
Нейросети в трейдинге: Пространственно-временная модель состояния для анализа финансовых данных (E-STMFlow)

Ведение
Рынок живёт не по расписанию. Он движется рывками, меняя темп. То ускоряется, то затихает. Каждое событие (сделка, всплеск объёма, резкий импульс) подобно короткой вспышке, изменяющей ход всей конструкции. Финансовые данные давно перестали быть спокойным, плавным рядом чисел. Они больше похоже на поток искр, в котором каждое мгновение рождается новая часть картины. И именно здесь возникает главная трудность: многие модели просто не успевают уловить эту живую динамику.
Традиционные методы всё ещё смотрят на рынок как на последовательность равномерных точек: им нужны фиксированные шаги, ровные интервалы, аккуратно выровненные данные. Но рынок не знает, что такое ровный интервал. Он дёргается, пульсирует, создаёт события там, где секунду назад было пусто. Когда модель требует идеально отформатированных данных, она теряет саму суть — бесконечную асинхронность реального потока. Она видит только итог, но упускает процесс.
Эта проблема особенно заметна в высокочастотных данных. Сделки приходят вразнобой. Ликвидность меняет направление без предупреждения. Стакан дышит быстрее, чем любая классическая модель способна обработать. Одни алгоритмы слишком медленные. Другие — слишком поверхностные. Трансформеры дают мощные представления, но требуют слишком много вычислений. Рекуррентные модели реагируют быстрее, но легко теряют связь между событиями. В итоге исследователь снова оказывается перед выбором: скорость или глубина. А рынок требует и то и другое одновременно.
Наблюдая за такой картиной, хочется модель, которая могла бы двигаться вместе с рынком, а не догонять его. Модель, которая реагирует на каждое событие так же легко, как маятник реагирует на новый толчок. Модель, которая хранит в памяти внутреннее состояние рынка — его скрытый импульс, давление ликвидности, настроение участников, и обновляет его каждый раз, когда появляется новая точка данных.
Именно здесь идея модели состояния начинает работать особенно хорошо. Она не фиксирует рынок в единичных точках, а описывает его как непрерывный процесс. Состояние меняется плавно. Каждое событие не просто регистрируется, а влияет на эволюцию всей системы.
В работе "Spatio-Temporal State Space Model for Efficient Event-Based Optical Flow" был предложен новый подход для решения задачи, на первый взгляд далёкой от финансовых рынков, но удивительно близкой по своей внутренней логике. Фреймворк создавался для обработки событийных данных, поступающих от динамических сенсоров, которые фиксируют изменения в наблюдаемом пространстве. Это поток микрособытий, каждое из которых несёт сигнал о локальном движении. В этой среде нет равномерных кадров, нет фиксированных интервалов. Только непрерывный поток изменений, который требует модели, способные работать с живым, асинхронным сигналом.
Создатели фреймворка E-STMFlow предложили систему, которая описывает динамику сцены через скрытое состояние, обновляемое при каждом новом событии. Это состояние живёт непрерывно, словно тонкая нить, протянутая через весь поток данных. Модель не ждёт накопления информации, не собирает крупные блоки, а реагирует на каждую микровспышку. Пространственная компонента отражает то, где возникло событие, а временная — когда. Вместе они образуют структуру, которая позволяет отслеживать движение так же легко, как глаз улавливает смещение объекта в периферическом зрении.
Архитектура использует линейные переходы состояния и эффективные обновления, а вычисления проходят быстро и почти без лишних операций. Модель не пытается хранить всю историю, она хранит саму суть — текущий вектор внутренней динамики.
Такой подход дал модели несколько важных преимуществ. Во-первых, высокую скорость: отсутствие тяжёлых вычислительных блоков позволяет выполнять обновления практически мгновенно. Во-вторых, компактность: модель обходится малым количеством параметров, поэтому она устойчивее к шуму и не требует огромных мощностей. В-третьих, способность работать с асинхронными данными: фреймворк создан специально для нерегулярных потоков событий, где важна реакция на каждую точку, а не на искусственно созданную сетку времени. И наконец, высокую точность: скрытое состояние помогает улавливать движение не как сумму отдельных фрагментов, а как непрерывный процесс. Это делает модель особенно устойчивой в сложных динамических условиях.
