
データサイエンスとML(第38回):外国為替市場におけるAI転移学習

内容
転移学習とは何か
転移学習とは、あるタスクで学習したモデルを、別のタスクの基盤として再利用する機械学習の手法です。
通常、機械学習モデルはゼロから学習させる必要がありますが、転移学習では、事前に学習済みのモデルが持つ知識を新しいタスク向けに微調整して利用します。この手法は、以下のような場合に特に有効です。
- 特定のタスクに対してラベル付きデータが十分に揃っていない場合
- ゼロからモデルを学習させるには時間がかかる、または計算資源が不足している場合
- 新しいタスクが、元のモデルが学習したタスクと類似している場合
以下は、実世界でAIの専門家が転移学習を使用する例です。
猫と犬の画像分類モデルを構築したいが、手元に1,000枚しか画像がありません。深層CNNをゼロから学習させるのは困難です。そこで、ImageNet(1,000クラス、数百万枚の画像を含むデータセット)で事前学習済みのResNet50やVGG16を活用し、その畳み込み層を特徴量抽出器として利用します。その上で、独自の分類層を追加し、小規模な猫・犬データセットで微調整(ファインチューニング)をおこないます。
このプロセスにより、モデルの情報を再利用でき、開発者として毎回ゼロからモデルを構築する必要がなくなります。類似タスクに特化した既存モデルをベースに学習をスケーリングできるため、効率的です。
一般に、スケートの経験がある人や定期的にスケートをする人は、スキーやスキー競技でも比較的上手にできる傾向があります。これは、両者のスポーツに共通点があるためで、個別に集中的な訓練を受けなくても応用が効くためです。
金融市場でも同様のことが言えます。異なる銘柄は異なる経済資産や金融市場を表していますが、ほとんどの市場は需給の影響を受けるため、基本的な挙動は非常に似ています。

市場を技術的な観点で詳しく観察すると、すべての市場は上昇・下降を繰り返し、似たようなローソク足パターンが複数の市場で確認できます。インジケーターも異なる銘柄で類似したパターンを示すことが多く、このような共通の挙動は非常に多く見られます。これが、ある銘柄で学んだテクニカル分析取引戦略を、銘柄ごとの価格の大きさの違いに関わらず、他の市場でも応用できる主な理由です。
しかし、機械学習モデルは通常、これらの市場間の類似性を自動的には理解しません。本記事では、転移学習を活用してモデルに複数の金融商品のパターンを理解させ、効果的に学習させる方法について解説します。また、この手法のメリットとデメリット、効果的に転移学習をおこなうために考慮すべきポイントについても詳しく説明します。
仕組み
転移学習とは、あるタスクでモデルがすでに学習した知識を、異なるが関連性のあるタスクに応用する賢い手法です。これにより学習時間を短縮でき、性能向上も期待できます。
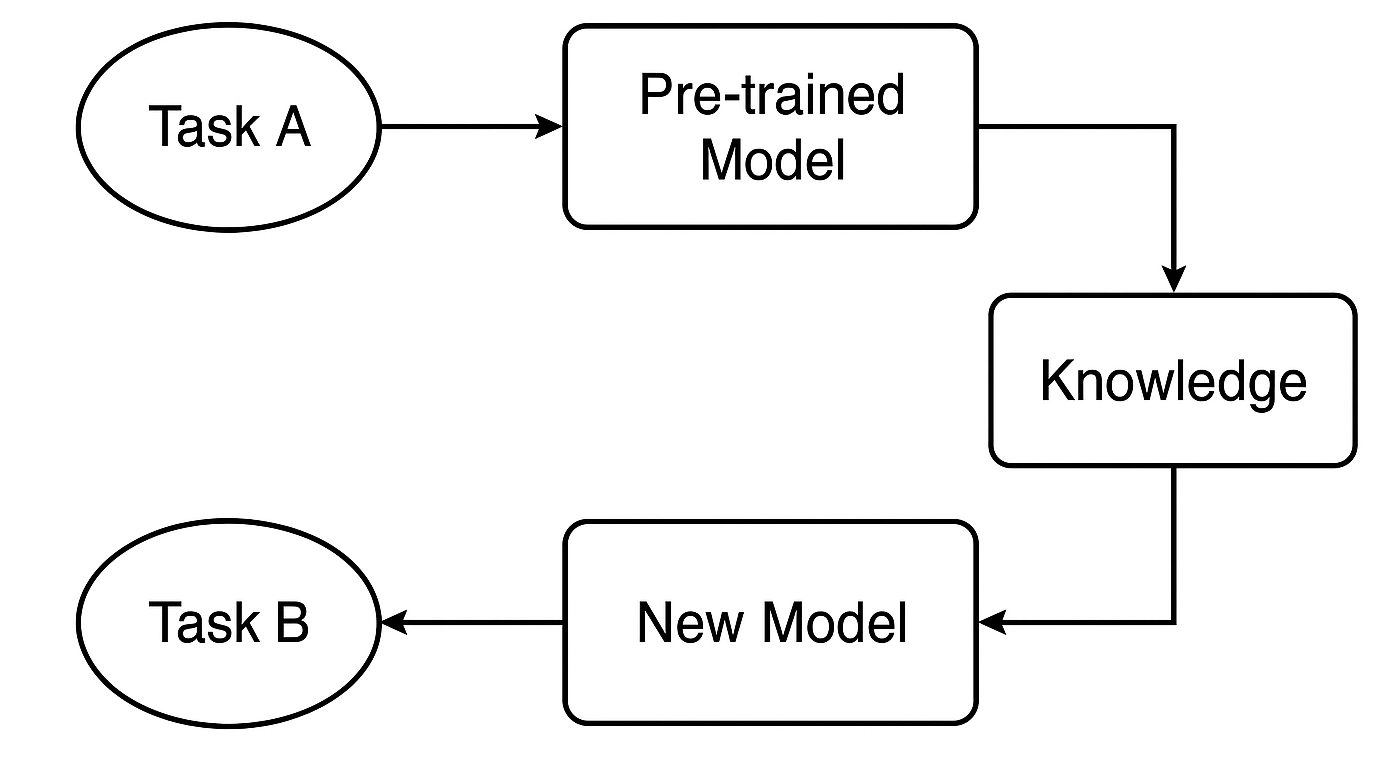
事前学習済みモデルとは何か
事前学習済みモデルとは、すでに大規模なデータセットを用いてタスクAで学習済みのモデルを指します。このモデルは、類似のタスクにも有用な一般的なパターンや特徴量をすでに学習しています。
取引の例で言えば、ある戦略や銘柄で学習済みのモデルが、他の外国為替銘柄にも現れる一般的な市場の挙動を理解している場合が該当します。
知識はどのように転移されるのか
CNNやRNNのようなニューラルネットワークを使用する場合、初期層(一般的な特徴量を捉える層)を取り出して再利用することができます。これらの層は基盤の役割を果たし、元のタスクと新しいタスクの両方で有用な広範なパターンを検出します。
新しいタスクへのファインチューニング
次に、タスクB(別の銘柄や戦略など)向けにモデルを調整します。特定の層やパラメータを微調整することで、新しいデータに対して高い性能を発揮できるようカスタマイズします。このステップにより、モデルは新しい状況に適応します。
転移学習を使用する理由
1. 学習時間の短縮
ゼロから学習を始めるのではなく、すでに学習された特徴量を再利用することで、学習時間を大幅に短縮できます。特に深層学習では、数時間から場合によっては数日の計算時間を節約できることが大きな利点です。
2. 精度の向上が期待できる
転移学習を用いたモデルは、特にラベル付きデータが少ない場合でも高い性能を発揮する傾向があります。事前学習済みモデルは、取引のセットアップやインジケーターなど重要なシグナルの検出方法をすでに学習しているため、新しいタスクでもより賢明な判断が可能になります。
3. 小規模またはノイズの多いデータセットでも有効
現実的に、MetaTrader 5で一部の銘柄の良質な過去データやティックデータを入手するのは難しい場合があります。データ量が不足している銘柄も少なくありません。しかし、豊富なデータで学習済みのモデルを利用することで、過学習を防ぎつつ、限られたデータでも高性能なモデルを構築できます。
4. 銘柄間で知識を再利用できる
市場はテクニカル面で類似した動きを示すことが多いため、銘柄ごとに新しいモデルを学習させる必要はありません。既存の知識を銘柄間で共有し再利用することで、学習時間の節約とモデルの一貫性向上が可能になります。
単純なベースモデル
まず、出発点として簡単なランダムフォレスト分類モデルを学習させ、ベースモデルを作成します。ここではシンプルにするため、OHLC(Open、High、Low、Close)データを使用します。
学習の第一歩として、主要およびマイナーな外国為替銘柄のOHLCデータを収集し、さらにいくつかの金属商品データも加えます。
#include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbols = "EURUSD|GBPUSD|AUDUSD|USDCAD|USDJPY|USDCHF|NZDUSD|EURNZD|AUDNZD|GBPNZD|NZDCHF|NZDJPY|NZDCAD|XAUUSD|XAUJPY|XAUEUR|XAUGBP"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string SymbolsArr[]; ushort sep = StringGetCharacter("|",0); if (StringSplit(symbols, sep, SymbolsArr)<0) { printf("%s failed to split the symbols, Error %d",__FUNCTION__,GetLastError()); return; } //--- vector open, high, low, close; for (uint i=0; i<SymbolsArr.Size(); i++) { string symbol = SymbolsArr[i]; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); continue; } //--- open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); df.to_csv(StringFormat("Fxdata.%s.%s.csv",symbol,EnumToString(timeframe)), true); } }
データを収集したら、Pythonスクリプト内でCSVファイルに直接アクセスできるようになります。
def getXandY(symbol: str, timeframe: str, lookahead: int) -> tuple: df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # Splitting data into X and y X = df.drop(columns=[ "future_close", "Signal" ]) y = df["Signal"] return (X, y)
CSVファイルを読み込んだ後、getXandY関数は目的変数を準備します。単純なロジックとして、次のバーの終値が現在の終値より高ければ強気シグナル、逆に次のバーの終値が現在の終値より低ければ弱気シグナルと判断します。
次に、Xとyのデータを用いてモデルを学習させ、Scikit-learnのパイプラインで学習済みモデルを返す関数を作成します。
def trainSymbol(X_train: pd.DataFrame, y_train: pd.DataFrame) -> Pipeline: # Training a model classifier = RandomForestClassifier(n_estimators=100, min_samples_split=3, max_depth = 5) pipeline = Pipeline([ ("scaler", RobustScaler()), ("classifier", classifier) ]) pipeline.fit(X_train, y_train) return pipeline
異なる銘柄に対してこのモデルの性能を評価するための関数を作成すると便利です。
def evalSymbol(model: Pipeline, X: pd.DataFrame , y: pd.Series) -> int: # evaluating the model preds = model.predict(X) acc = accuracy_score(y, preds) return acc
まず、EURUSDのデータでベースモデルを学習させ、その後、収集した他のすべての銘柄に対して性能を評価します。
symbols = ["EURUSD","GBPUSD","AUDUSD","USDCAD","USDJPY","USDCHF","NZDUSD","EURNZD","AUDNZD","GBPNZD","NZDCHF","NZDJPY","NZDCAD","XAUUSD","XAUJPY","XAUEUR","XAUGBP"] # training on EURUSD lookahead = 1 X, y = getXandY(symbol=symbols[0], timeframe="PERIOD_H4", lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, shuffle=True) model = trainSymbol(X_train, y_train) # Evaluating on the rest of symbols trained_symbol = symbols[0] print(f"Trained on {trained_symbol}") for symbol in symbols: X, y = getXandY(symbol=symbol, timeframe="PERIOD_H4", lookahead=1) acc = evalSymbol(model, X, y) print(f"--> {symbol} | acc: {acc}")
以下が出力です。
Trained on EURUSD --> EURUSD | acc: 0.5478518727715607 --> GBPUSD | acc: 0.5009182736455464 --> AUDUSD | acc: 0.5026133634694165 --> USDCAD | acc: 0.4973701860284514 --> USDJPY | acc: 0.49477401129943505 --> USDCHF | acc: 0.5078731817539895 --> NZDUSD | acc: 0.4976826463824518 --> EURNZD | acc: 0.5071507150715071 --> AUDNZD | acc: 0.5005597760895641 --> GBPNZD | acc: 0.503459397596629 --> NZDCHF | acc: 0.4990389436737423 --> NZDJPY | acc: 0.4908841561794127 --> NZDCAD | acc: 0.5023507681974645 --> XAUUSD | acc: 0.48674396277970605 --> XAUJPY | acc: 0.4816082121471343 --> XAUEUR | acc: 0.4925268155442237 --> XAUGBP | acc: 0.49455864570737607
このモデルは、学習に使用したEURUSDでは精度0.54を示しました。他の銘柄に対する精度は0.48〜0.50の範囲であり、一見すると学習銘柄での結果と大きくは変わらないように見えます。つまり、学習していない銘柄でもある程度動作しているように見えますが、実際には非常に問題のある結果です。
なぜなら、勝率0.5(50%)はコインの裏表を当てるのと同じであり、勝つ確率は0.5にすぎません。
ベースモデルは他の銘柄でも一応予測しているように見えますが、ここで大きな問題となるのは連続変数、つまりOHLCの値です。
連続変数における問題
ベースモデルを汎用的かつ頑健にし、さまざまな銘柄でパターンを検出できるようにしたい場合、Open、High、Low、Closeといった連続変数はこのタスクには適していません。これらの値は過去の価格の動きを示すだけで、汎用的なパターン検出にはほとんど寄与しないためです。
さらに、各銘柄の価格は他の銘柄と比べて桁が大きく異なることも問題です。たとえば、本日の終値は以下のようになっています。
| 銘柄 | 終値 |
|---|---|
| USDJPY | 142.17 |
| EURUSD | 1.13839 |
| XAUUSD | 3305.02 |
これは、各銘柄で学習したモデルが、価格の差異により他の銘柄ではうまく機能しない可能性があることを意味します。
さらに、連続変数には学習可能なパターンが含まれていないだけでなく、モデルは頻繁に再学習する必要があります。市場は日々新しい高値や安値を更新するため、最新の情報に追随するには定期的にモデルを学習させる必要があり、その計算コストは高くなります。これはまさに転移学習が解決を目指す課題です。
異なる市場間でモデルが有効に機能するためには、平均値、分散、自己相関が時間とともに変化しない変数(定常変数)のみが有効です。この性質は、複数の銘柄にわたって確認することができます。
転移学習を活用する場合、独立変数として市場から抽出するすべての特徴量(インジケーターやパターン)は、定数または定常である必要があります。
たとえば、どの銘柄でもRSIインジケーターの値は0〜100の範囲に収まります。これはパターンを捉える上で非常に重要です。
特徴量エンジニアリング
定常変数を得るためにはさまざまな手法がありますが、ここではいくつかの方法に絞ってデータを加工します。具体的には、終値のパーセンテージ変化の計算、各OHLC値の差分、そして定常性を持つインジケーターの利用です。
(a):終値のパーセンテージ変化
res_df["pct_change"] = df["Close"].pct_change()
銘柄ごとに価格の桁が異なっても、パーセンテージ変化は常に定常的な値として表されます。これにより、パターン検出に適した汎用的な特徴量となります。
(b):各OHLC値の差
res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff()
diff()メソッドは、現在の要素と直前の要素との差分を計算します(デフォルトでは1つ前)。この特徴量を用いることで、各銘柄において前のバーと比較した価格変動を捉えることができ、パターン検出に役立ちます。
(c):定常性を持つインジケーター
定常的な結果を示すモメンタム系やオシレーター系のインジケーターを追加することができます。
インジケーター | 値の範囲 |
|---|---|
# Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() | 0~100 |
# Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() | 0~100 |
# Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() | 小さな正と負の値(通常は-0.1~+0.1) |
# Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() | 通常は-300~+300 |
# Rate of Change (ROC) res_df['roc'] = ta.momentum.ROCIndicator(df["Close"], window=12).roc() | 無制限、負または正のいずれか |
# Ultimate Oscillator (UO) res_df['uo'] = ta.momentum.UltimateOscillator(df['High'], df['Low'], df['Close'], window1=7, window2=14, window3=28).ultimate_oscillator() | 0~100 |
# Williams %R res_df['williams_r'] = ta.momentum.WilliamsRIndicator(df['High'], df['Low'], df['Close']).williams_r() | -100~0 |
# Average True Range (ATR) res_df['atr'] = ta.volatility.AverageTrueRange(df['High'], df['Low'], df['Close'], window=14).average_true_range() | 制限のない小さな正の値 |
# Awesome Oscillator (AO) res_df['ao'] = ta.momentum.AwesomeOscillatorIndicator(df['High'], df['Low']).awesome_oscillator() | 制限のない小さな値(通常は-0.1~+0.1) |
# Average Directional Index (ADX) res_df['adx'] = ta.trend.ADXIndicator(df['High'], df['Low'], df['Close'], window=14).adx() | 0~100 |
# True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() | 通常は-100~+100 |
ここで紹介したのは一部の定常変数にすぎません。必要に応じて、自由に他の特徴量を追加してください。
これらの手法や処理は、すべて独立した関数としてまとめて実装することが可能です。
def getStationaryVars(df: pd.DataFrame) -> pd.DataFrame: res_df = pd.DataFrame() res_df["pct_change"] = df["Close"].pct_change() res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff() # Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() # Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() # Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() # Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() # .... See the code in the notebook in the attachments and above # .... # .... # True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() return res_df
では、次にベースモデルを作成します。このモデルは、ある銘柄から別の銘柄へ知識を転移させるために使用されます。
転移学習の実装
転移学習は通常、深層モデル、特に畳み込みニューラルネットワーク(CNN)でおこなわれます。 これは、CNNがパターン検出に優れており、この能力によって学習したパターンを同じドメイン内の異なる対象に転移できるためです。
ここでは、CNNモデルを関数trainCNNにラップして実装します。
import tensorflow as tf from tensorflow.keras import layers, models, Model from tensorflow.keras.callbacks import EarlyStopping
def trainCNN(train_set: tuple, val_set: tuple, learning_rate: float=1e-3, epochs: int=100, batch_size: int=32): X_train, y_train = train_set X_val, y_val = val_set input_shape = X_train.shape[1:] num_classes = len(np.unique(y_train)) model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(32, activation='tanh'), layers.Dense(num_classes, activation='softmax') ]) # Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'] ) # Early stopping callback early_stop = EarlyStopping( monitor='val_loss', # Watch validation loss patience=10, # Stop if no improvement restore_best_weights=True ) # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], verbose=1 ) # Save trained weights model.save_weights('cnn_pretrained.weights.h5') return model
このシーケンシャルモデルには、入力シーケンスから特徴量を抽出するための2つの1次元畳み込み(Convolutional 1D)層が含まれています。
グローバルアベレージプーリング層は、シーケンスを圧縮して全結合層(FNN層、活性化関数はtanh)に入力できるようにしています。
最後の層はsoftmax活性化関数を用いており、各クラスに対する予測確率を返します。
学習済みモデルの重みは保存します。これらの重みはデータから学習したすべてのパターンを表しており、次のモデルに引き継ぐことが可能です。
ここでは、EURUSDの4時間足データを使用し、元のデータフレームからOHLC値を収集します。
lookahead = 1 trained_symbol = symbols[0] timeframe = "PERIOD_H4" df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{trained_symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead)
再度、getXandY関数を使用して、終値(Close)を基に目的変数を作成します。このとき、将来を見る期間(lookahead)はここでは1に設定します。
def getXandY(df: pd.DataFrame, lookahead: int) -> tuple: # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # if next bar closed above the current one, thats a bullish signal otherwise bearish # Splitting data into X and y X = df.drop(columns=[ "Close", "future_close", "Signal" ]) y = df["Signal"] return (X, y)
データを学習用と検証(テスト)用のセットに分割し、その後、選択したスケーラー(この場合はRobust Scaler)を用いて結果を標準化する必要があります。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
畳み込みニューラルネットワーク(CNN)は3次元の入力データを必要とするため、このデータを特定のウィンドウ内に処理し、その範囲における時間的パターンの検出をおこなうことができます。
def create_sequences(X, Y, time_step): if len(X) != len(Y): raise ValueError("X and y must have the same length") X = np.array(X) Y = np.array(Y) Xs, Ys = [], [] for i in range(X.shape[0] - time_step): Xs.append(X[i:(i + time_step), :]) # Include all features with slicing Ys.append(Y[i + time_step]) return np.array(Xs), np.array(Ys)
# Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window)
One-hotエンコーディングは、ニューラルネットワークが関係するあらゆる分類問題における目的変数にとって非常に重要であり、クラスを区別するのに役立ちます。
# One-hot encode the labels for multi-class classification
y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes)
y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes)
最後に、ベースモデルを学習させます。
base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) print("Test acc: ", base_model.evaluate(X_test_seq, y_test_encoded)[1])
以下が出力です。
Epoch 1/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 4s 4ms/step - accuracy: 0.4994 - loss: 0.6990 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 2/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4976 - loss: 0.6939 - val_accuracy: 0.5023 - val_loss: 0.6936 Epoch 3/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4977 - loss: 0.6940 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 4/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5034 - loss: 0.6937 - val_accuracy: 0.4977 - val_loss: 0.6962 ... ... Epoch 16/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5039 - loss: 0.6934 - val_accuracy: 0.5023 - val_loss: 0.6932 Epoch 17/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4988 - loss: 0.6940 - val_accuracy: 0.4977 - val_loss: 0.6937 Epoch 18/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5013 - loss: 0.6943 - val_accuracy: 0.5023 - val_loss: 0.6931 266/266 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.5037 - loss: 0.6931 Test acc: 0.5022971034049988
EURUSDでベースモデルを学習させ、全体の正解率は0.502を達成しました。
次に、このモデルを活用して他の通貨ペアや異なる銘柄で学習したモデルに知識を転移、共有し、その結果を確認してみましょう。
for symbol in symbols: if symbol == trained_symbol: # skip transfer learning on the trained symbol continue print(f"Symbol: {symbol}") df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # we add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window) # One-hot encode the labels for multi-class classification y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes) y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes) # Freeze all layers except the last one for layer in base_model.layers[:-1]: layer.trainable = False # Create new model using the base model's architecture model = models.clone_model(base_model) model.set_weights(base_model.get_weights()) # Recompile with lower learning rate model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy']) early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) print("Test acc:", model.evaluate(X_test_seq, y_test_encoded)[1])
データ分割、時系列データの生成、目的変数のエンコードといった処理は同様に繰り返されます。ただし、各銘柄ごとに処理が指定されます。
ベースモデルから知識を転移するために、そのベースモデルに基づいて新しいモデルを構築します。ここで重要なのは、CNNの一部の層を凍結することです。
CNNモデルでは最後の層を除くすべての層を凍結します。これは、ベースデータから学習したパターンを保持するためです。層を凍結することで、新しいデータで再学習する際に有用な特徴量が失われるのを防ぐことができます。
最終層を凍結しないのは、各銘柄に応じて新しい決定境界に重みを再調整させたいからです。つまり、目的変数に新しい分布を与えることで、モデルがベースモデルから学習したパターンと新しいデータ上の目的変数との関係を見いだせるようにします。
さらに、ベースモデルのアーキテクチャを現在のモデルに複製し、その重みを新しいモデルに割り当てます。重みはtrainCNN関数内で保存しているため、外部からモデルをインポートする際にはファイルから読み込むこともでき、ベースモデルが同じPythonスクリプトやファイル内に存在する場合には、モデルオブジェクトから直接重みを読み込むことも可能です。
最後に、ベースモデルを学習させた際に使用した銘柄とは異なる金融商品の市場データを用いてモデルをコンパイルします。その他のパラメータも適宜変更することが可能です。
以下に、異なる為替銘柄において達成された正解率を示します。
| 銘柄 | GBPUSD | AUDUSD | USDCAD | USDJPY | USDCHF | NZDUSD | EURNZD | AUDNZD | GBPNZD | NZDCHF | NZDJPY | NZDCAD | XAUUSD | XAUJPY | XAUEUR | XAUGBP |
| 精度 | 0.505 | 0.506 | 0.501 | 0.516 | 0.506 | 0.497 | 0.505 | 0.502 | 0.504 | 0.505 | 0.51 | 0.505 | 0.506 | 0.514 | 0.507 | 0.504 |
この結果だけでは十分な情報が得られないため、分類レポートを取り入れて詳細に分析してみましょう。
preds = base_model.predict(X_test_seq) pred_indices = preds.argmax(axis=1) pred_class_labels = [classes_in_y[i] for i in pred_indices] print("Classification report\n", classification_report(pred_class_labels, y_test_seq))
以下は、ベースモデルの分類レポートです。
Classification report precision recall f1-score support 0 1.00 0.50 0.66 8477 1 0.00 0.00 0.00 0 accuracy 0.50 8477 macro avg 0.50 0.25 0.33 8477 weighted avg 1.00 0.50 0.66 8477
この結果は非常に良くありません。モデルによって強く偏った分類レポートが生成されました。
これは、モデルまたはデータに起因するバイアスが存在していることを示しています。
以前の記事で議論したように、このバイアスの問題に対処する方法はいくつかありますが、ここでは次のことをおこなってみましょう。
(a):データにクラス不均衡が存在する場合、それを是正するためにクラスの重みを追加します。
from sklearn.utils.class_weight import compute_class_weight
def trainCNN: #.... #.... y_train_integers = np.argmax(y_train, axis=1) # return to non-one hot encoded class_weights = compute_class_weight('balanced', classes=np.unique(y_train_integers), y=y_train_integers) class_weight_dict = {i: weight for i, weight in enumerate(class_weights)} # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], class_weight=class_weight_dict, verbose=1 )
(b):より複雑なパターンを捉えられるように、畳み込み層をもう1層追加し、全結合層のニューロン数を増やします。
def trainCNN: # ... # ... model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(32, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(128, activation='relu'), layers.Dense(num_classes, activation='softmax') ])
(c):これは二値分類問題であるため、目的変数には2つのクラスしか存在しません。0は売りシグナル、1は買いシグナルを表します。したがって、損失関数をbinary_crossentropyに、評価指標をbinary_accuracyに変更します。
# Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='binary_crossentropy', metrics=['binary_accuracy'] )
CNNモデルを再学習させたところ、値は大幅に改善されました。
.... .... 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5257 - loss: 0.6920 - val_binary_accuracy: 0.5043 - val_loss: 0.6933 Epoch 7/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5259 - loss: 0.6918 - val_binary_accuracy: 0.5027 - val_loss: 0.6934 Epoch 8/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5283 - loss: 0.6915 - val_binary_accuracy: 0.5042 - val_loss: 0.6936 Epoch 9/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5284 - loss: 0.6912 - val_binary_accuracy: 0.5028 - val_loss: 0.6937 Epoch 10/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5315 - loss: 0.6909 - val_binary_accuracy: 0.5036 - val_loss: 0.6938 Epoch 11/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5295 - loss: 0.6907 - val_binary_accuracy: 0.5042 - val_loss: 0.6940 Epoch 12/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5298 - loss: 0.6904 - val_binary_accuracy: 0.5074 - val_loss: 0.6941 619/619 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5101 - loss: 0.6926 265/265 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - binary_accuracy: 0.5018 - loss: 0.6933 Train acc: 0.5114434361457825 Test acc: 0.5050135850906372 265/265 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step Classification report precision recall f1-score support 0 0.58 0.50 0.54 4870 1 0.43 0.51 0.47 3607 accuracy 0.51 8477 macro avg 0.51 0.51 0.50 8477 weighted avg 0.52 0.51 0.51 8477
修正したパラメータには特に明確な理由はありません。単に、他のニューラルネットワークベースのモデルと同様に、最適化やパラメータ調整が非常に重要であることを示したかったのです。
現時点での結果が最適解であるとは限りません。CNNやニューラルネットワーク全般についてはまだ多く議論できる余地があります。
当面は現在のパラメータで進めますが、必要に応じてこれらの値を調整して、自分の目的に合ったモデルを作成してください。
偏りの少ないベースモデルができたので、これを使って他の金融商品に知識を転移させ、これらのモデルをすべてONNX形式で保存します。これにより、実際の取引環境で転移学習による結果を観察することが可能になります。
自動売買ロボット(EA)における転移学習
MetaTrader 5上で転移学習をテストするには、まずモデルをONNX形式で保存し、その後MQL5プログラミング言語を用いて読み込む必要があります。
以下がImportです。
import onnxmltools import tf2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
以下が関数です。
def saveCNN(model, window: int, features: int, filename: str): model.output_names = ["output"] # Specifying the input signature for the model spec = (tf.TensorSpec((None, window, features), tf.float16, name="input"),) # Convert the Keras model to ONNX format onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=14) # Save the ONNX model to a file with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Kerasモデルには、Scikit-learnモデルのように全ての前処理手順をラップして一括で保存できるパイプライン機能がサポートされていないため、モデルと前処理で使用したスケーラーをそれぞれ独立したONNXファイルとして保存する必要があります。
def saveScaler(scaler, features: int, filename: str): # Convert to ONNX format initial_type = [("input", FloatTensorType([None, features]))] onnx_model = convert_sklearn(scaler, initial_types=initial_type, target_opset=14) with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
これで、ベースモデルおよびそれ以前のモデルを保存する際に、これらの関数を呼び出すことができます。
ベースモデルを保存します。
# .... # .... base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) saveCNN(model=base_model, window=window, features=X_train_seq.shape[2], filename=f"{trained_symbol}.basemodel.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{trained_symbol}.{timeframe}.scaler.onnx")
転移学習で学習したモデルを保存します。
for symbol in symbols: # ... # ... history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) saveCNN(model=model, window=window, features=X_train_seq.shape[2], filename=f"basesymbol={trained_symbol}.symbol={symbol}.model.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{symbol}.{timeframe}.scaler.onnx")
ファイルを共通フォルダに保存した後、同様の命名方法でEA内に読み込むことができます。
#include <ta.mqh> //similar to ta in Python --> https://www.mql5.com/en/articles/16931 #include <pandas.mqh> //similar to Pandas in Python --> https://www.mql5.com/en/articles/17030 #include <CNN.mqh> //For loading Convolutional Neural networks in ONNX format --> https://www.mql5.com/en/articles/15259 #include <preprocessing.mqh> //For loading the scaler transformer #include <Trade\Trade.mqh> //The trading module #include <Trade\PositionInfo.mqh> //Position handling module CCNNClassifier cnn; RobustScaler scaler; CTrade m_trade; CPositionInfo m_position; input string base_symbol = "EURUSD"; input string symbol_ = "USDJPY"; input ENUM_TIMEFRAMES timeframe = PERIOD_H4; input uint window_ = 10; input uint lookahead = 1; input uint magic_number = 28042025; input uint slippage = 100; long classes_in_y_[] = {0, 1}; int OldNumBars = -1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!MQLInfoInteger(MQL_TESTER)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s Failed to set symbol_ = %s and timeframe = %s, Error = %d",__FUNCTION__,symbol_,EnumToString(timeframe), GetLastError()); return INIT_FAILED; } //--- string filename = StringFormat("basesymbol=%s.symbol=%s.model.%s.onnx",base_symbol, symbol_, EnumToString(timeframe)); if (!cnn.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a CNN model in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } //--- filename = StringFormat("%s.%s.scaler.onnx", symbol_, EnumToString(timeframe)); if (!scaler.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a scaler in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } }
この記事で説明したように、PythonのTA(テクニカル分析)モジュールに相当する機能がMQL5にも存在します。これにより、インジケーター関数を呼び出して、その結果をPythonのPandasのようなデータフレームに格納することができます。
CDataFrame getStationaryVars(uint start = 1, uint bars = 50) { CDataFrame df; //Dataframe object vector open, high, low, close; open.CopyRates(Symbol(), Period(), COPY_RATES_OPEN, start, bars); high.CopyRates(Symbol(), Period(), COPY_RATES_HIGH, start, bars); low.CopyRates(Symbol(), Period(), COPY_RATES_LOW, start, bars); close.CopyRates(Symbol(), Period(), COPY_RATES_CLOSE, start, bars); vector pct_change = df.pct_change(close); vector diff_open = df.diff(open); vector diff_high = df.diff(high); vector diff_low = df.diff(low); vector diff_close = df.diff(close); df.insert("pct_change", pct_change); df.insert("diff_open", open); df.insert("diff_high", high); df.insert("diff_low", low); df.insert("diff_close", close); // Relative Strength Index (RSI) vector rsi = CMomentumIndicators::RSIIndicator(close); df.insert("rsi", rsi); // Stochastic Oscillator (Stoch) vector stock_k = CMomentumIndicators::StochasticOscillator(close,high,low).stoch; df.insert("stock_k", stock_k); // Moving Average Convergence Divergence (MACD) vector macd = COscillatorIndicators::MACDIndicator(close).main; df.insert("macd", macd); // Commodity Channel Index (CCI) vector cci = COscillatorIndicators::CCIIndicator(high,low,close); df.insert("cci", cci); // Rate of Change (ROC) vector roc = CMomentumIndicators::ROCIndicator(close); df.insert("roc", roc); // Ultimate Oscillator (UO) vector uo = CMomentumIndicators::UltimateOscillator(high,low,close); df.insert("uo", uo); // Williams %R vector williams_r = CMomentumIndicators::WilliamsR(high,low,close); df.insert("williams_r", williams_r); // Average True Range (ATR) vector atr = COscillatorIndicators::ATRIndicator(high,low,close); df.insert("atr", atr); // Awesome Oscillator (AO) vector ao = CMomentumIndicators::AwesomeOscillator(high,low); df.insert("ao", ao); // Average Directional Index (ADX) vector adx = COscillatorIndicators::ADXIndicator(high,low,close).adx; df.insert("adx", adx); // True Strength Index (TSI) vector tsi = CMomentumIndicators::TSIIndicator(close); df.insert("tsi", tsi); if (MQLInfoInteger(MQL_DEBUG)) df.head(); df = df.dropna(); //Drop not-a-number variables return df; //return the last rows = window from a dataframe which is the recent information fromthe market }
各バーごとに、直近でクローズしたバー(インデックス1)から過去50本のバーを収集し、インジケーターの計算に使用します。
50本のバーを使用する主な理由は、インジケーター計算に伴うNaN値を回避するために十分なデータ量を確保することです。
中でもAwesome Oscillatorインジケーターは過去のデータを最も参照し、そのwindow2値は34です。したがって、50 − 34 = 16がモデルに利用可能なデータ数となります。
この関数をデバッグモードで実行すると、MetaTrader 5の[エキスパート]タブでデータの概要を確認することができます。
MD 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | Index | pct_change | diff_open | diff_high | diff_low | diff_close | rsi | stock_k | macd | cci | roc | uo | williams_r | atr | ao | adx | tsi | FF 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | 0 | nan | 142.67000000 | 143.08800000 | 142.49100000 | 142.68300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | JO 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 1 | -0.25300842 | 142.68400000 | 142.84900000 | 142.28700000 | 142.32200000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 2 | 0.09977375 | 142.32300000 | 142.63500000 | 141.89900000 | 142.46400000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | HF 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 3 | -0.00070193 | 142.46400000 | 142.71900000 | 142.34400000 | 142.46300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | GJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 4 | -0.04702976 | 142.37400000 | 142.47200000 | 142.18600000 | 142.39600000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | ... | NR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 45 | -0.22551954 | 142.33800000 | 142.38800000 | 141.98200000 | 142.01700000 | 28.79606321 | 1.70731707 | 0.20202343 | -149.46898289 | -0.42629273 | 28.03714657 | -48.58934169 | 0.58185714 | 0.84359706 | 29.65580624 | 8.31951160 | NJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 46 | 0.16054416 | 141.97800000 | 142.31600000 | 141.96400000 | 142.24500000 | 35.49705652 | 13.58800774 | 0.12993025 | -131.96513868 | -0.57316604 | 34.81743660 | -43.09139137 | 0.56978571 | 0.51217941 | 28.18573720 | 4.78996901 | HQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 47 | 0.19543745 | 142.24500000 | 142.58100000 | 142.12400000 | 142.52300000 | 43.03880625 | 27.03094778 | 0.09414295 | -86.63856716 | -0.76174826 | 43.61239023 | -36.38775018 | 0.57742857 | 0.21773529 | 26.19967843 | 3.09202782 | FH 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 48 | 0.04771160 | 142.52300000 | 142.61500000 | 142.29800000 | 142.59100000 | 44.85843867 | 30.31914894 | 0.07045611 | -66.64608781 | -0.57732936 | 49.55462139 | -34.74801061 | 0.56007143 | -0.01222353 | 24.37916904 | 2.01861384 | MQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 49 | -0.19776844 | 142.59100000 | 142.75800000 | 142.25100000 | 142.30900000 | 38.91058297 | 16.68278530 | 0.02859940 | -70.14493704 | -0.77257229 | 41.99481159 | -41.54810707 | 0.52700000 | -0.13378529 | 23.02215655 | 0.05188403 |
OnTick関数内では、まずこれらの固定変数を取得し、その後にスライス操作をおこないます。このスライス操作は、CNNモデルを学習させた際に使用した必要なウィンドウ内にデータや受け取ったバーの本数を収めることを目的としています。
void OnTick() { //--- if (!isNewBar()) return; CDataFrame x_df = getStationaryVars(); //--- Check if the number of rows received after indicator calculation is >= window size if ((uint)x_df.shape()[0]<window_) { printf("%s Fatal, Data received is less than the desired window=%u. Check your indicators or increase the number of bars in the function getSationaryVars()",__FUNCTION__,window_); DebugBreak(); return; } ulong rows = (ulong)x_df.shape()[0]; ulong cols = (ulong)x_df.shape()[1]; //printf("Before scaled shape = (%I64u, %I64u)",rows, cols); matrix x = x_df.iloc((rows-window_), rows-1, 0, cols-1).m_values; }
学習時に使用したウィンドウ値に対応する10行と16個の特徴量のスライス済み行列が用意できたので、このデータをCNNモデルで最終予測をおこなう前に、まず読み込んだRobustScalerに渡します。
matrix x_scaled = scaler.transform(x); //Transform the data, very important long signal = cnn.predict(x_scaled, classes_in_y_).cls; //Predicted class
最後に、モデルから得られたシグナルを用いて、簡単な取引戦略を実行できます。モデルからのシグナルが1(強気シグナル)の場合は買いポジションを開き、シグナルが0(弱気シグナル)の場合は売りポジションを開きます。
各取引は、現在の時間足でlookahead値に対応するバー数が経過した後に決済されます。
//--- Trading functionality MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe
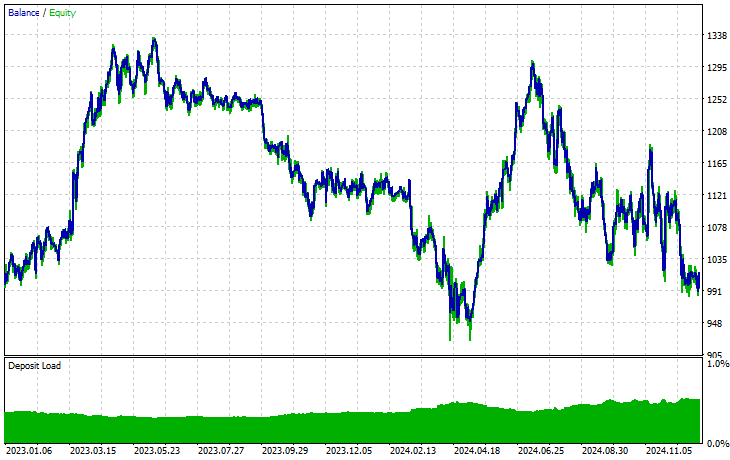
以上です。転移学習の過程で使用した複数の銘柄でこの自動売買ロボットを実行し、2023年1月1日から2025年1月1日までの予測結果を観察してみましょう。
時間足:PERIOD_H4、モデリング:1分間OHLC
銘柄:XAUEUR
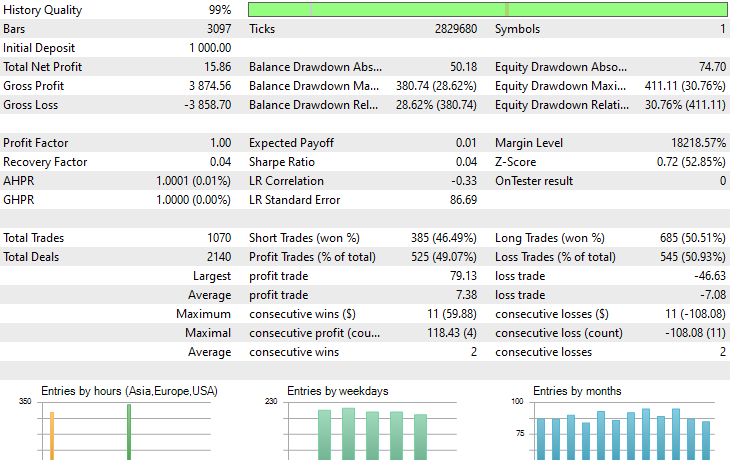
銘柄:XAUUSD
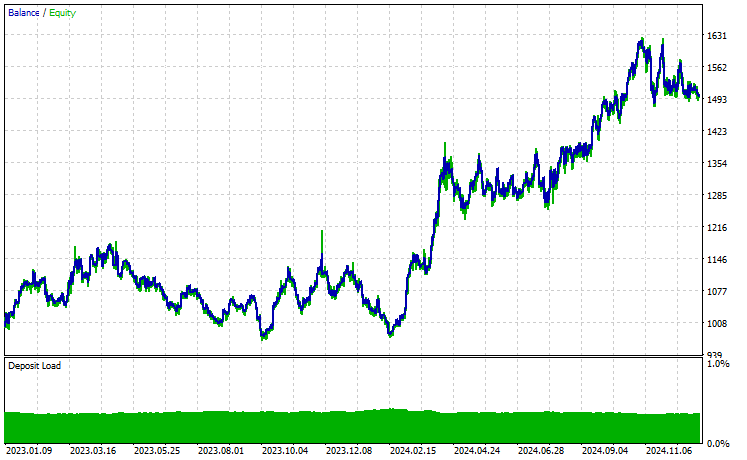
EURUSDをベースに学習したモデルを使って転移学習をおこなった17銘柄のうち、有望な結果を示したのは2銘柄だけで、残りはまったく使い物になりませんでした。
これは2つのことを意味する可能性があります。1つ目は、EURUSDで観測されたパターンがXAUUSDとXAUEURで見られるパターンと強く関連している、あるいは類似しているということです。これは理にかなっています。なぜなら、この2つの銘柄はどちらもEURとUSDを含んでおり、ベース銘柄EURUSDを構成しているからです。
2つ目は、CNNモデルが最適化されておらず、モデルのアーキテクチャやパラメータの最適な組み合わせを見つけるよう調整していない可能性があるということです。さらに、異なるベース銘柄を試して他の銘柄での結果を観察することもしていません。
いくつかの対応策を講じることは可能ですが、それは本記事の範囲を超えます。その部分は皆さんにお任せします。
最後に
私たちは現在、人工知能(AI)と機械学習の黄金時代にいます。この技術は予想以上の速度で進化しており、オープンソースのおかげで、数行のコードで既存のモデル上に優れたモデルを構築することが可能になっています。これがまさに、私たちが「転移学習」と呼ぶものです。
ResNet50やMobileNetのようなコンピュータビジョンや画像関連タスク向けの大規模オープンソースモデルが存在することで、開発者は最先端のAIソリューションを手軽に利用できるようになっています。しかし、金融分野におけるオープンソース活用はまだ十分に探索されていません。
本記事では、金融分野における転移学習の可能性に目を向けてもらうことを目的としました。これは、さまざまな金融商品の共通パターンを活用して市場を理解するための大規模モデル構築への出発点となるものです。
ご成功をお祈りしています。
添付ファイルの表
ファイル名 | 説明/用途 |
|---|---|
| Expert\Transfer Learning EA.mq5 | 取引環境で転移学習モデルをテストするためのメインEA |
| Include\CNN.mqh | MQL5でCNNモデルを.ONNXファイルで読み込み、展開するためのライブラリ |
Include\pandas.mqh | データ操作と保存のためのPython風Pandasライブラリ |
Include\preprocessing.mqh | .onnx形式で保存されたデータ変換・スケーリング技術を読み込むためのクラス |
Include\ta.mqh | MQL5上でインジケーターを簡単に利用できるプラグアンドプレイ型ライブラリ |
Scripts\CollectData.mqh | 複数銘柄のOHLCデータを収集し、CSVファイルに保存するスクリプト |
| Python\forex-transfer-learning.ipynb | 本記事で説明されているすべてのPythonコードを実行するためのPythonスクリプト(Jupyter Notebook) |
Common\Files\*scaler.onnx | データ前処理用スケーラーをONNX形式で保存したファイル |
Common\Files\*.onnx | CNNモデルをONNX形式で保存したファイル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/17886
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索