
使用 MQL4 的 HTML 引导

简介
HTML(超文本标记语言)创造用于便利的格式化文本资料。所有此类型的文件以名为“标记”的特殊函数语言进行格式化。实际上,所有 html 文件的信息都附上了标记。如果我们想提取纯数据,则需从相关数据中分离服务信息(标记)等。我们将此程序命名为 HTML 引导,旨在挑选出标记结构。
什么是标记?
简单来说,标记是任何包括在尖括号内的词语。例如,这是一个标记:<Tag>,尽管在 HTML 内,标记是按拉丁字母键入的特定词语。例如,<html> 是一个正确的标记,但 <html2> 则不是一个标记。此外,许多标记拥有额外的属性,这些属性由特定标记进行精确格式化。例如,<div align=“center” 意为 tag <div> 中标记内容中间对齐的额外属性已指定。
标记通常成对使用:分为开启标记和关闭标记。他们的区别仅在于是否有斜线。标记 <div> 为开启标记,而标记 </div> 则为关闭标记。所有在开启和关闭标记之间包含的数据都命名为标记内容。我们在 HTML 代码引导中感兴趣的,便是这些内容。示例:
<td>6</td>
此处,标记 <td> 包含了‘6’。
“文本引导”是什么意思?
在本文的上下文中,这表示我们想要获得 html 文件格式,且包括在两个尖括号之间的所有词语:‘<’ 和 ‘>’ - 开启和关闭。我们在这里不会分析括号内的每个词语的标记是否正确。我们的任务是纯技术的。我们将按照先后顺序编写所有在字符串数组内发现的连续标记。我们将此数组命名为‘标记结构’。
文件读取函数
分析文本文件之前,最好在字符串数组中加载文件。因此,我们将立即打开和关闭文件以避免错误地忘记关闭文件。此外,将文件文本读取到数组中的用户定义函数,比起每次编写数据读取的全部程序时都要对可能出现的错误进行必要检查,该函数可以更便于进行多项申请。函数 ReadFileToArray() 有三种参数:
- 字符串数组 [] - 一个由链接传递的字符串数组,允许在函数中直接改变其大小和内容;
- 字符串 FileName - 必须读取进数组 [] 的文件名;
- 字符串 WorkFolderName - 目录 Terminal_directory\experts\files中的子文件夹名。
//+------------------------------------------------------------------+ //| writing the content of the file into string array 'array[]' | //| in case of failing, return 'false' | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Trying to read file ",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Failed reading file ",FileName); } //---- return(res); }
辅助字符串数组的大小为 64000 个元素。不应经常出现大量行的文件。但是,你可以随意更改该参数。变量 stringCounter 计算从文件读取到辅助数组 temArray[] 中的行数,然后读取的行数将写入到 array[],该数组的大小预先设置为和 stringCounter 相等。如果出现错误,则程序将在 EA 日志内显示消息,你可以在 “Experts” 选项卡内看到该消息。
如果 array[] 成功填充,则函数 ReadFileToArray() 返回 ‘true’。否则,将返回 ‘false’。
辅助函数 FindInArray()。
开始在标记搜索中处理字符串数组内容前,我们应将整体任务分解至多个较小的子任务。有多个可检测标记结构任务的解决方案。现在我们将讨论一个具体的解决方案。让我们来创建一个函数,来告诉我们搜索词应放置在哪一行以及改行中的哪一个位置。我们将字符串数组和包含我们搜索的词语的字符串变量传递进该函数。
//+-------------------------------------------------------------------------+ //| It returns the coordinates of the first entrance of text matchedText | //+-------------------------------------------------------------------------+ void FindInArray(string Array[], // string array to search matchedText for int inputLine, // line number to start search from int inputPos, // position number to start search from int & returnLineNumber, // found line number in the array int & returnPosIndex, // found position in the line string matchedText // searched word ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
函数 FindInArray() 通过由链接传递的整数变量返回 matchedText 的 “coordinates”。变量 returnLineNumber 包含行数,returnPosIndex 则包含该行内的位置编号。
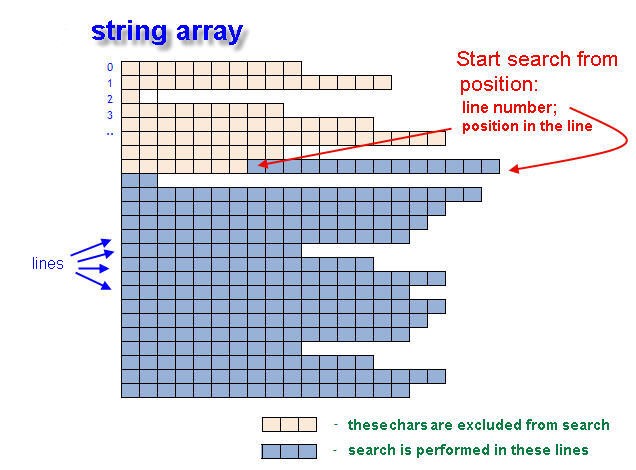
图 1。在字符串数组内搜索文本的初始位置。
搜索未在整个数组中执行,但始于行数 inputLine 和位置编号 inputPos。这是 Array[] 内的初始搜索坐标。如果未找到搜索词,则返回变量(returnLineNumber 和 returnPosIndex) 将包含 -1 值(负一)。
从字符串数组中获得开始和结束坐标的行。
如果我们拥有了标记内的开始和结束坐标,我们需要将所有位于两个尖括号之间的字符写进字符串内。我们将通过函数 getTagFromArray() 进行该操作。
//+------------------------------------------------------------------+ //| it returns a tag string value without classes | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Zero size of the array in function getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // both space and a closing angle bracket are available { endLine=MathMin(lineClose,line_); // the number of ending line is defined if (lineClose==line_ && pos_<posClose) endPos=pos_;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose==line_ && pos_>posClose) endPos=posClose;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose>line_) endPos=pos_;// if the line containing a space is before the line containing a closing bracket, // the position is equal to that of the space if (lineClose<line_) endPos=posClose;// if the line containing a closing bracket is before the line // containing a space, the position is equal to that of the closing bracket } if (lineClose>=0 && line_<0) // no space { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // if the initial line from the given position { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // one line { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // copy the whole line { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // copy the beginning of the end line { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
在该函数中,在空间坐标的参与下,我们连续在开始和结束尖括号坐标内的所有行进行搜索。函数运算得出了可由多行组成的 ‘<tag_name> 的表达式。
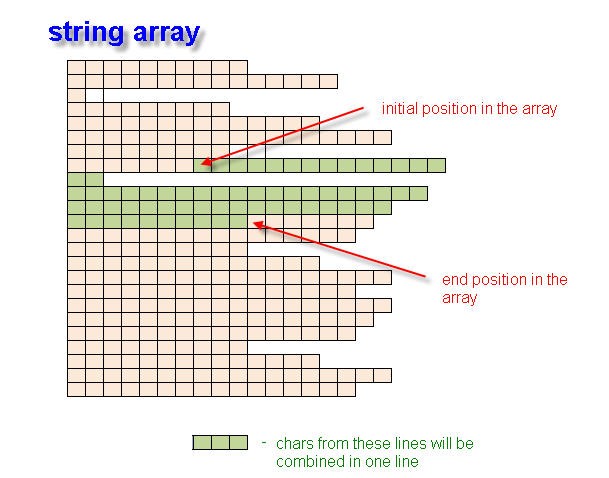
图 2。通过初始和结束位置创建字符串数组的字符串变量。
获得标记结构
现在我们拥有两个辅助函数,因此我们可以开始搜索标记了。为此,我们将使用函数 FindInArray() 来连续搜索 ‘<’, ‘>’ 和 ‘ ‘ (space)。更确切的说,我们将在字符串数组内搜索这些字符的位置,然后使用函数 getTagFromArray() 收集找到的标记名称,并将这些名称放置到包含标记结构的数组内。如你所见,技术就是如此简单。这种算法可在函数 FillTagStructure() 中实现。
//+------------------------------------------------------------------+ //| fill out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure being created string array[], // initial html text int line, // line number in array[] int pos) // position number in the line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Invalid values of search position in function FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Zero-size array is passed for processing to function FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_," "); if (lineClose !=-1) // a closing angle bracket is found { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Closing angle bracket is not found in function FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
请注意,如果成功找到标记,表示标记结构的数组大小增加 1,添加新的标记,然后函数以递归方式调用自身。

图 3。递归函数的示例:函数 FillTagStructure() 正在调用自身。
这种编写函数进行连续计算的方法非常具有吸引力,且可经常改善程序员的手数。基于这些函数,脚本 TagsFromHTML.mq4 被开发用于在测试程序报告 StrategyTester.html 中进行标记搜索,并显示日志中发现的所有标记。
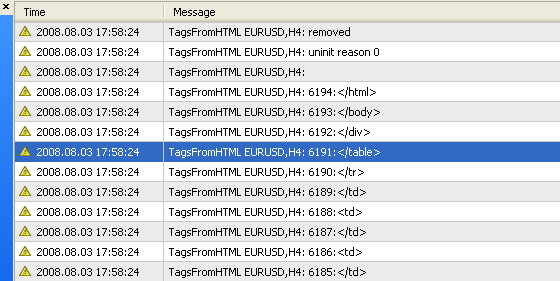
图 4。脚本 TagsFromHTML.mq4 的运算结果:显示标记编号和标记本身。
如你所见,测试报告可包含数千个标记。在图 4 中,你可以看见最后发现的标记 </html>,其数字为 6194。手动在如此数量的标记中进行搜索是不可能的。
获得标记中的内容
搜索标记是一项关联任务,主要任务是获得标记内的信息。如果我们通过文本编辑器(例如 Notepad)查看文件 StartegyTester.html 的内容,我们可以看到报告的数据位于标记 <table> 和 </table> 之间。标记 ‘table’ 用于格式化表格数据,且通常包括放置在标记 <tr> 和 </tr> 之间的许多行。
每一行又包含了标记 <td> 和 </td> 之间的单元。我们的目的是在 <td> 标记之间找到有价值的内容,并在格式化的字符串内按需要收集这些数据。首先,我们要在函数 FillTagStructure() 内进行修改,以便可以储存标记结构以及标记开始/结束位置的信息。

图 5。除了标记本身,标记在字符串数组内的开始和结束位置均写进对应的数组内。
知道标记名和每个标记开始和结束的坐标的话,我们可以很轻松地获取两个连续标记之间的内容。为此,我们来编写另一个函数 GetContent(),该函数和函数 getTagFromArray() 非常相似。
//+------------------------------------------------------------------+ //| get the contents of lines within the given range | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
现在我们可以按任何方便的方式处理标记内容了。你可以在脚本 ReportHTMLtoCSV.mq4.内看到这些流程的示例。以下是脚本的函数 start():
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // array to store tags int startPos[][2];// tag-start coordinates int endPos[][2]; // tag-end coordinates FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags contains tags"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Beginning of table"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// coordinates of the initial position for selecting the content between tags start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("End of table"); } } //---- return(0); }
在图 6 中,你可以看到包含脚本信息并以 Microsoft Excel 格式打开的日志文件的样子。
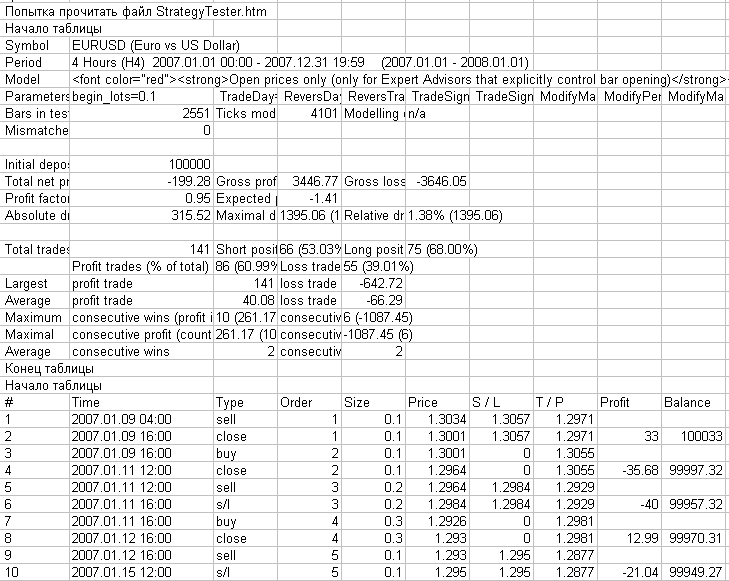
图 6。文件夹 MetaTrader 4\experts\logs 内的日志文件包含脚本 ReportHTMLtoCSV.mq4 的运算结果,以 Microsoft Excel 格式打开。
在上面的图 6 中,你可以看到 MetaTrader 4 测试报告的已知结构。
该脚本的缺陷
脚本存在多种类型的编程错误。第一种错误(语法错误)可在试运行阶段轻易检测到。第二种错误是算法性的。程序代码成功编译,但在算法中却会发生不可预测的情况,该情况会导致程序中出现错误模式,甚至令程序崩溃。虽然这些错误很难被检测到,但仍存在可能性。
最后,还有第三种错误——概念性错误。即便程序算法已正确写入,但未做好在稍有不同的环境下使用的准备时,这种错误便会发生。脚本 ReportHTMLtoCSV.mq4 很适合处理包含数千个标记的小型 html. 文件,但它并不适合处理数以百万计的标记。脚本存在两个瓶颈。第一个是数组多次调整大小。

图 7。为每一个新发现的标记多次调用函数 ArrayResize()。
在脚本运算过程中,调用函数 ArrayResize() 数十次,数十万次或数百万次将导致时间大量浪费。每次对数组进行动态调整都需要时间来分配计算机内存的必要空间,并将旧数组的内容拷贝到新数组内。如果我们提前分配较大的数组,我们将可以大幅缩短这些过度运算的所需时间。例如,让我们按以下方式声明数组 ‘tags’:
string tags[1000000]; // array to store tags
现在我们可以不用调用函数 ArrayResize() 百万次就可以写入百万个标记了!
该脚本 ReportHTMLtoCSV.mq4 的另一个缺陷是对递归函数的使用。每次调用 FillTagStructure() 函数都需要在 RAM 中分配部分空间以将必要的本地变量放入函数的本地拷贝内。如果文件包含 10 000 个标记,则函数 FillTagStructure() 将被调用 10 000 次。定位递归函数的内存由预留的空间中进行分配,该空间大小由指令 #property stacksize 所指定:
#property stacksize 1000000
在此情况下,指定编译器为堆栈分配一百万字节。如果堆栈内存不足以调用函数,将出现 stack overflow(堆栈溢出)的错误。如果我们需要调用递归函数几百万次,那就算是为堆栈分配了数百兆字节也是徒劳无用。所以,我们必须稍微修改标记搜索算法,以避免使用递归函数。
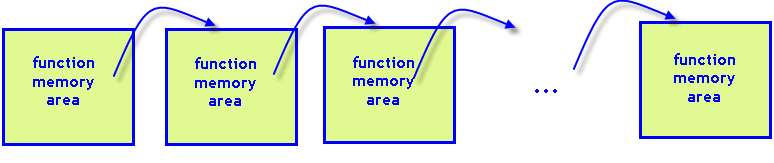
图 8。每次调用递归函数都需要程序堆栈中的自身内存空间。
我们将尝试另一种方法 - 新的函数 FillTagStructure()
让我们重新编写函数来获得标记结构。现在应明确使用循环来处理字符串数组 []。如果你了解旧函数算法的话,那新函数的算法便很简单明了。
//+------------------------------------------------------------------+ //| it fills out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure to be created int & start[][], // tag start (line, position) int & end[][], // tag end (line, position) string array[]) // initial html text { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // if the number of tags exceeds { // the storage capacity ArrayResize(structure, curCapacity + capacity); // increase the storage in size ArrayResize(start, curCapacity + capacity); // also increase the size of the array of start positions ArrayResize(end, curCapacity + capacity); // also increase the size of the array of end positions curCapacity += capacity; // save the new capacity } currString = array[i]; // take the current string //Print(currString); posOpen = StringFind(currString, "<", currPos); // search for the first entrance of '<' after position currPos if (posOpen == -1) // not found { line = i; // go to the next line currPos = 0; // in the new line, search from the very beginning i++; continue; // return to the beginning of the cycle } // we are in this location, so a '<' has been found pos_ = StringFind(currString, " ", posOpen); // then search for a space, too posClose = StringFind(currString, ">", posOpen); // search for the closing angle bracket if ((pos_ == -1) && (posClose != -1)) // space is not found, but the bracket is { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it into tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // we are in this location, so both the space and the closing bracket have been found if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // space is after bracket { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // no, the space is still before the closing bracket if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } } // we are in this location, so neither a space nor a closing bracket have been found if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // assemble a tag of what we have structure[tagCounter] = tag; // written it to the tags array while (posClose == -1) // and organized a cycle to search for { // the first closing bracket i++; // increase in size the counter of lines currString = array[i]; // count the new line posClose = StringFind(currString, ">"); // and search for a closing bracket in it } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // it seems to have been found, then set the initial position } // to search for a new tag } ArrayResize(structure, tagCounter); // cut the tags array size down to the number of //---- // tags found return; }
现在部分数组已通过元素 容量 进行了大小调整。容量的值通过声明常量来指定:
#define capacity 10000
每个标记开始和结束位置现已通过函数 setPositions()进行设定。
//+------------------------------------------------------------------+ //| write the tag coordinates into the corresponding arrays | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
顺便说一句,我们不再需要函数 FindInArray() 和 getTagFromArray() 了。全部代码都已提供在脚本 ReportHTMLtoCSV-2.mq4 内,附于此处。该视频告诉你如何使用脚本。
总结
针对标记的 HTML-文件引导算法被认为是如何从已知的 MetaTrader 4 客户终端内的策略测试程序报告提取信息的示例。
请尽量避免大批量调用 ArrayResize() 函数,因为这可能导致耗费过多时间。
此外,使用递归函数可能会消耗大量的 RAM 资源。如果已经大批量地调用了该函数,请尝试重新编写函数以避免递归的使用。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/1544
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。

 分组文件的操作
分组文件的操作
 使用 MetaTrader 4 进行基于时间的模式分析
使用 MetaTrader 4 进行基于时间的模式分析

