
Нейросети — это просто (Часть 68): Офлайн оптимизация политик на основе предпочтений

Введение
Обучение с подкреплением является универсальной платформы для обучения оптимальной политики поведения в исследуемом окружении. Оптимальность политики достигается путем максимизации вознаграждения, получаемого от окружающей среды в процессе взаимодействия с ней. Но здесь кроется одна из основных проблем данного подхода. Разработка подходящей функции вознаграждения часто требует значительных усилий человека. Кроме того, вознаграждения могут быть разреженными и/или недостаточными для выражения истинной цели обучения. В качестве одного из вариантов решения данной проблемы предлагается метод Offline Preference-guided Policy Optimization (OPPO), который был представлен в статье "Beyond Reward: Offline Preference-guided Policy Optimization". Авторы метода предлагают подменить вознаграждение от окружающей среды на предпочтения человеческого аннотатора между двумя траекториями, совершенными в анализируемой окружающей среде. Я предлагаю подробнее рассмотреть предложенный алгоритм.
1. Алгоритм OPPO
В контексте оффлайн обучения на основе предпочтений общий подход состоит из двух шагов и обычно включает в себя оптимизацию модели функции вознаграждения методом обучения с учителем, а затем обучение политики с использованием любого алгоритма оффлайн RL на переходах, переопределенных с использованием выученной функции вознаграждения. Однако практика отдельного обучения функции вознаграждения может не напрямую указывать политике, как действовать оптимально. Так как метки предпочтения определяют задачу обучения, и цель состоит в том, чтобы узнать наиболее предпочтительную траекторию, а не максимизировать вознаграждение. В случаях сложных задач скалярные вознаграждения могут создавать узкое место в информации при оптимизации политики, что в свою очередь приводит к неоптимальному поведению Агента. Кроме того, офлайн оптимизация политики может использовать уязвимости в неверных функциях вознаграждения. А это ведет к нежелательному поведению.
В качестве альтернативы такому двухэтапному подходу авторы метода Offline Preference-guided Policy Optimization (OPPO) стремятся изучать стратегию напрямую из офлайн набора данных с размеченными предпочтениями. И предлагают одношаговый алгоритм, который одновременно моделирует оффлайн предпочтения и изучает оптимальную политику принятия решений без необходимости отдельного обучения функции вознаграждения. Это достигается благодаря использованию двух целей:
- цели сопоставления информации "в отсутствие" офлайн;
- цели моделирования предпочтений.
Путем итеративной оптимизации этих целей мы приходим к построению контекстуальной политики π(A|S,Z) для моделирования офлайн данных и оптимального контекста предпочтений Z'. Основное внимание в OPPO уделяется изучению пространства Z высокой размерности и оценке политик в таком пространстве. Это пространство Z высокой размерности захватывает больше информации о поставленной задаче, по сравнению со скалярным вознаграждением, что делает его идеальным для целей оптимизации политики. Кроме того, оптимальная политика получается путем условного моделирования контекстуальной политики π(A|S,Z) на выученном оптимальном контексте Z'.
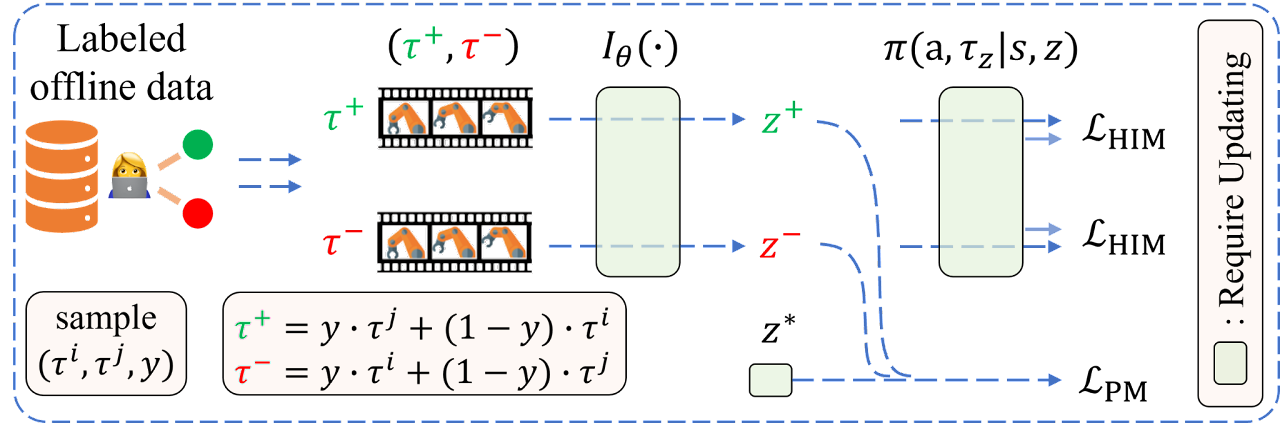
Авторами алгоритма вводится предположение о возможности аппроксимации функции предпочтений моделью Iθ, что позволяет сформулировать следующую цель:
![]()
где Z=Iθ(τ) и представляет собой контекст предпочтений. Такая структура кодировщик—декодировщик напомнит офлайн имитационное обучение. Однако, так как в настройке обучения на основе предпочтений отсутствуют демонстрации экспертов, авторами алгоритма используются метки предпочтений для извлечения ретроспективной информации.
Для достижения соответствия ретроспективной информации Iθ(τ) и предпочтений в размеченном наборе данных, авторы метода формулируют следующую цель моделирования предпочтений:
![]()
где z+ и z- представляют собой контекст предпочтительной (положительной) траектории Iθ(yτj + (1-y)τi) и менее предпочтительной (отрицательной) траектории Iθ(yτi + (1-y)τj), соответственно. Основное предположение при формулировке указанной цели заключается в том, что люди обычно проводят двухуровневые сравнения перед выражением предпочтений между двумя траекториями (τi, τj):
- отдельное сравнение сходства между траекторией τi и гипотетической оптимальной траекторией τ*, то есть l(z*,z+) и сходства между траекторией τj и гипотетической оптимальной траекторией τ*, то есть l(z*,z-),
- оценка различий между этими двумя сходствами l(z*,z+) и l(z*,z-) с установкой траектории более близкой к предпочтительной.
Таким образом, оптимизация цели гарантирует нахождение оптимального контекста, который более похоже на z+ и менее похоже на z-.
Следует уточнить, что z* — это соответствующий контекст для траектории τ*, в то время как траектория τ* всегда будет предпочтительнее любых офлайн траекторий в наборе данных.
Обратите внимание, что апостериорная вероятность оптимального контекста z* и извлечение ретроспективной информации предпочтений Iθ(•) обновляются поочередно для обеспечения стабильности обучения. Лучшая оценка оптимального вложения помогает кодировщику извлекать признаки, на которые обращает больше внимания человек при определении предпочтений. В свою очередь, лучший кодировщик ретроспективной информации ускоряет процесс поиска оптимальной траектории в пространстве высокоуровневого вложения. Таким образом, функция потерь для кодировщика состоит из двух частей:
- ошибка сопоставления информации ретроспектив в стиле обучения с учителем,
- ошибка для лучшего включения бинарного наблюдения, предоставленного помеченным набором данных предпочтений.
Авторская визуализация алгоритма OPPO представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода OPPO мы переходим к практической части нашей статьи, в которой рассмотрим один из вариантов реализации предложенного алгоритма. А начнем мы со структуры хранения данных SState. Как было сказано выше, авторы метода подменяют классически используемое вознаграждение на метку предпочтения траектории. Поэтому, нам нет необходимости сохранять вознаграждение на каждом переходе в новое состояние окружающей среды. В то же время вводится понятия контекста предпочтительной траектории. Следуя предложенной логике в структуре описания состояния окружающей среды мы замени массив декомпозированного вознаграждения rewards, на массив контекста scheduler.
struct SState { float state[BarDescr * NBarInPattern]; float account[AccountDescr]; float action[NActions]; float scheduler[EmbeddingSize]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- void Clear(void) { ArrayInitialize(state, 0); ArrayInitialize(account, 0); ArrayInitialize(action, 0); ArrayInitialize(scheduler, 0); } //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(scheduler, obj.scheduler); } };
Обратите внимание, что мы изменили не только наименование, но и размер массива.
Помимо скрытого контекста, алгоритмом вносится и понятие предпочтения траектории. Здесь следует обратить внимание на несколько аспектов:
- приоритет выставляется для траектории в целом, а не отдельных действий и переходов (оценивается политика);
- приоритеты выставляются попарно между всеми траектории в офлайн наборе данных в диапазоне [0: 1];
- приоритеты выставляются экспертом.
Сразу скажу, что мы не будем вручную размечать приоритеты всех траекторий из буфера воспроизведения опытом. Как и не будем составлять шахматную таблицу приоритетов.
Критериев приоритетов можно выбрать довольно много. Но в рамках данной статьи я использовал только один — профит от прохождения траектории. Я согласен, что в критерии можно добавить максимальную просадку как по балансу, так и по Эквити. Можно добавить профит фактор и многое другое. Я предлагаю Вам самостоятельно выбрать оптимальный для вас набор критериев и коэффициенты их ценности. Выбранный Вами набор критериев безусловно скажется на конечном результате обучения политики, но не окажет влияние на алгоритм предложенной реализации.
И так как приоритет выставляется для траектории в целом, то и нам достаточно сохранить размер прибыли, полученной в конце траектории. Её мы будем сохранять в структуре описания траектории STrajectory.
struct STrajectory { SState States[Buffer_Size]; int Total; double Profit; //--- STrajectory(void); //--- bool Add(SState &state); void ClearFirstN(const int n); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const STrajectory &obj) { Total = obj.Total; Profit = obj.Profit; for(int i = 0; i < Buffer_Size; i++) States[i] = obj.States[i]; } };
Разумеется, что изменение полей структур потребует и внесение изменений в методы работы копирования и работы с файлами, указанных структур. Но эти корректировки настолько точечные, что я предлагаю Вам самостоятельно ознакомиться с ними во вложенных файлах.
2.1 Архитектура моделей
Для обучения политики мы будем использовать 2 модели. Планировщик будет изучать предпочтения, а Агент учить политику поведения. Обе модели будут построены по принципу Трансформера Решений (DT) и использовать механизмы внимания. Однако, в отличии от авторского решения поочередного обновления моделей, мы создадим 2 советника для обучения моделей. И каждый из них будет участвовать в обучении только одной модели. Объединять их в единый механизм мы будем на стадии тестирования и эксплуатации модели. Поэтому для описания архитектуры моделей мы также создадим 2 метода:
- CreateSchedulerDescriptions — для описания архитектуры Планировщика;
- CreateAgentDescriptions — для описания архитектуры Агента.
На вход планировщика мы подаем:
- исторические данные ценового движения и индикаторов
- описания состояния счета и открытых позиций
- временную метку
- последние действие Агента.
bool CreateSchedulerDescriptions(CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Напомню, что Трансформер Решений эксплуатирует архитектуру GPT и сохраняет в своем скрытом состоянии эмбединги ранее полученных данных, что позволяет принимать решения в едином контексте на протяжении всего эпизода. Поэтому на вход модели мы подаем лишь краткое описание текущего состояния, акцентируя внимания на последних изменениях. Иными словами, на вход модели мы подаем информации лишь о последней закрытой свече.
Полученные данные проходят предварительную обработку в слое нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
После чего приводятся в сопоставимый вид в слое Эмбединга.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!scheduler.Add(descr)) { delete descr; return false; }
Полученные эмбединги нормализуем функцией SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 4; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Предварительно обработанные таким образом данные проходят через блок внимания.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Полученные данные мы снова нормализуем функцией SoftMax и пропускаем через блок полносвязных слоев принятия решения.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
На выходе модели мы получаем вектор латентного представления контекста, размер которого определяется константой EmbeddingSize.
Подобную архитектуру мы прорисовываем и для нашего Агента. Только в его исходных данных добавляется сгенерированный контекст.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateAgentDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + EmbeddingSize); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Данные так же проходят предварительную обработки через слои пакетной нормализации, эмбединга и нормализуются функцией SoftMax.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Мы полностью повторяем блок внимания с последующей нормализацией функцией SoftMax. Здесь следует обратить внимание лишь на изменение размера обрабатываемого тензора.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Далее мы понижаем размерность данных с помощью сверточных слоев и при этом пытаемся выделить в них устойчивые паттерны.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
После чего данные проходят через блок принятия решений из 4 полносвязных слоев. Размер последнего слоя равен пространству действий Агента.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 Сбор траекторий для обучения
После описания архитектуры моделей мы переходим к построению советников их обучения. И первым мы построим советник взаимодействия с окружающей средой для сбора траекторий и заполнения буфера воспроизведения опыта, который мы позже будем эксплуатировать в процессе офлайн обучения "...\OPPO\Research.mq5".
Для исследования окружающей среды мы будем использовать ɛ-жадную стратегию и добавим советнику соответствующий внешний параметр.
input double Epsilon = 0.5;
Как уже упоминалось выше, в процессе взаимодействия с окружающей средой мы используем обе модели. Следовательно, нам необходимо объявить для них глобальные переменные.
CNet Agent; CNet Scheduler;
Метод инициализации советника мало чем отличается от аналогичного метода рассмотренных ранее нами советников, и я предлагаю не останавливаться сейчас на рассмотрении его алгоритма. Вы самостоятельно можете ознакомиться с ним во вложении. А мы переходим к рассмотрению метода OnTick, в теле которого и построен основной процесс взаимодействия с окружающей средой и сбора данных.
В теле метода мы, как всегда, проверяем наступление события открытия нового бара.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
И, при необходимости, загружаем исторические данные ценового движения.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return;
После чего обновляем показания анализируемых индикаторов.
RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Полученные данные оформляем в структуру текущего состояния и передаем в буфер данных, для последующего использования в качестве исходных данных для наших моделей.
//--- History data float atr = 0; //--- for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Следующим этапом мы дополняем структуру описания текущего состояния окружающей среды информацией о балансе счета и открытых позициях.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Собранная информация также пополняет буфер исходных данных.
bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Добавим в буфер исходных данных временную метку и последнее действие Агента.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
На данном этапе мы собрали объем информации, достаточный для прямого прохода Планировщика. Что позволяет нам сформировать вектор контекста, необходимый нашему Агенту. Следовательно, осуществляем прямой проход Планировщика.
if(!Scheduler.feedForward(GetPointer(bState), 1, false)) return; Scheduler.getResults(sState.scheduler); bState.AddArray(sState.scheduler);
Выгружаем полученный результат и дополняем буфер исходных данных. После чего мы вызываем метод прямого прохода Агента.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
Здесь хочется напомнить о необходимости контролирования корректного выполнения операций на каждом этапе.
На данном этапе мы завершаем работу с моделями, сохраняем данные для последующих операций и переходим к непосредственному взаимодействию с окружающей средой.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Получив данные от нашего Агента, мы, в случае необходимости, добавляем к ним шум.
Agent.getResults(AgentResult); if(Epsilon > (double(MathRand()) / 32767.0)) for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
Убираем из размеров позиций дублирующие объемы.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
После чего мы сначала корректируем длинную позицию.
//--- buy control if(AgentResult[0] < 0.9 * min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double(AgentResult[0] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
А затем осуществляем аналогичные операции для короткой позиции.
//--- sell control if(AgentResult[3] < 0.9 * min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double(AgentResult[3] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
На данном этапе мы обычно формируем вектор вознаграждений, но в рамках рассматриваемого алгоритма он не используется. Поэтому мы лишь переносим данные о совершенных действиях Агента и передаем данные для сохранения траектории.
for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
После чего переходим к ожиданию открытия следующего бара.
В этом месте логичен вопрос: а как же мы будем оценивать предпочтения?
Ответ прост: информацию о результативности прохода мы добавим в методе OnTester после завершения прохода в тестере стратегий.
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- Base.Profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(Base.Profit >= MinProfit) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, Base.Profit, Frame); //--- return(ret); }
Остальные методы советника взаимодействия с окружающей средой остались без изменений, и Вы можете самостоятельно ознакомиться с ними во вложении. А мы переходим к рассмотрению алгоритмов непосредственного обучения моделей.
2.3 Обучение модели Предпочтений
Первым мы рассмотрим советник обучения модели предпочтений "...\OPPO\StudyScheduler.mq5". Архитектура построения советника осталась без изменений, и я предлагаю подробно остановиться только на методах, участвующих в обучении модели.
Здесь я должен признаться, что в процессе обучения модели используются наработки из прошлых статей. Симбиоз с которыми, по моему личному мнению, должен повысить эффективность процесса обучения.
Перед началом процесса обучения мы сформируем вероятностное распределение выбора траекторий на основе их доходности, как это было предложено в методе CWBC. Однако, описанный ранее метод GetProbTrajectories требует точечных правок, связанных с отсутствием вектора вознаграждений. Мы прежде всего изменяем источник получения информации о суммарном результате траектории. При этом вектор декомпозированного вознаграждения заменяется на скалярное значение итоговой прибыли. Следовательно, матрицу мы заменяем вектором.
vector<double> GetProbTrajectories(STrajectory &buffer[], float lanbda) { ulong total = buffer.Size(); vector<double> rewards = vector<double>::Zeros(total); for(ulong i = 0; i < total; i++) rewards[i]=Buffer[i].Profit;
После чего определяем уровень максимальной доходности и среднеквадратическое отклонение.
double std = rewards.Std(); double max_profit = rewards.Max();
Следующим шагом мы сортируем результаты траекторий для корректного определения перцентиля.
vector<double> sorted = rewards; bool sort = true; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { double temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } }
Дальнейшая процедура построения вероятностного распределения не претерпела изменений и перенесена в ранее описанном виде.
double min = rewards.Min() - 0.1 * std; if(max_profit > min) { double k = sorted.Percentile(90) - max_profit; vector<double> multipl = MathAbs(rewards - max_profit) / (k == 0 ? -std : k); multipl = exp(multipl); rewards = (rewards - min) / (max_profit - min); rewards = rewards / (rewards + lanbda) * multipl; rewards.ReplaceNan(0); } else rewards.Fill(1); rewards = rewards / rewards.Sum(); rewards = rewards.CumSum(); //--- return rewards; }
На этом подготовительный этап можно считать завершенным, и мы переходим к рассмотрению алгоритма метода обучения модели предпочтений Train.
В теле метода мы сначала формируем вектор вероятностного распределения выбора траекторий из буфера воспроизведения опытом с помощью выше рассмотренного метода GetProbTrajectories.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
Далее мы организовываем систему циклов обучения модели. Число итераций внешнего цикла определяется внешним параметром советника.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr_p = SampleTrajectory(probability); int tr_m = SampleTrajectory(probability); while(tr_p == tr_m) tr_m = SampleTrajectory(probability);
В теле цикла мы сэмплируем 2 траектории в качестве положительного и отрицательного примеров. Для соблюдения принципов максимальной объективности мы контролируем выбор 2 различных траекторий из буфера воспроизведения опыта.
Очевидно, что простое сэмплирование не гарантирует нам выбор положительной траектории первой, как и наоборот. Поэтому мы проверяем доходность выбранных траекторий и, при необходимости, переставляем указатели на траектории в переменных.
if(Buffer[tr_p].Profit < Buffer[tr_m].Profit) { int t = tr_p; tr_p = tr_m; tr_m = t; }
Далее, алгоритмом OPPO предусмотрено обучение модели предпочтений в направлении от отрицательной траектории к предпочтительной. На первый взгляд звучит легко и очевидно. Но на практике мы сталкиваемся с несколькими "подводными камнями".
В рамках генерации всех траекторий мы использовали один отрезок исторических данных. Поэтому информация о ценовом движении и значениях анализируемых индикаторов для всех траекторий будет идентичной. Чего не скажешь о других анализируемых параметрах. Я говорю о состоянии счета, открытых позициях и, конечно, действиях Агента. Становится очевидно, что для корректного распределения градиента ошибки нам необходимо последовательно осуществить прямой проход для состояний из обоих траекторий.
Но это приводит к постановке следующего вопроса. В своей модели мы эксплуатируем архитектуру GPT, которая чувствительна к последовательности подачи исходных данных. Как в таком случае нам сохранить последовательности двух различных траекторий в рамках одной модели. Напрашивается очевидный ответ — параллельно использовать 2 модели с периодическим слиянием весовых коэффициентов, по аналогии с мягким обновлением целевых моделей в методах TD3 и SAC. Но и здесь есть сложности. В упомянутых методах целевые модели не обучались, и мы использовали их буферы моментов в рамках процесса мягкого обучения. Однако в данном случае модели обучаются. И буферы моментов используются по прямому назначению. Доливка в них информации о мягком обновлении весовых коэффициентов может исказить процесс обучения. Не обходим детальный анализ и поиск конструктивных решений.
На мой взгляд, наиболее приемлемым вариантом является последовательное обучение одной модели вначале на данных одной траектории, а затем на данных второй траектории с использованием обратных значений градиентов ошибки. Ведь для предпочтительной траектории мы минимизируем расстояние, а для отрицательной — максимизируем.
Следуя этой логике мы сэмплируем начальное состояние на предпочтительной траектории.
//--- Positive int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_p].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_p].Total, 20))); if(i < 0) { iter--; continue; }
Очищаем стеки модели и организовываем процесс обучения в рамках предпочтительной траектории.
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_p].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_p].States[state].state);
В теле цикла мы заполняем буфер исходных данных историческими значениями ценового движения и показателей индикаторов из обучающей выборки траекторий.
Дополняем данные информацией о состоянии счета и открытых позициях.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr_p].States[state].account[0] : Buffer[tr_p].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_p].States[state].account[1] : Buffer[tr_p].States[state - 1].account[1]); State.Add((Buffer[tr_p].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_p].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_p].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_p].States[state].account[2]); State.Add(Buffer[tr_p].States[state].account[3]); State.Add(Buffer[tr_p].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[6] / PrevBalance);
Добавим гармоники временной метки и вектор последних действий Агента.
//--- Time label double x = (double)Buffer[tr_p].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_p].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
После успешного сбора всех необходимых данных мы осуществляем прямой проход обучаемой модели.
//--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Обучение модели осуществляется аналогично методам обучения с учителем и направленно на минимизацию отклонений прогнозных значений контекста от соответствующих данных предпочтительной траектории в буфере воспроизведения опыта.
//--- Study Result.AssignArray(Buffer[tr_p].States[state].scheduler); if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Далее мы информируем пользователя о ходе процесса обучения и переходим к следующей итерации в рамках обучения модели с предпочтительной траекторией.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После успешного завершения итераций цикла в рамках предпочтительной траектории мы переходим к работе со второй.
Здесь надо сказать, что теоретически мы можем работать с аналогичным временным отрезком и использовать начальное состояние, сэмплированное для положительной траектории. Ведь на одном историческом отрезке у нас одинаковое количество шагов во всех траекториях. Что, можно сказать, является частным случаем. Но если рассматривать более общий случай, то возможны варианты и с различным количеством шагов в траекториях. К примеру, при работе на достаточно длинном временном отрезке или с достаточно малым депозитом возможен "слив", что приведет к стоп-ауту. Поэтому было принято решение о сэмплировании начальных состояний в рамках рабочих траекторий.
//--- Negotive i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_m].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_m].Total, 20))); if(i < 0) { iter--; continue; }
Далее мы очищаем стек модели и организовываем цикл обучения, аналогично проделанной выше работе в рамках предпочтительной траектории.
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_m].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_m].States[state].state); //--- Account description float PrevBalance = (state == 0 ? Buffer[tr_m].States[state].account[0] : Buffer[tr_m].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_m].States[state].account[1] : Buffer[tr_m].States[state - 1].account[1]); State.Add((Buffer[tr_m].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_m].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_m].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_m].States[state].account[2]); State.Add(Buffer[tr_m].States[state].account[3]); State.Add(Buffer[tr_m].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[6] / PrevBalance); //--- Time label double x = (double)Buffer[tr_m].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_m].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions)); //--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Но есть нюанс в постановке целей. Надо сказать, что здесь мы рассматриваем 2 варианта. Первый, как частный случай, когда доходность предпочтительной и второй траектории одинакова (по существу, обе траектории предпочтительные) мы используем подход аналогичный предпочтительной траектории.
//--- Study if(Buffer[tr_p].Profit == Buffer[tr_m].Profit) Result.AssignArray(Buffer[tr_m].States[state].scheduler);
Второй случай более общий, кода доходность второй траектории все таки ниже, нам предстоит оттолкнуться от нее в обратном направлении. Для этого мы выгружаем прогнозное значение и находим его отклонение от контекста отрицательной траектории из буфера воспроизведения опыта. Но здесь нам предстоит двигаться в обратном направлении. Поэтому мы не прибавляем, а отнимаем полученное отклонение от прогнозных значений. С целью повышения приоритета движения в сторону предпочтительной траектории, при расчете целевого значения я понижаю полученное отклонение в 2 раза.
else { vector<float> target, forecast; target.Assign(Buffer[tr_m].States[state].scheduler); Scheduler.getResults(forecast); target = forecast - (target - forecast) / 2; Result.AssignArray(target); }
Теперь мы можем осуществить обратный проход модели имеющимися метода для минимизации отклонения со скорректированной целью.
if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Информируем пользователя о ходе процесса обучения и переходим к следующей итерации нашей системы циклов.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", (iter + 0.5) * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После завершения всех итераций системы циклов обучения мы очищаем поле комментариев на графике. Выводим в журнал результаты процесса обучения и инициализируем процесс принудительного завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение методов советника обучения модели предпочтений "...\OPPO\StudyScheduler.mq5". С полным кодом всех его методов и функций Вы можете ознакомиться во вложении.
2.4 Обучение политики Агента
Следующим этапом мы переходим к построению советника обучения политики Агента "...\OPPO\StudyAgent.mq5". Должен признаться, что архитектура построения советника практически идентична рассмотренному выше советнику. Существуют лишь некоторые отличия именно в методе обучения модели Train. На нем мы и остановимся.
Как и ранее, в теле метода мы первым делом определяем вероятности выбора траекторий путем вызова метода GetProbTrajectories.
vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
Далее мы организовываем систему вложенных циклов обучения модели.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
На этот раз в теле внешнего цикла мы сэмплируем лишь одну траекторию. На данном этапе нам предстоит выучить политику Агента, которая способна сопоставить латентный контекст с конкретными действиями. Что сделает действия Агента более предсказуемыми и управляемыми. Поэтому мы не делим траектории на предпочтительные и нет.
Далее мы очищаем стек модели и организовываем вложенный цикл обучения модели в рамках последовательных состояний сэмплированной подтраектории.
Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
В теле цикла мы заполняем буфер исходных данных историческими данными ценового движения и показателей анализируемых индикаторов из обучающей выборки. Дополняем их данными о состоянии счета и открытых позициях.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Вносим гармоники временной метки и вектор последних действий Агента.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
И в отличии от модели предпочтений, Агенту нужен еще контекст. Его мы берем так же из буфера воспроизведения опыта.
//--- Scheduler
State.AddArray(Buffer[tr].States[state].scheduler);
Собранных данных достаточно для прямого прохода модели Агента. И мы вызываем соответствующий метод.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Как уже было сказано выше, мы обучаем политику Актера на построение зависимостей между латентным контекстом и совершаемым действием. Напомню, что это полностью соответствует целям DT. В нем мы выстраивали зависимости межу целями и действиями. Латентный контекст можно рассматривать как некоторый эмбединг цели. Форма меняется — суть остается. Следовательно, и процесс обучения аналогичный. Мы минимизируем ошибку между прогнозным и фактическим действием.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Далее нам остается проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После полного завершения процесса обучения мы очищаем поле комментариев на графике. Выводим в журнал результат обучения модели и инициализируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы заканчиваем с алгоритмом используемых в статье программ. А с полным их кодом Вы можете познакомиться во вложении. Там же Вы найдете код советника тестирования обученной модели "...\OPPO\Test.mq5", который практически полностью повторяет алгоритм советника взаимодействия с окружающей средой. В нем я лишь исключил добавления шума к действиям Агента. Что позволяет исключить фактор случайности и полностью оценить выученную политику.
3. Тестирование
Выше была проведена большая работа по реализации алгоритма Offline Preference-guided Policy Optimization (OPPO). Еще раз обращаю Ваше внимание, что в работе представлено личное видение реализации с добавлением некоторых операций, отсутствующих в описанном авторами метода алгоритме. Я не коим образом не хочу присвоить себе заслуги и труд авторов метода OPPO, но и не хочу переадресовывать в их адрес возможные своими недоработки или недопонимания их идеи.
Как всегда, обучение модели осуществляется на исторических данных инструмента EURUSD, тайм-фрейм H1 за первые 7 месяцев 2023 года. Тестирование обученных моделей было проведено на исторических данных августа 2023 года.
Ввиду изменения структуры сохранения траекторий в данной работе мы не можем использовать примеры траекторий, собранных для предыдущих работ. Поэтому в обучающую выборку были собраны полностью новые траектории.
Здесь я должен признать, что сбор 500 траекторий от новых моделей, инициализированных случайными весовыми коэффициентами, на моем ноутбуке занял 3 суток непрерывной работы. И это оказалось весьма неожиданным.
После сбора обучающей выборки я запустил параллельное обучение моделей, что стало возможно благодаря разделению процесса обучения на 2 независимых советника.
Как всегда, процесс обучения не обошелся без итерационного добора обучающей выборки с учетом обновлений моделей. Здесь я должен признать, что процесс обучения довольно устойчив и направлен. Даже при наличии только убыточных проходов в обучающей выборке метод находит возможным улучшение политики.
По моему личному наблюдению, для построения прибыльной стратегии поведения Агента просто необходимо наличие положительных проходов в обучающей выборке. А это достигается только путем исследования окружающей среды при сборе дополнительных траекторий. Так же можно воспользоваться экспертными траекториями или копированием сделок сигналов, как это было продемонстрировано в предыдущей статье. Зато появление прибыльных проходов значительно ускоряет процесс обучения моделей.
В процессе обучения мы получили модель способную генерировать прибыль как на обучающей, так и на тестовой выборке. Результаты работы модели на тестовом временном интервале представлены ниже.


Как можно заметить на представленных скриншотах, линия баланса имеет как резкие подъемы, так и падения. График баланса сложно назвать устойчивым, но при этом сохраняется общая тенденция к росту. И по итогам тестового месяца мы получили прибыль.
В целом за период тестирования было совершено 180 сделок. Почти 49% из них закрыты с прибылью. Можно сказать, что достигнут паритет прибыльных и убыточных сделок. Но благодаря 30% превышению средней прибыльная сделки над средней убыточной достигается общий рост баланса. При этом профит-фактор на тестовом историческом отрезке составил 1.25.
Заключение
В данной статье мы познакомились с еще одним довольно интересным методом обучения моделей Offline Preference-guided Policy Optimization (OPPO). Основной особенность данного метода является отказ от использования функции вознаграждения в процессе обучения моделей. Что значительно расширяет область его использования. Согласитесь, иногда бывает довольно сложно сформулировать и конкретизировать конкретную цель обучения. Еще более сложно становится оценить влияние каждого отдельного действия на конечный результат, особенно в случае разреженного ответа от окружающей среды. Или когда такой ответ поступает с некоторой задержкой. Вместо этого, представленный метод OPPO оценивает всю траекторию как единое целое, являющееся следствием отдельной политики. Таким образом, мы оцениваем не действия Агента, а его политику в конкретной среде. И принимаем решения наследовать данную политику или жен наоборот оттолкнуться от неё в противоположную сторону для поиска более оптимального решения.
В практической части данной статьи мы реализовали метод OPPO средствами MQL5, хотя и с некоторыми отступлениями от авторского метода. Тем не менее нам удалось обучить политику, способную генерировать прибыль как на обучающем историческом промежутке, так и на тестовом, выходящим за пределы обучающей выборки.
Результаты обучения и тестирования модели позволяют сделать выводы о возможности использования предложенных подходов для построения реальных торговых стратегий.
Однако напоминаю, что все программы, представленные в статье, предназначены только для демонстрации технологий и не адаптированы для работы на реальных финансовых рынках.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | StudyAgent.mq5 | Советник | Советник обучения агента |
| 3 | StudyScheduler.mq5 | Советник | Советник обучения модели предпочтений |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования