文章 "开发多币种 EA 交易(第 19 部分):创建用 Python 实现的阶段"
您好、
在这段代码 中,我们通过执行 shell 命令来启动 Python:
//+------------------------------------------------------------------+ //| 启动任务| //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // 如果这是一项 EA 优化任务 if(m_type == TASK_TYPE_EX5) { // 在测试仪中启动新的优化任务 MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // 更新数据库中的任务状态 DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // 如果是执行 Python- 程序的任务 } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // 调用操作系统(Windows)的函数来执行 shell 命令 ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
其中
- m_pythonPath 是当前计算机上 Python 的路径;
- m_setting 是字符串,包含执行的 Python 程序的名称及其命令行参数
你好
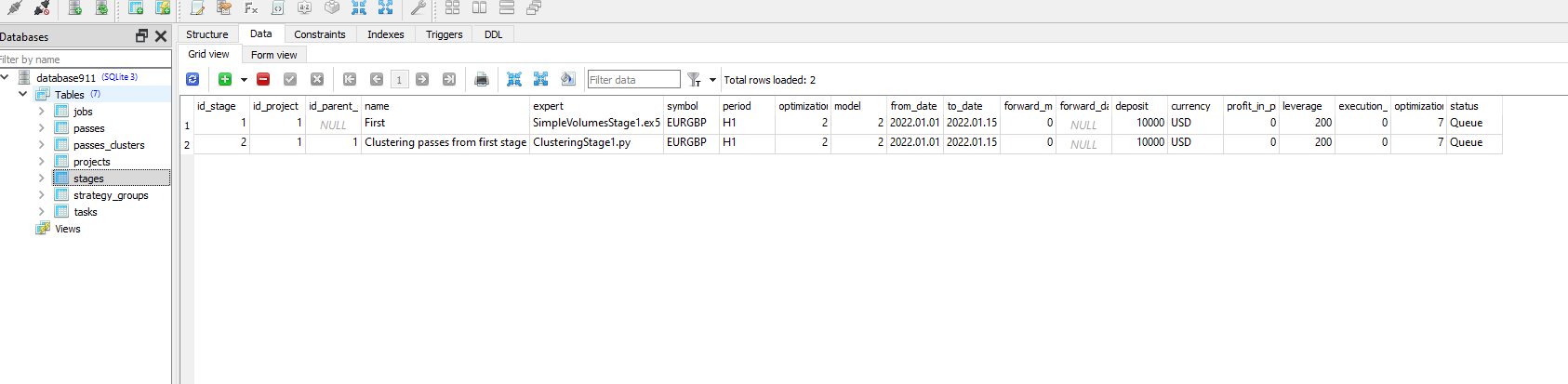
首先,我优化了 satge 1 并完成了优化
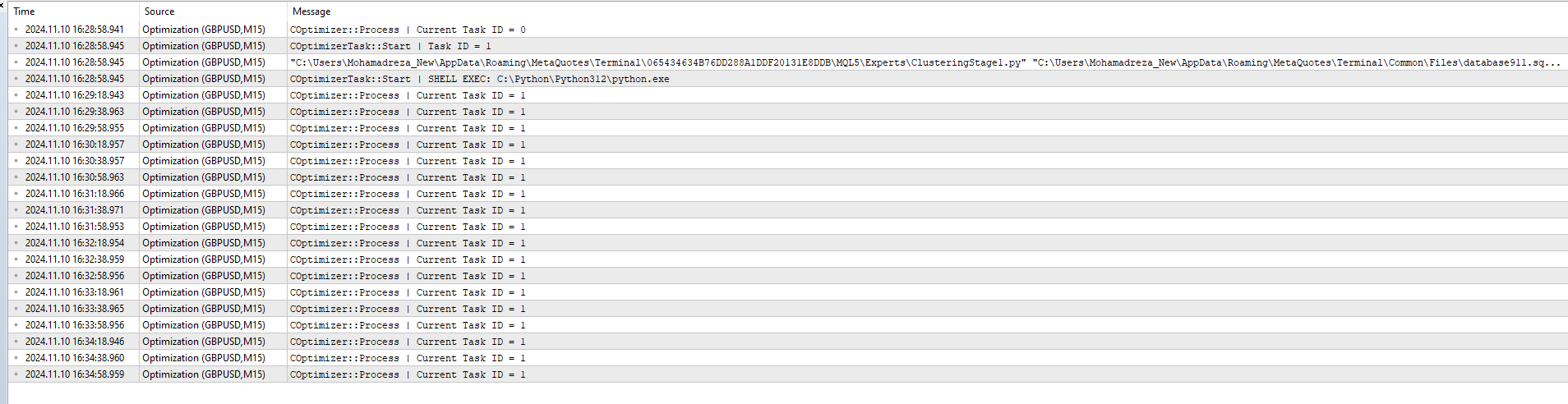
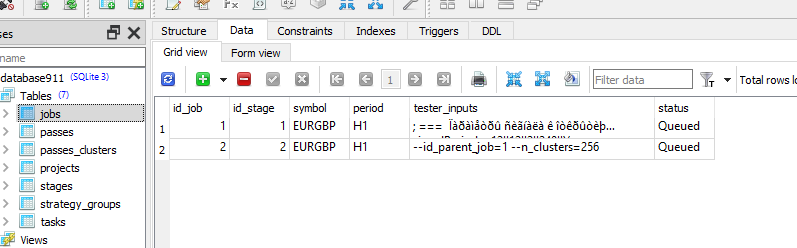
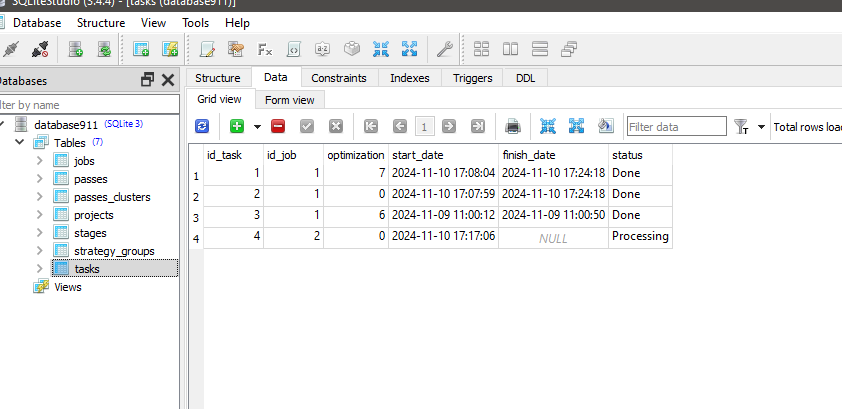
然后,我在数据库中添加了 ClusteringStage1.py、任务和工作,并再次优化,但没有成功,只是出现了这样的信息:
2024.11.10 16:35:18.952 Optimisation ( GBPUSD , M15) COptimizer::Process | Current Task ID = 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
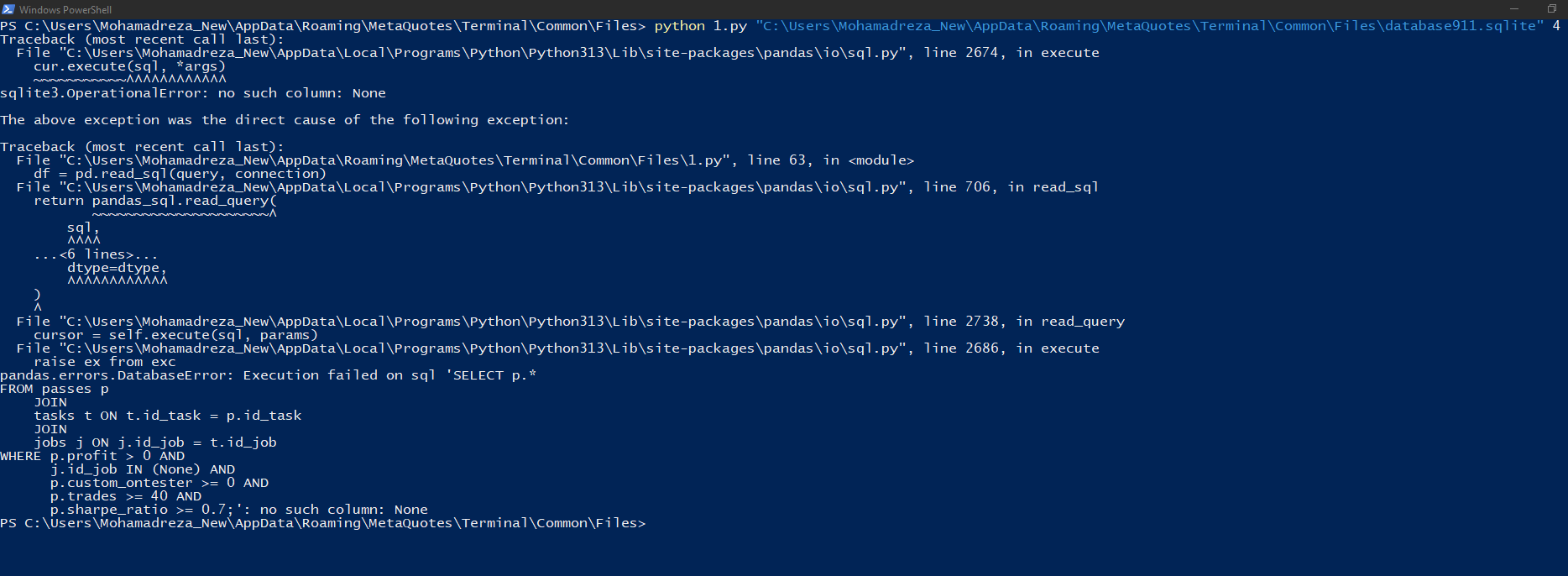
我在 powershell 中运行,看到如下内容
试试这样运行:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
我们需要设置参数:db_path、id_task。然后,我们得到了您发布的错误信息:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
我们还需要设置两个参数:--id_parent_job=1 -n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
你会得到什么?
我这样运行
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
得到以下错误
ValueError: n_samples=150 should be >= n_clusters=256.
然后我更改 n_clusters=150,并运行
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
我认为成功了。但数据库中没有任何变化
之后,我尝试用 n_samples=150 进行优化, 但没有成功
有趣的文章!那我就把整个系列读完。
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
他们为什么放弃 AlgLib 库的功能?
#include <Math\Alglib\alglib.mqh> 速度上的减分,但主要是因为 Python 可以在所有内核上进行并行计算。
新文章 开发多币种 EA 交易(第 19 部分):创建用 Python 实现的阶段已发布:
为了执行聚类,我们使用了现成的 Python 库 scikit-learn ,或者更准确地说,使用了 K-Means 算法的实现。这不是唯一的聚类算法,但考虑到其他可能的算法,比较和选择应用于该问题的最佳算法超出了可接受的范围。因此,基本上采用了第一种算法,使用它获得的结果非常好。
然而,使用这种特殊的实现使得有必要运行一个小型 Python 程序。当我们手动进行大部分操作时,这并不太麻烦。但现在我们已经在自动化测试和选择良好的单个交易策略实例组的整个过程方面取得了重大进展,即使是在顺序执行的优化任务的管道中间进行简单的手动操作也显得很糟糕。
为了解决这个问题,我们可以采取两条途径。第一种是找到集群算法的现成 MQL5 实现,或者自己实现。第二种涉及添加不仅启动用 MQL5 编写的 EA 的能力,而且还在自动优化的所需阶段启动 Python 程序的能力。
作者:Yuriy Bykov