
Desenvolvendo um EA Multimoeda (Parte 13): Automação da segunda etapa — Seleção de grupos
Introdução
Após uma breve pausa para tratar do gerenciamento de risco no último artigo, voltamos ao foco principal do desenvolvimento : a automação dos testes. Em um dos artigos anteriores, delineamos algumas etapas que devem ser concluídas no processo de otimização e na busca dos melhores parâmetros para o EA final. A primeira etapa, em que otimizamos os parâmetros de uma instância individual da estratégia de trading, já foi realizada. Seus resultados foram armazenados em um banco de dados.
A próxima etapa é a seleção de grupos eficazes de instâncias individuais das estratégias de trading, que, ao trabalharem juntas, possam melhorar os parâmetros de negociação — reduzir a retração, aumentar a linearidade do crescimento do saldo, e assim por diante. Na sexta parte do ciclo de artigos, exploramos essa etapa manualmente. Inicialmente, selecionamos dos resultados da otimização aqueles parâmetros das instâncias individuais das estratégias de trading que mereciam atenção. Esse processo poderia seguir vários critérios, mas limitamo-nos à remoção dos resultados com lucro negativo. Em seguida, experimentamos diversas combinações de oito instâncias de estratégias de trading, agrupando-as em um único EA e executando testes para avaliar os parâmetros de desempenho conjunto.
Após iniciar com a seleção manual, implementamos a seleção automática de combinações de parâmetros de entrada das instâncias individuais das estratégias de trading, que eram retiradas de uma lista armazenada em um arquivo CSV. Constatamos que, mesmo no caso mais simples, ao executar a otimização genética com oito combinações, os resultados desejados eram alcançados.
Agora, vamos modificar o EA que realiza a otimização da seleção de grupos, para que ele possa usar os resultados da primeira etapa do banco de dados. Seus resultados também deverão ser armazenados no banco de dados. Analisaremos, ainda, a criação de tarefas para realizar otimizações da segunda etapa por meio da adição de registros necessários em nosso banco de dados.
Transferência de dados para agentes de testes
Para o EA anterior, voltado à seleção de grupos eficientes, tivemos que fazer alguns ajustes para possibilitar a otimização utilizando agentes de teste remotos. O problema era que o EA em otimização precisava ler dados de um arquivo CSV. Ao otimizar apenas no computador local, isso não gerava problemas — bastava colocar o arquivo de dados na pasta compartilhada do terminal, acessível a todos os agentes de teste locais.
No entanto, os agentes de teste remotos não têm acesso a esse arquivo de dados. Assim, utilizamos a diretiva #property tester_file, que permite transferir qualquer arquivo especificado para todos os agentes de teste em suas respectivas pastas de dados. Durante a execução da otimização, o arquivo de dados era copiado da pasta compartilhhada para a pasta de dados do agente local que iniciava o processo de otimização. Em seguida, esse arquivo era automaticamente distribuído para as pastas de dados dos demais agentes de teste.
Agora que os dados dos resultados de teste das instâncias individuais das estratégias de trading estão em um banco de dados SQLite, nossa primeira ideia foi seguir um procedimento semelhante. Como o banco de dados SQLite é composto por um único arquivo, ele também pode ser replicado para os agentes de teste remotos usando a diretiva mencionada. No entanto, há um detalhe importante: o arquivo CSV tinha cerca de 2 MB, enquanto o arquivo de banco de dados já ultrapassa 300 MB.
Essa diferença se deve ao fato de que, no banco de dados, procuramos armazenar a maior quantidade possível de informações estatísticas de cada execução, enquanto o arquivo CSV continha apenas alguns parâmetros estatísticos e valores dos parâmetros de entrada das instâncias das estratégias. Além disso, o banco de dados já reúne informações sobre os resultados da otimização em três símbolos diferentes e três timeframes distintos para cada símbolo. Ou seja, o número de execuções aumentou cerca de nove vezes.
Considerando que cada agente de teste recebe sua própria cópia do arquivo, a execução de testes em um servidor com 32 núcleos requer mais de 9 GB de dados. Se, na primeira etapa, forem processados ainda mais símbolos e timeframes, o volume do arquivo de banco de dados aumentará significativamente, podendo esgotar o espaço de armazenamento disponível nos servidores dos agentes e demandar um excesso de dados a serem transferidos pela rede.
Contudo, a maioria das informações armazenadas sobre os resultados das execuções do testador não será necessária na segunda etapa, ou ao menos não toda ao mesmo tempo. Ou seja, de todas as informações salvas para uma execução, precisamos extrair apenas a linha de inicialização do EA usada naquela execução. Planejamos, ainda, agrupar não apenas uma, mas várias instâncias individuais das estratégias de trading, uma para cada combinação de símbolo e timeframe. Isso significa que, ao buscar, por exemplo, o grupo para EURGBP H1, não são necessários dados sobre execuções em outros símbolos que não EURGBP e outros timeframes que não H1.
Portanto, procederemos da seguinte forma: ao iniciar cada otimização, criaremos um novo banco de dados com um nome predefinido, contendo apenas as informações mínimas necessárias para essa tarefa específica de otimização. O banco de dados atual será chamado de banco de dados principal, e o novo banco criado será chamado de banco de dados de tarefa de otimização ou simplesmente banco de dados da tarefa.
O arquivo desse banco de dados será transferido para os agentes de teste, pois especificaremos seu nome na diretiva #property tester_file. O EA otimizado, ao ser iniciado no agente de teste, trabalhará com esse extrato do banco de dados principal. Já em execução no computador local, no modo de coleta de dados, o EA otimizado continuará salvando os dados recebidos dos agentes de teste no banco de dados principal.
A implementação de uma estrutura de trabalho desse tipo requer, antes de tudo, a modificação da classe de manipulação de banco de dados CDatabase.
Modificação de CDatabase
Ao criar esta classe, não previmos a necessidade de manipular várias bases de dados a partir de um único EA. Inicialmente, nosso objetivo era garantir o uso de uma única base de dados para evitar confusões sobre onde as informações estavam armazenadas. No entanto, as demandas do projeto evoluíram, e precisamos ajustar nossa abordagem.
Para minimizar alterações, decidimos manter a classe CDatabase como estática. Isso significa que não criaremos instâncias dessa classe; em vez disso, usaremos seus métodos públicos como uma coleção de funções em um namespace definido. Ainda assim, poderemos utilizar propriedades e métodos privados nesta classe.
Para permitir a conexão com diferentes bases de dados, modificaremos o método de abertura Open(), renomeando-o para Connect(). A mudança de nome ocorreu porque inicialmente adicionamos o método Connect() como novo, mas percebemos que ele realizava a mesma função que o método Open(). Portanto, optamos por descartar o uso do método antigo.
A principal diferença do novo método em relação ao anterior é a possibilidade de passar o nome do banco de dados como parâmetro. O método Open() sempre abria apenas o banco de dados especificado na propriedade s_fileName, que era constante. Esse comportamento será mantido no novo método caso o nome do banco não seja fornecido. No entanto, ao passar um nome não vazio para Connect(), ele abrirá a base de dados com o nome especificado e armazenará esse nome na propriedade s_fileName. Assim, uma chamada subsequente para Connect() sem nome abrirá a última base acessada.
Além do nome do arquivo, também passaremos para o método Connect() um sinalizador indicando o uso da pasta compartilhada. Isso é necessário porque nosso banco de dados principal é mais conveniente na pasta compartilhada do terminal, enquanto a base da tarefa — deve estar na pasta de dados do agente de teste. Dependendo do caso, usaremos o sinalizador DATABASE_OPEN_COMMON na função de abertura da base, e em outros casos — não. Para isso, adicionaremos uma nova propriedade estática s_common à classe, assumindo por padrão que o arquivo está na pasta compartilhada. Por padrão, consideraremos que queremos abrir o arquivo do banco de dados da pasta compartilhada. E o nome do banco principal mantemos como o valor inicial da propriedade estática s_fileName.
O esboço da classe ficará aproximadamente assim:
//+------------------------------------------------------------------+ //| Класс для работы с базой данных | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // Хендл соединения с БД static string s_fileName; // Имя файла БД static int s_common; // Флаг использования общей папки данных public: static int Id(); // Хендл соединения с БД static bool IsOpen(); // Открыта ли БД? static void Create(); // Создание пустой БД // Подключение к БД с заданным именем и положением static bool Connect(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON ); static void Close(); // Закрытие БД ... }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database892.sqlite"; int CDatabase::s_common = DATABASE_OPEN_COMMON;
Dentro do método Connect(), verificaremos inicialmente se há algum banco aberto. Se sim, fecharemos a conexão atual. Em seguida, verificaremos se um novo nome de arquivo foi fornecido; caso afirmativo, atualizaremos o nome e o sinalizador de uso da pasta compartilhada. Após isso, realizamos a abertura da base, criando um arquivo vazio, se necessário.
Removemos a necessidade de preenchimento imediato da nova base de dados com tabelas e dados pelo método Create(), ao contrário do que foi feito anteriormente. Como agora trabalhamos principalmente com uma base de dados existente, essa abordagem é mais prática. Se for necessário recriar e popular a base com informações iniciais, podemos usar um script auxiliar, CleanDatabase.
//+------------------------------------------------------------------+ //| Проверка подключения к базе данных с заданным именем | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, int p_common) { // Если база данных открыта, то закроем её if(IsOpen()) { Close(); } // Если задано имя файла, то запомним его и флаг общей папки if(p_fileName != NULL) { s_fileName = p_fileName; s_common = p_common; } // Открываем базу данных // Пробуем открыть существующий файл БД s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // Если файл БД не найден, то пытаемся создать его при открытии if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Сообщаем об ошибке при неудаче if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } } return true; }
As modificações serão salvas no arquivo Database.mqh na pasta atual.
EA da primeira etapa
Embora não utilizemos o EA da primeira etapa nesta análise, faremos algumas pequenas alterações por consistência. Primeiro, removeremos os parâmetros de entrada do gerenciamento de risco adicionados no artigo anterior. Eles não são necessários neste EA, já que, na primeira etapa, não ajustaremos os parâmetros de risco. Eles serão incluídos em um EA em uma das próximas etapas de otimização. O objeto de gerenciamento de risco será criado diretamente a partir da string de inicialização, em estado inativo.
Também, na primeira etapa de otimização, não precisamos variar parâmetros como o número mágico, o saldo fixo para negociações e o coeficiente de escala. Portanto, retiraremos a palavra input em suas declarações. O código resultante será:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input int idTask_ = 0; input group "=== Параметры сигнала к открытию" input int signalPeriod_ = 130; // Количество свечей для усреднения объемов input double signalDeviation_ = 0.9; // Относ. откл. от среднего для открытия первого ордера input double signaAddlDeviation_ = 1.4; // Относ. откл. от среднего для открытия второго и последующих ордеров input group "=== Параметры отложенных ордеров" input int openDistance_ = 231; // Расстояние от цены до отлож. ордера input double stopLevel_ = 3750; // Stop Loss (в пунктах) input double takeLevel_ = 50; // Take Profit (в пунктах) input int ordersExpiration_ = 600; // Время истечения отложенных ордеров (в минутах) input group "=== Параметры управление капиталом" input int maxCountOfOrders_ = 3; // Макс. количество одновременно отрытых ордеров ulong magic_ = 27181; // Magic double fixedBalance_ = 10000; double scale_ = 1; datetime fromDate = TimeCurrent(); CAdvisor *expert; // Указатель на объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CMoney::FixedBalance(fixedBalance_); CMoney::DepoPart(1.0); // Подготавливаем строку инициализации для одного экземпляра стратегии string strategyParams = StringFormat( "class CSimpleVolumesStrategy(\"%s\",%d,%d,%.2f,%.2f,%d,%.2f,%.2f,%d,%d)", Symbol(), Period(), signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_ ); // Подготавливаем строку инициализации для группы с одним экземпляром стратегии string groupParams = StringFormat( "class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " )", strategyParams, scale_ ); // Подготавливаем строку инициализации для риск-менеджера string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )", 0,0,0,0,0,0 ); // Подготавливаем строку инициализации для эксперта с группой из одной стратегии и риск-менеджером string expertParams = StringFormat( "class CVirtualAdvisor(\n" " %s,\n" " %s,\n" " %d,%s,%d\n" ")", groupParams, riskManagerParams, magic_, "SimpleVolumesSingle", true ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
O novo código será salvo com o nome SimpleVolumesStage1.mq5 na pasta atual.
EA da segunda etapa
Chegou a hora de abordar o EA principal deste artigo — o EA da segunda etapa de otimização. Conforme mencionado, ele otimizará a seleção de grupos de instâncias individuais das estratégias de trading obtidas na primeira etapa. Usaremos como base o EA OptGroupExpert.mq5 da sexta parte e faremos as devidas alterações.
Primeiro, definiremos o nome da base de dados da tarefa de teste na diretiva #property tester_file. O nome específico é irrelevante, pois será usado apenas para uma execução de otimização e apenas neste EA.
#define PARAMS_FILE "database892.stage2.sqlite" #property tester_file PARAMS_FILE
Em vez do nome de arquivo CSV, que era configurado como parâmetro de entrada, agora usaremos o nome do nosso banco de dados principal:
input group "::: Отбор в группу" sinput string fileName_ = "database892.sqlite"; // - Файл с основной базой данных
Como queremos selecionar grupos de instâncias de estratégias de trading que operam no mesmo símbolo e timeframe, definidos na base de dados principal na tabela de tarefas (jobs), adicionaremos um parâmetro de entrada para especificar o identificador da tarefa (job) que formou o conjunto de instâncias para seleção no grupo atual:
input int idParentJob_ = 1; // - Идентификатор родительской работы
Anteriormente, selecionávamos grupos de oito instâncias; agora aumentaremos esse número para dezesseis. Para isso, adicionaremos mais oito parâmetros de entrada para índices de instâncias adicionais e aumentaremos o valor padrão do parâmetro count_.
input int count_ = 16; // - Количество стратегий в группе (1 .. 16) input int i1_ = 1; // - Индекс стратегии #1 input int i2_ = 2; // - Индекс стратегии #2 input int i3_ = 3; // - Индекс стратегии #3 input int i4_ = 4; // - Индекс стратегии #4 input int i5_ = 5; // - Индекс стратегии #5 input int i6_ = 6; // - Индекс стратегии #6 input int i7_ = 7; // - Индекс стратегии #7 input int i8_ = 8; // - Индекс стратегии #8 input int i9_ = 9; // - Индекс стратегии #9 input int i10_ = 10; // - Индекс стратегии #10 input int i12_ = 11; // - Индекс стратегии #11 input int i11_ = 12; // - Индекс стратегии #12 input int i13_ = 13; // - Индекс стратегии #13 input int i14_ = 14; // - Индекс стратегии #14 input int i15_ = 15; // - Индекс стратегии #15 input int i16_ = 16; // - Индекс стратегии #16
Criamos uma função específica para construir o banco de dados da tarefa de otimização atual. Nela, conectaremos ao banco da tarefa, criando-o caso não exista na pasta de dados do terminal, usando o método DB::Connect(). Esse banco conterá apenas uma tabela com dois campos:
- id_pass — Identificador da Execução do Testador na Primeira Etapa
- params — String de Inicialização do EA para a Execução Correspondente na Primeira Etapa
Se a tabela já foi criada anteriormente (ou seja, caso não seja o primeiro início de otimização da segunda etapa), removeremos e recriaremos essa tabela para que a nova otimização use diferentes execuções da primeira etapa.
A seguir, conectamo-nos ao banco de dados principal e extraímos os dados das execuções do testador que servem como base para a seleção de grupos. O nome do arquivo da base principal é passado como parâmetro fileName para essa função. A consulta SQL para extrair os dados necessários une as tabelas passes, tasks, jobs e stages e retorna as linhas que atendem aos seguintes critérios:
- o nome da etapa para a execução é First, que atribuímos à primeira etapa, permitindo-nos filtrar apenas as execuções dessa fase;
- o identificador do trabalho é igual ao idParentJob passado como parâmetro para a função;
- o lucro normalizado para a execução é superior a 2500;
- o número de negociações é maior que 20;
- o índice de Sharpe é maior que 2.
Os três últimos critérios são opcionais. Esses parâmetros foram ajustados aos resultados específicos das execuções da primeira etapa, de modo que nosso conjunto de resultados fosse suficientemente extenso e de boa qualidade.
Durante a extração dos resultados, criamos uma lista de comandos SQL para inserir dados na base da tarefa. Quando todos os resultados são extraídos, alternamos do banco de dados principal para o banco da tarefa e executamos, em uma única transação, todas as instruções de inserção. Depois, voltamos ao banco de dados principal.
//+------------------------------------------------------------------+ //| Создание базу данных для отдельной задачи этапа | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Создаём новую базу данных для текущей задачи оптимизации DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Подключаемся к основной базе данных DB::Connect(fileName); // Запрос на получение необходимой информации из основной базы данных string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE (s.name='First' AND " " j.id_job = %d AND" " p.custom_ontester > 2500 AND " " trades > 20 AND " " p.sharpe_ratio > 2)" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC;", idParentJob); // Выполнем запрос int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return; } // Структура для результатов запроса struct Row { string params; } row; // Массив для запросов на вставку данных в новую базу данных string queries[]; // Заполняем массив запросов: будем сохранять только строки инициализации while(DatabaseReadBind(request, row)) { APPEND(queries, StringFormat("INSERT INTO passes VALUES(NULL, '%s');", row.params)); } // Переподключаемся к новой базе данных и заполняем её DB::Connect(PARAMS_FILE, 0); DB::ExecuteTransaction(queries); // Переподключаемся к основной базе данных DB::Connect(fileName); DB::Close(); }
Essa função será chamada em dois pontos. A chamada principal ocorre — no manipulador OnTesterInit(), que é executado antes do início da otimização em um gráfico específico do terminal. Sua tarefa é — criar e preencher o banco de dados da tarefa de otimização, verificar a presença dos conjuntos de parâmetros das instâncias individuais no banco da tarefa e definir corretamente os intervalos de iteração dos índices dessas instâncias:
//+------------------------------------------------------------------+ //| Инициализация перед оптимизацией | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Создаём базу данных для отдельной задачи этапа CreateTaskDB(fileName_, idParentJob_); // Получаем количество наборов параметров стратегий int totalParams = GetParamsTotal(); // Если ничего не загрузили, то сообщим об ошибке if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Параметру scale_ устанавливаем значение 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Параметрам перебора индексов наборов задаём диапазоны изменения for(int i = 1; i <= 16; i++) { if(i <= count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 1, 1, totalParams); } else { // Для лишних индексов отключаем перебор ParameterSetRange("i" + (string) i + "_", false, 0, 1, 1, totalParams); } } return CVirtualAdvisor::TesterInit(idTask_); }
Para obter a quantidade de conjuntos de parâmetros das instâncias individuais, utilizamos uma função separada GetParamsTotal(). cuja tarefa é simples: conectar-se ao banco de dados da tarefa, executar uma consulta SQL para obter o total desejado e retornar o resultado:
//+------------------------------------------------------------------+ //| Количество наборов параметров стратегий в базе данных задачи | //+------------------------------------------------------------------+ int GetParamsTotal() { int paramsTotal = 0; // Если база данных задачи открыта, то if(DB::Connect(PARAMS_FILE, 0)) { // Создаём запрос на получение количества проходов для данной задачи string query = "SELECT COUNT(*) FROM passes p"; int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура данных для результата запроса struct Row { int total; } row; // Получаем результат запроса из первой строки if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } return paramsTotal; }
A seguir, reescrevemos a função LoadParams() para carregar conjuntos de parâmetros das instâncias individuais. Em vez de ler todo o arquivo, criar uma matriz com todos os conjuntos e selecionar alguns, agora passaremos uma lista de índices necessários e formularemos uma consulta SQL para extrair apenas os conjuntos com esses índices da base da tarefa. Os conjuntos extraídos (como strings de inicialização) serão concatenados em uma única string de inicialização, que a função retornará.
//+------------------------------------------------------------------+ //| Загрузка наборов параметров стратегий | //+------------------------------------------------------------------+ string LoadParams(int &indexes[]) { string params = NULL; // Получаем количество наборов int totalParams = GetParamsTotal(); // Если они есть, то if(totalParams > 0) { if(DB::Connect(PARAMS_FILE, 0)) { // Формируем строку из индексов наборов, взятых из входных параметров советника // через запятую для дальнейшей подстановки в SQL-запрос string strIndexes = ""; FOREACH(indexes, strIndexes += IntegerToString(indexes[i]) + ","); strIndexes += "0"; // Дополняем несуществующим индексом, чтобы не удалять последнюю запятую // Формируем запрос на получение наборов параметров с нужными индексами string query = StringFormat("SELECT params FROM passes p WHERE id_pass IN(%s)", strIndexes); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура данных для результатов запроса struct Row { string params; } row; // Читаем результаты запроса и соединяем их через запятую while(DatabaseReadBind(request, row)) { params += row.params + ","; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } } return params; }
Finalmente, na função de inicialização do EA, além de definir parâmetros de gerenciamento de capital, reunimos um array de índices necessários para os conjuntos de parâmetros das instâncias. O número necessário é definido no parâmetro de entrada count_, e os próprios índices estão nos parâmetros i{N}_, onde {N} varia de 1 a 16.
Em seguida, verificamos o array para garantir que não haja duplicatas, colocando todos os índices em um conjunto (CHashSet) e conferindo se o número de índices no conjunto é igual ao do array. Se sim, os índices são únicos; caso contrário, informamos sobre a duplicação e abortamos a execução.
Se os índices estiverem corretos, verificamos o modo de execução do EA. Em uma execução de otimização, a base da tarefa já foi criada e está acessível. Em um teste individual, não garantimos a presença da base, portanto, recriaremos a base chamando a função CreateTaskDB().
Após isso, carregamos da base da tarefa os conjuntos de parâmetros nos índices necessários, formando uma string de inicialização (ou sua parte, que será inserida na string final de inicialização do EA). Resta então criar a string final e instanciar o EA a partir dela.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Массив всех индексов из входных параметров советника int indexes_[] = {i1_, i2_, i3_, i4_, i5_, i6_, i7_, i8_, i9_, i10_, i11_, i12_, i13_, i14_, i15_, i16_ }; // Массив для индексов, которые будут участвовать в оптимизации int indexes[]; ArrayResize(indexes, count_); // Копируем в него индексы из входных параметров FORI(count_, indexes[i] = indexes_[i]); // Множество для индексов наборов параметров CHashSet<int> setIndexes; // Добавляем все индексы во множество FOREACH(indexes, setIndexes.Add(indexes[i])); // Сообщаем об ошибке, если if(count_ < 1 || count_ > 16 // количество экземпляров не в диапазоне 1 .. 16 || setIndexes.Count() != count_ // не все индексы уникальные ) { return INIT_PARAMETERS_INCORRECT; } // Если это не оптимизация, то надо пересоздать базу данных задачи if(!MQLInfoInteger(MQL_OPTIMIZATION)) { CreateTaskDB(fileName_, idParentJob_); } // Загружаем наборы параметров стратегий string strategiesParams = LoadParams(indexes); // Если ничего не загрузили, то сообщим об ошибке if(strategiesParams == NULL) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", "database892.sqlite"); return(INIT_PARAMETERS_INCORRECT); } // Подготавливаем строку инициализации для эксперта с группой из нескольких стратегий string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }As mudanças serão salvas no arquivo SimpleVolumesStage2.mq5 na pasta atual. O EA otimizado para a segunda etapa está pronto. Agora, passamos à criação das tarefas da segunda etapa no banco de dados principal.
Criação das tarefas da segunda etapa
Primeiro, criamos a própria segunda etapa de otimização. Para isso, inserimos uma nova linha na tabela stages do banco de dados principal, preenchendo-a com os valores necessários:

Fig. 1. Linha da tabela stages com a segunda etapa.
Neste momento, precisamos apenas do id_stage para a segunda etapa, que será 2, e do name para a segunda etapa, que definimos como "Second". Para criar os trabalhos (jobs) da segunda etapa, pegamos todos os trabalhos da primeira etapa e, para cada um, criamos uma tarefa correspondente na segunda etapa com o mesmo símbolo e timeframe. O valor do campo tester_inputs será formatado como uma string que define o parâmetro idParentJob_ para o identificador correspondente da primeira etapa.
Para isso, executaremos a seguinte consulta SQL no banco de dados principal:
INSERT INTO jobs SELECT NULL, 2 AS id_stage, j.symbol, j.period, 'idParentJob_=' || j.id_job || '||0||1||10||N' AS tester_inputs, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='First';
Executando-a uma única vez, todos os trabalhos da segunda etapa serão criados para os trabalhos da primeira etapa.
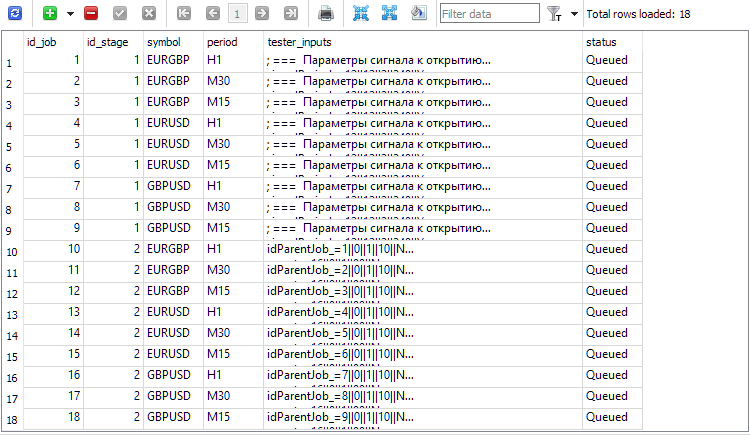
Fig. 2. Registros adicionados para os trabalhos da segunda etapa (id_job = 10 .. 18)
Mais um aspecto a ser observado. Um leitor atento pode ter notado que tanto a primeira etapa quanto as tarefas da primeira etapa no banco de dados principal estão com o status "Queued", embora já tenhamos concluído a primeira etapa de otimização. Existe aqui uma contradição? Infelizmente, sim. Ainda não implementamos a atualização automática dos status das tarefas ao concluir todas as otimizações relacionadas, nem dos status das etapas ao finalizar todas as tarefas. Existem duas abordagens para resolver isso: Adicionando código adicional ao EA de otimização:
- ao final de cada tarefa de otimização, o código verificaria a necessidade de atualização do status das tarefas, trabalhos e etapas;
- adicionando um gatilho no banco de dados: esse gatilho detectaria a conclusão de uma tarefa e, ao ser acionado, verificaria a necessidade de atualizar os status dos trabalhos e das etapas correspondentes.
Resta agora criar as tarefas para cada trabalho, e podemos iniciar a segunda etapa. Ao contrário da primeira etapa, na segunda fase não usaremos múltiplas tarefas com diferentes critérios de otimização em um mesmo trabalho. Utilizaremos apenas um critério — o de média anual de lucro normalizado. Para definir este critério, precisamos selecionar o índice 6 no campo de critério de otimização.
As tarefas da segunda etapa, para todos os trabalhos, podem ser criadas com o critério de otimização 6 usando a seguinte consulta SQL:
INSERT INTO tasks SELECT NULL, j.id_job AS id_job, 6 AS optimization, NULL AS start_date, NULL AS finish_date, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='Second';
Executando essa consulta uma vez, obtemos novas entradas na tabela tasks, correspondentes às tarefas da segunda etapa. Em seguida, adicionamos o EA Optimization.ex5 a qualquer gráfico do terminal e aguardamos que ele conclua todas as tarefas de otimização. O tempo de execução pode variar bastante, dependendo do EA, da duração do período de teste, do número de símbolos, de timeframes e, claro, da quantidade de agentes envolvidos.
Para o EA usado neste projeto, em um intervalo de 2 anos (2021 e 2022), otimizando com três símbolos e três timeframes em 32 agentes, todas as tarefas da segunda etapa foram concluídas em aproximadamente cinco horas. Vamos observar os resultados.
EA para executar as tarefas selecionadas
Para facilitar a análise, criaremos outro EA, ou melhor, faremos pequenas alterações em um existente. Incluiremos nele um parâmetro de entrada passes_, onde indicaremos, separados por vírgula, os identificadores das execuções do testador cujos conjuntos de estratégias desejamos agrupar neste EA.
Na função de inicialização do EA, extrairemos os parâmetros (strings de inicialização dos grupos de estratégias) das execuções da base principal e os inseriremos na string de inicialização do objeto EA.
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input group "::: Управление капиталом" sinput double expectedDrawdown_ = 10; // - Максимальный риск (%) sinput double fixedBalance_ = 10000; // - Используемый депозит (0 - использовать весь) в валюте счета input double scale_ = 1.00; // - Масштабирующий множитель для группы input group "::: Отбор в группу" input string passes_ = "734469,735755,736046,736121,761710,776928,786413,795381"; // - Идентификаторы проходов через запятую ulong magic_ = 27183; // - Magic bool useOnlyNewBars_ = true; // - Работать только на открытии бара datetime fromDate = TimeCurrent(); CVirtualAdvisor *expert; // Объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Строка инициализации с наборами параметров стратегий string strategiesParams = NULL; // Если соединение с основной базой данных установлено, то if(DB::Connect()) { // Формируем запрос на получение проходов с указанными идетификаторами string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " WHERE id_pass IN (%s);" , passes_); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура для чтения результатов struct Row { string params; } row; // Для всех строк результата запроса, соединяем строки инициализации while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // Если наборов параметрв не найдено, то прерываем тестирование if(strategiesParams == NULL) { return INIT_FAILED; } // Подготавливаем строку инициализации для эксперта с группой из нескольких стратегий string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Salve o EA atualizado com o nome SimpleVolumesExpert.mq5 na pasta atual.
Para obter os melhores identificadores de execução da segunda etapa, podemos usar a seguinte consulta SQL:
SELECT p.id_pass, j.symbol, j.period, p.custom_ontester, p.profit, p.profit_factor, p.sharpe_ratio, p.equity_dd, p.params FROM ( SELECT p0.*, ROW_NUMBER() OVER (PARTITION BY id_task ORDER BY custom_ontester DESC) AS rn FROM passes p0 ) AS p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage WHERE rn = 1 AND s.name = 'Second';
Nesta consulta, conectamos nossas tabelas do banco de dados principal para selecionar as execuções da etapa "Second" (segunda etapa). Fazemos um join da tabela de execuções (passes) com sua própria cópia, dividida em seções com o mesmo identificador de tarefa. Dentro de cada seção, as linhas são ordenadas por valor decrescente do critério de otimização (custom_ontester) e numeradas. Somente as primeiras linhas de cada seção são mantidas, representando os valores mais altos do critério.

Fig. 3. Lista de identificadores de execução para os melhores resultados em cada trabalho da segunda etapa
Pegamos os valores dos identificadores da primeira coluna id_pass e os inserimos no parâmetro de entrada passes_ do EA agrupado. Executamos o teste e obtemos os seguintes resultados:
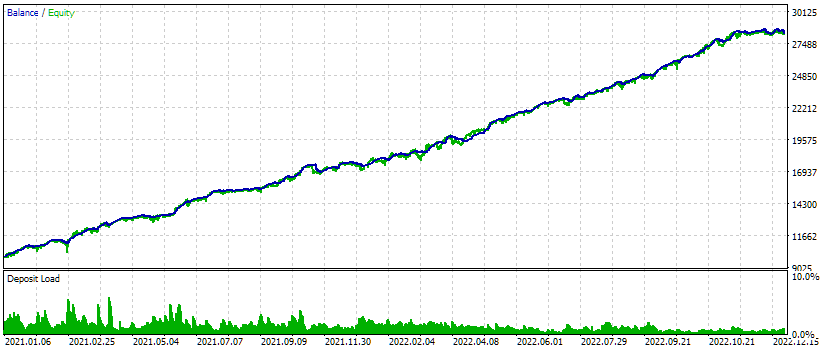

Fig. 4. Resultados do teste do EA agrupado para três símbolos e três timeframes.
Neste intervalo de teste, o gráfico de crescimento dos fundos mostra um desempenho bastante positivo: o crescimento se mantém linear ao longo de todo o período e a retração permanece dentro do esperado. Embora nossa principal preocupação aqui não seja o gráfico em si, este exercício nos mostra que agora podemos criar automaticamente uma string de inicialização para um EA que combina várias das melhores estratégias individuais, agrupadas por símbolo e timeframe.
Considerações finais
Com isso, completamos o segundo estágio de nossa otimização em uma versão preliminar. Para melhorar o processo, seria útil desenvolver uma interface web específica para criar e gerenciar projetos de otimização de estratégias de trading. Porém, antes de buscar tais melhorias, é aconselhável seguir todas as etapas propostas, sem desviar para detalhes não essenciais no momento. Durante o desenvolvimento das versões preliminares, é comum termos que ajustar o plano inicial em função de novas descobertas.
Até agora, a otimização foi executada apenas em um intervalo de tempo relativamente curto. Idealmente, devemos expandir o período de teste e refazer a otimização. Também não incluímos a clusterização na segunda etapa, como feito na sexta parte da série, onde o processo foi acelerado em comparação com a otimização sem clusterização. Implementar isso exigiria esforços de desenvolvimento substancialmente maiores, pois precisaríamos automatizar ações que são complexas de implementar em MQL5, mas muito mais simples em Python ou R.
Fica difícil decidir o próximo passo a seguir. Vamos dar uma pequena pausa e, quem sabe, as dúvidas de hoje se tornem claras amanhã.
Obrigado pela atenção e até a próxima!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14892
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá.
Antes da Parte 16, você tinha de fazer exatamente isso: baixar os arquivos dos artigos um a um e atualizar os que foram modificados. A partir da Parte 16, cada artigo é acompanhado por um arquivo completo da pasta do projeto.
Olá.
Antes da Parte 16, você tinha de fazer exatamente isso: baixar os arquivos dos artigos um a um e atualizar os que foram modificados. A partir da Parte 16, cada artigo é acompanhado por um arquivo completo da pasta do projeto.
Obrigado por essa resposta/ Vou começar imediatamente
Olá novamente,
Estou tendo dois problemas.
Usando o código da Parte 13, quando tentei compilar o Optimizer, recebi um identificador não identificado para DB::Open() que estava na versão 1.00 e não na 1.03 do banco de dados.
Copiar o código da versão 1.00 para a 1.03 eliminou esse erro, mas produziu um identificador não identificado para Id(), que está claramente no objeto de banco de dados.
O outro erro é que a guia Artigos em meu Terminal lista a Parte 13 de seus artigos como a última versão em inglês. Se eu seguir seu link, descobri que, além do Artigo 16, você publicou a Parte 20.
Ambos os artigos estão em cirílico e, quando tento traduzi-los para o inglês, uma página totalmente diferente é apresentada em inglês. Isso também ocorreu durante o download do Multitester.
Você tem alguma sugestão para me ajudar a seguir seu excelente tópico?
Olá.
Os artigos são inicialmente escritos em russo e, posteriormente, traduzidos para o inglês e outros idiomas, com um atraso de cerca de três a quatro meses. Portanto, você pode esperar até que a Parte 16 seja publicada em inglês. A substituição de "ru" por "en" no endereço do artigo não inclui a tradução automática, mas leva à versão em inglês do artigo criada por tradutores. Se a tradução ainda não tiver sido feita pela MetaQuotes, você receberá um erro informando que essa página não existe.
Em relação às perguntas sobre os erros que você recebe durante a compilação, receio que será difícil para mim ajudá-lo. Posso anexar aqui um arquivo da pasta do projeto do repositório da versão que era a mais recente no momento da publicação da Parte 13. Mas lá, ao contrário do código nos artigos traduzidos, todos os comentários nos arquivos não estarão em inglês.
Muito obrigado pelo esclarecimento sobre a defasagem. Acho que vou para a Parte 16, baixarei o sistema e tentarei novamente. Sei que corro o risco de ter alterações incorporadas entre a 13 e a 16, mas espero poder resolver quaisquer conflitos. Manterei você informado.