
Нейросети в трейдинге: Рекуррентное моделирование микродвижений рынка (EV-MGRFlowNet)

Введение
Современные финансовые рынки напоминают гигантский поток микрособытий — бесконечную последовательность мельчайших изменений, каждое из которых несёт след прошедших сделок и предчувствие будущих. Цены колеблются, объёмы дышат, ордера сменяют друг друга с частотой, недостижимой для человеческого восприятия. Анализировать этот поток так же трудно, как уловить направление ветра в бурю: мгновения превращаются в миллисекунды, шум перекрывает сигнал, а традиционные методы, привыкшие к статичным срезам, теряют способность видеть движение как непрерывный процесс. Именно в этой точке пересечения — между скоростью информации и ограничениями классических моделей — возникает необходимость в принципиально новом взгляде на динамику рынка.
В последние годы подобный прорыв случился в смежной области — обработке данных событийных камер. Устройства, регистрирующие не кадры, а изменения освещённости в каждой точке, породили целое направление исследований. В них ключевым объектом стала не картинка, а поток событий во времени. Для анализа таких данных традиционные свёрточные сети оказались малопригодны. Им не хватало чувствительности к последовательным микросдвигам, определяющим структуру движения. Ответом на этот вызов стал фреймворк EV-MGRFlowNet, представленный в работе "EV-MGRFlowNet: Motion-Guided Recurrent Network for Unsupervised Event-based Optical Flow with Hybrid Motion-Compensation Loss". Предложенный фреймворк представляет собой рекуррентную модель, способную обучаться без учителя, извлекая структуру движения напрямую из потока событий.
Авторы EV-MGRFlowNet предложили архитектуру, которая сочетает рекуррентный энкодер FERE-Net, декодер FGD-Net и гибридную функцию потерь HMC-Loss. Вместо того чтобы подгонять модель под заранее размеченные примеры, сеть сама учится понимать, как распределяются изменения во времени и пространстве, выравнивая последовательные события по принципу компенсации движения. В основе этой идеи — наблюдение, что динамика сама себя объясняет. Если правильно оценить движение, поток событий соберётся в логичную последовательность. Таким образом, EV-MGRFlowNet не просто вычисляет оптический поток, а строит внутреннее представление временной структуры, основанное на причинно-следственных связях между микрособытиями.
Для финансовых рынков эта концепция оказывается удивительно близкой по духу. Биржевые данные, особенно тиковые, по своей природе тоже событийные. Здесь нет кадров, есть лишь непрерывная череда элементарных изменений — обновлений цены, объёма, дисбаланса заявок. Каждое такое изменение несёт локальную информацию, но только во временном контексте оно раскрывает истинную картину рыночного движения. Если рассматривать рынок как событийную сцену, а поток котировок как аналог оптического потока, становится возможным применить подходы, разработанные для анализа динамики изображений, к пониманию финансового видеоряда.
Классические методы анализа — от ARIMA до сложных нейросетей — строят прогноз на основе фиксированных выборок данных, игнорируя непрерывность событий. Они работают с усреднёнными значениями, обрезая богатую структуру внутрисекундной динамики. В отличие от них, событийный подход предлагает модель, способную воспринимать рынок как живой организм, где каждое движение несёт импульс и направление. Рекуррентная часть фреймворка EV-MGRFlowNet обеспечивает непрерывное накопление контекста, позволяя системе видеть не просто текущий тик, а траекторию его возникновения. А гибридная функция потерь HMC-Loss создаёт условия, при которых модель учится различать истинное движение цены от случайных колебаний, что особенно ценно в условиях рыночного шума.
Следовательно, перенос идей EV-MGRFlowNet в плоскость финансового анализа открывает путь к созданию новых поколений моделей, способных ощущать рынок. Мы перестаём рассматривать данные как статичную последовательность чисел и начинаем видеть их как поток взаимодействий — как непрерывную ткань событий, где каждый тик связан с предыдущим и предвосхищает следующий. В этой парадигме задача модели уже не сводится к предсказанию следующего значения ряда, а заключается в реконструкции внутреннего вектора движения — аналоге оптического потока, но в экономическом пространстве. Такой подход позволяет не просто угадывать будущие цены, а понимать направление и скорость рыночной динамики, выделяя устойчивые паттерны поведения участников.
Важно подчеркнуть, что событийная архитектура имеет и практические преимущества. Во-первых, она естественным образом адаптируется к неравномерным временным рядам: в отличие от стандартных сетей, ей не требуется фиксированное окно данных, она работает с последовательностями переменной длины. Во-вторых, обучение без надзора снижает зависимость от исторической разметки, которая в финансовых задачах почти всегда субъективна. И наконец, гибридная функция потерь позволяет объединить метрики временной согласованности с экономическими критериями — например, с оценкой устойчивости тренда или энергетики колебаний. Это даёт возможность обучать модель на сырых потоках без вмешательства человека, что делает систему автономной и устойчивой к изменению рыночного режима.
Рассматривая финансовые данные как событийную сцену, мы получаем новый уровень интерпретации: не просто что произошло, а как и почему изменилась структура движения. Это особенно важно в высокочастотной торговле, где миллисекунды определяют результат. Модель, способная уловить момент, когда движение теряет согласованность (оптический поток рынка распадается), получает конкурентное преимущество в определении фаз перехода, разворотов и зарождения новых импульсов. В этом смысле EV-MGRFlowNet становится концепцией восприятия рынка, в которой каждый тик рассматривается как элемент живого движения.
С практической точки зрения, перенос фреймворка в финансовую сферу предполагает адаптацию его модулей под специфику данных. Визуальные события заменяются микрособытиями рынка, пространственные координаты — индексами инструмента и уровнями ордеров, а временной контекст сохраняет ту же непрерывность. Рекуррентный энкодер формирует представление о локальных паттернах движения, декодер восстанавливает вектор потока — динамику изменения цены или дисбаланса, а функция потерь компенсирует различия между прогнозным и фактическим развитием рынка. В итоге модель учится понимать не отдельные изменения, а их направление и скорость — то, что интуитивно называют ритмом рынка.
Фактически, мы имеем дело с новой парадигмой анализа — переходом от постфактум-аналитики к восприятию рынка в процессе его движения. Это делает фреймворк EV-MGRFlowNet особенно перспективным для систем алгоритмической торговли, риск-менеджмента и предиктивного мониторинга ликвидности. Там, где раньше требовались десятки сложных индикаторов и фильтров, теперь достаточно одного самонастраивающегося модуля, который наблюдает за рынком так же, как глаз наблюдает за движением в пространстве — фиксируя направление, ускорение и устойчивость потока.
Алгоритм EV-MGRFlowNet
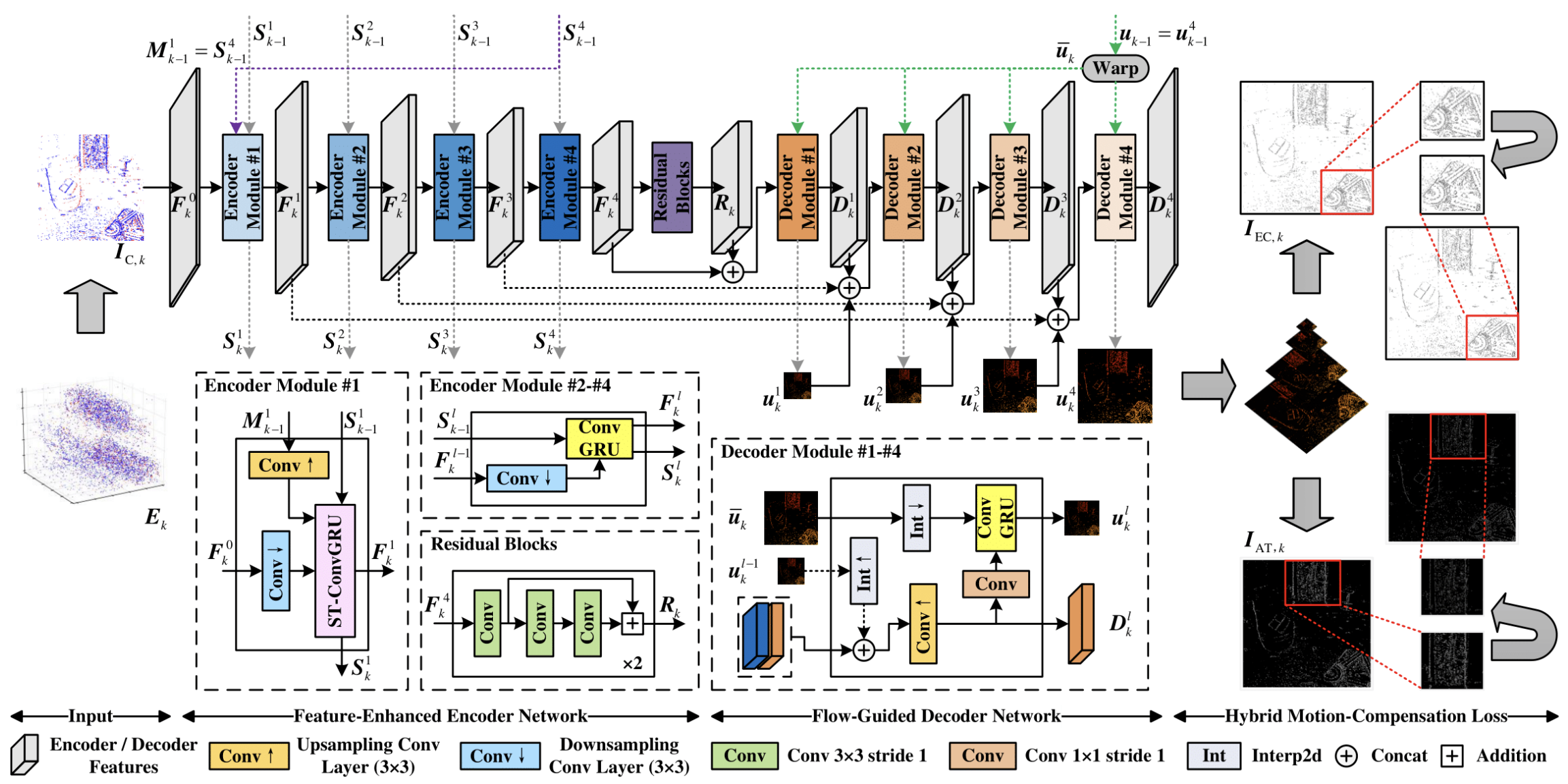
Архитектура EV-MGRFlowNet по своей сути представляет рекуррентную модель типа Энкодер–Декодер, разработанную для анализа непрерывных потоков событий. В её основе лежит два ключевых компонента — FERE-Net (Feature-Enhanced Recurrent Encoder) и FGD-Net (Flow-Guided Decoder). Первый отвечает за восприятие и накопление пространственно-временных признаков, второй — за восстановление и уточнение динамики движения на множественных масштабах.
На вход модели подаётся событийный объём данных, который преобразуется в карту подсчёта событий. В контексте финансовых рынков эту структуру можно рассматривать как аналог агрегированных рыночных микрособытий — мини-изменений цены, объёма или ликвидности, происходящих в пределах коротких временных интервалов. Эти данные проходят через FERE-Net, где извлекаются скрытые закономерности и временные зависимости. Рекуррентная природа модели позволяет ей не просто фиксировать моментальное состояние, а формировать непрерывное восприятие потока, подобно тому, как опытный трейдер ощущает темп и направление рынка, наблюдая за мелкими изменениями в ленте ордеров.
Важнейшим элементом архитектуры является использование рекуррентных блоков ConvGRU и ST-ConvGRU, которые обеспечивают сохранение многослойных скрытых состояний. Благодаря этому, модель способна улавливать даже кратковременные импульсы и асинхронные сдвиги в данных — то, что в рыночной среде выражается в микроколебаниях котировок и переходах между фазами активности.
После этапа кодирования выходные признаки поступают в FGD-Net, где реализуется многоуровневая оценка направленного потока. Здесь извлечённая ранее информация о движении используется для уточнения новых прогнозов, формируя систему самокоррекции — принцип, который особенно ценен при работе с нелинейными и стохастическими рыночными процессами. По сути, модель учится видеть не саму цену, а её направление и скорость изменения, создавая представление о рыночном потоке.
Финальный этап обучения основан на гибридной функции потерь HMC-Loss (Hybrid Motion Compensation Loss), которая использует только событийные данные и оценивает качество реконструкции по резкости временных и экспоненциальных карт интенсивности. В контексте трейдинга это можно интерпретировать как проверку чёткости рыночного восприятия: насколько точно модель улавливает реальные импульсы движения без внешнего обучения на заранее размеченных данных.
В предложенной авторами фреймворка схеме анализа потоков движения используется событийные камеры — устройства, способные регистрировать изменения интенсивности на каждом пикселе независимо и асинхронно. Принцип работы таких сенсоров обеспечивает им уникальные преимущества: высокое временное разрешение и широкий динамический диапазон. В отличие от традиционных камер, фиксирующих изображения с постоянной частотой, каждый пиксель событийной камеры реагирует только на значимые изменения интенсивности и создаёт события в момент возникновения этих изменений.
Формально, событие ei = (xi, ti, pi) на пикселе xi = (xi, yi) возникает тогда, когда логарифмическое изменение интенсивности превышает заданный порог контраста θ в момент времени ti. Полярность события pi ∈ {+1, -1} отражает направление изменения. Таким образом формируется разреженный асинхронный поток событий в трёхмерных координатах (x,y,t).
Один отдельный сигнал несёт очень мало информации, и напрямую подавать отдельные события в глубокую сеть сложно. Поэтому события агрегируются в короткие временные окна, формируя представление событий, пригодное для обработки нейросетью. Поток событий делится на последовательность сегментов событий Ek с фиксированными интервалами. Каждый сегмент затем преобразуется в удобное представление.
В авторской работе в качестве входа модели используется карта подсчёта событийIC,k ∈ R2*H*W, широко применяемая в исследованиях событийного зрения. Положительные и отрицательные карты IC,+,k и IC,-,k формируются путем подсчёта числа событий в каждом пикселе для соответствующих полярностей.
В финансовом контексте аналогично можно рассматривать микрособытия рынка — изменения цены, объёма или ликвидности, происходящие на каждом уровне инструмента в течение короткого интервала времени. Вместо визуального кадра, формируется карта событий рынка, где каждый пиксель отражает число событий в конкретной позиции и временном окне. Агрегируя микрособытия, мы получаем компактное, но информативное представление, которое модель может обрабатывать эффективно, выявляя закономерности и направление движения рынка.
После преобразования объёмов событий Ek в карты подсчёта событий IC,k, они подаются в энкодер для извлечения пространственно-временных признаков. Ключевым элементом энкодера является сверточная рекуррентная единица ConvGRU, которая позволяет модели учитывать текущее состояние анализируемого сигнала и информацию, накопленную на предыдущих шагах. Формально скрытое состояние на текущем временном шаге (Hk) вычисляется как функция от текущего входа (Xk) и предыдущего скрытого состояния (Hk-1).
![]()
Такая структура позволяет явно кодировать пространственную информацию и одновременно фиксировать временные зависимости. ConvGRU включает reset-гейт (rk) и update-гейт (zk), которые регулируют накопление и обновление памяти модели. Эти гейты обеспечивают гибкость в обработке потоков событий, позволяя сети фокусироваться на значимых изменениях и забывать шумные или нерелевантные сигналы.
Энкодер ConvGRU реализуется как многослойная архитектура. В четырёхслойной реализации каждый слой обрабатывает входные признаки и передает обновлённые скрытые состояния следующему слою. При этом каждый слой накапливает информацию о событиях на своём уровне разрешения. Однако стандартная архитектура ConvGRU имеет ограничение. Память модулей разных уровней обновляется только по временной оси. Это означает, что нижние слои могут терять ценные данные, накопленные верхними слоями, которые особенно важны для фиксации мелких, тонких паттернов движения.
С целью сохранения этих ключевых пространственно-временных признаков авторы фреймворка интегрируют в FERE-Net блок ST-ConvGRU. Этот модуль расширяет возможности стандартного ConvGRU, создавая дополнительный набор гейтов для отдельной памяти (M), которая сохраняет информацию от верхнего слоя и комбинируется с основной памятью (S) через выходной гейт (ok) и 1×1 свертку. Таким образом формируются обновлённые карты признаков (Fk1) и скрытое состояние (Sk1).
Вход первого слоя энкодера (fE1) включает три составляющие: текущую карту событий (Fk0 = IC,k), скрытое состояние предыдущего шага нижнего слоя (Sk-11) и скрытое состояние верхнего слоя (Mk-11). ST-ConvGRU объединяет эти элементы, обеспечивая обогащение признаков, что позволяет фиксировать локальные микродвижения и глобальные структурные изменения потока событий.

Далее обновлённые признаки последовательно проходят через слои (fE2), (fE3) и (fE4), где используется стандартный ConvGRU. На каждом слое скрытые состояния предыдущего шага интегрируются с текущими признаками, что позволяет модели аккумулировать информацию на разных уровнях и фиксировать сложные пространственно-временные паттерны. Финальные выходные признаки (Fk4) подаются в остаточные блоки (Residual Blocks), что обеспечивает дополнительное уточнение и переработку признаков.
Эти окончательные карты признаков (Rk) представляют собой полное, обогащённое представление потока событий, готовое для декодера.
В контексте финансовых временных рядов нижние слои FERE-Net фиксируют мгновенные локальные колебания, которые можно сравнить с кратковременными импульсами на рынке. Верхние слои аккумулируют более глобальные тенденции, позволяя модели воспринимать постепенные тренды и общую структуру движения. ST-ConvGRU обеспечивает сохранение ключевых признаков с разных уровней, чтобы модель не теряла информацию о тонких, но значимых микродвижениях.
Таким образом, FERE-Net превращает поток разрозненных рыночных событий в структурированное и обогащённое представление динамики рынка, позволяя выявлять направление движения, интенсивность изменений и устойчивость рыночных паттернов. Это фундамент для последующего декодирования и восстановления потоков движения, где модель сможет прогнозировать целостное поведение рынка на микроуровне.
