
HTML Walkthrough Using MQL4

Introduction
HTML (Hypertext Mark-Up Language) was created for convenient formatting textual materials. All documents of this type are formatted with special function words named 'tags'. Practically all information in html files turns out to be enclosed with tags. If we want to extract pure data, we have to separate the service information (tags) from relevant data. We will named this procedure HTML walkthrough aimed at singling the tag structure out.
What Is Tag?
In terms of a simple description, tag is any word enclosed in angle brackets. For example, this is a tag: <tag>, although, in HTML, tags are certain words typed in Latin letters. For example, <html> is a correct tag, but there is no tag <html2>. Besides, many tags can have additional attributes that precise formatting performed by the given tag. For example, <div align="center"> means tag <div> in which the additional attribute of center alignment of the tag content is specified.
Tags are usually utilized in pairs: there are opening and closing tags. They differ from each other only with the presence of slash. Tag <div> is an opening tag, while tag </div> is a closing one. All data enclosed between the opening and the closing tags is named tag content. It is this content we are interested in at HTML code walkthrough. Example:
<td>6</td>
Tag <td> contains '6' here.
What Does "Text Walkthrough" Mean?
In the context of this article, it means that we want to get all words occurred in an html file and enclosed in two angle brackets: '<' and '>' - opening and closing. We won't analyze here whether each word in these brackets is a correct tag or not. Our task is purely technical. We will write all consecutive tags found in a string array on a first-come basis. We will named this array 'tag structure'.
File Reading Function
Before analyzing a text file, it is better to load it in a string array. Thus, we will immediately open and close the file in order not to forget to close the file by mistake. Besides, a user-defined function that reads the text from a file into an array is much more convenient for multiple application than writing each time the full procedure of data reading with an obligatory check for possible errors. Function ReadFileToArray() has three parameters:
- string array[] - a string array passed by a link, it allows to change its size and content directly in the function;
- string FileName - file name the lines from which must be read into array[];
- string WorkFolderName - subfolder name in directory Terminal_directory\experts\files.
//+------------------------------------------------------------------+ //| writing the content of the file into string array 'array[]' | //| in case of failing, return 'false' | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Trying to read file ",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Failed reading file ",FileName); } //---- return(res); }
The size of the auxiliary string array is 64000 elements. Files of a large number of lines are supposed not to occur very often. However, you can change this parameter as you wish. Variable stringCounter counts the number of lines read from the file into auxiliary array temArray[], then the read lines are written to array[] the size of which is preliminarily set as equal to stringCounter. In case of an error, the program will display a message in EAs' logs, which you can see in the "Experts" tab.
If array[] has been filled out successfully, function ReadFileToArray() returns 'true'. Otherwise, it returns 'false'.
Help Function FindInArray()
Before to start processing the content of the string array in our search for tags, we should divide the general task into several smaller subtasks. There are several solutions for the task of detecting the tag structure. Now we will consider a specific one. Let's create a function that would inform us in what line and in what position in this line the searched word is placed. We will pass to this function the string array and the string variable containing the word we are searching for.
//+-------------------------------------------------------------------------+ //| It returns the coordinates of the first entrance of text matchedText | //+-------------------------------------------------------------------------+ void FindInArray(string Array[], // string array to search matchedText for int inputLine, // line number to start search from int inputPos, // position number to start search from int & returnLineNumber, // found line number in the array int & returnPosIndex, // found position in the line string matchedText // searched word ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
Function FindInArray() returns the "coordinates" of matchedText using integer variables passed by the link. Variable returnLineNumber contains the line number, while returnPosIndex contains the position number in this line.
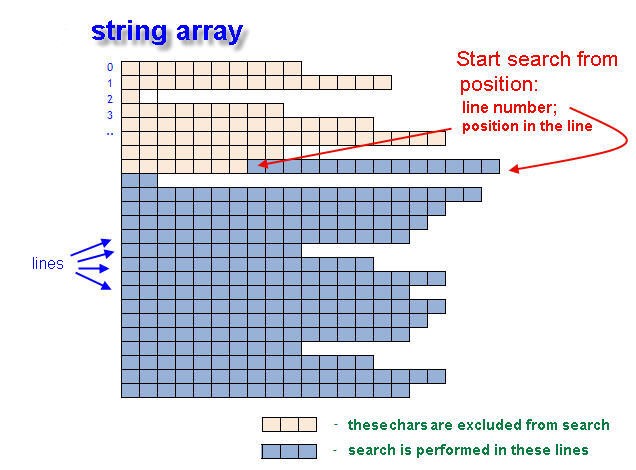
Fig. 1. Search for the initial position of the text in the string array.
The search is not performed in the entire array, but starts from line number inputLine and position number inputPos. These are initial search coordinates in Array[]. If the search word is not found, the return variables (returnLineNumber and returnPosIndex) will contain the value of -1 (minus one).
Getting a Line by Its Starting and Ending Coordinates from a String Array
If we have the starting and the ending coordinates of a tag, we need to get and write into string all characters located between the two angle brackets. We will use function getTagFromArray() for this.
//+------------------------------------------------------------------+ //| it returns a tag string value without classes | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Zero size of the array in function getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // both space and a closing angle bracket are available { endLine=MathMin(lineClose,line_); // the number of ending line is defined if (lineClose==line_ && pos_<posClose) endPos=pos_;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose==line_ && pos_>posClose) endPos=posClose;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose>line_) endPos=pos_;// if the line containing a space is before the line containing a closing bracket, // the position is equal to that of the space if (lineClose<line_) endPos=posClose;// if the line containing a closing bracket is before the line // containing a space, the position is equal to that of the closing bracket } if (lineClose>=0 && line_<0) // no space { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // if the initial line from the given position { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // one line { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // copy the whole line { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // copy the beginning of the end line { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
In this function, we consecutively search in all lines located within the coordinates of the opening and the closing angle brackets with the participation of the space coordinates. The function operation results in getting the expression of '<tag_name>, which can be assembled of several lines.
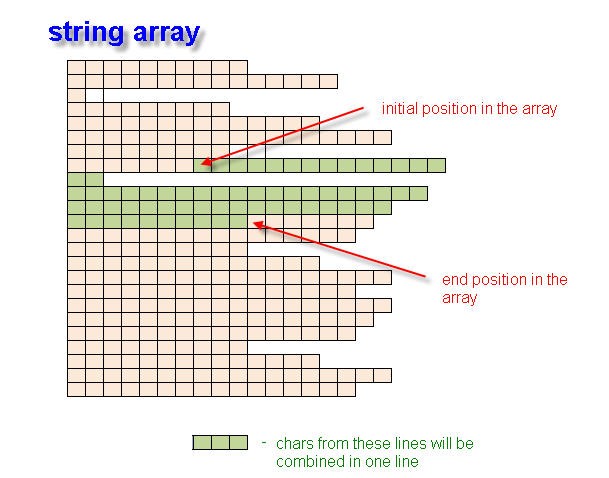
Fig. 2. Creation of a string variable of string array using the initial and the end positions.
Getting Tag Structure
Now we have two helper function, so we can start searching for tags. For this, we will consecutively search for '<', '>' and ' ' (space) with function FindInArray(). To be more exact, we will search for the positions of these characters in the string array and then assemble the names of the found tags using function getTagFromArray(), and place them in an array containing the tag structure. As you can see, the technology is very simple. This algorithm is realized in function FillTagStructure().
//+------------------------------------------------------------------+ //| fill out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure being created string array[], // initial html text int line, // line number in array[] int pos) // position number in the line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Invalid values of search position in function FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Zero-size array is passed for processing to function FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_," "); if (lineClose !=-1) // a closing angle bracket is found { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Closing angle bracket is not found in function FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
Please note that, in case of successful finding a tag, the size of the array representing the tag structure increases by one, a new tag is added, and then the function calls to itself recursively.

Fig. 3. An example recursive function: Function FillTagStructure() is calling to itself.
This method of writing functions for consecutive calculations is very attractive and often betters a programmer's lot. Basing on these function, script TagsFromHTML.mq4 was developed that searches for tags in the tester report, StrategyTester.html, and displays all found tags in the log.
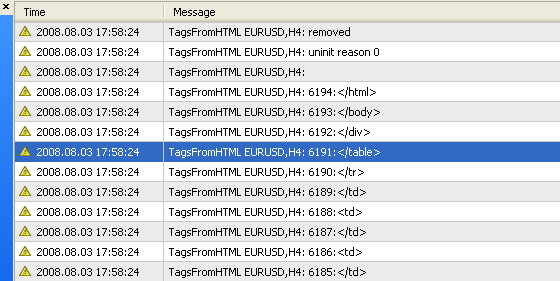
Fig. 4. Result of operations of script TagsFromHTML.mq4: The tag number and the tag itself are displayed.
As you can see, a test report may contain some thousands of tags. In Fig. 4, you can see that the last tag found, </html>, has the number of 6194. It is impossible to search in such amount of tags manually.
Getting Contents Enclosed in Tags
Searching for tags is an associated task, the main task is to get the information wrapped in tags. If we view the content of file StartegyTester.html using a text editor, for example, Notepad, we can see that the data of the report is located between tags <table> and </table>. Tag 'table' serves for formatting tabular data and usually includes many lines placed between tags <tr> and </tr>.
In its turn, each line contains cells that are enclosed in tags <td> and </td>. Our purpose is to find the valuable contents between <td> tags and collect this data in strings formatted for our needs. First of all, let's make some modifications in function FillTagStructure() so that we could store both the tag structure and the information about the tag start/end positions.

Fig. 5. Along with the tag itself, its start and end positions in the string array are written to the corresponding arrays.
Knowing the tag name and the coordinates of each tag's start and end, we can easily get the content located between two consecutive tags. For this purpose, let's write another function, GetContent(), that is very similar to function getTagFromArray().
//+------------------------------------------------------------------+ //| get the contents of lines within the given range | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
Now we can process the contents of tags in any way convenient to us. You can see an example of such processing in script ReportHTMLtoCSV.mq4. Below is function start() of the script:
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // array to store tags int startPos[][2];// tag-start coordinates int endPos[][2]; // tag-end coordinates FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags contains tags"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Beginning of table"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// coordinates of the initial position for selecting the content between tags start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("End of table"); } } //---- return(0); }
In Fig. 6, you can see how a log file appears containing the messages from this script and opened with Microsoft Excel.
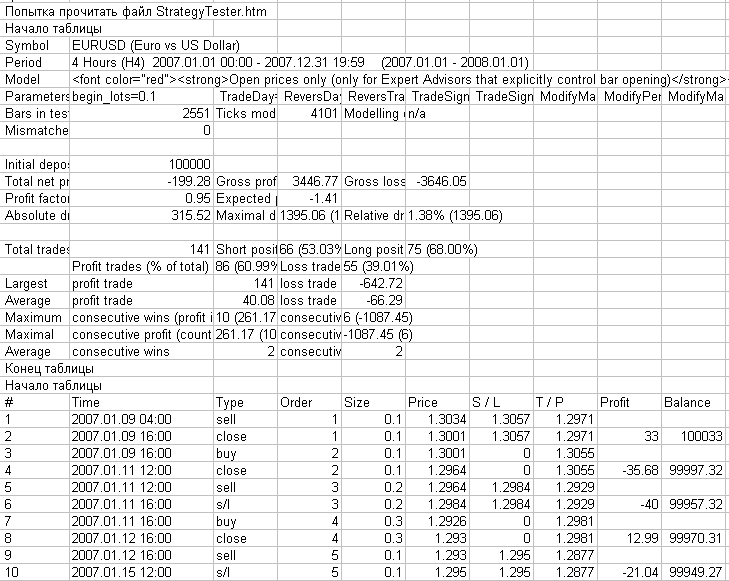
Fig. 6. Log file from folder MetaTrader 4\experts\logs containing the operation results of script ReportHTMLtoCSV.mq4, opened with Micrisoft Excel.
In Fig. 6 above, you can see the known structure of the MetaTrader 4 test report.
Defects of This Script
There are several types of programming errors. Errors of first kind (syntax errors) are easy to detect at the compilation stage. Errors of second kind are algorithmic. The program code is successfully compiled, but there can happen situations unforeseen in the algorithm, which results in error patterns in the program or even in its crash. These errors are not so easy to detect, but still possible.
Finally, there can be errors of third kind, the conceptual ones. Such errors occur if the program algorithm, though being written correctly, is not ready to use the program in a bit different conditions. Script ReportHTMLtoCSV.mq4 suits well for processing small html documents containing some thousands of tags, but it does not suit for processing millions of them. It has two bottlenecks. The first one is the multiple resizing of arrays.

Fig. 7. Multiple calls to function ArrayResize() for each newly found tag.
In the process of the script operation, calling function ArrayResize() tens, hundreds of thousands, or even millions of times will result in huge time wasting. Each dynamical resizing an array requires some time to allocate a new area of the necessary size in the PC memory and to copy the content of the old array into this new one. If we allocate an array of a rather large size in advance, we will be able to essentially reduce the time taken by these excessive operations. For example, let's declare array 'tags' as follows:
string tags[1000000]; // array to store tags
Now we can write in it up to million tags without the necessity to call to function ArrayResize() million times!
The other defect of the considered script ReportHTMLtoCSV.mq4 is the use of the recursive function. Each FillTagStructure() function call is accompanied with allocation of some area of RAM in order to place the necessary local variable in this local copy of the function. If the document contains 10 000 tags, function FillTagStructure() will be called to 10 000 times. The memory to locate the recursive function is allocated from a preliminarily reserved area the size of which is specified by directive #property stacksize:
#property stacksize 1000000
In this case, the compiler is assigned to allocate one million bytes for stack. If the stack memory is not sufficient for function calls, we will get the error of stack overflow. If we need to call to the recursive function millions of times, even allocation of hundreds of megabytes for stack may be in vain. So we have to slightly modify the tag search algorithm to avoid using recursive calls.
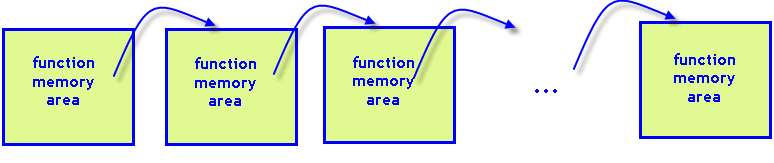
Fig. 8. Each recursive function call requires its own memory area in the program stack.
We Will Go Another Way - New Function FillTagStructure()
Let's rewrite the function of getting tag structure. It will now explicitly use a cycle to work with string array[]. The algorithm of the new function is clear, if you have understood that of the old function.
//+------------------------------------------------------------------+ //| it fills out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure to be created int & start[][], // tag start (line, position) int & end[][], // tag end (line, position) string array[]) // initial html text { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // if the number of tags exceeds { // the storage capacity ArrayResize(structure, curCapacity + capacity); // increase the storage in size ArrayResize(start, curCapacity + capacity); // also increase the size of the array of start positions ArrayResize(end, curCapacity + capacity); // also increase the size of the array of end positions curCapacity += capacity; // save the new capacity } currString = array[i]; // take the current string //Print(currString); posOpen = StringFind(currString, "<", currPos); // search for the first entrance of '<' after position currPos if (posOpen == -1) // not found { line = i; // go to the next line currPos = 0; // in the new line, search from the very beginning i++; continue; // return to the beginning of the cycle } // we are in this location, so a '<' has been found pos_ = StringFind(currString, " ", posOpen); // then search for a space, too posClose = StringFind(currString, ">", posOpen); // search for the closing angle bracket if ((pos_ == -1) && (posClose != -1)) // space is not found, but the bracket is { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it into tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // we are in this location, so both the space and the closing bracket have been found if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // space is after bracket { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // no, the space is still before the closing bracket if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } } // we are in this location, so neither a space nor a closing bracket have been found if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // assemble a tag of what we have structure[tagCounter] = tag; // written it to the tags array while (posClose == -1) // and organized a cycle to search for { // the first closing bracket i++; // increase in size the counter of lines currString = array[i]; // count the new line posClose = StringFind(currString, ">"); // and search for a closing bracket in it } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // it seems to have been found, then set the initial position } // to search for a new tag } ArrayResize(structure, tagCounter); // cut the tags array size down to the number of //---- // tags found return; }
The arrays are now resized in portions by capacity of elements. The value of capacity is specified by declaring the constant:
#define capacity 10000
The start and the end positions of each tag are now set using function setPositions().
//+------------------------------------------------------------------+ //| write the tag coordinates into the corresponding arrays | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
By the way, we don't need functions FindInArray() and getTagFromArray() anymore. The full code is given in script ReportHTMLtoCSV-2.mq4 attached here.
Conclusion
The algorithm of HTML-document walkthrough for tags is considered and an example of how to extract information from the Strategy Tester report in MetaTrader 4 Client Terminal is given.
Try not to use mass ArrayResize() function calls since this may result in excessive time consuming.
Besides, the use of recursive functions may consume essential RAM resources. If mass calls to such function are taken to be, try to rewrite it so that no recursion is necessary.
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/1544
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.

 Idleness is the Stimulus to Progress. Semiautomatic Marking a Template
Idleness is the Stimulus to Progress. Semiautomatic Marking a Template
 Expert Advisors Based on Popular Trading Strategies and Alchemy of Trading Robot Optimization (Part VI)
Expert Advisors Based on Popular Trading Strategies and Alchemy of Trading Robot Optimization (Part VI)
 View of Technical Analysis in the Context of Automatic Control Systems (ACS), or "Reverse View"
View of Technical Analysis in the Context of Automatic Control Systems (ACS), or "Reverse View"
 How to Write Fast Non-Redrawing ZigZags
How to Write Fast Non-Redrawing ZigZags
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Thanks for an important article
I have one question, can we read HTML file for URL i.e. 'HTML Walkthrough Using MQL4' this page from code?
Thanks for an important article
I have one question, can we read HTML file for URL i.e. 'HTML Walkthrough Using MQL4' this page from code?
Thanks for an important article
I have one question, can we read HTML file for URL i.e. 'HTML Walkthrough Using MQL4' this page from code?
See Http Client :)
... string res = httpGET("/en/articles/1544", status); Print("HTTP:",status[0]," ", res);