
MQL4 によるHTML チュートリアル

はじめに
HTML (Hypertext Mark-Up Language)はテキスト資料を便利にフォーマットするために作成されました。このタイプの書類はすべて「タグ」と呼ばれる特殊機能後でフォーマットされます。実質的に html ファイルの情報はすべてタグで囲まれていることが判ります。純粋なデータを抽出したい場合、相当するデータからサービス情報(タグ)を分離する必要があります。タグ構造を拾い出すこの手順を HTML チュートリアルと呼びます。
タグとは何でしょうか?
簡単に説明すると、タグは山括弧に囲まれた任意の語です。たとえば、これはタグです:<tag>。HTMLではタグはラテン文字でタイプされた特定の語ですが。たとえば<html> は正しいタグですが、タグはありません<html2>。また、多くのタグには、所定のタグによる正確なフォーマットの追加属性があります。たとえば、<div align="center"> が意味するのは、タグ内容の中央寄せの追加属性が指定されるタグ <div> です。
タグは通常ペアで使用されます。開始グと終了タグです。それらはスラッシュのあるなしだけで異なります。タグ <div> は開始タグです。同時にタグ </div> は終了タグです。開始タグと終了タグの間に入っているデータはすべてタグコンテンツと呼ばれます。HTML のコードチュートリアルで関心を持つのはこのコンテンツです。例
<td>6</td>
タグ <td> にはここではコンテンツ '6' が入っています。
"Text Walkthrough" が意味することは?
本稿のコンテキストでは、それは、html ファイル内に入っていて、2つの山括弧に囲まれる語すべてが必要であることを意味します。:'<' および '>' -開始と終了。これら括弧内の各語が正しいか正しくないかは分析しません。われわれのタスクは純粋に技術的なものなのです。先着順に文字列配列に見られる連続タグをすべて書きます。この配列を「タグ構造」と呼びます。
ファイル読み出し関数
テキストファイルを分析する前に、それを文字列配列にロードする方がよいです。そうするとすぐにファイルを開いたり閉じたりし、ファイルを誤って閉じ忘れることになりません。また、ファイルから配列にテキストを読むユーザー定義関数は、データ読み出しのプロシージャをすべて毎回書き、潜在的エラーを必ずチェックするよりは、複数アプリケーションに対してずっと便利です。関数 ReadFileToArray() にはパラメータが3つあります。
- string array[] -リンクによって渡される文字列配列。それによりサイズとコンテンツを関数内で直接変更することができます。
- string FileName -ファイル名。そこからの行が array[] に読み出されます。
- string WorkFolderName -ディレクトリ Terminal_directory\experts\files のサブフォルダ名。
//+------------------------------------------------------------------+ //| writing the content of the file into string array 'array[]' | //| in case of failing, return 'false' | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Trying to read file ",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Failed reading file ",FileName); } //---- return(res); }
補助的な文字列配列のサイズは 64000 エレメントです。多数の行を持つファイルはあまり頻繁ではないと考えられます。が、このパラメータは好きなように変更できます。変数 stringCounter はファイルから補助配列 temArray[] に読み込むファイル数を数えます。読まれた行は array[] に書き込まれ、そのサイズは stringCounter と等しくなるよう事前に設定されます。エラーが発生した場合は、プログラムが EA のログにメッセージを表示します。それは "Experts" タブで確認できます。
array[] が正常に書き込まれたら、関数 ReadFileToArray() が「真」を返します。それ以外では、「偽」を返します。
ヘルプ関数 FindInArray()
タグ検索で文字列配列のコンテンツを処理し始める前に、一般的なタスクを複数の小さなサブタスクに分けます。タグ構造を検索するタスクには複数のソリューションがあります。ここでは特定のソリューションを考察します。どの行で、そしてその行のどの位置に検索される語があるか伝えてくれる関数を作成します。この関数に文字列配列と、検索している語を持つ文字列変数を渡すことにします。
//+-------------------------------------------------------------------------+ //| It returns the coordinates of the first entrance of text matchedText | //+-------------------------------------------------------------------------+ void FindInArray(string Array[], // string array to search matchedText for int inputLine, // line number to start search from int inputPos, // position number to start search from int & returnLineNumber, // found line number in the array int & returnPosIndex, // found position in the line string matchedText // searched word ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
関数 FindInArray() は、リンクから渡される整数変数によって一致するテキストの『座標』を返します。変数 returnLineNumber は行番号を持ち、同時にreturnPosIndex はこの行の位置番号を持ちます。
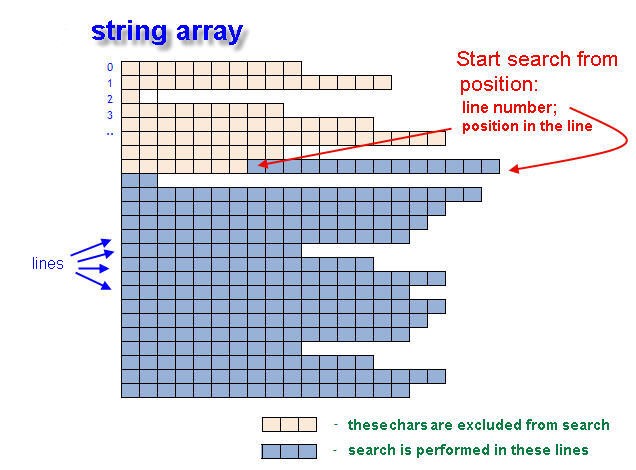
図12 文字列配列でテキストの初期位置を検索します。
検索は配列全体で行われませんが、行番号 inputLine と位置番号 inputPos から開始されます。これらは Array[] 内の初期検索条件です。検索する語が見つからなければ、戻り変数(returnLineNumber および returnPosIndex)には値 -1 (マイナス1)が入っています。
文字列配列の開始および終了座標で行を取得する
タグの開始および終了座標がわかっていれば、2つの山括弧の間にある文字すべてを取得して文字列に書き込みます。これには関数 getTagFromArray() を使います。
//+------------------------------------------------------------------+ //| it returns a tag string value without classes | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Zero size of the array in function getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // both space and a closing angle bracket are available { endLine=MathMin(lineClose,line_); // the number of ending line is defined if (lineClose==line_ && pos_<posClose) endPos=pos_;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose==line_ && pos_>posClose) endPos=posClose;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose>line_) endPos=pos_;// if the line containing a space is before the line containing a closing bracket, // the position is equal to that of the space if (lineClose<line_) endPos=posClose;// if the line containing a closing bracket is before the line // containing a space, the position is equal to that of the closing bracket } if (lineClose>=0 && line_<0) // no space { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // if the initial line from the given position { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // one line { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // copy the whole line { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // copy the beginning of the end line { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
この関数では、空間座標も含め、開始および終了山括弧の座標内にある行をすべて連続して検索します。関数処理は <tag_name> の式を得る結果となります。これは複数行で組立っている可能性があります。
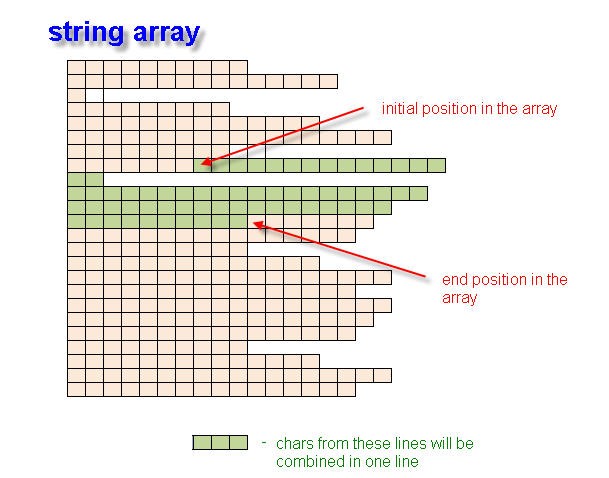
図2 開始および終了位置による文字列配列の文字列変数作成
タグ構造の取得
次に、ヘルパー関数を2つ取得し、タグ検索を開始できるようにします。これには、関数 FindInArray() で連続して '<'、 '>' と ' ' (スペース)を検索します。より正確に言えば、文字列配列内でこれら文字の位置を検索し、関数getTagFromArray() によって見つかったタグ名を組み合わせ、それらをタグ構造を持つ配列に入れるのです。ごらんのように、技術はごくシンプルです。このアルゴリズムは関数 FillTagStructure() に実装されます。
//+------------------------------------------------------------------+ //| fill out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure being created string array[], // initial html text int line, // line number in array[] int pos) // position number in the line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Invalid values of search position in function FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Zero-size array is passed for processing to function FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_," "); if (lineClose !=-1) // a closing angle bracket is found { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Closing angle bracket is not found in function FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
タグがうまく見つかる場合、タグ構造を表す配列サイズは1ずつ増え、新しいタグが追加され、それから関数が再帰的にそれ自体を呼び出すことにご注意ください。

図3 再帰的関数例:関数 FillTagStructure() は自分自身を呼び出します。
連続計算のために関数を書くこの方法はひじょうに魅力的で、プログラマーの運命をより良く導くことが多いものです。こういった関数を基に、テスターレポートStrategyTester.html でタグを検索し、見つかったタグをすべてログに表示するスクリプト TagsFromHTML.mq4 が作成されました。
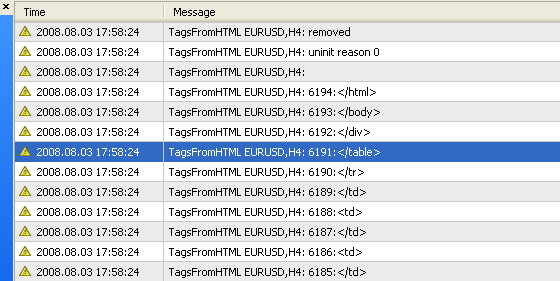
図4 スクリプトTagsFromHTML.mq4 の動作結果:タグナンバーとタグ自体が表示されます。
ごらんのように、テストレポートには何千ものタグがあります。図4で、見つかった最終タグ </html> は 6194 番であることがわかります。そのような量のタグをマニュアルで検索するのは不可能です。
タグに囲まれたコンテンツを取得する
タグ検索は関連タスクで、主要なタスクはタグ内にラップされる情報を取得することです。テキストエディタ、たとえば Notepad を使ってファイル StartegyTester.html の中身を見れば、レポートのデータがタグ <table> と </table>の間にあるのがわかります。タグ 'table' は表データをフォーマットし、通常タグ <tr> と </tr> の間に多くの行が入ります。
そして今度は各行にタグ <td> と </td> に囲まれたセルがあります。われわれの目的は、<td> タグ間の変数コンテンツを見つけ、このデータを必要に応じてフォーマットされる文字列に集めることです。まず、関数 FillTagStructure() に少し変更を加え、タグ構造とタグの開始/終了位置に関する情報の両方を格納できるようにします。

図5 タグそれ自体と併せて、文字列配列内での開始および終了位置は対応する配列に書き込まれます
タグ名と各タグの開始および終了座標がわかっているので、2つの連続タグにあるコンテンツを簡単に取得することができます。このために、もう一つ別の関数 GetContent() を書きます。それは関数 getTagFromArray() にひじょうに似ています。
//+------------------------------------------------------------------+ //| get the contents of lines within the given range | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
次に、都合のよい方法でタグのコンテンツを処理します。スクリプト ReportHTMLtoCSV.mq4でそのような処理例を確認できます。以下はスクリプトの関数 start() です。
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // array to store tags int startPos[][2];// tag-start coordinates int endPos[][2]; // tag-end coordinates FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags contains tags"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Beginning of table"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// coordinates of the initial position for selecting the content between tags start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("End of table"); } } //---- return(0); }
図6でこのスクリプトからのメッセージを持ってマイクロソフトエクセルによって開かれるログファイルがどのように表示されるか確認できます。
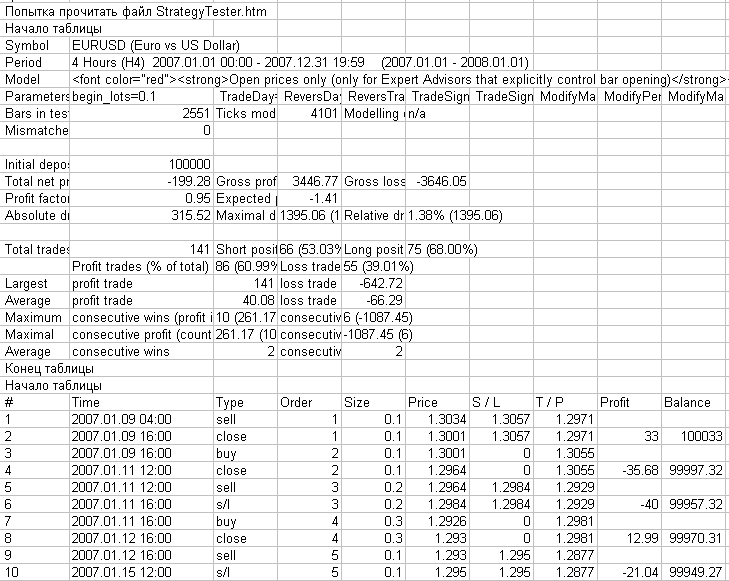
図6 スクリプト ReportHTMLtoCSV.mq4 の動作結果を持つフォルダ MetaTrader 4\experts\logs からマイクロソフトエクセルによって開かれたログファイル
上の図6では、MetaTrader 4 テストレポートの既知のストラクチャが確認できます。
このスクリプトの不具合
いくつかのタイプのプログラミングエラーがあります。第1タイプのエラー(構文エラー)はコンパイル段階で簡単に検出されます。第2タイプのエラーはアルゴリズムのエラーです。プログラムコードは正常にコンパイルされますが、アルゴリズムに予期せぬ状況が発生し、それがプログラムのエラーパターンやクラッシュにさえつながります。こういったエラーを検出するのは容易ではありませんが、それでも可能です。
最後に、第3タイプのエラー、概念的エラーがあります。そのようなエラーが発生するほは、プログラムのアルゴリズムが正しく書かれているにもかかわらずわずかに異なる条件ではプログラムを使用する準備ができていない場合です。スクリプト ReportHTMLtoCSV.mq4 は数千個のタグを持つ小さな html ドキュメントを処理するのによく適していますが、何百万のものを処理するには適していません。そこにはボトルネックが2つあります。最初の障害は配列の複数回のサイズ変更です。

図7 新たに見つかったタグそれぞれに対する関数 ArrayResize() の複数回呼び出し
スクリプト処理の過程では、関数 ArrayResize() を何十回、何百回、何千回、何百万回と呼び出すことはたいへんな時間の無駄につながります。動的に配列のサイズ変更をするたびに、PC メモリの新しい必要なサイズ領域を割り当て、古い配列の内容を新しい配列にコピーするのにいくばくかの時間が必要です。事前にかなり大きなサイズの配列を割り当てると、そういった余分な処理にかかる時間を基本的に削減することができます。たとえば、次のように配列 'tags' を宣言します。
string tags[1000000]; // array to store tags
これで、関数 ArrayResize() を百万回呼ぶことなく百万個までのタグをそこに書くことができるのです。
考察しているスクリプトReportHTMLtoCSV.mq4 のその他の不具合は再帰的関数の使用です。FillTagStructure() 関数呼び出しのたびに、関数のローカルコピーで必要なローカル変数を入れるため、RAM 領域の割り当てが行われます。ドキュメントに 10,000 個のタグがある場合、関数FillTagStructure() は 10,000 回呼ばれることとなります。再帰的関数を入れるメモリは事前に予約された領域から割り当てられ、そのサイズは命令 #property stacksize で指定されます。
#property stacksize 1000000
この場合、コンパイラはスタックに対して百万バイトを割り当てるように指定されています。スタックメモリが関数呼び出しに対して十分でなければ、エラースタックオーバーフローを取得することとなります。再帰的関数を百万回呼ぶ必要がある場合は、スタックに対する何百メガバイトの割り付けも無駄になる可能性があります。そこで、回帰的呼び出しをしなくてすむようにタグ検索アルゴリズムをやや変更する必要があります。
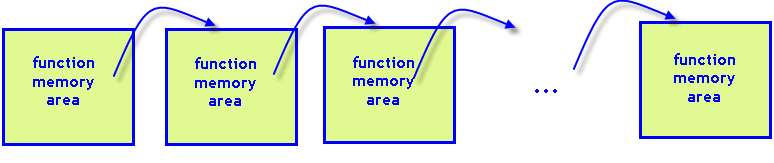
図8 各再帰的関数の呼出しにはプログラムスタックに専用のメモリ領域が必要です
別の方法を行います。新しい関数 FillTagStructure() です。
タグ構造を取得する関数を書き直します。文字列 array[] を処理するサイクルをはっきりとわかるように使用します。古い関数のアルゴリズムを理解していれば、新しい関数のアルゴリズムは明確です。
//+------------------------------------------------------------------+ //| it fills out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure to be created int & start[][], // tag start (line, position) int & end[][], // tag end (line, position) string array[]) // initial html text { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // if the number of tags exceeds { // the storage capacity ArrayResize(structure, curCapacity + capacity); // increase the storage in size ArrayResize(start, curCapacity + capacity); // also increase the size of the array of start positions ArrayResize(end, curCapacity + capacity); // also increase the size of the array of end positions curCapacity += capacity; // save the new capacity } currString = array[i]; // take the current string //Print(currString); posOpen = StringFind(currString, "<", currPos); // search for the first entrance of '<' after position currPos if (posOpen == -1) // not found { line = i; // go to the next line currPos = 0; // in the new line, search from the very beginning i++; continue; // return to the beginning of the cycle } // we are in this location, so a '<' has been found pos_ = StringFind(currString, " ", posOpen); // then search for a space, too posClose = StringFind(currString, ">", posOpen); // search for the closing angle bracket if ((pos_ == -1) && (posClose != -1)) // space is not found, but the bracket is { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it into tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // we are in this location, so both the space and the closing bracket have been found if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // space is after bracket { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // no, the space is still before the closing bracket if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } } // we are in this location, so neither a space nor a closing bracket have been found if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // assemble a tag of what we have structure[tagCounter] = tag; // written it to the tags array while (posClose == -1) // and organized a cycle to search for { // the first closing bracket i++; // increase in size the counter of lines currString = array[i]; // count the new line posClose = StringFind(currString, ">"); // and search for a closing bracket in it } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // it seems to have been found, then set the initial position } // to search for a new tag } ArrayResize(structure, tagCounter); // cut the tags array size down to the number of //---- // tags found return; }
これで配列はエレメントの capacity 部分でサイズ変更されました。capacity の値は定数宣言によって指定されます。
#define capacity 10000
各タグの開始位置と終了位置は関数 setPositions() によって設定されました。
//+------------------------------------------------------------------+ //| write the tag coordinates into the corresponding arrays | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
ところで、FindInArray() と getTagFromArray() はもう必要ではありません。スクリプトのフルコードはここに添付されているReportHTMLtoCSV-2.mq4 に提供されています。ビデオがスクリプトの使用方法を示しています。
ビデオ: HTML テキストチュートリアルでのスクリプト処理例
おわりに
タグに対する HTML ドキュメントチュートリアルのアルゴリズムが考察され、MetaTrader 4 クライアントターミナルのストラテジーテスタレポートから情報を抽出する方法例が提供されました。
ArrayResize() 関数の多量の呼出しをしないようにしてください。それは過度の時間消費につながる可能性があるためです。
また、再帰的関数の使用は重要な RAM リソースを消耗する可能性があります。そういった関数を多量に呼び出す場合、回帰が不要なように書き直すようにしてください。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/1544
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。

 高速で再描画しない ZigZag の書き方
高速で再描画しない ZigZag の書き方

 怠慢は、進歩またはグラフィックスとインタラクティブに作業する方法への刺激
怠慢は、進歩またはグラフィックスとインタラクティブに作業する方法への刺激
 一般的なトレーディングシステムを基にしたExpert Advisor と売買ロボット最適化の錬金術(パート7)
一般的なトレーディングシステムを基にしたExpert Advisor と売買ロボット最適化の錬金術(パート7)
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索