
ニューロネット用レシピ
はじめに
少し前、間違いなくトレーダーが必ずしもコンピュータを持たなかったテクニカル分析の黎明時、人は自分が編み出した式や規則を使って将来の価格を予想しようとしていたようでした。そういう人たちはペテン師と呼ばれたものです。時は流れ、情報処理手法はより複雑化し、今やテクニカル分析に無関心なトレーダーはほとんどいません。どんな初心者トレーダーでもチャート、さまざまなインディケータ、規則検索を簡単に利用できるのです。
外為トレーダー数は日に日に伸びています。それに伴い、彼らの市場分析手法に対する要求も高まっています。そのような『相対的』新手法の一つが理論的には、ファジー理論とニューラルネットワークの使用です。これら疑問に対するトピックはさまざまなテーマのフォーラムで積極的に議論されているのがわかります。それらは存在し、これからも存在し続けるのです。市場に参入した人はめったに去ることをしません。それが人の知性、脳、意志の強さへの挑戦である間は。トレーダーが何か新しいことを学習することや、実践で多様な方法を使うのをやめないのはそのためです。
本稿では、ニューロネット作成の基本を分析し、コホーネン ニューラルネットの概念を学習し、トレーディング最適化方法について少しお話します。本稿はまずニューロネットや情報処理原理の学習を始めたばかりのトレーダーを対象としています。
コホーネン層を持つニューラルネットワークを料理するには、以下が必要です。
1) 任意の通貨ペアの履歴バー 10,000 本
2) 移動平均(またはその他どんなインディケータも。みなさん次第です) 5 グラム
3) 逆分布 2~3 層
4) 最適化方法 詰め物として
5) 付け合わせの野菜に、成長しているバランスと正確に推測されたトレード方向
セクション1 コホーネン層のレシピ
まさにこれから始める人のために本セクションからスタートします。コホーネン層のトレーニングに対するさまざまな方法です。もっと正確に言うなら、その基本バージョンに関してです。というのもそのバリアントが数多く存在するためです。本章にはなんら目新しいものはありません。説明はすべてこのテーマに関する従来の資料から採られています。ただこの章の利点は各セクションについて説明の画像がふんだんにあることです。
本章では以下の課題について詳しく説明していきます。
-コホーネンウェイトベクトルの調整方法
-入力ベクトルの事前準備
-コホーネンニューロンの初期ウェイト選択
ウィキペディアによると、コホーネンニューラルネットワークはある種のニューラルネットワークを代表し、その主要なエレメントはコホーネン層である、ということです。コホーネン層は適応型線形加算器(『線形フォーマルニューロン』)で構成されています。原則として、コホーネン層のアウトプット信号は『勝者占有』のルールに従って処理されます。もっとも大きな信号が 1、その他はゼロになるのです。
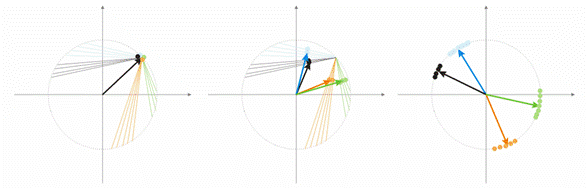
例を用いてこの概念をお話します。可視化のためには、計算はすべて二次元の入力ベクトルとして出されます。図1 では、入力ベクトルが色づきで表示されています。コホーネン層(その他の層のように)のニューロンはすべて、単純にインプットをウェイトで掛け、合計します。実際、コホーネン層のウェイトはすべてこのニューロンに対するベクトル座標です。
よって、コホーネンニューロンそれぞれのアウトプットは2つのベクトルの内積です。幾何学から、ベクトル間の角度が傾けば(角度のコサインが1に傾く)、最大内積はゼロになることがわかっています。よって、最大値は入力ベクトルにもとも近いコホーネンニューロンの値なのです。
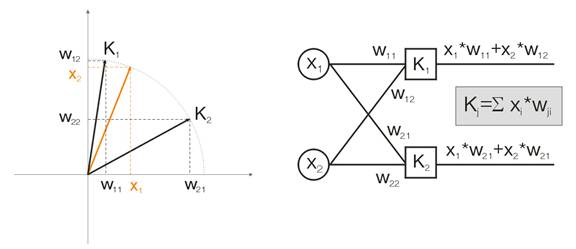
図1 勝者はそのベクトルが入力シグナルにもっとも近いニューロンである
定義から、全ニューロンの中で最大のアウトプット値を見つけ、そのアウトプットを1に割り当て、ゼロをその他ニューロンすべてに割り当てます。そうすると、コホーネン層は入力ベクトルがどの空間領域にあるのか『答えて』くれます。
コホーネンウェイトベクトルの調整
層トレーニングの目的は上述のとおり、入力ベクトルの精密な空間分類です。これは各ニューロンが特定の領域に関与し、そこでそれが勝者となっていることを意味します。インプット ニューロンからの勝者ニューロンの偏差の誤差はその他ニューロンの偏差の誤差よりも小さいはずですそれを達成するには、勝者ニューロンが入力ベクトルの側に『向きを変えます』。
図2 は2つのニューロン(黒のニューロン)が 2 つの入力ベクトル(色付きのベクトル)に分割されることを示しています。

図2 各ニューロンはもっとも近い入力信号に近づきます。
各反復で勝者ニューロンは『それ自体』の入力ベクトルに近づきます。その新しい座標は以下の式で計算されます。
![]()
ここで、A(t) は時間 t によって決まるトレーニング速度のパラメータです。これは各反復で 1~0 に減る非増加関数です。初期値が A=1 であれば、ウェイト修正は1段階で行われています。これは各入力ベクトルに対してコホーネンニューロンが1つ(たとえば、入力ベクトル10、コホーネン層のニューロン10)の場合に可能です。
ただし、実際にはそのようなケースにはほとんどお目にかかりません。なぜなら、通常、大容量の入力データは似通ったデータにグループ分けされ、そのため入力データの多様性が減じるからです。それが値 A=1 が望ましくない理由です。実践によって最適な初期値は0.3より小さいものであることがわかっています。
また、A は入力ベクトル数に反比例します。すなわち、大規模な選択では、勝者ニューロンが修正中に全空間をくまなく見ていくことのないように、小さな修正を行う方がよいのです。A の機能としては通常、単調に任意の減少関数が選択されます。たとえば、双曲線や線形減少、またはガウス関数です。
図3 はスピード A=0.5 でのニューロンウェイト修正のステップを示しています。このニューロンは入力ベクトルに近づき、誤差は小さいものです。
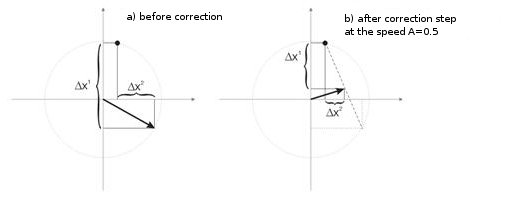
図3 入力信号の影響下でのニューロンウェイト修正
幅広いサンプルにおける小数のニューロン
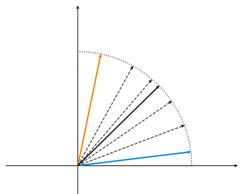
図4 2つの入力ベクトル間でのニューロン変動
図4(左)には、入力ベクトルが2つ(色表示)ありコホーネンニューロンは1つだけです。修正の過程でニューロンは1つのベクトルからもう1つのベクトル(点線)へ揺れ動きます。A の値が0まで減るに従い、ニューロンは 2 つのベクトルの間で安定します。時間で変化するニューロン座標はジグザグの線で特徴づけられます(図4 右)。
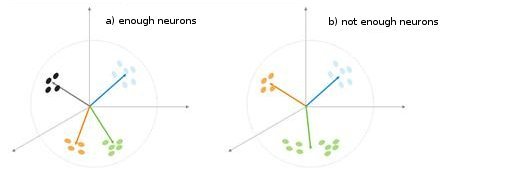
図5 ニューロンの数における分類タイプの依存性
もう一つの状況が図5で示されています。第1のケースでは、4つのニューロンがサンプルを適切に超球の4つの領域に分割しています。第2のケースでは、不十分な数のニューロンにより、異常を増やし、サンプルを再分類する結果につながっています。これにより、コホーネン層は分類されたサンプルのボリュームで決まる自由なニューロンを十分な数持つ必要がある、と結論づけることができます。
入力ベクトルの事前準備
Philip D. Wasserman が著書に著しているように、ネットに導入する前に入力ベクトルを正規化することが望ましい(必須ではありませんが)ものです。これは入力ベクトルの各成分をベクトル長で割ることで行います。この長さはベクトル成分の二乗の合計から平方根を抽出することで求められます。これは代数的な表現です。
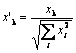
これは入力ベクトルを同方向の単位ベクトル、すなわち、n 次元空間にある単位長のベクトル、に変換します。これの意味するところは、明らかです。超球表面にある入力ベクトルをすべて予測すること、それによりコホーネン層に対する検索タスクを単純化することです。言い換えれば、入力ベクトルとコホーネンニューロン ベクトル間の角度を求めようとしているので、すべてのニューロンの機会を等しくしてベクトル長などの要因は排除する必要があるのです。
サンプルベクトルの要素が負の数ではない(たとえば移動平均値、価格)ことはありがちです。それらはすべて正の象限空間に集中しています。そのような『正の』サンプルを正規化した結果、正の領域だけに大規模なベクトルの蓄積を取得します。それは条件付けにとってはあまり良いことではありません。そのため、正規化の前にサンプルの平滑化が行われるのです。サンプルがかなり大きい場合は、主要サンプルから遠く離れた『異分子』は含まずベクトルがおよそ一領域にあると予想できます。よって、サンプルは『極端な』座標に相対的に中央にあるのです。
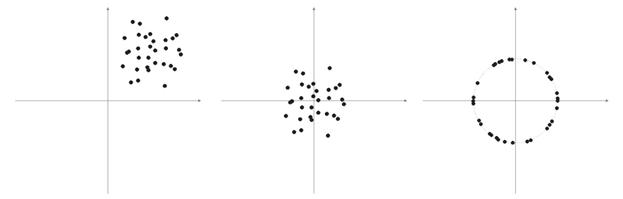
図6 入力ベクトルの正規化
上述のように、ベクトルの正規化が望まれます。それはコホーネン層の修正を簡単にします。ただし、サンプルを明確に表し球上に投影されるか否かを判断する必要があります。
リスト1 入力ベクトルを範囲 [-1, 1] に狭める
for (N=0; N<nNeuron[0]; N++) // for all neurons of the input layer { min=in[N][0]; // finding minimum in the whole sample for (pat=0; pat<nPattern; pat++) if (in[N][pat]<min) min=in[N][pat]; for (pat=0; pat<nPattern; pat++) in[N][pat]-=min; // shift by the value of the minimal value max=in[N][0]; // finding maximum in the whole sample for (pat=0; pat<nPattern; pat++) if (in[N][pat]>max) max=in[N][pat]; for (pat=0; pat<nPattern; pat++) in[N][pat]=2*(in[N][pat]/max)-1; // narrowing till [-1,1] }
入力ベクトルを正規化する場合、それに応じてニューロンのウェイトもすべて正規化する必要があります。
初期ニューロンウェイトの選択
可能なバリアントは多数あります。
1) 通常ニューロンに行われると同様に、ウェイトにはランダムな値が割り当てられます(ランダム化)
2) 例による初期化。トレーニングサンプルから無作為に選択された例の値が初期値として割り当てられる場合。
3) リニア初期化。この場合、ウェイトはデータの初期設定から2つのベクトルの間にあるリニア空間全体とともに線的に整理あれたベクトル値で開始されます。
4) ウェイトはすべて同じ値を持ちます-凸結合の方法。
第1と最後のケースを分析します。
1) ウェイトにはランダムな値が割り当てられます。
ランダム化の間、ベクトル ニューロはすべて超球の表面に分布します。と同時に、入力ベクトルはグループ化傾向にあります。この場合、ウェイトベクトルの一部は入力ベクトルからひじょうに離れているので、それらは決してより良い相関を持てず、結果的に学習ができません-図7 の『グレー』の数字(右)。また、残りのニューロンは異常を最小限に抑え、同様のクラスに分割するには十分ではありません-『赤色』のものは『グリーン』のニューロンに含まれます。
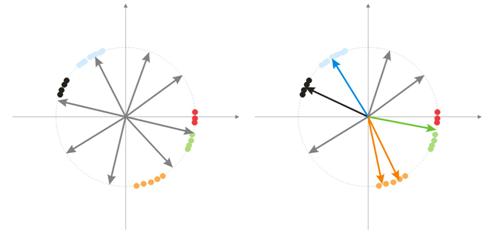
図7 ランダム化されたニューロンのトレーニング結果
一つの領域に大規模な蓄積されたニューロンがある場合、いくつかのニューロンがあるクラスの領域に入ることができ、それを下位クラスに分けます-図7 のオレンジの領域。これは重要ではありません。というのも、のちの層シグナルの処理は状況を修正できますが、これにはトレー二ング時間がかかります。
こういった問題を解決するためのバリアントの一つは、初期段階で勝利ニューロンのベクトルだけではなく、それにもっとも近いベクトルグループにに対しても相関が作られるときの方法です。それからグループ数は徐々に減少し、最終的に1ニューロンだけが修正されます。グループはニューロンアウトプットのソートされた配列から選択可能です。最初の K 最大アウトプットからのニューロンは修正されます。
ウェイトベクトルのグループ調整におけるもう一つの方法は以下のものです。
a) 各ニューロンに対して、修正ベクトル長が定義されます。
![]()
b) 最短距離のニューロンが勝者- Wn、となります。その後、ニューロングループがもし見つかれば、その修正は Wn から距離 C × Ln に制限されます。
c) これらニューロンのウェイトは単純なルールで修正されます![]() 。よってサンプル全体の修正が行われます。
。よってサンプル全体の修正が行われます。
C パラメータはなんらかの数字(通常は1から)から0へトレーニング過程で変化します。
3番目に興味深い方法は、ニューロンそれぞれがサンプルを1度通貨するにあたり、N ÷ k 回のみ修正されることを意味します。ここで、N はサンプルサイズ、k はニューロン数です。すなわち、任意のニューロンが別のニューロンより頻繁に勝者になる場合、それはサンプルをぜんぶ通過するまで『ゲームを降り』るのです。よって他のニューロも学習ができるのです。
2) 凸結合の方法
この方法の意味は、ウェイトと入力ベクトル両方が最初にある領域に配置される、ということです。入力ベクトルと初期ウェイトベクトルの現在座標計算式は以下です。
![]()
,
![]()
ここで、n は入力ベクトルの次元、a(t) は時間での非減少関数で、反復のたびに値を 0 ~1 に増加します。その結果、入力ベクトルはすべてウェイトベクトルと一致し、最終的にその場所を奪います。ウェイトベクトルはそのクラスに『到達します』。
以上が、本ニューラルネットワークに適用されるコホーネン層の基本バージョンにおける材料のすべてです。
II. スプーン、おたま、スクリプト
これから話す第1のスクリプトはバーにデータを集め、入力ベクトルのファイルを作成します。トレーニング例として MA を取り上げます。
リスト 2 入力ベクトルファイルの作成
// input parameters #define NUM_BAR 10000 // number of bars for training (number of training patterns) #define NUM_MA 5 // number of movings #define DEPTH_MA 3 // number of values of a moving // creating a file hFile = FileOpen(FileName, FILE_WRITE|FILE_CSV); FileSeek(hFile, 0, SEEK_END); // Creating an array of inputs int i, ma, depth; double MaIn; for (i=NUM_BAR; i>0; i--) // going through bars and collecting values of MA fan { for (depth=0; depth<DEPTH_MA; depth++) //calculating moving values for (ma=0; ma<NUM_MA; ma++) { MaIn=iMA(NULL, 0, 2+MathSqrt(ma*ma*ma)*3, 0, 1, 4, i+depth*depth)- ((High[i+depth*depth] + Low[i+depth*depth])/2); FileWriteDouble(hFile, MaIn); } }
データファイルはアプリケーション間の情報送信手段として作成されます。トレーニングアルゴリズムを知ろうとする場合、その動作の中間結果、一部の変数値、必要に応じてトレーニング条件の変化を注意して見ることを強くお薦めします。
レベルの高いプログラム言語(VB、VC++、など)の使用を推奨するのはそのためです。と同時に、現在の MQL4 のデバッグ方法は十分ではありません(この状況は MQL5 で改善されることを願っています)。のちに、みなさんのアルゴリズムや関数の落とし穴について学ぶとき、MQL4 を使い始めます。その上、MQL4 で最終的な目標(インディケータまたは Expert Advisor)を書かなくてはならなくなります。
クラスの一般構造
リスト 3 ニューラルネットワークのクラス
