算的优化准则超过先前验算中已写入文件的优化准则时,我们才将训练的网络权重写入共用目录中的文件。如果达成这一点,并写入了文件,那么在下一次验算网络初始化时,初始权重将从该文件读取。
反向传播和梯度下降都由 AlgLib 的 “CMLPTrain” 类中的 “MLPTrainLM” 函数处理。
使用函子和神经网络生成交易信号
标普 500 指数范畴是指数变化的线性序,与财经日历数据范畴中的“两个”函子形成一个协域。总而言之,有“两个”,因为对象和态射两者都要链接。故此,我们在测试期间的信号是由从 csv 文件中读取的输入日期定义,且依据每次训练结束时获得的权重产生。本文所附代码的训练,是在每次智能系统初始化时发生。附加的是一个信号文件,与之前文章中附加的尾随文件一样,一旦通过 MetaEditor IDE 在 MQL5 向导中组装即可使用。我们可以依据计时器进行额外的训练,因为每个新柱线都为我们的 csv 文件提供了一行新的数据,不过本文并不会探讨这种方式,而是邀请读者独立探索,因为也许会从中快速拾取更多紧急信号。
与过去的文章一样,我们的 “GetOutput” 函数将负责从我们的交易决策过程中获取数值。正如下面的清单中所见,除了使用当前值更新范畴外,网络输入还基于共用目录中 csv 文件的当前日历读数来做准备,这些输入被填充到 “_x_inputs” 数组当中,而该数组会被转发到网络,函数 “MLPProcess” 是 “CMLPBase” 类的一部分。清单如下所列:
//+------------------------------------------------------------------+ //| Get Output value, forecast for next change in price bar range. | //+------------------------------------------------------------------+ double CSignalCT::GetOutput(datetime Date) { if(Date>=D'2023.07.01') { printf(__FUNCSIG__+" log profit: "+DoubleToString(m_training_profit)+", account profit: "+DoubleToString(m_account.Profit())+", equity: "+DoubleToString(m_account.Equity())+", deposit: "+DoubleToString(m_training_deposit)); if(m_training_profit<m_account.Equity()-m_training_deposit) { printf(__FUNCSIG__+" perceptron write... "); m_training_profit=m_account.Equity()-m_training_deposit; WritePerceptron(m_training_profit,_MLP); } } ... _value="";_e.Let();_e.Cardinality(1); _d_economic.Get(3,_e);_e.Get(0,_value); _x_inputs[3]=StringToDouble(_value);//printf(__FUNCSIG__+" val 4: "+_value); //forward feed?... CMLPBase _base; _base.MLPProcess(_MLP,_x_inputs,_y_inputs); _output=_y_inputs[0]; //printf(__FUNCSIG__+" output is: "+DoubleToString(_output)); return(_output); }
在运用这些方法的交易系统中,也有可能将风险管理和持仓规模纳入其中,这些方法可能涉及根据信号的幅度进行规模调整。这当然需要对信号值进行常规化,并且与往常一样,当涉及持仓规模的变化时,需要格外小心。不过,这些变化可以通过创建 “ExpertMoney” 类的自定义实例来实现,就像我们在定义入场和离场点时所用的 “ExpertSignal” 类的自定义实例一样。
回溯测试和性能评估
我们的回溯测试将对隐藏层中的理想权重数字进行优化。由于这些范围从 5 到 12,因此只有 8 个选项,但我们希望在选择理想数字之前对每个数字的权重运行多次。因此,为了获得多次运行,我们添加了一个参数,该参数对智能系统的性能没有任何影响,但必须进行优化,因此在优化过程中增加了额外的运行,以便允许每个权重数字的选项实现运行多次测试。如上所述,在每次运行结束时,如果测试结果优于在共用文件夹文件中写入的最后一个结果,则这些权重将替换之前写入的权重。给出的优化准则将是最大盈利。我们在月度时间帧内运行,因为财经日历数据的平均更新频率差不多如此。标普 500 指数的测试运行时间为 2022-07-01 至 2023-08-01,月度时间帧,我们的对象到对象函子的最佳运行结果报告如下:

类似地,我们的态射到态射函子产生了以下报告:

分析报告中关于回撤和盈利因子的关键指标,捡取态射到态射函子作为最佳表现。或许这是值得进一步研究的?这个问题的答案不仅要基于替代证券的进一步测试,还在于使用不同的训练方法进行测试运行,例如考虑是否应该对每根新柱线、或每季度进行一次训练。
结束语
总而言之,使用感知器进行测试的主要发现是可以利用信号(诸如信号文件中存在的信号)开发一个交易系统。在开发之前,需要有一个合适的域范畴,其数据格式易于策略测试器访问,且鉴于可靠的测试往往需要跨越多年,因此这些数据需要延申。
使用多层感知器作为函子的意义不仅仅是一个进步,而且受惠于神经网络可采取的类型和格式很多。文章中分享了关于进一步研究感知器的超链接,但这是一个众所周知、且文档众多的主题,因此它们仅用作指向。极限、协限和通用属性中已经涵盖的许多概念都可以在神经网络的帮助下制定。
参考
维基百科共享链接。
附件注意事项
将文件 'SignalCT_16_.mqh' 放在文件夹 'MQL5\include\Expert\Signal\' 中,文件 'ct_16.mqh' 可以放在 'MQL5\include\' 文件夹中。
此外,您也许希望按照本指南了解如何使用向导组装智能交易系统,因为您需要将它们组装为智能交易系统的一部分。如文章中所述,我没有采用尾随止损和固定保证金进行资金管理,这两者都是 MQL5 标准库的一部分。始终如一,本文的目标不是向您出示圣杯,而是一个思路,您可以根据自己的策略进行定制。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/13116
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。