Для финансовых рынков эта логика оказывается удивительно естественной. Рынок, как и сенсор событий, генерирует сигнал не равномерно, а вспышками. Каждая сделка — это маленькое событие, которое сдвигает всю систему. Потоки ликвидности напоминают движение текстуры на изображении, а всплески активности похожи на локальные изменения яркости. Рынок тоже меняется непрерывно, хотя мы наблюдаем его в дискретных данных. И если рассматривать его как непрерывный процесс скрытых состояний, то можно уловить такие структуры, которые в традиционных моделях просто растворяются в шуме.
Преимущества фреймворка оказываются особенно значимы именно здесь. Его событийная природа идеально ложится на асинхронный поток сделок и заявок. Способность обновлять внутреннее состояние при каждом событии позволяет моделировать рынок практически в реальном дыхании. Компактность делает модель устойчивой к рыночному шуму, который неизбежно окружает каждое движение цены. А пространственно-временная структура даёт возможность видеть рынок не только как последовательность сделок, но и как динамическое информационное поле, в котором каждая вспышка активности становится частью общего движения.
В результате мы получаем подход, который может стать прямым мостом между аналитикой и реальным поведением рынка. Он делает анализ более гибким, быстрым и точно отражающим структуру событий. Такой фреймворк не пытается подогнать рынок под свои правила — наоборот, он подстраивается под его естественный ритм. И именно благодаря этому он может стать основой для нового класса моделей, способных видеть за изменением цены скрытые процессы, которые управляют её движением.
Алгоритм E-STMFlow
Понять логику E-STMFlow проще всего, если начать с основ оптического потока. Той самой базы, которая десятилетиями определяла методы анализа движения. В оптическом потоке всё строится на предположении постоянства яркости. Если точка на изображении смещается, но её яркость остаётся прежней, выполняется фундаментальное соотношение:
![]()
В трейдинге есть похожая идея. Цена сама по себе мало о чём говорит, пока мы не учитываем её связь с изменениями во времени. Точно так же и здесь — важно, как интенсивность меняется в пространстве и в динамике.
Разложение яркости в ряд Тейлора приводит к классическому уравнению оптического потока:
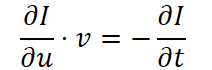
Здесь v — скорость движения.
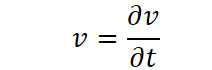
Это уравнение связывает пространственные и временные производные изображения. Очень похоже на ситуацию на рынке, где изменения цены зависят не только от текущего уровня, но и от мгновенной динамики спроса и предложения.
Однако для однозначного определения потока только этого уравнения недостаточно. Поэтому вводится допущение о пространственной согласованности, напоминающее взгляд трейдера, который оценивает рынок по локальному контексту. Для набора точек в окрестности Ω(u,t) задача сводится к минимизации квадратичной ошибки:

Аналитическое решение получается в закрытом виде:
![]()
Mатрицы Φ и Θ содержат пространственные и временные производные, соответственно. Этот вывод подчёркивает, что корректная оценка потока невозможна без одновременного учёта пространства и времени. Именно здесь становится понятно, почему многие современные методы вводят громоздкие четырёхмерные корреляционные тензоры и тянут за собой контекстные события. Они как аналитики, которые пытаются подстраховаться, собирая избыточное число индикаторов. Формально это работает, но эффективность таких подходов оставляет вопросы, ведь обработка лишнего контекста снижает скорость и увеличивает вычислительные затраты.
Авторы фреймворка справедливо замечают, что проблему можно решить гораздо изящнее, если взглянуть на структуру событийного потока с позиции динамической системы. Каждое событие ek(t) = (uk, vk, tk, pk) представляет собой компактный набор информации о пространственно-временных координатах и знаке изменения яркости. Событие возникает, когда изменение интенсивности достигает порога.
![]()
Этот порог C — как минимальный размер тикового движения на рынке, который должен быть превышен, чтобы торговый алгоритм посчитал это значимым сигналом.
Если временной интервал мал, то изменение интенсивности можно аппроксимировать.
![]()
Тогда условие возникновения события принимает форму:
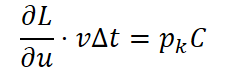
Вместе с уравнением оптического потока это даёт важный вывод: каждое событие содержит информацию о движении. Похожим образом в тиковых данных каждая микроструктурная сделка отражает внутреннее ускорение или замедление рынка — короткая вспышка динамики, которая в совокупности формирует полноценный поток.
И если события уже несут в себе движение, то нет необходимости строить тяжёлые 4D-корреляционные структуры. Вместо этого авторы предлагают рассматривать последовательность событий как эволюцию состояния системы. Такая трактовка открывает путь к стохастической модели, где движение описывается внутренней динамикой, а не внешними корреляциями. На этой базе формируется STSSM-блок — сердце новой архитектуры, позволяющей эффективно кодировать динамику событийных данных. И эта идея особенно хорошо перекладывается на финансовый анализ, где компактность, скорость и способность удерживать скрытое состояние системы становятся ключевыми преимуществами перед классическими, тяжёлыми методами обработки потока рыночных данных.
Когда речь заходит о моделях, способных удерживать динамику во времени, невозможно обойти стороной классическое состояние системы, описываемое через линейно-временной инвариантный подход. Эта идея, старая как инженерия автоматических систем, неожиданно органично ложится на анализ сложных потоков данных — будь то события в видеокамере или рыночные тики, формирующие движение цены. И хотя на первый взгляд такие явления относятся к разным мирам, математическая структура, описывающая их динамику, удивительно схожа.
Линейно-временной инвариантный подход даёт инструмент, позволяющий формулировать эволюцию состояния в виде матричного уравнения.
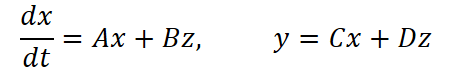
Данное уравнение по своей сути напоминает модель, отслеживающую движение цены под действием внешних сил. Состояние X(t) — это почти как скрытые рыночные факторы: трендовая составляющая, волатильность, моментум. Вход Z(t) — поток наблюдаемых изменений, будь то яркость пикселей или изменения цены. А выход Y(t) — это наша попытка извлечь полезный сигнал.
Матрица A, управляющая динамикой, играет роль своеобразного генерального плана системы. Она задаёт, как текущее состояние влияет на будущее, аналогично тому, как реальные рыночные процессы наследуют историческую структуру. Долгие периоды спокойствия сменяются взрывами активности, и всё это подчиняется скрытым законам.
Матрицы B и C определяют, насколько сильно вход меняет состояние, и насколько точно состояние отражается в наблюдении. Это похоже на то, как разные рынки по-разному реагируют на один и тот же новостной импульс: где-то влияние мгновенное, а где-то растянутое.
Но сама по себе непрерывная модель не всегда удобна для практических вычислений. Поэтому систему переводят в дискретный формат, используя, например, метод удержания нулевого порядка. Это превращает динамику в последовательность шагов.
![]()
А переход между состояниями принимает форму:
![]()
Такой формат даёт гибкость, которую невозможно получить в обычных рекуррентных моделях. И это критически важно, когда работаешь с плотными потоками событий, где нужно учитывать и связь во времени, и связь в пространстве. В мире финансов такая модель ярко напоминает высокочастотный анализ. Данные приходят асинхронно, интервалы между событиями неравномерны, а каждая новая точка на графике добавляет к общей картине крошечный, но значимый фрагмент информации. Структурированные SSM-модели на этом фоне выглядят настоящими рабочими лошадками — мощными, экономичными, способными обрабатывать длинные последовательности, не теряя устойчивости.
И всё же прогресс не стоит на месте. Стало ясно, что даже структурированного состояния иногда недостаточно, чтобы уловить богатую динамику событийного потока. Так родилась идея сделать параметры модели зависимыми от исходных данных. Это, по сути, адаптивность. Вместо статичной системы мы получаем живой организм, способный менять свои свойства в зависимости от того, какой поток данных поступает внутрь. Так появился механизм выбора, ставший сердцем архитектуры Mamba.
В этом подходе временной шаг Δ, а также матрицы B и C перестают быть фиксированными. Они подстраиваются под анализируемый поток, создавая линейно-временнóй вариант системы. В результате такая модель способна реагировать на сложные и высокочастотные события почти как опытный трейдер, который видит, когда рынок становится нервным, замечает фазовые переходы и меняет чувствительность в зависимости от структуры входящего потока.
В контексте оценки движения это особенно важно. Оптический поток, как известно, требует не только временной, но и пространственной согласованности. Многие подходы используют две последовательные во времени проекции данных — опорную и целевую. Это позволяет построить соответствие между ними. Но если окно событий достаточно велико, становится возможным полностью отказаться от этой схемы. Сама последовательность оказывается достаточной для восстановления движения FtR→tT.
Это похоже на анализ рынка, когда при достаточно богатой тиковой истории можно извлечь направление тренда без привлечения дополнительных агрегированных данных. Каждый тик — это событие. Каждая вспышка активности — часть скрытого движения. И если окно истории достаточно широкое, мы можем восстановить структуру динамики напрямую.
4D-корреляционные объёмы, которыми перегружены многие современные методы, в таком случае становятся излишними. Они громоздки, едят память, неэффективны. Намного естественнее, и математически изящнее, извлекать пространственно-временные зависимости с помощью моделей состояния, которые делают это напрямую из потока событий. Именно такая архитектура открывает путь к более быстрым, лёгким и точным алгоритмам анализа динамики.
И что особенно важно в контексте финансовых рынков, подобный подход позволяет строить модели, которые не боятся длинных временных последовательностей и не захлёбываются от плотности событий. Они способны учитывать как краткосрочные всплески, так и долгосрочную структуру данных. Spatio-Temporal State Space Model даёт инструментарий, который по духу ближе к реальному рынку: динамичный, адаптивный, способный работать там, где традиционные методы начинают буксовать.
При переходе к построению архитектуры модели становится понятно, что именно форма исходных данных определяет стиль всей последующей обработки. Модель не может прыгнуть выше данных, и потому первым делом авторы фреймворка бережно формируют объём событий в виде компактной трёхмерной сетки. Время становится такой же осью, как цена и объём в биржевых лентах.
Именно 3D-представление событий служит фундаментом для аккуратного извлечения динамики. E-STMFlow принимает поток событий и превращает его в равномерный тензор. Простой, но точный аналог свечного графика, где цена сглажена во времени, но каждая микроструктурная деталь остаётся на своём месте.
По сути, авторы фреймворка аккуратно распределяют вклад каждого события по ближайшим координатам в пространстве и времени, максимально снижая дискретизационную ошибку. Это похоже на аккуратное построение объёмного профиля рынка. Каждое совершенное на рынке действие даёт свой небольшой вклад в общую плотность ликвидности. И чем больше таких вкладов, тем яснее становится структура движения.
Получив такое компактное представление, модель дальше работает как опытный аналитик, который умеет смотреть на рынок в непрерывной ленте. Для него важны не только локальные всплески, но и вся накопленная история импульса. Специально разработанный пространственно-временной энкодер проходит через этот объём серией STSSM-блоков. Каждый блок бережно вылавливает связи между соседними моментами времени, фиксирует пространственные контрасты и оценивает общую динамику сцены. В этом есть сходство с поведением торговой системы, которая одновременно смотрит и на тренд, и на локальные возмущения, и на их взаимодействие.
На каждом шаге пространственные и временные размеры выходных гиперобъёмов уменьшаются, но каналов становится больше. Так модель будто сжимает пространство и время, чтобы расширить смысл. Такой подход не случаен. Чем меньше остаётся пространства, тем больше сеть смотрит вглубь. Как трейдер, который начинает с общего плана рынка, а затем переключается на короткие импульсы, чтобы ухватить микродвижение. Финальный STSSM-блок держит пространство прежним, но собирает время в единичный слой. В результате появляются чистые двумерные карты признаков, насыщенные и компактные — идеальный материал для финального прогноза.
Здесь подходим к описанию STSSM-блока. Именно в нем скрыта главная инженерная изюминка всей архитектуры. Этот блок работает как опытный аналитик временных рядов, который не нуждается в громоздких многоуровневых корреляционных структурах. Вместо традиционных 4D-корреляционных объёмов, использующих два соседних состояния, авторы фреймворка берут один сплошной пространственно-временной массив и извлекают корреляции прямо внутри него. Аккуратно, без лишних вычислительных трат. Это напоминает переход от методов кластеризации объёмов сделок к современным моделям пространства-состояний, которые читают структуру рынка по одной непрерывной ленте.
Чтобы STSSM мог работать с таким массивом данных, авторы фреймворка предложили начать с пространственно-временного патчинга. Видеоданные имеют удобную структуру: каждый кадр — момент, а каждый момент — картинка. Но события, как и тиковые данные на рынке, ведут себя сложнее. Они могут быть редкими на спокойном участке и плотными, почти взрывообразными, когда начинается резкое движение. Один временной интервал далеко не всегда содержит нужный контекст, поэтому создаём трёхмерные патчи размера (m×k×k) для каждого из C каналов мультимодального массива данных. В результате временная ось приобретает новую структуру. Количество временных блоков становится равным Nt = T/m. Таким образом, заставляем данные говорить более связно — как если бы тиковый поток разбивали на интервалы не по секундам, а по смысловым кускам.
После патчинга наступает очередь проекции. Здесь нужно превратить каждый объёмный патч в аккуратный одномерный вектор, удобный для последовательной обработки. Линейный слой делает это быстро и без осложнений. Напоминает процесс, когда сложное распределение сделок превращают в набор факторов — всё лишнее остаётся за скобками, внутри только информативный вектор состояния.
Однако у нас последовательности особенные. Они состоят из перемешанных пространственных и временных компонент, и чтобы модель могла работать как LTI-система, необходимо развести их по разным координатным осям. Для этого авторы фреймворка вводят временные эмбеддинги, которые аккуратно, без лишнего шума, размечают позиции во времени. Это похоже на метки времени в финансовых данных, которые позволяют системе понимать, где именно она находится — внутри спокойного рынка или на пороге резкого импульса. Любопытно, что классические методы позиционного кодирования здесь оказываются не просто ненужными, но даже вредными. Модель начинает вести себя тяжелее и менее устойчиво.
Когда структура подготовлена, последовательность передается в блок Seq-to-Seq преобразования. Здесь в игру входит Mamba — архитектура, которая в последние годы стала чем-то вроде умного фильтра для длинных последовательностей. По аналогии с торговыми алгоритмами это похоже на систему, которая не пытается строить полный граф корреляций между всеми ценами, а обновляет состояние линейно, шаг за шагом, но с глубоким пониманием динамики. Именно здесь модель учится улавливать пространственно-временные связи без 4D-пирамид и дорогостоящих сверточных каскадов.
Получив выходную последовательность, возвращаем данные обратно в пространственно-временной мир. Репроекция работает как обратная сборка: каждый вектор D×1 преобразуется в 2D-патч с помощью набора из C ядер размером (D×l×l). Это похоже на восстановление полной рыночной картины из набора факторов: сначала компактное представление, затем разворот обратно в плотное поле состояний.
Результат — точное, плавное пространственно-временное представление, полученное без лишних вычислительных затрат и способное соперничать с гораздо более тяжёлыми архитектурами. На финансовых данных такая конструкция будет вести себя как лёгкая, но умная система анализа рынка, которая не перегружена историей и корреляциями, но прекрасно понимает динамику.
Когда признаки достаточно созрели, на сцену выходит финальная голова прогнозирования — модуль, который на основе накопленных пространственно-временных признаков восстанавливает плотное поле движения на полном разрешении. Это похоже на последнюю стадию анализа рынка, когда после долгого выстраивания статистики система делает окончательный, чёткий торговый прогноз.
Логика процесса достаточно прозрачна: сначала последовательно уплотняем события, вытягиваем из них динамику, усиливаем пространственно-временные паттерны и выводим финальную оценку. Гладкость всей конструкции обеспечивается тем, что каждая стадия взаимодействует с предыдущей как элемент единого аналитического цикла. Это делает архитектуру естественной, понятной и устойчивой.
Авторская визуализация фреймворка E-STMFlow представлена ниже.


Реализация средствами MQL5
После того как мы разобрали теоретические основы фреймворка E-STMFlow, самое время перейти к практической части. Показать, как ключевые идеи можно воплотить средствами MQL5. Здесь важно сразу уточнить. Мы не пытаемся в точности воспроизвести авторскую модель. Вместо этого мы берем её фундаментальные принципы и адаптируем под собственную архитектуру, ориентированную на обработку событий в спайковом формате. Такой подход органично ложится на специфику анализа потоков данных, где важны скорость реакции, экономия вычислительных ресурсов и умение извлекать структуру из разреженных сигналов.
Впереди нас ждет колоссальная работа. Но хвататься за всё одновременно — неверный путь. Разделим фреймворк на отдельные модули и реализуем их последовательно, шаг за шагом. Так мы сохраняем ясность, экономим время и уменьшаем риск ошибок.
На первом этапе мы объединим механизмы патчинга и генерации эмбеддингов, но подойдем к этому делу немного нестандартно. В оригинальной модели авторы предлагают нарезать трёхмерные патчи — словно кубики, которые охватывают изображение во времени. В финансовых данных картина немного другая. У нас обычно мультимодальные последовательности, где каждый канал — это всего лишь одномерная цепочка значений. В таком случае трёхмерные патчи вырождаются в простые одномерные векторы, и кажется, что пространственная связь между признаками теряется.
Попробуем её восстановить. Можно объединять в патчи признаки, которые соседствуют в векторе состояния. Но тут есть ловушка. Близость в векторе не всегда соответствует реальной корреляции между признаками. И вот тут на сцену выходит волшебство предложенной авторами E-STMFlow архитектуры энкодера. Подобно сверточной сети, он постепенно расширяет окно обзора, шаг за шагом охватывая весь объём данных. В итоге модель видит полную картину и умеет улавливать взаимосвязи между признаками, где бы они ни находились.
Это значит, что мы спокойно можем объединять элементы в патчи, не боясь упустить важное. Даже в виде одномерных последовательностей финансовых данных модель остаётся способной распознавать сложные взаимосвязи, создавать богатые эмбеддинги и подготавливать информацию для следующих этапов анализа.
Второй момент касается нарезки патчей по временной оси. Финансовый рынок никогда не стоит на месте, и мы имеем дело не с зафиксированным кадром, а с непрерывным потоком событий. Теоретически можно взять исторические данные, нарезать их на патчи и работать с ними, словно с готовым снимком рынка. Но на практике нам нужна система онлайн-анализа, которая реагирует на каждый новый тик или изменение цены.
Повторно обрабатывать всю историю при появлении каждого события было бы крайне накладно и неэффективно — это всё равно что пытаться пересчитать весь график сделок каждый раз, когда появляется новая котировка. Нам нужен подход, который позволяет обновлять анализ постепенно, аккуратно и без лишней перегрузки, сохраняя точность и полноту картины.
И здесь, на мой взгляд, наиболее естественным решением выглядит использование стека. Каждое новое событие попадает в стек, хранится там определённое время и участвует в формировании эмбеддингов. Таким образом, мы всегда имеем под рукой актуальный набор данных для анализа.
Но сразу возникает вопрос: зачем при появлении одного нового события пересчитывать эмбеддинги для всего стека? Это слишком накладно и неэффективно. Гораздо разумнее класть в стек уже готовые эмбеддинги, а не сырые данные. Тогда каждый новый тик будет лишь добавлять свежий вектор состояния, а не заставлять систему заново обрабатывать всю историю. Такой подход позволяет поддерживать онлайн-анализ с минимальными вычислительными затратами, сохраняя точность и полноту картины рынка.
Следующий вопрос касается непосредственного учёта событий. Рынок полон мелких колебаний и шумов, которые сами по себе не несут существенной информации, но могут сильно загромождать анализ. Как их отделить от действительно значимых изменений?
Здесь на помощь приходит спайковая система с обучаемым порогом срабатывания. Каждый входящий сигнал оценивается относительно порога: только события, превышающие порог, превращаются в спайки и участвуют в формировании эмбеддингов. Такой механизм позволяет автоматически фильтровать шум и одновременно сохранять чувствительность к значимым движениям рынка. При этом порог можно адаптировать в процессе обучения модели, чтобы система сама определяла, какие колебания стоит учитывать, а какие игнорировать.
В результате мы получаем аккуратный поток событий, очищенный от лишнего шума — похожий на график Ренко, где учитываются только значимые движения. При этом каждый канал может получать свой собственный шаг, адаптированный под специфику конкретного признака. Предложенный подход позволяет выстроить точную и компактную эмбеддинговую репрезентацию финансового потока.
В рамках нашей работы предложенное архитектурное решение для работы со спайковыми событиями и стеком эмбеддингов реализовано в классе CNeuronSpikePatchStak, который наследует функциональность базового стека CNeuronAddToStack.
class CNeuronSpikePatchStak : public CNeuronAddToStack { protected: CNeuronSpikeConvBlock cBlock; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikePatchStak(void) {}; ~CNeuronSpikePatchStak(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint dimension, uint patch_dimension, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikePatchStak; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Внутри класса размещён ключевой компонент — блок спайковой свёртки cBlock (CNeuronSpikeConvBlock), отвечающий за генерацию эмбеддингов из патчей.
Напомню, что класс CNeuronSpikeConvBlock заимствован из фреймворка SDformerFlow. Он включает в себя 3 нейронных слоя:
- спайковой активации,
- сверточный слой,
- пакетной нормализации.
Этот блок обеспечивает весь необходимый функционал для формирования информативных эмбеддингов.
Иными словами, именно CNeuronSpikeConvBlock превращает сырые данные событийного потока в компактные, но богатые по информации векторы признаков. Благодаря сочетанию спайковой активации и сверточной обработки, блок умеет фильтровать шум, выявлять ключевые зависимости и одновременно поддерживать структуру эмбеддингов, пригодную для последующих STSSM-блоков. Такой подход позволяет нам строить качественные представления данных, не теряя важной динамики рынка и сохраняя вычислительную эффективность.
Для инициализации класса используется метод Init, который задаёт все необходимые параметры для корректной работы стека эмбеддингов и спайкового блока.
bool CNeuronSpikePatchStak::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint dimension, uint patch_dimension, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronAddToStack::Init(numOutputs, myIndex, open_cl, stack_size, patch_dimension, variables, optimization_type, batch)) return false; if(!cBlock.Init(0, 0, OpenCL, dimension, dimension, patch_dimension, variables, 1, optimization, iBatch)) return false; //--- return true; }
Сначала вызывается одноименный метод родительского класса, где определяется размер стека и параметры оптимизации. Если этот шаг проходит успешно, инициализируется вложенный блок cBlock, отвечающий за генерацию эмбеддингов. Ему передаются размерности входа и выхода, параметры патчей и переменных.
Таким образом, метод инициализации гарантирует, что стек и спайковый свёрточный блок полностью готовы к работе. В случае любой ошибки инициализации возвращается false, что позволяет надёжно контролировать корректность конфигурации перед запуском обучения или обработки данных.
Алгоритм прямого прохода реализован в методе feedForward. Сначала вызывается прямой проход вложенного блока cBlock, который обрабатывает входящие данные событийного потока и формирует эмбеддинги. Если этот шаг проходит успешно, результат передаётся в родительский класс CNeuronAddToStack, где обновляется стек эмбеддингов.
bool CNeuronSpikePatchStak::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cBlock.FeedForward(NeuronOCL)) return false; //--- return CNeuronAddToStack::feedForward(cBlock.AsObject()); }
Такой подход позволяет модели эффективно работать с потоками событий, минимизируя вычислительные затраты и сохраняя актуальность данных для онлайн-анализа рынка.
В итоге CNeuronSpikePatchStak становится ядром нашей системы онлайн-анализа событийного потока, аккуратно объединяя патчи, фильтруя шум и поддерживая стек эмбеддингов для последующей обработки в STSSM-блоках.
Мы хорошо потрудились и заслуживаем небольшой отдых. В следующей статье продолжим нашу работу, углубляясь в обработку эмбеддингов и построение полноценного STSSM-потока для анализа финансовых событий.
Заключение
В данной статье мы познакомились с фреймворком E-STMFlow и начали его адаптацию для анализа финансовых потоков. Основным преимуществом подхода является способность эффективно обрабатывать спайковые события в онлайн-режиме, извлекая информативные эмбеддинги из потоков данных с высокой временной и пространственной разрешающей способностью.
Использование стека эмбеддингов и спайковых механизмов с обучаемым порогом позволяет фильтровать шум и сосредоточиться на значимых изменениях рынка, сохраняя при этом вычислительную эффективность. Архитектура энкодера обеспечивает анализ сложных взаимосвязей между признаками, даже если исходные данные представлены одномерными временными рядами.
В итоге E-STMFlow предлагает универсальное и масштабируемое решение для построения моделей, способных выявлять скрытые закономерности и динамику финансового рынка. Этот фреймворк открывает новые возможности для онлайн-прогнозирования, автоматизации анализа и разработки интеллектуальных торговых систем, сочетая точность, эффективность и гибкость в обработке сложных потоков данных.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования