
Нейросети в трейдинге: Рекуррентное моделирование микродвижений рынка (Окончание)

Введение
Рынок по-прежнему остаётся той самой сложной многослойной системой, где каждое микрособытие, будь то всплеск объёма или сдвиг баланса ликвидности, формирует собственную траекторию движения. Мы наблюдаем эту ткань событий ежедневно, но лишь немногие архитектурные решения способны работать с ней так же естественно, как это делает событийная нейросеть. Именно поэтому фреймворк EV-MGRFlowNet стал основой для построения по-настоящему современного подхода к анализу рыночного микродвижения. В предыдущих статьях мы разобрали ключевые элементы оригинальной архитектуры и адаптировали их под специфику финансовых временных рядов, перенеся в среду MQL5 с использованием OpenCL. Этот путь необходим, чтобы добиться главного — получить модель, способную воспринимать рынок как поток событий, в котором прошлое и настоящее переплетаются в единую структуру.
Такой взгляд ближе к классической трактовке поведения сложной системы, когда первостепенным становится изменение цены как процесс. Именно здесь архитектура EV-MGRFlowNet раскрывает свою концептуальную силу. Её первое важное преимущество — способность работать с данными в событийной форме, не требуя равномерной дискретизации и фиксированных временных окон. Рынок никогда не движется равномерно: его ритм определяется всплесками активности, затишьями и краткими импульсами, которые в традиционном подходе растворяются между свечами. Событийная модель, напротив, реагирует на каждое микроизменение в момент его появления, а не в заранее нарезанной сетке, что делает её особенно выразительной в условиях реального движения цен.
К этому добавляется глубина временной памяти, которую обеспечивает FERE-Net на основе ConvGRU и его модификации ST-ConvGRU. Эти механизмы не просто накапливают информацию о последовательности событий. Они удерживают структуру разворачивающегося движения, подобно тому, как опытный аналитик отслеживает не моментные колебания, а общую кинематику процесса. В условиях, когда направление движения определяется не плавными трендами, а хаотичными импульсами ликвидности, такая память становится одним из главных преимуществ архитектуры. Именно благодаря ей модель не теряет контекста и может корректно интерпретировать последовательность рыночных изменений даже в условиях высокой плотности данных.
Эту динамику дополняет многомасштабное уточнение, реализованное в FGD-Net. В авторской архитектуре он восстанавливает оптический поток на разных уровнях разрешения, а в нашем финансовом контексте выполняет схожую роль, позволяя модели воссоздавать направление и скорость рыночного микродвижения. Такая реконструкция воспринимает рынок как непрерывный векторный процесс, а не последовательность дискретных точек. Каждая новая порция событий уточняет структуру потока, формируя более связное и устойчивое описание направления движения. Благодаря этому удаётся рассматривать не только локальные всплески, но и более протяжённые импульсы. Это особенно важно для построения логики принятия решений.
Не меньшую роль играет гибридная функция потерь HMC-Loss, позволяющая обучать модель без заранее подготовленной разметки. Для финансовых рынков, где не существует единственно верного направления в строгом машинном смысле, это качество оказывается ключевым. Поток оценивается через собственную согласованность во времени, через плавность реконструируемого движения и через внутренние связи между событиями. Такой подход естественно снижает влияние случайного шума и выделяет устойчивые структуры — те самые, что и определяют реальную динамику рынка. По сути, модель учится различать импульсы, способные перерасти в движение, и шум, который следует игнорировать.
Авторская визуализация фреймворка представлена ниже.
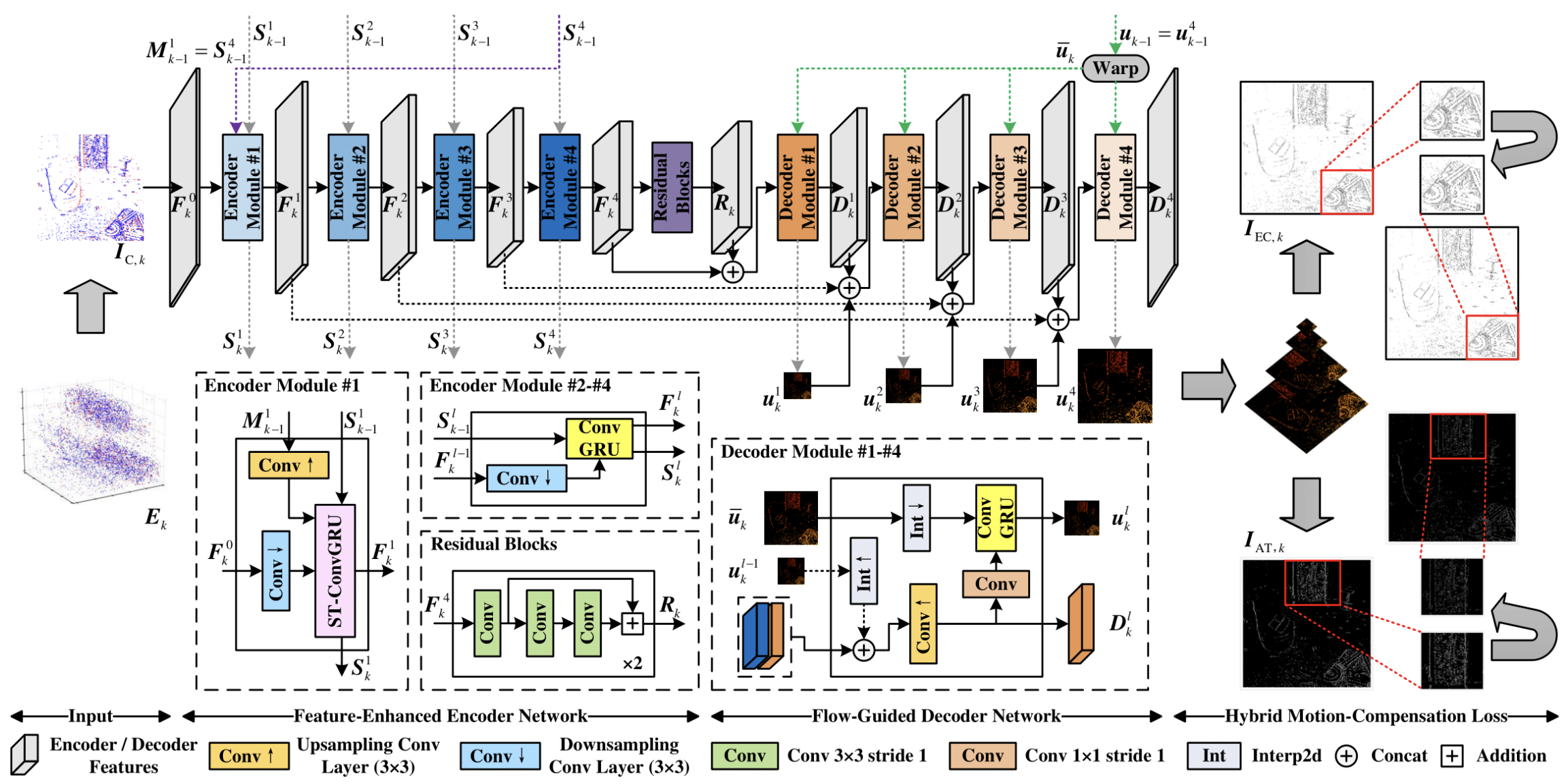
Перенося архитектуру EV-MGRFlowNet в MQL5, мы столкнулись не только с задачей перевода отдельных компонентов, но и с необходимостью адаптации самой вычислительной схемы. Реализация ST-ConvGRU стала фундаментом, на котором строится весь фреймворк. Мы показали, как организовывать память, как поддерживать скрытые состояния и как использовать OpenCL для обработки событийного потока. Эти элементы сформировали прочный каркас, позволяющий работать с большим объёмом данных и сохранять архитектурную целостность модели в условиях торгового терминала.
Особую сложность представляло отсутствие в финансовых данных пространственного измерения в привычном для задач компьютерного зрения виде. Поэтому многомерность исходных модулей была переосмыслена через структуру рыночных данных: плотность событий, концентрацию ликвидности, характер агрессивных и пассивных заявок. Такой перенос сохранил логику оригинальной архитектуры, позволив ей работать в условиях, где пространство проявляется не визуально, а структурно.
И сегодня мы продолжаем работу по реализации подходов, предложенных авторами фреймворка, средствами MQL5. На этом этапе нам важно не просто расширить архитектуру, но и придать ей способность формировать осмысленное описание рыночного движения. Если ранее мы сосредоточились на том, чтобы научить модель видеть поток событий и удерживать его структуру через рекуррентные механизмы, то теперь делаем следующий шаг — переходим к восстановлению самого движения. Именно здесь в игру вступает декодер FGD-Net, тот самый модуль, который в оригинальной архитектуре отвечает за многомасштабное уточнение оптического потока, а в нашем контексте становится инструментом для реконструкции вектора рыночной динамики.
Декодер
В архитектуре EV-MGRFlowNetдекодер играет особую роль. Он связывает скрытые состояния, накопленные рекуррентной частью, с конкретным прогнозом направления и интенсивности движения, позволяя перевести накопленную динамику в форму, пригодную для анализа. Иными словами, FGD-Net — это своего рода линза, через которую события, собранные моделью, превращаются в измеримый и интерпретируемый сигнал. Именно с него мы и начнём сегодняшнюю работу, подробно рассматривая логику его устройства и поэтапно перенося архитектурные решения в формат, соответствующий возможностям MQL5 и OpenCL.
Перед началом работы давайте еще раз посмотрим на авторскую визуализацию модулей декодера.
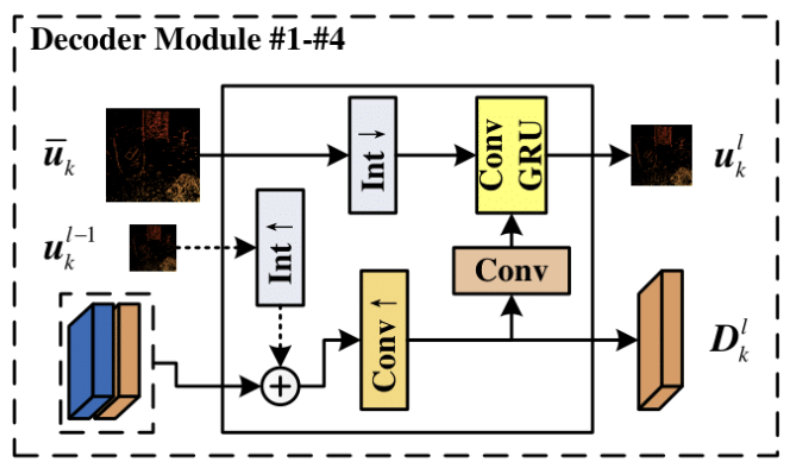
На первый взгляд кажется, что это просто очередная итерация рекуррентного свёрточного узла, но если присмотреться внимательнее, становится понятно: здесь заложена куда более тонкая логика взаимодействия между уровнями модели.
Прежде всего стоит обратить внимание на то, как формируются признаки, подаваемые на вход рекуррентного блока. В отличие от традиционной схемы, где каждый слой декодера работает исключительно со своим собственным выходом или с результатом предыдущего уровня, здесь используется проекция конкатенированного тензора, который объединяет два источника информации. Первый источник — это результаты работы предыдущего слоя декодера, то есть уже частично реконструированная динамика на более низком разрешении. Второй — соответствующий уровень энкодера, содержащий структурную информацию об исходных событиях, но ещё не пропущенную через механизмы многомасштабного восстановления. Такое объединение создаёт богатый по структуре входной сигнал, где хранится и накопленный контекст, и свежая информация о пространствено-структурных особенностях анализируемых событий.
Это сочетание не просто технический приём, а принципиально важный элемент всей архитектуры. Модель получает возможность уточнять движение, постоянно сопоставляя текущую реконструкцию с реальной структурой исходного потока. В классических задачах оптического потока это помогает избегать дрейфа и стабилизировать поле скоростей. В нашем контексте это позволяет корректировать вектор рыночного микродвижения, опираясь на фактическую структуру событий.
Не менее интересна организация скрытого состояния. В обычном ConvGRU оно обновляется по слоям. Каждый уровень декодера хранит и использует свою собственную память. Здесь же подход совсем другой — скрытое состояние представляет собой проекцию результата работы всей модели на предыдущем шаге, а не локальное состояние отдельного слоя. Это решение приближает декодер к концепции глобального рекуррентного механизма. Модель не замыкается на частичных, разрозненных состояниях, а использует единый поток динамики, выведенный на предыдущем шаге обработки последовательности. Таким образом архитектура избегает накопления ошибок между слоями и удерживает целостную историческую траекторию в едином рекуррентном контексте.
Именно это делает FGD-Net таким выразительным. Декодер работает как многоступенчатый фильтр, который на каждом шаге сравнивает свои промежуточные реконструкции с глобальным состоянием модели. Благодаря этому получается достоверное и устойчивое восстановление направления движения — будь то оптический поток в оригинальной задаче или рыночный микропоток в нашем портировании.
И когда общая логика вычислений становится достаточно прозрачной, наступает момент, переноса архитектурного замысла из абстрактной схемы в конкретный объект. Именно здесь появляется новый модуль, который аккумулирует в себе функции декодера и связывает отдельные ветви вычислений в единую, рабочую структуру. Мы создаём его как самостоятельный элемент модели — достаточно гибкий, чтобы обрабатывать сложные тензорные структуры, и достаточно строгий, чтобы выдерживать требования OpenCL-вычислений.
Так рождается класс CNeuronFGDModule, который аккуратно вписывается в уже сформированную структуру.
class CNeuronFGDModule : public CNeuronBaseOCL { protected: CNeuronBatchNormOCL cNorm; CNeuronConvOCL cD; CNeuronBaseOCL cFlowIn; CNeuronConvOCL cFlow; CNeuronBaseOCL cConcatenated; CNeuronMultiWindowsConvOCL cXH; //--- virtual bool GRU(void); virtual bool GRU_grad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput)override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second)override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; public: CNeuronFGDModule(void) {}; ~CNeuronFGDModule(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint main_dimension, uint flow_dimension, uint dimension_out, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFGDModule; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual CNeuronConvOCL* GetD(void) { return cD.AsObject(); } virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
Его устройство отражает ту же архитектурную идею, что мы наблюдали в графе декодера. Отдельные подмодули отвечают за нормализацию, свёрточные преобразования, формирование признаков и рекуррентную динамику, а основной объект становится координатором всех взаимодействий.
Инициализация объекта стала естественным продолжением архитектурной логики. Здесь задаются размеры входных и выходных пространств, формируется структура каналов, устанавливается связь с OpenCL-контекстом, определяются режимы оптимизации. То самое многослойное устройство вычислительного графа, о котором мы говорили ранее, теперь получает физическую форму. Каждый компонент знает своё место и свою роль, каждый готов вписаться в общий цикл вычислений.
bool CNeuronFGDModule::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint main_dimension, uint flow_dimension, uint dimension_out, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, units * dimension_out, optimization_type, batch)) return false; activation = None;
Первым шагом модуль наследует параметры базового объекта. Это словно фундамент, на котором вырастают остальные узлы. Без корректной связи с OpenCL-контекстом и без точной конфигурации выходных каналов вся дальнейшая логика просто не сможет запуститься. Затем отключается активация на верхнем уровне — декодеру важно сохранить чистоту числовых преобразований, не внося нелинейность туда, где она не предусмотрена авторами фреймворка.
Далее начинается последовательная настройка внутренних компонентов. Мы ожидаем поступление на вход модуля конкатенированного тензора, сформированного из 3 источников данных. Очевидно, что значения будут представлены в несогласованных распределениях, поэтому первым мы используем слой пакетной нормализации. Он отвечает за выравнивание масштабов карт признаков.
uint index = 0; if(!cNorm.Init(0, index, OpenCL, main_dimension * units, iBatch, optimization)) return false; cNorm.SetActivationFunction(None);
Его инициализация определяет число каналов, соответствующее произведению размерности основного потока и числа унитарных последовательностей — то самое пространство, где переплетаются признаки энкодера и декодера. Отсутствие активации подчёркивает его скромную, но незаменимую роль: он не меняет смысл данных, лишь делает их устойчивыми для последующих операций.
Затем на сцену выходит свёрточный слой cD. Это инструмент, который вносит в модуль динамику — он сопоставляет локальное состояние и формирует уточняющие карты движения. Активация TANH выбрана неслучайно. В контексте GRU она помогает удерживать значения в ограниченном диапазоне, сохраняя устойчивость при обновлении скрытого состояния.
index++; if(!cD.Init(0, index, OpenCL, main_dimension, main_dimension, dimension_out, units, 1, optimization, iBatch)) return false; cD.SetActivationFunction(TANH);
Вслед за ним инициализируется блок проекции потока, который служит своеобразным шлюзом между состоянием прошлых шагов и текущими вычислениями.
index++; if(!cFlowIn.Init(0, index, OpenCL, flow_dimension * units, optimization, iBatch)) return false; DeleteObj(cFlowIn.getOutput()) cFlowIn.SetActivationFunction(None); index++; if(!cFlow.Init(0, index, OpenCL, flow_dimension, flow_dimension, dimension_out, units, 1, optimization, iBatch)) return false; cFlow.SetActivationFunction(None);
Чуть дальше формируется объект объединения признаков (cConcatenated). Здесь особенно важно точное совпадение размерностей, ведь малейшее несоответствие мгновенно разрушит весь вычислительный граф.
index++; if(!cConcatenated.Init(0, index, OpenCL, 2 * dimension_out * units, optimization, iBatch)) return false; cConcatenated.SetActivationFunction(None);
И завершающий штрих — многоканальная свёртка cXH. Она становится вычислительным ядром ConvGRU-механизма: именно здесь генерируются проекции анализируемых признаков и скрытого состояния. Пара окон одинакового размера создаёт симметричную структуру, а общее число выходных каналов — тройная ширина выходного измерения — отражает три сущности алгоритма GRU.
index++; uint windows[] = { dimension_out, dimension_out }; if(!cXH.Init(0, index, OpenCL, windows, 3 * dimension_out, units, 1, optimization, iBatch)) return false; cXH.SetActivationFunction(None); //--- return true; }
Без активации, без лишних украшений — чистая математика.
Когда все подмодули проходят инициализацию, FGD-модуль становится готов к работе. Как единая архитектурная единица, в которой каждый элемент занимается своим делом, соблюдая порядок и структуру, заложенные в оригинальной модели. И именно эта точность, эта гармония внутреннего устройства делает его фундаментом для последующей реализации рекуррентной логики и восстановления многомасштабного поля движения.
После инициализации объекта мы переходим к построению алгоритма прямого прохода в методе feedForward, который демонстрирует строгую, детерминированную последовательность обработки данных, характерную для архитектуры EV-MGRFlowNet.
bool CNeuronFGDModule::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cFlowIn.SetOutput(SecondInput, false)) return false;
В параметрах модуля мы получаем указатели на 2 источника исходных данных. Один из них представлен объектом буфера. Однако, архитектура внутренних компонентов объекта предполагает использование только нейронных слоев, поэтому первой операцией мы устанавливаем полученный указатель в качестве буфера результатов специально созданного объекта.
Следующий шаг — нормализация данных. Слой нормализации выравнивает распределение входных значений, обеспечивая стабильность работы последующих слоёв и повышая эффективность обучения. Ошибка на этом этапе приводит к немедленному завершению метода.
if(!cNorm.FeedForward(NeuronOCL)) return false;
После нормализации данные передаются в блок cD. Этот компонент выступает как преобразующий слой, реализующий свёрточные операции фильтрации и формируший первичную карту признаков.
if(!cD.FeedForward(cNorm.AsObject())) return false;
Параллельно осуществляется обработка второго потока данных через cFlow, который осуществляет проекцию глобального скрытого состояния в пространство признаков текущего слоя.
if(!cFlow.FeedForward(cFlowIn.AsObject())) return false;
Далее результаты обоих потоков конкатенируются.
if(!Concat(cD.getOutput(), cFlow.getOutput(), cConcatenated.getOutput(), cD.GetFilters(), cFlow.GetFilters(), cFlow.GetUnits())) return false;
Объединённые данные передаются в слой cXH. Он выполняет проекцию анализируемых признаков и скрытого состояния в сущности, необходимые для выполнения операция алгоритма GRU. Использование объекта многооконной свертки позволяет нам выполнить формирование всех сущностей одновременно в параллельных потоках на стороне OpenCL-контекста.
if(!cXH.FeedForward(cConcatenated.AsObject())) return false;
Ключевой этап прямого прохода — вызов метода GRU, где реализуется рекуррентная обработка временных зависимостей. GRU обеспечивает способность модуля учитывать последовательности событий во времени, что критично для анализа финансовых данных. Любая ошибка на этом шаге останавливает метод.
if(!GRU()) return false;
Перед завершением работы метода мы обнуляем градиенты блока cD. Эта операция гарантирует, что накопленные ранее значения градиента не будут влиять на последующие итерации обучения, поддерживая чистоту вычислений.
if(!cD.getGradient().Fill(0)) return false; //--- return true; }
Если все шаги выполнены успешно, метод возвращается с результатом true, подтверждая корректность работы прямого прохода. В совокупности, эта последовательность отражает ключевые принципы архитектуры EV-MGRFlowNet: чёткая модульность, контроль состояния каждого блока и оптимизация вычислительных ресурсов.
Метод calcInputGradients формирует ключевой элемент процесса обучения модуля CNeuronFGDModule — алгоритм обратного распространения ошибки. Если прямой проход организует поток информации через сеть, обратное распространение отвечает за корректировку параметров и позволяет модели постепенно приближаться к желаемым результатам.
bool CNeuronFGDModule::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
Работа метода начинается с проверки корректности полученных указателей на объекты исходных данных. Без них дальнейшие вычисления невозможны. Это базовая, но критически важная защита от ошибок.
Далее мы синхронизируем указатели на буфер градиентов второго информационного потока и специально созданного внутреннего объекта.
if(!cFlowIn.SetGradient(SecondGradient, true)) return false; cFlowIn.SetActivationFunction(SecondActivation);
Затем рекуррентный блок проходит этап обратного распространения градиента ошибки. Именно здесь вычисляются градиенты рекуррентных связей, что позволяет учитывать влияние временных зависимостей на ошибку модели.
if(!GRU_grad()) return false;
Следующий этап — вычисление скрытых градиентов объединённого буфера. Метод корректно распределяет ошибку между объединёнными потоками, готовя данные для раздельной обработки.
if(!cConcatenated.CalcHiddenGradients(cXH.AsObject())) return false;
Операция DeConcat разделяет объединённый градиент на части, соответствующие слоям cD и cFlow. Параметры фильтров и размерность последовательности обеспечивают корректное разбиение многомерных данных.
if(!DeConcat(cD.getPrevOutput(), cFlow.getGradient(), cConcatenated.getGradient(), cD.GetFilters(), cFlow.GetFilters(), cFlow.GetUnits())) return false;
Далее выполняется суммирование градиента объекта cD. Этот шаг позволяет объединить значения двух информационных потоков и стабилизировать обучение.
if(!SumAndNormilize(cD.getGradient(), cD.getPrevOutput(), cD.getGradient(), cD.GetFilters(), false, 0, 0, 0, 1)) return false;
Метод Deactivation корректно корректирует полученные значения градиентов на производные соответствующих функций активации.
Deactivation(cFlow) Deactivation(cD)
После этого корректно распределяем градиенты двух информационных потоков до уровня исходных данных.
if(!cFlowIn.CalcHiddenGradients(cFlow.AsObject())) return false; if(!cNorm.CalcHiddenGradients(cD.AsObject())) return false; if(!NeuronOCL.CalcHiddenGradients(cNorm.AsObject())) return false; //--- return true; }
Если все шаги завершились успешно, метод возвращает true, сигнализируя о корректном расчёте градиентов.
В совокупности, эта последовательность отражает детальный контроль над распределением ошибки и демонстрирует модульную, устойчивую архитектуру EV-MGRFlowNet, где каждый компонент строго выполняет свою задачу и обеспечивает стабильное обучение модели.
Таким образом, модуль FGD становится не просто частью архитектуры, но и мостом между теорией и практикой. Он принимает те же структурные решения, что и авторская модель, но выражает их в форме, доступной среде MQL5 и OpenCL. И именно на этом этапе становится ясно: декодер — это не формальность, а ключ к тому, чтобы модель умела восстанавливать движение в его многомасштабной природе.
Объект верхнего уровня
После успешной реализации отдельных модулей фреймворка EV-MGRFlowNet наступает ключевой этап — интеграция всех компонентов в единую, согласованную структуру. В этой роли выступает класс CNeuronEVMGRFlowNet, который наследует базовую функциональность от CNeuronSpikeActivation и объединяет в себе энкодер, центральный блок и декодер, обеспечивая полный цикл обработки информации от входа до выхода модели.
class CNeuronEVMGRFlowNet : public CNeuronSpikeActivation { protected: CNeuronFERENet cEncoder; CNeuronSTEFlowNetResidualBlock cNeck; CLayer cDecoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronEVMGRFlowNet(void) {}; ~CNeuronEVMGRFlowNet(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &chanels[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronEVMGRFlowNet; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual bool Clear(void) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
Внутри класса мы видим три основных компонента:
- cEncoder (CNeuronFERENet) — выполняющий роль кодировщика признаков и транслятора анализируемых данных во внутреннее представление модели;
- cNeck (CNeuronSTEFlowNetResidualBlock) — служит центральным, резидуальным блоком обработки, обеспечивая глубокое извлечение и трансформацию скрытых признаков;
- cDecoder — возвращающий преобразованное представление обратно в пространство выходных данных.
Метод Init выполняет комплексную инициализацию всех внутренних компонентов класса, обеспечивая согласованность структуры и корректность работы модели на каждом уровне. Это ключевой этап, формирующий полную архитектуру от энкодера до декодера, готовую к обучению и прямому проходу.
bool CNeuronEVMGRFlowNet::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &chanels[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(chanels.Size() < 2) return false; if(!CNeuronSpikeActivation::Init(numOutputs, myIndex, open_cl, units * chanels[0], optimization_type, batch)) return false;
Сначала метод проверяет корректность входного массива каналов chanels — минимальный размер массива должен быть не менее двух. Это гарантирует, что сеть будет иметь входной и выходной поток информации. Если условие не выполняется, инициализация прерывается.
Далее вызывается одноименный метод родительского класса, который инициализирует базовый функционал и задаёт фундаментальные настройки объекта, включая распределение ресурсов и память для вычислений.
Количество слоёв энкодера и декодера определяется на 1 меньше размерности массива каналов.
uint layers = chanels.Size() - 1;
Затем создаётся и инициализируется энкодер. Ему передаются параметры, полученные от пользователя.
//--- Encoder int index = 0; if(!cEncoder.Init(0, index, OpenCL, units, chanels, optimization, iBatch)) return false;
Успешная инициализация энкодера гарантирует корректное формирование внутреннего представления данных.
Следующий шаг — инициализация центрального блока cNeck, который отвечает за глубокое извлечение признаков и обеспечивает резидуальные соединения, необходимые для стабильного обучения глубокой модели.
index++; if(!cNeck.Init(0, index, OpenCL, chanels[layers], units, 32, 8, optimization, iBatch)) return false;
Затем переходим к работе с декодером. Вначале очищается динамический массив объектов и передается указатель на объект OpenCL, после чего начинается построение слоёв восстановления данных.
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronFGDModule* fgd = NULL; CNeuronBaseOCL* concat = cNeck.AsObject(); uint flow_dimension = chanels[0];
На каждом этапе создаётся новый модуль CNeuronFGDModule с параметрами, соответствующими размерностям предыдущего слоя (main_dimension), размеру потока (flow_dimension) и числу выходов текущего слоя. После успешной инициализации модуль добавляется в декодер.
for(uint i = 0; i < layers; i++) { uint main_dimension = concat.Neurons() / units; fgd = new CNeuronFGDModule(); if(!fgd || !fgd.Init(0, index, OpenCL, units, main_dimension, flow_dimension, chanels[layers - i - 1], optimization, iBatch) || !cDecoder.Add(fgd)) { DeleteObj(fgd) return false; }
Особое внимание уделено корректному объединению слоёв. Если для текущего уровня существует соответствующий слой кодировщика, создаётся объект concat, объединяющий нейроны декодера, блока D текущего модуля и энкодера.
if(i == (layers - 1)) break; index++; CNeuronBaseOCL* encoder = cEncoder.GetLayer(-int(i + 1)); CNeuronBaseOCL* d = fgd.GetD(); if(!encoder) { concat = new CNeuronBaseOCL(); if(!concat || !concat.Init(0, index, OpenCL, fgd.Neurons() + d.Neurons(), optimization, iBatch) || !cDecoder.Add(concat)) { DeleteObj(concat) return false; } } else { concat = new CNeuronBaseOCL(); if(!concat || !concat.Init(0, index, OpenCL, fgd.Neurons() + d.Neurons() + encoder.Neurons(), optimization, iBatch) || !cDecoder.Add(concat)) { DeleteObj(concat) return false; } } index++; }
Если кодировщик отсутствует, объединение выполняется только между декодером и блоком D. Этот механизм обеспечивает согласованное распространение сигналов и градиентов между уровнями, сохраняя целостность архитектуры.
После построения всех слоёв декодера добавляется слой нормализации. Он стабилизирует распределение активаций, минимизирует смещение и ускоряет обучение, что особенно важно при работе с глубокими сетями.
CNeuronBatchNormOCL* norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, fgd.Neurons(), iBatch, optimization) || !cDecoder.Add(norm)) { DeleteObj(norm) return false; } //--- return true; }
В случае любой ошибки на любом из шагов метод немедленно завершает работу, освобождая ресурсы. Если все компоненты успешно инициализированы, метод возвращает true, сигнализируя о полной готовности модели к обучению и прямому проходу.
После завершения инициализации всех компонентов объекта, следующим этапом является построение алгоритма прямого прохода, который обеспечивает последовательную обработку исходных данных через энкодер, центральный блок и декодер. Метод feedForward реализует этот процесс, обеспечивая согласованное движение сигналов.
bool CNeuronEVMGRFlowNet::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cEncoder.FeedForward(NeuronOCL)) return false;
Сначала данные проходят через энкодер, который формирует внутреннее представление анализируемых сигналов, извлекая первичные признаки и структурируя их в многомерное пространство скрытых представлений. Любая ошибка на этом шаге немедленно завершает выполнение метода, предотвращая некорректную обработку.
Затем сигнал поступает в центральный блок cNeck. Этот резидуальный блок отвечает за глубокую трансформацию признаков, поддерживая устойчивость модели и эффективность извлечения сложных зависимостей между исходными данными.
if(!cNeck.FeedForward(cEncoder.AsObject())) return false;
Далее начинается работа декодера. Количество слоёв определяется как половина от общего числа элементов в декодере, что отражает структуру чередования модулей восстановления и промежуточных буферов. Для каждого слоя создаются указатели на текущий модуль FGD, блок D, соответствующий слой энкодера (encoder) и предыдущий слой (prev), что обеспечивает точное управление потоками данных.
//--- Decoder int layers = cDecoder.Total() / 2; CNeuronFGDModule* fgd = NULL; CNeuronBaseOCL* d = NULL; CNeuronBaseOCL* encoder = NULL; CNeuronBaseOCL* prev = cNeck.AsObject(); CNeuronBaseOCL* flow = cDecoder[-2]; if(!flow.SwapOutputs()) return false; uint units = cEncoder.GetUnits(); if(!flow) return false;
Особое внимание уделено подготовке потока результатов предыдущего слоя, что обеспечивает корректное перемещение информации внутри декодера.
На каждом уровне декодера вызывается метод прямого прохода соответствующего FGD-модуля, где он получает данные из предыдущего слоя и дополнительного потока.
for(int i = 0; i < layers; i++) { fgd = cDecoder[i * 2]; if(!fgd || !fgd.FeedForward(prev, flow.getPrevOutput())) return false;
После этого данные объединяются с выходами соответствующих слоёв энкодера и блока D с помощью метода Concat, что позволяет сохранить согласованность размерностей и корректно объединить многомерные данные.
prev = cDecoder[i * 2 + 1]; if(!prev) return false; if(i == (layers - 1)) { if(!prev.FeedForward(fgd)) return false; break; } d = fgd.GetD(); encoder = cEncoder[-(i + 1)]; if(!encoder) { if(!Concat(fgd.getOutput(), d.getOutput(), prev.getOutput(), fgd.Neurons() / units, d.Neurons() / units, units)) return false; } else { if(!Concat(fgd.getOutput(), d.getOutput(), encoder.getOutput(), prev.getOutput(), fgd.Neurons() / units, d.Neurons() / units, encoder.Neurons() / units, units)) return false; } }
На последнем слое выполняется прямой проход через промежуточный буфер prev, после чего результаты передаются в одноименный метод родительского класса, замыкая полный цикл обработки.
return CNeuronSpikeActivation::feedForward(prev);
}
Это гарантирует, что сигнал полностью обработан и готов к следующему этапу.
Следующий этап после прямого прохода — работа с ошибками и распределение градиентов по всем уровням модели. Метод calcInputGradients реализует обратное распространение ошибки для полной структуры EV-MGRFlowNet, обеспечивая корректное обновление весов и подготовку модели к следующей итерации.
bool CNeuronEVMGRFlowNet::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Сначала выполняется базовая проверка полученного указателя на объект исходных данных. Если объект отсутствует, дальнейшие вычисления невозможны, и метод немедленно возвращает false.
Далее вызывается одноименный метод родительского класса, который передает градиенты на уровень последнего слоя декодера, замыкающего цепочку прямого прохода.
if(!CNeuronSpikeActivation::calcInputGradients(cDecoder[-1])) return false;
Декодер обрабатывается в обратном порядке. Количество слоёв вычисляется как половина от общего числа элементов в динамическом массиве.
//--- Decoder int layers = cDecoder.Total() / 2; CNeuronFGDModule* fgd = cDecoder[-2]; CNeuronBaseOCL* d = NULL; CNeuronBaseOCL* encoder = NULL; CNeuronBaseOCL* next = cDecoder[-1]; CNeuronBaseOCL* flow = cDecoder[-2]; if(!fgd || !fgd.CalcHiddenGradients(next)) return false; uint units = cEncoder.GetUnits();
На каждом уровне создаются указатели на текущий модуль FGD, блок D, соответствующий слой энкодера (encoder), следующий объект (next) и поток (flow).
На первом этапе обратного прохода декодера распределяется ошибка на уровень модуля FGD. Далее в цикле градиенты вычисляются для каждого слоя декодера, начиная с предпоследнего и двигаясь к входу.
for(int i = layers - 2; i >= 0; i--) { next = cDecoder[i * 2 + 1]; if(!next || !next.CalcHiddenGradients(fgd, flow.getOutput(), flow.getGradient(), (ENUM_ACTIVATION)flow.Activation())) return false; //--- fgd = cDecoder[i * 2]; if(!fgd) return false; d = fgd.GetD(); encoder = cEncoder[-(i + 1)];
Особое внимание уделено операции DeConcat, которая разделяет объединённые градиенты на составляющие для модуля FGD, блока D и, при наличии, соответствующего слоя энкодера. Такой подход обеспечивает согласованность размерностей и правильное распределение ошибки между слоями.
if(!encoder) { if(!DeConcat(fgd.getGradient(), d.getGradient(), next.getGradient(), fgd.Neurons() / units, d.Neurons() / units, units)) return false; } else { if(!DeConcat(fgd.getGradient(), d.getGradient(), encoder.getGradient(), next.getGradient(), fgd.Neurons() / units, d.Neurons() / units, encoder.Neurons() / units, units)) return false; } Deactivation(fgd); }
После вычисления градиентов каждого модуля FGD осуществляется корректировка полученных значений на производную соответствующей функции активации.
Завершающий этап работы с ошибками проходит через центральный блок cNeck и энкодер cEncoder.
if(!cNeck.CalcHiddenGradients(fgd, flow.getOutput(), flow.getGradient(), (ENUM_ACTIVATION)flow.Activation())) return false; if(!cEncoder.CalcHiddenGradients(cNeck.AsObject())) return false; if(!NeuronOCL.CalcHiddenGradients(cEncoder.AsObject())) return false; //--- return true; }
Наконец, объект исходных данных получает градиенты от энкодера, что замыкает полный цикл обратного распространения.
Если все операции завершены успешно, метод возвращает true. В совокупности, этот алгоритм демонстрирует тщательно продуманную последовательность распределения ошибки и управления градиентами, обеспечивая устойчивое обучение модели EV-MGRFlowNet и сохранение согласованности всех внутренних потоков данных.
В целом, CNeuronEVMGRFlowNet является связующим звеном всех компонентов EV-MGRFlowNet. Его архитектура отражает классический принцип модульности и контроля, при этом сохраняя возможность глубокого анализа и обработки временных зависимостей, что делает модель одновременно гибкой, устойчивой и эффективной для задач прогнозирования на финансовых данных.
После завершения реализации ключевых подходов, предложенных авторами фреймворка EV-MGRFlowNet, важно подчеркнуть архитектурные особенности обучаемых моделей. В данном проекте мы строим полноценную торговую систему, способную автономно принимать решения и совершать операции на финансовом рынке.
Все архитектурные решения были перенесены из предыдущих работ практически без изменений, что позволило сохранить проверенную временем логику обработки сигналов и алгоритмы обучения. Основные модификации коснулись Энкодера окружающей среды. Именно туда был внедрён объект верхнего уровня CNeuronEVMGRFlowNet в качестве отдельного слоя. Такой подход минимизирует сложность интеграции фреймворка в модель, сохраняя модульность и чистоту архитектуры, а также упрощает поддержку и расширение модели в будущем.
Создание объекта верхнего уровня выступает своеобразным мостом между базовыми модулями и внешней моделью, обеспечивая согласованное взаимодействие всех слоёв без необходимости масштабной переработки существующей структуры. Это решение отражает основной принцип EV-MGRFlowNet: высокая модульность при минимальных усилиях по интеграции.
Полный код описания архитектуры обучаемых моделей представлен во вложении.
Тестирование
После интерграции фреймворк EV-MGRFlowNet в Энкодер состояния окружающей среды, наша модель готова выйти на первую тренировочную арену. Этот этап можно сравнить с репетицией начинающего трейдера на исторических данных. Она получает карту прошлого рынка, изучает движения цен и пытается понять, как вести себя в разных ситуациях.
Представьте, что EURUSD за период с Января 2024 по Июнь 2025 года — это её тренировочная площадка. Модель, словно новичок на бирже, смотрит на каждую свечу, изучает объёмы и скрытые закономерности между ключевыми признаками. А EV-MGRFlowNet — её наставник: подсказывает, куда обратить внимание, формирует информативное состояние для Актёра и Критика, подталкивает к выработке интуиции трейдера. С каждым шагом она учится прогнозировать движение рынка и оценивать риски, постепенно превращаясь из ученицы в уверенного практиканта.
Следующий этап — онлайн-тренировка в реальном времени через тестер стратегий MetaTrader 5. Теперь нет роскошного спокойствия исторических данных. Каждая свеча — как живая реакция рынка. Модель реагирует моментально, анализирует шумовые колебания, приспосабливается к резким всплескам и корректирует свои действия при низкой ликвидности. EV-MGRFlowNet действует как невидимый наставник, удерживая сеть от ошибок, подсказывая, когда действовать смело, а когда проявить осторожность. Базовая структура, выстроенная на исторических данных, остаётся её опорой, но теперь модель учится гибко реагировать на текущую ситуацию, словно трейдер с опытом живой торговли.
Финальный экзамен — тестирование модели на новых данных за Июль–Сентябрь 2025 года. Все навыки, накопленные на предыдущих этапах, проверяются на честность: никаких подсказок, только рынок и её собственные решения. Результаты тестирования представлены ниже.
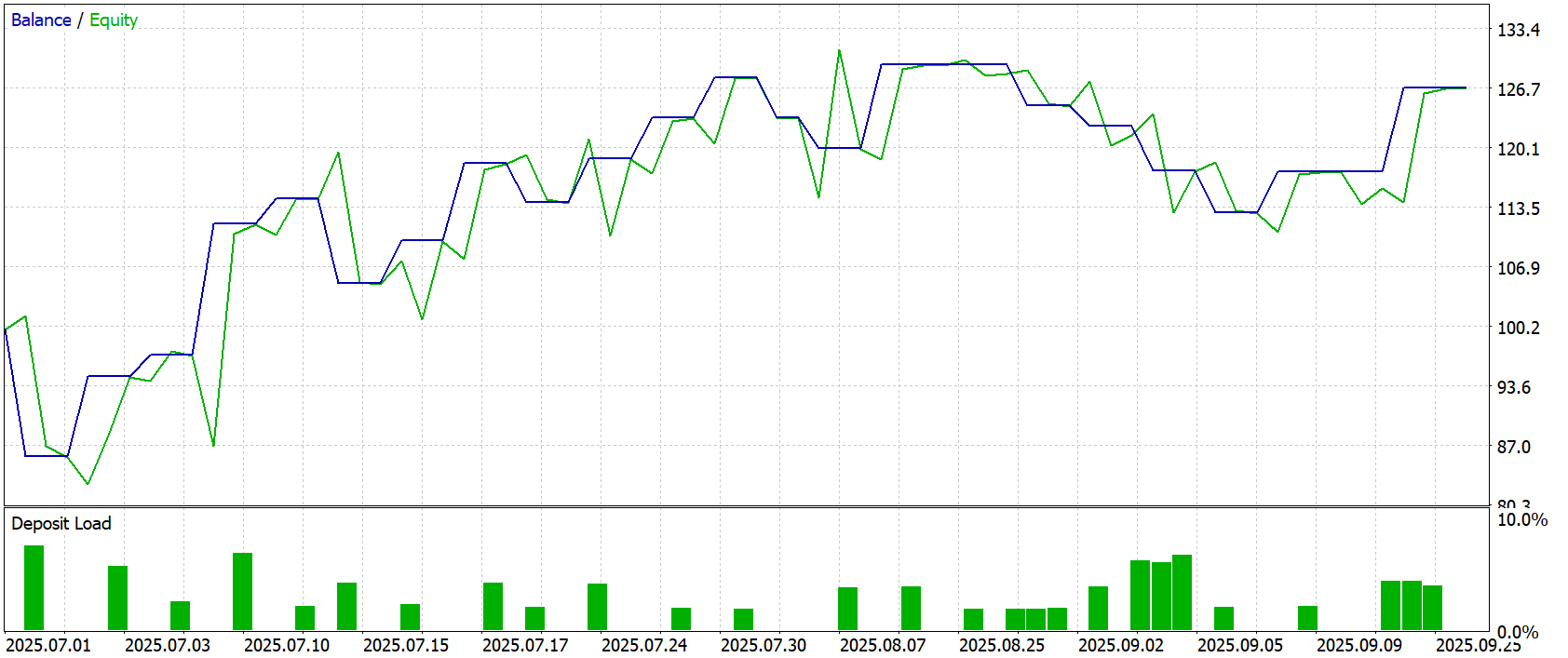
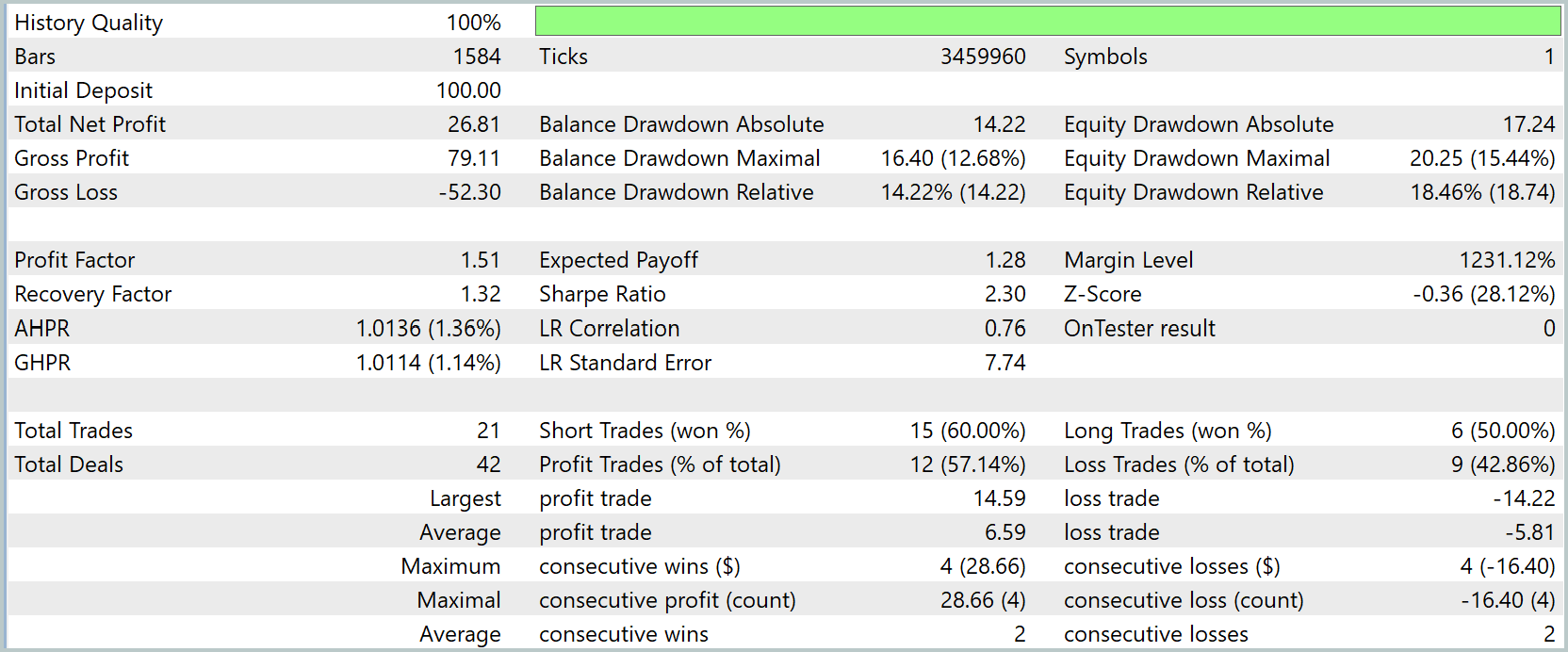
Результаты тестирования демонстрируют уверенную и спокойную динамику. Кривая капитала поднимается ровно, без резких скачков и нестабильных колебаний. Баланс и эквити идут почти бок о бок, словно два согласованных механизма. Один поддерживает системную логику стратегии, другой отражает текущее состояние открытых позиций. Вместе они формируют плавный рост, где нет ощущения случайности или перенапряжения. Итоговая доходность — от $100.0 до $126.81 — выглядит естественным результатом работы алгоритма, а не следствием случайных импульсов.
Эта плавность подкреплена количественными характеристиками. Профит-фактор 1.51 и коэффициент восстановления 1.32 показывают, что стратегия не только чаще приносит прибыль, чем убытки, но и уверенно возвращается из просадок. Средняя прибыль на сделку $1.28 формируется не за счёт единичных выбросов, а через последовательное, ритмичное движение, что делает результат более предсказуемым.
Просадки воспринимаются как естественные неровности. Максимальная балансовая просадка — $16.40 (12.68 %), эквити — $20.25 (15.44 %) — не создают тревожного впечатления, так как эквити почти не отделяется от баланса. Это означает, что открытые позиции не зависают в минусе, не создают затяжной нагрузки на маржу, а график наглядно подтверждает: небольшие спады быстро сменяются последовательными подъёмами.
Торговая структура демонстрирует внутреннюю гармонию алгоритма. Из 21 сделки прибыльных оказалось около 57%, а распределение коротких и длинных позиций выглядит сбалансированным. Это свидетельствует о том, что стратегия не зациклена на одной фазе рынка и способна адаптироваться к различным условиям — будь то импульсные движения или флетовые сегменты.
Наблюдение за кривой капитала и загрузкой депозита показывает аккуратный трейдинг на низком плече. Загрузка редко превышает несколько процентов и преимущественно держится в диапазоне 1–5%. Алгоритм не форсирует рынок, действуя решительно, но в рамках предусмотренного риска.
В итоге тестирование формирует цельную, согласованную картину: алгоритм ведёт капитал уверенно вверх, удерживает просадки под контролем и стабильно генерирует прибыль.
Заключение
Мы завершили работу по имплементации подходов, предложенных авторами фреймворка EV-MGRFlowNet. Реализованное решение демонстрирует высокую согласованность архитектуры, устойчивость к рыночным колебаниям и способность к самостоятельной выработке стратегии. Интеграция всех компонентов — энкодера, центрального блока и декодера — в единую структуру позволила создать модель, которая плавно и прогнозируемо ведёт капитал, минимизируя стрессовые просадки и сохраняя контроль над рисками.
Тестирование показало, что стратегия работает сбалансированно. Прибыль формируется системно, без опоры на единичные удачные сделки, а механизмы обратного распространения ошибок обеспечивают стабильное обновление весов и адаптивность модели. Профит-фактор, коэффициенты восстановления и показатели геометрической доходности подтверждают эффективность и надежность построенной модели.
Главное преимущество решения — его модульность и гибкость. Объект верхнего уровня CNeuronEVMGRFlowNet легко интегрируется в различные торговые модели, сохраняя проверенную логику работы всех слоев. Это делает фреймворк не только мощным инструментом для анализа и прогнозирования, но и платформой для дальнейшей оптимизации стратегий, повышения адаптивности и расширения функционала.
Ссылки
- EV-MGRFlowNet: Motion-Guided Recurrent Network for Unsupervised Event-based Optical Flow with Hybrid Motion-Compensation Loss
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
продолжаю пытаться запустить.)) включил Study Online в визуальном режиме - посыпались вот такие ошибки
продолжаю пытаться запустить.)) включил Study Online в визуальном режиме - посыпались вот такие ошибки
У Вас включено использование OpenCL в тестере?
и Study в журнале заканчивается вот так
и Study в журнале заканчивается вот так