
Нейросети в трейдинге: Единый взгляд на пространство и время (Global-Local Attention)

Введение
Финансовые рынки — это сложная и динамичная система, где пространство и время тесно переплетены. Каждое движение котировки отражает не только мгновенный баланс спроса и предложения, но и следы предшествующих событий, а также влияние соседних инструментов, секторов и даже целых экономик. Прогнозировать поведение такой системы традиционными методами всегда было задачей высокой сложности. Статистические модели и классические нейросети неплохо справлялись с краткосрочными прогнозами, но теряли устойчивость и точность при попытке выйти за рамки нескольких часов. Главная проблема заключалась в том, что временные и пространственные факторы рассматривались раздельно. А попытки их объединения приводили к лавинообразному росту вычислительных затрат.
Фреймворк Extralonger, знакомство с которым мы начали в предыдущей статье, предложил принципиально иной подход. Его авторы исходили из идеи, что пространство и время должны рассматриваться как единое целое. Эта философия, перекликающаяся с теорией относительности Эйнштейна, воплотилась в Unified Spatial-Temporal Representation — представлении, где временные ряды и пространственные связи интегрируются без искусственного разделения. Такое решение позволило резко снизить вычислительную сложность. Там, где раньше операции росли экспоненциально, Extralonger упростил их до квадратичных зависимостей. Практический эффект оказался впечатляющим. Ускорение обучения в сотни раз, многократное снижение потребления памяти и, самое главное, возможность строить прогнозы длительностью не в часы, а в целые дни и даже недели.
Для финансовых рынков это открывает новые перспективы. Там, где трейдеры и аналитики традиционно ограничивались краткосрочными оценками, появляется возможность заглянуть вперёд на несколько торговых сессий, или спрогнозировать движение рынков вокруг публикаций макроэкономических данных и решений центральных банков. Extralonger превращает недельный прогноз из недосягаемой мечты в инструмент, который можно использовать на практике.
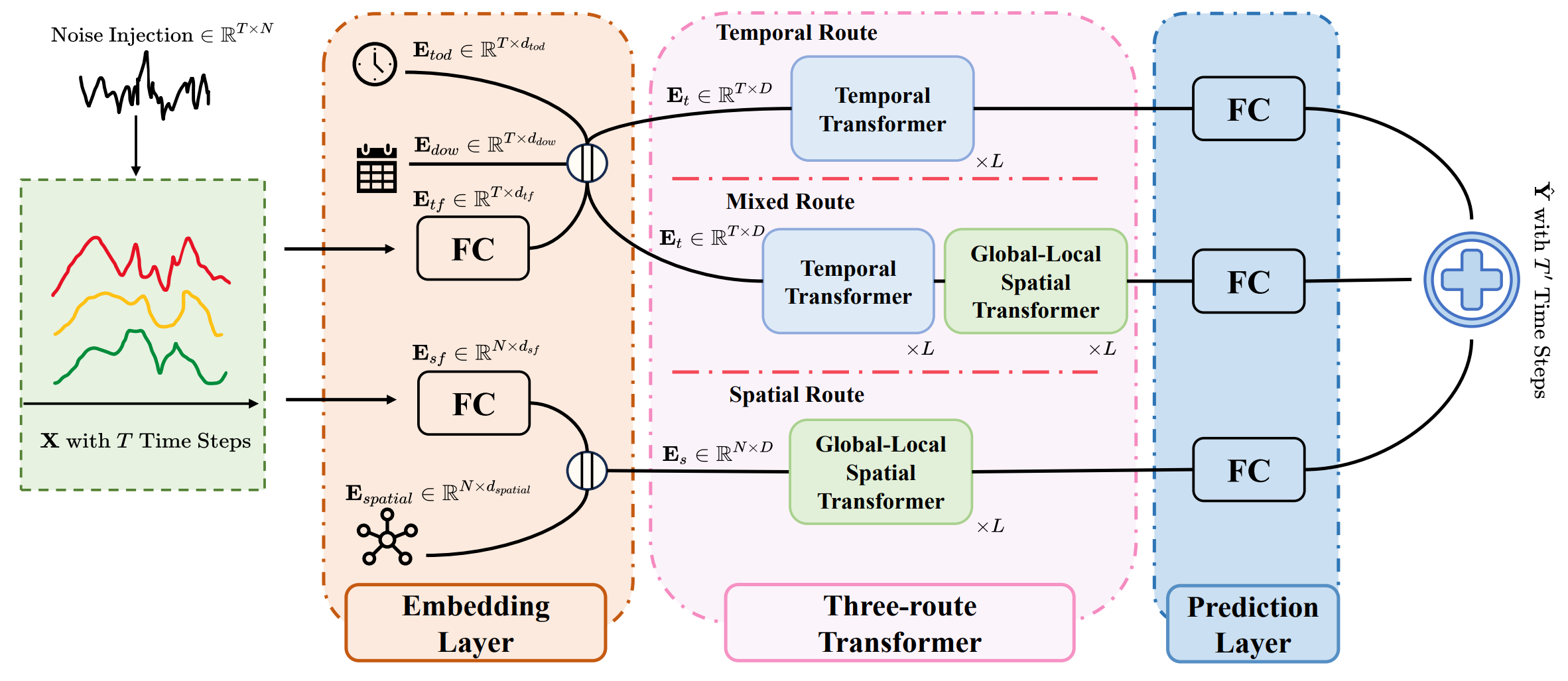
Однако истинная сила фреймворка раскрывается через его архитектуру. В её основе лежит трёхмаршрутный Transformer, каждый маршрут которого отвечает за определённый аспект анализа.
Временной маршрут можно сравнить с макроэкономическим аналитиком. Он изучает ритмы рынка, выявляет циклы роста и спада, улавливает сезонность и повторяющиеся паттерны. Используя механизм Self-Attention, модель связывает удалённые отрезки временного ряда. Текущее движение валютной пары может оказаться продолжением тенденции, начавшейся месяц назад.
Пространственный маршрут выполняет роль специалиста по межрыночным связям. На финансовых рынках ни один актив не существует в изоляции. Динамика золота отражается на фондовых индексах. Курс доллара влияет на сырьевые рынки. А доходности облигаций задают тон акциям. Extralonger учитывает это через Global-Local Spatial Transformer, который объединяет два взгляда: глобальный — где каждая бумага связана со всеми остальными, и локальный — где акцент делается на кластеры активов, объединённых отраслью или регионом.
Смешанный маршрут ближе всего к роли портфельного управляющего. Его задача — соединить временную динамику и пространственные взаимосвязи в единую картину. Благодаря этому, модель воспринимает рынок целостно. Рост волатильности в секторе технологий, сопровождающийся изменением цен на нефть и колебаниями процентных ставок, для неё не набор случайных фактов, а сигнал о формировании крупного рыночного сценария.
Финальный прогноз рождается в точке пересечения трёх маршрутов. Подобно инвестиционному комитету, где каждый эксперт вносит свой вклад, Extralonger объединяет выводы всех участников во взвешенное решение. В результате модель получает не только локальную глубину анализа и охват глобальных связей, но и целостное восприятие рыночных процессов во времени.
Такое построение делает фреймворк особенно ценным для финансовых приложений. Он сочетает глубину анализа временных рядов, широту охвата межрыночных связей и целостность восприятия. Благодаря этому, Extralonger способен строить устойчивые прогнозы там, где другие модели либо теряют точность, либо требуют чрезмерных ресурсов.
Авторская визуализация фреймворка Extralonger представлена ниже.
В практической части предыдущей статьи мы сделали первые шаги по реализации предложенных подходов средствами MQL5. Был разработан модуль пространственного кодирования, обеспечивающий работу с взаимосвязями между инструментами, а также представлены отдельные блоки OpenCL-программы для временного кодирования. Эти наработки стали фундаментом, на котором мы можем строить полноценную инженерную версию фреймворка.
Сегодня мы продолжаем эту работу, двигаясь дальше в сторону практического воплощения идей Extralonger. Наша цель — шаг за шагом перенести предложенную авторами архитектуру в среду MQL5, обеспечив её жизнеспособность в условиях реальных финансовых данных.
Временной эмбеддинг
Продолжаем работу по построению алгоритмов фреймворка Extralonger средствами MQL5. В предыдущей статье мы подробно рассмотрели кернелы OpenCL-программы, которые добавляют временные эмбеддинги к исходным данным. Теперь мы переходим к организации этого процесса на стороне основной программы. Для этого создаём новый объект CNeuronTempEmbedding, наследующий базовый функционал от класса CNeuronBaseOCL.
class CNeuronTempEmbedding : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint aiEmbeddingDim[2]; uint aiFrames[2]; uint aiPeriod[2]; CParams caEmbeddings[2]; //--- virtual bool ConcatByLabel(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool ConcatByLabelGrad(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override {return false;} virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false;} virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None ) override; public: CNeuronTempEmbedding(void) {}; ~CNeuronTempEmbedding(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint embed_dim1, uint period1, uint frame1, uint embed_dim2, uint period2, uint frame2, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTempEmbedding; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
Основные параметры объекта включают количество анализируемых признаков iWindow, длину последовательности iUnits, размеры встраивания aiEmbeddingDim, размер одного шага iFrames и периоды повторения aiPeriod. Всё это задаётся через массивы, что делает объект гибким и настраиваемым под разные временные масштабы финансовых данных.
Архитектура объекта формируется в методе Init, который отвечает за инициализацию всех ключевых параметров слоя временного кодирования и его внутренних компонентов.
bool CNeuronTempEmbedding::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint embed_dim1, uint period1, uint frame1, uint embed_dim2, uint period2, uint frame2, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, (window + embed_dim1 + embed_dim2)*units, optimization_type, batch)) return false;
На первом шаге вызывается инициализация родительского класса CNeuronBaseOCL. Здесь задаются основные характеристики слоя и инициализируются унаследованные интерфейсы. Если базовая инициализация не проходит, функция возвращает false, предотвращая дальнейшее создание некорректного объекта.
Затем инициализируются два компонента caEmbeddings, которые формируют временные встраивания данных. Каждый embedding создаётся с учётом своей размерности (embed_dim1 и embed_dim2) и периода повторения (period1 и period2). Это позволяет модели захватывать временные закономерности с разными масштабами и глубиной анализа, что особенно важно при работе с динамикой финансовых рынков.
if(!caEmbeddings[0].Init(0, 0, OpenCL, embed_dim1 * period1, optimization, iBatch)) return false; if(!caEmbeddings[1].Init(0, 1, OpenCL, embed_dim2 * period2, optimization, iBatch)) return false;
После успешной инициализации embedding-компонентов, сохраняются параметры объекта во внутренние переменные. Эти параметры определяют структуру временного слоя и управляют тем, как нейрон видит рынок во времени.
iWindow = window; iUnits = units; aiEmbeddingDim[0] = embed_dim1; aiEmbeddingDim[1] = embed_dim2; aiFrames[0] = MathMax(1, frame1); aiFrames[1] = MathMax(1, frame2); aiPeriod[0] = period1; aiPeriod[1] = period2; //--- return true; }
В конце метод возвращает true, подтверждая успешное создание полностью готового к работе объекта.
Метод feedForward реализует прямое распространение сигнала через слой. Сначала проверяется, находится ли объект в режиме обучения (bTrain==true). Если да, то для каждого компонента embedding выполняется его собственный прямой проход. Этот шаг позволяет сформировать тензор временных признаков для захвата закономерностей на разных временных масштабах. Если хотя бы один embedding не удаётся обработать, функция возвращает false, предотвращая дальнейшее распространение некорректных данных.
bool CNeuronTempEmbedding::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(bTrain) for(uint i = 0; i < caEmbeddings.Size(); i++) if(!caEmbeddings[i].FeedForward()) return false; //--- return ConcatByLabel(NeuronOCL, SecondInput); }
После успешного прямого прохода embedding-компонентов, происходит объединение данных с помощью метода ConcatByLabel, который является оберткой соответствующего кернела OpenCL-программы. Здесь временные признаки аккуратно интегрируются с исходными данными. В итоге объект формирует готовый к обработке сигнал, в котором сочетаются исторические данные и текущие рыночные наблюдения, обеспечивая точность и чувствительность модели к динамике финансового рынка.
Как можно заметить, метод прямого прохода реализован достаточно просто и линейно. Аналогично, методы обратного прохода и обновления градиентов не представляют сложностей и следуют логике стандартного обучения нейронных сетей, поэтому, для более глубокого понимания, их работу можно изучать самостоятельно. Полный исходный код класса CNeuronTempEmbedding и всех его методов представлен во вложении, что позволит подробно ознакомиться с реализацией и интеграцией этого объекта в вычислительную цепочку модели.
Объект внимания
После подготовки временных эмбеддингов и их интеграции с исходными данными, мы переходим к следующему этапу работы — реализации алгоритмов модуля Global-Local Spatial Attention. Прежде чем приступить к кодированию, важно обсудить предложенный авторами фреймворка подход.
Основная идея заключается в объединении глобального внимания, характерного для классического Self-Attention, с локальным фокусом, реализуемым через матрицу смежности. Такой подход напоминает методы графовой свёртки, с которыми мы уже сталкивались ранее, но в данном случае он адаптирован к пространственно-временной структуре данных.
Авторы статьи не предоставляют детальной информации о формировании матрицы смежности. Чтобы восполнить этот пробел, мы используем алгоритм Significant Neighbors Sampling из фреймворка SAGDFN. С его помощью создаётся разряженная матрица смежности, что позволяет существенно экономить вычислительные ресурсы и одновременно сохраняет способность модели учитывать значимые локальные зависимости. Следует отметить, что этот подход вносит особенности в реализацию процесса, поскольку работа с разреженной матрицей требует аккуратного обращения с индексами и вычислительными потоками.
Реализация на стороне OpenCL-контекста
При переносе алгоритмов в OpenCL-программу мы сталкиваемся с двумя серьёзными задачами, напрямую влияющими на скорость и точность анализа рыночных данных. Первая — последовательное выполнение Global- и Local-Attention, которое снижает общую производительность модели и тормозит обработку больших потоков исторических котировок. Вторая задача ещё более деликатная: как согласовать потоки полного Global-Attention с разреженной матрицей смежности, чтобы не потерять важную информацию о локальных связях между ценовыми уровнями. От качества этой настройки напрямую зависит, насколько модель сможет эффективно распознавать сложные рыночные паттерны.
Решение обеих задач оказалось на удивление прямым. В духе многоголового внимания мы распределили вычисления по отдельным потокам, позволяя модели одновременно анализировать разные аспекты рыночных данных. Конечно, это потребовало ветвления алгоритма в зависимости от конкретной головы внимания. Однако, такой подход позволил сохранить скорость и точность обработки больших исторических рядов, что критично для своевременного выявления рыночных паттернов.
После того как мы решили вопросы архитектуры выполнения Global- и Local-Attention в рамках параллельных потоков одного кернела, настало время перейти к практической реализации алгоритма прямого прохода. Его мы реализовали в кернеле GlobalLocalAttention. Каждая строка здесь — это шаг модели в анализе исторических данных и выявлении значимых сигналов.
__kernel void GlobalLocalAttention(__global const float *q, __global const float2* kv, __global float *scores, __global const float* mask, __global const float* label, __global float *out, const int dimension, const int total_kv, const int total_mask ) { //--- init const int q_id = get_global_id(0); const int local_id = get_local_id(1); const int h_id = get_global_id(2); const int total_q = get_global_size(0); const int total_local = get_local_size(1); const int total_heads = get_global_size(2); //--- __local float temp[LOCAL_ARRAY_SIZE];
Кернел получает все ключевые данные:
- векторы запросов q — наши текущие рыночные запросы,
- пары ключ-значение kv — исторические паттерны и их результаты,
- маску и метки для локальных ограничений,
- параметры для размеров пространства признаков и объёмов данных.
В теле кернела модель сначала определяет кто есть кто в трехмерном пространстве задач:
- q_id — это конкретный запрос;
- local_id — поток внутри группы, в зависимости от головы внимания указывает на пару ключ-запрос или позицию в разреженной матрице смежности:
- h_id — голова внимания, анализирующая конкретный аспект рынка.
Локальный массив служит временным буфером для промежуточных вычислений, как рабочий стол трейдера, где складываются все текущие результаты перед финальной оценкой.
Далее определяем смещение анализируемого запроса в памяти — это как найти нужный бар на графике, чтобы сопоставить его с историческими движениями.
int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, q_id);
И организуем ветвление алгоритма: чётные головы — это глобальный взгляд на рынок, где оцениваются ключевые закономерности на всём историческом массиве, а нечетные — локальный.
Для четных голов внимания мы вычисляем позиции ключей и соответствующих коэффициентов внимания. Это как отметить на графике все прошлые уровни поддержки и сопротивления для текущего запроса.
if(h_id % 2 == 0) { const int shift_kv = RCtoFlat(h_id, 0, total_heads, dimension, local_id); const int shift_s = RCtoFlat(h_id / 2, local_id, total_heads / 2, total_kv + total_mask, q_id); float score = 0; if(local_id < total_kv) { //--- for(int d = 0; d < dimension; d++) score += IsNaNOrInf(q[shift_q + d] * kv[shift_kv + d].s0, 0); } else score = MIN_VALUE; //--- norm score score = LocalSoftMax(score, 1, temp); if(local_id < total_kv) scores[shift_s] = score;
Считаем корреляцию текущего запроса с историческими данными. Если поток не участвует в расчёте — присваиваем минимальное значение, чтобы он не портил картину, как неактивные трейдеры на рынке. После чего, нормализуем вес каждого паттерна. Это как взвешивать важность сигналов — одни уровни цен влияют сильнее, другие почти не учитываются.
Финальная сборка выхода: умножаем исторические значения на их значимость и суммируем.
//--- out for(int d = 0; d < dimension; d++) { float val = (local_id < total_kv ? kv[shift_kv + d].s1 * score : 0); val = LocalSum(val, 1, temp); if(local_id == 0) out[shift_q + d] = val; } }
На выходе получаем сигнал для текущего запроса — готовый к анализу или использованию в торговой стратегии.
Вторая ветвь алгоритма обрабатывает локальные связи с соответствующей маской. Здесь мы фактически работаем с разряженной матрицей смежности, где многие элементы либо отсутствуют, либо неактуальны для текущего анализа.
Алгоритм начинается с проверки существования связи для текущего локального элемента. Локальна переменная kv_id указывает на реальный ключ, с которым нужно вычислить коэффициент внимания. Если kv_id меньше 0, значит в разреженной матрице нет соответствующего элемента, и поток пропускается. Маска m дополнительно фильтрует невалидные связи.
else { int kv_id = -1; float score = 0; int shift_kv = -1; float m = 0; if(local_id < total_mask) { const int shift_s = RCtoFlat(h_id / 2, total_kv + local_id, total_heads / 2, total_kv + total_mask, q_id); const int l = RCtoFlat(q_id, local_id, total_q, total_mask, 0); kv_id = IsNaNOrInf(label[l], -1); m = IsNaNOrInf(mask[l], 0); shift_kv = RCtoFlat(h_id, 0, total_heads, dimension, kv_id); if(kv_id >= 0) for(int d = 0; d < dimension; d++) score += IsNaNOrInf(q[shift_q + d] * kv[shift_kv + d].s0, 0); else score = MIN_VALUE; } else score = MIN_VALUE; //--- norm score score = LocalSoftMax(score * m, 1, temp); if(local_id < total_mask) scores[shift_s] = score;
Только существующие локальные связи участвуют в вычислении коэффициентов внимания, остальные получают минимальное значение. Это гарантирует, что разряженная структура не загрязняет результат, а модель фокусируется исключительно на релевантных локальных паттернах.
Нормализация через SoftMax учитывает маску, чтобы суммарная вероятность распределялась только по реальным локальным элементам.
И наконец, формируем выход для запроса с учётом только тех локальных паттернов, которые реально присутствуют в разряженной матрице.
//--- out for(int d = 0; d < dimension; d++) { float val = (kv_id >= 0 ? IsNaNOrInf(kv[shift_kv + d].s1, 0) * score : 0); val = LocalSum(val, 1, temp); if(local_id == 0) out[shift_q + d] = val; } } }
Использование разряженной матрицы делает невозможным простой универсальный алгоритм для всех голов внимания. Глобальная голова работает с плотной матрицей — все элементы присутствуют, вычисления прямолинейны. Локальная голова работает с разреженной структурой — многие связи отсутствуют, нужны проверки маски и меток, фильтрация NaN/Inf и отдельная логика суммирования. Поэтому внутри одного кернела пришлось реализовать два отдельных алгоритма, каждый оптимизирован под свой тип данных: один — для плотной глобальной матрицы, второй — для разряженной локальной.
После того как прямой проход был реализован, мы столкнулись с куда более хитрой задачей — распределением градиентов ошибки. Кернел GlobalLocalAttentionGrad здесь играет роль опытного трейдера, который одновременно следит за глобальной картиной и локальными паттернами. Каждый поток внутри кернела — это как отдельный аналитик, который получает свой участок графика. При этом, это не узкий фронт работ.
Понимание global_id здесь меняется в зависимости от конкретного этапа. Он может указывать на Query, Key или Value. Функционал меняется на каждом этапе и указывает на объект получения градиента ошибки. Аналогично меняется функциональность local_id, который задаёт поток внутри группы, как трейдер, просматривающий несколько таймфреймов. А h_id определяет голову внимания, то есть аспект рынка, на котором фокусируется аналитик.
Все эти индексы формируют сеть наблюдения, позволяя аккуратно распределять градиенты, как если бы мы распределяли внимание между разными котировками, чтобы ни одна деталь не осталась незамеченной.
__kernel void GlobalLocalAttentionGrad(__global const float *q, __global float *q_gr, __global const float *kv, __global float *kv_gr, __global float *scores, __global const float *mask, __global const float *mask_gr, __global const float *label, __global float *out_gr, const int dimension, const int total_q, const int total_kv, const int total_mask ) { //--- init const int global_id = get_global_id(0); const int local_id = get_local_id(1); const int h_id = get_global_id(2); const int total_global = get_global_size(0); const int total_local = get_local_size(1); const int total_heads = get_global_size(2); //--- __local float temp[LOCAL_ARRAY_SIZE];
Для чётных голов, которые работают с глобальной плотной матрицей, процесс напоминает анализ рынка по полным историческим данным. Сначала вычисляются градиенты Value: каждый поток аккумулирует влияние своей позиции на общий результат, суммируя его через LocalSum. Это похоже на то, как трейдер суммирует сигналы от всех исторических свечей, чтобы понять общий тренд.
if(h_id % 2 == 0) { //--- Value Gradient global_id -> v_id, local_id -> q_id for(int d = 0; d < dimension; d++) { const int shift_v = RCtoFlat(h_id, 2 * d + 1, total_heads, 2 * dimension, global_id); float grad = 0; for(int q_id = local_id; q_id < total_q; q_id += total_local) { int shift_s = RCtoFlat(h_id / 2, global_id, total_heads / 2, total_kv + total_mask, q_id); int shift_q = RCtoFlat(h_id, d, total_heads, dimension, q_id); grad += IsNaNOrInf(scores[shift_s] * out_gr[shift_q], 0); } grad = LocalSum(grad, 1, temp); kv_gr[shift_v] = grad; }
Затем формируются градиенты Query. Здесь важно учитывать SoftMax нормализацию — аналогично тому, как аналитик оценивает значимость каждого сигнала на фоне всех остальных, чтобы ни один шум не исказил картину. Градиенты Query аккуратно суммируются по локальным потокам и записываются в q_gr.
//--- Query Gradient global_id -> q_id, local_id -> k_id/v_id if(global_id < total_q) { //--- 1. Score grad float grad_s = 0; const int shift_v = RCtoFlat(h_id, 1, total_heads, 2 * dimension, local_id); const int shift_s = RCtoFlat(h_id / 2, local_id, total_heads / 2, total_kv + total_mask, global_id); int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, global_id); if(local_id < total_kv) for(int d = 0; d < dimension; d++) grad_s += IsNaNOrInf(kv[shift_v + 2 * d] * out_gr[shift_q + d], 0); //--- 2. SoftMax grad grad_s = LocalSoftMaxGrad(scores[shift_s], grad_s, 1, temp); //--- 3. Query grad const int shift_k = shift_v - 1; for(int d = 0; d < dimension; d++) { float grad = 0; if(local_id < total_kv) grad = kv[shift_k + 2 * d] * grad_s; grad = LocalSum(grad, 1, temp); if(local_id == 0) q_gr[shift_q + d] = grad; } }
А Key получает итоговые градиенты через суммирование вкладов всех запросов.
//--- Key Gradient global_id -> k_id, local_id -> score_id/v_id/dimension if(global_id < total_kv) { float grad = 0; for(int q_id = 0; q_id < total_q; q_id++) { //--- 1. Score grad local_id -> score_id/v_id float grad_s = 0; const int shift_v = RCtoFlat(h_id, 1, total_heads, 2 * dimension, local_id); const int shift_s = RCtoFlat(h_id / 2, local_id, total_heads / 2, total_kv + total_mask, q_id); int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, q_id); if(local_id < total_kv) for(int d = 0; d < dimension; d++) grad_s += IsNaNOrInf(kv[shift_v + 2 * d] * out_gr[shift_q + d], 0); //--- 2. SoftMax grad grad_s = LocalSoftMaxGrad(scores[shift_s], grad_s, 1, temp); BarrierLoc; if(global_id == local_id) temp[0] = grad_s; BarrierLoc; grad_s = temp[0]; //--- 3. Key grad local_id -> dimension shift_q = RCtoFlat(h_id, local_id, total_heads, dimension, q_id); if(local_id < dimension) grad += IsNaNOrInf(q[shift_q] * grad_s, 0); } const int shift_k = RCtoFlat(h_id, 2 * local_id, total_heads, 2 * dimension, global_id); if(local_id < dimension) kv_gr[shift_k] = IsNaNOrInf(grad); } }
Для глобальной матрицы процесс идёт плавно, потому что все данные присутствуют, и алгоритм может параллельно распределять градиенты.
Нечётные головы, работающие с локальной разряженной матрицей, требуют от кернела настоящей тщательности трейдера. Аналогично представленному выше алгоритму, сначала в цикле суммируем градиенты для Value от всех Query. Только здесь каждый сначала проверяем, существует ли связь через маску и метки. Если связи нет, или маска запрещает использование элемента, поток Query пропускается.
else { //--- Value Gradient global_id -> v_id, local_id -> mask_index/dimension if(global_id < total_kv) { float grad = 0; for(int q_id = 0; q_id < total_q; q_id++) { //--- 1. kv_id int kv_id = -1; float m = 0; const int l = RCtoFlat(q_id, local_id, total_q, total_mask, 0); const int shift_s = RCtoFlat(h_id / 2, total_kv + local_id, total_heads / 2, total_kv + total_mask, q_id); //--- Check for use current Value if(local_id < total_mask) kv_id = (int)label[l]; if(local_id == 0) temp[0] = 0; BarrierLoc; if(kv_id == global_id) temp[0] = scores[shift_s]; BarrierLoc; if(temp[0] == 0) continue;
Только для существующих элементов вычисляется градиент Value. Коэффициент внимания умножается на соответствующий градиент выхода и аккумулируется.
//--- Value grad int shift_q = RCtoFlat(h_id, local_id, total_heads, dimension, q_id); if(local_id < dimension) grad += IsNaNOrInf(temp[0] * out_gr[shift_q], 0); } const int shift_v = RCtoFlat(h_id, 2 * local_id + 1, total_heads, 2 * dimension, global_id); if(local_id < dimension) kv_gr[shift_v] = IsNaNOrInf(grad, 0); }
Градиенты Query формируются с учётом SoftMax и маски, что позволяет фильтровать лишние сигналы, словно трейдер игнорирует шумные бары и фейковые паттерны.
//--- Query Gradient global_id -> q_id, local_id -> mask label if(global_id < total_q) { //--- 1. kv_id; int kv_id = -1; float m = 0; const int l = RCtoFlat(global_id, local_id, total_q, total_mask, 0); if(local_id < total_mask) { kv_id = (int)IsNaNOrInf(label[l], -1); m = IsNaNOrInf(mask[l], 0); } //--- 2. Score grad float grad_s = 0; const int shift_v = RCtoFlat(h_id, 1, total_heads, 2 * dimension, kv_id); const int shift_s = RCtoFlat(h_id / 2, total_kv + local_id, total_heads / 2, total_kv + total_mask, global_id); int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, global_id); if(local_id < total_mask) for(int d = 0; d < dimension; d++) grad_s += IsNaNOrInf(kv[shift_v + 2 * d] * out_gr[shift_q + d], 0); //--- 3. SoftMax grad float score = IsNaNOrInf(scores[shift_s], 0); grad_s = LocalSoftMaxGrad(scores[shift_s], grad_s, 1, temp); mask_gr[l] = IsNaNOrInf(grad_s * score, 0); grad_s *= m; //--- 4. Query grad const int shift_k = shift_v - 1; for(int d = 0; d < dimension; d++) { float grad = 0; if(local_id < total_mask) grad = kv[shift_k + 2 * d] * grad_s; grad = LocalSum(grad, 1, temp); if(local_id == 0) q_gr[shift_q + d] = grad; } }
Градиенты Key аккумулируются только по тем запросам, которые реально имеют связь с ключом, и синхронизация потоков через BarrierLoc гарантирует, что ни один сигнал не потеряется. Как если бы аналитик сверял результаты своих коллег перед финальной записью сделки. Каждое вычисление точно отражает реальное распределение влияния в локальной разряженной матрице и предотвращает загрязнение градиентов лишними данными.
//--- Key Gradient global_id -> k_id, local_id -> score_id/v_id/dimension if(global_id < total_kv) { float grad = 0; for(int q_id = 0; q_id < total_q; q_id++) { //--- 1. kv_id; int kv_id = -1; float m = 0; const int l = RCtoFlat(global_id, local_id, total_q, total_mask, 0); if(local_id < total_mask) { kv_id = (int)label[l]; if(kv_id == global_id) m = mask[l]; } m = LocalSum(m, 1, temp); if(m == 0) continue; //--- 2. Score grad local_id -> score_id/v_id float grad_s = 0; const int shift_v = RCtoFlat(h_id, 1, total_heads, 2 * dimension, kv_id); const int shift_s = RCtoFlat(h_id / 2, total_kv + local_id, total_heads / 2, total_kv + total_mask, q_id); int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, q_id); if(local_id < total_mask) for(int d = 0; d < dimension; d++) grad_s += IsNaNOrInf(kv[shift_v + 2 * d] * out_gr[shift_q + d], 0); //--- 3. SoftMax grad grad_s = LocalSoftMaxGrad(scores[shift_s], grad_s, 1, temp); BarrierLoc; if(global_id == local_id) temp[0] = grad_s * m; BarrierLoc; grad_s = temp[0]; //--- 4. Key grad local_id -> dimension shift_q = RCtoFlat(h_id, local_id, total_heads, dimension, q_id); if(local_id < dimension) grad += IsNaNOrInf(q[shift_q] * grad_s, 0); } const int shift_k = RCtoFlat(h_id, 2 * local_id, total_heads, 2 * dimension, global_id); if(local_id < dimension) kv_gr[shift_k] = IsNaNOrInf(grad); } } }
Внутри одного кернела реализованы два логически разных алгоритма, потому что глобальная и локальная матрицы требуют принципиально разного подхода. Глобальная плотная матрица позволяет напрямую вычислять градиенты для всех элементов, словно трейдер видит весь рынок целиком. Локальная разряженная матрица требует аккуратной фильтрации, синхронизации и суммирования только существующих связей. Аналогично трейдеру, который тщательно проверяет каждый важный сигнал на ограниченном участке графика. Такое разделение обеспечивает корректное и эффективное распределение градиентов при обучении модели на больших исторических рядах, где одновременно сосуществуют плотные глобальные зависимости и редкие локальные корреляции.
Каждое действие кернела — это как отдельный шаг трейдера. Проверка маски и меток напоминает выбор реально значимых ценовых уровней. Фильтрация NaN и Inf — игнорирование шумных данных. Суммирование через LocalSum и синхронизация потоков — координацию аналитиков, чтобы не потерять важные сигналы. В результате модель получает точные градиенты для Value, Query и Key, что позволяет ей учиться на исторических данных, распознавать значимые рыночные паттерны и минимизировать ошибку прогнозирования. Кернел превращает абстрактные вычисления в динамичный процесс анализа рынка, где каждая операция градиента отражает реальное внимание и действия аналитика, обеспечивая точность и стабильность обучения.
Полный код кернелов представлен во вложении.
Реализация в основной программе
На стороне основной программы алгоритм Global-Local Spatial Attention аккуратно оформлен в виде нового объекта CNeuronGlobalLocalAttention, который наследует функциональность многоголовой feed-forward структуры CNeuronMHFeedForward. Этот объект объединяет несколько ключевых компонентов, каждый из которых выполняет строго определённую роль в построении внимания.
class CNeuronGlobalLocalAttention : public CNeuronMHFeedForward { protected: CNeuronSNSMHAttention cMask; CNeuronConvOCL cQ; CNeuronConvOCL cKV; CNeuronBaseOCL cScore; CNeuronBaseOCL cMHAttention; CNeuronConvOCL cW0; CNeuronBaseOCL cResidual; //--- virtual bool GlobalLocalAttention(void); virtual bool GlobalLocalAttentionGrad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronGlobalLocalAttention(void) {}; ~CNeuronGlobalLocalAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint dimension_k, uint heads, uint m_units, float sparse, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGlobalLocalAttention; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
Внутри класса есть объект cMask, отвечающий за управление масками локальных связей, что позволяет корректно работать с разряженной матрицей и фильтровать несущественные локальные паттерны. Два объекта свёрток cQ и cKV реализуют преобразования запросов и пар ключ-значение соответственно, подготавливая данные для вычислений коэффициентов внимания. Элемент cScore аккумулирует результаты скоров, а cMHAttention собирает результаты многоголового внимания, объединяя глобальные и локальные компоненты. Наконец, cW0 и cResidual отвечают за линейное преобразование и добавление остаточной связи, обеспечивая стабильность и корректность обновления выходных сигналов. Функционал блока FeedForward реализуется средствами родительского класса.
Метод Init отвечает за полную подготовку нейрона к работе и задаёт все ключевые параметры для алгоритма Global-Local Spatial Attention. Сначала вызывается инициализация базового класса CNeuronMHFeedForward. Здесь задаются все основные параметры объекта.
bool CNeuronGlobalLocalAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint dimension_k, uint heads, uint m_units, float sparse, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMHFeedForward::Init(numOutputs, myIndex, open_cl, window, 2 * window, units, 1, heads, optimization_type, batch)) return false; activation = None;
Если на этом этапе что-то идёт не так, торговая сессия не начинается: объект не инициализируется, предотвращая любые некорректные вычисления.
Далее мы отключаем функцию активации, словно трейдер решает работать без фильтров эмоций, полностью полагаясь на прямые сигналы рынка.
Первым делом на сцену выходит cMask. Он управляет локальными масками — фильтрует разряженные паттерны, чтобы трейдер не отвлекался на незначимые сигналы. С его помощью модель понимает, какие локальные связи важны, а какие можно проигнорировать.
int index = 0; if(!cMask.Init(0, index, OpenCL, units, window, heads, m_units, sparse, optimization, iBatch)) return false;
Следом формируются cQ и cKV, которые превращают сырые данные в понятные аналитические сигналы. cQ обрабатывает запросы, как трейдер оценивает текущие позиции на рынке, а cKV аккумулирует ключи и значения, подобно тому, как он собирает информацию о прошлых свечах, уровнях поддержки и сопротивления. Для обоих блоков функция активации отключена, чтобы линии анализа оставались чистыми и линейными, без искажений.
index++; if(!cQ.Init(0, index, OpenCL, window, window, 2 * dimension_k * heads, units, 1, optimization, iBatch)) return false; cQ.SetActivationFunction(None); index++; if(!cKV.Init(0, index, OpenCL, window, window, 4 * dimension_k * heads, units, 1, optimization, iBatch)) return false; cKV.SetActivationFunction(None);
Далее включается cScore, который аккумулирует полученные оценки — аналог того, как трейдер суммирует сигналы со всех индикаторов, чтобы понять, где стоит сделать ставку.
index++; if(!cScore.Init(0, index, OpenCL, (units + m_units)*units * heads, optimization, iBatch)) return false; cScore.SetActivationFunction(None); index++; if(!cMHAttention.Init(0, index, OpenCL, 2 * dimension_k * heads * units, optimization, iBatch)) return false; cMHAttention.SetActivationFunction(None);
На основе этих скорингов работает cMHAttention, многоголовое внимание, которое распределяет ресурсы между разными инструментами и временными интервалами. Точно как опытный аналитик решает, на что обратить максимум внимания в текущей рыночной ситуации.
Завершают цепочку cW0 и cResidual. Первый выполняет линейное преобразование сигналов, подобно тому, как трейдер корректирует расчёты с учётом текущего объёма и ликвидности рынка.
index++; if(!cW0.Init(0, index, OpenCL, 2 * dimension_k * heads, 2 * dimension_k * heads, window, units, 1, optimization, iBatch)) return false; cW0.SetActivationFunction(None); index++; if(!cResidual.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cResidual.SetActivationFunction(None); //--- return true; }
Второй добавляет остаточную связь, гарантируя, что информация о прошлых шагах обучения не теряется и сигнал остаётся стабильным — как проверка позиций по предыдущим сделкам перед открытием новой.
Каждый блок получает свой уникальный индекс и параметры, связывается с OpenCL-контекстом и готов к совместной работе. Всё это похоже на слаженную команду трейдеров и аналитиков: один фильтрует сигналы, другой оценивает тренды, третий аккумулирует результаты, а четвёртый распределяет внимание между инструментами. В итоге, когда инициализация завершена, объект полностью готов к работе, способный одновременно анализировать глобальные и локальные паттерны рынка, фильтровать шум и принимать точные решения на основе исторических данных.
После того как объект инициализирован, и все блоки настроены, наступает этап прямого прохода — момент, когда модель фактически наблюдает рынок и строит свои прогнозы. Метод feedForward задаёт чёткую последовательность действий, где каждый компонент выполняет строго определённую роль, а данные проходят через всю цепочку преобразований, напоминая работу слаженной команды трейдеров.
bool CNeuronGlobalLocalAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cMask.FeedForward(NeuronOCL)) return false;
Сначала активируется cMask, который проверяет и фильтрует локальные связи. Это как трейдер, внимательно выбирающий только те сигналы, которые реально имеют значение, игнорируя шумные или отсутствующие паттерны. Если здесь что-то идёт не так, дальнейший анализ невозможен — модель не будет строить прогноз на основе некорректных данных.
Затем последовательно выполняются cQ и cKV. Первый обрабатывает запросы, подготавливая их к сравнению с ключами, словно аналитик оценивает текущие рыночные позиции и формирует список потенциальных точек входа.
if(!cQ.FeedForward(NeuronOCL)) return false; if(!cKV.FeedForward(NeuronOCL)) return false;
Второй аккумулирует ключи и значения, словно собирая историю котировок и объёмы сделок для каждого инструмента, создавая основу для оценки влияния каждого сигнала.
После успешного завершения этапа подготовительной работы, вызывается метод-обертка GlobalLocalAttention, в котором организован процесс постановки в очередь выполнения одноименного кернела, выполняющего основной алгоритм на стороне OpenCL-контекста.
if(!GlobalLocalAttention()) return false;
Здесь запросы и ключи объединяются в глобальное и локальное внимание. Происходит магия модели: каждый паттерн оценивается с учётом всех релевантных связей, разряженных и плотных, а вклады аккуратно суммируются по всем головам внимания.
Этот этап аналогичен моменту, когда трейдер сравнивает текущие сигналы с историческими данными и принимает решение, на какие позиции стоит обратить максимум внимания.
Далее выполняется cW0, который применяет линейное преобразование к результатам многоголового внимания. Это можно представить как корректировку сигналов с учётом масштаба рынка, ликвидности и веса каждого паттерна.
if(!cW0.FeedForward(cMHAttention.AsObject())) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cResidual.getOutput(), cW0.GetFilters(), true, 0, 0, 0, cW0.GetUnits())) return false; //--- return CNeuronMHFeedForward::feedForward(cResidual.AsObject()); }
После чего, данные проходят через SumAndNormalize. В нем суммируются выходы линейного блока и остаточной связи, а затем нормализуются. Этот шаг гарантирует, что сигнал остаётся стабильным и масштабируемым — как если бы трейдер свёл воедино результаты нескольких аналитиков, проверил их согласованность и оценил общую силу сигнала перед принятием решения.
Наконец, обновлённый сигнал передаётся в одноименный метод родительского класса CNeuronMHFeedForward, который завершает прямой проход, выполняя функционал блока FeedForward и интегрируя результаты в общую структуру модели.
Таким образом, весь процесс прямого прохода можно представить как последовательный анализ рынка, где каждый блок выполняет свою роль: фильтрует, оценивает, аккумулирует, корректирует и суммирует данные, обеспечивая точность и согласованность прогнозов.
После того как модель успешно прошла прямой проход и сформировала прогноз, наступает этап обучения — момент, когда нейрон оценивает, насколько точно он отработал, и корректирует свои внутренние параметры. Метод calcInputGradients отвечает за эту оценку и за распределение оцифрованного влияния каждого компонента модели на итоговый результат.
bool CNeuronGlobalLocalAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!CNeuronMHFeedForward::calcInputGradients(cResidual.AsObject());) return false;
Сначала проверяется корректность полученного указателя на объект исходных данных NeuronOCL. Если объект отсутствует, дальнейшие вычисления невозможны — как если бы трейдер пытался анализировать данные без графика и котировок.
Затем вызывается одноименный метод родительского класса, который начинает процесс обратного распространения градиентов до уровня объекта остаточных связей.
Далее вызывается метод DeActivation для блока cW0, где полученные градиенты корректируются с учётом функции активации линейного слоя. Это аналог того, как аналитик учитывает влияние каждого индикатора на итоговое решение, фильтруя и нормализуя сигналы.
if(!DeActivation(cW0.getOutput(), cW0.getGradient(), cResidual.getGradient(), cW0.Activation())) return false;
После этого градиенты передаются в cMHAttention, где аккумулируется влияние каждого паттерна многоголового внимания.
if(!cMHAttention.CalcHiddenGradients(cW0.AsObject())) return false; if(!GlobalLocalAttentionGrad()) return false;
На этом этапе вызывается GlobalLocalAttentionGrad, который обеспечивает точное распределение градиентов между глобальной и локальной матрицами, учитывая разреженные и плотные связи — словно трейдер оценивает вклад каждой свечи и каждого уровня поддержки в общий тренд. И градиенты аккуратно распространяются на блоки cQ и cKV.
Далее нам предстоит собрать градиенты ошибки на уровне исходных данных от всех информационных потоков. А их у нас четыре. Сначала спускаем градиенты от cQ.
if(!NeuronOCL.CalcHiddenGradients(cQ.AsObject())) return false;
Полученные значения суммируем с градиентами магистрали остаточных связей, но предварительно скорректируем последние на функцию активации слоя исходных данных.
if(!DeActivation(cResidual.getOutput(), cResidual.getGradient(), cResidual.getGradient(), NeuronOCL.Activation())) return false; if(!SumAndNormilize(NeuronOCL.getGradient(), cResidual.getGradient(), cResidual.getGradient(), cW0.GetFilters(), false, 0, 0, 0, cW0.GetUnits())) return false;
Следующим шагом обрабатываются градиенты cKV с последующим добавлением к ранее накопленным данным.
if(!NeuronOCL.CalcHiddenGradients(cKV.AsObject())) return false; if(!SumAndNormilize(NeuronOCL.getGradient(), cResidual.getGradient(), cResidual.getGradient(), cW0.GetFilters(), false, 0, 0, 0, cW0.GetUnits())) return false;
Последним по счету, но не по значению, спускаем градиенты локальных масок cMask. Их влияние мы также суммируем с ранее накопленными данными.
if(!NeuronOCL.CalcHiddenGradients(cMask.AsObject())) return false; if(!SumAndNormilize(NeuronOCL.getGradient(), cResidual.getGradient(), NeuronOCL.getGradient(), cW0.GetFilters(), false, 0, 0, 0, cW0.GetUnits())) return false; //--- return true; }
В результате, метод calcInputGradients обеспечивает комплексную и детальную оценку влияния всех компонентов модели — от глобальных и локальных голов внимания до запросов, ключей, значений и масок. Каждый блок получает количественную обратную связь, позволяя модели корректно обновлять веса, минимизировать ошибку и улучшать точность прогнозов. Этот процесс превращает абстрактные вычисления градиентов в реальную оценку значимости каждого элемента системы, делая обучение максимально прозрачным и управляемым.
После того как модель оценила влияние каждого компонента через обратное распространение градиентов, наступает момент, когда нужно действовать — корректировать внутренние параметры и адаптировать модель к реальным рыночным данным. Метод updateInputWeights выполняет именно эту задачу.
bool CNeuronGlobalLocalAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cMask.UpdateInputWeights(NeuronOCL)) return false; if(!cQ.UpdateInputWeights(NeuronOCL)) return false; if(!cKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(cMHAttention.AsObject())) return false; //--- return CNeuronMHFeedForward::updateInputWeights(cResidual.AsObject()); }
Алгоритм метода на самом деле очень прямолинейный — он последовательно передаёт управление внутренним компонентам, которые содержат обучаемые параметры. Сначала обновляются веса локальных масок cMask, затем корректируются параметры запросов cQ и ключей/значений cKV. После чего обновляются веса линейного преобразования cW0. В конце корректируются параметры родительского класса.
Каждый шаг — это простой, но важный процесс: модель корректирует свои параметры так, чтобы точнее оценивать рынок и строить прогнозы, при этом все блоки действуют слаженно, как команда трейдеров, работающих по единой стратегии.
Мы проделали значительный объём работы и справились с многочисленными задачами. Сейчас самое время сделать небольшой перерыв, перевести дух и осмыслить результаты. В следующей статье, с обновлёнными силами и свежим взглядом, мы продолжим работу и доведём её до логического завершения.
Заключение
Мы прошли значительный путь: каждый блок алгоритма Global-Local Spatial Attention был тщательно интегрирован и выстроен в единую цепочку вычислений. Прямой проход, распределение градиентов и обновление параметров модели — всё это напоминало работу опытного трейдера, который фильтрует сигналы, оценивает влияние каждого инструмента и корректирует позиции для оптимального результата.
Реализованный средствами MQL5 подход показал, как сложные алгоритмы внимания можно адаптировать к практическому использованию, превращая абстрактные вычисления в точные и управляемые прогнозы. Каждый блок модели, как отдельный аналитик, внёс свой вклад в итоговое решение, обеспечивая гибкость, устойчивость и масштабируемость всей системы.
Следующий этап станет финальной проверкой нашей работы: мы доведём модель до логического завершения, протестируем её на реальных рыночных данных и оценим практическую эффективность предложенного фреймворка.
Ссылки
- Extralonger: Toward a Unified Perspective of Spatial-Temporal Factors for Extra-Long-Term Traffic Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования