
Нейросети в трейдинге: Обобщение временных рядов без привязки к данным (Базовые модули модели)

Введение
В предыдущей статье мы познакомились с фреймворком Mamba4Cast и его базовыми компонентами: SSM‑модулем и механизмов Prior‑data Fitted Networks (PFNs). Данный фреймворк закладывает прочный фундамент для прогнозирования временных рядов и может стать мощным инструментом в арсенале трейдера.
Mamba4Cast создавался не для долгого прогрева на каждом новом временном ряде, а для мгновенного включения в работу. Благодаря идее Zero‑Shot Forecasting, модель способна сразу выдавать качественные прогнозы на реальных данных без дообучения и тонкой настройки гиперпараметров. И трейдеру больше не нужно тратить дни на подбор оптимальных параметров.
В основе высокой скорости работы модели лежит линейная сложность SSM‑модулей. В отличие от трансформеров, чья вычислительная сложность растёт квадратично с длиной ряда, каждый шаг в Mamba4Cast обрабатывается за константное время. Это обеспечивает мгновенный вывод даже для очень длинных последовательностей и минимальную задержку при инференсе. В мире, где скорость принятия решения порой решает исход сделки, это преимущество трудно переоценить.
Кроме того, Mamba4Cast сразу же выдаёт полный прогноз на весь заданный горизонт, а не генерирует его по шагам. Такой подход позволяет избежать накопления ошибок, типичных для авторегрессионных моделей, и обеспечивает более стабильные траектории будущего развития события. Торговая стратегия получает полную картину сразу, а значит можем рассчитывать на уверенные решения без лишних оговорок.
Не менее важен и метод обучения на синтетических сценариях. Модель питалась миллионами искусственно сгенерированных рядов. Благодаря этому Mamba4Cast обрела универсальную интуицию и научилась устойчиво работать в самых разных условиях. Такой подход делает её стойкой к шуму и резким изменениям. Следовательно, снижается риск неожиданных сбоев в режиме промышленной эксплуатации.
Несмотря на всю мощь фундаментальных механизмов, Mamba4Cast остаётся экономичной в плане ресурсов. Эксперименты, проведенные авторами фреймворка, показали, что при сравнимой точности с современными трансформерными фундаментальными моделями она требует заметно меньше вычислительной мощности. Это позволяет запускать её даже на ограниченных инфраструктурах и встраивать прямо в торговый терминал без необходимости в мощных GPU-кластерах.
Именно сочетание мгновенной готовности к работе, рекордной скорости вывода, целостного прогноза, устойчивости к шуму и экономичности ресурсов делает Mamba4Cast по-настоящему революционным инструментом в сфере прогнозирования временных рядов.
Авторская визуализация фреймворка Mamba4Cast представлена ниже.
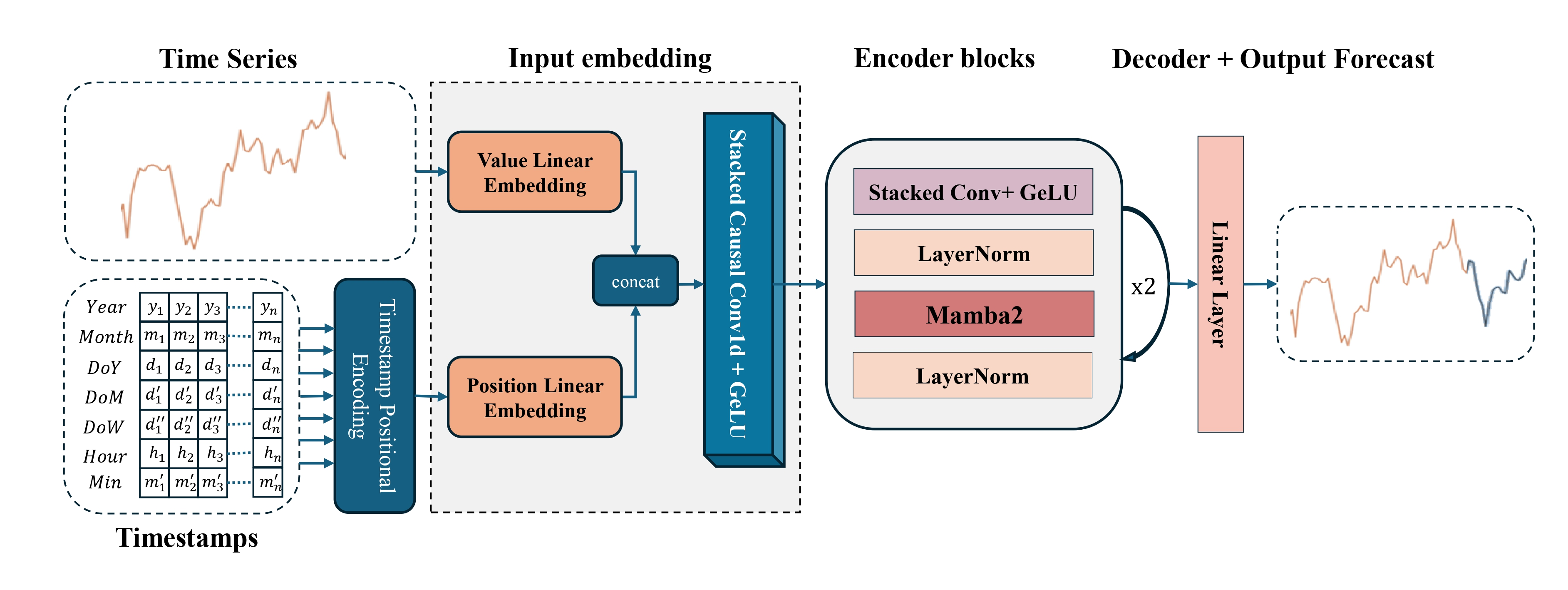
В практической части предыдущей статьи мы завершили построением объекта временного кодирования — ключевого элемента, отвечающего за позиционное представление исходных данных во временной последовательности. Этот компонент стал логичным завершением общего контура инициализации модели и важной частью архитектурной подготовки анализируемого сигнала. Без него фреймворк попросту не смог бы корректно различать временные зависимости.
Сегодня мы продолжим нашу работу именно с этого места.
Модуль предварительной обработки
Логика развития проста: прежде чем проводить какие-либо вычисления, прогнозирование движения цены и генерацию торговых сигналов, необходимо грамотно подготовить данные. Как и в любой системе машинного обучения, успех модели Mamba4Cast напрямую зависит от качества анализируемого потока данных. Если на вход поступит шум, разномасштабные значения или рваные структуры, даже самая передовая архитектура не спасёт. Поэтому в центре нашего внимания — блок предварительной обработки данных.
Этот модуль — не просто вспомогательный этап. Он служит связующим звеном между сырыми рыночными данными и аккуратными входами, которые модель способна интерпретировать. В нём происходит нормализация, масштабирование, формирование окон, работа с масками и — что особенно важно — контекстуализация данных через дополнительные каналы. Всё это подготовит анализируемую информацию к обработке внутри основной модели и задаёт фундамент, на котором строится дальнейшее прогнозирование.
Наша задача — не просто загрузить исходные данные в виде котировок и показаний анализируемых индикаторов. Мы должны привести их к единому масштабу, выявить границы полноценных окон, выделить маски недоступных значений и синхронизировать все каналы по времени. Только после этого можно передавать данные в Энкодер и рассчитывать на корректную их интерпретацию.
В практической части предыдущей статьи мы завершили построение объекта временного кодирования — одного из ключевых компонентов блока предварительной обработки данных, играющего важную роль в архитектуре Mamba4Cast. Этот элемент позволяет модели воспринимать последовательность рыночных событий не как абстрактный набор чисел, а как структурированную информацию с определённым порядком и ритмом.
Для реализации предложенного подхода, построим специализированный класс CMamba4CastEmbeding, который занимает центральное место в блоке предварительной обработки исходных данных. Структура объекта представлена ниже.
class CMamba4CastEmbeding : public CNeuronBaseOCL { protected: CNeuronConvOCL cProjection; CNeuronBatchNormOCL cNorm; CNeuronTSPositionEncoder cProjectionWithTE; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CMamba4CastEmbeding(void) {}; ~CMamba4CastEmbeding(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint &periods[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defMamba4CastEmbeding; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Основная идея заключается в преобразовании потока исходной информации в структурированный и информативный контур, пригодный для дальнейших этапов прогнозирования. Для этого применяется модульный подход — класс объединяет несколько специализированных модулей, каждый из которых отвечает за определённое преобразование данных.
Нужно отметить, что все внутренние объекты класса CMamba4CastEmbeding объявлены статически. Благодаря этому, конструктор и деструктор класса могут оставаться пустыми, поскольку не требуется управление динамической памятью — объекты создаются и уничтожаются автоматически. Такая архитектурная особенность упрощает логику жизненного цикла объекта, снижает риск утечек памяти и потенциальных ошибок, связанных с динамическим выделением памяти, что крайне важно в условиях высокопроизводительных торговых систем.
Непосредственная инициализация всех внутренних модулей осуществляется в методе Init, в параметрах которого получаем основные характеристики создаваемого объекта.
bool CMamba4CastEmbeding::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint &periods[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(periods.Size() <= 0) return false; int freqs = (int(window_out / 2 + 2 * periods.Size()) - 1) / int(2 * periods.Size()); if(freqs <= 0) return false;
В теле метода сначала проверяет наличие данных в массиве анализируемых периодов временного ряда. Это необходимо, так как временная кодировка требует наличия хотя бы одного периода для корректного расчёта. И сразу вычисляется значение параметра freqs, который представляет собой количество частотных гармоник для каждого периода.
Логика определения значения данного параметра требует отдельного пояснения. Один из параметров метода инициализации (window_out) указывает на размерность вектора эмбединга одного временного шага. Как уже упоминалось ранее, один и тот же временной срез данных должен быть представлен в двух вариантах: в виде чистого значения без учёта времени и в комбинации с временными признаками, встроенными в виде гармонических компонентов. Таким образом, итоговый эмбединг содержит в себе оба типа представления. Но объём памяти, выделяемый под это представление, у нас один. Поэтому, для кодирования временной составляющей, мы можем использовать только половину от заданного пользователем размера эмбединга. Вторая половина зарезервирована для обычной проекции исходных данных.
Теперь рассмотрим, как именно распределяется эта половина между частотными компонентами временного кодировщика. Авторы фреймворка Mamba4Cast использовали подход, близкий к позиционному кодированию в трансформерах: для каждого заданного периода создаются синусные и косинусные функции, описывающие фазу и частоту колебаний. Следовательно, на каждую частотную компоненту периода приходится по две гармоники — синусная и косинусная. Это значит, что общее количество частотных компонент должно быть, как минимум, вдвое больше количества периодов, указанных в массиве.
Чтобы избежать путаницы, формула здесь проста, но требует внимания: мы делим половину window_out на удвоенное количество заданных периодов. Полученное число показывает, сколько частотных компонент можно сгенерировать на каждый период. И это число должно быть строго больше нуля — ведь если оно окажется равным нулю, модель не сможет создать даже одну гармонику, а значит, временное кодирование просто не состоится.
На практике это означает, что при задании размера эмбединга одного временного шага нужно исходить не из желания увеличить модель, а из реальной потребности покрыть каждый из периодов хотя бы одной парой гармоник.
Далее, осуществляем вызов одноименного метода родительского класса, где уже организован процесс инициализации унаследованных объектов и интерфейсов.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units_count, optimization_type, batch)) return false;
И после успешного его выполнения переходим к поочерёдной инициализации внутренних модулей нашего класса. Первым инициализируем свёрточный слой проецирования исходных данных в компактное представление (cProjection).
int index = 0; if(!cProjection.Init(0, index, OpenCL, window, window, window_out - 2 * freqs * periods.Size(), units_count, 1, optimization, iBatch)) return false; cProjection.SetActivationFunction(TANH);
Данный объект отвечает за генерацию эмбединга исходных данных без временной составляющей. Мы используем функцию активации TANH для нелинейного преобразования данных, что помогает выделять существенные признаки, скрытые в сырых числовых потоках, и минимизировать влияние выбросов.
Слой пакетной нормализации (cNorm) корректирует полученные значения, устраняя возможные перекосы и обеспечивая устойчивость вычислений.
index++; if(!cNorm.Init(0, index, OpenCL, cProjection.Neurons(), iBatch, optimization)) return false; cNorm.SetActivationFunction(None);
Функционал генерирования эмбеддингов с учетом временной составляющей выполняет модуль временной кодировки (cProjectionWithTE), что особенно важно для прогнозирования сезонных трендов и динамических изменений в рыночном поведении.
index++; if(!cProjectionWithTE.Init(0, index, OpenCL, window, units_count, periods, freqs, optimization, iBatch)) return false; SetActivationFunction(None); //--- return true; }
В рамках логики фреймворка последовательное прохождение этапов инициализации гарантирует, что каждый подмодуль получает корректно согласованные параметры, позволяющие эффективно интегрировать временную информацию с исходными данными.
Одним из ключевых этапов работы блока CMamba4CastEmbedding является выполнение метода feedForward — механизма, обеспечивающего прямое прохождение данных через все звенья архитектуры предварительной обработки. Именно здесь формируется основа для того, чтобы последующие модули могли опираться не просто на сырые данные, а на качественно подготовленные представления, в которых уже учтены как структура исходного сигнала, так и его временной контекст.
bool CMamba4CastEmbeding::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cProjection.FeedForward(NeuronOCL)) return false;
Процесс начинается с того, что анализируемые данные направляются в модуль cProjection. Это компактный свёрточный блок, основная задача которого выполнить проецирование исходного сигнала в скрытое пространство признаков. Благодаря этому шагу система сразу фокусируется на наиболее выраженных и значимых изменениях во входном потоке.
Затем полученные признаки передаются в модуль cNorm. Это слой нормализации, который приводит значения к стабильному масштабу, устраняя скачки, выбросы и возможные перекосы в распределении.
if(!cNorm.FeedForward(cProjection.AsObject())) return false;
Без нормализации глубокие архитектуры часто начинают зашкаливать или, наоборот, терять градиент сигналов. Здесь же нормализация выполняет роль своеобразного стабилизатора, выравнивающего поведение модели в обучении и прогнозировании.
Однако особенность архитектуры Mamba4Cast заключается в следующем информационном потоке. Параллельно исходные данные передаются в cProjectionWithTE — модуль, отвечающий за временное кодирование.
if(!cProjectionWithTE.FeedForward(NeuronOCL, SecondInput)) return false;
В отличие от начального проецирования, где используются только свёртки, здесь дополнительно подключается второй вход — SecondInput. Именно через него в обработку поступают временные метки, предварительно подготовленные для каждого временного шага. Это позволяет модулю не просто опираться на значения, а учитывать в каком именно временном контексте они возникли, усиливая чувствительность модели к сезонным, циклическим и фазовым компонентам рынка.
Кульминацией этого процесса становится операция объединения. Финальные представления, полученные по двум информационным потокам, сшиваются в единый тензор путем конкатенации.
if(!Concat(cNorm.getOutput(), cProjectionWithTE.getOutput(), Output, cProjection.GetFilters(), cProjectionWithTE.GetWindowOut(), cProjection.GetUnits())) return false; //--- return true; }
Получившийся результат — это плотное, многоуровневое представление каждого временного шага, которое несёт в себе как непосредственные признаки, так и обогащённую временную структуру. И именно такое представление временной последовательности становится основой для всей последующей работы модели.
Как известно, одной только прямой передачи сигналов для обучения нейросетевой модели недостаточно. Чтобы модель могла адаптироваться к данным, необходимо организовать корректное обратное распространение ошибки. Именно эту задачу решает метод calcInputGradients. По сути, это внутренний механизм анализа ошибок, который запускается после того, как модель сформировала прогноз, и теперь должна понять, где именно допустила погрешность и как её можно скорректировать.
bool CMamba4CastEmbeding::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В первую очередь метод проверяет, с каким объектом он работает. Здесь важно убедиться, что все элементы, участвующие в вычислении градиентов, корректно инициализированы. После этой проверки в дело вступает метод DeConcat, предназначенный для декомпозиции ранее объединённого вектора градиентов на 2 информационных потока.
if(!DeConcat(cNorm.getGradient(), cProjectionWithTE.getGradient(), Gradient, cProjection.GetFilters(), cProjectionWithTE.GetWindowOut(), cProjection.GetUnits())) return false;
Напомним, на этапе прямого прохода нормализованные признаки и временные эмбеддинги были объединены в единый поток. Теперь же, чтобы обучать каждый модуль отдельно, необходимо аккуратно разъединить их, восстановив исходную структуру.
После разъединения сигналов начинается основной процесс — вычисления градиентов ошибки по двум информационным потокам до уровня исходных данных. Сначала выполняем операции с магистралью без временных меток.
if(!cProjection.calcHiddenGradients(cNorm.AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cProjection.AsObject())) return false;
Затем внимание переключается на магистраль временного контекста. Но прежде чем провести градиент ошибки нам необходимо обезопасить ранее полученные данные. С этой целью мы сначала осуществляем подмену указателя на буфер градиентов ошибки объекта исходных данных. И лишь после этого осуществляем операции определения погрешности.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cProjectionWithTE.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, cProjection.GetWindow(), false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false) ) return false; //--- return true; }
Заключительным этапом становится суммирование данных двух информационных потоков. После чего возвращаем указатели на буферы данных в исходное состояние и завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
Результатом этой отлаженной процедуры становится корректное распределение градиента ошибок по всей структуре модуля, что позволяет обеспечить сбалансированное обновление весов.
За оптимизацию весовых коэффициентов в каждом из подмодулей отвечает метод updateInputWeights. Обновление осуществляется последовательным вызовом одноименных методов внутренних объектов. Такой пошаговый порядок обновлений отражает принцип изолированного управления весами, что позволяет детально контролировать процесс обучения и вносить изменения без вмешательства в общую архитектуру системы. Если хотя бы один из этапов обновления завершится неудачей, метод возвращает ошибку, что гарантирует целостность обновлённого состояния модели.
С кодом метода updateInputWeights можно ознакомиться во вложении к статье. Там же представлен полный код класса CMamba4CastEmbeding и всех его методов.
Подводя итог, можно сказать, что класс CMamba4CastEmbeding — это не просто набор алгоритмов для преобразования данных, а изящно спроектированный модуль, в котором каждая функция тесно переплетена с общей логикой фреймворка Mamba4Cast. Он обеспечивает качественную предварительную обработку исходных данных, позволяя модели эффективно извлекать существенные признаки, учитывать временную динамику и корректно обучаться на полученных градиентах ошибки.
Энкодер
Следующим этапом нашей работы становится построение объектов Энкодера, предложенного авторами фреймворка Mamba4Cast, который играет важную роль в извлечении и структурировании признаков для дальнейшего прогнозирования. Архитектура этого блока основана на использовании стека сверточных слоев с окнами свертки разных размеров. Каждый сверточный слой фокусируется на извлечении определённых аспектов исходных данных, а их результаты затем объединяются путем конкатенации и нормализуются для дальнейшей обработки модулем Mamba. При этом, количество повторений такого блока определяется требуемой глубиной анализа, что позволяет фреймворку адаптироваться к задачам различной сложности.
Особое внимание в этом подходе привлекает стек сверточных слоев. Объект сверточного слоя уже давно реализован в нашей библиотеке, и его применение не вызывает сложностей. Однако при стандартном подходе, каждый сверточный слой создаётся, как отдельный объект, и обрабатывается последовательно. Использование объектов со свертками разного размера приводит к тому, что создается большое их количество, а последовательная обработка таких объектов значительно увеличивает вычислительную сложность модели и, соответственно, время её обучения.
Чтобы решить эту проблему, мы задумались о создании специального объекта, который сможет осуществлять обработку нескольких сверточных слоев параллельно. Такой объект позволит инициировать обработку данных на нескольких потоках одновременно, что кардинально сократит время выполнения операций. Внутри нового объекта можно будет реализовать механизмы распределения задачи: исходный сигнал будет одновременно подаваться на несколько сверточных фильтров с разными размерами окон свертки, а результаты их работы — конкатенироваться в одном тензоре. Это не только уменьшит количество промежуточных объектов, но и обеспечит более эффективное использование вычислительных ресурсов, особенно в условиях многопоточной обработки на современных GPU.
Идея не нова. Ранее мы уже реализовывали объект CNeuronMultiWindowsConvOCL, который позволял применять свёрточные операции с разными размерами окон. Но его алгоритм предусматривал наличие отдельного блока данных для каждого окна свертки. В данном же случае, мы сталкиваемся с иной задачей: необходимо обработать один и тот же поток информации с использованием разных окон свертки.
Проблема заключается в том, что изменение размера окна свертки влияет на количество возможных операций свертки. При увеличении окна свертки, число позиций, в которых можно выполнить свертку, уменьшается. Это приводит к тому, что количество потоков операций, отвечающих за вычисления с разными размерами окон свертки, оказываются несбалансированными. А это затрудняет эффективное параллельное выполнение.
Для решения этой проблемы было принято решение использовать нулевой паддинг, то есть добавление нулей в начало и конец анализируемого вектора. Такой приём позволяет растянуть вектор до нужной длины так, чтобы вне зависимости от размера окна свертки можно было использовать одинаковое количество потоков операций. Таким образом, количество операций свертки регулируется только размером шага окна свертки, который мы используем единый для всех окон, выравнивая нагрузку между параллельными потоками и значительно упрощает параллельную обработку.
Вся ключевая логика сведена на стороне OpenCL-программы в компактный, но мощный кернел FeedForwardMultWinConvWPad, который одновременно обрабатывает один и тот же входной поток через несколько свёрточных окон разной длины.
__kernel void FeedForwardMultWinConvWPad(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, __global const int *windows_in, const int inputs, const int step, const int window_out, const int activation ) { const size_t id = get_global_id(0); const size_t id_w = get_global_id(1); const size_t v = get_global_id(2); const size_t outputs = get_global_size(0); const size_t windows_total = get_global_size(1);
Каждый поток операций идентифицируется тремя координатами:
- id — индекс элемента в тензоре результатов,
- id_w — номер окна свёртки,
- v — идентификатор унитарного потока исходных данных.
Это позволяет параллельно обрабатывать несколько свёрточных окон, позиций и исходных последовательностей с различными параметрами операции.
На первом шаге кернел определяет длину текущего окна свёртки window_in, получая её из массива windows_in по идентификатору окна свертки.
int window_in = windows_in[id_w];
Далее рассчитывается смещение стартовой позицию окна свертки в буфере исходных данных в соответствии с текущим индексом элемента тензора результатов. Это смещение делается с учётом того, что центр окна должен приходиться на позицию id. Поскольку длины окон могут отличаться, применяется формула (window_in + 1) / 2, обеспечивая выравнивание центра окна.
int window_in = windows_in[id_w]; int mid_win = (window_in + 1) / 2; int shift_in = id * step - mid_win; int shift_in_var = v * inputs;
Смещение shift_in_var используется для корректной адресации нужной унитарной последовательности в глобальном массиве исходных данных.
Следующим этапом происходит вычисление shift_weight — смещения внутри глобального массива обучаемых параметров. Поскольку веса для каждого окна лежат последовательно друг за другом, с учётом их длины и bias-коэффициента, необходимо просуммировать размеры всех весовых блоков, предшествующих текущему окну id_w. Это позволяет точно определить, откуда начинаются веса для текущей свёртки.
int shift_weight = 0; for(int w = 0; w < id_w; w++) shift_weight += (windows_in[w] + 1) * window_out;
Далее запускается вложенный цикл, обрабатывающий каждый выходной канал w_out — это размерность эмбединга в буфере результатов, полученного после применения свёртки.
for(int w_out = 0; w_out < window_out; w_out++) { float sum = matrix_w[shift_weight + window_in]; //--- for(int w = 0; w < window_in; w++) if((shift_in + w) >= 0 && (shift_in + w) < inputs) sum += IsNaNOrInf(matrix_i[shift_in_var + shift_in + w] * matrix_w[shift_weight + w], 0); //--- int shift_out = (v * outputs + id) * window_out + w_out; matrix_o[shift_out] = Activation(sum, activation); shift_weight += window_in + 1; } }
Для каждого такого канала инициализируется переменная sum, которая сначала принимает значение bias (последний элемент блока весов), а затем, к ней прибавляются произведения значений исходных данных и соответствующих весов. При этом обязательно проверяется, не выходит ли текущий индекс за границы массива исходных данных. Если такое происходит — операция пропускается, что эквивалентно применению нулевого паддинга.
Когда цикл по окну завершён, результат обрабатывается функцией активации. Её тип задаётся параметром activation, а сама функция вызывается через вспомогательную обёртку Activation. Готовое значение записывается в глобальный буфер результатов matrix_o с учётом всех смещений.
Затем, указатель на блок весов shift_weight сдвигается вперёд — на величину окна плюс один (bias), чтобы перейти к весам для следующего фильтра. Таким образом, в рамках одного потока происходит последовательная обработка всех каналов, но параллельно для всех окон и всех унитарных последовательностей исходных данных.
Алгоритм получился не только гибким, но и исключительно эффективным: свёртка разных масштабов применяется к данным одновременно, обеспечивая широкое охватывающее представление с различных перспектив. Нулевой паддинг избавляет от необходимости резать данные вручную или выравнивать размерность эмбеддинга постфактум. Всё делается динамически, прямо в момент исполнения на GPU.
Подобная реализация демонстрирует ключевой принцип: высокая производительность не за счёт упрощения логики, а через разумное разделение вычислений, использование параллельной обработки и точную настройку всех этапов трансформации данных.
Следующий важный этап — расчёт градиентов ошибки на уровне исходных данных. В отличие от прямого прохода, здесь мы сталкиваемся с более сложной задачей: необходимо не просто прогнать данные через набор фильтров, но и обратным ходом собрать вклад каждого фильтра в ошибку на уровне результатов. При этом, необходимо правильно обработать смещения и сохранить согласованность формы данных.
Данный алгоритм мы реализуем в OpenCL-кернеле CalcHiddenGradientMultWinConvWPad. Его задача — агрегировать градиенты ошибки с учётом всех окон свёртки разной длины и всех выходных каналов. Иными словами, он реконструирует ошибку, восходящую обратно к исходной последовательности, учитывая нелинейность активации и структуру фильтров.
__kernel void CalcHiddenGradientMultWinConvWPad(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_ig, __global const float *matrix_og, __global const int *windows_in, const int outputs, const int step, const int window_out, const int activation ) { const size_t id_x = get_global_id(0); const size_t id_loc = get_local_id(1); const size_t id_win = id_loc / window_out; const size_t id_f = id_loc % window_out; const size_t v = get_global_id(2); const size_t inputs = get_global_size(0); const size_t size_loc = get_local_size(1); const size_t windows_total = size_loc / window_out;
Каждый поток в кернеле отвечает за один элемент градиента на уровне исходных данных:
- id_x — это индекс позиции в исходной последовательности;
- id_loc — локальный идентификатор в рабочей группе, который расщепляется на id_win (номер окна) и id_f (номер фильтра в буфере результатов);
- v — номер унитарной последовательности.
На первом этапе рассчитывается смещение shift_weight, позволяющее получить точное начало весового блока, соответствующего текущему окну и каналу. Здесь, как и ранее, приходится пройтись по всем предыдущим окнам, чтобы аккуратно просуммировать их длины и выйти на нужную позицию в глобальном массиве параметров matrix_w.
__local float temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)size_loc, (uint)LOCAL_ARRAY_SIZE); //--- int window_in = windows_in[id_win]; int shift_weight = id_f * (window_in + 1); for(int w = 0; w < id_win; w++) shift_weight += (windows_in[w] + 1) * window_out;
После этого, мы определяем диапазон в буфере результатов, в котором анализируемый элемент исходных данных мог участвовать — shift_out. Это значение ограничивается снизу нулём и рассчитывается как максимально возможный выход, при котором окно всё ещё может захватывать позицию id_x.
int shift_out = max((int)((id_x - window_in) / step), 0);
Но этого недостаточно — дальше запускается цикл по всем возможным выходам out, в которых наш элемент мог участвовать в прямом проходе.
float grad = 0; int mid_win = (window_in + 1) / 2; for(int out = shift_out; out < outputs; out++) { int shift_in = out * step - mid_win; if(shift_in > id_x) break; int shift_w = id_x - shift_in; if(shift_w >= window_in) continue; int shift_g = ((v * outputs + out) * windows_total + id_win) * window_out + id_f; grad += IsNaNOrInf(matrix_w[shift_w + shift_weight] * matrix_og[shift_g], 0); }
При каждой итерации этого цикла проверяется, входит ли id_x в текущее окно. Если да, то вычисляется локальное смещение shift_w внутри окна и позиция нужного выходного градиента shift_g. Умножив соответствующий вес на градиент ошибки выхода matrix_og, мы получаем вклад этой свёртки в ошибку анализируемого элемента. Все такие вклады аккумулируются в переменной grad.
На этом этапе мы имеем частный градиент по каждому потоку. Однако нужно учесть, что внутри рабочей группы могут быть несколько потоков, отвечающих за тот же id_x, но разные фильтры и каналы. Поэтому вводится промежуточный массив в локальной памяти temp, и запускается цикл суммирования с барьерами синхронизации. Сначала каждый поток пишет своё значение в temp.
for(int i = 0; i < size_loc; i += ls) { if(i <= id_loc && (i + ls) > id_loc) temp[id_loc % ls] = (i == 0 ? 0 : temp[id_loc % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); }
Затем, с помощью параллельного редукционного свёртывания, массив суммируется по степеням двойки, оставляя в temp[0] итоговый градиент по всем каналам и окнам.
uint count = ls; do { count = (count + 1) / 2; if(id_loc < count && (id_loc + count) < ls) { temp[id_loc] += temp[id_loc + count]; temp[id_loc + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Наконец, только поток с id_loc == 0 записывает итоговое значение градиента ошибки в глобальный массив matrix_ig. Но перед этим вызывается функция Deactivation, которая применяет производную функции активации к значению входа matrix_i. Это важно: градиент должен быть откорректирован с учётом формы активации, иначе обучение будет некорректным.
if(id_loc == 0) matrix_ig[v * inputs + id_x] = Deactivation(temp[0], matrix_i[v * inputs + id_x], activation); }
Это один из самых трудоёмких участков обратного прохода. Благодаря разделению вычислений по окнам и каналам, а так же использованию локальной памяти, достигается высокая эффективность даже при большом количестве параметров. В совокупности с прямым проходом, этот этап делает наш алгоритм не просто модульным и масштабируемым, но и способным обрабатывать очень сложные зависимости в финансовых временных рядах, не теряя в точности и производительности.
Финальный аккорд свёрточной симфонии — обновление весов. На этом этапе мы переводим вычисленные градиенты в реальные изменения параметров модели. Причём, делаем это не абы как, а по классике оптимизации — методом Adam, дополненный сдвигами для свёрток с окнами разной ширины и учётом нулевого паддинга. Кернел UpdateWeightsMultWinConvAdamWPad аккуратно воплощает всю эту механику.
__kernel void UpdateWeightsMultWinConvAdamWPad(__global float *matrix_w, __global const float *matrix_og, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, __global const int *windows_in, const int windows_total, const int window_out, const int inputs, const int step, const int outputs, const float l, const float b1, const float b2 ) { const size_t i = get_global_id(0); // weight shift const size_t v = get_local_id(1); // variable const size_t variables = get_local_size(1);
Каждый поток в этом кернеле отвечает за обновление одного конкретного параметра i — будь то коэффициент фильтра или bias (смещение). Переменная v здесь — индекс унитарной последовательности, а variables — общее их количество. Они участвуют в суммировании градиентов по всему потоку исходных данных, чтобы итоговое обновление было более стабильным.
В самом начале поток должен выяснить, к какому фильтру, какому выходному каналу и какому конкретно весу относится его индекс i. Это делается через цикл по всем окнам, где с помощью аккуратного счётчика shift_before отслеживается смещение каждого окна в линейном массиве обучаемых параметров.
__local float temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)variables, (uint)LOCAL_ARRAY_SIZE); //--- int step_out = window_out * windows_total; //--- int shift_before = 0; int window = 0; int number_w = 0; for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; if(shift_before <= i && (win + 1)*window_out > (i - shift_before)) { window = win; number_w = w; } else shift_before += (win + 1) * window_out; }
Как только находим, к какому окну относится индекс i, определяем:
- window — ширина окна фильтра;
- number_w — номер окна;
- id_f — номер фильтра;
- shift_in — смещение относительно начала окна (если оно равно размеру окна, то значит это bias);
- bias — логический флаг, определяющий, является ли анализируемый элемент параметром смещения.
int shift_in = (i - shift_before) % (window + 1); int shift_in_var = v * inputs; bool bias = (shift_in == window); int mid_win = (window + 1) / 2; int id_f = (i - shift_before) / (window + 1); int shift_out = number_w * window_out + id_f; int shift_out_var = v * outputs * step_out;
В случае обычного фильтрующего коэффициента, запускается цикл по всем выходам out. В каждом выходе мы проверяем, попадает ли соответствующая входная позиция в границы допустимых данных. Если да — производим стандартную процедуру: умножаем соответствующий выходной градиент matrix_og на входной сигнал matrix_i, аккумулируя произведения в grad.
float grad = 0; if(!bias) { for(int out = 0; out < outputs; out++) { int in = out * step - mid_win + shift_in; if(in >= inputs) break; if(in < 0) continue; //--- grad += IsNaNOrInf(matrix_og[shift_out_var + shift_out + out * step_out] * matrix_i[shift_in_var + in], 0); } } else { for(int out = 0; out < outputs; out++) grad += IsNaNOrInf(matrix_og[shift_out_var + shift_out + out * step_out], 0); }
Если же это параметр смещения, то исходные данные в расчёт не идут. Достаточно просто просуммировать градиенты на уровне результатов по всем позициям.
Дальше — знакомый приём: локальное суммирование через массив temp. Цель — аккумулировать градиенты по всем унитарным последовательностям и сократить влияние выбросов. Опять-таки, используется редукционное дерево с барьерами, чтобы корректно просуммировать значения внутри рабочей группы. И только поток с v == 0 (первый по счёту) выполняет финальное обновление веса.
//--- sum for(int s = 0; s < (int)variables; s += ls) { if(v >= s && v < (s + ls)) temp[v % ls] = (s == 0 ? 0 : temp[v % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); } //--- uint count = ls; do { count = (count + 1) / 2; if(v < count && (v + count) < ls) { temp[v] += temp[v + count]; temp[v + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Здесь и вступает в силу алгоритм Adam:
- Обновляется первая моментная оценка градиента mt — с экспоненциальным сглаживанием через коэффициент b1.
- Обновляется вторая моментная оценка vt — оценка дисперсии градиента с коэффициентом b2.
- Вес обновляется через нормализацию mt / sqrt(vt) и масштабируется коэффициентом скорости обучения l.
- Все значения принудительно ограничиваются с помощью clamp, чтобы избежать разлёта весов и деления на ноль.
if(v == 0) { grad = temp[0]; float mt = IsNaNOrInf(clamp(b1 * matrix_m[i] + (1 - b1) * grad, -1.0e5f, 1.0e5f), 0); float vt = IsNaNOrInf(clamp(b2 * matrix_v[i] + (1 - b2) * pow(grad, 2), 1.0e-6f, 1.0e6f), 1.0e-6f); float weight = clamp(matrix_w[i] + IsNaNOrInf(l * mt / sqrt(vt), 0), -MAX_WEIGHT, MAX_WEIGHT); matrix_w[i] = weight; matrix_m[i] = mt; matrix_v[i] = vt; } }
В финале обновлённые значения сохраняются обратно в глобальную память.
В совокупности с двумя предыдущими этапами (прямым проходом и обратным распространением ошибки) — этот механизм делает свёрточный блок полностью самодостаточным, дифференцируемым и пригодным для обучения в глубокой нейросетевой архитектуре. И, что особенно важно, он масштабируем и легко адаптируется к произвольному количеству окон и каналов. Это даёт модели уникальную гибкость в работе с реальными, нелинейными, нестационарными временными рядами.
На стороне основной программы весь функционал многоканальной свёртки с нулевым паддингом инкапсулирован в классе CNeuronMultiWindowsConvWPadOCL. Этот модуль наследуется от объекта базового сверточного слоя CNeuronConvOCL и служит интерфейсом для постановки в очередь всех описанных выше OpenCL-кернелов.
Структура класса представлена ниже.
class CNeuronMultiWindowsConvWPadOCL : public CNeuronConvOCL { protected: int aiWindows[]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronMultiWindowsConvWPadOCL(void) { activation = SoftPlus; iWindow = -1; } ~CNeuronMultiWindowsConvWPadOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMultiWindowsConvWPadOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); //--- virtual uint GetWindow(void) const { return aiWindows[0]; } virtual uint GetWindowsSize(void) const { return aiWindows.Size(); } virtual uint GetWindowOut(void) const { return iWindowOut; } virtual uint GetUnits(void) const { return Neurons()/(iVariables*GetWindowsSize()*iWindowOut); } };
Данный класс скрывает все сложности взаимодействия с OpenCL и позволяет без труда подключать блок мультиразмерной свертки в общую архитектуру модели. Полный исходный код класса вместе с реализацией всех методов доступен во вложении к статье и предназначен для самостоятельного изучения читателем.
К сожалению, формат статьи имеет свои пределы. И мы исчерпали доступный объем. Эффективность реализованных подходов мы оценим в следующей статье.
Заключение
В данной статье мы продолжили развитие реализацию подходов, предложенных авторами фреймворка Mamba4Cast. И сконцентрировались на двух краеугольных модулях: эмбеддинге исходных данных с учётом временного кодирования и многоканальной свёртке с нулевым паддингом. Объект CMamba4CastEmbedding показал, как в одном блоке объединить проекцию сырых данных и гармонический код временных меток. А OpenCL‑кернелы FeedForwardMultWinConvWPad, CalcHiddenGradientMultWinConvWPad и UpdateWeightsMultWinConvAdamWPad продемонстрировали, как эффективно реализовать параллельную обработку одновременно несколькими окнами свертки и обеспечить полную дифференцируемость во время обучения.
Мы уделили особое внимание не только производительности — тонкая настройка смещений, балансировка нагрузки между потоками и аккуратная агрегация градиентов через локальные редукции сделали свёрточный блок по‑настоящему масштабируемым инструментом. При этом вся логика остаётся прозрачной: класс CNeuronMultiWindowsConvWPadOCL инкапсулирует детали взаимодействия с OpenCL и позволяет легко подключать реализованные решения в любую модель.
В следующей статье мы соберём все разработанные компоненты в единую модель, запустим её обучение на реальных исторических данных и оценим эффективность реализованных подходов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 4 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования