
Entwicklung eines Expertenberaters für mehrere Währungen (Teil 13): Automatisierung der zweiten Phase — Aufteilung in Gruppen
Einführung
Nachdem wir im letzten Artikel ein wenig vom Risikomanager abgelenkt wurden, wollen wir nun zum Hauptthema zurückkehren — der Testautomatisierung. In einem der vorangegangenen Artikel haben wir mehrere Phasen beschrieben, die bei der Optimierung und der Suche nach den besten Parametern für den endgültigen EA durchlaufen werden sollten. Wir haben bereits die erste Stufe implementiert, in der wir die Parameter einer einzelnen Handelsstrategie optimiert haben. Die Ergebnisse wurden in der Datenbank gespeichert.
Die nächste Stufe ist eine Auswahl von guten Gruppen einzelner Instanzen von Handelsstrategien, die, wenn sie zusammenarbeiten, die Handelsparameter verbessern — den Drawdown reduzieren, die Linearität des Wachstums der Gleichgewichtskurve erhöhen, und so weiter. Wir haben uns bereits im sechsten Teil der Serie angesehen, wie dieser Schritt manuell durchgeführt werden kann. Zunächst haben wir aus den Ergebnissen der Optimierung der Parameter einzelner Handelsstrategien diejenigen ausgewählt, die unsere Aufmerksamkeit verdienen. Dies hätte anhand verschiedener Kriterien geschehen können, aber zu diesem Zeitpunkt beschränkten wir uns darauf, Ergebnisse mit negativem Gewinn einfach zu entfernen. Dann haben wir mit verschiedenen Methoden versucht, verschiedene Kombinationen von acht Instanzen von Handelsstrategien zu nehmen, sie in einem EA zu kombinieren und sie im Tester laufen zu lassen, um die Parameter ihrer gemeinsamen Arbeit zu bewerten.
Ausgehend von der manuellen Auswahl haben wir auch eine automatische Auswahl von Eingabekombinationen einzelner Handelsstrategien implementiert, die aus der Liste der in einer CSV-Datei gespeicherten Parameter ausgewählt wurden. Es zeigt sich, dass selbst im einfachsten Fall das gewünschte Ergebnis erzielt wird, wenn wir einfach eine genetische Optimierung durchführen, die acht Kombinationen auswählt.
Ändern wir nun den EA, der die Gruppenauswahloptimierung durchgeführt hat, so, dass er die Ergebnisse der ersten Stufe aus der Datenbank verwenden kann. Außerdem sollte es seine Ergebnisse in der Datenbank speichern. Wir werden auch die Erstellung von Aufgaben für die Durchführung von Optimierungen der zweiten Stufe in Betracht ziehen, indem wir die erforderlichen Einträge in unsere Datenbank aufnehmen.
Übermittlung von Daten an Testagenten
Für den bisherigen EA zur Auswahl geeigneter Gruppen mussten wir ein wenig tüfteln, um sicherzustellen, dass die Optimierung mit Hilfe von Remote-Test-Agenten durchgeführt werden kann. Das Problem war, dass der optimierte EA Daten aus einer CSV-Datei lesen musste. Bei der Optimierung auf einem lokalen Computer verursachte dies keine Probleme — es genügte, die Datendatei im gemeinsamen Ordner des Terminals abzulegen, und alle lokalen Testagenten konnten darauf zugreifen.
Nicht lokale Testagenten haben jedoch keinen Zugriff auf eine solche Datei mit Daten. Aus diesem Grund haben wir die Direktive #property tester_file verwendet, die es uns ermöglicht, jede angegebene Datei an alle Testagenten in ihrem Datenordner zu übergeben. Wenn die Optimierung gestartet wurde, wurde die Datendatei aus dem gemeinsamen Ordner in den Datenordner des lokalen Agenten kopiert, der den Optimierungsprozess gestartet hat. Die Datendatei aus dem Datenordner des lokalen Agenten wurde dann automatisch an die Datenordner aller anderen Testagenten gesendet.
Da wir nun Daten über die Ergebnisse von Tests einzelner Instanzen von Handelsstrategien in der SQLite-Datenbank haben, war mein erster Impuls, dies auch zu tun. Da es sich bei der SQLite-Datenbank um eine einzelne Datei auf dem Datenträger handelt, kann sie mit Hilfe der oben genannten Direktive auf dieselbe Weise auf entfernte Testagenten repliziert werden. Allerdings gibt es hier eine kleine Nuance — die Größe der übertragenen CSV Datei betrug etwa 2 MB, während die Größe der Datenbankdatei 300 MB überstieg.
Dieser Unterschied ist darauf zurückzuführen, dass wir erstens versucht haben, so viele statistische Informationen wie möglich über jeden Durchgang in der Datenbank zu speichern, und dass in der CSV-Datei nur einige statistische Parameter und Daten über die Werte der Eingabeparameter der Strategieinstanzen gespeichert sind. Zweitens haben wir in unserer Datenbank bereits Informationen über die Ergebnisse der Strategieoptimierung für drei verschiedene Symbole und drei verschiedene Zeitrahmen für jedes Symbol. Mit anderen Worten: Die Zahl der Durchgänge hat sich etwa verneunfacht.
Wenn man bedenkt, dass jeder Testagent seine eigene Kopie der übertragenen Datei erhält, müssten wir mehr als 9 GB an Daten auf einem 32-Kern-Server ablegen, um einen Test durchzuführen. Wenn wir in der ersten Phase eine noch größere Anzahl von Symbolen und Zeitrahmen verarbeiten, wird die Größe der Datei mit der Datenbank um ein Vielfaches ansteigen. Dies kann dazu führen, dass der verfügbare Speicherplatz auf den Agentenservern erschöpft ist, ganz zu schweigen von der Notwendigkeit, große Datenmengen über das Netz zu übertragen.
Allerdings werden wir die meisten gespeicherten Informationen über die Ergebnisse der abgeschlossenen Prüfungen in der zweiten Phase entweder nicht oder nicht alle gleichzeitig benötigen. Mit anderen Worten: Aus dem gesamten Satz gespeicherter Werte für einen Durchgang müssen wir nur den in diesem Durchgang verwendeten EA-Initialisierungsstring extrahieren. Wir planen auch, mehrere Gruppen von einzelnen Kopien von Handelsstrategien zu sammeln — eine für jede Kombination von Symbol und Zeitrahmen. Zum Beispiel, wenn wir nach der EURGBP H1 Gruppe suchen, brauchen wir keine Daten über Durchgänge für andere Symbole als EURGBP und andere Zeitrahmen als H1.
Wir gehen also wie folgt vor: Zu Beginn jeder Optimierung legen wir eine neue Datenbank mit einem vordefinierten Namen an und füllen sie mit den für eine bestimmte Optimierungsaufgabe erforderlichen Mindestinformationen. Wir nennen die bestehende Datenbank die Hauptdatenbank, während die neu zu erstellende Datenbank als Optimierungsproblem-Datenbank oder einfach als Aufgabendatenbank bezeichnet wird.
Die Datenbankdatei wird an die Testagenten übergeben, da wir ihren Namen in der Direktive #property tester_file angeben. Wenn er auf dem Testagenten ausgeführt wird, arbeitet der optimierte EA mit diesem Extrakt aus der Hauptdatenbank. Wenn der optimierte EA auf einem lokalen Computer im Datenerfassungsmodus läuft, speichert er die von den Testagenten empfangenen Daten dennoch in der Hauptdatenbank.
Die Implementierung eines solchen Arbeitsablaufs erfordert zunächst eine Änderung der Klasse CDatabase für die Handhabung der Datenbank.
Änderung von CDatabase
Bei der Entwicklung dieser Klasse habe ich nicht vorausgesehen, dass wir mit mehreren Datenbanken über den Code eines einzigen EA arbeiten müssen. Im Gegenteil, es schien, dass wir sicherstellen sollten, dass wir mit nur einer Datenbank arbeiten, um später nicht durcheinander zu kommen, was wir wo speichern. Aber die Realität passt sich an, und wir müssen unseren Ansatz ändern.
Um die Bearbeitungen zu minimieren, habe ich beschlossen, die Klasse CDatabase vorerst statisch zu lassen. Mit anderen Worten: Wir werden keine Klassenobjekte erstellen, sondern ihre öffentlichen Methoden einfach als eine Reihe von Funktionen in einem bestimmten Namensraum verwenden. Gleichzeitig haben wir weiterhin die Möglichkeit, private Eigenschaften und Methoden in dieser Klasse zu verwenden.
Um die Verbindung zu verschiedenen Datenbanken zu ermöglichen, ändern wir die Methode Open() und benennen sie in Connect() um. Die Umbenennung erfolgte, weil zuerst die neue Methode Connect() hinzugefügt wurde und sich dann herausstellte, dass sie eigentlich die gleiche Aufgabe wie Open() erfüllt. Deshalb haben wir beschlossen, letzteres aufzugeben.
Der Hauptunterschied zwischen der neuen Methode und ihrer Vorgängerin ist die Möglichkeit, den Datenbanknamen als Parameter zu übergeben. Die Methode Open() öffnete immer nur die Datenbank mit dem in der Eigenschaft s_fileName angegebenen Namen, der eine Konstante war. Die neue Methode behält dieses Verhalten auch dann bei, wenn Sie ihr keinen Datenbanknamen übergeben. Wenn wir einen nicht leeren Namen an die Methode Connect() übergeben, wird nicht nur die Datenbank mit dem übergebenen Namen geöffnet, sondern auch in der Eigenschaft s_fileName gespeichert. Der wiederholte Aufruf von Connect() ohne Angabe eines Namens wird also die zuletzt geöffnete Datenbank öffnen.
Zusätzlich zur Übergabe des Dateinamens an die Methode Connect() wird auch das Flag für die Verwendung des gemeinsamen Ordners übergeben. Dies ist notwendig, weil es bequemer ist, unsere Hauptdatenbank im gemeinsamen Terminal-Datenordner zu speichern, während die Aufgabendatenbank im Datenordner des Testagenten gespeichert ist. Daher müssen wir in einem Fall das Flag DATABASE_OPEN_COMMON in der Datenbank-Open-Funktion angeben. Fügen wir eine neue statische Klasse s_common hinzu, um das Flag zu speichern. Standardmäßig gehen wir davon aus, dass wir die Datenbankdatei aus dem gemeinsamen Ordner öffnen wollen. Der Haupt-Basisname wird weiterhin als der Anfangswert der statischen Eigenschafts_fileName festgelegt.
Dann wird die Klassenbeschreibung etwa so aussehen:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name static int s_common; // Flag for using shared data folder public: static int Id(); // Database connection handle static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB // Connect to the database with a given name and location static bool Connect(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON ); static void Close(); // Closing DB ... }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database892.sqlite"; int CDatabase::s_common = DATABASE_OPEN_COMMON;
In der Methode Connect() selbst wird zunächst geprüft, ob eine Datenbank derzeit geöffnet ist. Wenn ja, werden wir sie schließen. Als Nächstes wird geprüft, ob ein neuer Dateiname für die Datenbank angegeben wurde. Wenn ja, legen Sie einen neuen Namen und ein Flag für den Zugriff auf den gemeinsamen Ordner fest. Danach führen wir die Schritte zum Öffnen der Datenbank durch und legen gegebenenfalls eine leere Datenbankdatei an.
An diesem Punkt haben wir das erzwungene Füllen der neu erstellten Datenbank mit Tabellen und Daten durch den Aufruf der Methode Create() aufgehoben, wie es zuvor gemacht wurde. Da wir bereits größtenteils mit einer bestehenden Datenbank arbeiten, wird dies bequemer sein. Wenn wir die Datenbank noch einmal neu erstellen und mit den ursprünglichen Informationen füllen müssen, können wir das Hilfsskript CleanDatabase verwenden.
//+------------------------------------------------------------------+ //| Check connection to the database with the given name | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, int p_common) { // If the database is open, close it if(IsOpen()) { Close(); } // If a file name is specified, save it together with the shared folder flag if(p_fileName != NULL) { s_fileName = p_fileName; s_common = p_common; } // Open the database // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } } return true; }
Wir speichern die Änderungen in der Datei Database.mqh des aktuellen Ordners.
Erste Stufe EA
In diesem Artikel werden wir die erste Stufe des EA nicht verwenden, aber aus Gründen der Konsistenz werden wir einige kleinere Änderungen vornehmen. Zunächst entfernen wir die im vorherigen Artikel hinzugefügten Eingaben des Risikomanagers. In diesem EA werden wir sie nicht benötigen, da wir in der ersten Phase definitiv keine Risikomanager-Parameter auswählen werden. Wir werden sie einem EA einer der folgenden Optimierungsstufen hinzufügen. Wir werden das Risikomanager-Objekt selbst sofort aus dem Initialisierungsstring in einem inaktiven Zustand erstellen.
Außerdem brauchen wir in der ersten Phase der Optimierung keine Eingabeparameter wie eine magische Zahl, ein festes Gleichgewicht für den Handel und einen Skalierungsfaktor zu variieren. Nehmen wir ihnen also das Eingangswort weg, wenn sie es ankündigen. Wir erhalten den folgenden Code:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int idTask_ = 0; input group "=== Opening signal parameters" input int signalPeriod_ = 130; // Number of candles for volume averaging input double signalDeviation_ = 0.9; // Relative deviation from the average to open the first order input double signaAddlDeviation_ = 1.4; // Relative deviation from the average for opening the second and subsequent orders input group "=== Pending order parameters" input int openDistance_ = 231; // Distance from price to pending order input double stopLevel_ = 3750; // Stop Loss (in points) input double takeLevel_ = 50; // Take Profit (in points) input int ordersExpiration_ = 600; // Pending order expiration time (in minutes) input group "=== Money management parameters" input int maxCountOfOrders_ = 3; // Maximum number of simultaneously open orders ulong magic_ = 27181; // Magic double fixedBalance_ = 10000; double scale_ = 1; datetime fromDate = TimeCurrent(); CAdvisor *expert; // Pointer to the EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CMoney::FixedBalance(fixedBalance_); CMoney::DepoPart(1.0); // Prepare the initialization string for a single strategy instance string strategyParams = StringFormat( "class CSimpleVolumesStrategy(\"%s\",%d,%d,%.2f,%.2f,%d,%.2f,%.2f,%d,%d)", Symbol(), Period(), signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_ ); // Prepare the initialization string for a group with one strategy instance string groupParams = StringFormat( "class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " )", strategyParams, scale_ ); // Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )", 0,0,0,0,0,0 ); // Prepare the initialization string for an EA with a group of a single strategy and the risk manager string expertParams = StringFormat( "class CVirtualAdvisor(\n" " %s,\n" " %s,\n" " %d,%s,%d\n" ")", groupParams, riskManagerParams, magic_, "SimpleVolumesSingle", true ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Wir speichern den erhaltenen Code unter dem neuen Namen SimpleVolumesStage1.mq5 im aktuellen Ordner.
Zweite Stufe EA
Es ist an der Zeit, zum Hauptpunkt dieses Artikels zu kommen — zur zweiten Optimierungsstufe EA. Wie bereits erwähnt, wird es sich mit der Optimierung der Auswahl einer Gruppe einzelner Instanzen von Handelsstrategien befassen, die in der ersten Stufe ermittelt wurden. Lassen Sie uns den EA OptGroupExpert.mq5 aus dem sechsten Teil als Grundlage verwenden und die notwendigen Änderungen vornehmen.
Zunächst legen wir den Namen der Datenbank für die Testaufgaben in der Direktive #property tester_file fest. Die Wahl eines bestimmten Namens ist nicht wichtig, da er nur für einen Optimierungslauf und nur innerhalb dieses EA verwendet wird.
#define PARAMS_FILE "database892.stage2.sqlite" #property tester_file PARAMS_FILE
Anstelle des in den Eingaben angegebenen CSV-Dateinamens geben wir nun den Namen unserer Hauptdatenbank an:
input group "::: Selection for the group" sinput string fileName_ = "database892.sqlite"; // - File with the main database
Da wir Gruppen von einzelnen Instanzen von Handelsstrategien auswählen wollen, die auf demselben Symbol und Zeitrahmen arbeiten und die wiederum in der Hauptdatenbank in der Tabelle „Jobs“ definiert sind, fügen wir den Eingaben die Möglichkeit hinzu, die ID des Jobs anzugeben, dessen Aufgaben die Menge der einzelnen Instanzen von Handelsstrategien für die Auswahl in die aktuelle Gruppe bildeten:
input int idParentJob_ = 1; // - Parent job ID
Bisher haben wir eine Auswahl von Gruppen mit acht Exemplaren verwendet, aber jetzt werden wir ihre Anzahl auf sechzehn erhöhen. Dazu fügen wir acht weitere Eingänge für zusätzliche Strategieinstanzindizes hinzu und erhöhen den Standardwert für den Parameter count_:
input int count_ = 16; // - Number of strategies in the group (1 .. 16) input int i1_ = 1; // - Strategy index #1 input int i2_ = 2; // - Strategy index #2 input int i3_ = 3; // - Strategy index #3 input int i4_ = 4; // - Strategy index #4 input int i5_ = 5; // - Strategy index #5 input int i6_ = 6; // - Strategy index #6 input int i7_ = 7; // - Strategy index #7 input int i8_ = 8; // - Strategy index #8 input int i9_ = 9; // - Strategy index #9 input int i10_ = 10; // - Strategy index #10 input int i12_ = 11; // - Strategy index #11 input int i11_ = 12; // - Strategy index #12 input int i13_ = 13; // - Strategy index #13 input int i14_ = 14; // - Strategy index #14 input int i15_ = 15; // - Strategy index #15 input int i16_ = 16; // - Strategy index #16
Erstellen wir eine separate Funktion, die die Erstellung einer Datenbank für die aktuelle Optimierungsaufgabe übernimmt. In der Funktion stellen wir eine Verbindung zur Aufgabendatenbank her, indem wir die Methode DB::Connect() aufrufen. Wir werden nur eine Tabelle mit zwei Feldern in die Datenbank aufnehmen:
- id_pass — id des Testers in der ersten Phase
- params — EA-Initialisierungszeichenfolge für den Testerdurchgang in der ersten Stufe
Wenn die Tabelle bereits früher hinzugefügt wurde (dies ist nicht der erste Durchlauf der zweiten Optimierungsstufe), dann löschen wir sie und erstellen sie neu, da wir andere Durchläufe der ersten Stufe für die neue Optimierung benötigen.
Dann stellen wir eine Verbindung zur Hauptdatenbank her und extrahieren aus ihr die Daten der Testdurchläufe, aus denen wir nun eine Gruppe auswählen wollen. Der Name der Hauptdatenbankdatei wird als Parameter fileName an die Funktion übergeben. Die Abfrage zum Abrufen der erforderlichen Daten verbindet die Tabellen passes, tasks, jobs und stages und gibt die Zeilen zurück, die die folgenden Bedingungen erfüllen:
- Der Name der Stufe für den Durchgang ist „First“. So haben wir die erste Stufe genannt, und nach diesem Namen können wir nur die Durchgänge sortieren, die zur ersten Stufe gehören.
- Die Job-ID ist gleich der ID, die im Funktionsparameter idParentJob übergeben wurde.
- Der normalisierte Gewinn 2500 übersteigt.
- Die Anzahl der Handelsgeschäfte übersteigt 20.
- Die Sharpe Ratio ist größer als 2.
Die letzten drei Bedingungen sind fakultativ. Die Parameter wurden auf der Grundlage der Ergebnisse bestimmter Durchläufe der ersten Stufe ausgewählt, sodass einerseits eine große Anzahl von Durchläufen in den Abfrageergebnissen enthalten ist und andererseits diese Durchläufe von guter Qualität sind.
Beim Abrufen der Abfrageergebnisse erstellen wir sofort eine Reihe von SQL-Abfragen, um Daten in die Aufgabendatenbank einzufügen. Sobald alle Ergebnisse abgerufen wurden, wechseln wir von der Hauptdatenbank zur Aufgabendatenbank und führen alle generierten Dateneinfügeabfragen in einer Transaktion aus. Danach wechseln wir zurück zur Hauptdatenbank.
//+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Request to obtain the required information from the main database string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE (s.name='First' AND " " j.id_job = %d AND" " p.custom_ontester > 2500 AND " " trades > 20 AND " " p.sharpe_ratio > 2)" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC;", idParentJob); // Execute the request int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return; } // Structure for query results struct Row { string params; } row; // Array for requests to insert data into a new database string queries[]; // Fill the request array: we will only save the initialization strings while(DatabaseReadBind(request, row)) { APPEND(queries, StringFormat("INSERT INTO passes VALUES(NULL, '%s');", row.params)); } // Reconnect to the new database and fill it DB::Connect(PARAMS_FILE, 0); DB::ExecuteTransaction(queries); // Reconnect to the main database DB::Connect(fileName); DB::Close(); }
Diese Funktion wird an zwei Stellen aufgerufen. Sein Hauptaufruf erfolgt in OnTesterInit(), der vor dem Beginn der Optimierung auf einem separaten Terminal-Chart gestartet wird. Seine Aufgabe ist es, die Datenbank der Optimierungsaufgaben zu erstellen und zu füllen, das Vorhandensein von Parametersätzen einzelner Instanzen von Handelsstrategien in der erstellten Aufgabendatenbank zu überprüfen und die richtigen Bereiche für die Nummerierung einzelner Instanzindizes festzulegen:
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Create a database for a separate stage task CreateTaskDB(fileName_, idParentJob_); // Get the number of strategy parameter sets int totalParams = GetParamsTotal(); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 1; i <= 16; i++) { if(i <= count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 1, 1, totalParams); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 1, 1, totalParams); } } return CVirtualAdvisor::TesterInit(idTask_); }
Die separate Funktion GetParamsTotal() hat die Aufgabe, die Anzahl der Parametersätze der einzelnen Instanzen zu ermitteln. Sein Ziel ist sehr einfach: Verbindung zur Aufgabendatenbank herstellen, eine SQL-Abfrage ausführen, um die gewünschte Anzahl zu erhalten, und das Ergebnis zurückgeben:
//+------------------------------------------------------------------+ //| Number of strategy parameter sets in the task database | //+------------------------------------------------------------------+ int GetParamsTotal() { int paramsTotal = 0; // If the task database is open, if(DB::Connect(PARAMS_FILE, 0)) { // Create a request to get the number of passes for this task string query = "SELECT COUNT(*) FROM passes p"; int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query result struct Row { int total; } row; // Get the query result from the first string if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } return paramsTotal; }
Als Nächstes werden wir die Funktion LoadParams() zum Laden von Parametersätzen einzelner Instanzen von Handelsstrategien umschreiben. Anders als bei der vorherigen Implementierung, bei der wir die gesamte Datei gelesen, ein Array mit allen Parametersätzen erstellt und dann einige notwendige Parameter aus diesem Array ausgewählt haben, werden wir jetzt anders vorgehen. Wir übergeben dieser Funktion eine Liste der erforderlichen Set-Indizes und bilden eine SQL-Abfrage, die nur die Sets mit diesen Indizes aus der Aufgabendatenbank extrahiert. Wir kombinieren die aus der Datenbank erhaltenen Parametersätze (in Form von Initialisierungsstrings) zu einem einzigen, durch Komma getrennten Initialisierungsstring, der von dieser Funktion zurückgegeben wird:
//+------------------------------------------------------------------+ //| Loading strategy parameter sets | //+------------------------------------------------------------------+ string LoadParams(int &indexes[]) { string params = NULL; // Get the number of sets int totalParams = GetParamsTotal(); // If they exist, then if(totalParams > 0) { if(DB::Connect(PARAMS_FILE, 0)) { // Form a string from the indices of the comma-separated sets taken from the EA inputs // for further substitution into the SQL query string strIndexes = ""; FOREACH(indexes, strIndexes += IntegerToString(indexes[i]) + ","); strIndexes += "0"; // Add a non-existent index so as not to remove the last comma // Form a request to obtain sets of parameters with the required indices string query = StringFormat("SELECT params FROM passes p WHERE id_pass IN(%s)", strIndexes); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query results struct Row { string params; } row; // Read the query results and join them with a comma while(DatabaseReadBind(request, row)) { params += row.params + ","; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } } return params; }
Schließlich ist es Zeit für die EA-Initialisierungsfunktion. Zusätzlich zu den Parametern für das Kapitalmanagement stellen wir zunächst ein Array mit der erforderlichen Anzahl von Indizes der Parametersätze der einzelnen Handelsstrategie-Instanzen zusammen. Die gewünschte Anzahl wird in der Eingabe count_ EA angegeben, während die Indizes selbst in den Eingängen mit den Namen i{N}_ gesetzt werden, wobei {N} Werte von 1 bis 16 annimmt.
Anschließend wird das resultierende Array von Indizes auf Duplikate überprüft, indem alle Indizes in einen Container vom Typ Set (CHashSet) gestellt werden und sichergestellt wird, dass das Set die gleiche Anzahl von Indizes hat wie das Array. Wenn dies der Fall ist, sind alle Indizes eindeutig. Wenn die Menge weniger Indizes hat als das Array, melden Sie falsche Eingaben und führen Sie diesen Durchgang nicht aus.
Wenn mit den Indizes alles in Ordnung ist, dann überprüfen Sie den aktuellen EA-Modus. Wenn der Durchlauf Teil des Optimierungsverfahrens ist, wurde die Aufgabendatenbank definitiv vor Beginn der Optimierung erstellt und ist nun verfügbar. Wenn es sich um einen regulären einzelnen Testlauf handelt, können wir nicht garantieren, dass die Aufgabendatenbank vorhanden ist, also erstellen wir sie einfach neu, indem wir die Funktion CreateTaskDB() aufrufen.
Danach laden wir die Parametersätze mit den erforderlichen Indizes aus der Aufgabendatenbank in Form eines einzigen Initialisierungsstrings (oder besser gesagt, einen Teil davon, den wir in den endgültigen Initialisierungsstring des EA-Objekts einfügen werden). Nun muss nur noch der endgültige Initialisierungsstring gebildet und daraus ein EA-Objekt erstellt werden.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Array of all indices from the EA inputs int indexes_[] = {i1_, i2_, i3_, i4_, i5_, i6_, i7_, i8_, i9_, i10_, i11_, i12_, i13_, i14_, i15_, i16_ }; // Array for indices to be involved in optimization int indexes[]; ArrayResize(indexes, count_); // Copy the indices from the inputs into it FORI(count_, indexes[i] = indexes_[i]); // Multiplicity for parameter set indices CHashSet<int> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 16 // number of instances not in the range 1 .. 16 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // If this is not an optimization, then you need to recreate the task database if(!MQLInfoInteger(MQL_OPTIMIZATION)) { CreateTaskDB(fileName_, idParentJob_); } // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // If nothing is loaded, report an error if(strategiesParams == NULL) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", "database892.sqlite"); return(INIT_PARAMETERS_INCORRECT); } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }Wir speichern die an der Datei SimpleVolumesStage2.mq5 vorgenommenen Änderungen im aktuellen Ordner. Der in der zweiten Stufe zu optimierende EA ist fertig. Beginnen wir nun mit der Erstellung von Aufgaben für die zweite Stufe der Optimierung in der Hauptdatenbank.
Aufgaben der zweiten Stufe erstellen
Legen wir zunächst die zweite Optimierungsstufe selbst an. Dazu fügen wir eine neue Zeile in die Tabelle der Stufen bzw. stages ein und füllen die Werte wie folgt:

Abb. 1: Zeilen der Tabelle „stages“ mit der zweiten Stufe
Derzeit benötigen wir den Wert id_stage für die zweite Stufe, der 2 ist, und den Wert von name für die zweite Stufe, den wir mit „Second“ gleichgesetzt haben. Um die Jobs der zweiten Stufe zu erstellen, müssen wir alle Jobs der ersten Stufe nehmen und einen entsprechenden Job der zweiten Stufe mit demselben Symbol und Zeitrahmen erstellen. Der Wert des Feldes tester_inputs wird als Zeichenkette gebildet, in dem die ID des entsprechenden Jobs der ersten Stufe auf den Eingang idParentJob_ EA gesetzt wird.
Führen wir dazu die folgende SQL-Abfrage in der Hauptdatenbank aus:
INSERT INTO jobs SELECT NULL, 2 AS id_stage, j.symbol, j.period, 'idParentJob_=' || j.id_job || '||0||1||10||N' AS tester_inputs, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='First';
Wir müssen ihn nur einmal ausführen, und die Jobs der zweiten Stufe werden für alle bestehenden Jobs der ersten Stufe erstellt:
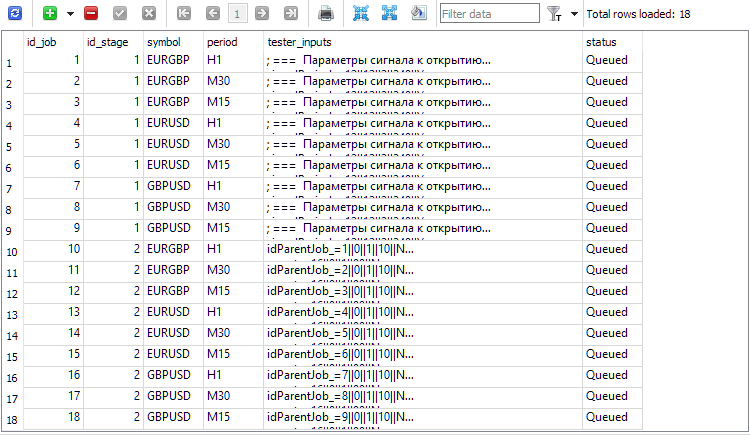
Abb. 2. Einträge für die Jobs der zweiten Stufe hinzugefügt (id_job = 10 .. 18)
Sie haben vielleicht bemerkt, dass sowohl die erste Stufe als auch die Aufgaben der ersten Stufe in der Hauptdatenbank den Status „Queued“ (in Warteschlange) haben, obwohl ich sagte, dass wir die erste Stufe der Optimierung bereits abgeschlossen haben. Das scheint ein Widerspruch zu sein. Ja, in der Tat. Zumindest im Moment. Wir haben nämlich noch nicht dafür gesorgt, dass die Zustände der Aufgaben nach Abschluss aller in der Arbeit enthaltenen Optimierungsaufgaben und die Zustände der Phasen nach Abschluss aller in den Phasen enthaltenen Aufgaben aktualisiert werden. Wir können dies auf zwei Arten beheben:
- durch Hinzufügen von zusätzlichem Code zu unserem Optimierungs-EA, sodass nach Abschluss jeder Optimierungsaufgabe geprüft wird, ob nicht nur die Zustände der Aufgaben, sondern auch der Jobs und Stages aktualisiert werden müssen;
- indem wir der Datenbank einen Trigger hinzufügen, der das Ereignis der Aufgabenänderung verfolgt. Wenn dieses Ereignis eintritt, muss der Triggercode prüfen, ob die Zustände von Jobs und Stufen aktualisiert werden müssen, und diese aktualisieren.
Es müssen nur noch Aufgaben für jeden Auftrag erstellt werden, und dann kann die zweite Phase eingeleitet werden. Anders als in der ersten Phase werden wir hier nicht mehrere Aufgaben mit unterschiedlichen Optimierungskriterien innerhalb eines Auftrags verwenden. Wir wollen nur ein Kriterium verwenden — den durchschnittlichen normalisierten Jahresgewinn. Um dieses Kriterium festzulegen, müssen wir im Feld Optimierungskriterium den Index 6 wählen.
Mit der folgenden SQL-Abfrage können wir für alle Jobs mit Optimierungskriterium 6 Aufgaben der zweiten Stufe erstellen:
INSERT INTO tasks SELECT NULL, j.id_job AS id_job, 6 AS optimization, NULL AS start_date, NULL AS finish_date, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='Second';
Wir führen es einmal aus und erhalten in der Aufgabentabelle neue Einträge, die den in der zweiten Phase durchgeführten Aufgaben entsprechen. Danach fügen wir den EA Optimization.ex5 zu einem beliebigen Terminal-Chart hinzu und warten, bis das Terminal alle Optimierungsaufgaben abgeschlossen hat. Die Ausführungszeit kann stark variieren, je nach EA selbst, der Länge des Testintervalls, der Anzahl der Symbole und Zeitrahmen und natürlich der Anzahl der beteiligten Agenten .
Für den in diesem Projekt verwendeten EA wurden alle Optimierungsaufgaben der zweiten Stufe in einem 2-Jahres-Intervall (2021 und 2022) in ca. 5 Stunden abgeschlossen, wobei die Optimierung über drei Symbole und drei Zeitrahmen mit 32 Agenten erfolgte. Werfen wir einen Blick auf das Ergebnis.
EA für bestimmte Durchgänge
Um unsere Aufgabe zu vereinfachen, nehmen wir einige kleine Änderungen an dem bestehenden EA vor. Wir werden die pass_ Eingabe implementieren, in der wir die durch Komma getrennten IDs der Strategiesätze angeben, die wir in diesem EA zu einer Gruppe zusammenfassen möchten.
In der EA-Initialisierungsmethode müssen wir dann nur noch die Parameter (Initialisierungsstrings der Strategiegruppen) dieser Übergänge aus der Hauptdatenbank abrufen und sie in den Initialisierungsstring des EA-Objekts im EA einfügen:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input string passes_ = "734469,735755,736046,736121,761710,776928,786413,795381"; // - Comma-separated pass IDs ulong magic_ = 27183; // - Magic bool useOnlyNewBars_ = true; // - Work only at bar opening datetime fromDate = TimeCurrent(); CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect()) { // Form a request to receive passes with the specified IDs string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " WHERE id_pass IN (%s);" , passes_); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // If no parameter sets are found, abort the test if(strategiesParams == NULL) { return INIT_FAILED; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Speichern wir die resultierende kombinierte EA in der Datei SimpleVolumesExpert.mq5 des aktuellen Ordners.
Die IDs der besten Durchläufe der zweiten Stufe können wir beispielsweise mit der folgenden SQL-Abfrage ermitteln:
SELECT p.id_pass, j.symbol, j.period, p.custom_ontester, p.profit, p.profit_factor, p.sharpe_ratio, p.equity_dd, p.params FROM ( SELECT p0.*, ROW_NUMBER() OVER (PARTITION BY id_task ORDER BY custom_ontester DESC) AS rn FROM passes p0 ) AS p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage WHERE rn = 1 AND s.name = 'Second';
In dieser Abfrage kombinieren wir wieder unsere Tabellen aus der Hauptdatenbank, sodass wir die Durchgänge auswählen können, die zur Stufe „Second“ gehören. Wir kombinieren auch die Tabelle passes mit ihrer Kopie, die in Abschnitte mit der gleichen Aufgabenkennung unterteilt ist. In jedem Abschnitt sind die Zeilen nummeriert und in absteigender Reihenfolge nach dem Wert unseres Optimierungskriteriums (custom_ontester) sortiert. Der Zeilenindex in den Abschnitten liegt innerhalb der Spalte rn. Im Endergebnis bleiben nur die ersten Zeilen aus jedem Abschnitt übrig - die mit dem höchsten Wert des Optimierungskriteriums.

Abb. 3. Die Liste der Pass-IDs für die besten Ergebnisse in jedem Auftrag der zweiten Stufe
Ersetzen wir die IDs aus der ersten Spalte id_pass in der Eingabe passes_ des kombinierten EA. Führen wir den Test durch und erhalten Sie die folgenden Ergebnisse:
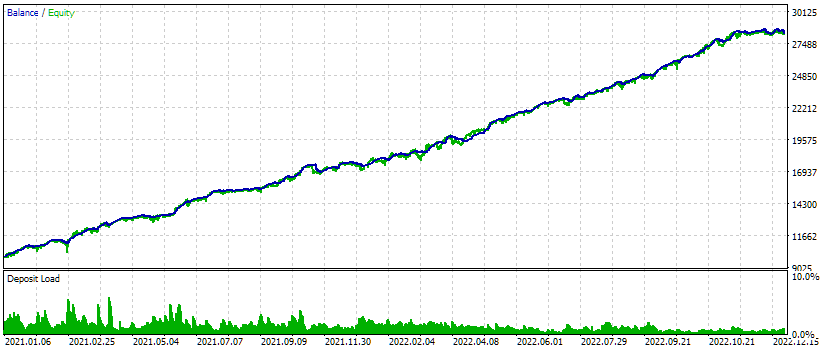

Abb. 4. Testergebnisse des kombinierten EA für drei Symbole und drei Zeitrahmen
Für dieses Testintervall sieht die Saldenkurve recht gut aus: Die Wachstumsrate bleibt während des gesamten Intervalls annähernd gleich, der Drawdown liegt innerhalb der akzeptablen erwarteten Grenzen. Aber mich interessiert mehr die Tatsache, dass wir jetzt fast automatisch einen EA-Initialisierungsstring generieren können, der mehrere der besten Gruppen von Einzelinstanzen von Handelsstrategien für verschiedene Symbole und Zeitrahmen kombiniert.
Schlussfolgerung
So wird auch die zweite Stufe unseres geplanten Optimierungsverfahrens in Form eines Entwurfs umgesetzt. Zur weiteren Vereinfachung wäre es gut, eine separate Web-Schnittstelle für die Erstellung und Verwaltung von Projekten zur Optimierung von Handelsstrategien zu schaffen. Bevor wir mit der Umsetzung verschiedener Verbesserungen der Lebensqualität beginnen, wäre es vernünftig, den gesamten geplanten Weg durchzugehen, ohne sich von Dingen ablenken zu lassen, auf die wir vorerst verzichten können. Darüber hinaus sind wir bei der Entwicklung von Umsetzungsoptionen oft gezwungen, den ursprünglichen Plan aufgrund neuer Umstände, die sich im Laufe des Prozesses ergeben, anzupassen.
Wir haben jetzt nur die erste und zweite Stufe der Optimierung in einem relativ kurzen Zeitintervall durchgeführt. Es wäre natürlich wünschenswert, das Testintervall zu verlängern und alles noch einmal zu optimieren. Wir haben auch nicht versucht, das Clustering auf der zweiten Stufe zu verbinden, was wir im sechsten Teil der Serie versucht haben, um eine Beschleunigung des Optimierungsprozesses zu erreichen. Dies würde jedoch einen wesentlich höheren Entwicklungsaufwand erfordern, da wir einen Mechanismus für die automatische Durchführung von Aktionen entwickeln müssten, die in MQL5 nur schwer zu implementieren sind, in Python oder R jedoch sehr leicht hinzugefügt werden können.
Es ist schwer zu entscheiden, in welche Richtung wir den nächsten Schritt gehen sollen. Lassen Sie uns also eine kleine Pause einlegen, damit die Dinge, die heute noch unklar sind, morgen klar werden.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14892
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo.
Vor Teil 16 mussten Sie genau das tun: die Dateien der Artikel einzeln herunterladen und die geänderten Dateien aktualisieren. Ab Teil 16 wird jeder Artikel von einem vollständigen Archiv des Projektordners begleitet.
Hallo.
Vor Teil 16 mussten Sie genau das tun: die Dateien der Artikel einzeln herunterladen und die geänderten Dateien aktualisieren. Ab Teil 16 wird jeder Artikel von einem vollständigen Archiv des Projektordners begleitet.
Vielen Dank für diese Antwort/ Ich werde sofort loslegen
Hallo nochmal,
Ich habe zwei Probleme.
Mit Teil 13 Code, wenn ich versuchte, Optimizer zu kompilieren, erhielt ich eine nicht identifizierte Bezeichner für DB::Open(), die in 1.00 und nicht in 1.03 der Datenbank war.
Das Kopieren des Codes von 1.00 in 1.03 löste diesen Fehler, erzeugte aber eine nicht identifizierte Kennung für Id(), die eindeutig im Datenbankobjekt enthalten ist.
Der andere Fehler ist, dass die Registerkarte "Artikel" in meinem Terminal Teil 13 Ihrer Artikel als die letzte englische Version auflistet. Wenn ich Ihrem Link folge, stelle ich fest, dass Sie zusätzlich zu Artikel 16 auch Teil 20 veröffentlicht haben.
Beide Artikel sind in kyrillischer Sprache, und wenn ich versuche, sie ins Englische zu übersetzen, wird eine völlig andere Seite in Englisch angezeigt. Dies ist auch beim Herunterladen von Multitester aufgetreten.
Haben Sie irgendwelche Vorschläge, um mir zu helfen, Ihrem ausgezeichneten Thema zu folgen?
Hallo.
Die Artikel werden zunächst auf Russisch geschrieben und später mit einer Verzögerung von etwa drei bis vier Monaten ins Englische und andere Sprachen übersetzt. Sie können also einfach warten, bis Teil 16 auf Englisch veröffentlicht wird. Das Ersetzen von "ru" durch "en" in der Artikeladresse beinhaltet keine automatische Übersetzung, sondern führt zu der von Übersetzern erstellten englischen Version des Artikels. Wenn die Übersetzung nicht bereits von MetaQuotes vorgenommen wurde, erhalten Sie eine Fehlermeldung, dass eine solche Seite nicht existiert.
Bei Fragen zu den Fehlern, die Sie beim Kompilieren erhalten, kann ich Ihnen leider nicht weiterhelfen. Ich kann hier ein Archiv des Projektordners aus dem Repository der Version anhängen, die zum Zeitpunkt der Veröffentlichung von Teil 13 die neueste war. Aber im Gegensatz zum Code in den übersetzten Artikeln sind dort alle Kommentare in den Dateien nicht auf Englisch.
Vielen Dank für die Klärung der Verzögerung. Ich denke, ich gehe zu Teil 16 und lade das System herunter und versuche es dann noch einmal. Ich weiß, dass ich Gefahr laufe, dass Änderungen zwischen 13 und 16 eingearbeitet werden, aber ich bin zuversichtlich, dass ich alle Konflikte lösen kann. Ich halte Sie auf dem Laufenden.