
Desenvolvendo um EA multimoeda (Parte 26): Informador para instrumentos de negociação
Conteúdo
- Introdução
- Traçando o caminho
- Criação do projeto
- Repositório da parte da biblioteca
- Repositório do projeto
- Descrição do projeto
- Criando a primeira versão
- Testando o EA
- Considerações finais
Introdução
No artigo anterior, alcançamos finalmente o que já pode ser chamado de um sistema completo, capaz de organizar a geração automática, a partir de uma simples estratégia de negociação, de um EA completo que viabilize a execução paralela dessa estratégia em diferentes instrumentos e timeframes. Também foram abordadas questões relacionadas ao sistema de gerenciamento de capital e ao gerenciador de risco, que permite interromper a negociação diante de situações desfavoráveis ou, ao contrário, excessivamente favoráveis.
Durante quase todo o ciclo, trabalhamos com apenas uma estratégia de negociação simples, e somente nas últimas partes — quando as principais funcionalidades já haviam sido implementadas — é que analisamos o processo de adição de uma nova estratégia de negociação e sua utilização como principal. Esse exemplo demonstrou a possibilidade de tentar explorar o potencial de praticamente qualquer estratégia de negociação (se é que esse potencial realmente existe).
Mas ao atingir esse novo patamar, abre-se um campo ainda mais vasto para o trabalho futuro. As possibilidades são muitas, e escolher a próxima direção a seguir não é nada fácil. Para enfrentar isso, foi feita uma tentativa de mudar a abordagem de organização e armazenamento dos códigos-fonte deste projeto. Os primeiros passos foram dados já na Parte 23, onde separamos a maioria do código na chamada "parte da biblioteca", deixando o restante na "parte do projeto". Em seguida, voltamos nossa atenção para os recursos do novo repositório de código, apresentando os primeiros passos em um artigo separado Migrando para o MQL5 Algo Forge (Parte 1): Criando o repositório principal. Por ora, a estratégia de uso do novo repositório continua em fase de consolidação. De modo geral, a ideia é viabilizar o trabalho paralelo na parte da biblioteca em várias frentes ao mesmo tempo. Até que ponto isso será possível, veremos mais adiante.
Para isso, é preciso prática. Só assim é possível entender se as decisões arquiteturais tomadas foram de fato boas. Por isso, vamos praticar criando um novo projeto que utilize a biblioteca já desenvolvida, chamada Advisor. Não vamos começar logo com um grande projeto de desenvolvimento de EA baseado em alguma estratégia de negociação complexa. Na verdade, faremos o oposto. Vamos criar um projeto que nem mesmo tenha como objetivo o desenvolvimento de um EA de negociação.
Traçando o caminho
Um dos leitores levantou uma questão interessante relacionada à última estratégia adicionada, a SimpleCandles. Nessa estratégia, um dos parâmetros é a quantidade de velas consecutivas na mesma direção, dentro de um determinado timeframe. Por isso, seria útil termos uma forma de visualizar quais séries desse tipo de velas ocorrem em diferentes instrumentos e timeframes, para não deixarmos todo o trabalho de ajuste dos valores ideais apenas a cargo do otimizador.
De fato, mesmo para a otimização automática, ainda é necessário entender em que intervalo os parâmetros de entrada irão variar. É claro que se pode simplesmente definir um intervalo amplo, mas isso provavelmente reduzirá a eficiência da otimização. Afinal, o número total de combinações de parâmetros será maior, e a chance de encontrar uma combinação bem-sucedida será menor. É difícil dizer o quanto menor, mas só o entendimento básico dessa perda já é suficiente para nos motivar a buscar formas de aumentar a eficiência.
Além disso, reunir esse tipo de informação sobre o comportamento dos preços dos diferentes instrumentos ajudará a responder à seguinte pergunta: "É possível usar os mesmos intervalos de parâmetros para diferentes instrumentos?" Se a resposta for sim, isso facilita a organização da primeira etapa da otimização. Caso contrário, será necessário tornar um pouco mais complexo o processo de criação das tarefas de otimização nessa fase.
Resumindo, vamos tentar criar um EA auxiliar — ou uma parte de um EA — que nos permita exibir algum tipo de estatística por símbolo e timeframe. Pode ser que isso venha a ser útil futuramente, inclusive dentro das estratégias de negociação.
Mas essa é uma questão secundária. A primeira, com a qual vamos começar, é: como organizar o armazenamento do código-fonte de modo que ele possa ser reutilizado posteriormente em outros projetos.
Criação do projeto
À primeira vista, parece: o que poderia haver de complicado nisso? Já armazenamos o código de alguma forma no passado, por que não continuar do mesmo jeito? Mas há, sim, uma diferença. Uma coisa é manter todo o código do projeto em uma única pasta, e para cada novo projeto simplesmente criar uma nova pasta, copiando para ela o código do projeto anterior. Essa abordagem tem a vantagem da simplicidade e faz sentido em um processo de desenvolvimento estritamente sequencial, sem a necessidade de se preocupar com compatibilidade retroativa. Na fase inicial, quando as mudanças significativas ainda são frequentes, essa abordagem é muito mais conveniente. Mas é outra história quando o projeto começa a crescer, e já conseguimos identificar claramente partes distintas: algumas que não sofrerão alterações (ou serão modificadas raramente), e outras que poderão mudar significativamente ou até mesmo surgir do zero.
Nesse cenário, os pontos negativos de manter todo o código em uma única pasta, na nossa visão, começam a superar os positivos. Em um momento anterior, já havíamos movido a maior parte do código para a pasta MQL5/Include/antekov/Advisor, chamando esse conjunto de "parte da biblioteca". Mas agora, essa estrutura de localização para a parte da biblioteca não nos parece mais tão conveniente.
Vamos imaginar que dois projetos estão sendo desenvolvidos paralelamente, ambos utilizando a biblioteca Advisor. Em geral, as alterações afetam a parte do projeto, mas eventualmente alguns ajustes são feitos também na parte da biblioteca. Se os dois projetos fizerem referência à mesma instância da biblioteca, localizada no mesmo diretório (MQL5/Include/antekov/Advisor), é bem provável que surjam conflitos. Para evitá-los, ao alternar de um projeto para outro, seria necessário, no mínimo, trocar a versão da biblioteca para aquela correspondente, armazenada em outro branch do repositório. Embora isso não seja algo complicado, esse tipo de manipulação não é desejável. Pode-se acabar esquecendo de trocar o branch, e então ter que limpar alterações feitas no branch errado, transferindo-as para o correto.
Por isso, vamos tentar uma abordagem diferente. Cada projeto será um repositório separado. Dentro da pasta do projeto, haverá obrigatoriamente uma pasta Include, onde ficarão as subpastas com as partes da biblioteca. Atenção: não apenas uma parte da biblioteca, mas várias, organizadas em pastas distintas. Cada parte da biblioteca será um clone de um repositório de código separado.
Repositório da parte da biblioteca
Para a parte da biblioteca, criaremos um novo repositório no MQL5 Algo Forge ou em qualquer outro repositório GIT público. O nome Advisor, que usamos até agora para a biblioteca, nos pareceu genérico demais. Vamos torná-lo mais único, renomeando-a para Adwizard. É assim que passaremos a nos referir à nossa biblioteca daqui em diante.
Neste repositório, colocaremos todos os arquivos da parte da biblioteca. Ao criar o repositório, ele conterá apenas um branch com o nome main. Criamos um novo branch chamado develop, a partir do qual serão criadas branches para os artigos e para os novos recursos da biblioteca. Esses branches auxiliares serão encerrados após a implementação dos novos recursos, e as modificações serão incorporadas ao branch develop e, em seguida, ao main. Em geral, isso ocorrerá após a finalização do trabalho de mais um artigo.
Para garantir o funcionamento do código nesse repositório, ao cloná-lo para qualquer pasta, foi necessário fazer pequenos ajustes em alguns arquivos da biblioteca. As correções foram necessárias nos pontos em que, nas diretivas de inclusão #include, usávamos caminhos que levavam à pasta Include da biblioteca padrão. Após substituí-los por caminhos relativos, eliminamos a dependência de um local fixo da biblioteca dentro de MQL5/Include/antekov/Advisor.
Por exemplo, no arquivo Optimization.mqh, foi feita uma substituição como esta:
#include <antekov/Advisor/Optimization/Optimizer.mqh> #include "../Optimization/Optimizer.mqh"
No arquivo OptimizerTask.mqh, ainda utilizávamos um único arquivo de uma biblioteca externa do fxsaber. Esse arquivo também foi transferido para dentro da biblioteca, na pasta Utils:
#include <antekov/Advisor/Database/Database.mqh> #include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132 #include "../Database/Database.mqh" #include "../Utils/MTTester.mqh" // https://www.mql5.com/ru/code/26132
Essas alterações foram enviadas para o repositório da biblioteca.
Repositório do projeto
Para o projeto, criamos um novo repositório chamado SymbolsInformer. Nele, além da branch principal main, também criamos uma branch de desenvolvimento chamada develop. Caso esse projeto venha a ser abordado em vários artigos, o ideal é que as modificações relacionadas a artigos distintos sejam separadas em branches diferentes. Essas branches derivarão de develop e serão posteriormente mescladas de volta em develop e main , conforme forem finalizadas.
Criamos uma pasta para armazenar o diretório do projeto, por exemplo: MQL5/Experts/Article/17606. Clonamos o repositório para essa pasta escolhida e, dentro dela, criamos a pasta Include. Nessa pasta, vamos colocar os repositórios das outras bibliotecas das quais este projeto dependerá. Por enquanto, será apenas uma: a biblioteca Adwizard. Clonamos o repositório da biblioteca Adwizard dentro da pasta Include . Caso fosse necessária alguma outra biblioteca, ela também seria clonada nesta mesma pasta Include.
Após essas operações, teremos uma estrutura de pastas no diretório do terminal mais ou menos assim:
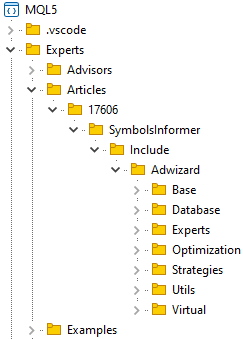
Na pasta clonada do repositório Adwizard, vamos alternar para o branch develop. Esse será o branch comum a todos os artigos. Se, durante o desenvolvimento deste projeto, não houver necessidade de alterar a biblioteca Adwizard, permaneceremos no branch develop, atualizando-o apenas quando surgirem novas alterações feitas em outros artigos. Se, por outro lado, for preciso fazer alguma modificação na biblioteca relacionada ao trabalho atual, então criaremos um novo branch.
Em seguida, no repositório do projeto, criamos um branch específico para o desenvolvimento do artigo atual e começamos a trabalhar nele. Aqui fornecemos uma descrição resumida do processo de criação de um novo projeto; uma explicação mais detalhada será abordada em um artigo separado.
Descrição do projeto
Vamos tentar formular uma especificação técnica resumida para o desenvolvimento da ferramenta desejada. Ela será implementada na forma de um EA, já que não haverá parâmetros de cálculo que exijam recálculo periódico e exibição de valores variáveis ao longo do tempo.
Antes de tudo, para contar a quantidade de séries de velas consecutivas na mesma direção, precisamos definir um certo intervalo de tempo no qual coletaremos essa estatística. Isso pode ser feito de várias formas. Por exemplo, é possível definir uma quantidade de dias a partir da data atual, ou estabelecer duas datas distintas, indicando início e fim. Inicialmente, faremos apenas o cálculo da estatística para um intervalo que começa a partir da data atual. A duração será determinada pela escolha de um timeframe (por exemplo, diário) e uma quantidade de velas desse timeframe. Vamos chamá-lo de timeframe principal.
Depois, será necessário indicar para quais instrumentos de negociação (símbolos) e quais timeframes desejamos realizar os cálculos. Claro, poderíamos limitar os cálculos apenas ao símbolo e timeframe no qual o EA estiver sendo executado. Mas é melhor desde já prever a possibilidade de realizar os cálculos para vários símbolos e vários timeframes.
Com base nisso, elaboramos a lista de parâmetros de entrada do EA:
- Timeframe principal
- Quantidade de velas do timeframe principal
- Lista de símbolos
- Lista de timeframes
Esse conjunto de parâmetros poderá ser ampliado no futuro. As listas de símbolos e timeframes conterão seus nomes separados por vírgulas. Os nomes dos timeframes serão definidos conforme aparecem no terminal, por exemplo: M5, M15, H1 e assim por diante.
Para cada símbolo e timeframe, vamos calcular os seguintes valores:
- Tamanhos médios das velas:
- bullish ("vela para cima" ou "buy", cuja cotação de fechamento não é inferior à de abertura);
- bearish ("vela para baixo" ou "sell", cuja cotação de fechamento não é superior à de abertura);
- todas (tanto bullish quanto bearish);
- Comprimento médio da série (série será considerada uma sequência de duas ou mais velas consecutivas com a mesma direção);
- Quantidade de séries com comprimento
- 2
- 3
- ...
- 8
- 9
Essa lista também é aberta, ou seja, podemos adicionar novos valores calculados conforme desejarmos.
Criando a primeira versão
Para começar, vamos desenvolver a versão mais simples possível. Os valores calculados serão armazenados em arrays globais, e os resultados serão exibidos de alguma forma no log e no gráfico, como comentário. Ainda não sabemos exatamente quais dados nos serão úteis e quais serão irrelevantes. Portanto, essa primeira versão servirá principalmente para determinar o que realmente precisamos. Nela, não daremos muita atenção à verificação da consistência dos parâmetros de entrada nem à organização do armazenamento das informações.
Os parâmetros de entrada, conforme a lista elaborada, podem ser definidos da seguinte forma:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Calculation period" sinput ENUM_TIMEFRAMES mainTimeframe_ = PERIOD_D1; // Main timeframe input int mainLength_ = 30; // Number of candles on the main timeframe input group "::: Symbols and timeframes " sinput string symbols_ = ""; // Symbols (comma separated) sinput string timeframes_ = ""; // Timeframes (e.g. M5, H1, H4)
Como nos parâmetros de entrada os símbolos e timeframes são especificados múltiplos por linha, vamos precisar de arrays que armazenem individualmente cada nome de símbolo e de timeframe.
Para armazenar os valores calculados, criaremos arrays bidimensionais. O primeiro índice estará associado ao símbolo, e o segundo, ao timeframe. Como ao declarar arrays bidimensionais é obrigatório especificar a quantidade de elementos no segundo índice, vamos definir uma constante chamada TFN, na qual indicaremos a quantidade total de timeframes padrão existentes no momento. Foram identificados 21.
// Number of existing timeframes #define TFN (21) // Global variables string g_symbols[]; // Array of all used symbols ENUM_TIMEFRAMES g_timeframes[]; // Array of all used timeframes // Arrays of calculated values. // The first index is a symbol, the second index is a timeframe double symbolAvrCandleSizes[][TFN]; // Array of average sizes of all candles double symbolAvrBuyCandleSizes[][TFN]; // Array of average sizes of bullish candles double symbolAvrSellCandleSizes[][TFN]; // Array of average sizes of bearish candles double symbolAvrSeriesLength[][TFN]; // Array of average series lengths int symbolCountSeries2[][TFN]; // Array of the number of series of length 2 int symbolCountSeries3[][TFN]; // Array of the number of series of length 3 int symbolCountSeries4[][TFN]; // Array of the number of series of length 4 int symbolCountSeries5[][TFN]; // Array of the number of series of length 5 int symbolCountSeries6[][TFN]; // Array of the number of series of length 6 int symbolCountSeries7[][TFN]; // Array of the number of series of length 7 int symbolCountSeries8[][TFN]; // Array of the number of series of length 8 int symbolCountSeries9[][TFN]; // Array of the number of series of length 9
Para fazer conversões entre as constantes simbólicas dos timeframes (do tipo ENUM_TIMEFRAMES), seus nomes em string e os índices nos arrays de timeframes, criaremos funções auxiliares. Com elas, poderemos resolver três tarefas:
- obter a constante simbólica a partir do nome em string (StringToTimeframe)
- obter o nome do timeframe (sem o prefixo "PERIOD_") a partir da constante simbólica (TimeframeToString)
- obter o índice no array de timeframes a partir da constante simbólica (TimeframeToIndex)
// Array of all timeframes ENUM_TIMEFRAMES tfValues[] = { PERIOD_M1, PERIOD_M2, PERIOD_M3, PERIOD_M4, PERIOD_M5, PERIOD_M6, PERIOD_M10, PERIOD_M12, PERIOD_M15, PERIOD_M20, PERIOD_M30, PERIOD_H1, PERIOD_H2, PERIOD_H3, PERIOD_H4, PERIOD_H6, PERIOD_H8, PERIOD_H12, PERIOD_D1, PERIOD_W1, PERIOD_MN1 }; //+------------------------------------------------------------------+ //| Convert a string name to a timeframe | //+------------------------------------------------------------------+ ENUM_TIMEFRAMES StringToTimeframe(string s) { // If the string contains the "_" symbol, leave only the characters that follow it int pos = StringFind(s, "_"); if(pos != -1) { s = StringSubstr(s, pos + 1); } // Convert to uppercase StringToUpper(s); // Arrays of corresponding string names of timeframes string keys[] = {"M1", "M2", "M3", "M4", "M5", "M6", "M10", "M12", "M15", "M20", "M30", "H1", "H2", "H3", "H4", "H6", "H8", "H12", "D1", "W1", "MN1" }; // Search for a match and return it if found FOREACH(keys) { if(keys[i] == s) return tfValues[i]; } return PERIOD_CURRENT; } //+------------------------------------------------------------------+ //| Convert a timeframe to a string name | //+------------------------------------------------------------------+ string TimeframeToString(ENUM_TIMEFRAMES tf) { // Get the timeframe name of the 'PERIOD_*' type string s = EnumToString(tf); // Return the part of the name after the '_' symbol return StringSubstr(s, StringFind(s, "_") + 1); } //+------------------------------------------------------------------+ //| Convert a timeframe to an index in an array of all timeframes | //+------------------------------------------------------------------+ int TimeframeToIndex(ENUM_TIMEFRAMES tf) { // Search for a match and return it if found FOREACH(tfValues) { if(tfValues[i] == tf) return i; } return WRONG_VALUE; }
O cálculo de todos os valores será feito dentro da função Calculate(). Nela, vamos organizar um laço duplo que percorre todas as combinações possíveis de símbolos e timeframes. Em cada iteração, verificaremos se um novo candle se formou especificamente para aquele símbolo e timeframe. Se sim, chamaremos as funções auxiliares de cálculo. Também será possível passar, por meio do parâmetro force , uma instrução para forçar o cálculo imediato de todos os valores, sem aguardar a formação de um novo candle. Esse modo será utilizado na inicialização do EA, para que possamos ver os resultados imediatamente.
//+------------------------------------------------------------------+ //| Calculate all values | //+------------------------------------------------------------------+ void Calculate(bool force = false) { string symbol; ENUM_TIMEFRAMES tf; // For each symbol and timeframe FOREACH_AS(g_symbols, symbol) { FOREACH_AS(g_timeframes, tf) { // If a new bar has arrived for the given symbol and timeframe, then if(IsNewBar(symbol, tf) || force) { // Find the number of candles for calculation int n = PeriodSeconds(mainTimeframe_) * mainLength_ / PeriodSeconds(tf); // Calculate the average candle sizes CalculateAvrSizes(symbol, tf, n); // Calculate the lengths of candlestick series CalculateSeries(symbol, tf, n); } } } }
Os cálculos propriamente ditos foram organizados em duas funções auxiliares. Cada uma realiza o cálculo para apenas um símbolo e um timeframe. Além desses dois parâmetros, também passamos um terceiro: a quantidade de velas sobre a qual será feito o cálculo.
O cálculo dos tamanhos médios das velas é feito na função CalculateAvrSizes(). No início, usamos o nome do símbolo e o timeframe para determinar os índices s e t do elemento correspondente nos arrays bidimensionais onde os resultados serão armazenados. Velas cuja cotação de abertura seja igual à de fechamento serão consideradas tanto como velas para cima quanto para baixo. Os valores médios calculados serão arredondados para o número inteiro mais próximo em pontos.
//+------------------------------------------------------------------+ //| Calculate average candle sizes | //+------------------------------------------------------------------+ void CalculateAvrSizes(string symbol, ENUM_TIMEFRAMES tf, int n) { // Find the index used for the desired symbol int s; FIND(g_symbols, symbol, s); // Find the index used for the desired timeframe int t = TimeframeToIndex(tf); // Array for candles MqlRates rates[]; // Copy the required number of candles into the array int res = CopyRates(symbol, tf, 1, n, rates); // If everything was copied, then if(res == n) { // Number of up and down candles int nBuy = 0, nSell = 0; // Zero out the elements for the calculated average values symbolAvrCandleSizes[s][t] = 0; symbolAvrBuyCandleSizes[s][t] = 0; symbolAvrSellCandleSizes[s][t] = 0; // For all candles FOREACH(rates) { // Find the candle size double size = rates[i].high - rates[i].low; // Add it to the total size of all candles symbolAvrCandleSizes[s][t] += size; // If this is a bullish candle, then we take it into account if(IsBuyRate(rates[i])) { symbolAvrBuyCandleSizes[s][t] += size; nBuy++; } // If this is a downward candle, take it into account if(IsSellRate(rates[i])) { symbolAvrSellCandleSizes[s][t] += size; nSell++; } } // Get the size of one point for a symbol double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Find the average values in points symbolAvrCandleSizes[s][t] /= n * point; symbolAvrBuyCandleSizes[s][t] /= nBuy * point; symbolAvrSellCandleSizes[s][t] /= nSell * point; // Round them to whole points symbolAvrCandleSizes[s][t] = MathRound(symbolAvrCandleSizes[s][t]); symbolAvrBuyCandleSizes[s][t] = MathRound(symbolAvrBuyCandleSizes[s][t]); symbolAvrSellCandleSizes[s][t] = MathRound(symbolAvrSellCandleSizes[s][t]); } }
O cálculo dos comprimentos das séries é feito de forma semelhante na função CalculateSeries(). Nela, é utilizado um array auxiliar chamado seriesLens, com 100 elementos. O índice de cada elemento desse array corresponde ao comprimento da série, e o valor do elemento indica a quantidade de séries com esse comprimento. Assim, estamos assumindo que a imensa maioria das séries terá menos de cem velas. Na prática, exibiremos apenas a quantidade de séries com comprimento inferior a 10 velas. No final da função, os valores correspondentes a essas séries são transferidos do array seriesLens para os elementos apropriados dos arrays de resultados, com nomes do tipo symbolCountSeries*.
//+------------------------------------------------------------------+ //| Calculate the lengths of candlestick series | //+------------------------------------------------------------------+ void CalculateSeries(string symbol, ENUM_TIMEFRAMES tf, int n) { // Find the index used for the desired symbol int s; FIND(g_symbols, symbol, s); // Find the index used for the desired timeframe int t = TimeframeToIndex(tf); // Array for candles MqlRates rates[]; // Copy the required number of candles into the array int res = CopyRates(symbol, tf, 1, n, rates); // If everything was copied, then if(res == n) { // Current series length int curLen = 0; // Direction of the previous candle bool prevIsBuy = false; bool prevIsSell = false; // Array of numbers of series of different lengths (index = series length) int seriesLens[]; // Set the size and initialize ArrayResize(seriesLens, 100); ArrayInitialize(seriesLens, 0); // For all candles FOREACH(rates) { // Determine the candle direction bool isBuy = IsBuyRate(rates[i]); bool isSell = IsSellRate(rates[i]); // If the direction is the same as the previous one, then if((isBuy && prevIsBuy) || (isSell && prevIsSell)) { // Increase the series length curLen++; } else { // Otherwise, if the length is within the required range, then if(curLen > 1 && curLen < 100) { // Increase the counter of the length series seriesLens[curLen]++; } // Reset the current series length curLen = 1; } // Save the direction of the current candle as the previous one prevIsBuy = isBuy; prevIsSell = isSell; } // Initialize the array element for the average series length symbolAvrSeriesLength[s][t] = 0; int count = 0; // For all series lengths we find the sum and quantity FOREACH(seriesLens) { symbolAvrSeriesLength[s][t] += seriesLens[i] * i; count += seriesLens[i]; } // Calculate the average length of candlestick series symbolAvrSeriesLength[s][t] /= (count > 0 ? count : 1); // Copy the values of the series lengths into the final arrays symbolCountSeries2[s][t] = seriesLens[2]; symbolCountSeries3[s][t] = seriesLens[3]; symbolCountSeries4[s][t] = seriesLens[4]; symbolCountSeries5[s][t] = seriesLens[5]; symbolCountSeries6[s][t] = seriesLens[6]; symbolCountSeries7[s][t] = seriesLens[7]; symbolCountSeries8[s][t] = seriesLens[8]; symbolCountSeries9[s][t] = seriesLens[9]; } }
A exibição dos resultados fica a cargo da função Show(). Nesta primeira versão, vamos apenas apresentar as informações no log do terminal e como comentário no gráfico onde o EA estiver em execução. Sendo assim, basta representar os resultados em forma de texto. Essa formatação textual será feita por uma função separada chamada TextComment().
//+------------------------------------------------------------------+ //| Show results | //+------------------------------------------------------------------+ void Show() { // Get the results as text string text = TextComment(); // Show it in the comment and in the log Comment(text); Print(text); }
Na função de inicialização do EA, resta processar os parâmetros de entrada, dividindo os nomes de símbolos e timeframes listados em valores individuais, e preparar os arrays de resultados com os tamanhos adequados. Depois disso, já podemos chamar a função de cálculo e exibição dos resultados:
//+------------------------------------------------------------------+ //| Initialize the EA | //+------------------------------------------------------------------+ int OnInit(void) { // Fill in the symbol array for calculations from the inputs SPLIT(symbols_, g_symbols); // If no symbols are specified, use the current single symbol if(ArraySize(g_symbols) == 0) { APPEND(g_symbols, Symbol()); } // Number of symbols for calculations int nSymbols = ArraySize(g_symbols); // Initialize arrays for calculated values Initialize(nSymbols); // Fill the array with timeframe names from the inputs string strTimeframes[]; SPLIT(timeframes_, strTimeframes); ArrayResize(g_timeframes, 0); // If timeframes are not specified, use the current one if(ArraySize(strTimeframes) == 0) { APPEND(strTimeframes, TimeframeToString(Period())); } // Fill the timeframe array from the timeframe names array FOREACH(strTimeframes) { ENUM_TIMEFRAMES tf = StringToTimeframe(strTimeframes[i]); if(tf != PERIOD_CURRENT) { APPEND(g_timeframes, tf); } } // Perform a forced recalculation Calculate(true); // Show the results Show(); return(INIT_SUCCEEDED); }
Na função acima, utilizamos um novo macro chamado SPLIT. Ele foi adicionado ao arquivo Utils/Macros.mqh da biblioteca Adwizard. Esse foi, até o momento, o único acréscimo à biblioteca necessário para este projeto.
O macro em si tem como propósito dividir uma string em partes, considerando dois possíveis separadores: vírgula e ponto e vírgula.
#define SPLIT(V, A) { string s=V; StringReplace(s, ";", ","); StringSplit(s, ',', A); }
Vamos agora observar os resultados da execução do EA desenvolvido.
Testando o EA
Executamos o EA com os parâmetros padrão em algum gráfico. Como resultado, obtemos algo semelhante a isto:
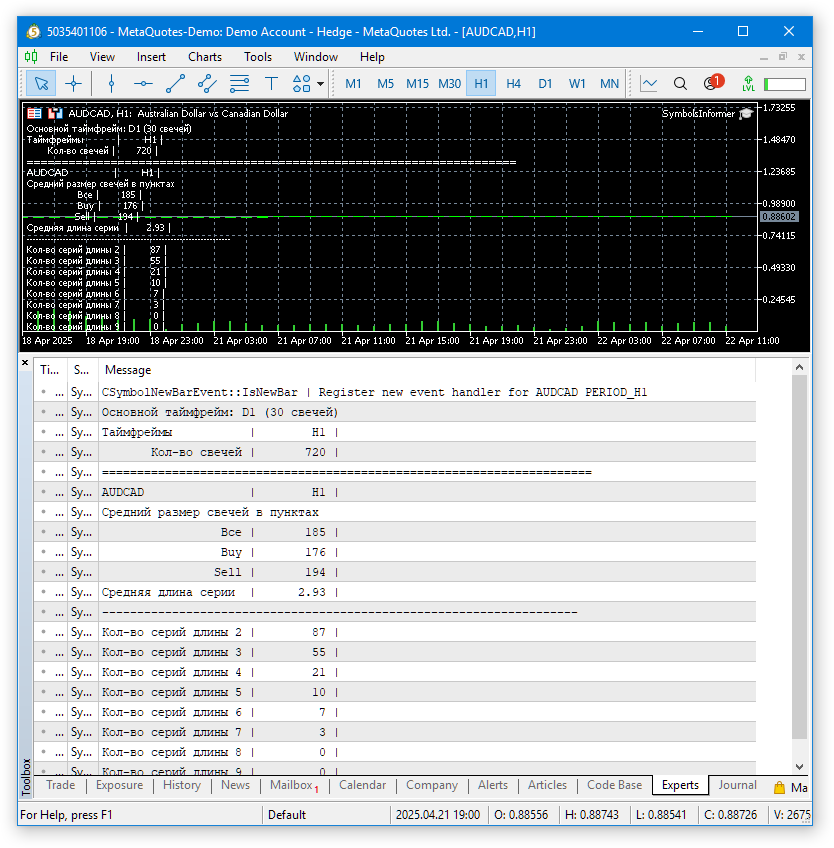
Fig. 1. Resultados do Expert Advisor com parâmetros padrão no AUDCAD H1
Como o comentário exibido no gráfico utiliza uma fonte proporcional (não monoespaçada), analisar os valores diretamente no gráfico não é muito prático. Já no log do terminal, onde a fonte é monoespaçada, a visualização é mais clara. Vamos ver como os resultados se apresentam ao utilizarmos múltiplos símbolos e timeframes.
Executamos o EA com os seguintes parâmetros de entrada:
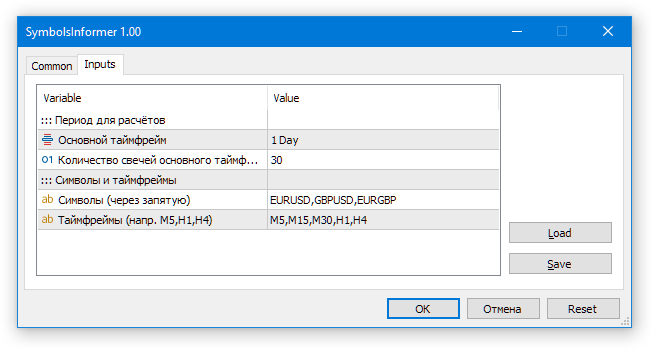
E conferimos o resultado.
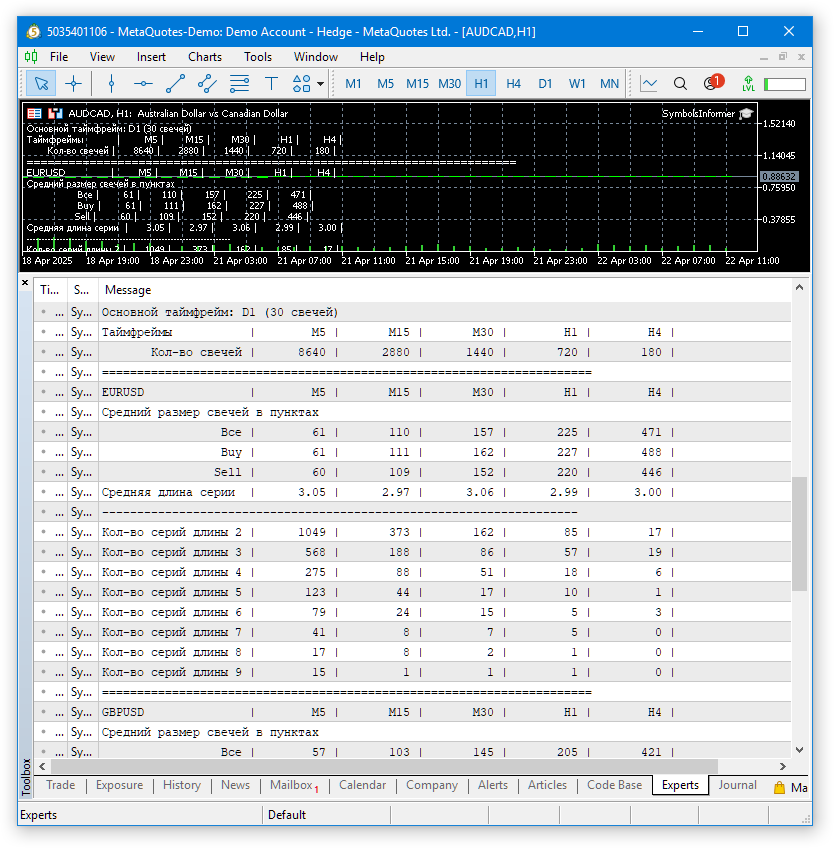
Fig. 2. Resultados do EA para vários símbolos e timeframes
Os cálculos para os diferentes símbolos e timeframes foram executados com sucesso. Os resultados foram exibidos em forma de tabela. É verdade que ainda não é muito confortável trabalhar com esses dados, mas, para uma análise preliminar rápida, esse formato de exibição já cumpre bem o seu papel.
Considerações finais
E assim, finalizamos a primeira versão do EA auxiliar-informador, que exibe informações sobre os tamanhos médios das velas em pontos e os comprimentos das séries de velas consecutivas na mesma direção. À primeira vista, isso pode parecer ter uma relação apenas indireta com o nosso projeto principal de criação de um sistema de otimização automática e execução de EAs multimoeda, baseados em diversas estratégias simples. E de fato é isso mesmo. Por isso, o desenvolvimento deste EA será continuado fora do escopo deste ciclo de artigos. No entanto, ao longo desse processo, vamos testar e validar a implementação de muitos recursos que, esperamos, possam ser aplicados com sucesso também no projeto principal.
Já avançamos bastante até aqui. A escolha de uma estrutura mais adequada para organização do código permitirá distribuir paralelamente o trabalho entre diferentes frentes de desenvolvimento da biblioteca Adwizard. E essas frentes já começam a se delinear em várias direções. Uma delas é a criação de uma interface visual para controle da execução dos EAs finais. O projeto apresentado neste artigo nos ajudará a explorar diferentes abordagens possíveis, sem que precisemos nos aprofundar logo de início em implementações complexas. Depois de avaliarmos os prós e contras de cada abordagem e escolhermos a mais adequada, poderemos focar o desenvolvimento do projeto principal com mais objetividade.
Obrigado pela atenção e até a próxima!
Aviso importante
Todos os resultados apresentados neste artigo e nos anteriores deste ciclo baseiam-se exclusivamente em testes realizados com dados históricos e não constituem garantia de qualquer tipo de rentabilidade futura. O trabalho desenvolvido neste projeto tem caráter de pesquisa. Todos os resultados publicados podem ser utilizados livremente, por conta e risco dos próprios usuários.
Conteúdo do arquivo compactado
| # | Nome | Versão | Descrição | Últimas alterações |
|---|---|---|---|---|
| SymbolsInformer | Pasta de trabalho do projeto | |||
| 1 | SymbolsInformer.mq5 | 1.00 | EA para exibir informações sobre os comprimentos de séries de velas consecutivas na mesma direção | Parte 26 |
| SymbolsInformer/Include/Adwizard/Base | Classes base das quais outras classes do projeto herdam | |||
| 2 | Advisor.mqh | 1.04 | Classe base do EA | Parte 10 |
| 3 | Factorable.mqh | 1.05 | Classe base de objetos criados a partir de uma string | Parte 24 |
| 4 | FactorableCreator.mqh | 1.00 | Classe de criadores que associam nomes a construtores estáticos de classes derivadas de CFactorable | Parte 24 |
| 5 | Interface.mqh | 1.01 | Classe base para visualização de diversos objetos | Parte 4 |
| 6 | Receiver.mqh | 1.04 | Classe base para conversão de volumes abertos em posições de mercado | Parte 12 |
| 7 | Strategy.mqh | 1.04 | Classe base para estratégia de negociação | Parte 10 |
| SymbolsInformer/Include/Adwizard/Database | Arquivos para trabalhar com todos os tipos de bancos de dados utilizados pelos EAs do projeto | |||
| 8 | Database.mqh | 1.12 | Classe para trabalhar com banco de dados | Parte 25 |
| 9 | db.adv.schema.sql | 1.00 | Esquema do banco de dados do EA final | Parte 22 |
| 10 | db.cut.schema.sql | 1.00 | Esquema do banco de dados reduzido de otimização | Parte 22 |
| 11 | db.opt.schema.sql | 1.05 | Esquema do banco de dados de otimização | Parte 22 |
| 12 | Storage.mqh | 1.01 | Classe para trabalhar com armazenamento do tipo Key-Value para o EA final no banco de dados do expert | Parte 23 |
| SymbolsInformer/Include/Adwizard/Experts | Arquivos com partes comuns dos EAs utilizados, de diferentes tipos | |||
| 13 | Expert.mqh | 1.22 | Arquivo de biblioteca para o EA final. Os parâmetros de grupos podem ser obtidos do banco de dados do expert | Parte 23 |
| 14 | Optimization.mqh | 1.04 | Arquivo de biblioteca para o EA que gerencia a execução de tarefas de otimização | Parte 23 |
| 15 | Stage1.mqh | 1.19 | Arquivo de biblioteca para o EA de otimização de uma instância individual de estratégia de negociação (Etapa 1) | Parte 23 |
| 16 | Stage2.mqh | 1.04 | Arquivo de biblioteca para o EA de otimização de um grupo de instâncias de estratégias de negociação (Etapa 2) | Parte 23 |
| 17 | Stage3.mqh | 1.04 | Arquivo de biblioteca para o EA que grava o grupo de estratégias normalizadas formado no banco de dados do Expert com o nome especificado. | Parte 23 |
| SymbolsInformer/Include/Adwizard/Optimization | Classes responsáveis pelo funcionamento da otimização automática | |||
| 18 | OptimizationJob.mqh | 1.00 | Classe para a etapa de execução do projeto de otimização | Parte 25 |
| 19 | OptimizationProject.mqh | 1.00 | Classe para o projeto de otimização | Parte 25 |
| 20 | OptimizationStage.mqh | 1.00 | Classe para a etapa do projeto de otimização | Parte 25 |
| 21 | OptimizationTask.mqh | 1.00 | Classe para a tarefa de otimização (para criação) | Parte 25 |
| 22 | Optimizer.mqh | 1.03 | Classe para o gerenciador da otimização automática de projetos | Parte 22 |
| 23 | OptimizerTask.mqh | 1.03 | Classe para a tarefa de otimização (para o pipeline) | Parte 22 |
| SymbolsInformer/Include/Adwizard/Strategies | Exemplos de estratégias de negociação usadas para demonstrar o funcionamento do projeto | |||
| 24 | HistoryStrategy.mqh | 1.00 | Classe da estratégia de negociação para reprodução do histórico de operações | Parte 16 |
| 25 | SimpleVolumesStrategy.mqh | 1.11 | Classe da estratégia de negociação com uso de volumes de ticks | Parte 22 |
| SymbolsInformer/Include/Adwizard/Utils | Utilitários auxiliares e macros para reduzir o código | |||
| 26 | ExpertHistory.mqh | 1.00 | Classe para exportar o histórico de ordens para arquivo | Parte 16 |
| 27 | Macros.mqh | 1.07 | Macros úteis para operações com arrays | Parte 26 |
| 28 | NewBarEvent.mqh | 1.00 | Classe para detectar novo candle para um símbolo específico | Parte 8 |
| 29 | SymbolsMonitor.mqh | 1.00 | Classe para obtenção de informações sobre instrumentos de negociação (símbolos) | Parte 21 |
| SymbolsInformer/Include/Adwizard/Virtual | Classes para criação de diferentes objetos reunidos pelo uso do sistema de ordens e posições virtuais de negociação | |||
| 30 | Money.mqh | 1.01 | Classe base para gerenciamento de capital | Parte 12 |
| 31 | TesterHandler.mqh | 1.07 | Classe para tratamento de eventos de otimização | Parte 23 |
| 32 | VirtualAdvisor.mqh | 1.10 | Classe do expert que trabalha com posições (ordens) virtuais | Parte 24 |
| 33 | VirtualChartOrder.mqh | 1.01 | Classe da posição virtual gráfica | Parte 18 |
| 34 | VirtualHistoryAdvisor.mqh | 1.00 | Classe do expert para reprodução do histórico de ordens | Parte 16 |
| 35 | VirtualInterface.mqh | 1.00 | Classe da interface gráfica do EA | Parte 4 |
| 36 | VirtualOrder.mqh | 1.09 | Classe de ordens e posições virtuais | Parte 22 |
| 37 | VirtualReceiver.mqh | 1.04 | Classe que converte volumes abertos em posições de mercado (receptor) | Parte 23 |
| 38 | VirtualRiskManager.mqh | 1.05 | Classe de gerenciamento de risco (risk manager) | Parte 24 |
| 39 | VirtualStrategy.mqh | 1.09 | Classe da estratégia de negociação com posições virtuais | Parte 23 |
| 40 | VirtualStrategyGroup.mqh | 1.03 | Classe de grupo de estratégias de negociação ou grupos de estratégias | Parte 24 |
| 41 | VirtualSymbolReceiver.mqh | 1.00 | Classe do receptor simbólico | Parte 3 |
O código-fonte também está disponível nos repositórios públicos SymbolsInformer e Adwizard
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17606
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
É uma pena(
Vou dar uma olhada em sua análise informativa amanhã
@Rashid Umarov
Hi
Você está acompanhando este tópico de perto e é capaz de implementar tudo e otimizar?
Pode me ajudar a fazer isso?
Obrigado