
Нейросети в трейдинге: Спайковая архитектура пространственно-временного анализа рынка (Окончание)

Введение
Рынок всегда жил по своим законам — стремительным, неровным, с постоянной сменой темпа и настроений. Каждая свеча на графике, каждый всплеск тикового потока — это маленькое событие в огромном механизме, который никогда не останавливается. Казалось бы, что нового можно предложить в среде, где испробованы десятки аналитических подходов? Где медленные линейные модели давно уступили место глубоким нейронным сетям, а современные трансформеры уверенно вскрывают закономерности многомерных процессов? Но финансовые ряды, как и природа человеческого поведения, продолжают упрямо сопротивляться полному структурированию. Они всё так же непредсказуемы, насыщены шумом, нарушенными зависимостями и асинхронной динамикой, которая бросает вызов даже самым мощным алгоритмам.
Именно на этом фоне вновь и вновь возникает потребность в моделях, способных работать не просто с данными, а с потоком событий. Не со сглаженными свечами, а с живыми изменениями, мгновенными колебаниями, точечными реакциями рынка. Классические модели, даже основанные на рекуррентных сетях или трансформерах, нередко теряют важную часть рыночной динамики, потому что вынуждены укладывать её в фиксированные временные рамки. Финансовая среда намного ближе к событийной, она дышит неравномерно — ускоряется и замедляется, разрывает привычные временные интервалы.
В этом смысле спайковые архитектуры оказались идеологически ближе к природе рынков, чем можно было бы предположить изначально. Они реагируют на события, порождают импульсы, опираются на временные различия, приводя вычисления к форме, удивительно созвучной рыночному хаосу. Спайковая модель не наблюдает за данными раз в секунду. Она реагирует тогда, когда появляется причина реагировать. Не интерполирует пустые промежутки, а пропускает их, экономя ресурсы и концентрируясь на действительно важном.
Эта идея и привела нас к изучению SDformerFlow — архитектуры, изначально созданной для обработки событийных потоков от камер, но по духу невероятно близкой задачам анализа тиковых данных. Авторы фреймворка предложили изящный симбиоз спайковых нейронов и механизмов внимания, усилив оба подхода. Внимание стало компактным и энергосберегающим, а спайковая динамика — более структурированной и предсказуемой. Архитектура SDformerFlow не просто превращает поток событий в осмысленные представления — она делает это экономно, последовательно, с ясной логикой внутреннего устройства. Именно эта комбинация свойств делает её настолько интересной для использования в финансовых задачах.
Если вспомнить ключевые элементы модели, то центральная роль принадлежит SpatioTemporal Swin SpikeFormer Encoder (STSF) — своеобразному сердцу системы, которое объединяет свёрточную предварительную обработку данных, оконные механизмы внимания и слой за слоем формирует представление о структуре анализируемой информации. В оригинальной работе этот модуль отвечал за выделение пространственно-временной структуры оптического потока. Маленькие блоки событий объединялись в окна. Окна смещались таким образом, чтобы охватить всю сцену. А затем на их основе строилось обобщённое описание динамики.
Перенося этот подход в трейдинг, мы сохраняем общий принцип. Малые фрагменты временного ряда — те самые локальные события, всплески активности, ускорения тренда, сдвиги волатильности — играют ту же роль, что пиксельные участки событийной карты в задачах обработки видео. Финансовая динамика распадается на окна, которые перекрываются и дают возможность модели увидеть движение под разными углами, не упуская ни локальные, ни глобальные структуры.
Здесь проявляется одно из важных преимуществ SDformerFlow — адаптивность. В отличие от классического трансформера, где внимание тянется ко всем позициям разом и порождает огромные вычислительные затраты, оконный механизм позволяет детально изучать локальные зависимости, не перегружая систему. При этом смещённые окна дают возможность модели периодически встряхивать восприятие и видеть картину целиком. На рынках, где локальные фрагменты нередко преобладают над глобальными структурами, такая гибридная схема оказывается особенно ценной.
Спайковая составляющая архитектуры дополняет картину. Она позволяет модели реагировать не на абсолютные значения, а на изменения. Это идеально ложится на природу тиковых данных. Спайковый нейрон активируется только тогда, когда происходит значимый сдвиг. В моменты покоя он молчит, не создавая лишней нагрузки. Такой подход одновременно снижает вычислительные затраты и повышает устойчивость к шуму — ведь именно шум является главной проблемой финансовых рядов.
Авторская визуализация фреймворка SDformerFlow представлена ниже.

Когда мы начали переносить SDformerFlow в MQL5, стало ясно, что сама структура модели отлично подходит для встроенной оптимизации. Наличие оконных механизмов и чёткой событийной природы делает возможным распараллеливание вычислений. А спайковая активность — естественный способ уменьшить количество операций. Именно поэтому в предыдущих статьях мы реализовали базовые строительные блоки, включая спайковое внимание, остаточные структуры и модульные компоненты, необходимые для сборки полноценного encoder-блока. Всё это стало фундаментом для текущей работы, где мы переходим от отдельных элементов к цельной архитектуре.
Мы продолжим развивать архитектуру, шаг за шагом собирая всю логику SDformerFlow в единый рабочий фреймворк, способный анализировать рынок с точностью событийной модели и эффективностью современных трансформеров.