Модели для оценки оптического потока на базе архитектуры U-Net редко используют информацию о предыдущих потоках, хотя такие данные могут служить эффективной инициализацией и предоставлять дополнительную информацию для уточнения текущего прогноза. Авторы фреймворка EV-MGRFlowNet решают эту задачу с помощью Flow-Guided Decoder Network (FGD-Net), которая позволяет использовать предыдущие оценки потока для улучшения текущих прогнозов.
Первым шагом является выравнивание последовательных потоков (uk-1) и (uk). Поскольку координаты пикселей, на которых основаны предыдущие прогнозы, не совпадают с текущими, используется метод forward warping. При допущении, что поток сохраняет локальную постоянность, можно получить выровненный поток (û*k) из предыдущего шага (u*k-1).
Декодер состоит из четырёх модулей fDl… l ∈ (1, 4), что позволяет выполнять многоуровневое прогнозирование потока движения. На каждом уровне входом служат промежуточные карты признаков предыдущего слоя декодера, соответствующие карты энкодера (F5-l,k) и выровненный предыдущий поток (ûk). Результатом работы каждого модуля являются уточнённый поток (ûlk) и промежуточные карты признаков (Dlk).
Сначала данные объединяются (конкатенируются) по каналам, формируя начальное предсказание потока (ûlk) и промежуточные карты признаков (Dlk). Далее используется ConvGRU, который извлекает информацию о движении из выровненного потока (ûk) и уточняет текущий прогноз, формируя окончательный поток (ûlk). На каждом уровне выровненный поток (ûk) дополнительно понижается в разрешении, чтобы соответствовать размеру карты признаков.
Таким образом, финальный прогноз (û4k) используется как текущая оценка потока (uk). При этом (uk) становится предварительным потоком для следующего шага декодирования, создавая циклическую связь, которая позволяет модели накапливать и корректировать информацию о динамике движения во времени.
В контексте финансовых временных рядов FGD-Net играет роль механизма, который учится использовать информацию о предыдущих движениях рынка для уточнения текущих прогнозов. Предыдущие оценки, как исторические микродвижения цены или объёма, помогают модели понять тенденции и прогнозировать последующие изменения с большей точностью, учитывая краткосрочные импульсы и накопленные тренды.
Таким образом, декодер FGD-Net превращает последовательность промежуточных признаков, накопленных FERE-Net, в точное, многоуровневое представление потока рыночных микродвижений, где каждый уровень отвечает за отдельный масштаб: от быстрых импульсов до более долгосрочных тенденций. Эта архитектура обеспечивает модели способность воспринимать рынок как непрерывный, структурированный поток событий, позволяя прогнозировать динамику с высокой детализацией.
Для обучения EV-MGRFlowNet авторы фреймворка предлагают гибридную функцию потерь с компенсацией движения (Hybrid Motion-Compensation Loss, HMC-Loss), которая позволяет модели обучаться без учителя, используя исключительно данные о событиях. Такой подход особенно важен для финансовых рынков, где размеченные данные о правильных движениях цены зачастую отсутствуют, а микродвижения происходят почти непрерывно.
Идея HMC-Loss основана на том, чтобы модель могла корректно выравнивать события во времени, учитывая предыдущие прогнозы потока. Сначала предсказанные потоки (uk ∈ R2*H*W) используются для переноса анализируемых сегментов событий (Ek) к эталонному моменту времени (t0), формируя выровненный объём (E'k). Этот шаг можно сравнить с приведением всех микроизменений цены и объёма к единой временной шкале — так модель получает согласованную картину происходящего на рынке.
Далее используется стандартная функция потерь LAT (Loss based on Average Timestamp LWE), которая измеряет чёткость усреднённой временной карты событий (IAT). LAT оценивает, насколько аккуратно выровнены события после компенсации потока. Она особенно эффективна для захвата локальных структурных изменений и хорошо себя зарекомендовала среди методов глубокого обучения.
Однако LAT имеет ограничение. Она недостаточно строго контролирует геометрию выравнивания событий. В результате модель может генерировать нежелательные потоки, где отдельные микрособытия остаются рассеянными, а структура движения теряется. Чтобы исправить это, авторы фреймворка вводят экспоненциальную карту подсчёта событий (LEC, Exponential Count IWE) и соответствующую функцию потерь (LEC). LEC делает акцент на пикселях без событий и усиливает влияние глобальной структуры данных.
Формально IEC формируется следующим образом:

И аналогично для отрицательных событий, где α — коэффициент насыщения, а κ — билинейный фильтр ядра.
Функция потерь LEC штрафует рассеяние событий и фокусируется на глобальной чёткости карты IEC, что критично для точного воспроизведения сложной структуры микродвижений.
Совмещение LAT и LEC формирует гибридную HMC-Loss, которая одновременно обеспечивает точность локальных временных паттернов и глобальное согласование движения. Кроме того, добавляется сглаживающий компонент Lsmooth, минимизирующий разницу потоков между соседними пикселями и обеспечивающий плавность прогнозов.
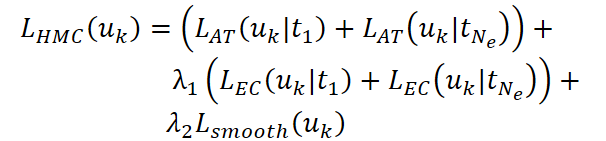
Здесь λ1 и λ2 регулируют баланс между локальной точностью, глобальной согласованностью и плавностью потока. Сглаживание Lsmooth обеспечивает мягкую и естественную регуляризацию.
В контексте финансовых рынков HMC-Loss выполняет роль интеллектуального выравнивателя событий. LAT отвечает за точное воспроизведение быстрых микродвижений цены или объёма — аналог кратковременных рыночных импульсов, которые часто предвосхищают краткосрочные колебания. LEC, в свою очередь, фокусируется на глобальной согласованности потока. Это позволяет фиксировать тренды и общую структуру движения рынка. Сглаживающая составляющая Lsmooth предотвращает резкие, нерелевантные колебания прогнозного потока, создавая гармоничное представление микродинамики.
Объединение этих трёх элементов позволяет EV-MGRFlowNet эффективно обучаться на реальных рыночных событиях без разметки, одновременно захватывая локальные микродвижения и накопленные глобальные тенденции. В итоге модель способна строить детализированные и согласованные прогнозы динамики рынка, которые учитывают все уровни движения — от мгновенных всплесков объёма до долгосрочных трендов цены.
Авторская визуализация фреймворка EV-MGRFlowNet представлена ниже.
Реализация средствами MQL5
После подробного рассмотрения теоретических основ EV-MGRFlowNet, предложенных его авторами, мы переходим к практической реализации фреймворка в среде MQL5. Начнём с ключевого компонента, который можно назвать сердцем модели — модуля ST-ConvGRU. Именно этот модуль обеспечивает сохранение и эффективное объединение пространственно-временной информации, позволяя модели фиксировать локальные микродвижения и глобальные тенденции. Реализация ST-ConvGRU требует аккуратного подхода к управлению скрытыми состояниями и памяти слоёв, а также точного воспроизведения операций свёртки и рекуррентных обновлений.
Как видно из описания модуля ST-ConvGRU, представленного в авторской работе, фактически он включает работу двух параллельных модулей ConvGRU. В нашей практике у нас уже была реализована отдельная версия ConvGRU, однако последовательное использование нескольких модулей приводит к заметным задержкам. Особенно на этапе обучения модели, когда сеть многократно обновляет скрытые состояния.
Чтобы минимизировать затраты времени на обработку данных и обучение, нам необходимо организовать параллельное выполнение модулей на стороне OpenCL-контекста. Здесь ключевой момент заключается в структуре алгоритма GRU. Если внимательно рассмотреть операции обновления скрытых состояний, то большая часть из них выполняется поэлементно, без взаимозависимости между различными каналами.
Это означает, что независимо от числа модулей, при правильной организации исходных данных, можно реализовать их работу так, чтобы OpenCL-программа воспринимала несколько модулей как один, выполняя вычисления параллельно. Таким образом, мы можем эффективно использовать вычислительные ресурсы GPU, сохраняя точность и корректность агрегации данных, но значительно ускоряя анализ данных и обучение модели.
На практике это потребует структурирования данных, продуманной разметки каналов и использования поэлементных операций на стороне OpenCL-программы для максимальной параллелизации. Такой подход позволит нам объединить работу нескольких ConvGRU в единый высокопроизводительный блок, что особенно важно для финансовых временных рядов с большим потоком событий и высоким разрешением временной модели.
Для реализации предложенного подхода, на стороне OpenCL-программы создаётся новый кернел, который позволяет эффективно обрабатывать скрытые состояния модуля параллельно, используя возможности GPU. Кернел принимает на вход три массива:
- XH — конкатенированный тензор необходимых проекций анализируемых данных и скрытого состояния;
- prev_state — последнее скрытое состояние;
- outputs — буфер для записи результатов (новое скрытое состояние модуля).
__kernel void GRU(__global const float* XH, __global const float* prev_state, __global float* outputs ) { const size_t id = get_global_id(0); const size_t d = get_global_id(1); const size_t units = get_global_size(0); const size_t dimension = get_global_size(1);
Каждый поток операций получает свои индексы, которые определяют, какую переменную и какой элемент в векторе её описания он обрабатывает. Эти индексы позволяют корректно адресовать данные в линейных массивах и обеспечить правильное соответствие между нейронами и каналами признаков.
При обращении к анализируемым данным GRU извлекаются шесть значений, соответствующие стандартной формуле GRU: компоненты для reset-гейта, update-гейта и кандидата нового состояния, как для входной, так и для рекуррентной части. Чтобы гарантировать устойчивость вычислений, все извлечённые значения проверяются на наличие NaN или бесконечностей.
const float xz = IsNaNOrInf(XH[RCtoFlat(0, d, 6, dimension, id)], 0); const float xr = IsNaNOrInf(XH[RCtoFlat(1, d, 6, dimension, id)], 0); const float xh = IsNaNOrInf(XH[RCtoFlat(2, d, 6, dimension, id)], 0); const float hz = IsNaNOrInf(XH[RCtoFlat(3, d, 6, dimension, id)], 0); const float hr = IsNaNOrInf(XH[RCtoFlat(4, d, 6, dimension, id)], 0); const float hh = IsNaNOrInf(XH[RCtoFlat(5, d, 6, dimension, id)], 0); const float prev = IsNaNOrInf(prev_state[RCtoFlat(id, d, units, dimension, 0)], 0);
Следующий шаг — вычисление самих элементов GRU. Сначала вычисляются reset-гейт и update-гейт с использованием сигмоидальной функции активации. Они определяют, какую часть предыдущего состояния нужно сохранить, а какую — заменить.
float r = fActivation(xr + hr, ActFunc_SIGMOID); float z = fActivation(xz + hz, ActFunc_SIGMOID); float ht = fActivation(r * hh + xh, ActFunc_TANH); float out = (1 - z) * prev + z * ht;
Затем формируется кандидат нового скрытого состояния, где reset-гейт применяется к рекуррентной части, и к результату добавляется входной вклад, проходящий через гиперболический тангенс для нормализации. После этого вычисляется окончательный выход GRU как комбинация предыдущего состояния и нового кандидата, управляемая значением update-гейта.
Наконец, этот результат записывается в массив outputs, предварительно снова проверяясь на корректность значений.
outputs[RCtoFlat(id, d, units, dimension, 0)] = IsNaNOrInf(out, 0); }
Главная особенность такой реализации заключается в том, что каждая операция выполняется поэлементно, а значит, независимо от количества модулей ConvGRU, их работу можно организовать как единый параллельный процесс. Правильная структура данных позволяет OpenCL-программе одновременно обрабатывать все нейроны и каналы, обеспечивая высокую производительность и минимальные задержки.
Такой подход особенно эффективен для работы с микрособытиями финансового рынка, где требуется быстрое и точное агрегирование информации из многочисленных источников. Параллельная организация работы модулей обеспечивает не только ускорение вычислений, но и стабильное сохранение всех ключевых особенностей скрытых состояний, что критически важно для дальнейшей работы сети и обучения на больших временных рядах.
В работе GRU-кернела обучение параметров напрямую не происходит, поскольку он лишь выполняет поэлементные вычисления скрытых состояний и выходов. Тем не менее, для корректного обучения модели нам необходимо распределить градиенты по всем элементам процесса. Данный функционал выполняется специализированным кернелом GRU_Grad, который обеспечивает вычисление градиентов для каждого входа и скрытого состояния, сохраняя структуру параллельной обработки на GPU.
Кернел принимает на вход массив XH с предварительно вычисленными входами GRU, массив prev_state с предыдущими состояниями скрытого слоя и массив outputs_gr, содержащий градиенты по выходам. Массив XH_gr предназначен для записи вычисленных градиентов входов.
__kernel void GRU_Grad(__global const float* XH, __global float * XH_gr, __global const float* prev_state, __global const float* outputs_gr ) { const size_t id = get_global_id(0); const size_t d = get_global_id(1); const size_t units = get_global_size(0); const size_t dimension = get_global_size(1);
Каждый поток операций получает свои индексы переменной и размерности данных, что позволяет корректно обращаться к элементам многомерных массивов, преобразованных в линейные.
const float xz = IsNaNOrInf(XH[RCtoFlat(0, d, 6, dimension, id)], 0); const float xr = IsNaNOrInf(XH[RCtoFlat(1, d, 6, dimension, id)], 0); const float xh = IsNaNOrInf(XH[RCtoFlat(2, d, 6, dimension, id)], 0); const float hz = IsNaNOrInf(XH[RCtoFlat(3, d, 6, dimension, id)], 0); const float hr = IsNaNOrInf(XH[RCtoFlat(4, d, 6, dimension, id)], 0); const float hh = IsNaNOrInf(XH[RCtoFlat(5, d, 6, dimension, id)], 0); const float prev = IsNaNOrInf(prev_state[RCtoFlat(id, d, units, dimension, 0)], 0); const float grad = IsNaNOrInf(outputs_gr[RCtoFloat(id, d, units, dimension, 0)], 0);
На основе извлечённых значений входов и предыдущих состояний вычисляются внутренние компоненты GRU: reset-гейт, update-гейт и кандидат нового состояния.
float r = fActivation(xr + hr, ActFunc_SIGMOID); float z = fActivation(xz + hz, ActFunc_SIGMOID); float ht = fActivation(r * hh + xh, ActFunc_TANH);
Затем на этих значениях выполняются обратные операции, которые рассчитывают градиенты по каждому элементу: градиент кандидата скрытого состояния умножается на update-гейт, градиент update-гейта формируется через разницу между новым и предыдущим состоянием, после чего применяются обратные функции активации к соответствующим компонентам входов.
float ht_grad = IsNaNOrInf(grad * z, 0); float z_grad = IsNaNOrInf(grad * (ht - prev), 0); float xh_grad = Deactivation(ht_grad, ht, ActFunc_TANH); float hh_grad = IsNaNOrInf(xh_grad * r, 0); float r_grad = IsNaNOrInf(xh_grad * hh, 0); float xz_grad = Deactivation(z_grad, z, ActFunc_SIGMOID); float hz_grad = xz_grad; float xr_grad = Deactivation(r_grad, r, ActFunc_SIGMOID); float hr_gra = xr_grad;
Результатом работы кернела является распределение градиентов по всем частям GRU — входным компонентам XH и рекуррентной части скрытого состояния. Вычисленные градиенты записываются в массив XH_gr с той же структурой, что и исходные данные, с проверкой на корректность чисел через IsNaNOrInf.
XH_gr[RCtoFlat(0, d, 6, dimension, id)] = IsNaNOrInf(xz_grad, 0); XH_gr[RCtoFlat(1, d, 6, dimension, id)] = IsNaNOrInf(xr_grad, 0); XH_gr[RCtoFlat(2, d, 6, dimension, id)] = IsNaNOrInf(xh_grad, 0); XH_gr[RCtoFlat(3, d, 6, dimension, id)] = IsNaNOrInf(hz_grad, 0); XH_gr[RCtoFlat(4, d, 6, dimension, id)] = IsNaNOrInf(hr_grad, 0); XH_gr[RCtoFlat(5, d, 6, dimension, id)] = IsNaNOrInf(hh_grad, 0); }
Такой подход позволяет сохранить параллельность вычислений на GPU, гарантируя, что каждый элемент получает свой градиент независимо от других потоков.
В итоге GRU_Grad обеспечивает необходимую основу для обратного распространения ошибки через несколько уровней ConvGRU, сохраняя полную совместимость с параллельной организацией модулей на OpenCL. Это особенно важно при работе с финансовыми временными рядами, где скорость и точность распространения градиентов напрямую влияют на эффективность обучения и качества прогнозов, генерируемых моделью.
Полный код OpenCL-программы представлен во вложении.
Сегодня мы проделали значительную работу и заслужили небольшой перерыв, чтобы дать мозгу передышку и оценить проделанное. В следующей статье, набравшись новых сил, мы продолжим реализацию ключевых подходов, предложенных авторами фреймворка EV-MGRFlowNet, средствами MQL5, углубляясь в практическую сторону. Шаг за шагом будем приближаться к полноценной интеграции предложенных алгоритмов в анализ финансовых рынков.
Заключение
В этой работе мы подробно рассмотрели архитектуру фреймворка EV-MGRFlowNet и показали, как его ключевые компоненты — FERE-Net с модулем ST-ConvGRU и FGD-Net — позволяют эффективно моделировать микродвижения. Основное преимущество такой архитектуры заключается в её способности полностью сохранять пространственно-временные паттерны событий, обеспечивая точное прогнозирование на основе мельчайших сигналов.
Параллельная организация работы модулей на стороне OpenCL-контекста обеспечивает высокую производительность без потери точности, что критически важно для обработки больших потоков рыночных данных в реальном времени. Гибкость и масштабируемость структуры позволяют легко адаптировать модель к различным инструментам и временным интервалам, а использование гибридного подхода к обучению через HMC-Loss гарантирует устойчивое и точное восстановление потоков событий.
Ссылки
- EV-MGRFlowNet: Motion-Guided Recurrent Network for Unsupervised Event-based Optical Flow with Hybrid Motion-Compensation Loss
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования