
Нейросети в трейдинге: Фреймворк кросс-доменного прогнозирования временных рядов (TimeFound)

Введение
Прогнозирование временных рядов уже давно стало неотъемлемым инструментом финансового аналитика. Если вы хоть раз пытались предугадать, куда пойдут котировки акций, или как изменится волатильность финансового индекса — вы хорошо знаете, что это сродни гаданию на кофейной гуще. Впрочем, без этого гадания ни один серьёзный фонд просто не выживет.
Раньше в ходу были классические статистические модели: ARIMA, экспоненциальное сглаживание. Да что там, даже линейная регрессия частенько приносила свои плоды. Аргументы, почему модель должна быть проще, звучали убедительно, пока на арену не вышли глубокие нейросети. Сегодня они не просто приносят плоды, а собирают урожай, поражая точностью и скоростью обработки терабайтов исторических данных.
Однако, как и любое мощное оружие, глубокие модели имеют свои побочные эффекты. Для обучения им нужен целый рудник размеченных данных по конкретной задаче. Без этого большой брат нейросеть работать не будет. А что делать, если в распоряжении только узкий фрагмент истории, или рынок только начал торговаться? Как прогнозировать цены на недавно выпущенный токен, данные по которому ещё счётчик в брокерском терминале не успел набрать? Тут и приходит на помощь концепция Zero‑Shot Forecasting — гарантия того, что модель проявит себя там, где классические подходы просто бессильны.
Исследователи временных рядов провели аналогии с большими языковыми моделями (Large Language Models). Знаменитые LLM успешно работают с текстом: переводят, пишут стихи, отвечают на вопросы. А почему бы не перенести их идеи на прогнозирование ценовых трендов? Так родился бум, так называемых, Foundation Models для временных рядов. Представьте: одна универсальная модель — и ей без разницы, прогнозирует ли она цену акций, объём потребления электроэнергии или уровень безработицы. Главное — грамотно обучить её на разнообразном датасете.
Вдохновлённые подобной фундаментальностью, авторы работы "TimeFound: A Foundation Model for Time Series Forecasting" представили в качестве основы для прогнозирования временных рядов новый фреймворк на базе архитектуры Transformer — TimeFound. Они взяли лучшие идеи из мира NLP и адаптировали их для прогнозирования временных рядов.
Фреймворк TimeFound построен по классической схеме Энкодер – Декодер. Эндкодер изучает историческую серию данных и выжимает из неё контекст. Декодер, в свою очередь, додумывает будущее, сохраняя причинно-следственные связи.
В основе модели лежит новый подход к патчингу временных рядов. Забываем про фиксированный размер окна. Авторы фреймворка предлагают разбивать последовательность сразу на несколько патчей разных размеров. Представьте, вы изучаете поведение акций компании: месячные колебания выглядят однообразно, а внутридневные — пестрят резкими скачками. Multi-resolution patching позволяет уловить оба масштаба: и долгосрочный тренд, и шум волатильности.
Для предварительного обучения, авторы фреймворка собрали огромный мультидоменный датасет. Всё это разнообразие необходимо, чтобы модель научилась выхватывать универсальные закономерности. Чем больше данных — тем богаче словарь паттернов, выученных моделью.
Цель обучения проста — задача авторегрессионного прогнозирования. На вход подаётся набор исторических данных, а модель учится прогнозировать последующие шаг за шагом. Однако, в данном случае, шаг прогноза может отличаться от шага исторических данных. Дело в том, что модель возвращает результаты в виде патчей. А один патч может включать несколько шагов анализируемой системы.
Алгоритм TimeFound
TimeFound — это универсальная модель, разработанная в качестве основы для построения прогнозных систем в различных доменах, включая, но не ограничиваясь, финансовыми рынками. Архитектура модели построена в формате Энкодер–Декодер с модульным принципом обработки данных. В ней центральную роль играют нормализация, многоуровневый патчинг, механизм внимания с относительным позиционированием и совместное обучение с использованием точечных и квантильных ошибок прогнозов.
Алгоритм фреймворка начинается с тщательной подготовки исходного временного ряда, ведь без надёжного основания любой прогноз рискует оказаться шатким. Сначала приводим данные к сопоставимому виду — нормализуем каждый ряд с помощью классической нормализации, вычитая из каждой точки среднее значение всей последовательности и деля на её стандартное отклонение. Благодаря этому приёму, модель не будет теряться, когда одно движение на рынке выглядит как маленькая синусоида, по сравнению с колоссальным подъёмом потребления электроэнергии, и напротив — почувствует даже тонкие флуктуации, когда они действительно важны.
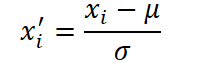
где μ и σ — среднее и стандартное отклонение ряда X. Это выравнивает шкалу данных без потери временной структуры.
Как только масштаб урегулирован, приходит пора разделить ряд на фрагменты или патчи. В классических решениях все патчи одинаковы, но мы знаем, что в одном и том же временном ряду могут скрываться и быстрые всплески, и медленные тренды. По этой причине авторы фреймворка TimeFound предлагают мульти-масштабный патчинг. На первом уровне формируются патчи минимального масштаба. Их максимальное количество. С ростом уровня, увеличивается и размер патча с кратным сокращением их количества. Авторы фреймворка в своей работе использовали патчи, размер которых является степенью 2.
Каждый такой патч хранит в себе кусочек временного сюжета, будь то кратковременный всплеск волатильности или долгий спад.
Затем к сформированным патчам добавляется бинарная маскировка, указывающая, где лежат реальные данные, а где — лишь заполнение до ровного размера. И каждый такой фрагмент временного ряда проходит через свой собственный двухслойный перцептрон с остаточными связями. Эти MLP-проектора переводят патчи разной длины в единое d-мерное латентное пространство, где каждый вектор отражает суть локального поведения анализируемого ряда.
Однако, ещё не всё готово. Как уже было сказано ранее, в процессе мультимасштабного патчинга на каждом уровне формируется различное количество объектов — мелких блоков в разы больше, чем больших. Чтобы объединить их воедино, авторы фреймворка предлагают дублировать (реплицировать) представления крупных патчей необходимое количество раз, чтобы выровнять их количество с числом самых мелких патчей. В результате, на каждом временном шаге оказывается стерео многоканальное представление, в котором слиты векторы всех масштабов. После этого, их признаки объединяются в одну латентную матрицу. Именно она поступает на вход блоку внимания, обеспечивая межмасштабное взаимодействие.
Основу модели составляет Энкодер–Декодер с модифицированным вниманием. Энкодер внимательно изучает полученную последовательность, применяя двунаправленное (bi-directional) внимание. Это означает, что каждая позиция может спросить у всех остальных, как развивались события до и после неё, и на основе взвешенных ответов формирует более глубокое представление. При этом механизм внимания опирается на относительное позиционирование патчей: модель чувствует, что недавний фрагмент (например, три патча назад) важнее далёкого (скажем, двадцати патчей назад), и распределяет веса соответственно.
Когда Энкодер завершил свою работу, его результаты передаются Декодеру, который уже не вправе смотреть вперёд по факту, а лишь опирается на исторические данные. Механизм внимания не даёт модели заглянуть в будущее больше, чем это позволяет агрегация ранее сделанных прогнозов, и потому, каждый новый прогноз точен и честен. Важным звеном здесь является Cross-Attention. Декодер, формируя представление следующего патча, снова обращается к богатым контекстным векторам Энкодера, вытягивая из них информацию о недавно прошедших тенденциях.
На выходе Декодера получаем прогнозный вектор последующего патча — сжатое описание предшествующих событий и ключевых сигналов. Этот вектор передаётся в модуль преобразования, реализованный в виде двухслойного MLP с остаточным соединением. В нём латентное представление разворачивается обратно в привычные значения временного ряда и сразу формируется блок будущих точек. Такой пакетный вывод прогнозов ускоряет работу модели и особенно эффективен при долгосрочных горизонтах.
При обучении авторы фреймворка не ограничиваются лишь поиском среднего сходимости к правильным значениям. Вместе со стандартной MSE-ошибкой, которая карает за квадратичную разницу между прогнозными и истинными значениями, они используют квантильную функцию потерь, заставляющую модель давать оценку неопределённости. Для каждого временного шага она учится, помимо средних значений, выдавать и, скажем, 10-й, 50-й и 90-й процентили. Совокупная функция потерь, аккумулирующая MSE и Quantile Loss, формирует баланс между точностью прогноза и шириной доверительного интервала.
Таким образом, весь алгоритм TimeFound представляет собой единый, хорошо продуманный конвейер. Он сочетает мощь трансформеров с гибкостью мультимасштабного патчинга и чувствительностью к неопределённости, что делает модель способной работать с любыми временными рядами.
Для предварительного обучения TimeFound, авторами фреймворка был сформирован обширный и разнородный датасет, охватывающий реальные и синтетические временные ряды в различных доменах. Собраны публично доступные ряды с различной частотой (от 5 минут до годовых). Использованы данные из финансовых рынков (цены акций, валютный фьючерс), потребления энергии, температур и объёмов продаж. После чего, увеличено их разнообразие через синтетические генерации. Это позволяет TimeFound формировать универсальные представления временных рядов, обеспечивая высокую обобщающую способность без дообучения на новых задачах.
Авторская визуализация фреймворка TimeFound представлена ниже.

Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка TimeFound, мы переходим к практической части нашей статьи, в которой реализуем средствами MQL5 собственное видение подходов, предложенных авторами фреймворка. Но перед тем, как погрузиться в детали кода, важно чётко представить себе последовательность задач и их взаимосвязь. Наш путь начинается с подготовки исходных данных — и именно здесь кроется залог качества всего дальнейшего прогноза.
Для нормализации данных анализируемого временного ряда мы не будем изобретать велосипед — воспользуемся готовым блоком пакетной нормализации. Этот модуль автоматически сканирует накопленный буфер цен, вычисляет среднее и дисперсию на каждом шаге и в реальном времени выравнивает распределение данных, избавляя модель от резких скачков при смене рыночной конъюнктуры. Благодаря такой скользящей нормализации, мы сохраняем динамику важных паттернов, но убираем разброс, мешающий стабильному обучению и прогнозу.
Когда данные выровнены на единую шкалу, приходит пора решения действительно ключевой задачи — мульти-масштабного патчинга. В классическом последовательно-репликационном подходе мы бы сначала разбили ряд на фрагменты разного размера, затем, досчитали до одинакового числа мелких блоков путём банальной копипасты больших векторов, и, лишь после этого, медленно склеивали всё обратно. Такой метод понятен, но неприемлем из-за задержек. При каждом заходе на новую свечу, теряем драгоценное время на репликацию, а итоговые эмбеддинги крупных масштабов дублируются по нескольку раз, теряя уникальность.
В своей реализации мы поступим иначе. Воспользуемся концепцией мультиоконной свёртки. Представьте, что вместо трёх отдельных процедур мы запускаем три ядра свёрточного слоя параллельно, каждое со своим размером окна. Благодаря нулевому паддингу и перекрытию, свёрточные фильтры с одинаковым шагом аккуратно прокатываются по всей длине анализируемого временного ряда, формируя одновременно сразу три массива признаков одинаковой длины.
Этот подход даёт нам сразу несколько выигрышных эффектов. Во-первых, все вычисления идут одновременно — не нужно ждать, пока мелкие патчи обработаются и потом дозаполнятся данными крупных. Во-вторых, за счёт скользящего окна с равным шагом, каждое новое значение ряда участвует во всех трёх преобразованиях, и у нас нет проблем с выравниванием. Выходные тензоры сразу выстроены по одному индексу времени. В-третьих, за счёт перекрытия, окно больших фильтров захватывает соседние сегменты, что позволяет лучше фиксировать медленные тренды и сглаженные колебания, а не только строгие блоки.
При этом, нам не нужно реплицировать или интерполировать чего-либо вручную — алгоритм сохраняет равное количество элементов и однородное представление для каждого временного шага.
В результате, получается мгновенный и компактный срез рыночной картины с требуемым уровнем детализации, готовый к проекции в латентное пространство MLP-проектора.
Именно такой параллельный мультимасштабный патчинг становится сердцем модуля предварительной обработки: он сохраняет уникальность эмбеддингов каждого масштаба, исключает избыточную репликацию и позволит вашему роботу принимать решения быстрее и точнее, реагируя сразу и на микровсплески, и на долгосрочные тренды.
Дальше мы переходим к трансформации полученных эмбеддингов в высокоинформативные признаки. После мультиоконной свёртки на каждом временном шаге уже лежит заданное количество каналов в виде эмбеддингов. Но для глубокой модели этого мало. Нужно добавить слой нелинейности и обучаемых связей, чтобы получить действительно выразительное представление. В оригинале авторы TimeFound предлагают двухслойный MLP с паттерном остаточных связей. Однако в нашей реализации, мы используем готовый блок многоголового Feed-Forward из фреймворка StockFormer.
Представьте, что у вас есть три потока признаков разного масштаба, и каждый из них нужно довести до единого стандарта качества. Наш блок разбивает эти потоки на независимые головы, каждая обрабатывается параллельно с собственными весами и смещениями. А затем, все результаты снова складываются в единый вектор. Благодаря остаточным связям, информация о первичных эмбеддингах сохраняется и мягко смешивается с выходом слоя, что улучшает сходимость и делает модель более устойчивой к шуму в данных.
Внутри этого блока Feed-Forward каждая голова представляет собой двухслойный MLP с нелинейностью между слоями. Результаты работы MLP суммируются с исходными данными и нормализуются. Таким образом, итоговый вектор на каждом шаге времени представляет собой синтез локальных паттернов и глобальных признаков, готовый к подаче в следующий модуль.
Такой подход позволяет нам сохранить концептуальную близость к оригинальной архитектуре TimeFound, но использовать проверенный и оптимизированный компонент из StockFormer, что экономит время разработки и гарантирует высокую производительность в реальном времени.
В завершение подготовки мульти-масштабных признаков, мы переходим к их агрегации, и здесь простой суммирующий приём уступает место более гибкому механизму — последовательности свёртки и макс-пулинга. Представьте, что у вас есть три канала эмбеддингов, и каждый из них несёт свой вклад в понимание происходящего. Если сложить эти каналы поэлементно, все они получат одинаковый вес, независимо от того, насколько значимы на этом участке краткосрочные всплески или долгосрочные тренды. Вместо этого, мы запускаем свёртку, в которой обучаемые фильтры анализируют значения их разных масштабов и выделяют наиболее информативные сочетания.
Во время прохода свёрточного слоя по трёхканальному тензору, каждый фильтр видит сразу все масштабы и ищет в них характерные паттерны. На выходе получаем набор новых признаков, каждый из которых отражает сочетание локальных и глобальных сигналов. И вот здесь включается макс-пулинг: скользя по полученным картам признаков, он оставляет лишь самые сильные отклики, игнорируя шум и несущественные флуктуации. Таким образом, если в одном и том же временном интервале микроуровень зафиксировал резкий скачок объёма, а макроуровень — устойчивый рост, пулинг гарантирует, что оба сигнала будут достойно представлены в итоговом векторе.
В результате этой комбинации свёртки и макс-пулинга, мы избавляемся от необходимости вручную задавать веса для каждого масштаба. Модель сама учится акцентировать внимание на том наборе признаков, который наиболее релевантен текущему прогнозу. Такой адаптивный механизм не только повышает точность вывода, но и делает алгоритм более устойчивым к рыночным прыжкам и шумам, поскольку слабые или редкие сигналы сглаживаются, а важные всплески — наоборот, усиливаются и доходят до этапов Энкодера и Декодера без потерь.
Изложенный выше подход мы реализуем в рамках объекта CNeuronTimeFoundPatching, структура которого представлена ниже.
class CNeuronTimeFoundPatching : public CNeuronConvOCL { protected: CNeuronTransposeOCL cToVarSeq; CNeuronMultiWindowsConvWPadOCL cProjecting; CNeuronTransposeVRCOCL cToVarProjSeq; CNeuronMultiWindowsConvWPadOCL cPatchingProj; CNeuronMHFeedForward cPatchsFeedForward; CNeuronConvOCL cPatchingAgr; CNeuronProofOCL cProof; CNeuronTransposeOCL cToPatchVarEmb; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTimeFoundPatching(void) {}; ~CNeuronTimeFoundPatching(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint patchs, uint variables, uint embedding_size, uint patch_filters, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronTimeFoundPatching; } //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Все внутренние модули CNeuronTimeFoundPatching живут своей независимой жизнью с самого старта программы. Они объявлены статически и инициализируются вместе с загрузкой библиотеки. Поэтому нам вовсе не нужно создавать их в конструкторе, или заботиться об очистке в деструкторе — эти методы остаются пустыми, а всю магию управления архитектурой объекта берет на себя один универсальный метод Init.
В параметрах метода инициализации мы получаем ряд констант, которые и определяют архитектуру внутренних объектов.
bool CNeuronTimeFoundPatching::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint patchs, uint variables, uint embedding_size, uint patch_filters, ENUM_OPTIMIZATION optimization_type, uint batch) { uint inside_emb = MathMax((embedding_size + 2) / 6, 8); if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, 3 * inside_emb, 3 * inside_emb, embedding_size, patchs * variables, 1, optimization_type, batch)) return false; SetActivationFunction(SoftPlus);
Надо сказать, что при построении данного объекта мы позаимствовали лучшие идеи из фреймворка Mantis. Вместо жёстко прописанных размеров патчей, наш класс принимает на вход лишь число сегментов для самого мелкого уровня и желаемый размер выходного токена. Это даёт гибкость — можно быстро менять гранулярность патчинга без правки кода.
Но мы пошли дальше. Mantis использовал единственную свёртку для генерации каналов признаков, а мы внедрили мультиоконную свёртку, которая создаёт сразу несколько уровней просмотра исходного сигнала. Когда же наступает момент инициализации, наша задача — расчёт внутреннего размера вектора токена для каждого из уровней детализации. Пользователь может задать любую длину токена на выходе объекта. Но она не всегда будет делиться на количество уровней без остатка. Здесь на сцену выходит родительский сверточный класс: он аккуратно доводит число каналов до заданного размера, применяя свои оптимизированные фильтры и обеспечивая согласованное, равномерное представление признаков.
Как и ранее, на вход объекта мы ожидаем получить двухмерный тензор описания мультимодального временного ряда, где каждая строка — это подробное описание одного временного шага. Но чтобы наш конвейер патчинга мог воспринимать отдельные признаки, как отдельные унитарные последовательности, мы сначала транспонируем матрицу исходных данных.
Этот простой, но важный приём гарантирует, что все последующие операции будут работать по строгому принципу один ряд — одна история, а не смешивать сигналы из разных источников. Именно таким образом мы сохраняем цельность и читабельность каждого временного ряда.
int index = 0; if(!cToVarSeq.Init(0, index, OpenCL, count, variables, optimization, iBatch)) return false;
Затем приходит черёд мультиоконной свёртки. Мы одновременно запускаем три фильтра с размерами окон 3, 7 и 8 баров и шагом 1. Благодаря нулевому паддингу, длина выходных рядов остаётся прежней, но каждое значение теперь обогащено знанием своих ближайших соседей и их контекстом.
index++;
{
int windows[] = {3, 5, 7};
if(!cProjecting.Init(0, index, OpenCL, windows, 1, inside_emb, count, variables,
optimization, iBatch))
return false;
cProjecting.SetActivationFunction(SoftPlus);
}
На этом этапе мы успешно сформировали базовые признаки для дальнейшего анализа. Теперь перед нами стоит задача структурировать эти данные для подачи в последующие блоки модели — то есть, осуществить патчинг. Но прежде, чем нарезать временной ряд на сегменты, необходимо выполнить важную техническую операцию: переставить последние оси в полученном четырехмерном тензоре.
Сформированный на предыдущем шаге тензор имеет форму [Переменная × Длина ряда × Количество каналов× Количество признаков], где каждый временной шаг описан вектором из трёх каналов, полученных с разных масштабов свёртки. Однако, для более удобной работы с унитарными последовательностями, которые будут сегментироваться независимо, нам нужно привести данные к виду `[Переменная × Количество каналов × Количество признаков × Длина ряда]`. Это позволяет обрабатывать каждую характеристику, как отдельную временную последовательность и, в дальнейшем, резать её на куски фиксированной длины — патчи.
index++; if(!cToVarProjSeq.Init(0, index, OpenCL, variables, count, 3 * inside_emb, optimization, iBatch)) return false;
Такое представление особенно удобно в финансовом контексте: каждый канал, обогащённый мультиоконной свёрткой, теперь выступает как самостоятельный рыночный индикатор, динамику которого можно анализировать в рамках патчинга.
Далее мы переходим к ключевому этапу — многомасштабному патчингу, который и составляет основу нашей архитектуры предварительной обработки временных рядов. Здесь мы реализуем концепцию, вдохновлённую не столько классическими подходами, сколько реальной практикой высокочастотного анализа рыночных данных, где важна и глубина охвата, и оперативность реакции.
Вместо того, чтобы нарезать последовательность на патчи жёстко и одномерно, мы используем слой мультиоконной свёртки, позволяющий работать сразу на нескольких масштабах. Это даёт модели возможность заглядывать на рынок с разных временных дистанций — словно аналитик, который смотрит одновременно и на 1-минутные свечи, и на часовики, и на дневной график.
index++;
{
uint step = (count + patchs) / (patchs + 1);
uint windows[] = {step, 3 * step / 2, 2 * step};
if(!cPatchingProj.Init(0, index, OpenCL, windows, step, patch_filters, patchs,
3 * inside_emb * variables, optimization, iBatch))
return false;
cPatchingProj.SetActivationFunction(SoftPlus);
}
Размеры окон свёртки, в этом случае, определяются автоматически — они зависят от длины анализируемой временной последовательности и от заданного пользователем количества патчей. На более высоких масштабах это значение масштабируется вверх с перекрытием, чтобы обеспечить связность и преемственность информации между патчами.
На следующем этапе предварительно извлечённые патчи поступают в модуль многоголового FeedForward. Это не просто формальность — здесь начинается настоящая работа с пониманием. Каждый патч, полученный с разных масштабов, теперь превращается в полноценный эмбединг — то есть, в компактное и насыщенное представление, которое кодирует ключевые характеристики соответствующего фрагмента временного ряда. Результатом работы модуля становится набор компактных, но выразительных векторов, каждый из которых можно считать квинтэссенцией соответствующего временного фрагмента.
index++; if(!cPatchsFeedForward.Init(0, index, OpenCL, 3 * patch_filters, 6 * patch_filters, patchs, 3 * inside_emb * variables, 3, optimization, iBatch)) return false; index++;
После того, как мы получили выразительные эмбединги каждого патча на всех масштабах, наступает этап агрегации данных. Ведь чтобы модель могла сформировать целостное представление о текущем рыночном контексте, ей необходимо объединить информацию с разных уровней детализации в единый вектор признаков.
Для решения этой задачи, мы используем комбинацию свёртки и макс-пулинга. Слой свёртки позволяет выявить локальные зависимости между эмбедингами различных масштабов. Он действует как аналитик, который ищет характерные сочетания коротких и длинных паттернов — скажем, краткосрочную волатильность на фоне устойчивого долгосрочного тренда. Такие комбинации часто оказываются ключевыми при принятии торговых решений, особенно на сложных участках рынка.
Далее, данные проходят через макс-пулинг, который выделяет наиболее сильные, выразительные признаки в каждой области полученного тензора. В результате мы получаем единый агрегированный вектор признаков. Это компактное, но содержательное представление всей входной истории, обработанной на нескольких масштабах.
index++; if(!cPatchingAgr.Init(0, index, OpenCL, 3 * patch_filters, 3 * patch_filters, patch_filters, patchs, 3 * inside_emb * variables, optimization, iBatch)) return false; cPatchingAgr.SetActivationFunction(SoftPlus); index++; if(!cProof.Init(0, index, OpenCL, patch_filters, patch_filters, 3 * patchs * inside_emb * variables, optimization, iBatch)) return false;
Но прежде, чем передать полученные токены дальше по архитектуре, нам необходимо выполнить ещё один важный шаг — транспонировать полученный тензор, возвращая ось времени на первое место.
index++; if(!cToPatchVarEmb.Init(0, index, OpenCL, variables * 3 * inside_emb, patchs, optimization, iBatch)) return false; //--- return true; }
Зачем это нужно? Всё дело в том, что на предыдущих этапах — в частности, при формировании эмбеддингов и агрегации патчей — данные были представлены в формате, где основное внимание уделялось патчам и признакам. Такой порядок осей удобен для локальной обработки, но не подходит для механизмов, чувствительных ко времени.
Возвращая ось времени в начало, мы фактически выстраиваем полученные токены в хронологическом порядке. Каждый токен теперь воспринимается как момент времени, насыщенный сведениями сразу с нескольких уровней масштаба. Это даёт модели возможность воспринимать данные в качестве полноформатной временной последовательности, а не как абстрактный набор признаков.
Именно в таком виде тензор передаётся на следующие этапы обработки — где уже вступают в игру временные зависимости, анализ контекста и генерация прогнозов. Такой порядок позволяет сохранить причинно-временную связь в данных, без чего любая попытка моделировать финансовый рынок теряет смысл.
Несмотря на кажущуюся сложность внутренней архитектуры объекта, реализация алгоритмов прямого и обратного проходов остаётся предельно прямолинейной. Логика вычислений организована поэтапно и последовательно, без вложенных циклов или запутанных ветвлений. Думаю, разобраться в устройстве этих методов не составит труда. По этой причине мы сознательно не будем подробно останавливаться на их рассмотрении в рамках данной статьи. А для всех желающих глубже погрузиться в техническую реализацию объекта CNeuronTimeFoundPatching полный исходный код, включая все его методы, будет доступен во вложении к статье.
Постепенно мы подошли к разумным пределам формата статьи. Объём материала уже достаточно велик. Однако, как вы понимаете, наша работа ещё далека от завершения. Мы лишь заложили фундамент и реализовали критически важный модуль предварительной обработки данных, который формирует основу всего последующего анализа.
Давайте сделаем небольшую паузу, переведём дух и уже в следующей статье продолжим путь, шаг за шагом реализуя остальные компоненты рассмотренного фреймворка.
Заключение
В данной статье мы познакомились с теоретическими аспектами TimeFound — фреймворка, способного преобразовать хаотичную структуру данных временных рядов в формализованный, прогнозируемый паттерн.
Мы начали реализацию собственного видения подходов, предложенных авторами фреймворка. Основное внимание мы уделили модулю предварительной обработки данных, ведь именно он определяет, насколько точно и выразительно модель будет воспринимать структуру входного сигнала.
Впереди — не менее интересная работа, в которую мы погрузимся в следующей статье.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера окружающей среды |
| 4 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 5 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 6 | Test.mq5 | Советник | Советник для тестирования модели |
| 7 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 8 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 9 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте, Дмитрий Гизлык, надеюсь, у вас всё очень хорошо.
В каком файле вы реализовали класс CNeuronTimeFoundPatching?
Я не понимаю, возможно, он уже есть в одной из папок архива zip, или это что-то, что ещё не было загружено как часть файлов этой статьи.
Этот подход очень интересен, надеюсь увидеть следующие части в ближайшее время (на испанском, моём родном языке). Обнимаю.
Не могли бы вы (если это возможно) подробнее указать, какие библиотеки дополняют код, так как при попытке скомпилировать любой файл не хватает многих зависимостей
(присутствуют только файлы «EXPERTS», но, возможно, отсутствуют другие файлы, например из «include»).
Здравствуйте, Дмитрий Гизлык, надеюсь, у вас все хорошо.
В каком файле вы реализовали класс CNeuronTimeFoundPatching?
Я не понимаю, возможно, он уже находится в одной из папок в zip-файле, или это что-то, что еще не было загружено как часть файлов в этой статье.
Очень интересный подход, надеюсь скоро увидеть следующие части (на испанском, моем родном языке). Обнимаю.
Добрый день, Мигель.
Класс CNeuronTimeFoundPatching представлен в библиотеке NeuroNet.mqh.
Не могли бы вы (если это возможно) подробнее указать, какие библиотеки дополняют код, так как при попытке скомпилировать любой файл не хватает многих зависимостей
(присутствуют только файлы «EXPERTS», но, возможно, отсутствуют другие файлы, например из «include»).