
Desenvolvendo um EA multimoeda (Parte 25): Conectando uma nova estratégia (II)
Introdução
Seguiremos com a próxima etapa do trabalho, iniciada no artigo anterior. Para relembrar, após dividir todo o código do projeto em uma parte de biblioteca e uma parte de projeto, decidimos verificar como seria a transição da estratégia de negociação modelo SimpleVolumes , utilizada por muito tempo, para outra estratégia qualquer. O que seria necessário fazer para isso? Seria fácil? Naturalmente, foi preciso escrever a classe da nova estratégia de negociação. Mas, surgiram dificuldades que não eram tão óbvias no início.
Essas dificuldades estavam diretamente ligadas ao nosso esforço de manter a biblioteca independente do projeto. Se tivéssemos decidido descumprir essa nova regra, as dificuldades nem teriam surgido. No entanto, encontramos uma forma de manter a separação do código e, ainda assim, permitir a conexão de uma nova estratégia de negociação. Isso exigiu mudanças nos arquivos da parte da biblioteca do projeto, não muito grandes em volume, mas significativas em conceito.
No fim, conseguimos compilar e executar a otimização do EA da primeira etapa com a nova estratégia, que chamamos de SimpleCandles. Os próximos passos planejados consistiam em fazer o pipeline de otimização automática funcionar com ela. Para a estratégia anterior, havíamos desenvolvido um EA auxiliar chamado CreateProject.mq5, que permitia formar tarefas no banco de dados de otimização para execução no pipeline. Nos parâmetros do EA era possível indicar em quais instrumentos (símbolos) e timeframes queríamos executar a otimização, quais os nomes dos EAs das etapas, entre outras informações necessárias. Se o banco de dados de otimização ainda não existisse, ele era criado automaticamente.
Agora, vejamos como fazer esse processo funcionar com a nova estratégia de negociação.
Traçando o caminho
Vamos começar o trabalho analisando o código do EA CreateProject.mq5. Nosso objetivo é identificar o código que é igual ou quase igual entre diferentes projetos. Esse código poderá ser movido para a biblioteca e dividido em arquivos separados, conforme necessário. A parte do código que varia entre os projetos permanecerá na seção de projeto e explicaremos quais mudanças deverão ser feitas nela.
Antes disso, porém, vamos corrigir um erro detectado ao salvar informações dos passes do testador no banco de dados de otimização, melhorar os macros utilizados para organizar os laços e verificar como adicionar parâmetros à estratégia de negociação desenvolvida anteriormente.
Correções em CDatabase
Nos últimos artigos, começamos a utilizar intervalos de teste relativamente curtos para os projetos de otimização. Em vez de períodos de cinco anos ou mais, passamos a usar intervalos de alguns meses. Isso se deve ao fato de que o principal objetivo era verificar o funcionamento do mecanismo do pipeline de otimização automática. A redução do intervalo diminui significativamente o tempo de execução de um único passe do testador e, portanto, o tempo total de otimização.
Para salvar as informações dos passes no banco de dados de otimização, cada agente de teste (local, remoto ou em nuvem) envia os dados em um frame para o terminal em que o processo de otimização está sendo executado. Nesse terminal, após o início da otimização, uma segunda instância do EA otimizado é iniciada em um modo especial: o modo de coleta de frames de dados. Essa instância não roda no testador, mas em um gráfico separado do terminal. Ela receberá e salvará todas as informações enviadas pelos agentes de teste.
Embora o código do manipulador do evento de chegada de novos frames de dados dos agentes de teste não contenha operações assíncronas, mensagens de erro relacionadas a bloqueio causado por outra operação começaram a surgir durante a otimização ao tentar inserir dados no banco de dados. Esse erro ocorria com pouca frequência. No entanto, algumas dezenas de passes entre vários milhares não conseguiam salvar seus resultados no banco de dados de otimização.
Aparentemente, a origem desses erros está no aumento da frequência com que vários agentes de teste finalizam um passe ao mesmo tempo e enviam seus frames de dados ao EA no terminal principal. Esse EA tenta inserir um novo registro no banco de dados antes que a operação de inserção anterior tenha sido concluída do lado do banco de dados.
Para corrigir isso, vamos adicionar um manipulador separado para essa categoria de erro. Se a causa do erro estiver relacionada ao bloqueio do banco de dados ou de uma tabela por outra operação, devemos simplesmente repetir a operação que falhou após um breve intervalo. Se, após algumas tentativas de reinserção dos dados, o mesmo erro ocorrer novamente, as tentativas devem ser encerradas.
Para a inserção, usaremos o método CDatabase::ExecuteTransaction(), e faremos as seguintes alterações nele. Adicionaremos ao método um argumento que represente o contador de tentativas de execução da consulta. Se um erro desse tipo ocorrer, faremos uma pausa por uma quantidade aleatória de milissegundos (entre 0 e 50) e chamaremos a mesma função novamente, incrementando o valor do contador de tentativas.
//+------------------------------------------------------------------+ //| Execute multiple DB queries in one transaction | //+------------------------------------------------------------------+ bool CDatabase::ExecuteTransaction(string &queries[], int attempt = 0) { // Open a transaction DatabaseTransactionBegin(s_db); s_res = true; // Send all execution requests FOREACH(queries, { s_res &= DatabaseExecute(s_db, queries[i]); if(!s_res) break; }); // If an error occurred in any request, then if(!s_res) { // Cancel transaction DatabaseTransactionRollback(s_db); if((_LastError == ERR_DATABASE_LOCKED || _LastError == ERR_DATABASE_BUSY) && attempt < 20) { PrintFormat(__FUNCTION__" | ERROR: ERR_DATABASE_LOCKED. Repeat Transaction in DB [%s]", s_fileName); Sleep(rand() % 50); ExecuteTransaction(queries, attempt + 1); } else { // Report it PrintFormat(__FUNCTION__" | ERROR: Transaction failed in DB [%s], error code=%d", s_fileName, _LastError); } } else { // Otherwise, confirm transaction DatabaseTransactionCommit(s_db); //PrintFormat(__FUNCTION__" | Transaction done successfully"); } return s_res; }
Por precaução, faremos alterações com o mesmo propósito no método de execução de consulta SQL sem transação CDatabase::Execute().
Outra pequena modificação, que será útil futuramente, foi a adição de uma variável lógica estática à classe CDatabase. Nela será armazenada a informação de que ocorreu um erro durante a execução das consultas:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { // ... static bool s_res; // Query execution result public: static int Id(); // Database connection handle static bool Res(); // Query execution result // ... }; bool CDatabase::s_res = true;
Salvaremos essas alterações no arquivo Database/Database.mqh, dentro da pasta da biblioteca.
Correções em Macros.h
Vamos comentar uma alteração que já estava pendente há bastante tempo, mas que ainda não havia sido implementada. Relembrando: para facilitar a escrita dos cabeçalhos de laços que devem iterar por todos os valores de um determinado array, criamos o macro FOREACH(A, D):
#define FOREACH(A, D) { for(int i=0, im=ArraySize(A);i<im;i++) {D;} }
Aqui, A é o nome do array e D é o corpo do laço. A implementação tinha um ponto fraco: durante o debug, não era possível acompanhar corretamente a execução passo a passo do código dentro do corpo do laço. Embora isso fosse necessário raramente, era bastante inconveniente. Certa vez, revisando a documentação, vimos uma outra forma de implementar esse tipo de macro. Nesse outro caso, o macro definia apenas o cabeçalho do laço, e o corpo era escrito fora do macro. Além disso, havia um parâmetro adicional para definir o nome da variável do laço.
Na nossa implementação anterior, o nome da variável do laço (índice do elemento do array) era fixo (i), o que nunca causou problemas. Mesmo nos casos onde foi necessário usar dois laços aninhados, foi possível usar o mesmo nome graças aos diferentes escopos dos índices. Por isso, a nova implementação também usa um nome de índice fixo. O único parâmetro passado agora é o nome do array que será percorrido no laço:
#define FOREACH(A) for(int i=0, im=ArraySize(A);i<im;i++)
Para adotar essa nova abordagem, foi preciso ajustar todos os pontos do código onde esse macro era usado. Por exemplo:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CAdvisor::Tick(void) { // Call OnTick handling for all strategies //FOREACH(m_strategies, m_strategies[i].Tick();) FOREACH(m_strategies) m_strategies[i].Tick(); }
Junto com esse macro, adicionamos mais um, responsável por montar o cabeçalho do laço. Nele, cada elemento do array A é, em sequência, colocado na variável E, que deve ser declarada previamente. Antes do cabeçalho do laço, essa variável recebe o primeiro elemento do array, se houver. Como variável de controle do laço, usaremos uma variável formada pela letra i seguida do nome da variável E. Na terceira parte do cabeçalho do laço, incrementamos a variável de controle e atribuímos à variável E o valor do próximo elemento do array A. O uso da operação de índice com módulo do número de elementos do array permite evitar ultrapassar os limites do array na última iteração do laço:
#define FOREACH_AS(A, E) if(ArraySize(A)) E=A[0]; \ for(int i##E=0, im=ArraySize(A);i##E<im;E=A[++i##E%im])
Salvaremos as alterações feitas no arquivo Utils/Macros.h, localizado na pasta da biblioteca.
Como adicionar um parâmetro à estratégia de negociação
Assim como praticamente todo o código do programa, a implementação da estratégia de negociação também está sujeita a alterações. Se essas alterações envolverem a modificação da lista de parâmetros de entrada de uma instância única da estratégia, será necessário ajustar não apenas a classe da estratégia, mas também mais alguns pontos. Vamos ver, por meio de um exemplo, o que precisa ser feito.
Suponhamos que decidimos adicionar à estratégia de negociação um parâmetro de spread máximo. A lógica de uso será a seguinte: se, no momento em que for gerado o sinal de abertura de posição, o spread atual ultrapassar o valor definido nesse parâmetro, então a posição não será aberta.
Primeiramente, no EA da primeira etapa, adicionaremos um parâmetro de entrada, que permitirá definir esse valor no momento da execução no testador. Em seguida, na função de formação da string de inicialização, adicionamos a substituição do valor do novo parâmetro dentro da string:
//+------------------------------------------------------------------+ //| 4. Strategy inputs | //+------------------------------------------------------------------+ sinput string symbol_ = ""; // Symbol sinput ENUM_TIMEFRAMES period_ = PERIOD_CURRENT; // Timeframe for candles input group "=== Opening signal parameters" input int signalSeqLen_ = 6; // Number of unidirectional candles input int periodATR_ = 0; // ATR period (if 0, then TP/SL in points) input group "=== Pending order parameters" input double stopLevel_ = 25000; // Stop Loss (in ATR fraction or points) input double takeLevel_ = 3630; // Take Profit (in ATR fraction or points) input group "=== Money management parameters" input int maxCountOfOrders_ = 9; // Max number of simultaneously open orders input int maxSpread_ = 10; // Max acceptable spread (in points) //+------------------------------------------------------------------+ //| 5. Strategy initialization string generation function | //| from the inputs | //+------------------------------------------------------------------+ string GetStrategyParams() { return StringFormat( "class CSimpleCandlesStrategy(\"%s\",%d,%d,%d,%.3f,%.3f,%d,%d)", (symbol_ == "" ? Symbol() : symbol_), period_, signalSeqLen_, periodATR_, stopLevel_, takeLevel_, maxCountOfOrders_, maxSpread_ ); }
Agora, a string de inicialização contém um parâmetro a mais do que antes. Por isso, a próxima alteração será a adição de uma nova propriedade à classe e a leitura desse valor da string de inicialização dentro do construtor:
//+------------------------------------------------------------------+ //| Trading strategy using unidirectional candlesticks | //+------------------------------------------------------------------+ class CSimpleCandlesStrategy : public CVirtualStrategy { protected: // ... //--- Money management parameters int m_maxCountOfOrders; // Max number of simultaneously open positions int m_maxSpread; // Max acceptable spread (in points) // ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleCandlesStrategy::CSimpleCandlesStrategy(string p_params) { // Read the parameters from the initialization string m_params = p_params; m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalSeqLen = (int) ReadLong(p_params); m_periodATR = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_maxSpread = (int) ReadLong(p_params); // ... }
Pronto. Agora o novo parâmetro pode ser usado como quisermos dentro dos métodos da classe da estratégia de negociação. Com base na sua finalidade, podemos adicionar o seguinte trecho de código ao método que obtém o sinal de abertura de posição.
//+------------------------------------------------------------------+ //| Signal for opening pending orders | //+------------------------------------------------------------------+ int CSimpleCandlesStrategy::SignalForOpen() { // By default, there is no signal int signal = 0; MqlRates rates[]; // Copy the quote values (candles) to the destination array. // To check the signal we need m_signalSeqLen of closed candles and the current candle, // so in total m_signalSeqLen + 1 int res = CopyRates(m_symbol, m_timeframe, 0, m_signalSeqLen + 1, rates); // If the required number of candles has been copied if(res == m_signalSeqLen + 1) { signal = 1; // buy signal // Go through all closed candles for(int i = 1; i <= m_signalSeqLen; i++) { // If at least one upward candle occurs, cancel the signal if(rates[i].open < rates[i].close ) { signal = 0; break; } } if(signal == 0) { signal = -1; // otherwise, sell signal // Go through all closed candles for(int i = 1; i <= m_signalSeqLen; i++) { // If at least one downward candle occurs, cancel the signal if(rates[i].open > rates[i].close ) { signal = 0; break; } } } } // If there is a signal, then if(signal != 0) { // If the current spread is greater than the maximum allowed, then if(rates[0].spread > m_maxSpread) { PrintFormat(__FUNCTION__" | IGNORE %s Signal, spread is too big (%d > %d)", (signal > 0 ? "BUY" : "SELL"), rates[0].spread, m_maxSpread); signal = 0; // Cancel the signal } } return signal; }
De forma análoga, outros novos parâmetros podem ser adicionados às estratégias de negociação ou parâmetros desnecessários podem ser removidos.
Análise do CreateProject.mq5
Vamos iniciar a análise do código do EA responsável pela criação dos projetos: CreateProject.mq5. Em sua função de inicialização, já fizemos a separação do código em funções distintas. A finalidade de cada uma fica clara pelo nome:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); }
Mas essa separação ainda não é muito conveniente, porque as funções extraídas acabaram ficando bem pesadas e responsáveis por tarefas bastante diversas. Por exemplo, na função CreateJobs(), tratamos da pré-processamento dos dados de entrada, da criação dos templates de parâmetros para os trabalhos, da inserção das informações no banco de dados e, depois, realizamos ações semelhantes para criar tarefas de otimização no banco de dados. O ideal seria o contrário: funções mais simples, cada uma resolvendo uma tarefa pequena e bem definida.
Para usar a nova estratégia na implementação atual, precisaríamos alterar o template de parâmetros da primeira etapa e, possivelmente, também a quantidade de tarefas com critérios de otimização para ela. O template de parâmetros da primeira etapa da estratégia anterior era definido na variável global paramsTemplate1:
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
Felizmente, ele era o mesmo para todos os trabalhos de otimização da primeira etapa. Mas isso pode não ser sempre assim. Por exemplo, na nova estratégia incluímos entre os parâmetros os valores do símbolo e do timeframe no qual a estratégia deve operar. Isso significa que, em diferentes trabalhos de otimização da primeira etapa — criados para diferentes símbolos e timeframes — haverá partes variáveis no template de parâmetros. Porém, para atribuir valores a essas partes, será necessário mergulhar no código da função de criação de tarefas e modificá-lo diretamente. Com isso, ela deixará de ser elegível para ser movida para a parte da biblioteca.
Além disso, atualmente nosso EA de criação do projeto de otimizão gera um projeto com três etapas fixas. Chegamos a essa composição simplificada durante o desenvolvimento, embora tenhamos testado a adição de etapas extras (veja, por exemplo, a parte 18 e a parte 19). As etapas adicionais não demonstraram melhorias significativas no resultado final, embora isso possa não se aplicar a outras estratégias de negociação. Portanto, se movermos o código atual para a biblioteca, perderemos a flexibilidade de alterar a composição das etapas no futuro, se desejarmos.
Sendo assim, por mais que quiséssemos evitar esforço, o melhor agora é realizar um trabalho mais profundo de refatoração nesse código, em vez de adiar essa tarefa. Vamos tentar dividir o código do EA de criação do projeto em várias classes. Essas classes serão movidas para a parte da biblioteca, e na parte de projeto nós as utilizaremos para montar projetos com a composição desejada de etapas e seus conteúdos. Ao mesmo tempo, isso também servirá como preparação futura para exibir informações sobre o progresso do pipeline.
Para começar, fizemos um esboço de como poderia parecer o código final. Essa versão preliminar permaneceu praticamente sem alterações até a versão funcional. Apenas foram adicionadas composições específicas de parâmetros nas chamadas dos métodos. Por isso, vejamos como está estruturada a nova versão da função de inicialização do EA de criação do projeto de otimização. Para evitar desviar o foco com detalhes menores, os argumentos dos métodos não estão mostrados:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create an optimization project object for the given database COptimizationProject p; // Create a new project in the database p.Create(...); // Add the first stage p.AddStage(...); // Adding the first stage jobs p.AddJobs(...); // Add tasks for the first stage jobs p.AddTasks(...); // Add the second stage p.AddStage(...); // Add the second stage jobs p.AddJobs(...); // Add tasks for the second stage jobs p.AddTasks(...); // Add the third stage p.AddStage(...); // Add the third stage job p.AddJobs(...); // Add a task for the third stage job p.AddTasks(...); // Put the project in the execution queue p.Queue(); // Delete the EA ExpertRemove(); // Successful initialization return(INIT_SUCCEEDED); }
Com essa estrutura de código, poderemos facilmente adicionar novas etapas e alterar seus parâmetros com flexibilidade. Mas, por enquanto, vemos apenas uma nova classe que com certeza será necessária, em nosso caso a classe do projeto de otimização COptimizationProject. Vamos analisar seu código.
Classe COptimizationProject
Durante o desenvolvimento dessa classe, rapidamente ficou claro que precisaríamos de classes separadas para cada tipo de entidade armazenada no banco de dados de otimização. Ou seja, a seguir viriam as classes COptimizationStage para as etapas do projeto, COptimizationJob para os trabalhos das etapas do projeto e COptimizationTask para as tarefas de cada trabalho da etapa do projeto.
Como os objetos dessas classes são, essencialmente, representações das entradas das várias tabelas do banco de dados de otimização, a estrutura dos campos dessas classes será semelhante à estrutura dos campos das respectivas tabelas. Além desses campos, também adicionaremos a essas classes outros campos e métodos necessários para cumprir as funções atribuídas a elas.
Por enquanto, para simplificar, tornaremos públicos todos os atributos e métodos das classes que estamos criando. Cada classe terá seu próprio método para criar um novo registro no banco de dados de otimização. Mais adiante, incluiremos métodos para modificar registros existentes e para ler registros do banco de dados, mas isso não será necessário na fase de criação do projeto.
Em vez dos templates de parâmetros do testador utilizados anteriormente, vamos criar funções separadas que retornam os parâmetros já preenchidos de acordo com o modelo. Assim, os templates de parâmetros serão movidos para dentro dessas funções. Como parâmetro, essas funções receberão um ponteiro para o projeto, o que permitirá acessar as informações necessárias para o preenchimento do modelo. A declaração dessas funções ficará na parte do projeto, enquanto na parte da biblioteca vamos apenas declarar um novo tipo: um ponteiro para função com a seguinte forma:
// Create a new type - a pointer to a string generation function // for optimization job parameters (job) accepting the pointer // to the optimization project object as an argument typedef string (*TJobsTemplateFunc)(COptimizationProject*);
Graças a isso, poderemos usar na classe COptimizationProject as funções de geração de parâmetros das etapas que ainda não existem, mas que no futuro, certamente, serão adicionadas na parte de projeto.
Veja como está estruturada a descrição dessa classe:
//+------------------------------------------------------------------+ //| Optimization project class | //+------------------------------------------------------------------+ class COptimizationProject { public: string m_fileName; // Database name // Properties stored directly in the database ulong id_project; // Project ID string name; // Name string version; // Version string description; // Description string status; // Status // Arrays of all stages, jobs and tasks COptimizationStage* m_stages[]; // Project stages COptimizationJob* m_jobs[]; // Jobs of all project stages COptimizationTask* m_tasks[]; // Tasks of all jobs of project stages // Properties for the current state of the project creation string m_symbol; // Current symbol string m_timeframe; // Current timeframe COptimizationStage* m_stage; // Last created stage (current stage) COptimizationJob* m_job; // Last created job (current job) COptimizationTask* m_task; // Last created task (current task) // Methods COptimizationProject(string p_fileName); // Constructor ~COptimizationProject(); // Destructor // Create a new project in the database COptimizationProject* COptimizationProject::Create(string p_name, string p_version = "", string p_description = "", string p_status = "Done"); void Insert(); // Insert an entry into the database void Update(); // Update an entry in the database // Add a new stage to the database COptimizationProject* AddStage(COptimizationStage* parentStage, string stageName, string stageExpertName, string stageSymbol, string stageTimeframe, int stageOptimization, int stageModel, datetime stageFromDate, datetime stageToDate, int stageForwardMode, datetime stageForwardDate, int stageDeposit = 10000, string stageCurrency = "USD", int stageProfitInPips = 0, int stageLeverage = 200, int stageExecutionMode = 0, int stageOptimizationCriterion = 7, string stageStatus = "Done"); // Add new jobs to the database for the specified symbols and timeframes COptimizationProject* AddJobs(string p_symbols, string p_timeframes, TJobsTemplateFunc p_templateFunc); COptimizationProject* AddJobs(string &p_symbols[], string &p_timeframes[], TJobsTemplateFunc p_templateFunc); // Add new tasks to the database for the specified optimization criteria COptimizationProject* AddTasks(string p_criterions); COptimizationProject* AddTasks(string &p_criterions[]); void Queue(); // Put the project in the execution queue // Convert a string name to a timeframe static ENUM_TIMEFRAMES StringToTimeframe(string s); };
No início, temos os atributos que são diretamente salvos no banco de dados de otimização, na tabela projects. Em seguida, aparecem os arrays com todas as etapas, trabalhos e tarefas do projeto, e depois os atributos relacionados ao estado atual do processo de criação do projeto.
Como, no momento, a única função dessa classe é criar um projeto no banco de dados de otimização, em seu construtor já fazemos a conexão com o banco de dados correspondente e iniciamos uma transação. O encerramento dessa transação será feito no destrutor. É aí que vamos utilizar o campo estático CDatabase::s_res, cujo valor indica se ocorreu algum erro durante as operações de inserção de registros no banco de dados de otimização na criação do projeto. Se não houve erros, a transação é confirmada; caso contrário, ela é cancelada. O destrutor também se encarrega de liberar a memória dos objetos dinâmicos criados.
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ COptimizationProject::COptimizationProject(string p_fileName) : m_fileName(p_fileName), id_project(0) { // Connect to the database if (DB::Connect(m_fileName)) { // Start a transaction DatabaseTransactionBegin(DB::Id()); } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ COptimizationProject::~COptimizationProject() { // If no errors occurred, then if(DB::Res()) { // Confirm the transaction DatabaseTransactionCommit(DB::Id()); } else { // Otherwise, cancel the transaction DatabaseTransactionRollback(DB::Id()); } // Close connection to the database DB::Close(); // Delete created task, job, and stage objects FOREACH(m_tasks) { delete m_tasks[i]; } FOREACH(m_jobs) { delete m_jobs[i]; } FOREACH(m_stages) { delete m_stages[i]; } }
Os métodos de adição de trabalhos e tarefas são declarados em duas variantes. Na primeira, as listas de símbolos, timeframes e critérios são passadas como parâmetros em forma de strings separadas por vírgulas. Dentro do método, essas strings são convertidas em arrays de valores e usadas como argumentos na chamada da segunda variante do método, que recebe exatamente arrays.
Veja como estão estruturados os métodos de adição de trabalhos:
//+------------------------------------------------------------------+ //| Add new jobs to the database for the specified | //| symbols and timeframes in strings | //+------------------------------------------------------------------+ COptimizationProject* COptimizationProject::AddJobs(string p_symbols, string p_timeframes, TJobsTemplateFunc p_templateFunc) { // Array of symbols for strategies string symbols[]; StringReplace(p_symbols, ";", ","); StringSplit(p_symbols, ',', symbols); // Array of timeframes for strategies string timeframes[]; StringReplace(p_timeframes, ";", ","); StringSplit(p_timeframes, ',', timeframes); return AddJobs(symbols, timeframes, p_templateFunc); } //+------------------------------------------------------------------+ //| Add new jobs to the database for the specified | //| symbols and timeframes in arrays | //+------------------------------------------------------------------+ COptimizationProject* COptimizationProject::AddJobs(string &p_symbols[], string &p_timeframes[], TJobsTemplateFunc p_templateFunc) { // For each symbol FOREACH_AS(p_symbols, m_symbol) { // For each timeframe FOREACH_AS(p_timeframes, m_timeframe) { // Get the parameters for work for a given symbol and timeframe string params = p_templateFunc(&this); // Create a new job object m_job = new COptimizationJob(0, m_stage, m_symbol, m_timeframe, params); // Insert it into the optimization database m_job.Insert(); // Add it to the array of all jobs APPEND(m_jobs, m_job); // Add it to the array of current stage jobs APPEND(m_stage.jobs, m_job); } } return &this; }
O terceiro argumento desses métodos é um ponteiro para a função responsável por gerar os parâmetros de otimização dos EAs das etapas.
Classe COptimizationStage
A descrição dessa classe possui muitos atributos em comparação com as outras classes, mas isso se deve apenas ao fato de que a tabela stages no banco de dados de otimização contém muitos campos. Cada um deles tem um campo correspondente nesta classe. Observe também que o construtor da etapa recebe um ponteiro para o objeto do projeto ao qual essa etapa pertence, além de um ponteiro para o objeto da etapa anterior. Para a primeira etapa, não há etapa anterior, portanto, neste caso, passamos o valor NULL.
//+------------------------------------------------------------------+ //| Optimization stage class | //+------------------------------------------------------------------+ class COptimizationStage { public: ulong id_stage; ulong id_project; ulong id_parent_stage; string name; string expert; string symbol; string period; int optimization; int model; datetime from_date; datetime to_date; int forward_mode; datetime forward_date; int deposit; string currency; int profit_in_pips; int leverage; int execution_mode; int optimization_criterion; string status; COptimizationProject* project; COptimizationStage* parent_stage; COptimizationJob* jobs[]; COptimizationStage(ulong p_idStage, COptimizationProject* p_project, COptimizationStage* parentStage, string p_name, string p_expertName, string p_symbol = "GBPUSD", string p_timeframe = "H1", int p_optimization = 0, int p_model = 0, datetime p_fromDate = 0, datetime p_toDate = 0, int p_forwardMode = 0, datetime p_forwardDate = 0, int p_deposit = 10000, string p_currency = "USD", int p_profitInPips = 0, int p_leverage = 200, int p_executionMode = 0, int p_optimizationCriterion = 7, string p_status = "Done") : id_stage(p_idStage), project(p_project), id_project(!!p_project ? p_project.id_project : 0), parent_stage(parentStage), id_parent_stage(!!parentStage ? parentStage.id_stage : 0), name(p_name), expert(p_expertName), symbol(p_symbol), period(p_timeframe), optimization(p_optimization), model(p_model), from_date(p_fromDate), to_date(p_toDate), forward_mode(p_forwardMode), forward_date(p_forwardDate), deposit(p_deposit), currency(p_currency), profit_in_pips(p_profitInPips), leverage(p_leverage), execution_mode(p_executionMode), optimization_criterion(p_optimizationCriterion), status(p_status) {} // Create a stage in the database void Insert(); }; //+------------------------------------------------------------------+ //| Create a stage in the database | //+------------------------------------------------------------------+ void COptimizationStage::Insert() { string query = StringFormat("INSERT INTO stages VALUES(" "%s," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "%s," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ");", (id_stage == 0 ? "NULL" : (string) id_stage), // id_stage id_project, // id_project (id_parent_stage == 0 ? "NULL" : (string) id_parent_stage), // id_parent_stage name, // name expert, // expert symbol, // symbol period, // period optimization, // optimization model, // model TimeToString(from_date, TIME_DATE), // from_date TimeToString(to_date, TIME_DATE), // to_date forward_mode, // forward_mode (forward_mode == 4 ? "'" + TimeToString(forward_date, TIME_DATE) + "'" : "NULL"), // forward_date deposit, // deposit currency, // currency profit_in_pips, // profit_in_pips leverage, // leverage execution_mode, // execution_mode optimization_criterion, // optimization_criterion status // status ); PrintFormat(__FUNCTION__" | %s", query); id_stage = DB::Insert(query); }
A lógica das ações realizadas tanto no construtor quanto no método de inserção de novo registro na tabela stages é bastante simples: armazenamos os valores passados como argumentos nos atributos do objeto e usamos esses valores para formar a consulta SQL que insere o registro na tabela correspondente do banco de dados de otimização.
Classe COptimizationJob
Esta classe possui a mesma estrutura da classe COptimizationStage. O construtor armazena os parâmetros, e o método Insert() insere uma nova linha na tabela de trabalhos jobs no banco de dados de otimização. Também é passado, na criação de cada objeto de trabalho, um ponteiro para o objeto da etapa à qual esse trabalho pertence.
//+------------------------------------------------------------------+ //| Optimization job class | //+------------------------------------------------------------------+ class COptimizationJob { public: ulong id_job; // job ID ulong id_stage; // stage ID string symbol; // Symbol string timeframe; // Timeframe string params; // Optimizer operation parameters string status; // Status COptimizationStage* stage; // Stage a job belongs to COptimizationTask* tasks[]; // Array of tasks related to the job // Constructor COptimizationJob(ulong p_jobId, COptimizationStage* p_stage, string p_symbol, string p_timeframe, string p_params, string p_status = "Done"); // Create a job in the database void Insert(); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ COptimizationJob::COptimizationJob(ulong p_jobId, COptimizationStage* p_stage, string p_symbol, string p_timeframe, string p_params, string p_status = "Done") : id_job(p_jobId), stage(p_stage), id_stage(!!p_stage ? p_stage.id_stage : 0), symbol(p_symbol), timeframe(p_timeframe), params(p_params), status(p_status) {} //+------------------------------------------------------------------+ //| Create a job in the database | //+------------------------------------------------------------------+ void COptimizationJob::Insert() { // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','%s');", id_stage, symbol, timeframe, params, status); id_job = DB::Insert(query); PrintFormat(__FUNCTION__" | %s -> %I64u", query, id_job); }
O último restante, o COptimizationTask, é construído da mesma forma, por isso não traremos seu código aqui.
Reescrevendo o CreateProject.mq5
Vamos voltar ao arquivo CreateProject.mq5 e observar quais são os principais parâmetros contidos nele. Esse arquivo está na parte de projeto, o que significa que podemos especificar, para cada projeto individual, os valores padrão dos parâmetros, evitando assim a necessidade de alterá-los na hora da execução.
Primeiramente, indicamos o nome do banco de dados de otimização:
input string fileName_ = "article.17328.db.sqlite"; // - Optimization database file
Na próxima seção de parâmetros, indicamos, separados por vírgula, os símbolos e os timeframes em que será realizada a otimização dos EAs da primeira e da segunda etapa:
input string symbols_ = "GBPUSD,EURUSD,EURGBP"; // - Symbols input string timeframes_ = "H1,M30"; // - Timeframes
Com essa escolha, serão criados seis trabalhos, um para cada combinação possível entre os três símbolos e os dois timeframes.
Em seguida, fazemos a escolha do intervalo no qual será realizada a otimização:
input group "::: Project parameters - Optimization interval" input datetime fromDate_ = D'2022-09-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
No grupo de parâmetros relacionados à conta, escolhemos o símbolo principal que será utilizado na terceira etapa, quando o testador executará o EA com múltiplos símbolos. Essa escolha se torna importante quando entre os símbolos há algum que continue sendo negociado durante os finais de semana (como criptomoedas, por exemplo). Nesse caso, é fundamental escolher justamente esse como o principal; do contrário, durante os passes, o testador não irá gerar ticks nos dias de fim de semana.
input group "::: Project parameters - Account" input string mainSymbol_ = "GBPUSD"; // - Main symbol input int deposit_ = 10000; // - Initial deposit
No grupo de parâmetros da primeira etapa, indicamos o nome do EA, que, na prática, pode ser sempre o mesmo. Em seguida, especificamos os critérios de otimização que serão utilizados em cada trabalho da primeira etapa. São apenas números separados por vírgulas. O valor 6, por exemplo, corresponde a um critério de otimização definido pelo usuário.
input group "::: Stage 1. Search" input string stage1ExpertName_ = "Stage1.ex5"; // - Stage EA input string stage1Criterions_ = "6,6,6"; // - Optimization criteria for tasks
Neste caso, indicamos três vezes o critério de usuário, o que significa que cada trabalho conterá três tarefas de otimização com o critério especificado.
No grupo de parâmetros da segunda etapa, adicionamos a possibilidade de especificar todos os valores dos parâmetros do EA, e não apenas o nome e o número de estratégias no grupo. Esses parâmetros afetam a seleção dos passes da primeira etapa, cujos parâmetros participarão da formação dos grupos na segunda etapa.
input group "::: Stage 2. Grouping" input string stage2ExpertName_ = "Stage2.ex5"; // - Stage EA input string stage2Criterion_ = "6"; // - Optimization criterion for tasks //input bool stage2UseClusters_= false; // - Use clustering? input double stage2MinCustomOntester_ = 500; // - Min value of norm. profit input uint stage2MinTrades_ = 20; // - Min number of trades input double stage2MinSharpeRatio_ = 0.7; // - Min Sharpe ratio input uint stage2Count_ = 8; // - Number of strategies in the group
Assim, por exemplo, com o valor do parâmetro stage2MinTrades_ = 20, somente instâncias individuais de estratégias que tenham realizado pelo menos 20 operações na primeira etapa poderão entrar no grupo. O parâmetro stage2UseClusters_ está, por enquanto, comentado, já que não estamos utilizando a clusterização dos resultados da segunda etapa no momento. Portanto, deve ser atribuído a ele o valor false.
No grupo de parâmetros da terceira etapa, também adicionamos alguns elementos. Além do nome do EA da terceira etapa (que igualmente pode permanecer o mesmo entre diferentes projetos), surgiram dois parâmetros que controlam a formação do nome do banco de dados do EA final. No próprio EA final, esse nome é gerado na função CVirtualAdvisor::FileName() de acordo com o seguinte modelo:
<Project name>-<Magic>.test.db.sqlite // To run in the tester <Project name>-<Magic>.db.sqlite // To run on a trading account
Por isso, o EA da terceira etapa utiliza o mesmo modelo. Para substituir <Nome do projeto>, é usado o parâmetro projectName_, e para <Magic>, é usado stage3Magic_. O parâmetro stage3Tester_ define se será adicionado o sufixo ".test".
input group "::: Stage 3. Result" input string stage3ExpertName_ = "Stage3.ex5"; // - Stage EA input ulong stage3Magic_ = 27183; // - Magic input bool stage3Tester_ = true; // - For the tester?
Na prática, poderíamos ter criado um único parâmetro no qual fosse indicado diretamente o nome completo do banco de dados do EA final. Após a conclusão da terceira etapa, o arquivo gerado dessa base de dados pode ser renomeado livremente antes do uso posterior.
Agora só falta criarmos as funções de geração dos parâmetros dos EAs das etapas, com base nos templates definidos. Como estamos utilizando três etapas, serão necessárias três funções.
Para a primeira etapa, a função será semelhante a esta:
// Template of optimization parameters at the first stage string paramsTemplate1(COptimizationProject *p) { string params = StringFormat( "symbol_=%s\n" "period_=%d\n" "; === Open signal parameters\n" "signalSeqLen_=4||2||1||8||Y\n" "periodATR_=21||7||2||48||Y\n" "; === Pending order parameters\n" "stopLevel_=2.34||0.01||0.01||5.0||Y\n" "takeLevel_=4.55||0.01||0.01||5.0||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=15||1||1||30||Y\n", p.m_symbol, p.StringToTimeframe(p.m_timeframe)); return params; }
A base dela é composta pelos parâmetros de otimização do EA da primeira etapa copiados do testador de estratégias, com os intervalos desejados já definidos para cada parâmetro de entrada. Nessa string são inseridos os valores do símbolo e do timeframe que, no momento da chamada dessa função, estão sendo utilizados para criar o objeto de trabalho do projeto. Se, por exemplo, for necessário usar intervalos diferentes de parâmetros de entrada para algum timeframe específico, essa lógica poderá ser implementada diretamente dentro desta função.
Ao mudar de projeto, com outra estratégia de negociação, essa função deverá ser substituída por uma nova, feita especialmente para a nova estratégia e seu conjunto de parâmetros de entrada.
Para a segunda e terceira etapas, também criamos as implementações dessas funções no arquivo CreateProject.mq5, mas, ao mudar de projeto, provavelmente não será necessário modificá-las. Ainda assim, por ora, não vamos movê-las para a parte da biblioteca, portanto elas continuarão aqui:
// Template of optimization parameters for the second stage string paramsTemplate2(COptimizationProject *p) { // Find the parent job ID for the current job // by matching the symbol and timeframe at the current and parent stages int i; SEARCH(p.m_stage.parent_stage.jobs, (p.m_stage.parent_stage.jobs[i].symbol == p.m_symbol && p.m_stage.parent_stage.jobs[i].timeframe == p.m_timeframe), i); ulong parentJobId = p.m_stage.parent_stage.jobs[i].id_job; string params = StringFormat( "idParentJob_=%I64u\n" "useClusters_=%s\n" "minCustomOntester_=%f\n" "minTrades_=%u\n" "minSharpeRatio_=%.2f\n" "count_=%u\n", parentJobId, (string) false, //(string) stage2UseClusters_, stage2MinCustomOntester_, stage2MinTrades_, stage2MinSharpeRatio_, stage2Count_ ); return params; } // Template of optimization parameters at the third stage string paramsTemplate3(COptimizationProject *p) { string params = StringFormat( "groupName_=%s\n" "advFileName_=%s\n" "passes_=\n", StringFormat("%s_v.%s_%s", p.name, p.version, TimeToString(toDate_, TIME_DATE)), StringFormat("%s-%I64u%s.db.sqlite", p.name, stage3Magic_, (stage3Tester_ ? ".test" : ""))); return params; }
A seguir, temos o código da função de inicialização, que executa todo o processo e, ao final, remove o EA do gráfico. Agora já podemos mostrar esse código com os parâmetros usados nas chamadas de função:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create an optimization project object for the given database COptimizationProject p(fileName_); // Create a new project in the database p.Create(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE))); // Add the first stage p.AddStage(NULL, "First", stage1ExpertName_, mainSymbol_, "H1", 2, 2, fromDate_, toDate_, 0, 0, deposit_); // Adding the first stage jobs p.AddJobs(symbols_, timeframes_, paramsTemplate1); // Add tasks for the first stage jobs p.AddTasks(stage1Criterions_); // Add the second stage p.AddStage(p.m_stages[0], "Second", stage2ExpertName_, mainSymbol_, "H1", 2, 2, fromDate_, toDate_, 0, 0, deposit_); // Add the second stage jobs p.AddJobs(symbols_, timeframes_, paramsTemplate2); // Add tasks for the second stage jobs p.AddTasks(stage2Criterion_); // Add the third stage p.AddStage(p.m_stages[1], "Save to library", stage3ExpertName_, mainSymbol_, "H1", 0, 2, fromDate_, toDate_, 0, 0, deposit_); // Add the third stage job p.AddJobs(mainSymbol_, "H1", paramsTemplate3); // Add a task for the third stage job p.AddTasks("0"); // Put the project in the execution queue p.Queue(); // Delete the EA ExpertRemove(); // Successful initialization return(INIT_SUCCEEDED); }
Essa parte do código também não precisará ser modificada ao trocar de projeto, desde que não queiramos alterar a estrutura das etapas do pipeline de otimização automática. Com o tempo, também iremos aprimorá-la. Por exemplo, atualmente há constantes numéricas no código que, por questões de legibilidade, devem ser substituídas por constantes nomeadas. Se constatarmos que esse trecho realmente não precisa de alterações, poderemos movê-lo completamente para a parte da biblioteca.
Com isso, o EA de criação de projetos de otimização no banco de dados está pronto. Agora vamos criar os EAs das etapas.
EAs das etapas
O EA da primeira etapa, Stage1.mq5, já havia sido feito na parte anterior, por isso agora apenas realizamos nele as alterações relacionadas à adição do novo parâmetro maxSpread_ na estratégia de negociação. Essas mudanças já foram detalhadas anteriormente.
// 1. Define a constant with the EA name #define __NAME__ "SimpleCandles" + MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; // 3. Connect the general part of the first stage EA from the Advisor library #include <antekov/Advisor/Experts/Stage1.mqh> //+------------------------------------------------------------------+ //| 4. Strategy inputs | //+------------------------------------------------------------------+ sinput string symbol_ = ""; // Symbol sinput ENUM_TIMEFRAMES period_ = PERIOD_CURRENT; // Timeframe for candles input group "=== Opening signal parameters" input int signalSeqLen_ = 6; // Number of unidirectional candles input int periodATR_ = 0; // ATR period (if 0, then TP/SL in points) input group "=== Pending order parameters" input double stopLevel_ = 25000; // Stop Loss (in ATR fraction or points) input double takeLevel_ = 3630; // Take Profit (in ATR fraction or points) input group "=== Money management parameters" input int maxCountOfOrders_ = 9; // Max number of simultaneously open orders input int maxSpread_ = 10; // Max acceptable spread (in points) //+------------------------------------------------------------------+ //| 5. Strategy initialization string generation function | //| from the inputs | //+------------------------------------------------------------------+ string GetStrategyParams() { return StringFormat( "class CSimpleCandlesStrategy(\"%s\",%d,%d,%d,%.3f,%.3f,%d,%d)", (symbol_ == "" ? Symbol() : symbol_), period_, signalSeqLen_, periodATR_, stopLevel_, takeLevel_, maxCountOfOrders_, maxSpread_ ); }
Nos EAs da segunda e da terceira etapa, basta definir a constante __NAME__ com um nome único para o EA e incluir o arquivo ou arquivos das estratégias de negociação utilizadas. O restante do código será extraído do arquivo da biblioteca correspondente à etapa. Veja como pode ser o código do EA da segunda etapa, Stage2.mq5:
// 1. Define a constant with the EA name #define __NAME__ "SimpleCandles" + MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; #include <antekov/Advisor/Experts/Stage2.mqh>
e da terceira etapa, Stage3.mq5:
// 1. Define a constant with the EA name #define __NAME__ "SimpleCandles" + MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; #include <antekov/Advisor/Experts/Stage3.mqh>
EA final
No EA final, precisamos apenas adicionar a inclusão da estratégia utilizada. A constante __NAME__ não deve ser declarada aqui, pois, nesse caso, tanto ela quanto a função de formação da string de inicialização já estarão declaradas no arquivo incluído da parte da biblioteca. No trecho de código abaixo, mostramos em comentários quais serão, nesse caso, o nome do EA e a função responsável por gerar a string de inicialização:
// 1. Define a constant with the EA name //#define __NAME__ MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; #include <antekov/Advisor/Experts/Expert.mqh> //+------------------------------------------------------------------+ //| Function for generating the strategy initialization string | //| from the default inputs (if no name was specified). | //| Import the initialization string from the EA database | //| by the strategy group ID | //+------------------------------------------------------------------+ //string GetStrategyParams() { //// Take the initialization string from the new library for the selected group //// (from the EA database) // string strategiesParams = CVirtualAdvisor::Import( // CVirtualAdvisor::FileName(__NAME__, magic_), // groupId_ // ); // //// If the strategy group from the library is not specified, then we interrupt the operation // if(strategiesParams == NULL && useAutoUpdate_) { // strategiesParams = ""; // } // // return strategiesParams; //}
Se, por algum motivo, quisermos alterar algum desses elementos, basta remover os comentários do respectivo trecho de código e fazer as alterações desejadas.
Dessa forma, na parte de projeto teremos os seguintes arquivos:
Compilamos todos os arquivos da parte de projeto para que, para cada arquivo com extensão mq5, seja gerado um arquivo com extensão ex5.
Montando tudo
Passo 1. Criação do projeto
Arrastamos o EA CreateProject.ex5 para qualquer gráfico no terminal (este EA não deve ser executado no testador!). No código-fonte deste EA, já definimos os valores atualizados para todos os parâmetros de entrada, portanto, na janela que aparecer, basta clicar em OK.
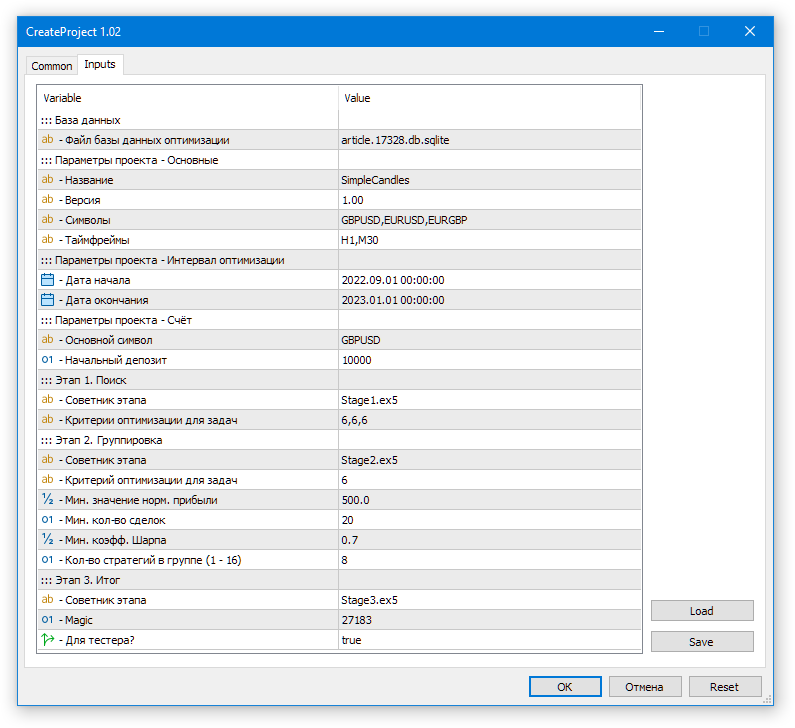
Fig. 1. Execução do EA de criação do projeto no banco de dados de otimização
Como resultado, será criado na pasta comum dos terminais um arquivo chamado article.17328.db.sqlite, contendo o banco de dados de otimização.
Passo 2. Início da otimização
Arrastamos o EA Optimization.ex5 para qualquer gráfico (este EA também não deve ser executado no testador!). Na janela que se abrir, habilitamos o uso de DLLs e, na aba de parâmetros, verificamos se o nome do banco de dados de otimização está correto:
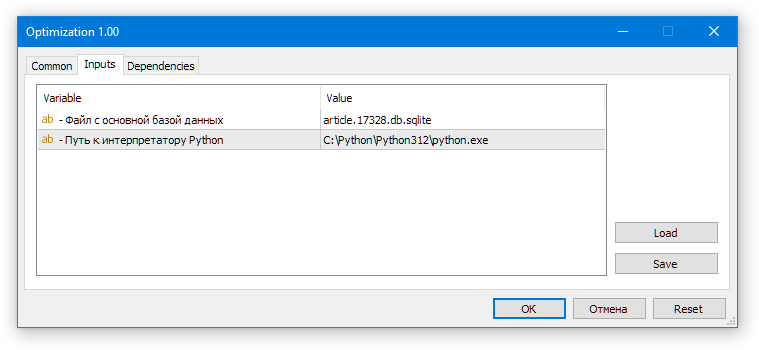
Fig. 2. Execução do EA de otimização automática
Se tudo estiver certo, devemos ver algo parecido com isso: o testador inicia a otimização do EA da primeira etapa com o primeiro par símbolo-timeframe, e no gráfico onde o EA Optimization.ex5 foi iniciado será exibido: “Total tasks in queue: ..., Current Task ID: ...”.
Fig. 3. Funcionamento do EA de otimização automática.
Depois, é necessário aguardar algum tempo até que todas as tarefas de otimização sejam concluídas. Esse tempo pode ser considerável caso o intervalo de teste seja longo e haja muitos símbolos e timeframes. Com os parâmetros padrão atuais e 33 agentes, todo o processo levou cerca de quatro horas.
Na última etapa do pipeline, nenhuma otimização é realizada, sendo apenas executado um único passe do EA da terceira etapa. Como resultado, será gerado um arquivo de banco de dados do EA final. Como escolhemos, ao criar o projeto, o nome "SimpleCandles", o número mágico 27183, e definimos o valor do parâmetro de entrada stage3Tester_=true, será criado na pasta comum dos terminais um arquivo com o nome SimpleCandles-27183.test.db.sqlite.
Passo 3. Execução do EA final no testador
Vamos tentar executar o EA final no testador. Como o código dele atualmente é totalmente extraído da parte da biblioteca, os valores padrão dos parâmetros de entrada também estão definidos ali. Portanto, ao executarmos no testador o EA SimpleCandles.ex5 sem alterar os valores dos parâmetros, ele usará o último grupo de estratégias adicionado (groupId_= 0), com atualização automática ativada (useAutoUpdate_= true), a partir do arquivo de banco de dados com o nome SimpleCandles-27183.test.db.sqlite (nome do EA: SimpleCandles, mais o número mágico padrão magic_= 27183, e o sufixo ".test" por estar sendo executado no testador).
Infelizmente, ainda não criamos nenhuma ferramenta específica para visualizar os identificadores dos grupos de estratégias existentes no banco de dados do EA final. A única forma, por enquanto, é abrir o próprio banco de dados com algum editor SQLite e verificar a tabela strategy_groups.
No entanto, se apenas um projeto de otimização tiver sido criado e executado uma única vez, então o banco de dados do EA final conterá somente um grupo de estratégias com o identificador 1. Portanto, nesse caso, não faz diferença se agora indicarmos explicitamente groupId_= 1 ou deixarmos groupId_= 0. De qualquer forma, será carregado o único grupo existente. Já se executarmos esse mesmo projeto novamente (o que pode ser feito alterando diretamente o status do projeto no banco de dados) ou criarmos outro projeto igual e o executarmos, novos grupos de estratégias começarão a ser adicionados ao banco de dados do EA final. Nesse cenário, valores diferentes para o parâmetro groupId_, resultarão na utilização de diferentes grupos.
O parâmetro que ativa a atualização automática (useAutoUpdate_= true) também merece atenção. Mesmo havendo apenas um grupo, esse parâmetro afeta o funcionamento do EA final. Isso ocorre porque, com a atualização automática ativada, somente os grupos de estratégias cuja data de criação seja anterior à data atual simulada poderão ser carregados.
Isso significa que, se executarmos o EA final no mesmo intervalo usado durante a otimização (2022.09.01 - 2023.01.01), nosso único grupo de estratégias não será carregado, pois ele tem como data de criação o dia 2023.01.01. Portanto, será necessário ou desativar a atualização automática (useAutoUpdate_ = false) e especificar diretamente o identificador do grupo de estratégias (groupId_ = 1) nos parâmetros de entrada ao iniciar o EA final, ou escolher um intervalo diferente, posterior à data final do intervalo de otimização.
De modo geral, enquanto ainda não tivermos definido quais estratégias serão usadas no EA final, e tampouco estivermos focados em avaliar a viabilidade da reotimização periódica, podemos simplesmente definir esse parâmetro como false e indicar diretamente o identificador do grupo de estratégias a ser utilizado.
O último conjunto de parâmetros importantes determina qual nome de banco de dados será usado pelo EA final. Nas configurações padrão dele, o número mágico coincide com o que foi definido durante a criação do projeto. Também fizemos com que o nome do arquivo do EA final fosse igual ao nome do projeto. E o valor do parâmetro stage3Tester_ na criação do projeto estava definido como true, por isso o nome do arquivo gerado do banco de dados do EA final será SimpleCandles-27183.test.db.sqlite. Esse nome coincide exatamente com o que será utilizado pelo EA final SimpleCandles.ex5.
Vamos observar os resultados da execução do EA final no intervalo de otimização:
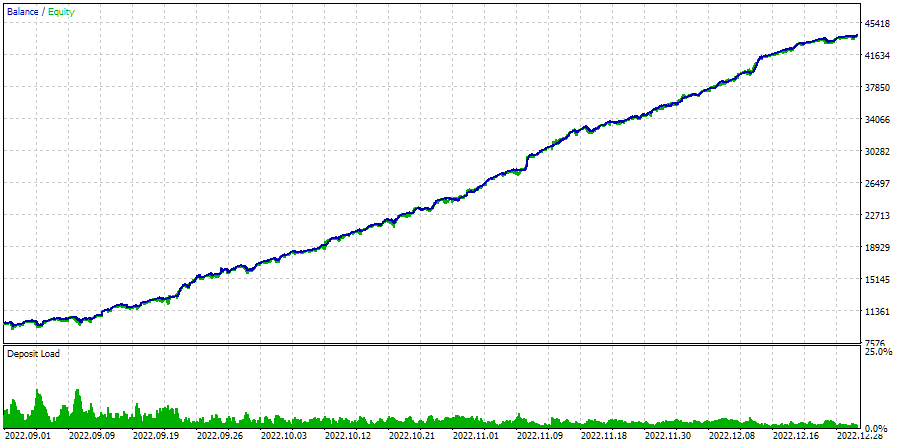
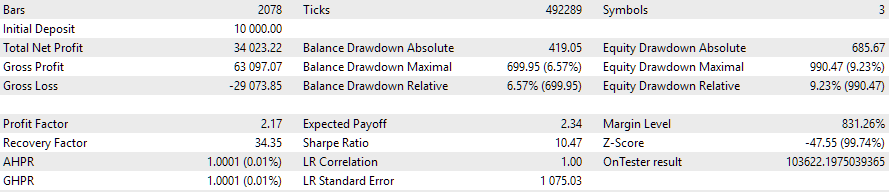
Fig. 4. Funcionamento do EA de otimização automática no intervalo 2022.09.01 - 2023.01.01
Se executarmos o EA em um outro intervalo de tempo, provavelmente os resultados não serão tão bons:
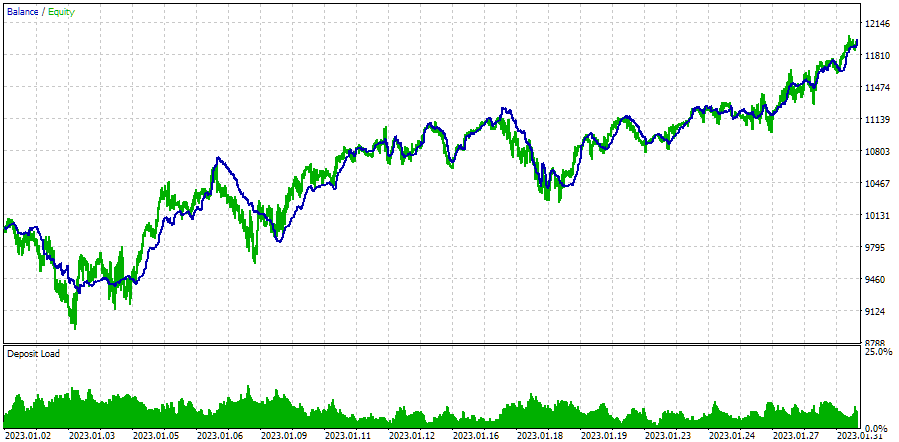
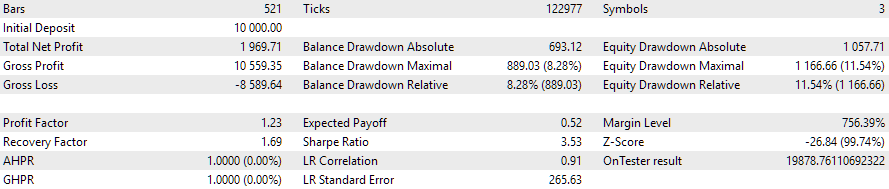
Fig. 5. Funcionamento do EA de otimização automática no intervalo 2023.01.01 - 2023.02.01
Pegamos como exemplo um intervalo de um mês, logo após o período de otimização. De fato, o drawdown superou ligeiramente o valor esperado de 10%, e o lucro normalizado caiu cerca de cinco vezes. Será que é possível realizar uma nova otimização com base nos últimos três meses e obter um comportamento semelhante do EA durante o mês seguinte? Essa questão ainda permanece em aberto.
Passo 4. Execução do EA final em conta real
Para executar o EA final em uma conta de negociação, precisaremos ajustar o nome do arquivo de banco de dados gerado. O sufixo ".test" deve ser removido do nome. Em outras palavras, basta renomear ou copiar o arquivo SimpleCandles-27183.test.db.sqlite para SimpleCandles-27183.db.sqlite. O local do arquivo permanece o mesmo, isto é, na pasta comum dos terminais.
Arrastamos o EA final SimpleCandles.ex5 para qualquer gráfico do terminal. Nos parâmetros de entrada, podemos deixar tudo com os valores padrão, já que nos atende perfeitamente carregar o grupo de estratégias mais recente, e a data atual certamente será posterior à data de criação desse grupo.
Fig. 6. Parâmetros de entrada padrão para o EA final
Enquanto este artigo estava sendo escrito, esse EA final já havia operado em uma conta demo por cerca de uma semana, apresentando os seguintes resultados:
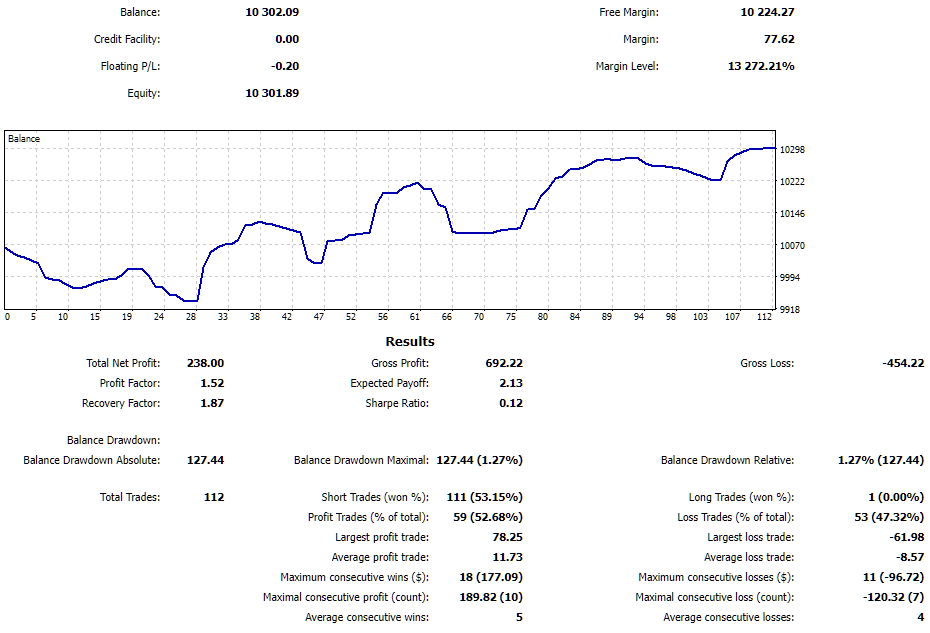
Fig. 7. Resultados do funcionamento do EA final em conta de negociação
A semana foi bastante positiva para o EA. Com um drawdown de 1,27%, obteve lucro em torno de 2%. Houve alguns reinícios do EA por conta de reinicializações do computador, mas ele conseguiu restaurar com sucesso as informações das posições virtuais abertas e seguiu operando normalmente.
Considerações finais
Vejamos o que conseguimos alcançar. Finalmente reunimos os resultados de um longo processo de desenvolvimento em algo que começa a se assemelhar a um sistema completo. A ferramenta criada para organizar a otimização automática e o teste de estratégias de negociação permite melhorar significativamente os resultados dos testes, mesmo para estratégias simples, graças à diversificação entre diferentes instrumentos de negociação.
Ela também reduz drasticamente a quantidade de ações que exigem intervenção manual para atingir os mesmos objetivos. Agora, não é mais necessário acompanhar o momento em que um processo de otimização termina para iniciar o próximo, nem se preocupar com a forma de salvar os resultados intermediários das otimizações e incorporá-los posteriormente ao EA. Podemos focar diretamente no desenvolvimento da lógica das estratégias de negociação.
É claro que ainda há muito o que melhorar em termos de desempenho e conveniência dessa ferramenta. Nos planos de longo prazo, ainda permanece a ideia de criar uma interface web completa, capaz de gerenciar não apenas a criação, o lançamento e o monitoramento do estado dos projetos de otimização em execução, mas também o controle dos EAs rodando em diferentes terminais, com acesso às suas estatísticas. Trata-se de uma tarefa de grande escala, mas, olhando para trás, o mesmo podia ser dito sobre o desafio que hoje já alcançou uma solução quase completa.
Obrigado pela atenção e até a próxima!
Aviso importante
Todos os resultados apresentados neste artigo e nos anteriores deste ciclo são baseados exclusivamente em dados de testes históricos e não constituem garantia de qualquer lucro futuro. O trabalho realizado neste projeto tem caráter puramente experimental. Todos os resultados publicados podem ser utilizados livremente por qualquer pessoa, por sua conta e risco.
Conteúdo do arquivo
| # | Nome | Versão | Descrição | Últimas alterações |
|---|---|---|---|---|
| MQL5/Experts/Article.17328 | Pasta de trabalho do projeto | |||
| 1 | CreateProject.mq5 | 1.02 | EA-script para criação de projeto com etapas, trabalhos e tarefas de otimização. | Parte 25 |
| 2 | Optimization.mq5 | 1.00 | EA para otimização automática de projetos. | Parte 23 |
| 3 | SimpleCandles.mq5 | 1.01 | EA final para execução paralela de múltiplos grupos de estratégias-modelo. Os parâmetros são obtidos da biblioteca interna de grupos. | Parte 25 |
| 4 | Stage1.mq5 | 1.02 | EA de otimização de uma única instância de estratégia de negociação (Etapa 1). | Parte 25 |
| 5 | Stage2.mq5 | 1.01 | EA de otimização de grupo de instâncias de estratégias de negociação (Etapa 2). | Parte 25 |
| 6 | Stage3.mq5 | 1.01 | EA que grava o grupo de estratégias normalizadas formado no banco de dados do Expert Advisor com o nome especificado. | Parte 25 |
| MQL5/Experts/Article.17328/Strategies | Pasta das estratégias do projeto | |||
| 7 | SimpleCandlesStrategy.mqh | 1.01 | Classe da estratégia de negociação SimpleCandles | Parte 25 |
| MQL5/Include/antekov/Advisor/Base | Classes base das quais herdam outras classes do projeto | |||
| 8 | Advisor.mqh | 1.04 | Classe base do Expert Advisor | Parte 10 |
| 9 | Factorable.mqh | 1.05 | Classe base para objetos criados a partir de uma string | Parte 24 |
| 10 | FactorableCreator.mqh | 1.00 | Parte 24 | |
| 11 | Interface.mqh | 1.01 | Classe base para visualização de diferentes objetos | Parte 4 |
| 12 | Receiver.mqh | 1.04 | Classe base para conversão de volumes abertos em posições de mercado | Parte 12 |
| 13 | Strategy.mqh | 1.04 | Classe base da estratégia de negociação | Parte 10 |
| MQL5/Include/antekov/Advisor/Database | Arquivos para trabalho com todos os tipos de bancos de dados utilizados pelos EAs do projeto | |||
| 14 | Database.mqh | 1.12 | Classe para trabalhar com o banco de dados | Parte 25 |
| 15 | db.adv.schema.sql | 1.00 | Esquema do banco de dados do EA final | Parte 22 |
| 16 | db.cut.schema.sql | 1.00 | Esquema do banco de dados de otimização reduzido | Parte 22 |
| 17 | db.opt.schema.sql | 1.05 | Esquema do banco de dados de otimização | Parte 22 |
| 18 | Storage.mqh | 1.01 | Classe para trabalhar com o armazenamento Chave-Valor para o EA final no banco de dados do Expert | Parte 23 |
| MQL5/Include/antekov/Advisor/Experts | Arquivos com as partes comuns dos EAs de diferentes tipos utilizados | |||
| 19 | Expert.mqh | 1.22 | Arquivo de biblioteca para o EA final. Os parâmetros dos grupos podem ser obtidos do banco de dados do Expert | Parte 23 |
| 20 | Optimization.mqh | 1.04 | Arquivo de biblioteca para o EA que gerencia a execução das tarefas de otimização | Parte 23 |
| 21 | Stage1.mqh | 1.19 | Arquivo de biblioteca para o EA de otimização de uma única instância de estratégia de negociação (Etapa 1) | Parte 23 |
| 22 | Stage2.mqh | 1.04 | Arquivo de biblioteca para o EA de otimização de grupo de instâncias de estratégias de negociação (Etapa 2) | Parte 23 |
| 23 | Stage3.mqh | 1.04 | Arquivo de biblioteca para o EA que grava o grupo de estratégias normalizadas formado no banco de dados do Expert com o nome especificado. | Parte 23 |
| MQL5/Include/antekov/Advisor/Optimization | Classes responsáveis pelo funcionamento da otimização automática | |||
| 24 | OptimizationJob.mqh | 1.00 | Classe para o trabalho da etapa do projeto de otimização | Parte 25 |
| 25 | OptimizationProject.mqh | 1.00 | Classe para o projeto de otimização | Parte 25 |
| 26 | OptimizationStage.mqh | 1.00 | Classe para a etapa do projeto de otimização | Parte 25 |
| 27 | OptimizationTask.mqh | 1.00 | Classe para a tarefa de otimização (para criação) | Parte 25 |
| 28 | Optimizer.mqh | 1.03 | Classe para o gerenciador de otimização automática de projetos | Parte 22 |
| 29 | OptimizerTask.mqh | 1.03 | Classe para a tarefa de otimização (para o pipeline) | Parte 22 |
| MQL5/Include/antekov/Advisor/Strategies | Exemplos de estratégias de negociação usadas para demonstrar o funcionamento do projeto | |||
| 30 | HistoryStrategy.mqh | 1.00 | Classe da estratégia de negociação para reprodução do histórico de operações | Parte 16 |
| 31 | SimpleVolumesStrategy.mqh | 1.11 | Classe da estratégia de negociação baseada em volumes de ticks | Parte 22 |
| MQL5/Include/antekov/Advisor/Utils | Utilitários auxiliares e macros para redução de código | |||
| 32 | ExpertHistory.mqh | 1.00 | Classe para exportar o histórico de operações para arquivo | Parte 16 |
| 33 | Macros.mqh | 1.06 | Macros úteis para operações com arrays | Parte 25 |
| 34 | NewBarEvent.mqh | 1.00 | Classe para detecção de novo candle para um símbolo específico | Parte 8 |
| 35 | SymbolsMonitor.mqh | 1.00 | Classe para obtenção de informações sobre instrumentos de negociação (símbolos) | Parte 21 |
| MQL5/Include/antekov/Advisor/Virtual | Classes destinadas à criação de diversos objetos unificados pelo uso do sistema de ordens e posições virtuais | |||
| 36 | Money.mqh | 1.01 | Classe base de gerenciamento de capital | Parte 12 |
| 37 | TesterHandler.mqh | 1.07 | Classe para tratamento de eventos de otimização | Parte 23 |
| 38 | VirtualAdvisor.mqh | 1.10 | Classe do Expert Advisor que trabalha com posições virtuais (ordens) | Parte 24 |
| 39 | VirtualChartOrder.mqh | 1.01 | Classe de posição virtual exibida graficamente | Parte 18 |
| 40 | VirtualHistoryAdvisor.mqh | 1.00 | Classe do EA de reprodução do histórico de operações | Parte 16 |
| 41 | VirtualInterface.mqh | 1.00 | Classe da interface gráfica do EA | Parte 4 |
| 42 | VirtualOrder.mqh | 1.09 | Classe de ordens e posições virtuais | Parte 22 |
| 43 | VirtualReceiver.mqh | 1.04 | Classe de conversão de volumes abertos em posições de mercado (receptor) | Parte 23 |
| 44 | VirtualRiskManager.mqh | 1.05 | Classe de gerenciamento de risco (risk manager) | Parte 24 |
| 45 | VirtualStrategy.mqh | 1.09 | Classe da estratégia de negociação com posições virtuais | Parte 23 |
| 46 | VirtualStrategyGroup.mqh | 1.03 | Classe de grupo de estratégias de negociação ou grupos de estratégias agrupadas | Parte 24 |
| 47 | VirtualSymbolReceiver.mqh | 1.00 | Classe de receptor vinculado a um símbolo | Parte 3 |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17328
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Antes de mais nada, gostaria de saber em que idioma isso está escrito.
É coreano, mas seu navegador não o mostra por algum motivo.
É coreano, mas seu navegador não o exibe por algum motivo.
Exatamente. Eu não publiquei nada neste tópico naquele dia, 2025.07.08, desde o início. Se você seguir esse link para o tópico, ele mostrará uma postagem com uma data diferente. Provavelmente também é culpa do meu navegador o fato de seus programadores restantes não conseguirem acompanhar o ritmo.
Exatamente. Eu não publiquei nada neste tópico naquele dia, 2025.07.08, desde o início. Se você seguir este link para o tópico, ele mostrará uma postagem com uma data diferente. Provavelmente também é culpa do meu navegador o fato de seus programadores restantes não conseguirem acompanhar o ritmo.
Obrigado por sua persistência, consertei o problema.
Obrigado por sua persistência, corrigido.
Desculpe a persistência, mas não vejo uma correção. O link ainda leva a uma mensagem estranha que não foi escrita por mim. Bem, mesmo se presumirmos que eu a escrevi, por que não há nenhuma mensagem em russo ao lado dela? Ou você acha que, se eu não consigo aprender inglês, aprendi coreano e estou me divertindo....
Essa é a diferença em uma discussão em idiomas diferentes.
Isso é do link.
Esta é a tradução russa.
E isso é o que está na versão russa do artigo.
Então, em que idioma eu estava tentando escrever????
Trata-se de um único tópico. E se você olhar os outros, encontrará mensagens de origem estranha em idiomas com os quais nunca sonhei.
Talvez eu tenha exagerado. Encontrei apenas uma outra mensagem semelhante, em inglês e provavelmente uma tradução real.
Por favor, exclua a mensagem acima em todas as versões de idioma e ela provavelmente será corrigida. Talvez não completamente como da última vez.......
Fórum sobre negociação, sistemas de negociação automatizados e teste de estratégias de negociação
Discussão do artigo "Developing a multicurrency Expert Advisor (Part 25): Inserção de uma nova estratégia (II)"
Rashid Umarov, 2025.07.06 14:04
Obrigado, vamos resolver o problema.
Já resolvemos esse problema, mas parece que ele não está completamente resolvido.