
Datenwissenschaft und ML (Teil 38): AI Transfer Learning auf den Forexmärkten

Inhalt
- Was ist Transferlernen?
- Wie funktioniert das?
- Vorteile des Transferlernens
- Ein einfaches Basismodell
- Das Problem mit kontinuierlichen Variablen
- Lernen übertragen
- Transferlernen bei einem Handelsroboter
- Abschließende Überlegungen
Was ist Transfer Learning?
Transfer-Lernen ist eine Technik des maschinellen Lernens, bei der ein für eine Aufgabe trainiertes Modell als Grundlage für eine zweite Aufgabe wiederverwendet wird.
Beim Transfer-Lernen wird ein maschinelles Lernmodell nicht von Grund auf neu trainiert, sondern das von einem bereits trainierten Modell gelernte Wissen übertragen und für eine neue spezifische Aufgabe feinabgestimmt. Diese Technik ist sehr nützlich, wenn:
- Wir haben nicht viele beschriftete Daten für eine bestimmte Aufgabe.
- Ein Modell von Grund auf zu trainieren würde zu lange dauern oder zu viel Rechenleistung erfordern.
- Die zu lösende Aufgabe hat Ähnlichkeiten mit der Aufgabe, für die das ursprüngliche Modell trainiert wurde.
Hier ist ein Beispiel aus der Praxis, bei dem KI-Experten Transfer Learning einsetzen;
Nehmen wir an, Sie erstellen einen Klassifikator für Katzen- und Hundebilder, aber Sie haben nur 1.000 Bilder. Ein tiefes CNN von Grund auf zu trainieren, wäre schwierig. Stattdessen können Sie ein Modell wie ResNet50 or VGG16 nehmen, das bereits auf ImageNet (mit Millionen von Bildern in 1000 Klassen) trainiert wurde, dann seine Faltungsschichten als Merkmalsextraktoren verwenden, dann Ihre nutzerdefinierte(n) Klassifizierungsschicht(en) hinzufügen und es auf Ihrem kleineren Katzen-/Hundedatensatz feinabstimmen.
Dieser Prozess ermöglicht die gemeinsame Nutzung von Modellinformationen, was uns als Entwicklern das Leben leichter macht, da wir das Rad nicht jedes Mal neu erfinden müssen. Anstatt ein Modell von Grund auf neu zu trainieren, können Sie auf der Grundlage verfügbarer Modelle, die für eine sehr ähnliche Aufgabe vorgesehen sind, skalieren.
Man sagt, dass die meisten Menschen, die Schlittschuh laufen oder regelmäßig Schlittschuh laufen, auch beim Skifahren oder im Skisport gute Leistungen erbringen und umgekehrt, obwohl sie nicht intensiv dafür trainiert haben. Das liegt einfach daran, dass diese beiden Sportarten einige Ähnlichkeiten aufweisen.
Dies gilt auch für die Finanzmärkte, auf denen sich trotz unterschiedlicher Instrumente (Symbole), die verschiedene Wirtschaftsgüter oder Finanzmärkte repräsentieren, alle Märkte die meiste Zeit ähnlich verhalten, da sie alle von Angebot und Nachfrage gesteuert und beeinflusst werden.

Betrachtet man den Markt unter technischen Gesichtspunkten, so stellt man fest, dass alle Märkte zu Auf- und Abwärtsbewegungen neigen, dass alle Märkte ähnliche Kerzenmuster aufweisen, dass die Indikatoren bei verschiedenen Instrumenten ähnliche Muster zeigen und vieles mehr. Dies ist der Hauptgrund, warum wir oft eine Handelsstrategie der technischen Analyse für ein Instrument erlernen und das erlernte Wissen auf alle Märkte anwenden, ungeachtet der Unterschiede in den Preisgrößen, die jedes Instrument bietet.
Beim maschinellen Lernen verstehen die Modelle oft nicht, dass diese Märkte vergleichbar sind. In diesem Artikel werden wir erörtern, wie wir Transfer Learning nutzen können, um Modelle dabei zu unterstützen, Muster in verschiedenen Finanzinstrumenten zu verstehen, um ein effektives Modelltraining zu ermöglichen, was die Vor- und Nachteile dieser Technik sind und was für ein effektives Transfer Learning zu beachten ist.
Wie funktioniert das Transferlernen?
Transferlernen ist eine intelligente Methode, um das, was ein Modell bereits bei einer Aufgabe gelernt hat, wiederzuverwenden und auf eine andere, aber verwandte Aufgabe anzuwenden. Das spart Zeit und steigert oft die Leistung.
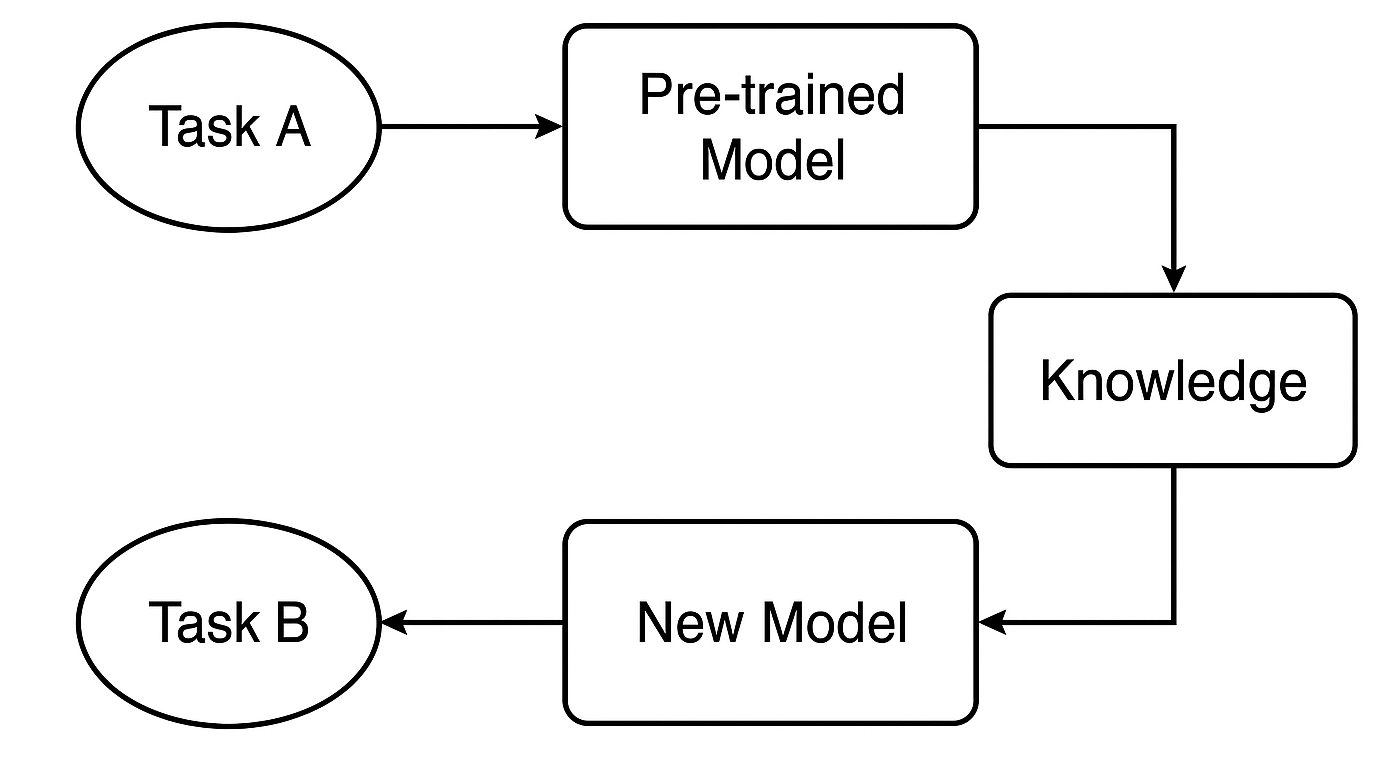
Was ist ein vortrainiertes Modell?
Wir beginnen mit einem Modell, das bereits auf einem großen Datensatz für Aufgabe A trainiert wurde. Dieses Modell hat gelernt, allgemeine Muster und Merkmale zu erkennen, die für ähnliche Aufgaben nützlich sind.
Beim Handel könnte es sich beispielsweise um ein Modell handeln, das auf eine Strategie oder ein Symbol trainiert wurde und das bereits gängige Marktverhaltensweisen versteht, die auch bei anderen Deviseninstrumenten auftreten.
Wie wird Wissen übertragen?
Wenn wir ein neuronales Netz wie ein CNN oder RNN verwenden, können wir die ersten Schichten - die, die allgemeine Merkmale erfassen - wiederverwenden. Diese Schichten wirken wie ein Fundament, auf dem breite Muster erkannt werden, die sowohl bei den ursprünglichen als auch bei den neuen Aufgaben hilfreich sind.
Feinabstimmung für die neue Aufgabe
Als Nächstes passen wir das Modell für Aufgabe B - vielleicht ein anderes Instrument oder eine andere Strategie - an, indem wir bestimmte Schichten oder Parameter so einstellen, dass es mit den neuen Daten gut funktioniert. In diesem Schritt wird das Modell an die neue Situation angepasst.
Warum sollte man Transfer Learning einsetzen?
1. Schnellere Ausbildung
Anstatt bei Null anzufangen, verwenden wir erlernte Funktionen. Dadurch wird die Trainingszeit erheblich verkürzt - vor allem beim Deep Learning, wo die Einsparung von Stunden oder sogar Tagen an Rechenzeit einen großen Unterschied ausmachen kann.
2. Häufige Verbesserung der Genauigkeit
Modelle, die das Transfer-Lernen nutzen, schneiden in der Regel besser ab, insbesondere wenn nur wenige markierte Daten vorhanden sind. Das vorab trainierte Modell weiß bereits, wie es wichtige Signale wie Handels-Setups oder Indikatoren erkennen kann, was ihm hilft, bei der neuen Aufgabe intelligentere Entscheidungen zu treffen.
3. Funktioniert auch bei kleinen oder verrauschten Datensätzen
Seien wir ehrlich: Es ist schwierig, in MetaTrader 5 für einige Symbole gute historische oder Tick-Daten zu erhalten. Einige Instrumente verfügen einfach nicht über genügend Daten. Durch die Verwendung eines Modells, das mit einem umfangreicheren Datensatz trainiert wurde, können wir jedoch eine Überanpassung vermeiden und auch mit begrenzten Daten ein starkes Modell erstellen.
4. Wiederverwendbares Wissen für alle Instrumente
Die Märkte verhalten sich auf technischer Ebene oft ähnlich. Anstatt also für jedes Symbol ein neues Modell zu trainieren, können wir das Wissen über alle Instrumente hinweg gemeinsam nutzen und wiederverwenden - das spart Zeit und verbessert die Konsistenz.
Ein einfaches Basismodell
Um einen Ausgangspunkt (ein Basismodell) zu erhalten, trainieren wir einen Klassifizierer, den einfachen Random Forest. Der Einfachheit halber können wir die OHLC-Werte (Open, High, Low und Close) verwenden.
Wir beginnen mit der Sammlung von OHLC-Werten für verschiedene wichtige und weniger wichtige Forex-Instrumente und fügen auch einige Metalle in den Mix ein.
#include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbols = "EURUSD|GBPUSD|AUDUSD|USDCAD|USDJPY|USDCHF|NZDUSD|EURNZD|AUDNZD|GBPNZD|NZDCHF|NZDJPY|NZDCAD|XAUUSD|XAUJPY|XAUEUR|XAUGBP"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string SymbolsArr[]; ushort sep = StringGetCharacter("|",0); if (StringSplit(symbols, sep, SymbolsArr)<0) { printf("%s failed to split the symbols, Error %d",__FUNCTION__,GetLastError()); return; } //--- vector open, high, low, close; for (uint i=0; i<SymbolsArr.Size(); i++) { string symbol = SymbolsArr[i]; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); continue; } //--- open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); df.to_csv(StringFormat("Fxdata.%s.%s.csv",symbol,EnumToString(timeframe)), true); } }
Nachdem wir die Daten gesammelt haben, können wir in einem Python-Skript sofort auf die CSV-Dateien zugreifen.
def getXandY(symbol: str, timeframe: str, lookahead: int) -> tuple: df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # Splitting data into X and y X = df.drop(columns=[ "future_close", "Signal" ]) y = df["Signal"] return (X, y)
Nach dem Einlesen der CSV-Datei bereitet die Funktion getXandY die Zielvariable auf der Grundlage einer einfachen Logik vor: Wenn der nächste Bar-Close größer ist als der aktuelle Schlusskurs, ist das ein bullisches Signal, und umgekehrt, wenn der nächste Bar-Close unter dem aktuellen Schlusskurs liegt.
Wir erstellen eine Funktion zum Trainieren eines Modells auf der Grundlage von X- und Y-Daten und geben ein trainiertes Modell in einer Scikit-learn Pipeline zurück.
def trainSymbol(X_train: pd.DataFrame, y_train: pd.DataFrame) -> Pipeline: # Training a model classifier = RandomForestClassifier(n_estimators=100, min_samples_split=3, max_depth = 5) pipeline = Pipeline([ ("scaler", RobustScaler()), ("classifier", classifier) ]) pipeline.fit(X_train, y_train) return pipeline
Eine Funktion zur Evaluierung dieses Modells über verschiedene Instrumente hinweg wäre nützlich.
def evalSymbol(model: Pipeline, X: pd.DataFrame , y: pd.Series) -> int: # evaluating the model preds = model.predict(X) acc = accuracy_score(y, preds) return acc
Lassen Sie uns unser Basismodell auf EURUSD trainieren und dann seine Leistung auf den übrigen von uns gesammelten Symbolen bewerten.
symbols = ["EURUSD","GBPUSD","AUDUSD","USDCAD","USDJPY","USDCHF","NZDUSD","EURNZD","AUDNZD","GBPNZD","NZDCHF","NZDJPY","NZDCAD","XAUUSD","XAUJPY","XAUEUR","XAUGBP"] # training on EURUSD lookahead = 1 X, y = getXandY(symbol=symbols[0], timeframe="PERIOD_H4", lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, shuffle=True) model = trainSymbol(X_train, y_train) # Evaluating on the rest of symbols trained_symbol = symbols[0] print(f"Trained on {trained_symbol}") for symbol in symbols: X, y = getXandY(symbol=symbol, timeframe="PERIOD_H4", lookahead=1) acc = evalSymbol(model, X, y) print(f"--> {symbol} | acc: {acc}")
Ausgabe:
Trained on EURUSD --> EURUSD | acc: 0.5478518727715607 --> GBPUSD | acc: 0.5009182736455464 --> AUDUSD | acc: 0.5026133634694165 --> USDCAD | acc: 0.4973701860284514 --> USDJPY | acc: 0.49477401129943505 --> USDCHF | acc: 0.5078731817539895 --> NZDUSD | acc: 0.4976826463824518 --> EURNZD | acc: 0.5071507150715071 --> AUDNZD | acc: 0.5005597760895641 --> GBPNZD | acc: 0.503459397596629 --> NZDCHF | acc: 0.4990389436737423 --> NZDJPY | acc: 0.4908841561794127 --> NZDCAD | acc: 0.5023507681974645 --> XAUUSD | acc: 0.48674396277970605 --> XAUJPY | acc: 0.4816082121471343 --> XAUEUR | acc: 0.4925268155442237 --> XAUGBP | acc: 0.49455864570737607
Das Modell war 0,54 genau auf dem Symbol, auf dem es trainiert wurde, und die Genauigkeit auf dem Rest lag zwischen 0,48 - 0,50, man könnte meinen, dass dieses Ergebnis nicht viel von dem abweicht, das auf dem Trainingssymbol erreicht wurde, sodass dies bedeutet, dass das Modell gut auf Symbolen funktioniert, auf denen es nicht trainiert wurde, um es gelinde auszudrücken, aber dies ist ein schreckliches Ergebnis.
Denn eine Gewinnquote von 0,5 zu 1 (50 % zu 100 %) ist wie das Werfen einer Münze: Ihre Gewinnwahrscheinlichkeit beträgt 0,5 zu 1.
Obwohl das Basismodell scheinbar einige Vorhersagen für andere Instrumente macht, für die es nicht trainiert wurde, haben wir ein großes Problem, das durch kontinuierliche Merkmale (Variablen) verursacht wird. Diese OHLC-Werte.
Das Problem mit kontinuierlichen Variablen
Da wir unser Basismodell robust und universell machen wollen, sodass es in der Lage ist, Muster zu erkennen und über verschiedene Symbole hinweg zu operieren, sind Merkmale kontinuierlicher Variablen wie Eröffnungs-, Höchst-, Tiefst- und Schlusskurswerte für diese Aufgabe ungeeignet, da sie keine anderen Muster bieten als eine Anzeige, wie sich die Preise in der Vergangenheit bewegt haben.
Ganz zu schweigen davon, dass jedes Instrument seinen Preis in einer ganz anderen Größenordnung hat als die anderen. Die heutigen Schlusskurse sehen zum Beispiel wie folgt aus:
| SYMBOL | TAGESSCHLUSSKURS |
|---|---|
| USDJPY | 142.17 |
| EURUSD | 1.13839 |
| XAUUSD | 3305.02 |
Das bedeutet, dass ein Modell, das für ein bestimmtes Instrument trainiert wurde, möglicherweise nicht in der Lage ist, mit anderen Instrumenten zurechtzukommen, da sie sich in der Preisgestaltung unterscheiden.
Abgesehen davon, dass sie keine erlernbaren Muster enthalten, müssen Modelle, die auf kontinuierlichen Variablen trainiert wurden, häufig neu trainiert werden, da die Märkte jeden Tag neue Höhen erreichen, sodass wir unsere Modelle regelmäßig trainieren müssen, um mit dem Tempo Schritt zu halten und unsere Modelle mit neuen/jüngsten Informationen zu aktualisieren.
Nur stationäre Variablen sind in der Lage, maschinelle Lernmodelle bei der Erfassung und Relevanz über verschiedene Märkte hinweg zu unterstützen, weil sich ihr Mittelwert, ihre Varianz und ihre Autokorrelation im Laufe der Zeit nicht ändern (sie bleiben konstant). Dies kann bei verschiedenen Instrumenten beobachtet werden.
Wenn wir das Transfer-Lernen nutzen wollen, dann müssen alle Merkmale wie Indikatoren und Muster, die aus dem Markt in unseren unabhängigen Variablen extrahiert werden, entweder konstant oder stationär sein.
Wenn Sie z. B. den RSI-Indikator für ein beliebiges Instrument ablesen, liegen die Werte immer noch zwischen 0 und 100, was für die Erfassung von Mustern entscheidend ist.
Technische Merkmale
Es gibt viele Techniken, die wir einsetzen können, um stationäre Variablen zu erhalten, aber für den Moment können wir einige Techniken verwenden, um unsere Daten zu bearbeiten, wie z. B. die Berechnung der prozentualen Veränderung des Schlusskurses, die Differenzierung jedes OHLC-Wertes und die Verwendung einiger stationärer Indikatoren.
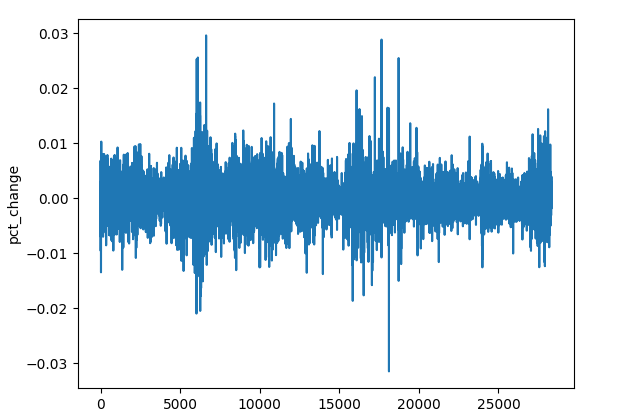
(a): Prozentuale Veränderung des Schlusskurses
res_df["pct_change"] = df["Close"].pct_change()
Trotz der unterschiedlichen Größenordnung des Preises zwischen den verschiedenen Symbolen (Instrumenten) sind die prozentualen Veränderungswerte immer konstant, was sie zu einem guten universellen Merkmal für die Mustererkennung macht.
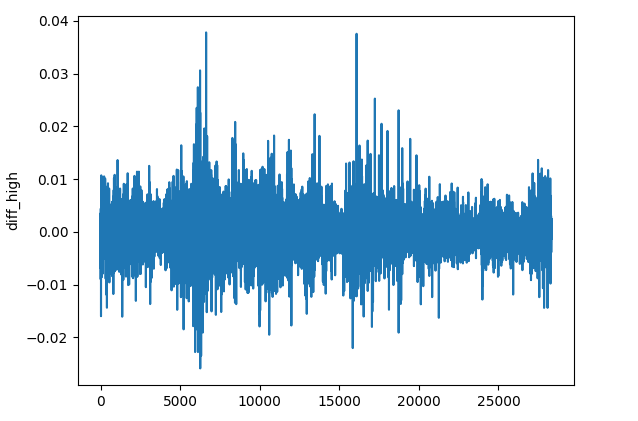
(b): Differenzierung der einzelnen OHLC-Werte
res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff()
Die Methode diff() berechnet die Differenz zwischen dem aktuellen Element und dem vorherigen Element 1 (standardmäßig). Diese Funktion kann uns dabei helfen, zu erkennen, wie sich der Preis auf jedem Balken im Vergleich zum vorherigen auf jedem Instrument verändert.
(c): Stationäre Indikatoren
Wir können einige Momentum- und Oszillatorindikatoren hinzufügen, die stationäre Ergebnisse aufweisen.
Indikator | Bereich der Werte |
|---|---|
# Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() | Von 0 bis 100. |
# Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() | Von 0 bis 100. |
# Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() | Kleine positive und negative Werte, in der Regel von -0,1 bis +0,1. |
# Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() | In der Regel von -300 bis +300. |
# Rate of Change (ROC) res_df['roc'] = ta.momentum.ROCIndicator(df["Close"], window=12).roc() | Unbegrenzt, kann entweder negativ oder positiv sein. |
# Ultimate Oscillator (UO) res_df['uo'] = ta.momentum.UltimateOscillator(df['High'], df['Low'], df['Close'], window1=7, window2=14, window3=28).ultimate_oscillator() | Von 0 bis 100. |
# Williams %R res_df['williams_r'] = ta.momentum.WilliamsRIndicator(df['High'], df['Low'], df['Close']).williams_r() | Von -100 bis 0. |
# Average True Range (ATR) res_df['atr'] = ta.volatility.AverageTrueRange(df['High'], df['Low'], df['Close'], window=14).average_true_range() | Unbegrenzt kleine positive Werte. |
# Awesome Oscillator (AO) res_df['ao'] = ta.momentum.AwesomeOscillatorIndicator(df['High'], df['Low']).awesome_oscillator() | Unbegrenzte kleine Werte, typischerweise von -0,1 bis +0,1 |
# Average Directional Index (ADX) res_df['adx'] = ta.trend.ADXIndicator(df['High'], df['Low'], df['Close'], window=14).adx() | Von 0 bis 100. |
# True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() | In der Regel von -100 bis +100. |
Dies sind nur einige wenige stationäre Variablen, Sie können gerne weitere Ihrer Wahl hinzufügen.
Alle diese Methoden und Operationen können in eine eigenständige Funktion verpackt werden.
def getStationaryVars(df: pd.DataFrame) -> pd.DataFrame: res_df = pd.DataFrame() res_df["pct_change"] = df["Close"].pct_change() res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff() # Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() # Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() # Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() # Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() # .... See the code in the notebook in the attachments and above # .... # .... # True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() return res_df
Lassen Sie uns nun ein Basismodell erstellen, das dazu dient, Wissen von einem Instrument auf ein anderes zu übertragen.
Transfer Learning
Transfer Learning wird in der Regel mit tiefen Modellen durchgeführt, meist mit Convolutional Neural Networks (CNNs). Da CNNs bei der Erkennung von Mustern überragend sind, ermöglicht ihnen diese Fähigkeit, ähnliche Muster zu erkennen, die dann auf andere Aspekte innerhalb desselben Bereichs übertragen werden können.
Wir verpacken ein Convolutional Neural Network (CNN)-Modell in eine Funktion namens trainCNN.
import tensorflow as tf from tensorflow.keras import layers, models, Model from tensorflow.keras.callbacks import EarlyStopping
def trainCNN(train_set: tuple, val_set: tuple, learning_rate: float=1e-3, epochs: int=100, batch_size: int=32): X_train, y_train = train_set X_val, y_val = val_set input_shape = X_train.shape[1:] num_classes = len(np.unique(y_train)) model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(32, activation='tanh'), layers.Dense(num_classes, activation='softmax') ]) # Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'] ) # Early stopping callback early_stop = EarlyStopping( monitor='val_loss', # Watch validation loss patience=10, # Stop if no improvement restore_best_weights=True ) # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], verbose=1 ) # Save trained weights model.save_weights('cnn_pretrained.weights.h5') return model
Dieses sequentielle Modell hat zwei 1D-Faltungsschichten, die uns bei der Extraktion der Merkmale aus der Eingabesequenz helfen können.
Die Global Average Pooling-Schicht wird eingeführt, um die Sequenzen zu reduzieren, sodass sie einer dichten Schicht (FNN layer) mit einer tanh-Aktivierungsfunktion zugeführt werden können.
Die letzte Schicht hat eine Softmax-Aktivierungsfunktion für die Rückgabe der vorhergesagten Wahrscheinlichkeiten für jede Klasse.
Wir speichern die Gewichte der Modelle, da sie alle gelernten Muster aus den Daten repräsentieren, diese Gewichte können an ein vorangehendes Modell weitergegeben werden.
Wenn wir EURUSD mit einem 4-Stunden-Zeitrahmen verwenden, können wir OHLC-Werte aus dem ursprünglichen Datenrahmen sammeln.
lookahead = 1 trained_symbol = symbols[0] timeframe = "PERIOD_H4" df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{trained_symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead)
Auch hier erstellt die Funktion getXandY eine Zielvariable unter Verwendung der Close-Werte und auf der Grundlage des angegebenen Lookahead-Werts (in diesem Fall 1).
def getXandY(df: pd.DataFrame, lookahead: int) -> tuple: # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # if next bar closed above the current one, thats a bullish signal otherwise bearish # Splitting data into X and y X = df.drop(columns=[ "Close", "future_close", "Signal" ]) y = df["Signal"] return (X, y)
Wir müssen die Daten in einen Trainings- und einen Validierungs- (Test-) Satz aufteilen und dann das Ergebnis mit einem Skalierer der Wahl, in diesem Fall dem Robust Scaler, standardisieren.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Da Faltungsneuronale Netze (CNNs) eine 3D-Eingabe/Daten benötigen, können wir diese Daten so verarbeiten, dass sie innerhalb eines bestimmten Fensters für die zeitliche Mustererkennung über diesen bestimmten Horizont liegen.
def create_sequences(X, Y, time_step): if len(X) != len(Y): raise ValueError("X and y must have the same length") X = np.array(X) Y = np.array(Y) Xs, Ys = [], [] for i in range(X.shape[0] - time_step): Xs.append(X[i:(i + time_step), :]) # Include all features with slicing Ys.append(Y[i + time_step]) return np.array(Xs), np.array(Ys)
# Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window)
One-hot encoding ist für die Zielvariable in jedem Klassifizierungsproblem, an dem neuronale Netze beteiligt sind, von entscheidender Bedeutung, da sie ihnen hilft, die Klassen zu unterscheiden.
# One-hot encode the labels for multi-class classification
y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes)
y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes)
Schließlich können wir ein Basismodell trainieren.
base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) print("Test acc: ", base_model.evaluate(X_test_seq, y_test_encoded)[1])
Ausgabe:
Epoch 1/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 4s 4ms/step - accuracy: 0.4994 - loss: 0.6990 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 2/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4976 - loss: 0.6939 - val_accuracy: 0.5023 - val_loss: 0.6936 Epoch 3/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4977 - loss: 0.6940 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 4/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5034 - loss: 0.6937 - val_accuracy: 0.4977 - val_loss: 0.6962 ... ... Epoch 16/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5039 - loss: 0.6934 - val_accuracy: 0.5023 - val_loss: 0.6932 Epoch 17/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4988 - loss: 0.6940 - val_accuracy: 0.4977 - val_loss: 0.6937 Epoch 18/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5013 - loss: 0.6943 - val_accuracy: 0.5023 - val_loss: 0.6931 266/266 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.5037 - loss: 0.6931 Test acc: 0.5022971034049988
Toll, wir haben gerade ein Basismodell für EURUSD trainiert und eine Gesamtgenauigkeit von 0,502 erreicht.
Nun wollen wir dieses Modell nutzen, um Wissen auf andere Modelle zu übertragen und auszutauschen, die mit anderen Instrumenten trainiert wurden, und sehen, wie das funktioniert.
for symbol in symbols: if symbol == trained_symbol: # skip transfer learning on the trained symbol continue print(f"Symbol: {symbol}") df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # we add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window) # One-hot encode the labels for multi-class classification y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes) y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes) # Freeze all layers except the last one for layer in base_model.layers[:-1]: layer.trainable = False # Create new model using the base model's architecture model = models.clone_model(base_model) model.set_weights(base_model.get_weights()) # Recompile with lower learning rate model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy']) early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) print("Test acc:", model.evaluate(X_test_seq, y_test_encoded)[1])
Die gleichen Prozesse werden für die Aufteilung der Daten, die Erstellung sequenzieller Daten und die Codierung der Zielvariablen wiederholt. Die Operationen werden nur für jedes Symbol angegeben.
Um das Wissen aus dem Basismodell zu übertragen, bauen wir ein weiteres Modell auf, das auf dem Basismodell basiert. Entscheidend ist dabei, dass einige der CNN-Schichten eingefroren werden.
Wir frieren alle Schichten eines CNN-Modells ein, außer der letzten, weil wir wollen, dass unser Modell die aus den Basisdaten gelernten Muster beibehält. Indem wir einige der Schichten einfrieren, verhindern wir, dass nützliche Merkmale zerstört werden, wenn wir das Modell mit neuen Daten neu trainieren.
Wir lassen die letzte Schicht nicht einfrieren, weil wir wollen, dass sich die Gewichte der letzten Schicht für jedes Symbol an neue Entscheidungsgrenzen anpassen. Im Grunde geben wir dem Modell also neue Verteilungen auf der Zielvariablen und lassen es die Beziehungen zwischen den gelernten Mustern aus dem Basismodell und dem, was auf der Zielvariablen ist, auf diesen neuen Daten bestimmen.
Wir klonen auch die Modellarchitektur vom Basismodell auf das aktuelle Modell und weisen dem neuen Modell seine Gewichte zu. Denken Sie daran, dass wir die Gewichte in der Funktion trainCNN gespeichert haben. Sie können die Gewichte aus einer Datei laden, wenn Sie das Modell von irgendwoher importieren, oder die Gewichte des Modells direkt aus dem Modellobjekt laden, wenn sich das Basismodell in demselben Python-Skript oder derselben Datei befindet, wie oben beschrieben.
Schließlich erstellen wir das Modell auf der Grundlage von Marktdaten eines anderen Instruments als dem, das beim Training des Basismodells verwendet wurde; auch andere Parameter können geändert werden.
Nachfolgend finden Sie die Genauigkeit, die bei verschiedenen Forex-Symbolen erreicht wurde.
| SYMBOL | GBPUSD | AUDUSD | USDCAD | USDJPY | USDCHF | NZDUSD | EURNZD | AUDNZD | GBPNZD | NZDCHF | NZDJPY | NZDCAD | XAUUSD | XAUJPY | XAUEUR | XAUGBP |
| GENAUIGKEIT | 0.505 | 0.506 | 0.501 | 0.516 | 0.506 | 0.497 | 0.505 | 0.502 | 0.504 | 0.505 | 0.51 | 0.505 | 0.506 | 0.514 | 0.507 | 0.504 |
Nun sagt uns dieses Ergebnis nicht viel, lassen Sie uns den Klassifizierungsbericht einbeziehen, um dieses Ergebnis im Detail zu analysieren.
preds = base_model.predict(X_test_seq) pred_indices = preds.argmax(axis=1) pred_class_labels = [classes_in_y[i] for i in pred_indices] print("Classification report\n", classification_report(pred_class_labels, y_test_seq))
Der Klassifizierungsbericht für das Basismodell.
Classification report precision recall f1-score support 0 1.00 0.50 0.66 8477 1 0.00 0.00 0.00 0 accuracy 0.50 8477 macro avg 0.50 0.25 0.33 8477 weighted avg 1.00 0.50 0.66 8477
Dieses Ergebnis deutet auf ein schreckliches Ergebnis hin. Das Modell erstellte einen stark verzerrten Klassifizierungsbericht.
Dies deutet darauf hin, dass wir in unserem Modell ein Bias haben, die durch unser Modell oder die Daten verursacht werden könnte.
Es gibt mehrere Möglichkeiten, dieses Bias zu beseitigen, wie wir in einem früheren Artikel erörtert haben, aber lassen Sie uns zunächst ein paar Dinge tun:
(a): Fügen wir Klassengewichte hinzu, um ein eventuelles Klassenungleichgewicht in unseren Daten zu beheben.
from sklearn.utils.class_weight import compute_class_weight
def trainCNN: #.... #.... y_train_integers = np.argmax(y_train, axis=1) # return to non-one hot encoded class_weights = compute_class_weight('balanced', classes=np.unique(y_train_integers), y=y_train_integers) class_weight_dict = {i: weight for i, weight in enumerate(class_weights)} # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], class_weight=class_weight_dict, verbose=1 )
(b): Fügen wir eine weitere Faltungsschicht hinzu und erhöhen die Anzahl der Neuronen in der dichten Schicht, um die Erfassung komplizierter Muster zu erleichtern.
def trainCNN: # ... # ... model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(32, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(128, activation='relu'), layers.Dense(num_classes, activation='softmax') ])
(c): Da es sich um ein binäres Klassifizierungsproblem handelt, gibt es in unserer Zielvariablen nur zwei Klassen. 0 für Verkaufssignale und 1 für Kaufsignale. Wir ändern die Verlustfunktion in „binary_crossentropy“ und die Bewertungsmetrik in „binary_accuracy“
# Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='binary_crossentropy', metrics=['binary_accuracy'] )
Als ein CNN-Modell neu trainiert wurde, sahen die Werte viel besser aus.
.... .... 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5257 - loss: 0.6920 - val_binary_accuracy: 0.5043 - val_loss: 0.6933 Epoch 7/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5259 - loss: 0.6918 - val_binary_accuracy: 0.5027 - val_loss: 0.6934 Epoch 8/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5283 - loss: 0.6915 - val_binary_accuracy: 0.5042 - val_loss: 0.6936 Epoch 9/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5284 - loss: 0.6912 - val_binary_accuracy: 0.5028 - val_loss: 0.6937 Epoch 10/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5315 - loss: 0.6909 - val_binary_accuracy: 0.5036 - val_loss: 0.6938 Epoch 11/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5295 - loss: 0.6907 - val_binary_accuracy: 0.5042 - val_loss: 0.6940 Epoch 12/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5298 - loss: 0.6904 - val_binary_accuracy: 0.5074 - val_loss: 0.6941 619/619 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5101 - loss: 0.6926 265/265 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - binary_accuracy: 0.5018 - loss: 0.6933 Train acc: 0.5114434361457825 Test acc: 0.5050135850906372 265/265 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step Classification report precision recall f1-score support 0 0.58 0.50 0.54 4870 1 0.43 0.51 0.47 3607 accuracy 0.51 8477 macro avg 0.51 0.51 0.50 8477 weighted avg 0.52 0.51 0.51 8477
Es gab keinen besonderen Grund für die geänderten Parameter. Ich wollte beweisen, dass wie bei jedem anderen Modell, das auf einem neuronalen Netz basiert, die Optimierung und Abstimmung der Parameter sehr wichtig sind.
Das derzeitige Ergebnis ist vielleicht auch nicht die optimale Lösung, denn es gibt viel zu diskutieren über CNNs und neuronale Netze im Allgemeinen.
Lassen Sie uns zunächst mit den aktuellen Parametern fortfahren, aber Sie können diese Werte beliebig anpassen, um ein Modell zu erhalten, das Ihren Bedürfnissen entspricht.
Jetzt, da wir ein Basismodell haben, das nicht so voreingenommen ist, können wir es verwenden, um sein Wissen auf andere Instrumente zu übertragen und alle diese Modelle im ONNX-Format zu speichern, um die Ergebnisse des Transfer-Learnings in einer tatsächlichen Handelsumgebung zu beobachten.
Transfer Learning auf einen Handelsroboter (EA)
Um Transfer Learning in einer Handelsumgebung in MetaTrader 5 zu testen, müssen wir die Modelle zunächst im ONNX-Format speichern und sie dann mit der Programmiersprache MQL5 laden.
Einfuhren.
import onnxmltools import tf2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Funktionen
def saveCNN(model, window: int, features: int, filename: str): model.output_names = ["output"] # Specifying the input signature for the model spec = (tf.TensorSpec((None, window, features), tf.float16, name="input"),) # Convert the Keras model to ONNX format onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=14) # Save the ONNX model to a file with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Da Keras-Modelle nicht über eine unterstützte Pipeline verfügen, wie wir sie oft verwenden, um alle Vorverarbeitungstechniken neben dem Scikit-learn-Modell zu verpacken, was es einfacher macht, das Modell und alle seine Schritte in einer einzigen ONNX-Datei zu speichern, müssen wir ein Keras-Modell und einen separat verwendeten Skalierer als unabhängige ONNX-Dateien speichern.
def saveScaler(scaler, features: int, filename: str): # Convert to ONNX format initial_type = [("input", FloatTensorType([None, features]))] onnx_model = convert_sklearn(scaler, initial_types=initial_type, target_opset=14) with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Nun können wir diese Funktionen beim Speichern des Basismodells und der Vorgängermodelle aufrufen.
Speichern des Basismodells.
# .... # .... base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) saveCNN(model=base_model, window=window, features=X_train_seq.shape[2], filename=f"{trained_symbol}.basemodel.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{trained_symbol}.{timeframe}.scaler.onnx")
Speichern von Modellen, die durch Transferlernen trainiert wurden.
for symbol in symbols: # ... # ... history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) saveCNN(model=model, window=window, features=X_train_seq.shape[2], filename=f"basesymbol={trained_symbol}.symbol={symbol}.model.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{symbol}.{timeframe}.scaler.onnx")
Nachdem wir die Dateien im gemeinsamen Ordner gespeichert haben, können wir sie in einen Expert Advisor (EA) laden, wobei die Namensgebung ähnlich ist.
#include <ta.mqh> //similar to ta in Python --> https://www.mql5.com/en/articles/16931 #include <pandas.mqh> //similar to Pandas in Python --> https://www.mql5.com/en/articles/17030 #include <CNN.mqh> //For loading Convolutional Neural networks in ONNX format --> https://www.mql5.com/en/articles/15259 #include <preprocessing.mqh> //For loading the scaler transformer #include <Trade\Trade.mqh> //The trading module #include <Trade\PositionInfo.mqh> //Position handling module CCNNClassifier cnn; RobustScaler scaler; CTrade m_trade; CPositionInfo m_position; input string base_symbol = "EURUSD"; input string symbol_ = "USDJPY"; input ENUM_TIMEFRAMES timeframe = PERIOD_H4; input uint window_ = 10; input uint lookahead = 1; input uint magic_number = 28042025; input uint slippage = 100; long classes_in_y_[] = {0, 1}; int OldNumBars = -1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!MQLInfoInteger(MQL_TESTER)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s Failed to set symbol_ = %s and timeframe = %s, Error = %d",__FUNCTION__,symbol_,EnumToString(timeframe), GetLastError()); return INIT_FAILED; } //--- string filename = StringFormat("basesymbol=%s.symbol=%s.model.%s.onnx",base_symbol, symbol_, EnumToString(timeframe)); if (!cnn.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a CNN model in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } //--- filename = StringFormat("%s.%s.scaler.onnx", symbol_, EnumToString(timeframe)); if (!scaler.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a scaler in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } }
Da wir das Äquivalent des TA - (Technische Analyse) Module von Python in MQL5 haben, das wir in diesem Artikel besprochen haben. Wir können die Indikatorfunktionen aufrufen und das Ergebnis in einem Python-Pandas-ähnlichenDatenrahmen zuordnen.
CDataFrame getStationaryVars(uint start = 1, uint bars = 50) { CDataFrame df; //Dataframe object vector open, high, low, close; open.CopyRates(Symbol(), Period(), COPY_RATES_OPEN, start, bars); high.CopyRates(Symbol(), Period(), COPY_RATES_HIGH, start, bars); low.CopyRates(Symbol(), Period(), COPY_RATES_LOW, start, bars); close.CopyRates(Symbol(), Period(), COPY_RATES_CLOSE, start, bars); vector pct_change = df.pct_change(close); vector diff_open = df.diff(open); vector diff_high = df.diff(high); vector diff_low = df.diff(low); vector diff_close = df.diff(close); df.insert("pct_change", pct_change); df.insert("diff_open", open); df.insert("diff_high", high); df.insert("diff_low", low); df.insert("diff_close", close); // Relative Strength Index (RSI) vector rsi = CMomentumIndicators::RSIIndicator(close); df.insert("rsi", rsi); // Stochastic Oscillator (Stoch) vector stock_k = CMomentumIndicators::StochasticOscillator(close,high,low).stoch; df.insert("stock_k", stock_k); // Moving Average Convergence Divergence (MACD) vector macd = COscillatorIndicators::MACDIndicator(close).main; df.insert("macd", macd); // Commodity Channel Index (CCI) vector cci = COscillatorIndicators::CCIIndicator(high,low,close); df.insert("cci", cci); // Rate of Change (ROC) vector roc = CMomentumIndicators::ROCIndicator(close); df.insert("roc", roc); // Ultimate Oscillator (UO) vector uo = CMomentumIndicators::UltimateOscillator(high,low,close); df.insert("uo", uo); // Williams %R vector williams_r = CMomentumIndicators::WilliamsR(high,low,close); df.insert("williams_r", williams_r); // Average True Range (ATR) vector atr = COscillatorIndicators::ATRIndicator(high,low,close); df.insert("atr", atr); // Awesome Oscillator (AO) vector ao = CMomentumIndicators::AwesomeOscillator(high,low); df.insert("ao", ao); // Average Directional Index (ADX) vector adx = COscillatorIndicators::ADXIndicator(high,low,close).adx; df.insert("adx", adx); // True Strength Index (TSI) vector tsi = CMomentumIndicators::TSIIndicator(close); df.insert("tsi", tsi); if (MQLInfoInteger(MQL_DEBUG)) df.head(); df = df.dropna(); //Drop not-a-number variables return df; //return the last rows = window from a dataframe which is the recent information fromthe market }
Bei jedem Balken werden für die Berechnung des Indikators 50 Balken in der Vergangenheit gesammelt, beginnend mit dem kürzlich geschlossenen Balken mit dem Index 1.
Der Hauptgrund für 50 Balken ist, dass genügend Platz für Indikatorberechnungen vorhanden ist, die mit NaN-Werten (Not a Number) einhergehen, die wir vermeiden wollen.
Der Awesome-Oszillator-Indikator ist derjenige, der am meisten in die Vergangenheit blickt, mit einem window2-Wert von 34, d.h. 50-34 = 16 ist die Anzahl der in Frage kommenden Daten, die für unser Modell übrig bleiben.
Wenn Sie diese Funktion im Debug-Modus ausführen, erhalten Sie einen Überblick über die Daten auf der Registerkarte Experten im MetaTrader 5.
MD 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | Index | pct_change | diff_open | diff_high | diff_low | diff_close | rsi | stock_k | macd | cci | roc | uo | williams_r | atr | ao | adx | tsi | FF 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | 0 | nan | 142.67000000 | 143.08800000 | 142.49100000 | 142.68300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | JO 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 1 | -0.25300842 | 142.68400000 | 142.84900000 | 142.28700000 | 142.32200000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 2 | 0.09977375 | 142.32300000 | 142.63500000 | 141.89900000 | 142.46400000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | HF 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 3 | -0.00070193 | 142.46400000 | 142.71900000 | 142.34400000 | 142.46300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | GJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 4 | -0.04702976 | 142.37400000 | 142.47200000 | 142.18600000 | 142.39600000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | ... | NR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 45 | -0.22551954 | 142.33800000 | 142.38800000 | 141.98200000 | 142.01700000 | 28.79606321 | 1.70731707 | 0.20202343 | -149.46898289 | -0.42629273 | 28.03714657 | -48.58934169 | 0.58185714 | 0.84359706 | 29.65580624 | 8.31951160 | NJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 46 | 0.16054416 | 141.97800000 | 142.31600000 | 141.96400000 | 142.24500000 | 35.49705652 | 13.58800774 | 0.12993025 | -131.96513868 | -0.57316604 | 34.81743660 | -43.09139137 | 0.56978571 | 0.51217941 | 28.18573720 | 4.78996901 | HQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 47 | 0.19543745 | 142.24500000 | 142.58100000 | 142.12400000 | 142.52300000 | 43.03880625 | 27.03094778 | 0.09414295 | -86.63856716 | -0.76174826 | 43.61239023 | -36.38775018 | 0.57742857 | 0.21773529 | 26.19967843 | 3.09202782 | FH 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 48 | 0.04771160 | 142.52300000 | 142.61500000 | 142.29800000 | 142.59100000 | 44.85843867 | 30.31914894 | 0.07045611 | -66.64608781 | -0.57732936 | 49.55462139 | -34.74801061 | 0.56007143 | -0.01222353 | 24.37916904 | 2.01861384 | MQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 49 | -0.19776844 | 142.59100000 | 142.75800000 | 142.25100000 | 142.30900000 | 38.91058297 | 16.68278530 | 0.02859940 | -70.14493704 | -0.77257229 | 41.99481159 | -41.54810707 | 0.52700000 | -0.13378529 | 23.02215655 | 0.05188403 |
In der Funktion OnTick werden zunächst diese stationären Variablen abgerufen, gefolgt von der Slicing-Operation, die sicherstellen soll, dass die empfangenen Daten oder die Anzahl der Balken innerhalb des erforderlichen Fensters liegen, das wir beim Training eines CNN-Modells verwendet haben.
void OnTick() { //--- if (!isNewBar()) return; CDataFrame x_df = getStationaryVars(); //--- Check if the number of rows received after indicator calculation is >= window size if ((uint)x_df.shape()[0]<window_) { printf("%s Fatal, Data received is less than the desired window=%u. Check your indicators or increase the number of bars in the function getSationaryVars()",__FUNCTION__,window_); DebugBreak(); return; } ulong rows = (ulong)x_df.shape()[0]; ulong cols = (ulong)x_df.shape()[1]; //printf("Before scaled shape = (%I64u, %I64u)",rows, cols); matrix x = x_df.iloc((rows-window_), rows-1, 0, cols-1).m_values; }
Da wir nun eine geslicte Matrix mit 10 Zeilen haben, die dem Fensterwert und den 16 Merkmalen entsprechen, die wir beim Training verwendet haben, können wir diese Daten an den geladenen RobustScaler weitergeben, bevor wir sie für die endgültigen Vorhersagen an das CNN-Modell weitergeben.
matrix x_scaled = scaler.transform(x); //Transform the data, very important long signal = cnn.predict(x_scaled, classes_in_y_).cls; //Predicted class
Schließlich können wir mit Hilfe des vom Modell erhaltenen Signals eine einfache Handelsstrategie entwickeln: Wenn das vom Modell erhaltene Signal gleich 1 ist (Aufwärtssignal), kaufen wir, und wenn das erhaltene Signal gleich 0 ist (Abwärtssignal), verkaufen wir.
Jedes Handelsgeschäft wird geschlossen, nachdem die Anzahl der Balken, die dem Lookahead-Wert entsprechen, im aktuellen Zeitrahmen verstrichen ist.
//--- Trading functionality MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe
Das war's. Lassen wir diesen Handelsroboter auf mehreren Instrumenten laufen, die wir während dieses Transfer-Learning-Prozesses verwendet haben, und beobachten wir ihre Vorhersageergebnisse vom 1. Januar 2023 bis zum 1. Januar 2025.
Zeitrahmen: PERIOD_H4. Modellierung: 1 Minute OHLC.
Symbol: XAUEUR
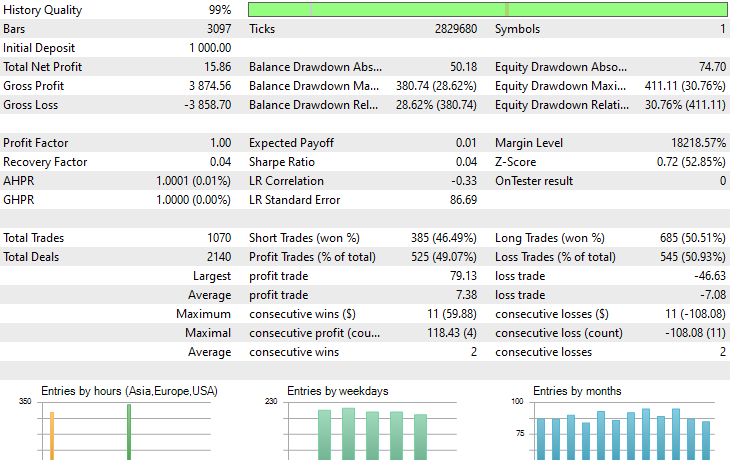
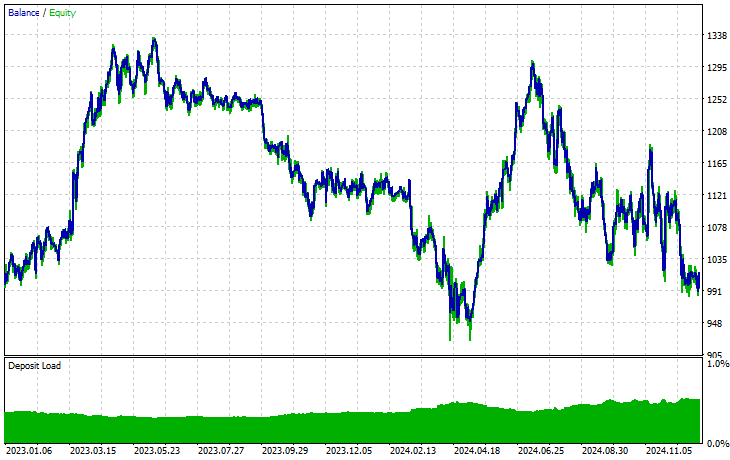
Symbol: XAUUSD
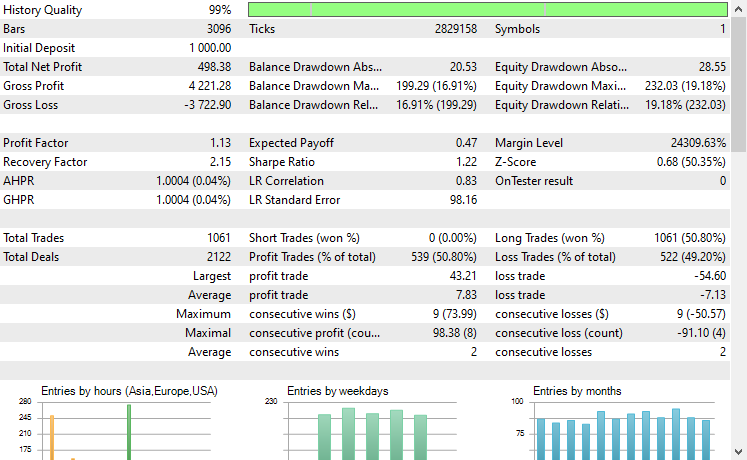
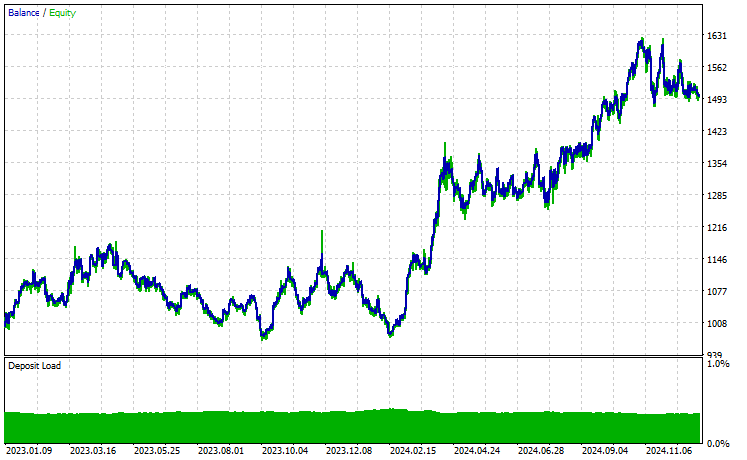
Von den 17 Instrumenten, die wir während des Transfer-Learnings für ein auf EURUSD trainiertes Basismodell verwendet haben, zeigten nur 2 Instrumente vielversprechende Ergebnisse. Der Rest war völliger Müll.
Dies könnte zweierlei bedeuten: Zum einen, dass die auf dem EURUSD beobachteten Muster eine starke Beziehung zu den auf dem XAUUSD und XAUEUR angezeigten Mustern haben oder diesen ähneln. Das macht Sinn, denn diese beiden Instrumente haben beide EUR und USD, die das Basissymbol EURUSD bilden.
Zweitens könnte dies auch bedeuten, dass wir suboptimale CNN-Modelle haben, da wir unsere Modelle nicht optimiert haben, um die beste Kombination aus Modellarchitektur und Parametern zu finden, ganz zu schweigen davon, dass wir nicht einmal verschiedene Basissymbole ausprobiert und die Ergebnisse bei anderen beobachtet haben.
Wir hätten ein paar Dinge tun können, aber das würde den Rahmen dieses Artikels sprengen. Das überlasse ich Ihnen.
Abschließende Überlegungen
Wir befinden uns im goldenen Zeitalter der künstlichen Intelligenz und des maschinellen Lernens. Diese Technologie schreitet schneller voran als erwartet, und dank Open-Source kann man jetzt mit ein paar Zeilen Code hervorragende Modelle auf bereits vorhandene aufbauen, was wir ganz einfach Transfer Learning nennen.
Zwar gibt es diese massiven Open-Source-Modelle für Computer Vision und bildbezogene Aufgaben wie ResNet50, MobileNet usw. Was es Entwicklern ermöglicht hat, an den Rand zu gelangen und sinnvolle KI-Lösungen zu entwickeln, muss im Finanzbereich erst noch unter dem Open-Source-Aspekt erforscht werden.
Dieser Artikel soll Ihnen die Augen für die Möglichkeiten des Transfer-Lernens öffnen und zeigen, wie es in diesem Bereich aussehen könnte. Er soll Ihnen dabei helfen, umfangreiche Modelle zu erstellen, die uns dabei helfen, die Finanzmärkte zu verstehen, indem sie gemeinsame Muster aus verschiedenen Instrumenten nutzen.
Viel Glück.
Tabelle der Anhänge
Dateiname | Beschreibung/Verwendung |
|---|---|
| Expert\Transfer Learning EA.mq5 | Der wichtigste Expert Advisor zum Testen von Transfer-Learning-Modellen in einer Handelsumgebung. |
| Include\CNN.mqh | Eine Bibliothek zum Laden und Bereitstellen von CNN-Modellen in .onnx-Dateien In MQL5. |
Include\pandas.mqh | Python-ähnliche Pandas-Bibliothek für Datenmanipulation und -speicherung |
Include\preprocessing.mqh | Enthält Klassen für Lade-, Skalierungstechniken und Datentransformatoren im .onnx-Format. |
Include\ta.mqh | Eine Bibliothek mit einem Plug-and-Play-Ansatz für die Arbeit mit Indikatoren in MQL5. |
Scripts\CollectData.mqh | Ein Skript zum Sammeln und Speichern von OHLC-Daten für verschiedene Instrumente in CSV-Dateien. |
| Python\forex-transfer-learning.ipynb | Ein Python-Skript (Jupyter Notebook) zum Ausführen des gesamten in diesem Artikel beschriebenen Python-Codes. |
Common\Files\*scaler.onnx | Skalierer für die Datenvorverarbeitung werden in Dateien im ONNX-Format gespeichert. |
Common\Files\*.onnx | CNN-Modelle, die in ONNX-formatierten Dateien gespeichert sind. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/17886
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 64): Verwendung von Mustern von DeMarker und Envelope-Kanälen mit dem Kernel des weißen Rauschens
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 64): Verwendung von Mustern von DeMarker und Envelope-Kanälen mit dem Kernel des weißen Rauschens
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.