U-блок
В предыдущей статье мы завершили формирование SDSA-блока — центрального компонента STSF-энкодера, который стал для нашей модели своего рода интеллектуальным центром тяжести. Именно в нём мы объединили оконное внимание, спайковую динамику и остаточную структуру, создав механизм, способный улавливать скрытую временную геометрию событийного потока. После того как этот блок обрел завершённую форму, естественным шагом становится переход к построению декодера, ведь без него модель остаётся наполовину немой. Она умеет понимать структуру исходных данных, но ещё не умеет превращать внутренние представления в осмысленный выходной сигнал.
Когда мы вновь обращаемся к оригинальной архитектуре SDformerFlow, то видим любопытную деталь. Компоненты декодера по своей структуре повторяют архитектурный рисунок уже реализованного нами спайкового свёрточного блока CNeuronSpikeConvBlock. Такая схожесть — не случайность, а продуманная особенность модели. Авторы не стали создавать для декодера отдельную экзотическую конструкцию. Вместо этого они использовали хорошо работающий, компактный и энергетически эффективный механизм, погружённый в спайковую динамику и свёрточную обработку.
Этот момент играет нам на руку. Мы уже прошли весь путь от низкоуровневой реализации до оптимизации вычислительных ядер свёрточного блока средствами MQL5 и OpenCL. Мы убедились, что модуль справляется с нагрузкой, корректно реагирует на события и формирует стабильные выходы. А значит, архитектурный фундамент готов, и нам не нужно изобретать новый блок с нуля.
В этом есть своя красота. Архитектура остаётся цельной, без искусственных разрывов между энкодером и декодером. Все ключевые элементы говорят на одном языке — языке событийных свёрток, импульсной активации и согласованных масштабов. Это позволяет не только упростить реализацию, но и повысить устойчивость модели. Блоки, построенные на одних и тех же принципах, предсказуемо взаимодействуют между собой, а внутренние представления легко проходят путь от кодирования к восстановлению.
Следующим этапом нашей работы становится построение полноценной U-образной структуры, объединяющей энкодер и декодер в единый многослойный механизм. В авторской интерпретации SDformerFlow эта часть модели выглядит довольно традиционно. Несколько уровней SDSA-блоков, соединённых SPM-модулями (Spiking Patch Merge), формируют энкодер. А затем поток данных последовательно проходит через каскад спайковых свёрточных блоков, составляющих декодер. Между ними устанавливаются прямые горизонтальные связи, чтобы каждый уровень декодера мог получать дополненную информацию. Таким образом на вход каждого слоя декодера поступает конкатенированный тензор результатов работы предыдущего декодирующего блока и соответствующего слоя энкодера. Данная схема давно доказала свою эффективность в задачах, где важно сочетать глобальный охват и локальную чувствительность, позволяя модели извлекать структуру и восстанавливать её в различных масштабах.
Однако в нашей работе мы решили пойти немного иным путём. Инженерная практика подсказывает, что чрезмерное дробление архитектуры на множество отдельных объектов затрудняет реализацию и дальнейшее сопровождение модели. Особенно если речь идёт о глубоких структурах с несколькими уровнями вложенности, где каждый слой зависит от соседнего и формирует свой собственный масштаб представления. Поэтому вместо того, чтобы выстраивать энкодер и декодер в отдельных ветвях и соединять их вручную, мы выбрали более компактный и элегантный вариант — построить вложенную архитектуру, подобную матрёшке. В ней каждый уровень содержит сразу два компонента: энкодерную часть и декодерную, объединённые шеей.
Такой подход позволяет представить модель в виде серии самоподобных модулей, каждый из которых отражает принципы U-образной структуры, но в уменьшенном масштабе. Верхний уровень выступает глобальным каркасом, а внутри него скрывается следующий уровень — точно такой же, но более компактный. И так до тех пор, пока на дне вложений мы не достигнем MS-ResBlock — финального элемента, который служит ядром нашей структуры и замыкает архитектурную линию. Это решение даёт нам сразу несколько преимуществ.
Во-первых, мы получаем естественную симметрию. Энкодер и декодер в каждом слое развиваются параллельно и всегда имеют доступ к общему контексту, который обеспечивает шея. Во-вторых, такой подход существенно упрощает управление внутренними тензорами. Данные передаются строго по вложенной логике, уменьшая вероятность ошибок и перекрёстных несоответствий. В-третьих, в плане реализации это оказывается гораздо удобнее — каждый модуль становится не просто блоком, а самостоятельной структурной единицей, которой легко управлять. И которую легко расширять, заменять или модифицировать.
Но самое важное преимущество — в согласованности вычислительного потока. В классической U-образной архитектуре движение данных постоянно переключается между разными ветвями, требуя аккуратного контроля всех связей. В нашем вложенном подходе эта сложность исчезает. Переходы происходят внутри единого пространства блока, что делает архитектуру более собранной и устойчивой. Фактически, мы получаем уникальную разновидность U-образной сети, где каждый уровень является самостоятельным узлом, включающим в себя все необходимые компоненты — SDSA-энкодер, свёрточный спайковый декодер и соединяющую их шею, представленную вложенной U-структурой следующего уровня.
Последний уровень, где вместо вложения расположен MS-ResBlock, потянет на себя всю глубину вычислительной логики и станет центром финального преобразования. Этот блок хорошо подходит для роли самого глубокого узла. Он стабилен, компактен, обладает сильной пропускной способностью и умеет аккуратно собирать сигналы от всех верхних уровней, формируя фундамент для обратного хода декодера. Таким образом, наша рекурсивная архитектура сохраняет дух оригинального SDformerFlow, но адаптируется под реалии событийных рынков и особенности MQL5 — компактно, иерархично и с высокой степенью повторяемости структуры.
Для реализации вложенной U-образной архитектуры нам потребовалась новая структурная единица, способная объединить в себе сразу несколько уровней вычислений и обеспечить сквозное взаимодействие между энкодером, декодером и шеей блока. Эти требования привели нас к созданию отдельного объекта CNeuronSDformerUBlock — центрального элемента, который станет кирпичиком нашей матрёшечной структуры. Именно в нём сосредоточена логика двунаправленного прохождения данных, их соединения, обработки и последующего восстановления.
class CNeuronSDformerUBlock : public CNeuronSpikeConvBlock { protected: CLayer cEncoder; CNeuronBaseOCL* cNeck; CNeuronBaseOCL cConcat; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSDformerUBlock(void) {}; ~CNeuronSDformerUBlock(void) { DeleteObj(cNeck) }; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &windows[], uint &heads[], uint &layers[], uint dimension_k, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSDformerUBlock; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; virtual CBufferFloat* GetStack(void); };
Концептуально этот объект продолжает линию уже реализованных нами спайковых свёрточных модулей, поэтому наследование от CNeuronSpikeConvBlock выглядит не только естественным, но и крайне полезным. Это позволяет сохранить согласованность вычислительного интерфейса, повторно использовать проверенные механизмы и избегать дублирования кода. Но при этом новый класс значительно расширяет функциональность базового блока, превращаясь из простого модуля обработки в полноценный компонент U-образной архитектуры.
Структура объекта отражает его концептуальную роль. Внутри него сосуществуют три ключевых элемента. Первый — это блок энкодера cEncoder, который занимается нисходящим преобразованием данных и отвечает за извлечение структурных признаков на текущем уровне вложений. Второй — переменная cNeck, представляющая шею, то есть вложенный U-блок следующего уровня. Именно благодаря этому механизму создаётся иерархичность архитектуры. Каждый блок содержит внутри себя ещё один, более компактный, пока на самом нижнем уровне вложений структура не завершается MS-ResBlock. Третий элемент — модуль cConcat, который обеспечивает корректное объединение тензоров из энкодера и декодера предыдущего уровня, получаемого из шеи. Функционал декодера мы реализуем унаследованными средствами родительского класса.
Метод инициализации выступает своеобразным архитектором всей U-образной конструкции. Именно здесь абстрактная схема, описывающая количество уровней вложенности, число SDSA-блоков в каждом уровне, параметры окон и голов внимания, превращается в реальный набор взаимодействующих объектов.
bool CNeuronSDformerUBlock::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &windows[], uint &heads[], uint &layers[], uint dimension_k, ENUM_OPTIMIZATION optimization_type, uint batch) { uint block = layers.Size(); if(block <= 0 || block > heads.Size() || (block + 1) > windows.Size()) return false;
Полученный в параметрах метода массив layers определяет глубину матрёшки, задавая, сколько раз структура будет рекурсивно пробуриваться внутрь себя, пока, наконец, не упрётся в MS-Resblock на самом нижнем ярусе.
Работа метода начинается с проверки согласованности параметров: количество уровней должно совпадать с размерностью соответствующих массивов голов внимания и окон, поскольку каждая ступень U-структуры обязана опираться на строго определённый набор параметров. Если числа не бьются, дальнейшее строительство теряет смысл.
Когда полученные данные признаны корректными, управление предается одноименному методу родительского класса. В нём задаются основные параметры модуля декодирования: размеры окон, количество каналов и ключевые параметры оптимизации.
if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, 2 * windows[1], 2 * windows[1], windows[0], units, 1, optimization_type, batch)) return false;
Далее формируется энкодер — линейная последовательность SDSA-блоков, число которых задаётся layers[0]. Каждый SDSA-блок создаётся динамически, получает собственный индекс в пределах уровня и немедленно добавляется в контейнер cEncoder.
cEncoder.Clear(); cEncoder.SetOpenCL(OpenCL); //--- uint index = 0; CNeuronSDSA* sdsa = NULL; for(uint i = 0; i < layers[0]; i++) { sdsa = new CNeuronSDSA(); if(!sdsa || !sdsa.Init(0, index, OpenCL, units, windows[0], heads[0], dimension_k, optimization, iBatch) || !cEncoder.Add(sdsa)) { DeleteObj(sdsa) return false; } index++; }
Эта последовательность формирует входную ветвь уровня, где вычислительная нагрузка растёт по мере продвижения данных вниз по U-структуре.
Следующим шагом добавляется объект Spiking Patch Merge. Он объединяет пространственные фрагменты и уменьшает размерность, являясь точкой сужения перед шейным компонентом.
CNeuronSpikeConvBlock* spm = new CNeuronSpikeConvBlock(); if(!spm || !spm.Init(0, index, OpenCL, 2*windows[0], 2*windows[0], 2*windows[1], (units+1)/2, 1, optimization, iBatch) || !cEncoder.Add(spm)) { DeleteObj(spm) return false; } index++;
Логика выбора шеи зависит от глубины вложения. Если текущий уровень — последний, достаточно создать MS-Resblock. Именно он завершает нисходящую ветвь и начинает восходящую часть, где пространственные структуры восстанавливаются и уточняются.
if(block == 1) { CNeuronMSRes* neck = new CNeuronMSRes(); if(!neck || !neck.Init(0, index, OpenCL, units, windows[1], 1, optimization, iBatch)) { DeleteObj(neck) return false; } cNeck = neck; }
Но если глубина больше единицы, то в качестве шеи выступает вложенный U-блок. Для него формируются усечённые массивы параметров — без первых элементов. Поскольку каждый следующий уровень должен оперировать своими локальными размерами окон, голов внимания и количеством SDSA-слоёв.
else { uint new_layers[], new_windows[], new_heads[]; if(ArrayResize(new_layers, block - 1) < 0 || ArrayResize(new_windows, block) < 0 || ArrayResize(new_heads, block - 1) < 0) return false; if(ArrayCopy(new_heads, heads, 0, 1, block - 1) < (int(block) - 1) || ArrayCopy(new_layers, layers, 0, 1, block - 1) < (int(block) - 1) || ArrayCopy(new_windows, windows, 0, 1, block) < int(block)) return false;
Рекурсивный вызов создаёт новый CNeuronSDformerUBlock, фактически повторяя ту же логику, но уже для следующего слоя матрёшки.
CNeuronSDformerUBlock* neck = new CNeuronSDformerUBlock(); if(!neck || !neck.Init(0, index, OpenCL, units, new_windows, new_heads, new_layers, dimension_k, optimization, iBatch)) { DeleteObj(neck) return false; } cNeck = neck; } index++;
Финальным компонентом выступает объект cConcat, который отвечает за объединение тензоров декодера и параллельного слоя энкодера. Его инициализация требует учёта изменившейся размерности после SPM и шеи, что отражено в параметре с использованием окна второго уровня.
if(!cConcat.Init(0, index, OpenCL, 2 * windows[1]*units, optimization, iBatch)) return false; cConcat.SetActivationFunction(None); //--- return true; }
Конкатенатор — ключевой элемент восходящей части, который позволяет модели восстанавливать детали, используя как глубокие абстракции, так и высокоуровневые признаки.
После успешной инициализации всех элементов структура считается полностью построенной. Каждая компонент знает своё место, параметры согласованы, связи сформированы. А рекурсивная вложенность превращает логическую абстракцию в иерархический вычислительный механизм, способный сложным образом сворачивать и разворачивать сигналы.
При этом алгоритм прямого прохода выглядит удивительно чисто и слаженно, словно хорошо отрепетированная сцена. Каждый участник точно знает свой выход. Несмотря на вложенную природу U-блоков, код остаётся компактным и легко читаемым. А логика вычислительного потока — последовательной и интуитивной.
bool CNeuronSDformerUBlock::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *curr = NULL; for(int i = 0; i < cEncoder.Total(); i++) { curr = cEncoder[i]; if(!curr || !curr.FeedForward(prev)) return false; prev = curr; }
Прямой проход начинается с обхода энкодера. Формируется цепочка из SDSA-блоков и завершающего SPM, которые последовательно обрабатывают исходные данные. Каждый объект получает на вход результат предыдущего, постепенно уплотняя представление и передавая его дальше вниз по U-структуре. Эта часть работает как нисходящая ветвь — сигнал по шагам теряет избыточную пространственную детализацию, превращаясь в более концентрированное и информативное представление.
Следующим вступает шейный элемент, который становится ключевой поворотной точкой вычислительного маршрута. Независимо от того, является ли это финальный MS-Resblock или вложенный U-блок, шейный объект принимает уже условно сжатые признаки и продолжает их преобразовывать. На этом этапе данные достигают нижней точки вложенной структуры, после чего начинается восходящее движение.
if(!cNeck || !cNeck.FeedForward(prev)) return false;
Далее происходит конкатенация результатов работы шеи и верхней ветви энкодера. Этот шаг фактически восстанавливает U-образную природу конструкции. Модель объединяет глубокие признаки, полученные после последовательных сжатий, с их более поверхностными аналогами, сохраняя обобщённую информацию и важные детали. Конкатенация формирует расширенный тензор, служащий отправной точкой для декодера, и реализуется строго с учётом размеров окон и числа каналов, что гарантирует корректную сборку данных.
if(!Concat(prev.getOutput(), cNeck.getOutput(), cConcat.getOutput(), GetWindow() / 2, GetWindow() / 2, GetUnits())) return false;
Заключительный этап — передача объединённого тензора в декодер, роль которого выполняет родительский класс — спайковый сверточный блок. Он завершает цикл прямого прохода, формируя окончательное представление уровня U-структуры и обеспечивая связанность всей рекурсивной цепочки.
if(!CNeuronSpikeConvBlock::feedForward(cConcat.AsObject())) return false; //--- return true; }
В результате перед нами — элегантный и сбалансированный алгоритм, где каждая часть U-блока органично встроена в общий поток вычислений. Несмотря на глубинную рекурсию и многослойность, структура сохраняет архитектурную чистоту. Логика работы остаётся предельно прозрачной.
И теперь возникает естественный вопрос — каким образом эта сложная многослойная конструкция обучается? Как ошибка проходит через вложенные уровни, не теряясь и не разрушая устойчивость всей архитектуры? Ответ на эти вопросы заключён в механизме расчёта градиентов, который реализован в методе calcInputGradients.
Здесь всё аккуратно выстроено — словно послесловие к хорошо срежиссированному спектаклю, где каждая реплика идёт в нужный момент и в нужном порядке. Метод выполняет роль дирижёра обратного прохода. Он аккуратно разворачивает прямой проход, распределяет ошибки по вложенным уровням и возвращает сигнал туда, где он необходим для обновления весов.
bool CNeuronSDformerUBlock::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !cNeck) return false; //--- if(!CNeuronSpikeConvBlock::calcInputGradients(cConcat.AsObject())) return false;
Сначала делается самая простая, но жизненно важная проверка наличия объектов входного контекста и шейного узла — без этого продолжать бессмысленно.
Затем вызывается одноименный метод родительского класса, который распределит градиенты ошибки через модуль нашего декодера до уровня конкатенированного тензора результатов работы шеи и энкодера.
Далее идёт аккуратная расшивка конкатената — DeConcat делит общий градиент на две составляющие: ту, что пойдёт назад в шею, и ту, что вернётся в энкодер.
if(!DeConcat(cConcat.getPrevOutput(), cNeck.getGradient(), cConcat.getGradient(), GetWindow() / 2, GetWindow() / 2, GetUnits())) return false; Deactivation(cNeck)
После этого вызывается деактивация шейного блока — обработка производной функции активации, важнейший этап для корректного распространения ошибки через спайковую динамику. Это тот самый момент, когда модель вспоминает, на какие именно входы она реагировала, и корректирует веса с учётом чувствительности активаций.
Движение назад по энкодеру начинается с SPM-блока. Для него сначала рассчитываются скрытые градиенты относительно шеи, затем применяется обратная деактивация и суммирование с градиентом, полученным от декодера.
CNeuronBaseOCL* curr = cEncoder[-1]; if(!curr || !curr.CalcHiddenGradients(cNeck)) return false; if(!DeActivation(curr.getOutput(), cConcat.getPrevOutput(), cConcat.getPrevOutput(), curr.Activation()) || !SumAndNormilize(curr.getGradient(), cConcat.getPrevOutput(), curr.getGradient(), GetWindow() / 2, false, 0, 0, 0, 1)) return false;
После этого сигнал последовательно распространяется по остальным блокам энкодера в обратном порядке. Каждый блок получает градиент от следующего и вычисляет свои внутренние скрытые градиенты, готовя почву для обновления весов.
for(int i = cEncoder.Total() - 2; i >= 0; i--) { curr = cEncoder[i]; if(!curr || !curr.CalcHiddenGradients(cEncoder[i + 1])) return false; }
Финальный аккорд — передача накопленного градиента на уровень объекта исходных данных.
if(!NeuronOCL.CalcHiddenGradients(curr)) return false; //--- return true; }
Именно этот вызов завершает обратный путь внутри U-блока и позволяет вышестоящим структурам продолжить свёртку ошибок дальше по цепочке обучения. В результате метод получается строгим по порядку операций, устойчивым к ошибкам в структуре. И в то же время гибким — он корректно обрабатывает как случай конечного MS-Resblock, так и рекурсивно вложенный U-блок в шее. Такой дизайн минимизирует вероятность рассогласования градиентов между уровнями и сохраняет читабельность даже при глубокой вложенности — качество, которое особенно ценно в реализации сложных спайковых архитектур.
Таким образом CNeuronSDformerUBlock выступает своего рода узловой точкой всей конструкции. Объект объединяет компоненты в единое целое, поднимая архитектуру на новый уровень абстракции и превращая сложный набор локальных операций в скоординированный механизм построения глубокой U-образной структуры. Именно через него проходит основная логика сквозного движения данных. Полный код класса и всех его методов представлен во вложении.
Объект верхнего уровня
На данном этапе мы фактически подошли к логическому завершению реализации. Остаётся последний шаг — построение объекта верхнего уровня, который станет своеобразным дирижёром всей модели. Именно через него организуется окончательный порядок прохождения данных: от анализируемых событийных рядов, через последовательность вложенных U-блоков, до формирования конечного результата.
Этот объект не просто объединяет ранее созданные компоненты. Он обеспечивает согласованность их взаимодействия. Гарантирует правильную последовательность прямого и обратного проходов. Задаёт единую точку управления параметрами обучения. Благодаря этому все слои модели работают как единый организм: синхронно обмениваются информацией, комбинируют признаки разных масштабов и сохраняют устойчивость вычислений.
В нашей реализации объект CNeuronSDformerFlow выступает венцом всей архитектуры SDformerFlow — верхним уровнем, который объединяет накопленные решения и задаёт единую логику работы модели. Если CNeuronSDformerUBlock можно представить, как строительный блок или матрёшку, то CNeuronSDformerFlow — это каркас, удерживающий и синхронизирующий всю конструкцию.
Наследование от CNeuronSDformerUBlock даёт объекту все преимущества вложенной U-образной структуры. На этом фоне CNeuronSDformerFlow добавляет ещё один уровень управления и координации: контейнер cFlow аккумулирует все входящие потоки данных, формируя единый канал для их обработки и передачи вниз по иерархии. Это обеспечивает согласованность вычислений на всех уровнях вложенности и упрощает управление обучением и обновлением весов.
class CNeuronSDformerFlow : public CNeuronSDformerUBlock { protected: CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSDformerFlow(void) {}; ~CNeuronSDformerFlow(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &windows[], uint &heads[], uint &layers[], uint dimension_k, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSDformerFlow; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Функция инициализации превращает абстрактную архитектурную схему модели в полностью рабочий объект, готовый к обработке событийных финансовых рядов. На этом этапе задаются все ключевые параметры: количество выходов, размерности окон, число голов внимания, глубина вложенности, а также параметры оптимизации и размер батча.
bool CNeuronSDformerFlow::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &windows[], uint &heads[], uint &layers[], uint dimension_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(layers.Size() < 3) return false; if(heads.Size() != (layers.Size() - 2)) return false; if(windows.Size() < (layers[0] + layers.Size() - 1)) return false;
Метод тщательно проверяет корректность входных массивов. Число слоёв должно быть не меньше трёх, массив голов внимания — соответствовать структуре уровней, а размеры окон — обеспечивать согласованность всех блоков.
Далее определяется количество блоков для построения потока предварительной обработки данных (cFlow), и формируются новые массивы new_layers и new_windows для корректной передачи в родительский объект U-блока.
uint block = layers.Size() - 2; uint new_layers[], new_windows[]; if(ArrayResize(new_layers, block) < 0 || ArrayResize(new_windows, block + 1) < 0) return false; if(ArrayCopy(new_layers, layers, 0, 2, block) < int(block) || ArrayCopy(new_windows, windows, 0, layers[0], block + 1) < int(block + 1)) return false; //--- if(!CNeuronSDformerUBlock::Init(numOutputs, myIndex, open_cl, units, new_windows, heads, new_layers, dimension_k, optimization_type, batch)) return false;
Этот вызов разворачивает основную U-структуру, включая энкодер, шею и декодер, обеспечивая согласованность вложенных уровней.
После этого происходит инициализация контейнера cFlow и передача указателя на контекст OpenCL.
cFlow.Clear(); cFlow.SetOpenCL(OpenCL);
Внутри cFlow создаются два типа блоков: спайковые сверточные блоки CNeuronSpikeConvBlock и многомасштабные блоки с остаточными связями CNeuronMSRes. Сначала формируется последовательность свёрточных блоков для первого модуля, где каждый блок инициализируется с учётом соответствующих окон и количества каналов, после чего добавляется в cFlow.
CNeuronSpikeConvBlock* conv = NULL; uint index = 0; for(uint i = 0; i < layers[0]; i++) { conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, windows[i], windows[i], windows[i + 1], units, 1, optimization, iBatch) || !cFlow.Add(conv)) { DeleteObj(conv) return false; } index++; }
Затем создаются MS-Res блоки второго модуля, обеспечивая дополнительное углубление и обработку признаков на более высоком уровне абстракции.
CNeuronMSRes* msres = NULL; for(uint i = 0; i < layers[1]; i++) { msres = new CNeuronMSRes(); if(!msres || !msres.Init(0, index, OpenCL, units, windows[layers[0]], 1, optimization, iBatch) || !cFlow.Add(msres)) { DeleteObj(msres) return false; } index++; } //--- return true; }
Каждый блок создаётся динамически, проверяется на корректную инициализацию и добавляется в поток обработки. В случае ошибки объект уничтожается, что гарантирует стабильность и отсутствие утечек памяти.
По завершении всех операций метод возвращает true, сигнализируя о полном построении объекта и готовности к сквозной обработке данных.
Таким образом, метод инициализации формирует верхнеуровневый объект CNeuronSDformerFlow как связующее звено между рекурсивной U-структурой и последующими вычислительными потоками, обеспечивая интеграцию всех компонентов модели и подготовку к практическому использованию в анализе событийных финансовых рядов.
Алгоритм прямого прохода реализован линейно, что обеспечивает предсказуемость вычислений и ясность структуры модели. Это особенно важно при работе с глубокими вложенными U-блоками.
bool CNeuronSDformerFlow::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr || !curr.FeedForward(prev)) return false; prev = curr; } //--- return CNeuronSDformerUBlock::feedForward(prev); }
Все операции выполняются строго по порядку. Сначала последовательно обрабатываются свёрточные и MS-Res блоки в cFlow, а затем вызывается одноименный метод родительского U-блока, который аккуратно интегрирует выходы энкодера, шеи и декодера.
Организация обратного прохода при этом становится прямолинейной и прозрачной — градиенты следуют по той же цепочке, что и данные в прямом проходе. Подробности алгоритмов обратного распространения ошибки и обновления весов мы предлагаем изучить самостоятельно, чтобы увидеть, как линейная структура упрощает управление сложной рекурсивной архитектурой.
Полный код класса и всех его методов приведён во вложении к статье.
По сути, это финальный узел, который завершает архитектурную линию SDformerFlow и превращает теоретические принципы фреймворка в полностью работоспособную и готовую к использованию систему.
Тестирование
В этом проекте мы создаём полноценную торговую систему, способную самостоятельно принимать решения и совершать сделки на финансовом рынке. Она действует слаженно, точно и уверенно, словно трейдер, который знает каждый поворот графика.
Архитектура модели в основном перенесена из предыдущих работ без серьёзных изменений, что позволило сохранить проверенные временем алгоритмы обработки сигналов и обучения. Основные новшества коснулись Энкодера окружающей среды — в него был внедрён объект верхнего уровня CNeuronSDformerFlow. Такой подход облегчает интеграцию фреймворка в модель, сохраняет модульность и упрощает поддержку. Полный код описания архитектуры доступен во вложении.
Первая тренировка модели на исторических данных напоминает репетицию новичка на бирже. Представьте EURUSD с Января 2024 по Июнь 2025 года как огромную тренировочную площадку. Модель словно молодой трейдер, внимательно всматривается в каждую свечу, изучает объёмы, ищет закономерности между индикаторами и реакциями рынка. SDformerFlow — это одновременно микроскоп, позволяющий видеть мельчайшие движения каждой свечи, и подзорная труба, раскрывающая глобальные рыночные тенденции. Он формирует информативное состояние для Актёра и Критика, комбинирует признаки разного масштаба и обучается вместе с моделью. С каждой новой свечой модель учится прогнозировать движение рынка, оценивать риски и постепенно превращается из робкой ученицы в уверенного практиканта, способного принимать самостоятельные решения.
Настоящее испытание наступает на этапе онлайн-обучения в тестере стратегий MetaTrader 5. Здесь нет роскоши спокойных исторических данных. Каждая свеча — как удар реального рынка. Модель реагирует быстро и точно, анализирует шумовые колебания, приспосабливается к резким всплескам и корректирует действия при низкой ликвидности. SDformerFlow комбинирует признаки разного масштаба, синхронизирует работу всех блоков и обучается вместе с моделью.
Финальный экзамен — тест на данных с Июля по Сентябрь2025 года. Здесь нет подсказок, нет истории, на которую можно опереться. Только рынок и собственные решения модели. Каждое движение проверяет её подготовку: насколько она усвоила принципы анализа, научилась комбинировать признаки разного масштаба и предугадывать рыночные реакции. Результаты тестирования, представленные ниже, демонстрируют, как SDformerFlow превращает сложную архитектуру в слаженную, адаптивную и эффективную торговую систему, способную действовать почти как опытный трейдер.
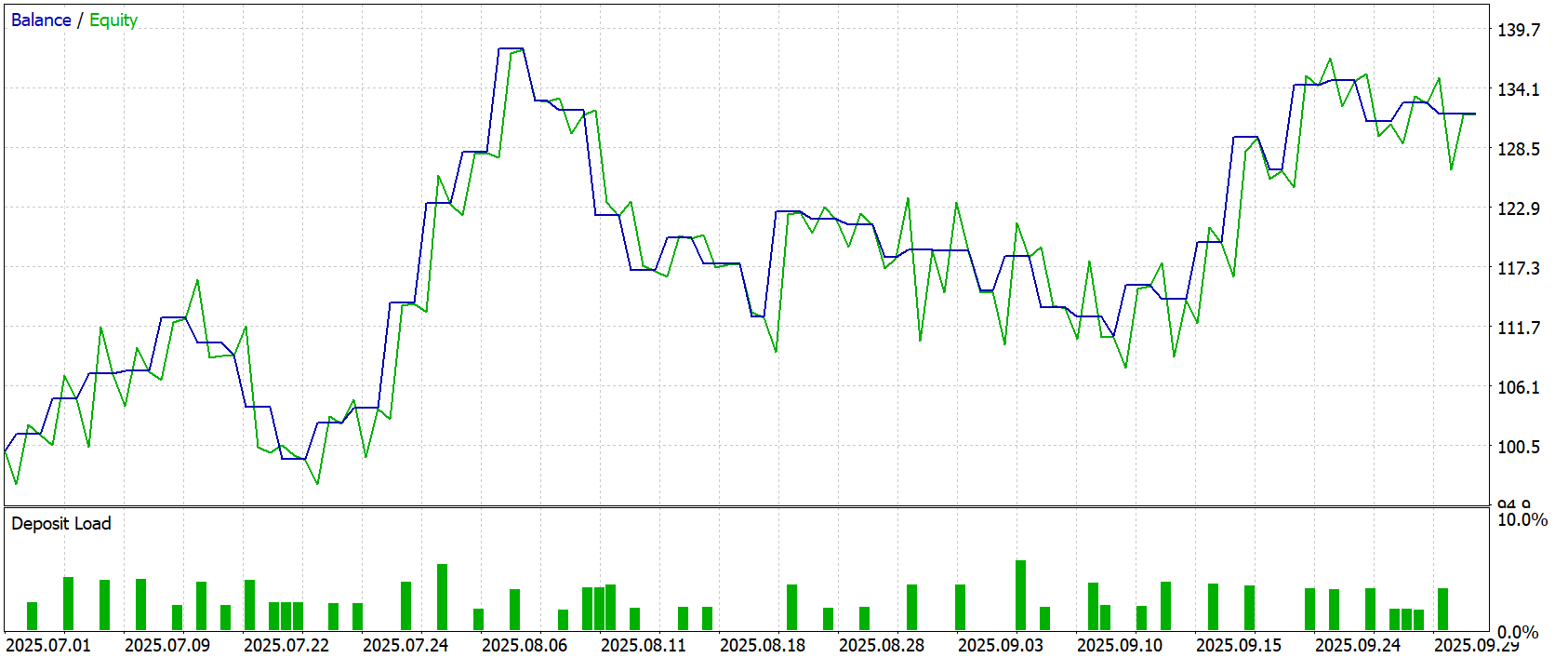
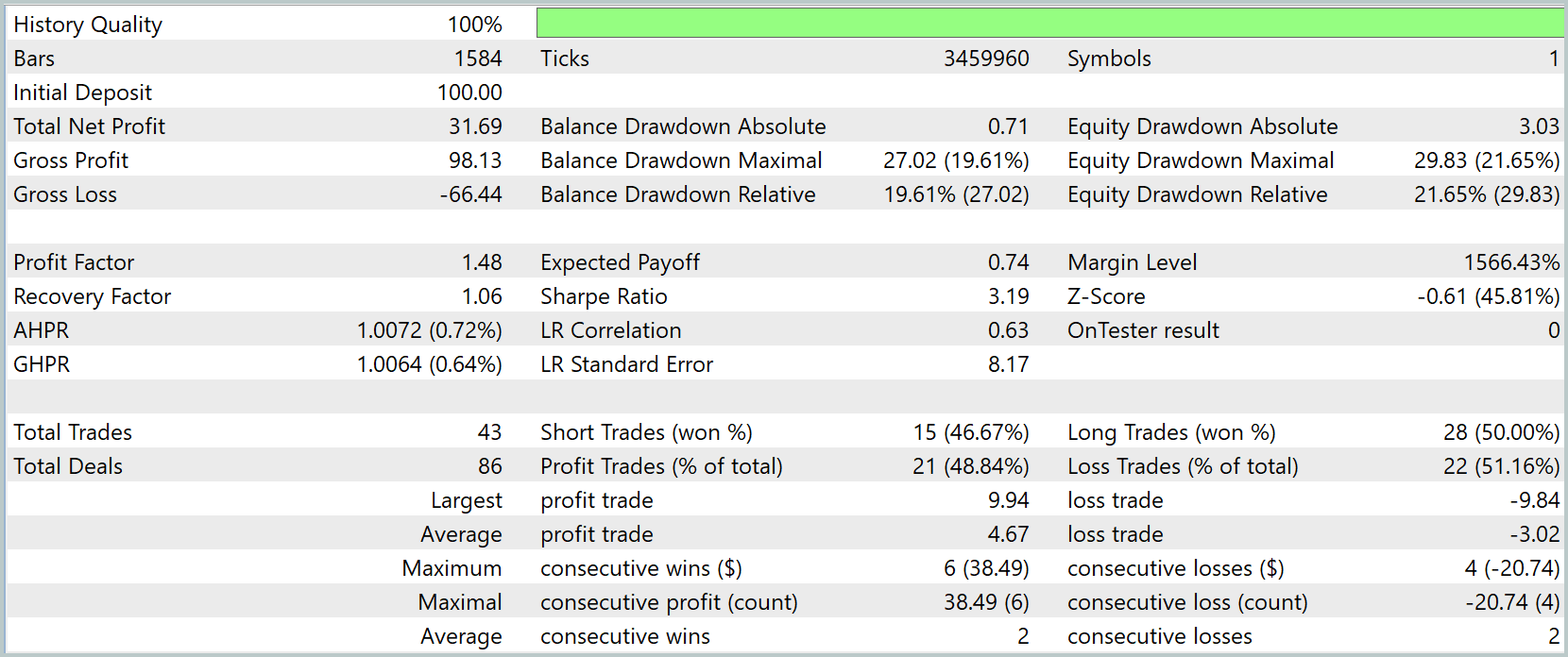
Во время тестирования модель показала рост капитала со 100.0USD до 133.36USD — устойчивый прирост на 33.36%. Баланс и эквити демонстрируют плавный рост с контролируемыми просадками, без резких падений. Максимальная просадка составила 29.83USD (25.36%), но модель быстро восстанавливалась, демонстрируя способность адаптироваться к рыночным колебаниям.
Стратегия показала умеренную прибыльность при разумном уровне риска: фактор прибыли 1.48, средняя прибыльная сделка 2.12USD, средняя убыточная — -1.70USD. Из 86 сделок 47 были прибыльными (54.65%), длинные позиции выиграли 53.52%, короткие — 46.67%. Максимальная серия прибыльных сделок — 9, а убыточных — 6. Это подтверждает стабильность работы модели.
Заключение
Реализованная архитектура SDformerFlow стала полноценным инструментом для анализа событийных финансовых рядов. Модель одновременно фиксирует мельчайшие движения рынка и улавливает глобальные тенденции. Каждая свеча, каждый сигнал проходят через многоуровневую U-структуру, где локальные и глобальные признаки комбинируются, обогащая внутреннее состояние модели и обеспечивая точность прогнозов.
Реализация рекурсивных U-блоков и объекта верхнего уровня CNeuronSDformerFlow позволила нам создать единый организм. Прямой и обратный проходы согласованы, градиенты и веса обновляются синхронно, а обучение всей модели происходит гармонично. Такая структура обеспечивает устойчивость вычислений, сквозное движение информации и способность адаптироваться к любым рыночным колебаниям, превращая теоретические принципы фреймворка в полностью работоспособную торговую систему.
Результаты тестирования на исторических данных подтверждают эффективность подхода. Устойчивый рост капитала, контролируемые просадки и высокая адаптивность модели демонстрируют практическую ценность SDformerFlow. Модель показывает, что сочетание многоуровневой обработки, конкатенации признаков разных масштабов и синхронизации всех блоков делает её надежной основой для построения современных торговых систем.
Ссылки
- SDformerFlow: Spatiotemporal swin spikeformer for event-based optical flow estimation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования