
Рецепты нейросетей
Введение
Не так давно - на заре технического анализа, когда компьютеры были далеко не у каждого биржевика - появлялись люди, которые пытались предсказывать будущие цены по ими же придуманным законам и формулам. Таких людей часто называли шарлатанами. Время шло, усложнялись методы обработки информации, и теперь очень сложно найти равнодушного к техническому анализу. Любой трейдер-новичок с легкостью может оперировать графиками, различными индикаторами, искать закономерности.
С каждым днем пополняются ряды форекс-трейдеров. Одновременно с этим растут их запросы к методам анализа рынка. Одними из таких "относительно" новых методов являются использование теории нечеткой логики и нейросетей. Мы сами видим, как на любом тематическом форуме обсуждаются темы, посвященные этим вопросам. Они есть и всегда будут появляться. Человек, придя в мир биржи, навряд ли покинет ее. Ибо она есть вызов его интеллекту, его силе ума, силе воли. Поэтому трейдер всегда учится чему-то новому и применяет в своей практике самые разнообразные подходы.
В этой статье мы разберем основы создания нейросетей, познакомимся с понятием нейросетей Кохонена и немного поговорим о методах оптимизации торговли. Эта статья адресована в первую очередь трейдерам, которые только начинают знакомиться с нейросетями и их принципами обработки информации.
Для приготовления нейросети со слоем Кохонена нам понадобится:
1) 10 000 баров истории любой валютной пары;
2) 5 грамм скользящих средних (или любых других индикаторов по вашему вкусу);
3) 2-3 слоя обратного распространения;
4) В начинку добавим методы оптимизации;
5) Украсим зеленью растущего баланса и числом верно угаданных направлений сделки.
Раздел I. Рецептура слоя Кохонена
Начнем с раздела для тех, кто еще «до». В нем мы поговорим про различные подходы обучения слоя Кохонена, а точнее его, так называемой, базовой версии, ибо разнообразий очень много. Этот раздел не претендует на оригинальность материала, все авторские пояснения, которые в ней описаны, взяты из классической литературы данной тематики. Но хороший плюс, который в нем есть, – это обилие пояснительных рисунков для каждой главы.
В разделе рассмотрим следующие вопросы:
- Как происходит подстройка весовых векторов Кохонена;
- Предварительная подготовка входных векторов;
- Выбор начальных весов нейронов Кохонена.
Итак, как гласит Википедия, нейронные сети Кохонена - это класс нейронных сетей, основным элементом которых является слой Кохонена. Слой Кохонена состоит из адаптивных линейных сумматоров («линейных формальных нейронов»). Как правило, выходные сигналы слоя Кохонена обрабатываются по правилу «победитель забирает всё»: наибольший сигнал превращается в единичный, остальные обращаются в ноль.
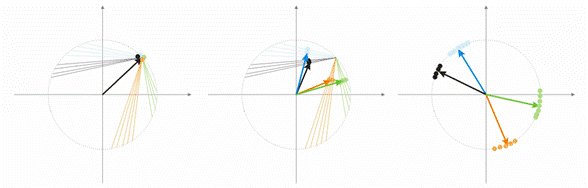
Давайте разберем это понятие на примере. Для наглядности все выкладки будут даваться для двумерных входных векторов. На рисунке 1 цветом изображен входной вектор. Каждый нейрон слоя Кохонена (как в принципе и любого другого слоя) просто суммирует вход, умножая его на свои веса. На самом деле веса слоя Кохонена есть не что иное как координаты вектора для данного нейрона.
Таким образом, выход каждого нейрона Кохонена – это скалярное произведение двух векторов. Из геометрии мы знаем, что максимальное скалярное произведение будет в том случае, если угол между векторами будет стремиться к нулю (косинус угла будет стремиться к 1). Из этого следует, что максимальное значение будет иметь тот нейрон слоя Кохонена, который ближе всех к входному вектору.
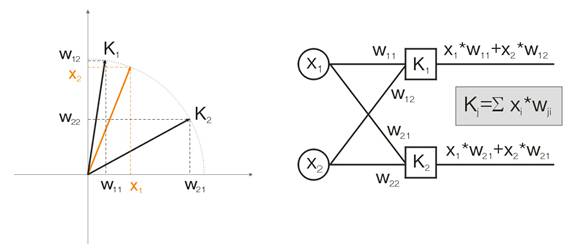
Рис.1 Победителем является тот нейрон, чей вектор наиболее близок ко входному сигналу.
Как следует дальше из понятия, мы должны найти среди всех нейронов максимальное выходное значение, присвоить его выход единице, остальным нейронам присвоить ноль. Таким образом, слой Кохонена будет выдавать нам "ответ", в какой области пространства лежит входной вектор.
Как происходит подстройка весовых векторов Кохонена
Целью обучения слоя, как писалось выше, является четкая пространственная классификация входных векторов. А это означает, что каждый нейрон должен отвечать за свой определенный участок, в котором он является победителем. Ошибка отклонения нейрона-победителя от входного вектора должна быть меньше, чем у остальных нейронов. Чтобы достичь этого, нейрон-победитель "поворачивается" в сторону входного вектора.
На рисунке 2 показано разделение двух нейронов (черные векторы) для двух входных векторов (они обозначены цветом).
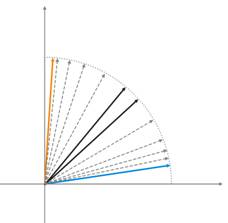
Рис.2. Каждый из нейронов приближается к своему ближайшему входному сигналу.
С каждой итерацией нейрон-победитель приближается к "своему" входному вектору. Его новые координаты определяются по формуле:
![]()
где A(t) - параметр скорости обучения, зависящий от времени t. Это невозрастающая функция, которая уменьшается с каждой итерацией от 1 до 0. Если начальное значение А=1, то корректировка веса происходит в один этап. Это возможно, когда для каждого входного вектора имеется один нейрон Кохонена (например, 10 входных векторов и 10 нейронов в слое Кохонена).
Но на практике такого случая практически не встречается, так как обычно требуется большой объем входных данных разделить на группы схожих, тем самым уменьшив разнообразие входных данных. Поэтому значение А=1 нежелательно. Оптимальным на практике оказываются начальные значения менее 0.3.
К тому же А обратно пропорционально числу входных векторов. То есть, желательно при большой выборке делать маленькие коррекции, чтоб нейрон-победитель не "летал" по всему пространству в своих корректировках. В качестве функционала А обычно выбирается любая монотонно убывающая функция. Например, гипербола или линейное убывание, или гауссовская функция.
На рисунке 3 показан шаг коррекции весов нейрона со скоростью А=0.5. Нейрон приблизился к входному вектору, ошибка уменьшилась.
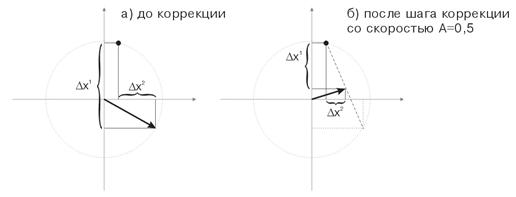
Рис.3. Коррекция весов нейрона под воздействием входного сигнала.
Малое число нейронов при широкой выборке
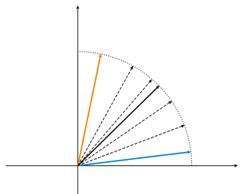
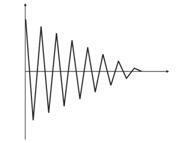
Рис.4. Колебания нейрона между двумя входными векторами.
На рисунке 4 (слева), имеется два входных вектора (обозначены цветом) и всего один нейрон Кохонена. В процессе коррекции нейрон будет качаться от одного входного вектора до другого (пунктирные линии). И по мере уменьшения значения А до 0 стабилизируется между ними. Изменения координат нейрона от времени можно охарактеризовать зигзагообразной линией (рисунок 4 справа).
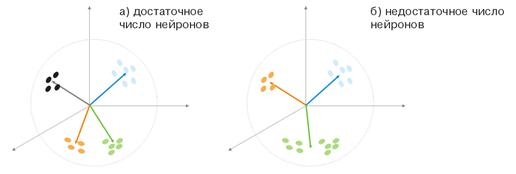
Рис. 5. Зависимость вида классификации от числа нейронов
Еще одна ситуация показана на рисунке 5. В первом случае четыре нейрона адекватно разделяют выборку на четыре области гиперсферы. Во втором случае недостаточное число нейронов приводит к увеличению ошибки и переклассификацию выборки. Таким образом, можно сделать вывод, что в слое Кохонена должно быть достаточное число свободных нейронов, которое зависит от объема классифицируемой выборки.
Предварительная подготовка входных векторов
Как пишет Уосермен в своей книге, весьма желательно (хотя и не обязательно) нормализовать входные векторы перед тем, как предъявлять их сети. Это выполняется с помощью деления каждой компоненты входного вектора на длину вектора. Эта длина находится извлечением квадратного корня из суммы квадратов компонент вектора. В алгебраической записи
![]()
Это превращает входной вектор в единичный вектор с тем же самым направлением, т.е. в вектор единичной длины в n-мерном пространстве. Смысл данной операции очевиден – спроецировать все входные вектора на поверхности гиперсферы, тем самым, облегчить слою Кохонена задачу поиска. Другими словами, так как мы будем искать угол между входными векторами и векторами-нейронами Кохонена, то должны избавиться от такого фактора как длина вектора, уравняв шансы всех нейронов.
Часто элементами векторов выборки являются неотрицательные числа (например, значения скользящих средних, РСИ, сама цена). Все они сосредоточены в положительном квадранте пространства. В результате нормализации такой "положительной" выборки получим большое скопление векторов только в одной положительной области, что не очень хорошо для классификации. Поэтому перед нормализацией можно выполнить выравнивание выборки. Если выборка довольно большая, то можно предположить, что вектора находятся примерно в одной области без «аутсайдеров», которые вылетают далеко за основную выборку. Следовательно, выборку можно просто отцентрировать относительно ее «крайних» координат.
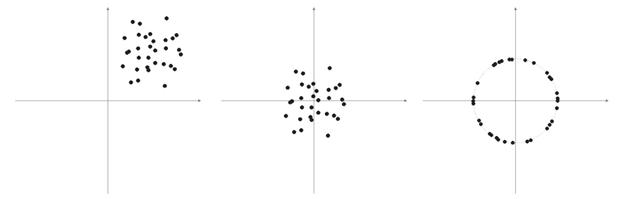
Рис. 6. Нормализация входных векторов
Как писалось выше, нормализация векторов желательна. Она упрощает корректировку слоя Кохонена. Но все же мы должны четко представлять себе выборку и принимать решение, стоит ли ее проецировать на сферу или нет.
Листинг 1. Сужение входных векторов в диапазон [-1, 1]
for (N=0; N<nNeuron[0]; N++) // по всем нейронам входного слоя { min=in[N][0]; // ищем минимум на всей выборке for (pat=0; pat<nPattern; pat++) if (in[N][pat]<min) min=in[N][pat]; for (pat=0; pat<nPattern; pat++) in[N][pat]-=min; // подвигаем на величину минимального значения max=in[N][0]; // ищем максимум на всей выборке for (pat=0; pat<nPattern; pat++) if (in[N][pat]>max) max=in[N][pat]; for (pat=0; pat<nPattern; pat++) in[N][pat]=2*(in[N][pat]/max)-1; // сужаем до [-1,1] }
Если мы нормализуем входные вектора, то должны соответственно нормализовать и все веса нейронов.
Выбор начальных весов нейронов
Вариантов может быть много.
1) Весам даются случайные значения, как обычно поступают при работе с нейросетями (рандомизация);
2) Инициализация примерами, когда в качестве начальных значений задаются значения случайно выбранных примеров из обучающей выборки;
3) Линейная инициализация. В этом случае веса инициируются значениями векторов, линейно упорядоченных вдоль линейного подпространства, проходящего между двумя главных собственными векторами исходного набора данных;
4) Все веса имеют одинаковые значения – метод выпуклой комбинации.
Остановимся на первом и последнем случае подробно.
1) Весам даются случайные значения
При рандомизации все векторы-нейроны распределяются по поверхности гиперсферы. Входные же вектора имеют тенденцию – группироваться. В таком случае, может произойти событие, когда некоторые весовые вектора будут так удалены от входных векторов, что никогда не смогут давать наилучшего соответствия, а значит, что не смогут обучаться – «серые» векторы на рисунке 7 (справа). Но более того, оставшихся нейронов будет мало для того, чтобы минимизировать ошибку и разделить близкие классы – «красный» класс попал в «зеленый» нейрон.
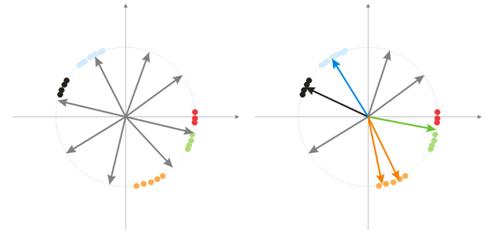
Рис. 7. Результат обучения рандомизированных нейронов
Также, если в некоторой области будет большое скопление нейронов, то несколько нейронов может попасть в область одного класса и разделить его на подклассы – оранжевая область на рисунке 7. Что в принципе не так и критично, ведь дальнейшая обработка сигналов слоя может исправить ситуацию, но все же за это придется расплатиться временем обучения.
Одним из вариантов решения данных проблем является метод, когда на начальных этапах корректируются веса не только одного нейрона-победителя, но и группы ближайших к нему векторов. Затем постепенно число группы уменьшается и в конце корректируется только один нейрон. Группу можно выбирать из отсортированного массива выходов нейронов. Нейроны из числа первых К максимальных выходов будут корректироваться.
Еще одним подходом в групповой настройке весовых векторов является следующий метод.
а) Для каждого нейрона определяется длина вектора коррекции
![]()
б) Нейрон с минимальным расстоянием объявляется победителем – Wп. Затем находится группа нейронов, коррекция которых находится в пределе расстояния С*Lп от Wп.
в) Веса этих нейронов корректируется по обычному правилу ![]() . Так проводится коррекция для всей выборки.
. Так проводится коррекция для всей выборки.
Параметр С в процессе обучения изменятся от некоторого числа (обычно от 1) до 0.
Третий интересный метод состоит в том, что каждому нейрону разрешается корректироваться только N/k раз за один проход по выборке. Где N – размер выборки, k – число нейронов. То есть если какой-то нейрон становится победителем чаще других, то он до конца прохода по выборке «выбывает из игры». Таким образом, остальные нейроны также могут обучаться.
2) метод выпуклой комбинации
Смысл метода в том, чтоб и весовые и входные векторы изначально поместить в одну область. Формулы для расчета текущих координат входных и начальных весовых векторов будут иметь вид:
![]() ,
, ![]()
где n – размерность входного вектора, a(t)- неубывающая функция по времени, с каждой итерацией увеличивает свое значение от 0 до 1, вследствие чего в начале все входные векторы совпадают с векторами весов, а в конце встают на свои места. При этом весовые вектора будут как бы «тянуться» за своими классами.
Вот в принципе и весь материал по базовой версии слоя Кохонена, который будет применяться в данной нейросети.
II. Ложки, поварешки и скрипты
Первый скрипт, который мы рассмотрим, будет собирать данные по барам, и составлять файл входных векторов. В качестве обучающего примера используем Машки.
Листинг 2. Создание файла входных векторов
// параметры входа #define NUM_BAR 10000 // число баров для обучения (число обучающих шаблонов) #define NUM_MA 5 // число скользящих #define DEPTH_MA 3 // число значений скользящей // создаем файл hFile = FileOpen(FileName, FILE_WRITE|FILE_CSV); FileSeek(hFile, 0, SEEK_END); // Составляем массив входов int i, ma, depth; double MaIn; for (i=NUM_BAR; i>0; i--) // проходим по барам и собираем значения веера МА { for (depth=0; depth<DEPTH_MA; depth++) //расчитываем скользящие средние for (ma=0; ma<NUM_MA; ma++) { MaIn=iMA(NULL, 0, 2+MathSqrt(ma*ma*ma)*3, 0, 1, 4, i+depth*depth)- ((High[i+depth*depth] + Low[i+depth*depth])/2); FileWriteDouble(hFile, MaIn); } }
Файл данных создается как средство переноса информации между приложениями. На первых порах, когда вы только знакомитесь с алгоритмами обучения, вам обязательно нужно будет смотреть на промежуточные результаты их работы, данные некоторых переменных, или нужно быстро менять обучающие условия.
Поэтому для начала мы рекомендуем использовать язык программирования высокого уровня (VB, VC++ и т.д.), так как пока средств отладки в MQL4 не хватает (надеюсь, что они появятся уже в пятой версии). В дальнейшем, когда вы уже будете знать все «подводные» камни ваших алгоритмов и функций, то можно будет перейти на MQL4. Тем более что конечную цель – индикатор или советник - в любом случае придется писать на нем.
Обобщенная структура классов
Листинг 3. Класс нейросети
class CNeuroNet : public CObject { public: int nCycle; // число циклов обучения до останова int nPattern; // число обучающих паттернов int nLayer; // число обучающих слоев double Delta; // требуемая минимальная ошибка выхода int nNeuron[iMaxLayer]; // число нейронов в слое (по слоям) int LayerType[iMaxLayer]; // типы слоев (по слоям) double W[iMaxLayer][iMaxNeuron][iMaxNeuron];// веса по слоям double dW[iMaxLayer][iMaxNeuron][iMaxNeuron];// коррекция веса double Thresh[iMaxLayer][iMaxNeuron]; // порог double dThresh[iMaxLayer][iMaxNeuron]; // коррекция порога double Out[iMaxLayer][iMaxNeuron]; // значение выхода double OutArr[iMaxNeuron]; // сортированные значения выхода слоя Кохонена int IndexWin[iMaxNeuron]; // сортированные индексы нейронов слоя Кохонена double Err[iMaxLayer][iMaxNeuron][iMaxNeuron];// ошибка double Speed; // Скорость обучения double Impuls; // Импульс обучения double in[100][iMaxPattern]; // Вектор входных значений double out[10][iMaxPattern]; // вектор выходных значяний double pout[10]; // предыдущий вектор выходных значяний double bar[4][iMaxPattern]; // бары, на которых учимся int TradePos; // направление ордера double ProfitPos; // полученная прибыль/убыток ордера public: CNeuroNet(); virtual ~CNeuroNet(); // функции void Init(int aPattern=1, int aLayer=1, int aCycle=10000, double aDelta=0.01, double aSpeed=0.1, double aImpuls=0.1); // функции обучения void CalculateLayer(); // Расчет выхода слоя void CalculateError(); // Расчет ошибки /для массива Target/ void ChangeWeight(); // Корректировка весов bool TrainNetwork(); // Обучение сети void CalculateLayer(int L); // Расчет выхода слоя Кохонена void CalculateError(int L); // Расчет ошибки слоя Кохонена void ChangeWeight(int L); // Корректировка весов для указания слоя bool TrainNetwork(int L); // Обучение слоя Кохонена bool TrainMPS(); // Обучение сети на получение наилучшего профита // переменные для обмена с внешним миром bool bInProc; // флаг входа в функцию TrainNetwork bool bStop; // флаг для принудительного прекращения функции TrainNetwork int loop; // номер текущей итерации int pat; // номер текущего обрабатываемого паттерна int iMaxErr; // паттерн с максимальной ошибкой double dMaxErr; // максимальная ошибка double sErr; // квадрат ошибки паттерна int iNeuron; // максимальное число нейронов при корректировке слоя Кохонена int iWinNeuron; // число нейронов победителей в слое Кохонена int WinNeuron[iMaxNeuron]; // массив активных нейронов (упорядоченный) int NeuroPat[iMaxPattern][iMaxNeuron]; // массив активных нейронов void LinearCovariation(); // Нормирование выборки void SaveW(); // Анализ нейронной активности };
В принципе класс не сложный. В нем имеется основной джентльменский набор + сервисные переменные.
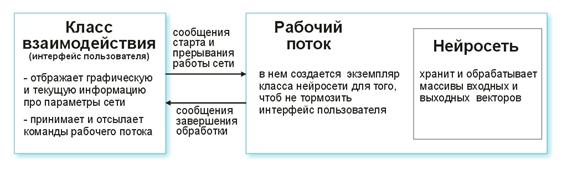
Разберем все по порядку. Интерфейсный класс по команде пользователя создает рабочий поток и инициализирует таймер для периодического снятия показаний нейросети. Также получает указатели для съема информации с параметров нейросети. Рабочий поток в свою очередь сначала читает массивы входных/выходных векторов из заранее подготовленного файла и задает параметры слоев (типы слоев и число нейронов в каждом слое). Это подготовительный этап.
Затем вызывается функция CNeuroNet::Init, в которой инициализируются веса, нормируется выборка и задаются параметры обучения (скорость, импульс, требуемая ошибка и число циклов обучения). И только потом вызывается «рабочая лошадка» - функция CNeuroNet::TrainNetwork (или TrainMPS, или TrainNetwork(int L), смотря что мы хотим получить). По окончанию обучения рабочий поток сохраняет веса сети в файл для воссоздания последней в индикаторе или советнике.
III. Выпекаем сеть
Перейдем теперь к вопросам обучения. Обычной практикой при обучении является задание пары «образец-учитель». То есть для каждого входящего образца соответствует вполне конкретная цель. И на основании отличия текущего выходного и целевого проходит корректировка весов. Например, исследователь хочет, чтоб сеть при предъявлении ей данных про цены закрытия 10 предыдущих баров предсказывала цену закрытия следующего бара. В таком случае мы должны после подачи на вход 10 значений сравнивать получаемый выход и учительское значение и затем откорректировать веса на разницу между ними.
В предлагаемой нами модели выходных «учительских» векторов в обычном понимании не будет, так как мы заранее не знаем, на каких барах нам нужно входить или выходить из рынка. Это значит, что наша сеть будет корректировать свои выходные вектора на своих же предыдущих выходных показаниях. То есть сеть будет стремиться к получению максимального профита (максимизации числа верно угаданных направлений торговли). Рассмотрим пример на рисунке 8.
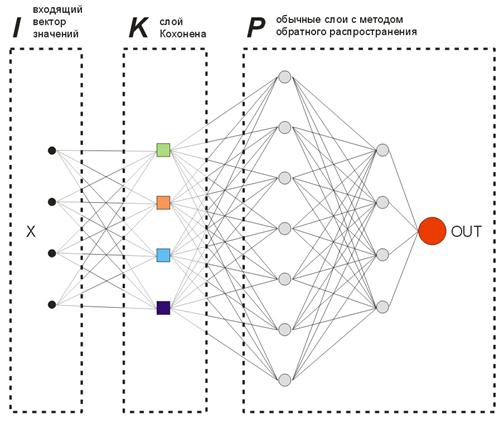
Рис. 8. Схема обучаемой нейросети
Слой Кохонена, предварительно обученный на выборке, подает свой вектор дальше в сеть. На выходе последнего слоя сети будем иметь число OUT, которое интерпретируем следующим образом. Если OUT>0.5, то входим на покупку, если OUT<0.5, то входим на продажу (значения сигмоида изменяются в пределах [0, 1]).
![]()
Допустим, что на некоторый входящий вектор Х1 сеть откликнулась выходом OUT1>0.5. Значит, на этом баре, к которому принадлежит образец, мы открываем позицию на покупку. Дальше, при хронологической подаче входных векторов на некотором Хk знак OUTk меняется на "противоположный". Следовательно, мы закрываем позицию покупки и открываем продажу.
Именно в этот момент мы должны посмотреть на результат закрытого ордера. Если получили прибыль – то можем усилить этот сигнал. Или посчитать что, ошибки нет, и ничего корректировать не будем. Если же получили убыток, то корректируем веса слоев так, чтоб вход по сигналу вектора Х1 показывал OUT1<0.5.
Теперь мы должны вычислить значение учительского (целевого) выхода. В качестве такового возьмем значение сигмоида от полученного убытка (в пунктах), умноженного на знак направления торговли. Следовательно, чем больше будет получаемый убыток, тем больше будет «наказываться» сеть и корректировать свои веса на большее значение. Например, если получили -50 пунктов убытка при покупке, то корректировка будет вычисляться для выходного слоя так:
![]() ,
, ![]() ,
, ![]()
Можно ограничить правила торговли, введя в процесс анализа сделок параметры тейкпрофита (ТП) и стоплоса (СЛ) в пунктах. Итого мы должны отслеживать 3 события: 1) смена знака OUT, 2) цена изменилась от цены открытия на величину ТП, 3) цена изменилась от цены открытия на величину -СЛ.
При наступлении одного из этих событий корректировка весов проходит в аналогичном порядке. Если получили прибыль, то веса или не трогаются или корректируются (усиление сигнала). Если получили убыток, то корректируются, чтоб вход по сигналу вектора Х1 показывал OUT1 с «нужным» знаком.
Единственным минусом данного ограничения есть то, что мы привязываемся к абсолютным величинам ТП и СЛ, что не очень хорошо для оптимизации сети на длительном промежутке времени в нынешних условиях рынка. По личным наблюдениям тейкпрофит и стоплос не должны сильно отличаться друг от друга.
То есть, система должна быть симметричной, чтоб при обучении не поймать отклонение в сторону более глобального тренда на покупку или продажу. Также бытует мнение делать тейкпрофит в 2-4 раза больше чем стоплос, искусственно повышая соотношение прибыльных и убыточных сделок. Но опять-таки при этом мы рискуем обучить сеть со сдвигом на тренд. Оба эти варианта, конечно, имеют право на жизнь, но вы в своих исследованиях должны проверять оба.
Листинг 4. Одна итерация настройки весов сети
int TradePos; int pat=0; // открываем ордер для первого шаблона for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][pat]; // взяли обучающий шаблон CalculateLayer(); // рассчитали выход сети TradePos=TradeDir(Out[nLayer-1][0]); // если выход больше 0.5, то покупка, иначе продажа ipat=pat; // запомнили шаблон for(pat=1;pat<nPattern;pat++) // проходим по шаблону и обучаем сеть { for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][pat]; // взяли обучающий шаблон CalculateLayer(); // рассчитали выход сети ProfitPos=1e4*TradePos*(bar[3][pat]-bar[3][ipat]); // считаем прибыль/убыток по ценам закрытия [3] // если поменялось направление торговли или сработал стоп-ордер if (TradeDir(Out[nLayer-1][0])!=TradePos || ProfitPos>=TP || ProfitPos<=-SL) { // корректируем веса Out[nLayer][0]=Sigmoid(0.1*TradePos*ProfitPos); // задали требуемы выход сети for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][ipat];// взяли шаблон, по которому // открывались CalculateLayer(); // рассчитали выход сети CalculateError(); // рассчитали ошибку ChangeWeight(); // подкоректировали веса for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][pat]; // переходим на новый ордер CalculateLayer(); // рассчитали новый выход сети TradePos=TradeDir(Out[nLayer-1][0]); // если выход больше 0.5, то покупка, //иначе продажа ipat=pat; // запомнили шаблон } }
Такими несложными проходами сеть в результате распределит полученные классы от слоя Кохонена так, чтоб для каждого из них соответствовал сигнал входа в рынок с максимальным числом профитов. Или если смотреть с точки зрения статистики – каждый входной шаблон настраивается сетью на групповую работу.
Так как один и тот же входной вектор может в процессе подстройки весов давать сигналы в разные стороны, постепенно получив максимальное число правильных угадываний, этот метод обучения можно назвать динамическим. А используемый подход – больше известный как Система Максимизации Прибыли (MPS).
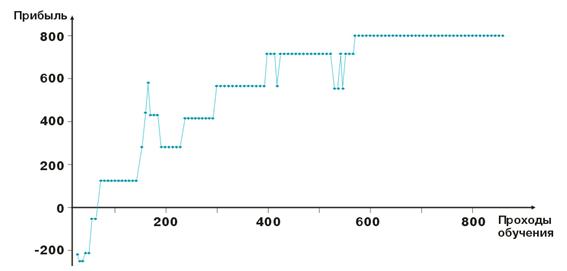
Вот результаты "подгонки" весов сети. Каждая точка на графике – это значение в пунктах полученной прибыль за один проход обучаемого периода. Система находится всегда в рынке, тейкпрофит=стоплос=50 пунктов, фиксация только по стоп-ордеру, корректировка весов в случае прибыли и убытка.
Как видим, после отрицательного начала веса слоёв настраиваются так, что уже в районе сотой итерации прибыль становится положительной. Характерно также то, что система как бы притормаживается на некоторых уровнях. Это связано с параметрами скорости обучения.
Как вы могли заметить в листинге 2, прибыль ProfitPos считается по ценам закрытия бара, на котором вошли, и на котором сработало одно из условий (стоп-ордер или сменился сигнал). Это, конечно, немного грубоватый метод, особенно для случая со стоп-ордерами. Можно добавить некоторое усложнение, анализируя цены High и Low бара (bar[1][ipat] и bar[2][ipat] соответственно). Пусть это станет вашим домашним заданием.
Переворачивать или искать входы?
Итак, мы познакомились с динамическим методом обучения, который учит сеть на своих же ошибках. Наверно вы заметили, что по алгоритму мы находимся в рынке всегда, фиксируем прибыль/убыток и бежим дальше в бой. Но наверно надо как-то ограничить наши входы и пытаться входить в рынок только на «хороших» входных векторах. Точнее надо определить зависимость уровня сигнала сети для входа от числа прибыльных/убыточных сделок.
Делается это довольно просто. Введем переменную 0<М<0.5, которая будет критерием требуемого входа. Если Out>0.5+M, то покупка, если Out<0.5-M, то продажа. Мы отсеиваем входы и выходы от тех векторов, которые лежат между 0.5-M<Out<0.5+M.
Другой способ отсеивания ненужных векторов – собрание статистической информации о прибыльности ордера от значений конкретных выходов сети, назовем его визуальный анализ. Перед этим мы должны определиться со способом закрытия позиции – срабатывания стоп-ордера, смена знака выхода сети. Далее составляем таблицу Out | ProfitPos. Значения Out и ProfitPos вычисляются для каждого входного вектора (т.е. для каждого бара).
Затем делаем сводную таблицу с суммированием поля ProfitPos. В результате будем видеть зависимость значения Out и полученную прибыль. Выделяем диапазон Out=[MLo, MHi], на котором имеем наилучшую прибыль и используем его значения в торговле.
Назад к MQL4
Начав разработку в VС++, мы нисколько не пытались приуменьшить возможности MQL4. Просто так удобнее. Расскажу случай. Недавно одному знакомому понадобилась базу данных предприятий города. В Интернете очень много справочников, но к кому он не обращался, никто не хотел продавать базу.
Тогда мы просто написали скрипт на MQL4, который сканирует html-страницу и выделяет из нее область, где находятся данные о предприятии, и загоняет в текстовый файл. Осталось только отредактировать файл в Excel и база данных трех крупных справочников со всеми телефонами, адресами, видами деятельностями готова. Знакомый получил самую полную базу в городе, а лично я – чувство гордости за простоту и возможности MQL4.
Понятно то, что каждый человек может решать одну задачу в разных языках, но лучше выбирать тот, который будет оптимален по соотношению возможность/сложность для конкретной задачи.
Итак, после тренировки сети мы должны сохранить все ее параметры в файл для передачи в MQL4.
- размерность входного вектора
- размерность выходного вектора
- число слоев
- число нейронов по слоям – от входного до выходного
- веса нейронов по слоям
Индикатор будет использовать только одну функцию из арсенала класса CNeuroNet – CalculateLayer. Формируем входной вектор для каждого бара, вычисляем значение выхода сети и строим индикатор [6].
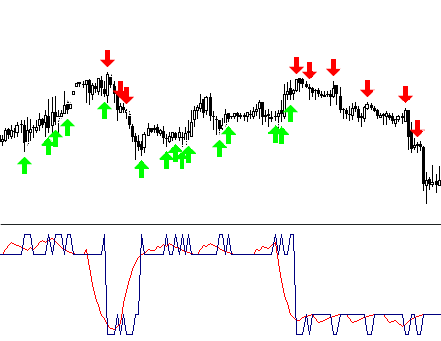
Если мы уже определились с уровнями входа, то можно закрасить участки полученной кривой разными цветами.
Пример кода !NeuroInd.mq4 в конце статьи.
IV. Творческий подход
Если делать хорошо, нужно мыслить широко. Нейросети не исключение. Не думаю, что предложенный вариант идеальный и подойдет для любой вашей задачи. Поэтому вы всегда должны искать свои решения, составлять общую картину, систематизировать и проверять идеи. Ниже содержится несколько предупреждений и советов.
- адаптация сети. Как известно, нейросеть – это аппроксиматор. Нейросеть восстанавливает вид кривой при предъявлении ей узловых точек. Если точек будет слишком много, то дальнейшее построение в будущее даст плохие результаты. Для этого необходимо убирать старые исторические данные из обучения и добавлять новые. Таким образом, производится аппроксимация к новому полиному.
- переобучение. Возникает при «идеальной» подгонке (или при обучении сети помехам входных значений). В результате при подаче проверочного значения сеть выдаст неправильный результат (рисунок 9).
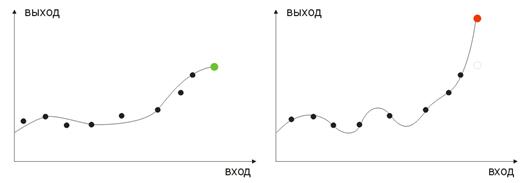
Рис. 9. Результат "переобученной" сети - неправильное прогнозирование
- сложность, повторяемость, противоречивость обучающей выборки. В работах [8, 9] рассмотрена зависимость между перечисленными параметрами. Наверное, понятно всем, что если для одного и того же обучающего вектора соответствуют разные учительские вектора (а еще хуже если противоречивые), то сеть никогда не научится правильно классифицировать их. Для этого советуется составлять входные вектора большой размерности, чтоб в них были данные, которые позволяют разделить их в пространстве классов. На рисунке 10 представлена эта зависимость. Чем больше сложность входного вектора, тем меньше повторяемость и противоречивость образцов.
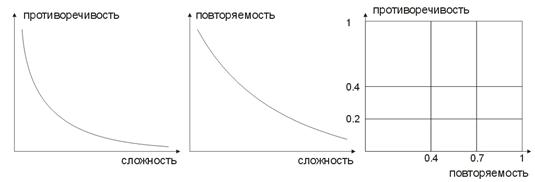
Рис. 10. Зависимости характеристик входных векторов
- обучение сети методом Больцмана. Это метод несколько похож на перебор всевозможных вариантов весов. В статье Как найти прибыльную торговую стратегию рассматривается советник ArtificialIntelligence, который в своем обучении работает по похожему принципу. При обучении своей сети он перебирает абсолютно все варианты значений весов (как взлом пароля к почтовому ящику) и выбирает самую лучшую комбинацию.
Это трудоемкая задача для машины, поэтому число всех весов сети ограничено десятком. Например, если вес изменяется от 0 до 1 с шагом 0,01, то нам понадобиться 100 шагов. Для 5 весов это будет 5100 комбинаций. Согласитесь, это довольно большое число и современной машине это не под силу. Единственный способ построить таким методом сеть – это использовать очень много машин, давая каждой свой участок работы.
Желающие вполне могут осуществить его с 10 машинами. Тогда на каждую придется всего по 510 комбинаций, а значит можно усложнить сеть, используя большее число весов, слоев и шагов.
В отличие от такого «Brut Force Attack», метод Больцмана действует мягче и главное быстрее. На каждой итерации задается случайное смещение весу. Если с новым весом система улучшает свои выходные характеристики, то вес оставляется, и переходим на новую итерацию.
Если вес увеличивает ошибку выхода, то он оставляется с вероятностью, определяемой по формуле распределения Больцмана. Таким образом, поначалу выход сети может иметь самые разные значения, постепенно «охлаждаясь» приводя сеть в искомый глобальный минимум [10, 11].
Конечно, это далеко не полный перечень направлений в ваших будущих исследованиях, есть еще генетические алгоритмы, методы ускорения сходимости, сети с памятью, радиальные сети, ассоциативные машины и много другое.
Заключение
Хотелось бы добавить, что нейросеть - это не панацея от всех ваших проблем в трейдинге. Кто-то выбирает самостоятельную работу и создание своих алгоритмов, а для кого-то лучшим вариантом будет использование готовых нейропакетов, которых сейчас на рынке большое количество.
Главное - не бойтесь экспериментировать! Удачи и больших профитов!
Рекомендуемая литература
1. Бэстенс Д.-Э., Ван ден Берг В.-М., Вуд Д. Нейронные сети и финансовые рынки: принятие решений в торговых операциях. – М.: ТВП, 1997. – хх. – 236 с.
2. Вороновский Г.К. и др. Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности. – Х.: Основа, 1997. – 112 с.
3. Галушкин А.И. Теория нейронных сетей. Кн. 1: Учебное пособие для вузов/ Общ. ред. А.И. Галушкина. – М.: ИПРЖР, 2000. – 416 с. (Нейрокомпьютеры и их применение)
4. Дебок Г., Кохонен Т. Анализ финансовых данных с помощью самоорганизующихся карт / Пер. с англ. – М.: Альпина, 2001. – 317 с.
5. Ежов А.А., Шумский С.А. Нейрокомпьютинг и его применения в экономике и бизнесе (серия “Учебники экономико-аналитического института МИФИ” под ред. проф. В.В. Харитонова). М.: МИФИ, 1998. – 224 с.
6. Иванов Д.В. Прогнозирование финансовых рынков с использованием искусственных нейронных сетей Дипломная работа, Владивосток, 2000
7. Осовский С. Нейронные сети для обработки информации / Пер. с польского И.Д. Рудинского, М.: Финансы и статистика, 2002. – 344 с.
8. Тарасенко Р.А., Крисилов В.А., Выбор размера описания ситуации при формировании обучающей выборки для нейронных сетей в задачах прогнозирования временных рядов
9. Тарасенко Р.А., Крисилов В.А., Предварительная оценка качества обучающей выборки для нейронных сетей в задачах прогнозирования временных рядов
10. Уоссермен Ф. Нейрокомпьютерная техника: теория и практика
11. Хайкин Саймон. Нейронные сети: полный курс, М.: Издательский дом «Вильямс», 2006. – 1104 с.
12. www.wikipedia.org
13. Великий и могучий интернет
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Каналы. Продвинутые модели. Волны Вульфа
Каналы. Продвинутые модели. Волны Вульфа
 Программная папка клиентского терминала MetaTrader 4
Программная папка клиентского терминала MetaTrader 4
 Эффективные алгоритмы усреднения с минимальным лагом и их использование в индикаторах и экспертах
Эффективные алгоритмы усреднения с минимальным лагом и их использование в индикаторах и экспертах
 Спать или не спать?
Спать или не спать?
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
"профессиональный плюсовый код НС" искать не надо, как и многие другие математические функции, нужен код иди на www.scilab.org ... лет так через десять ты закочишь блуждать в чужом "открытом коде".
Думаю автор статьи, просто хотел чтобы его поняли все, и упростил код для Вашего блага.
Спасибо за оценку моих способностей разобраться в чужом коде. Вопрос не в этом, читайте внимательно текст поста.
По поводу статьи, все намного проще, если заглянуть в код. У автора родилась идея автоматической кластеризации рыночных ситуаций на основе карт Кохонена. Логично, сначала определяем, категорию, затем отдаем результат на обученную backprop сеть, которая даст ответ, куда открываться. Однако в процессе разработки автор понял, что карты сами никаких полезных (с т.з. трейдера) кластеров не найдут, более того, на выходе карт получается вектор нулей и одна единица (некий класс) и из этих нулей и одной единицы сеть с обратным распространением ошибки вообще ничего не определит (чему обучать то, когда не понятно, что за класс?). Поэтому автор "упростил" и без того простой код, выбросив слой Кохонена, и выложил то, что осталось, сообществу, видимо, в надежде, что никто в этом копаться не будет. Статья получилась, безусловно, красивая :), но идея, к сожалению, тупиковая :(.
Спасибо за оценку моих способностей разобраться в чужом коде. Вопрос не в этом, читайте внимательно текст поста.
По поводу статьи, все намного проще, если заглянуть в код. У автора родилась идея автоматической кластеризации рыночных ситуаций на основе карт Кохонена. Логично, сначала определяем, категорию, затем отдаем результат на обученную backprop сеть, которая даст ответ, куда открываться. Однако в процессе разработки автор понял, что карты сами никаких полезных (с т.з. трейдера) кластеров не найдут, более того, на выходе карт получается вектор нулей и одна единица (некий класс) и из этих нулей и одной единицы сеть с обратным распространением ошибки вообще ничего не определит (чему обучать то, когда не понятно, что за класс?). Поэтому автор "упростил" и без того простой код, выбросив слой Кохонена, и выложил то, что осталось, сообществу, видимо, в надежде, что никто в этом копаться не будет. Статья получилась, безусловно, красивая :), но идея, к сожалению, тупиковая :(.
Доброго времени суток!
Люблю людей которые умеют читать!
Первая статья, которую я прочитал про НС, была г-на Решетова, Combo - кстати своего рода бестселлер, почему? Простая линейная НС, несложный алгоритм, "маленькие доработки" и результат 65-75% выигрышных сделок МТС, с маленьким "но". Не более трех-четырех дней работы... далее опять настраивать НС. Именно с того момента начал изучать НС, в результате чего появилась моя первая Dll библиотека, нелинейной НС - персептрона. Особых выигрышей от этого я не получил, плюс 2-3% к выигрышу, и более 850 строк C++ кода, который надо было еще "дорабатывать лобзиком". Именно тогда понял, что строить самостоятельно свой код на С++: НС, генетический и прочие математические методы обработки временных рядов, дело скажем неблагодарное, легче взять готовое решение, тем более что продуктов математической обработки достаточно. А Вас лично не хотел обижать, и писав строки "...лет так через десять ты закочишь блуждать в чужом открытом коде..." хотел подчеркнуть, что лишь единицы легко налету читают С/С++, и обычно они тестируют Linux, на чем и зарабатывают не малые деньги. У scilab открытый код, выдергивай, но это не тот путь, которым следует идти, это трата Вашего бесценного времени на теоретическую часть модели МТС, а практической кто будет заниматься? Решать Вам.
На счет статьи: красивая, хорошая и легкий язык. Чего не хватает? Для статьи достаточно, для книги мало индикаторов... любая НС требует много данных, такова её природа - великий аппроксиматор!