Diskussion zum Artikel "Neuronale Netze leicht gemacht (Teil 29): Der Algorithmus Advantage Actor Critic"
Hallo,
Gute Arbeit! Ich habe aktiv an auf Reinforcement Learning basierenden Handelsalgorithmen gearbeitet, und mir gefallen Ihre Artikel zu diesem Thema.
Ich habe eine Frage zu den Ergebnissen. Ich sehe, dass Sie nur die Handelsleistung der ersten 10 Tage (2022-09-01 bis 2022-09-10) zeigen. Hat der EA nach dem 10. Tag verloren?
/Rasoul
Hallo Dmitriy
vielen Dank für die ausführliche und sehr lehrreiche Artikelserie. Wirklich gut gemacht.
Nur eine Frage: nachdem ich den gesamten Code aus dem Anhang deines letzten Artikels (#29) heruntergeladen habe, kann ich nicht kompilieren, weil die Klassendefinition von CBufferDouble fehlt, die meiner Meinung nach in
NeuroNet_DNG\NeuroNet.mqh
sein sollte, aber das ist nicht der Fall.
Übersehe ich etwas?
Vielen Dank!
Beste Grüße
Paolo
Hallo Dmitrij
vielen Dank für die ausführliche und sehr lehrreiche Artikelserie. Wirklich gut gemacht.
Nur eine Frage: nachdem ich den gesamten Code aus dem Anhang deines letzten Artikels (#29) heruntergeladen habe, kann ich nicht kompilieren, weil die Klassendefinition von CBufferDouble fehlt, die meiner Meinung nach in
NeuroNet_DNG\NeuroNet.mqh
sein sollte, aber das ist nicht der Fall.
Übersehe ich etwas?
Danke!
Mit freundlichen Grüßen
Paolo
Hallo, im letzten Artikel habe ich CBufferDouble in CBufferFloat geändert. Seine Hilfe laufen Bibliothek auf GPU ohne Typ double.
Hallo Dmitriy,
Tolle Serie, ich bin ein großer Fan von dieser Arbeit. Ich habe auch versucht, die Reinforce EA zu kompilieren und sah, dass es auch die Aunto-Encoder (natürlich) benötigt, so fügte ich die letzte Version enthalten (aus Beitrag 22) VAE.mqh, jedoch aus irgendeinem Grund kann es nicht die Normal.mqh Definitionen finden:
![]()
Ich bin sicher, dass ich etwas falsch gemacht habe, ich hoffe, Sie können mir helfen.
Prost!
Hallo Dmitriy,
Tolle Serie, ich bin ein großer Fan von dieser Arbeit. Ich habe auch versucht, die Reinforce EA zu kompilieren und sah, dass es auch die Aunto-Encoder (natürlich) benötigt, so fügte ich die letzte Version enthalten (aus Beitrag 22) VAE.mqh, jedoch aus irgendeinem Grund kann es nicht die Normal.mqh Definitionen finden:
Ich bin sicher, ich habe etwas falsch gemacht, hoffe, Sie könnten helfen.
Prost!
Hallo, lade die letzte Version dieses Artikels https://www.mql5.com/ru/articles/11804
: Полностью параметризированная квантильная функция")
- www.mql5.com
Hallo, Laden Sie die letzte Version auf diesen Artikel https://www.mql5.com/ru/articles/11804
Vielen Dank Dmitriy für die schnelle Antwort und die Bereitstellung Ihrer Hilfe und wertvolle Zeit, aber ich habe immer noch das gleiche Ergebnis.
Anscheinend ruft FQF-learning nach FQF.mqh
Was wiederum NeuroNet aufruft...
Und dieses letzte ruft natürlich VAE.mqh auf.
Und die einzige Version, die ich finden konnte, ist die aus Beitrag 22...
Die Verwendung dieser Version führt dazu, dass die VAE keinen Verweis auf die Funktionen von Normal.mqh findet.
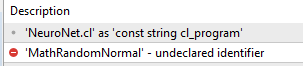
Könnte es an meiner Editor-Version liegen?

Ich danke Ihnen.
...Nun aus irgendeinem Grund die Normal lib ist unerreichbar auf VAE.mqh, wenn es von NeuroNet aufgerufen wird, ich weiß wirklich nicht, warum (ich versuchte auf 2 verschiedenen Builds)...
Also habe ich das Problem gelöst, indem ich den Aufruf von Normal direkt auf VAE und Neuronet hinzugefügt habe, aber ich musste den Math-Space auf dem FQF loswerden:
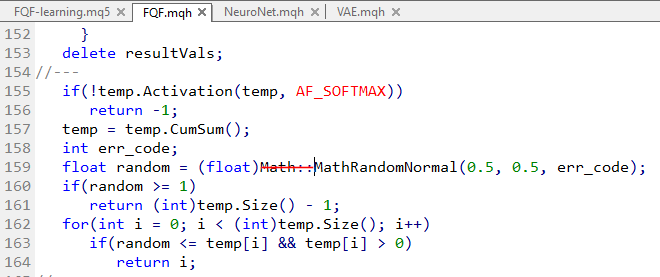
seltsam... aber es hat funktioniert:
Die Initialisierung schlug fehl, weil keine EURUSD_PERIOD_H1_REINFORCE.nnw vorhanden war, als die folgenden Anweisungen ausgeführt wurden
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
INIT_FAILED zurückgeben;
Wie lässt sich dieses Problem lösen? Vielen Dank!
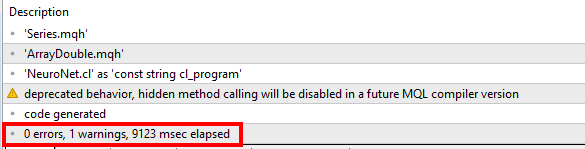
Eine andere Lösung für die Warnung "... hidden method calling ..."
In Zeile 327 von Actor_Critic.mq5:

Ich erhalte die Warnung "deprecated behavior, hidden method calling will be disabled in a future MQL compiler version":

Dies bezieht sich auf den Aufruf von "Maximum(0, 3)", der in geändert werden muss:

In diesem Fall müssen wir also "CArrayFloat::" hinzufügen, um die gewünschte Methode anzugeben. Die Maximum()-Methode wird von der Klasse CBufferFloat überschrieben, aber diese hat keine Parameter.
Obwohl der Aufruf eindeutig sein sollte, weil er zwei Parameter hat, will der Compiler, dass wir uns dessen bewusst sind ;-)
Die Initialisierung ist fehlgeschlagen, weil es keine EURUSD_PERIOD_H1_REINFORCE.nnw gibt, wenn die folgenden Anweisungen ausgeführt werden
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
return INIT_FAILED;
Wie lässt sich dieses Problem lösen? Danke!
In diesen Zeilen wird die Netzstruktur geladen, die trainiert werden soll. Sie müssen das Netz aufbauen und in der genannten Datei speichern , bevor Sie diesen EA starten. Sie können z.B. das Modellbildungstool in Artikel Nr. 23 verwenden
: Practicing Transfer Learning")
- www.mql5.com
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Neuronale Netze leicht gemacht (Teil 29): Der Algorithmus Advantage Actor Critic :
In den vorangegangenen Artikeln dieser Reihe haben wir zwei Algorithmen des verstärkten Lernens (Reinforcement Learning) kennengelernt. Jede von ihnen hat seine eigenen Vor- und Nachteile. Wie so oft in solchen Fällen kommt man dann auf die Idee, beide Methoden in einem Algorithmus zu kombinieren und das Beste aus beiden zu verwenden. Dies würde die Unzulänglichkeiten eines jeden von ihnen ausgleichen. Eine dieser Methoden wird in diesem Artikel erörtert.
Der Vorteil des zusätzlichen Trainings der Modelle aus früheren Artikeln ist, dass wir Test-EAs aus dem vorherigen Artikel verwenden können, um die Ergebnisse ihres Trainings zu überprüfen. So habe ich das gemacht. Nach dem Training des Modells nahm ich das zusätzlich trainierte Politikmodell und startete den „REINFORCE-test.mq5“ EA im Strategietester unter Verwendung des genannten Modells. Sein Algorithmus wurde im vorigen Artikel beschrieben. Der vollständige Code des EAs befindet sich im Anhang.
Unten sehen Sie ein Salden-Diagramm des EAs während des Tests. Sie können sehen, dass der Saldo während des Tests gleichmäßig zunahm. Beachten Sie, dass das Modell an Daten außerhalb der Trainingsstichprobe getestet wurde. Dies zeigt die Konsistenz des Ansatzes zum Aufbau eines Handelssystems. Um nur das Modell zu testen, wurden alle Operationen mit einem festen Mindestlot durchgeführt, ohne Stop-Loss und Take-Profit zu verwenden. Es wird dringend davon abgeraten, einen solchen EA für den echten Handel zu verwenden. Er demonstriert lediglich die Arbeit des trainierten Modells.
Auf dem Preischart können Sie sehen, wie schnell Verlustgeschäfte geschlossen werden und gewinnbringende Positionen eine Zeit lang gehalten werden. Alle Operationen werden bei der Eröffnung einer neuen Kerze durchgeführt. Sie können auch mehrere Handelsoperationen beobachten, die fast bei der Eröffnung von Umkehrkerzen (Fraktale) durchgeführt werden.
Autor: Dmitriy Gizlyk