
Регулярные выражения для трейдеров

Введение
Регулярные выражения (англ. regular expressions) — особый инструмент, язык для обработки текстов по заданному образцу. Такой образец, или паттерн, имеет и другие названия — шаблон или маска регулярного выражения. Синтаксисом регулярных выражений определены множество метасимволов и правил.
Регулярные выражения способны выполнять две основные задачи:
- поиск шаблона в строке;
- замена найденного шаблона.
При составлении шаблонов для регулярных выражений, как мы уже написали, используются специальные символы, метасимволы и классы (наборы) символов. Это означает, что регулярное выражение представляет собой обычную строку, и все неспециальные (незарезервированные) символы в ней считаются обычными.
Конкретно поиск заданного паттерна в строке осуществляется обработчиком регулярных выражений. В .NET Framework, а следовательно — и в библиотеке RegularExpressions для MQL5, обработчик регулярных выражений выполняет поиск с возвратом для регулярных выражений. Он представляет собой вариацию традиционной NFA-машины (недетерминированного конечного автомата), аналогично тем, которые используются в Perl, Python, Emacs и Tcl. Замены найденных совпадений в строке осуществляет именно он.
1. Основы регулярных выражений
Метасимволы — это специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям MQL5 и C#. Такие символы предваряются обратным слэшем (\), каждый из них имеет особое назначение.
В нижеследующих таблицах метасимволы регулярных выражений MQL5 и C# сгруппированы по смыслу.
1.1. Классы символов:
| Символ | Значение | Пример | Соответствует |
|---|---|---|---|
| [...] | Любой из символов, указанных в скобках | [a-z] | В исходной строке может быть любой символ английского алфавита в нижнем регистре |
| [^...] | Любой из символов, не указанных в скобках | [^0-9] | В исходной строке может быть любой символ, кроме цифры |
| . | Любой символ, кроме перевода строки или другого разделителя Unicode-строки | ta.d | "trad" в строке "trade" |
| \w | Любой текстовый символ, не являющийся пробелом, символом табуляции и т.п. | \w | "M","Q","L","5" в строке "MQL 5" |
| \W | Любой символ, не являющийся текстовым символом | \W | " ", "." в строке "MQL 5." |
| \s | Любой пробельный символ из набора Unicode | \w\s | "L " в строке "MQL 5" |
| \S | Любой непробельный символ из набора Unicode. Обратите внимание, что символы \w и \S - это не одно и то же | \S | "M", "Q", "L", "5", "." в строке "MQL 5." |
| \d | Любые ASCII-цифры. Эквивалентно [0-9] | \d | "5" в "MQL 5." |
1.2. Символы повторения:
| Символ | Значение | Пример | Соответствует |
|---|---|---|---|
| {n,m} | Соответствует предшествующему шаблону, повторенному не менее n и не более m раз | s{2,4} | "Press", "ssl", "progressss" |
| {n,} | Соответствует предшествующему шаблону, повторенному n или более раз | s{1,} | "ssl" |
| {n} | Соответствует в точности n экземплярам предшествующего шаблона | s{2} | "Press", "ssl", но не "progressss" |
| ? | Соответствует нулю или одному экземпляру предшествующего шаблона; предшествующий шаблон является необязательным | Эквивалентно {0,1} | |
| + | Соответствует одному или более экземплярам предшествующего шаблона | Эквивалентно {1,} | |
| * | Соответствует нулю или более экземплярам предшествующего шаблона | Эквивалентно {0,} |
1.3. Символы регулярных выражений выбора:
| Символ | Значение | Пример | Соответствует |
|---|---|---|---|
| | | Соответствует либо подвыражению слева, либо подвыражению справа (аналог логической операции ИЛИ). | 1(1|2)0 | "110", "120" в строке "100, 110, 120, 130" |
| (...) | Группировка. Группирует элементы в единое целое, которое может
использоваться с символами *, +, ?, | и т.п. Также запоминает символы, соответствующие этой группе для использования в последующих ссылках. | ||
| (?:...) | Только группировка. Группирует элементы в единое целое, но не запоминает символы, соответствующие этой группе. |
1.4. Якорные символы регулярных выражений:
| Символ | Значение | Пример | Соответствует |
|---|---|---|---|
| ^ | Соответствует началу строкового выражения или началу строки при многострочном поиске. | ^Hello | "Hello, world", но не "Ok, Hello world" т.к. в этой строке слово "Hello" находится не в начале |
| $ | Соответствует концу строкового выражения или концу строки при многострочном поиске. | Hello$ | "World, Hello" |
| \b | Соответствует границе слова, т.е. соответствует позиции между
символом \w и символом \W или между символом \w и началом или концом строки. | \b(my)\b | В строке "Hello my world" выберет слово "my" |
Более подробно ознакомиться с элементами регулярных выражений вы можете, прочитав статью на официальном сайте Microsoft.
2. Особенности реализации регулярных выражений для MQL5
2.1. Сторонние файлы, хранящиеся в папке Internal
Для максимально близкой реализации RegularExpressions для MQL5 к исходному коду .Net нам потребовалось также перевести часть сторонних файлов. Все они хранятся в папке Internal и тоже представляют большой интерес.
Рассмотрим внимательнее содержимое папки Internal.
- Generic — в этой папке расположены файлы для реализации строго типизированных коллекций, перечислителей и интерфейсы для них. Более подробное описание будет приведено ниже.
- TimeSpan — файлы для реализации структуры TimeSpan, представляющей интервал времени.
- Array.mqh — в данном файле реализован класс Array, для которого, в свою очередь, имеется ряд статических методов по работе с массивами. Например: сортировка, бинарный поиск, получение перечислителя, получение индекса элемента и др.
- DynamicMatrix.mqh — в этом файле находятся два основных класса для реализации многомерных динамических массивов. Данные классы являются шаблонными, а следовательно, пригодны для стандартных типов и для указателей на классы.
- IComparable.mqh — файл, реализующий интерфейс IComparable, необходимый для поддержки ряда методов в типизированных коллекциях.
- Wrappers.mqh — обертки для стандартных типов и методы для нахождения хэш-кодов по ним.
В Generic реализованы три строго типизированных коллекции:
- List<T> представляет строго типизированный список объектов, доступных по индексу. Поддерживает методы для поиска по списку, выполнения сортировки и других операций со списками.
- Dictionary<TKey,TValue> представляет коллекцию ключей и значений.
- LinkedList<T> представляет двусвязный список.
Рассмотрим использование List<T> из эксперта TradeHistoryParsing. Этот эксперт считывает торговую историю из .html файла и фильтрует её по выбранным колонкам и записям. Торговая история состоит из двух таблиц: Сделки и Ордера. Классы OrderRecord и DealRecord интерпретируют одну запись (кортеж) из таблиц Ордера и Сделки, соответственно. Следовательно, каждую из таблиц можно представить как список её записей:
List<OrderRecord*>*m_list1 = new List<OrderRecord*>(); List<DealRecord*>*m_list2 = new List<DealRecord*>();
Поскольку класс List<T> поддерживает методы сортировки, значит, объекты типа T должны быть сравнимы между собой. Иными словами, для этого типа реализованы операции <,>,==. В случае со стандартными элементами проблем не возникает, но если нам нужно создать List<T>, где T — указатель на пользовательский класс, мы получим ошибку. Решить эту проблему можно двумя способами. Во-первых, мы можем в нашем классе явно перегрузить операторы сравнения. Другое решение — сделать класс наследником от интерфейса IComparable. Второй вариант значительно короче в реализации, но при этом нарушается правильность сортировки. В случаях, когда возникает необходимость в проведении сортировки для пользовательских классов, мы должны перегрузить все операторы сравнения, и вдобавок желательно реализовать наследование.
Это лишь одна из особенностей класса List<T>. Более подробнее мы рассмотрим его ниже.
Dictionary<TKey,TValue> — своего рода словарь из набора значений и соответствующих им уникальных ключей. При этом к одному ключу может быть привязано несколько значений. Типы ключей и значений определяет пользователь на этапе создания объекта. Как видно из описания, класс Dictionary<TKey,TValue> отлично подходит на роль хэш-таблицы. Для ускорения работы с Dictionary<TKey,TValue> необходимо создать новый класс, который является наследником от класса IEqualityComparer<T> и перегрузить две функции:
- bool Equals(T x,T y) — функция возвращает true, если x равен y, и false — в ином случае.
- int GetHashCode(T obj) — функция возвращает хэш-код от объекта obj.
В библиотеке RegularExpresiions для MQL5 эта особенность используется для всех словарей, ключами для которых служат строки.
Реализация класса StringEqualityComparer:
class StringEqualityComparer : public IEqualityComparer<string> { public: //--- Methods: //+------------------------------------------------------------------+ //| Determines whether the specified objects are equal. | //+------------------------------------------------------------------+ virtual bool Equals(string x,string y) { if(StringLen(x)!=StringLen(y)){ return (false); } else { for(int i=0; i<StringLen(x); i++) if(StringGetCharacter(x,i)!=StringGetCharacter(y,i)){ return (false); } } return (true); } int GetHashCode(string obj) { return (::GetHashCode(obj)); } };
Теперь при создании нового объекта, принадлежащего классу Dictionary<TKey,TValue>, где ключами являются строки, в конструкторе в качестве параметра передадим указание на объект StringEqualityComparer:
Dictionary<string,int> *dictionary= new Dictionary<string,int>(new StringEqualityComparer);
LinkedList<T> — это структура данных, которая включает в себя ряд элементов. Каждый элемент содержит информационную часть и два указателя: на предыдущий и нижеследующий элементы. Соответственно, два находящихся рядом элемента взаимно ссылаются друг на друга. Узлы такого списка реализуются объектами LinkedListNode<T>. В каждом таком узле содержится стандартный набор: значение, указатель на список и указатели на соседние узлы.
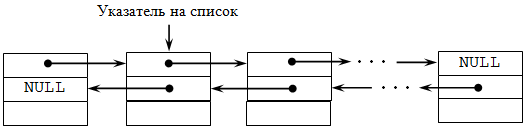
Также для всех трех вышеописанных коллекций реализованы перечислители. Перечислитель — это объект, представляющий собой обобщенный интерфейс IEnumerator<T>. IEnumerator<T> позволяет реализовать полный обход по коллекции вне зависимости от её структуры.
Для получения перечислителя необходимо вызвать метод GetEnumerator() от объекта, класс которого реализует интерфейс IEnumerable:
List<int>* list = new List<int>(); list.Add(0); list.Add(1); list.Add(2); IEnumerator<int> *en = list.GetEnumerator(); while(en.MoveNext()) { Print(en.Current()); } delete en; delete list;
В данном примере мы пробегаем по всему списку и печатаем каждое значение. Все это можно было проделать, организовав обычный цикл for, но зачастую подход с использованием перечислителей удобней. В частности, такое решение подходит, если нужно осуществить проход по Dictionary<TKey,TValue>.
2.2. Особенности библиотеки RegularExpressions для MQL5.
1. Для подключения всего функционала регулярных выражений в наш проект нужно добавить следующий фрагмент:
#include <RegularExpressions\Regex.mqh>2. Из-за отсутствия в языке MQL5 областей имен, а следовательно — и такого модификатора доступа, как internal, мы имеем доступ ко всем внутренним классам библиотеки и многим методам для них. По сути, это является излишним для работы с регулярными выражениями.
Для работы с регулярными выражениями нас будут интересовать классы:
- Capture — представляет результаты одной успешной записи части выражения.
- CaptureCollection — представляет набор записей, сделанных одной группой.
- Group — представляет результаты отдельной группы записи.
- GroupCollection — возвращает набор записанных групп в одном сопоставлении.
- Math — представляет результаты из отдельного совпадения регулярного выражения.
- MathCollection — представляет набор успешных совпадений, обнаруженных путем итеративного применения шаблона регулярного выражения к входной строке.
- Regex — представляет неизменяемое регулярное выражение.
Вдобавок к вышеперечисленному мы будем использовать:
- MatchEvaluator — указатель на функцию, который представляет метод, вызываемый каждый раз, когда обнаружено совпадение регулярного выражения.
- RegexOptions — перечисление, которое предоставляет значения для использования при задании параметров регулярных выражений.
RegexOptions — неполная копия исходного перечисления из .Net и включает в себя следующие элементы:
| Параметр | Описание |
|---|---|
| None |
Параметры не установлены. |
| IgnoreCase |
Регистр при поиске совпадений не учитывается. |
| Multiline | Указывает многострочный режим. |
| ExplicitCapture | Не захватывать неименованные группы. Единственные допустимые выделения — это явно именованные или нумерованные группы в формате (?<имя> часть выражения). |
| Singleline | Указывает однострочный режим. |
| IgnorePatternWhitespace | Устраняет из шаблона разделительные символы без escape-последовательности и включает комментарии, помеченные символом "#". |
| RightToLeft | Указывает, что поиск будет выполнен в направлении справа налево, а не слева направо. |
| Debug | Указывает, что программа работает под отладчиком. |
| ECMAScript | Включает ECMAScript-совместимое поведение для выражения. Это значение может быть использовано только вместе со значениями IgnoreCase и Multiline. |
Эти опции используются при создании нового объекта класса Regex или при вызовах его статических методов.
Примеры использования всех этих классов, указателя и перечисления вы можете найти в исходном коде эксперта Tests.mq5.
3. Как и в версии под .Net, в данной библиотеке реализовано хранилище (статическая кэш-память)
регулярных выражений. Все неявно созданные регулярные выражения
(экземпляры класса Regex) заносятся в это хранилище. Такой подход
ускоряет работу скриптов, поскольку отпадает необходимость заново строить
регулярные выражения, если его шаблон совпадает с одним из уже
имеющихся. По умолчанию размер хранилища равен 15. Метод Regex::CacheSize() возвращает или задаёт максимальное количество записей в текущей статической кэш-памяти скомпилированных регулярных выражений.
4. Вышеупомянутое хранилище необходимо очищать. Для этого вызывается статическая функция Regex::ClearCache(). Это рекомендуется делать только после того, как вы закончили работу с
регулярными выражениями, иначе велика вероятность удаления нужных
указателей и объектов.
5. Синтаксис языка C# позволяет ставить перед строками символ '@' для игнорирования всех знаков форматирования. В MQL5 такой подход не предусмотрен, поэтому все управляющие символы в шаблоне регулярных выражений нужно прописывать явно.
3. Пример разбора торговой истории
Внимание! Примеры, представленные в данной статье, воспроизводятся только при условии того, что на компьютер уже установлена библиотека RegularExpressions для MQL5.
Данный пример подразумевает следующие операции.
- Чтение торговой истории из песочницы в формате .html файла.
- Выбор одной из двух таблиц (таблиц "Ордера" или таблицы "Сделки") для последующей работы с ней.
- Выбор фильтров для таблицы.
- Графическое представление отфильтрованной таблицы.
- Краткая математическая статистика по отфильтрованной таблице.
- Возможность сохранения отфильтрованной таблицы.
Все эти шесть пунктов реализованы в эксперте TradeHistoryParsing.mq5.
Для работы с экспертом первым делом необходимо скачать торговую историю. Для этого в торговом терминале MetaTrader5 на панели "Инструменты" переходим во вкладку "История", правым кликом открываем диалоговое окно, выбираем пункт "Отчеты" и далее — HTML (InternetExplorer).
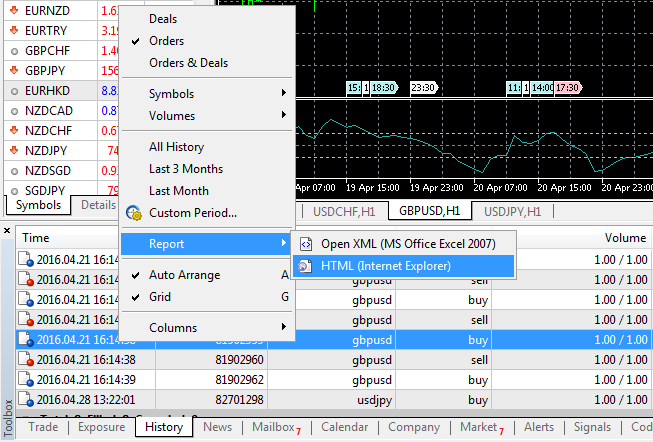
Сохраняем файл в песочнице (\MetaTrader 5\MQL5\Files).
Теперь при запуске эксперта в диалоговом окне переходим во вкладку "Входные параметры" и в поле file_name вводим имя нашего файла:
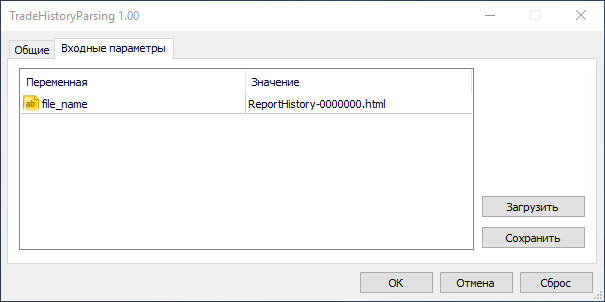
Теперь после нажатия "ОК" появится сам интерфейс эксперта:
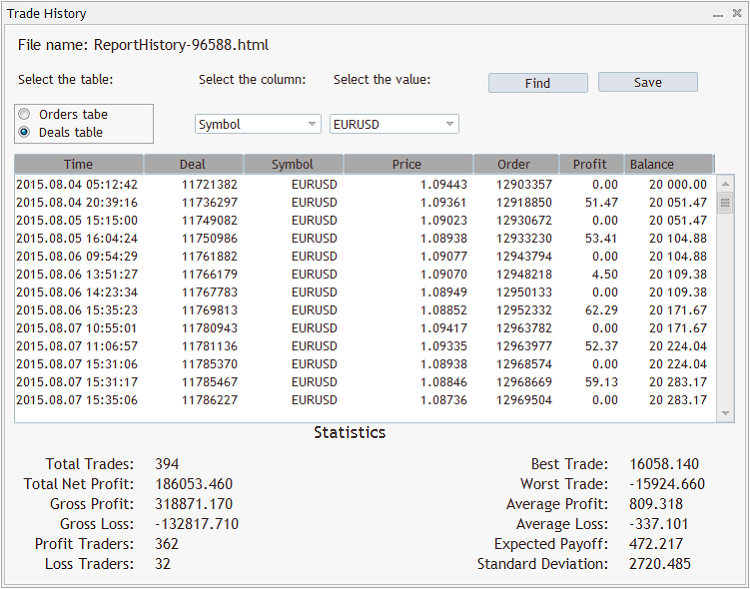
Как уже говорилось выше, обе таблицы представлены в эксперте в виде двух типизированных листов: List<OrderRecord*> и List<DealRecord*>.
Конструкторы для классов OrderRecord и DealRecord принимают в качестве параметров массив строк, который переставляет из себя одну запись из таблицы.
Для создания этих массивов нам и пригодятся регулярные выражения. Весь разбор истории происходит в конструкторе класса TradeHistory, также в этом классе хранятся представления обеих таблиц и реализованы методы по их фильтрации. Конструктор данного класса принимает один параметр — path, в нашем случае это имя .html файла истории:
TradeHistory(const string path) { m_file_name=path; m_handel= FileOpen(path,FILE_READ|FILE_TXT); m_list1 = new List<OrderRecord*>(); m_list2 = new List<DealRecord*>(); Regex *rgx=new Regex("(>)([^<>]*)(<)"); while(!FileIsEnding(m_handel)) { string str=FileReadString(m_handel); MatchCollection *matches=rgx.Matches(str); if(matches.Count()==23) { string in[11]; for(int i=0,j=1; i<11; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list1.Add(new OrderRecord(in)); } else if(matches.Count()==27) { string in[13]; for(int i=0,j=1; i<13; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list2.Add(new DealRecord(in)); } delete matches; } FileClose(m_handel); delete rgx; Regex::ClearCache(); }
Как видно из кода данного конструктора, для разбора торговой истории мы используем только одно регулярное выражение с шаблоном "(>)([^<>]*)(<)". Рассмотрим этот шаблон подробнее:
| (>) | Поиск символа '>' |
| (^[<>]*) | Любой символ, кроме '>' и '<', повторяющийся ноль или более раз |
| (<) | Поиск символа '<' |
Данное регулярное выражение ищет все подстроки, которые начинаются с '>' и заканчиваются '<'. Текст же, который находится между ними, не должен начинаться с '<' или '>'. Проще говоря, мы получаем тест между тегами в .html файле, по краям которого еще будут ненужные скобки, их мы уберем позже. Все найденные подстроки мы сохраняем в MathcCollection — коллекции всех подстрок, удовлетворяющих шаблону регулярного выражения и найденных в исходной строке. Из-за структуры .html файла мы точно можем определить, является наша строка записью из таблицы Ордеров, записью из таблицы Сделок или иной строкой, просто посчитав количество совпадений. Так, строка является записью таблицы Ордеров, если количество её совпадений равно 23, таблицы Сделок — если совпадений 27. В ином случае эта строка нас не интересует. Теперь из нашей коллекции мы извлекаем все четные элементы (в нечетных будут строки "><"), обрезаем первый и последний символ и записываем готовую строку в массив:
in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2);
При этом после прочтения каждой новой строки нужно удалять коллекцию совпадений. После прочтения всего файла необходимо закрыть его, удалить регулярное выражение и почистить буфер регулярных выражений.
Теперь нам необходимо реализовать фильтрацию таблиц, а именно: выбрав некоторую колонку и определенное значение из неё, получить урезанную таблицу. В нашем случае из листа мы должны получить подлист. Для это мы можем создать новый лист, организовать полный перебор всех элементов старого листа и, если он удовлетворяет заданным условиям, добавлять его в новый лист.
Но есть и другой способ на основе метода FindAll(Predicate match) для List<T>. Он извлекает все элементы, удовлетворяющие условиям указанного предиката, который является указателем на функцию и имеет вид:
typedef bool (*Predicate)(IComparable*);
Про интерфейс IComparable уже было рассказано ранее.
Осталось лишь реализовать саму функцию match, где уже заранее известно правило, по которому мы принимаем или отклоняем элемент листа. В нашем случае это номер колонки и значение в ней. Для решения этой задачи в классе Record, который является наследником для классов OrderRecord и DealRecord, есть два статических метода SetIndex(const int index) и SetValue(const string value). Эти методы принимают и запоминают номер колонки и значения в ней. Потом эти данные как раз и будут использоваться при реализации нашего метода для поиска:
static bool FindRecord(IComparable *value) { Record *record=dynamic_cast<Record*>(value); if(s_index>=ArraySize(record.m_data) || s_index<0) { Print("Iindex out of range."); return(false); } return (record.m_data[s_index] == s_value); }
Здесь s_index — статическая переменная, значение которой задаётся методом SetIndex, а s_value — статическая переменная, значение которой задаётся методом SetValue.
Теперь, задавая нужные нам значения номера колонки и значения в ней, мы с легкостью получим урезанную версию нашего листа:
Record::SetValue(value); Record::SetIndex(columnIndex); List<Record*> *new_list = source_list.FindAll(Record::FindRecord);
Именно эти отфильтрованные листы будут отображаться в графическом интерфейсе эксперта.
При необходимости имеется возможность сохранения этих отфильтрованных таблиц в .csv файлы. Файл будет сохранен также в песочницу под названием Result.csv.
ВАЖНО! При сохранении файлов им всегда присваивается одно и то же имя. Таким образом, если возникает необходимость сохранения двух и более таблиц, нужно сохранять их по одной и переименовывать. Иначе будет происходить перезапись одного и того же файла.
4. Пример разбора результатов оптимизации эксперта
Данный пример обрабатывает .xml файл результата оптимизации эксперта из терминала MetaTrader5. В нем реализовано графическое представление для данных, полученных в ходе оптимизации, а также возможность их фильтрации. Все данные делятся на две таблицы:
- "Tester results table" — в нее входят все статистические данные, полученные в ходе тестирования;
- "Input parameters table" — здесь хранятся все значения входных переменных. Для этой таблицы установлен лимит в десять входных параметров. Если параметров больше, то они не будут отображаться.
Для установления фильтра на одну из таблиц необходимо выбрать имя колонки, по которой будет проходить фильтрация, и задать диапазон значений.
Графический интерфейс примера имеет вид:
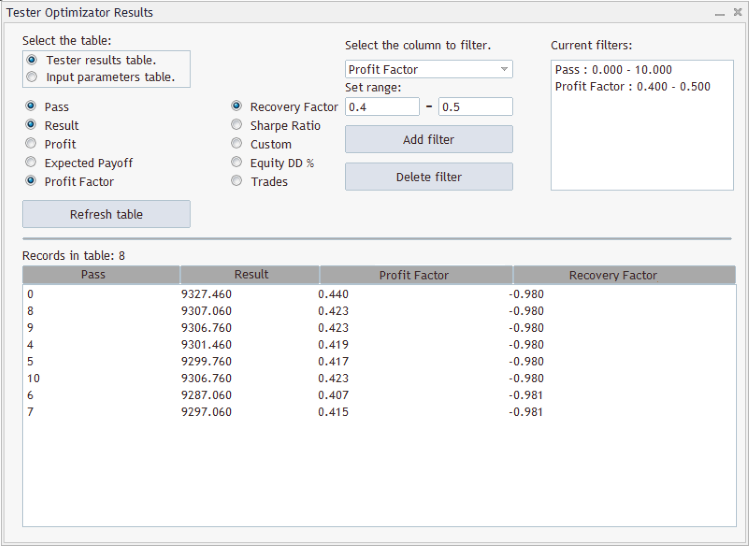
На данном рисунке показано отображение таблицы "Tester results table" с активными колонками: "Pass", "Result", "Profit Factor", "Recovery Factor" и двумя фильтрами:
- Значения в колонке "Pass" должны принадлежать диапазону значений [0; 10];
- Значения в колонке "Profit Factor" должны принадлежать диапазону значений [0.4; 0.5].
5. Краткое описание примеров из библиотеки RegularExpressions для MQL5
Помимо двух описанных экспертов, к библиотке RegularExpressions для MQL5 прилагается 20 примеров. В них будут реализованы различные возможности регулярных выражений и данной библиотеки в целом. Все они находятся в эксперте Tests.mq5:
Рассмотрим, какие конкретно особенности и возможности библиотеки задействованы в каждом из примеров.
- MatchExamples — показывает два возможных варианта перебора всех сопадений (Match) — через создание MatchCollection или путем использования метода Match.NextMatch().
- MatchGroups — показывает способ получения результатов отдельной группы записи(Group) и дальнейшую работу с ними.
- MatchResult — демонстрирует использование метода Match.Result(string), который возвращает расширение указанного шаблона замены.
- RegexConstructor — показывает 3 различных варианта создания класса Regex: на основе шаблона, шаблона с указаным параметрами, шаблона с параметрами и значением, указывающим, как долго метод сравнения с шаблоном должен пытаться найти совпадение, прежде чем время ожидания истечёт.
- RegexEscape — демонстрирует работу метода Regex::Escape(string).
- RegexExample — показывает процесс создания регулярных выражений и их последующую обработку.
- RegexGetGroupNames — показывает пример использования метода Regex.GetGroupNames(string);
- RegexGetGroupNumbers — показывает пример использования метода Regex.GetGroupNumbers(int);
- RegexGroupNameFromNumber — показывает пример использования метода Regex.GroupNameFromNumber(int);
- RegexIsMatch — показывает пример использования всех вариантов статического метода Regex::IsMatch();
- RegexReplace — показывает пример использования основных вариантов статического метода Regex::Replace();
- RegexSplit — показывает пример использования основных вариантов статического метода Regex::Split();
- Capture — пример работы с результатом одной успешной записью части выражения(Capture).
- CaptureCollection — пример работы с набором записей, сделанных одной группой записи(CaptureCollection).
- Group — пример работы с результатом отдельной группы записи(Group).
- GroupCollection — пример работы с набором записанных групп в одном сопоставлении(GroupCollection).
- MatchCollectionItem — создание MatchCollection статическим методом Regex::Matches(string,string);
- MatchEvaluator — пример создания указателя на функцию типа MatchEvaluator и его использование.
- RegexMatchCollectionCount — демонстрация метода MatchCollection.Count();
- RegexOptions — демонстрация влияния параметра RegexOptions на обработку регулярного выражения.
Большинство примеров пересекаются по функциональным возможностям и служат по большей части для тестирования работы библиотеки.
Заключение
В данной статье вкратце рассказано о возможностях регулярных выражений и их применении. Для более подробного ознакомления рекомендуем почитать статьи по указанным ниже ссылкам. Синтаксис регулярных выражений на .Net во многом совпадает и с реализацией на MQL5, поэтому все справки от Microsoft будут актуальны, хотя бы отчасти. То же самое касается и классов из папки Internal.
Ссылки
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.

 Графические интерфейсы VI: Элементы "Слайдер" и "Двухсторонний слайдер" (Глава 2)
Графические интерфейсы VI: Элементы "Слайдер" и "Двухсторонний слайдер" (Глава 2)
 Графические интерфейсы VI: Элементы "Чекбокс", "Поле ввода" и их смешанные типы (Глава 1)
Графические интерфейсы VI: Элементы "Чекбокс", "Поле ввода" и их смешанные типы (Глава 1)
 Создаем помощника в ручной торговле
Создаем помощника в ручной торговле
 Битва за скорость: QLUA vs MQL5 - почему MQL5 быстрее от 50 до 600 раз?
Битва за скорость: QLUA vs MQL5 - почему MQL5 быстрее от 50 до 600 раз?
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Я не могу запустить ваши примеры у себя на МТ5 build1340, т.к. при компиляции