
Разбор HTML средствами MQL4

Введение
Язык HTML был создан для удобного оформления текстовых материалов. Все форматирование в таких документах осуществляется с помощью специальных служебных слов, называемых тегами. Практически вся информация в html-файлах оказывается окружена тегами. Если мы хотим извлекать данные в чистом виде, то нам необходимо отделить служебную информацию (теги) от основных данных. такую процедуру мы назовем разбором HTML-кода на структуру тегов.
Что такое тег?
С точки зрения проcтого описания, тег - это любое слово, окруженное двумя угловыми скобками. Например, вот это тег - <тег>. Хотя на самом деле в языке HTML тегами являются только определенные слова, набранные латиницей. Например, <html> - правильный тег, а тега <html2> не существует. Кроме того, многие теги могут иметь дополнительные атрибуты, которые уточняют форматирование, осуществляемой данным тегом. Например, <div align="center"> указывает на наличие тега <div>, в котором дополнительно задан атрибут выравнивания содержимого тега по центру.
Обычно теги идут парами, существуют открывающий и закрывающий тег. Отличаются они между собой только наличием слеша. Если <div> - это открывающий тег, то </div> - это закрывающий тег. Все то, что находится между открывающим и закрывающим тегами, называется содержимым тега (content). Вот это содержимое обычно и интересует при разборе HTML-кода. Пример:
<td>6</td>
Здесь тег <td> содержит "6".
Что значит разобрать текст?
В контексте данной статьи это будет означать, что мы хотим получить все встреченные в html-файле слова, окруженные двумя угловыми скобками: "<" и ">" - открывающей и закрывающей. Является ли каждое слова в этих скобках правильным тегом или нет - мы анализировать не будем. У нас стоит задача чисто техническая. Все последовательно найденные теги мы будем записывать в строковый массив в порядке поступления. Этот массив мы назовем структурой тегов.
Функция для считывания файла
Прежде чем анализировать текстовый файл, лучше всего его загрузить в строковый массив. Таким образом, мы сразу же откроем и закроем файл во избежание забыть оставить открытый файл по неосторожности. Кроме того, пользоваетльская функция, которая считывает текст из файла в массив, гораздо удобнее в многократном применении, чем каждый раз писать полную процедуру считывания данный с обязательной проверкой на возможные ошибки. Приведенная функция ReadFileToArray() имеет три параметра:
- string array[] - строковый массив, переданный по ссылке, позволяет изменять его размер и содержимое его элементов прямо в функции;
- string FileName - имя файла, строки из которого необходимо считать в массив array[];
- string WorkFolderName - имя подпапки в директории каталог_терминала\experts\files.
//+------------------------------------------------------------------+ //| запись содержимого файла в массив строк array[] | //| в случае неудачи вернем false | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Попытка прочитать файл ",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Не удалось прочитать файл ",FileName); } //---- return(res); }
Размер вспомогательного строкового массива составляет 64000 элементов, предполагается, что файлы с большим количеством строк встречаются не так часто. Но вы можете изменить этот параметр по своему усмотрению. Переменная stringCounter подсчитывает количество считанных из файла строк во вспомогательный массив temArray[], а затем считанные строки переписываются в массив array[], размер которого предварительно устанавливается равным stringCounter. В случае возникновения ошибки будет выведено сообщение в логи экспертов, которое можно будет увидеть на закладке "Experts".
Если массив array[] был заполнен успешно, функция ReadFileToArray() верент true, в противном случае возвращается false.
Вспомогательная функция FindInArray()
Прежде чем начать обрабатывать содержимое строкового массива в поисках тегов, необходимо общую задачу разбить на несколько более мелких подзадач. Существует несколько вариантов решения задачи выявления структуры тегов, сейчас мы рассмотрим один конкретный. Создадим функцию, которая будет нам сообщать в какой строке и на какой позиции этой строки находится искомое слово. Данной функции мы будем передавать строковый массив и строковую переменную, содержащее слово, которое мы ищем.
//+------------------------------------------------------------------+ //| возвращает координаты первого вхождения текста matchedText | //+------------------------------------------------------------------+ void FindInArray(string Array[], // массив строк, в котором ищем matchedText int inputLine, // номер строки, с которой начинать поиск int inputPos, // номер позиции, с которой начинать поиск int & returnLineNumber, // найденный номер строки в массиве int & returnPosIndex, // найденная позиция в строке string matchedText // искомое слово ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
Функция FindInArray() возвращает "координаты" найденного слова matchedText с помощью целочисленных переменных, переданных по ссылке. Переменная returnLineNumber содержит номер строки, а returnPosIndex содержит номер позиции в данной строке.
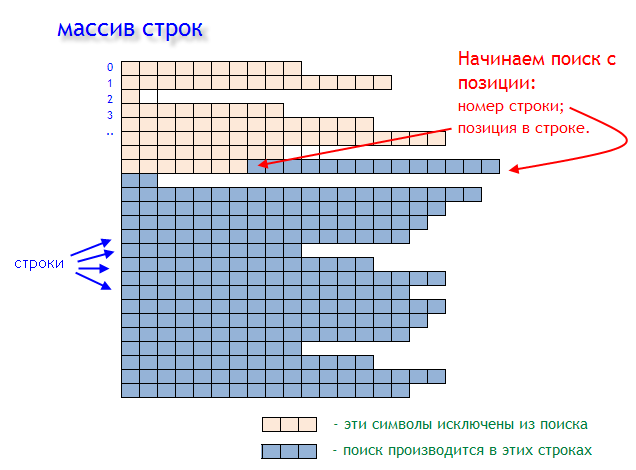
Рис. 1. Поиск начальной позиции текста в строковом массиве.
Поиск производится не во всем массиве, а начиная со строки с номером inputLine и позиции inputPos. Это начальные координаты поиска в массиве Array[]. Если искомое слово не будет найдено, то переменные ответа (returnLineNumber и returnPosIndex) будут содержать значение -1 (минус единица).
Получение строки из строкового массива по координатам начала и конца
Если мы имеем координаты начала и конца тега, то нам необходимо получить и записать в строку все символы, которые находятся между двумя угловыми скобками. Для этого служит функция getTagFromArray().
//+------------------------------------------------------------------+ //| возвращет строковое значение тега без классов | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Нулевой размер массива в функции getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // есть и пробел и закрывающая скобка { endLine=MathMin(lineClose,line_); // номер строки окончания определен if (lineClose==line_ && pos_<posClose) endPos=pos_;// если пробел и закрывающая скобка // в одной строке - позиция равна позиции пробела if (lineClose==line_ && pos_>posClose) endPos=posClose;// если пробел и закрывающая скобка // в одной строке - позиция равна позиции пробела if (lineClose>line_) endPos=pos_;// если строка пробела идет раньше строки закрывающей скобки //- позиция равна позиции пробела if (lineClose<line_) endPos=posClose;// если строка закрывающей скобки идет раньше // строки пробела - позиция равна позиции закрывающей скобки } if (lineClose>=0 && line_<0) // нет пробела { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // если начальную строку с указанной позиции { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // строка одна { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // копируем строку целиком { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // копируем начало конечной строки { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
В этой функции последовательно перебираются все строки, которые попали в координаты открывающей и закрывающей скобок, а также участвуют координаты пробела. Результатом работы функции будет выражение "<название_тега>", которое может быть собрано из нескольких строк.
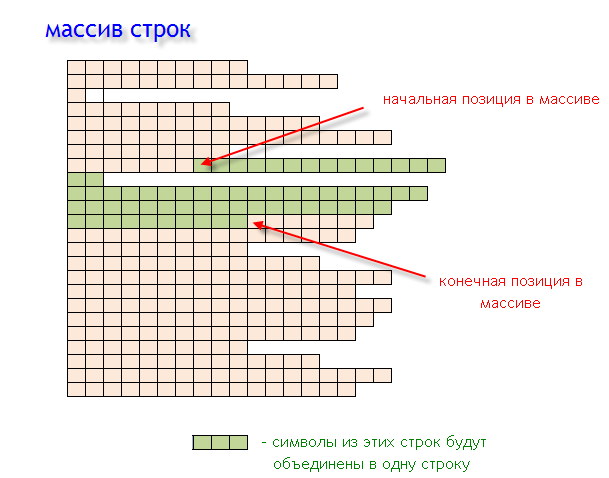
Рис. 2. Создание строковой переменной из массива строк с использованием начальной и конечной позиции.
Получение структуры тегов
Теперь у нас есть две вспомогательные функции, и мы можем приступить к поиску тегов. Для этого функцией FindInArray() мы будем последовательно искать "<", ">" и " " (пробел), а точнее, будем искать позиции этих символов в массиве строк, а затем из найденных позиций собирать с помощью функции getTagFromArray() названия найденных тегов и помещать их в массив, который содержит структуру тегов. Как видите, технология очень простая. Реализован этот алгоритм в функции FillTagStructure().
//+------------------------------------------------------------------+ //| заполняет структуру тегов | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// создаваемая структура тегов string array[], // исходный html-текст int line, // номер строки в array[] int pos) // номер позиции в строке line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Неправильные значения позиции поиска в функции FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Массив нулевого размера передан на обработку в функцию FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_," "); if (lineClose !=-1) // закрывающая скобка найдена { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Не найдена закрывающая скобка в функции FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
Обратите внимание, что в случае успешного нахождения тега, размер массива, представляющего структуру тегов увеличивается на единицу, новый тег добавляется, и после этого происходит рекурсивный вызов функцией самой себя.
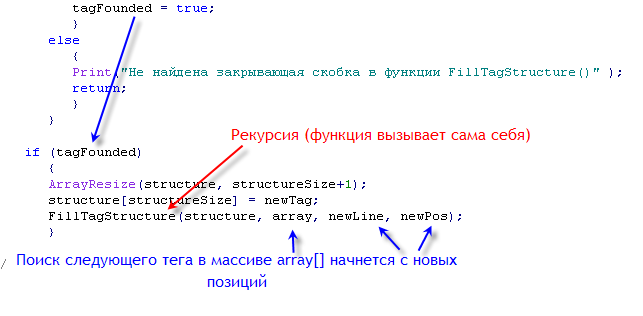
Рис. 3. Пример рекурсивной функции: Функция FillTagStructure() вызывает сама себя.
Этот способ написания функций для последовательных вычислений очень заманчив и часто упрощает жизнь программиста. На основании этих функций был написан скрипт TagsFromHTML.mq4, который ищет теги в отчете тестера StrategyTester.html и выводит все найденные теги в лог.
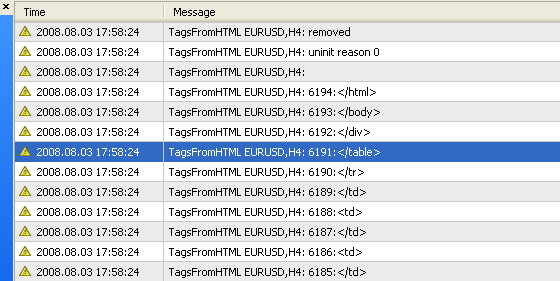
Рис. 4. Результат работы скрипта TagsFromHTML.mq4: выводтся порядковый номер номер тега и сам тег.
Как видите, отчет о тестировании может содержать несколько тысяч тегов. На рисунке видно, что последний найденный тег </html> имеет порядковый номер 6194. Разобрать вручную такое количество тегов нереально.
Получение содержимого, заключенного между тегами.
Поиск тегов является попутной задачей, основная задача - это получение информации, которая обернута в теги. Если посмотреть в любом простом текстовом редакторе, например в блокноте (Notepad), содержимое файла StartegyTester.html, то можно увидеть, что данные отчета находятся между тегами <table> и </table>. Тег table служит для форматирования табличных данных, и содержит в себе обычно множество строк, которые находятся между тегами <tr> и </tr>.
В свою очередь, каждая строка содержит в себя ячейки, которые выделяются тегами <td> и </td>. Наша цель - находить ценное содержимое между тегами <td> и собирать эти данные в строки, отформатированные под наши нужды. В первую очередь немного переделаем функцию FillTagStructure() таким образом, чтобы вместе со структурой тегов сохранялась информация о позициях начала и окончания тега.

Рис. 5. Одновременно с записью самого тега, происходит и запись его начальной и конечной позиций в массиве строк в соответствующие массивы.
Зная название тега и координаты начала и конца каждого тега, мы легко можем получать содержимое между двумя подряд идущими тегами. Для этого напишем еще одну функцию GetContent(), которая очень похожа на функцию getTagFromArray().
//+------------------------------------------------------------------+ //| получить содержимое строк в указанных границах | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
Теперь мы можем обрабатывать содержимое тегов любым удобным для нас способом. Пример такой обработки вы можете посмотреть в скрипте ReportHTMLtoCSV.mq4. Функция start() этого скрипта:
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // массив для хранения тегов int startPos[][2];// координаты начала тега int endPos[][2]; // координатры конца тега FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags содержит теги"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Начало таблицы"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// координаты начальной позиции для выборки содержимого между тегами start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// координаты конечной позиции для выборки содержимого между тегами end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// координаты конечной позиции для выборки содержимого между тегами end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("Конец таблицы"); } } //---- return(0); }
На рисунке показано, как выглядит лог-файл с сообщениями из этого скрипта, открытый в Microsoft Excel.
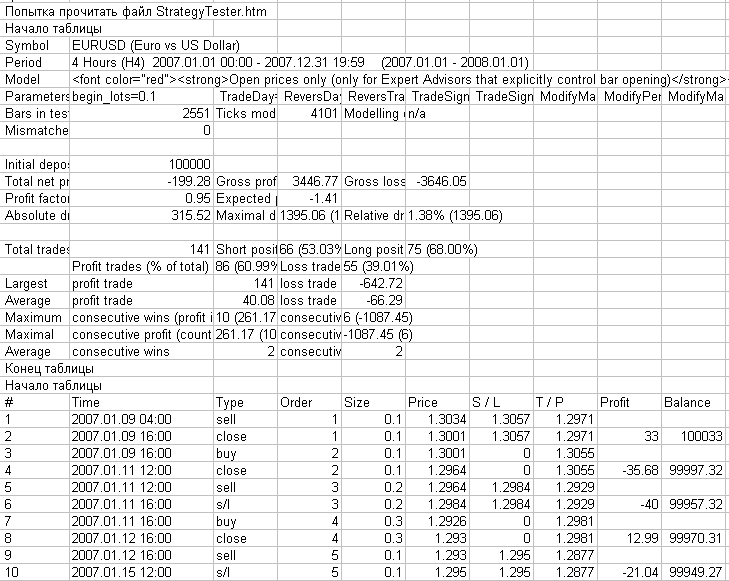
Рис. 6. Лог файл из папки MetaTrader 4\experts\logs с результатами работы скрипта ReportHTMLtoCSV.mq4, открытый в Micrisoft Excel.
Вы видите на рисунке знакомую структуру отчета о тестировании в MetaTrader 4.
Минусы данного скрипта
Существует несколько типов ошибок при программировании. Ошибки первого рода - синтаксические - легко обнаруживаются на стадии компиляции. Ошибки второго рода - это ошибки алгоритмические. Код программы успешно проходит компиляцию, но при запуске могут случаться непредвиденные в алгоритме ситуации, которые приводят к ошибочной работе программы, или даже к ее краху. Эти ошибки обнаруживать сложнее, но все таки можно.
И бывают ошибки третьего рода - концептуальные. Такие ошибки возникают в тех случаях, когда алгоритм программы написан правильно, но он не готов к использованию программы в немного иных условиях. Скрипт ReportHTMLtoCSV.mq4 хорошо подходит для обработки небольших html-документов, содержащих всего несколько тысяч тегов, но для обработки миллионов тегов он не подойдет. В нем есть два узких места. Первое - это многократное изменение размеров массивов.

Рис. 7. Множественные вызовы функции ArrayResize() на каждый новый найденный тег.
Вызов в процессе выполнения скрипта функции ArrayResize() десятки, сотни тысяч или даже миллионы раз приведет к огромным потерям времени. Каждое динамическое изменение размера массива требует времени на отведение в памяти компьютера новой области памяти нужного размера и копирование содержимого старого массива в этот новый массив. Если мы сразу выделим массив достаточно большого размера, то мы сможем существенно сократить расход времени на эти избыточные операции. Например, объявим массив tags таким образом:
string tags[1000000]; // массив для хранения тегов
Теперь мы можем записать в него до одного миллиона тегов без необходимости миллион раз вызывать функцию ArrayResize()!
Второй недостаток рассмотренного скрипта ReportHTMLtoCSV.mq4 - это использование рекурсивной функции. Каждый вызов функции FillTagStructure() сопровождается выделением некоторого пространства из оперативной памяти компьютера для того, чтобы в этой локальной копии функции размещать необходимые локальные переменные. Если документ содержит 10 000 тегов, то будет произведено 10 000 вызовов функции FillTagStructure(). Память под размещение вызовов рекурсивной функции выделяется из заранее зарезервированной области, размер которой задается директивой #property stacksize:
#property stacksize 1000000
В данном случае компилятору предписывается выделить под стек один миллион байт. Если памяти стека не хватит под вызовы функции, мы получим ошибку переполнения стека stack overflow. В случае, если потребуется вызвать рекурсивную функцию миллионы раз, может не помочь даже выделение сотен мегабайт под стек. Поэтому необходимо немного изменить алгоритм поиска тегов с тем, чтобы избежать использования рекурсивных вызовов.

Рис. 8. Каждый вызов рекурсивной функции требует своей собственной области памяти в стеке программы.
Мы пойдем другим путем - новая функция FillTagStructure()
Перепишем заново функцию для получения структуры тегов, теперь в ней в явном виде будет использоваться цикл для работы со строковым массивом array[]. Алгоритм новой функции понять не сложно, если вы разобрались с алгоритмом старой функции.
//+------------------------------------------------------------------+ //| заполняет структуру тегов | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// создаваемая структура тегов int & start[][], // начало тега (строка, позиция) int & end[][], // окончание тега (строка, позиция) string array[]) // исходный html-текст { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // если количество тегов превысило { // мощность хранилища ArrayResize(structure, curCapacity + capacity); // увеличим размер хранилища ArrayResize(start, curCapacity + capacity); // увеличим также размер массива начальных позиций ArrayResize(end, curCapacity + capacity); // увеличим и размер массива конечных позиций curCapacity += capacity; // запомним новую мощность } currString = array[i]; // взяли текущую строку //Print(currString); posOpen = StringFind(currString, "<", currPos); // ищем первое вхождение "<" с позиции currPos if (posOpen == -1) // не нашли { line = i; // перейдем на следующую строку currPos = 0; // вновой строке будем искать с самого начала i++; continue; // вернемся в началу цикла } // дошли до этого места, значит "<" найдена pos_ = StringFind(currString, " ", posOpen); // тогда поищем и пробел posClose = StringFind(currString, ">", posOpen); // поищем и закрывающую скобку if ((pos_ == -1) && (posClose != -1)) // пробела нет, но скобка найдена { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // собрали тег structure[tagCounter] = tag; // записали его в массив тегов setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // увеличили счетчик найденных тегов currPos = posClose; // следующий поиск нового тега начнем теперь continue; // с позиции posClose, где найдена закрывающая скобка } // дошли до этого места, значит найден и пробел и закрывающая скобка if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // пробел находится после скобки { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // собрали тег structure[tagCounter] = tag; // записали его в массив тегов setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // увеличили счетчик найденных тегов currPos = posClose; // следующий поиск нового тега начнем теперь continue; // с позиции posClose, где найдена закрывающая скобка } // нет, все же пробел находится раньше, чем закрывающая скобка if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // собрали тег structure[tagCounter] = tag; // записали его в массив тегов setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // увеличили счетчик найденных тегов currPos = posClose; // следующий поиск нового тега начнем теперь continue; // с позиции posClose, где найдена закрывающая скобка } } // дошли до этого места, значит не найден ни пробел ни закрывающая скобка if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // соберем тег из того что есть structure[tagCounter] = tag; // записали его в массив тегов while (posClose == -1) // и организуем цикл по поиску { // первой закрывающей сокбки i++; // увеличим счетчик строк currString = array[i]; // считаем новую строку posClose = StringFind(currString, ">"); // и поищем в ней закрывающую скобку } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // увеличили счетчик найденных тегов currPos = posClose; // видимо нашли, тогда установим начальную позицию } // для поиска нового тега } ArrayResize(structure, tagCounter); // урезали размер массивв тегов до количества найденных //---- // тегов return; }
Изменение размера массивов теперь происходит порциями по capacity элементов, значение capacity задано объявлением константы:
#define capacity 10000
Установка начальной и конечной позиции каждого тега теперь осуществляется с помощью функции setPositions().
//+------------------------------------------------------------------+ //| записать координаты тега в соотвествующие массивы | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
Попутно нам стали не нужны функции FindInArray() и getTagFromArray(). Полный код приведен в приложенном скрипте ReportHTMLtoCSV-2.mq4.
Заключение
Рассмотрен алгоритм по разбору HTML-документа на теги и показан пример извлечения информации из отчета тестера в терминале MetaTrader 4.
Старайтесь не пользоваться массовыми вызовами функции ArrayResize(), так как это может привести к неоправданным затратам времени.
Кроме того, использование рекурсивных функций может потребовать существенных ресурсов оперативной памяти. Если предполагается массовый вызов такой функции, постарайтесь переписать ее без использования рекурсии.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.

 Материалы Automated Trading Championship: Интервью с Участниками 2006 года
Материалы Automated Trading Championship: Интервью с Участниками 2006 года
 Материалы Automated Trading Championship: Статистические отчеты
Материалы Automated Trading Championship: Статистические отчеты
 Метод выявления ошибок в коде при помощи комментирования
Метод выявления ошибок в коде при помощи комментирования
 Материалы Automated Trading Championship: Регистрация
Материалы Automated Trading Championship: Регистрация
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Согласен. Но в данном месте многие не умеют ни того ни другого ни третьего (и т.д.). Предлагать им MQL как панацею от всего и для всего - сомнительно.
1. Логика очень проста: не забивать гвозди плоскогубцами.
2. Как Вы давно заметили на этот портал заходят два "вида" программистов: с багажом и без оного.
Для тех кого есть программистский багаж (С, С++, Delphi, VB и т.д.) всё написанное в данной статье - nonsense, для тех у кого такового нет, всё едино, для них Ваша статья как китайская грамота.
И объяснением алгоритма разборки HTML (к стати ещё один язык, который даже "мудрёнее" чем MQL) не обойтись.
3. Программистами не рождаются - ими становятся, и не через 30 минут прочтения описания или статьи...
1. Логика очень проста: не забивать гвозди плоскогубцами.
2. Как Вы давно заметили на этот портал заходят два "вида" программистов: с багажом и без оного.
Для тех кого есть программистский багаж (С, С++, Delphi, VB и т.д.) всё написанное в данной статье - nonsense, для тех у кого такового нет, всё едино, для них Ваша статья как китайская грамота.
И объяснением алгоритма разборки HTML (к стати ещё один язык, который даже "мудрёнее" чем MQL) не обойтись.
3. Программистами не рождаются - ими становятся, и не через 30 минут прочтения описания или статьи...
Не надо палки перегибать. У меня есть "багаж", но мне статья интересна. Скорее всего я не буду использовать алгоритм "как есть". Но при случае воспользуюсь написанным здесь.
Автору спасибо.
Осталось привести файл отчёта к well-formed xml и задача упростится на порядок для тех, кто знает XSLT :)
1. Логика очень проста: не забивать гвозди плоскогубцами.
2. Как Вы давно заметили на этот портал заходят два "вида" программистов: с багажом и без оного.
Для тех кого есть программистский багаж (С, С++, Delphi, VB и т.д.) всё написанное в данной статье - nonsense, для тех у кого такового нет, всё едино, для них Ваша статья как китайская грамота.
И объяснением алгоритма разборки HTML (к стати ещё один язык, который даже "мудрёнее" чем MQL) не обойтись.
3. Программистами не рождаются - ими становятся, и не через 30 минут прочтения описания или статьи...
Присоединяюсь, хотя сам выразился куда более резко - етсь куча других способов для парсинга строк. №1 ил них - регулярные выражения. Есть реализации в DLL, цепляешь в mql модуль и тратишь вагон оставшегося времени на изучение более полезных вещей чем страдание а****м с изобретением нового более никому не нужного велосипеда.
Rashid, спасибо за статью! Она сэкономила огромное количество времени мне. За 15 минут я решил задачу с помощью Вашей статьи, хотя предварительно предполагал, что на это может уйти не один час. И не слушайте снобов от программирования! Большинство приходящих на этот сайт как раз именно люди, которые что-то понимают в программировании, но не на таком уровне чтобы возиться с какими-то там dll, PHP и прочей высокоинтеллектуальной лабудой когда требуется просто получить столбец с результатами сделок в Excel из УЖЕ существующего файла отчёта.