class CNeuroNet : public CObject { public: int nCycle; // number of learning cycles until stop int nPattern; // number of training patterns int nLayer; // number of training layers double Delta; // required minimal output error int nNeuron[iMaxLayer]; // number of neurons in a layer (by layers) int LayerType[iMaxLayer]; // types of layers (by layers) double W[iMaxLayer][iMaxNeuron][iMaxNeuron];// weights by layers double dW[iMaxLayer][iMaxNeuron][iMaxNeuron];// correction of weight double Thresh[iMaxLayer][iMaxNeuron]; // threshold double dThresh[iMaxLayer][iMaxNeuron]; // correction of threshold double Out[iMaxLayer][iMaxNeuron]; // output value double OutArr[iMaxNeuron]; // sorted output values of Kohonen layer int IndexWin[iMaxNeuron]; // sorted neuron indexes of Kohonen layer double Err[iMaxLayer][iMaxNeuron][iMaxNeuron];// error double Speed; // Speed of training double Impuls; // Impulse of training double in[100][iMaxPattern]; // Vector of input values double out[10][iMaxPattern]; // vector of output values double pout[10]; // previous vector of output values double bar[4][iMaxPattern]; // bars, on which we learn int TradePos; // order direction double ProfitPos; // obtained profit/loss of an order public: CNeuroNet(); virtual ~CNeuroNet(); // functions void Init(int aPattern=1, int aLayer=1, int aCycle=10000, double aDelta=0.01, double aSpeed=0.1, double aImpuls=0.1); // learning functions void CalculateLayer(); // Calculation of layer output void CalculateError(); // Error calculation /for Target array/ void ChangeWeight(); // Correction of weights bool TrainNetwork(); // Network training void CalculateLayer(int L); // Output calculation of Kohonen layer void CalculateError(int L); // Error calculation of Kohonen layer void ChangeWeight(int L); // Correction of weights for layer indication bool TrainNetwork(int L); // Training of Kohonen layer bool TrainMPS(); // Network training for getting the best profit // variables for internal interchange bool bInProc; // flag for entering the TrainNetwork function bool bStop; // flag for the forced termination of the TrainNetwork function int loop; // number of the current iteration int pat; // number of the current processed pattern int iMaxErr; // pattern with the maximal error double dMaxErr; // maximal error double sErr; // square of pattern error int iNeuron; // maximal number of neurons in Kohonen layer correction int iWinNeuron; // number of winner neurons in Kohonen layer int WinNeuron[iMaxNeuron]; // array of active neurons (ordered) int NeuroPat[iMaxPattern][iMaxNeuron]; // array of active neurons void LinearCovariation(); // normalization of the sample void SaveW(); // Analysis of neuron activity };
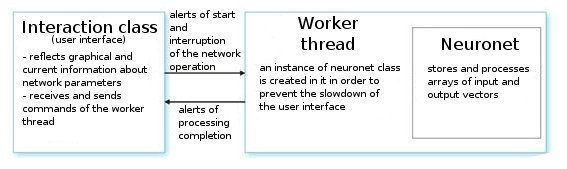
実際、クラスは複雑ではありません。それにはメインの必要セット+サービス変数が入っています。
それを分析します。ユーザーのコマンドにおいては、インターフェース クラスは作業スレッドを作成し、ネットワーク値を周期的に読み出すためのタイマーを初期化します。またニューロネットのパラメータから情報を読むためのインデックスを受け取ります。作業者スレッドに至っては、まず事前準備済みのファイルから入力/出力ベクターの配列を読み、層用のパラメータ(層タイプ、各層のニューロン数)を設定します。これが準備段階です。
その後、関数 CNeuroNet::Init を呼び出します。そこでウェイトが初期化され、サンプルが正規化され、トレーニング パラメータ(速度、インパルス、必要な誤差、トレーニングサイクル数)が設定されます。その後初めて、『働き者』-関数CNeuroNet::TrainNetwork(または TrainMPS または TrainNetwork(int L)を取得したいものに応じて呼び出します。トレーニングが終わると、作業者スレッドはインディケータや Expert Advisor に最後の一つを実装するためのファイルにネットワークウェイトを保存します。
III. ネットワークを焼く
トレーニングの問題に移ります。トレーニングでの恒例は、ペアの『パターン ティーチャー』を設定することです。それが各入力パターンに対応する一定の目標です。現在のインプットと目標値の間の差に基づいてウェイト修正が行われます。たとえば、研究者がネットに、ネットに提供された前の10本のバー価格に基づく次のバー価格を予想してほしいとします。この場合、10個の値の入力を設定したあと、取得したアウトプットとティーチャー値を比較し、その差についてウェイトを修正する必要があります。
われわれが提供するモデルでは、通常の意味での『ティーチング』ベクターはありません。なぜなら、どのバーで市場に参入し、市場から出るか前もってわからないからです。それは、われわれのネットワークは自分の前のアウトプット値に基づいてアウトプットベクトルを修正する、ということです。ネットワークは最大利益を得ようとする(正確に予想されたトレード方向数の最大化をする)、ということです。図8 で例を考察します。
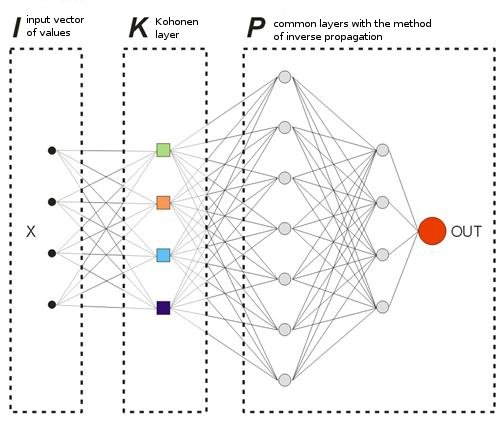
図8 トレーニングされたニューラルネットワークのスキーム
サンプルで事前にトレーニングされたコホーネン層は、そのベクトルをさらにネットワークに転送します。そのネットワークの最後の層のアウトプットで、値 OUT を取得します。それは次のように解釈されます。OUT>0.5 であれば、「買い」に参入する。OUT<0.5 であれば、「売り」に参入する(シグモイド値は [0, 1] の範囲で変化します)。
![]()
入力ベクトル X1 に対してネットワークが出力 OUT1>0.5 で応答したとします。それはパターンが属するバーで「買い」ポジションをオープンすることを意味します。その後、Xkにおける入力ベクトルの時系列表示で、記号 OUTk は『逆』に変わります。結果としおて、「買い」ポジションをクローズし、「売り」ポジションをオープンします。
まさにこの瞬間に、クローズした注文の結果を見る必要があるのです。利益を得たら、この警告を強化することができます。もしくは、異常がなくなにも修正しないと考えることができます。損失が出る場合、 X1 ベクトルのアラートで参入することが、OUT1<0.5 を示す、という方法で層のウェイトを修正します。
ここでティーチャー(目標)出力値を計算します。そのように、トレード方向の記号を掛けた取得済み損失(ポイント表示)からシグモイド値を取ります。結果、損失が大きいほど、ネットワークは厳しく罰せられ、大きな値でウェイトを修正します。たとえば、「買い」での損失ポイント=50 を取得すると、出力層に対する修正は以下のように計算されます。
![]() ,
, ![]() ,
, ![]()
ポイントでのテイクプロフィット(TP)とストップロス(SL)のトレード分析手順パラメータに取り入れることで、取引ルールを区切ることができます。よって3つのイベントを追跡する必要があります。1) OUT サインの変化、 2) TP の値により始値からの価格変化、3) SL の値により始値からの価格変化。
これらイベントのうちの1つが起こると、類似した方法でウェイトの修正が行われます。利益を得れば、ウェイトは変更なしのまま残るか、修正されます(より強いシグナル)。損失が出れば、ウェイトは修正されX1 ベクトルのアラートによりインプットに『望む』サインのある OUT1 を表示させます。
この制限の唯一のデメリットは、現在の市場条件では長期でネットワークの最適化に適していない絶対的な TP および SL 値を使用することです。私の通知に従って、TP と SL は互いにあまり違わないことです。
それは、トレーニング中の「買い」または「売り」トレンドの方向における偏差を避けるため、システムが対称でなければならないことを意味します。TP は SL より2~4倍大きくなければならないという意見もあります。そのため、故意に利益の出るトレードと損失を出すトレードの比率を増やします。ただし、その場合、トレンドに向かって移動するネットワークをトレーニングする危険を冒します。もちろん、この2種類のバリアントは存在しますが、両方、ご自分の調査で確認する必要があります。
リスト4 ネットワークウェイト設定の一回の反復
int TradePos; int pat=0; // open an order for the first pattern for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][pat]; // take the training pattern CalculateLayer(); // calculate the network output TradePos=TradeDir(Out[nLayer-1][0]); // if exit is larger than 0.5, then buy. Otherwise - sell ipat=pat; // remember the pattern for(pat=1;pat<nPattern;pat++) // go through the pattern and train the network { for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][pat]; // take the training pattern CalculateLayer(); // calculate the network output ProfitPos=1e4*TradePos*(bar[3][pat]-bar[3][ipat]); // calculate profit/loss at close prices [3] // if trade direction has changed or stop order has triggered if (TradeDir(Out[nLayer-1][0])!=TradePos || ProfitPos>=TP || ProfitPos<=-SL) { // correcting weights Out[nLayer][0]=Sigmoid(0.1*TradePos*ProfitPos); // set the desired output of the network for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][ipat];// take the pattern by which // CalculateLayer() were opened; // calculate the network output CalculateError(); // calculate the error ChangeWeight(); // correct weights for(i=0;i<nNeuron[0];i++) Out[0][i]=in[i][pat]; // go to the new order CalculateLayer(); // calculate the new output of the network TradePos=TradeDir(Out[nLayer-1][0]); // if output is > 0.5, then buy //otherwise sell ipat=pat; // remember the pattern } }
これら簡単な通過により、ネットワークは最終的にコホーネン層から、そのうちのそれぞれに対応する利益の最大数で市場参入のアラートがある、という方法で取得したクラスを分布します。統計的観点から、各入力パターンはグループ作業用にネットによって調整されます。
ある同一入力ベクトルがウェイト調整手続き中に異なる方向にアラートを出しているとき、徐々に真の予想の最大値を取得します。この方法はダイナミックと呼ばれます。使用される方法は MPS -利益最大化システム、として知られます。
以下にネットワークのウェイト調整結果があります。グラフの各点は、一つがトレーニング期間を通過する間、取得された利益値で、ポイントで表示されています。システムはつねに市場にあり、TakeProfit = StopLoss = 50 ポイント、固定はストップオーダーによってのみ行われ、ウェイトは利益と損失の場合に修正されます。
負から開始したあと、層のウェイトは、約100回目の反復で利益が正にんかるよう修正されています。興味深いのは、システムはレベルの一部で、一種のスピードダウンをしていることです。これはトレーニング速度のパラメータに関連しています。
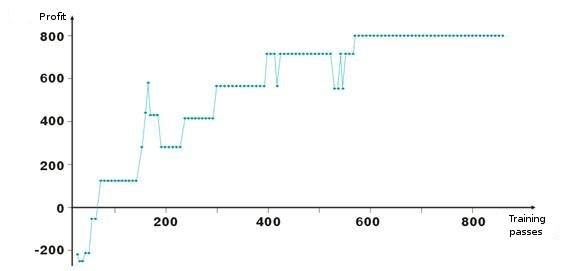
リスト2 でわかるように、利益ProfitPos はバーの終値によって計算され、その価格でわれわれは参入し、条件の一つが満たされています(ストップオーダーまたはアラート変化)。もちろん、特にストップオーダーに対しては、これはおおざっぱな方法です。バーの高値と安値を分析することでより複雑化することができます(それぞれ bar[1][ipat] および bar[2][ipat] )。ご自分で試してみることが可能です。
ターンするかまたはエントリを検索するか?
ネットワークが自分の誤りによってトレーニングするダイナミック法を調査しました。アルゴリズムに従い、われわれはつねに市場にいて利益/損し乙を固定し、先に進むことに気づいています。よって、われわれのエントリを区切り、『好ましい』入力ベクトルのときだけ市場参入をしてみることが必要です。それは、収益性ある/損失を出すトレード数に対して参入のネットワークアラートレベルの依存性を定義する必要があることを意味します。
それを行うのはひじょうに簡単です。必要なエントランス基準となる変数 0<M<0.5 を取り入れます。Out>0.5+M であれば買い、Out<0.5-M であれば売ります。0.5-M<Out<0.5+M の間のベクトル上にあるエントリおよびエグジットはふるい落とします。
不要なベクトルをふるい落とすためのもう一つ別の方法は、ネットワークの特定のアウトプット値からのオーダーの収益性についての統計的情報を収集することです。それを視覚分析と呼びます。その前に、ポジションをクローズする方法-ストップオーダー、ネットワークアウトプット変化、を定義します。それからテーブル Out | ProfitPos を作成します。Out と ProfitPos の値はそれぞれ入力ベクトル(すなわち、各バー)に対して計算されます。
その次に、ProfitPos フィールドの集計テーブルを作成します。結果として、Out 値と取得された利益の依存性を確認します。範囲 Out=[MLo、 MHi]を選択し、そこで最良の利益を取得し、取引でその値を使用します。
MQL4 に戻ります
VC++で作成を始めたからといって、MQL4 の可能性をおろそかにしようとしたのではありません。これは便宜のためです。ある出来事についてお話します。最近、ある知人が私たちが住む市の企業の基盤を入手しようとしました。インターネットには数多くのディレクトリがありますが、だれもその基盤を売却したいと思いませんでした。
われわれはページをスキャンし、企業に関する情報がある地域を選択し、それをファイルに保存するスクリプトを MQL4 で書きました。それからそのファイルを Excel で編集し、すべての電話番号、住所、企業活動が入った 3 冊分のイエローページのデータベースが準備できました。 これは市でもっとも完全なデータベースとなりました。私は、MQL4 の簡易さと可能性に誇りを感じました。
当然、同一タスクを異なる言語で行うことはできますが、特定のタスクに対しての可能性/難しさの比率という点で最適なものを選択するのがより良いものです。
ネットワークのトレーニング後、MQL4 に転送するため、そのパラメータをすべてファイルに保存します。
-入力ベクトルのサイズ
-出力ベクトルのサイズ
-層の数
-層ごとのニューロン数-入力から出力まで
-層ごとのニューロンウェイト
インディケータはクラス CNeuroNet~ CalculateLayerのアーセナルから関数1つだけを使用します。各バーに入力ベクトルを形成し、ネットワークの出力値を計算し、インディケータを構築します [6]。
すでに入力レベルを決めていたら、取得した曲線の部分を別の色で塗ります。
本稿にコード !NeuroInd.mq4 例の添付があります。
IV. クリエイティブな方法
首尾よく実装するためには広い心を持つことです。ニューラルネットワークも例外ではありません。私は、提供されているバリアントが理想的でどんなタスクにも適切であるとは思いません。そのため、つねに自分自身のソリューションを探し、一般的な絵を描き、体系化し、考えを確認する必要があるのです。以下は、いくつかの警告と推薦事項す。
- ネットワークの適応。ニューラルネットワークは近似です。ニューロネットは節点を取得すると曲線を復元します。点の数量が大きすぎると、以降の構築の結果は悪くなります。古い履歴データはトレーニングから削除し、新しい履歴データを追加する必要があります。これが新しい多項式に対して近似化が行われる方法です。
-過度なトレーニング入力値のノイズは『理想的な』調整時(またはネットのトレーニング時)に発生します。結果、検証値がネットワークに提供されるとき、誤った結果を表示するのです(図9)。
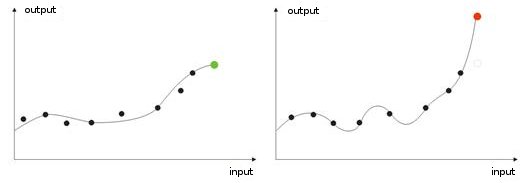
図9 『過度にトレーニングされた』ネットワークの結果-誤った予測
-トレーニング サンプルの複雑さ、再現性、矛盾。著作 [8, 9] で著者は列挙されたパラメータ間の依存性を分析しています。私は、異なるティーチング ベクトル(またはさらに悪ければ、矛盾したベクトル)がまったく同一の学習ベクトルに対応すれば、ネットワークは決して自分で正確に分類することを学習しないことは明らかである、と思います。これには、大きな入力ベクトルが作成され、それらがクラス空間で区別できるようなデータを持つようにすることが必要です。図10 はこの依存性を示しています。ベクトルが複雑になるほど、パターンの信頼性と矛盾は低くなります。
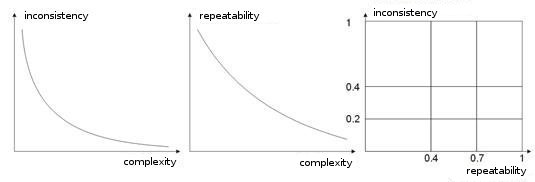
図10 入力ベクトルの特性の依存性
-ボルツマン手法によるネットワーク トレーニング。 この方法は多様な可能性あるウェイトのバリアントを試すことに似ています。Expert Advisor の人工知能はその学習において類似の原理に従って動作します。ネットワークをトレーニングするとき、ウェイト値のバリアントすべてをくまなく調べ(メールボックスのパスワードを破るように)、最良の組み合わせを選択するのです。
これはコンピュータにとって労働集約型のタスクで、ネットワークをの全ウェイト数が10に制限されているのはこのためです。たとえば、ウェイトが0.01ずつ0から1まで変化する場合、100ステップが必要となります。5 ウェイトに対してこれは5,100とおりの組み合わせを意味します。これは相当な数でこのタスクはコンピュータの能力を超えています。この方法でネットワークを構築する唯一の方法は、数多くのコンピュータを使用し、それぞれが特定部分を処理するようにすることです。
このタスクは10台のコンピュータで行うことができます。各コンピュータは510とおりの組み合わせを処理し、そうするとネットワークはより大きな数字のウェイト、層、ステップを持つ複雑なものに作ることができます。
そのような『総当たり攻撃』とは異なり、ボルツマン手法はよりソフトで静かなものです。各反復ではウェイトにおけるランダムな移動が設定されます。新しいウェイトでシステムが入力特性を改善するなら、ウェイトは受け入れられ、新しい反復が作成されます。
ウェイトが出力エラーを増やす場合、それはボルツマン分布の式で計算される確率で受け取られます。よって、はじめにネットワークの出力は完全に異なる値を持ち、ネットワークを必要な大域的最小値にもっていきつつ、次第に『クールダウン』するのです [10, 11]。
もちろん、これはみなさんのさらなる学習の完全リストではありません。遺伝的アルゴリズム、収束を改善する方法、メメリを持つネットワーク、ラジアル ネットワーク、関連マシン、などもあるのです。
おわりに
ニューロネットは、取引における問題に対する万能薬ではないことを付け加えたいと思います。独立した動作と独自のアルゴリズム作成を選択する人もいれば、マーケットで数多く見つけられる既製のニューロ パッケージを好んで使用する人もいます。
実験することを恐れないでください!グッドラック!大きな利益を!!
参照資料
1. Baestaens, Dirk-Emma; Van Den Bergh, Willem Max; Wood, Douglas. Neural Network Solutions for Trading in Financial Markets.
2. Voronovskii G.K. and others. Geneticheskie algoritmy, iskusstvennye neironnye seti i problemy virtualnoy realnosti (Genetic Algoritms, Artificial Neural Networks and Problems of Virtual Reality).
3. Galushkin A.I. Teoriya Neironnyh setei (Theory of Neural Networks).
4. Debok G., Kohonen T. Analyzing Financial Data using Self-Organizing Maps.
5. Ezhov A.A., Shumckii S.A. Neirokompyuting i ego primeneniya v ekonomike i biznese (Neural Computing and Its Use in Economics and Business).
6. Ivanov D.V. Prognozirovanie finansovyh rynkov s ispolzovaniem neironnyh setei (Forcasring of Financial Maarkets Using Artificial Neural Networks) (Graduate work)
7. Osovsky S. Neural Networks for Data Processing .
8. Tarasenko R.A., Krisilov V.A., Vybor razmera opisaniya situatsii pri formirovanii obuchayushchey vyborki dlya neironnyh setei v zadachah prognozirovaniya vremennyh ryadov (Choosing the Situation Discription Size when Forming a Training Sample for Neural Networks in Tasks of Forecasting of Time Series).
9. Tarasenko R.A., Krisilov V.A., Predvaritelnaya otsenka kachestva obuchayushchey vyborki dlya neironnyh setei v zadachah prognozirovaniya vremennyh ryadov (Preliminaruy Estimation of the Quality of a training Sample for Neural Networks in Tasks of Forecasting of Time Series).
10. Philip D. Wasserman. Neral Computing: Theory and Practice.
11. Simon Haykin. Neural Networks: A Comprehensive Foundation.
12. www.wikipedia.org
13. The Internet.
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/1562
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
 最小の遅れでの効果的な平均化アルゴリズム:インディケータおよび Expert Advisor での使用
最小の遅れでの効果的な平均化アルゴリズム:インディケータおよび Expert Advisor での使用

 チャネルアドバンスドモデルWolfe Waves
チャネルアドバンスドモデルWolfe Waves
 MetaTrader 4 クライアントターミナルのプログラムフォルダ
MetaTrader 4 クライアントターミナルのプログラムフォルダ
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索