
多通貨エキスパートアドバイザーの開発(第13回):第2段階の自動化 - グループへの選択
はじめに
前回の記事ではリスクマネージャーについて少し触れましたが、本題のテスト自動化に戻りましょう。以前の記事の1つで、最終的なEA(エキスパートアドバイザー)の最適なパラメータを最適化して検索する際に完了する必要があるいくつかの段階について概説しました。すでに最初の段階を実装しており、そこで単一の取引戦略インスタンスのパラメータを最適化し、その結果をデータベースに保存しました。
次の段階は、取引戦略の単一インスタンスの優れたグループを選択し、それらを連携させることです。これにより、ドローダウンの削減、残高曲線の成長の直線性の向上など、取引パラメータが向上します。この段階は手動で実行する方法について、本連載第6部で説明しました。まず、単一取引戦略インスタンスのパラメータを最適化した結果から、注目に値するものを選択しました。これはさまざまな基準を使用して実行できますが、当時は利益がマイナスの結果のみを除外することに限定していました。その後、さまざまな方法を使用して、取引戦略の8つのインスタンスのさまざまな組み合わせを取得し、それらを1つのEAに組み合わせてテスターで実行し、共同作業のパラメータを評価しました。
手動選択から始めて、CSVファイルに保存されているパラメータのリストから選択された単一の取引戦略インスタンスの入力組み合わせの自動選択も実装しました。最も単純なケースでも、8つの組み合わせを選択する遺伝的最適化を実行するだけで、目的の結果が得られることが分かっています。
次に、グループ選択の最適化を実行したEAを変更し、第1段階の結果をデータベースから利用できるようにします。また、その結果をデータベースに保存する必要があります。また、データベースに必要なエントリを追加して、第2段階の最適化を実行するためのタスクを作成することも検討します。
テストエージェントへのデータの転送
適切なグループを選択するための以前のEAでは、リモートテストエージェントを使用して最適化を実行できるようにするために、少し調整が必要でした。問題は、最適化されたEAがCSVファイルからデータを読み取る必要があったことです。ローカルコンピュータのみで最適化をおこなう場合、この問題は発生しませんでした。データファイルを端末の共有フォルダに配置するだけで、すべてのローカルテストエージェントがアクセスできたからです。
しかし、リモートテストエージェントは、そのようなファイルにアクセスできません。このため、#property tester_fileディレクティブを使用しました。これにより、指定したファイルをすべてのテストエージェントのデータフォルダに渡すことができます。最適化が開始されると、データファイルは共有フォルダから、最適化プロセスを開始したローカルエージェントのデータフォルダにコピーされ、その後、ローカルエージェントデータフォルダのデータファイルは他のすべてのテストエージェントのデータフォルダに自動的に送信されました。
SQLiteデータベースで取引戦略の単一インスタンスをテストした結果のデータを得たので、最初に同じことをしようと考えました。SQLiteデータベースはメディア上の単一のファイルなので、上記のディレクティブを使用してリモートテストエージェントに同様に複製できます。しかし、ここで少し微妙な違いがあります。転送されたCSVファイルのサイズは約2MBでしたが、データベースファイルのサイズは300MBを超えていました。
この違いは、まず、各パスに関する統計情報をデータベースに最大限保存しようとした点にあります。一方、CSVファイルには、戦略インスタンスの入力パラメータに関する統計パラメータとデータのみがいくつか保存されていました。さらに、データベースには、3つの異なる銘柄と各銘柄の3つの異なる時間枠での戦略最適化の結果に関する情報がすでに含まれているため、パスの数はおよそ9倍に増加しました。
各テストエージェントが転送されたファイルの独自のコピーを受け取ることを考慮すると、テストを実行するには、32コアのサーバーに9GBを超えるデータを配置する必要があります。最初の段階でさらに多くの銘柄と時間枠を処理する場合、データベースを含むファイルのサイズは数倍に増加します。これにより、エージェントサーバーで使用可能なディスク領域が枯渇する可能性があり、ネットワーク経由で大量のデータを転送する必要が生じることは言うまでもありません。
ただし、第2段階では、完了したテストパスの結果に関する保存された情報の大部分は必要ないか、すべてを同時に必要としません。言い換えると、1つのパスに保存された値のセット全体から、このパスで使用されるEA初期化文字列のみを抽出する必要があります。また、取引戦略の単一コピーのグループをいくつか収集する予定です(銘柄と時間枠の組み合わせごとに1つ)。たとえば、EURGBP H1グループを検索する場合、EURGBP以外の銘柄とH1以外の時間枠のパスに関するデータは必要ありません。
では、次のことを実行してみましょう。各最適化を開始するときに、定義済みの名前で新しいデータベースを作成し、特定の最適化タスクに必要な最小限の情報を入力します。 既存のデータベースを「メインデータベース」と呼び、作成される新しいデータベースは「最適化問題データベース」または単に「タスクデータベース」と呼びます。
#property tester_fileディレクティブでデータベースファイルの名前を指定するため、このデータベースファイルはテストエージェントに渡されます。テストエージェントで実行する場合、最適化されたEAはメインデータベースからのこの抽出を使用して動作します。データフレーム収集モードでローカルコンピュータで実行する場合、最適化されたEAはテストエージェントから受け取ったデータをメインデータベースに保存します。
このようなワークフローを実装するには、まず、データベースを処理するためのCDatabaseクラスを変更する必要があります。
Cデータベースの変更
このクラスを開発している際、単一のEAのコードから複数のデータベースを操作する必要が出てくるとは予想していませんでした。それどころか、後で何をどこに保存するかで混乱しないように、1つのデータベースだけで作業すべきだと思っていました。しかし、現実には状況に応じて調整をおこない、アプローチを変更する必要がありました。
編集を最小限に抑えるため、今のところCDatabaseクラスは静的のままにしておくことにしました。つまり、クラスオブジェクトを作成せず、そのpublicメソッドを特定の名前空間内の関数のセットとしてのみ使用します。同時に、このクラスではprivateプロパティやメソッドを使用することも可能です。
異なるデータベースへの接続を可能にするために、Open() メソッドを変更し、Connect()と名前を変更しました。名前の変更の理由は、新しいConnect()メソッドが最初に追加され、その後このメソッドが実際にはOpen()と同じ機能を果たすことがわかったからです。そのため、Open()メソッドを放棄することにしました。
新しいConnect()メソッドと以前のOpen()メソッドの主な違いは、データベース名をパラメータとして渡すことができる点です。Open()メソッドは、常に、定数であるs_fileNameプロパティで指定された名前のデータベースのみを開いていました。新しいConnect()メソッドは、データベース名を渡さない場合でもこの動作を維持しますが、名前を指定すると、その名前でデータベースが開かれると同時に、その名前がs_fileNameプロパティに保存されます。したがって、Connect()メソッドに空でない名前を渡して繰り返し呼び出すと、最後に開かれたデータベースが開かれることになります。
Connect()メソッドにファイル名を渡すだけでなく、共有フォルダを使用するフラグも渡します。これは、メインデータベースを共通のターミナルデータフォルダに保存し、タスクデータベースをテストエージェントのデータフォルダに保存するためです。そのため、場合によってはデータベースオープン関数でDATABASE_OPEN_COMMONフラグを指定する必要があります。フラグを保存するための新しい静的クラスs_commonを追加します。デフォルトでは、共有フォルダからデータベースファイルを開くことを想定しており、メインのベース名s_fileName静的プロパティの初期値として引き続き設定されます。
クラスの説明は以下のとおりです。
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name static int s_common; // Flag for using shared data folder public: static int Id(); // Database connection handle static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB // Connect to the database with a given name and location static bool Connect(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON ); static void Close(); // Closing DB ... }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database892.sqlite"; int CDatabase::s_common = DATABASE_OPEN_COMMON;
Connect()メソッド自体では、まず現在開いているデータベースがあるかどうかを確認します。開いている場合は、それを閉じます。次に、新しいデータベースファイル名が指定されているかどうかを確認し、指定されている場合は、共有フォルダにアクセスするための新しい名前とフラグを設定します。その後、データベースを開く手順を実行し、必要に応じて空のデータベースファイルを作成します。
この時点で、Create()メソッドを呼び出すことで、以前と同様に新しく作成されたデータベースにテーブルとデータを強制的に入力する処理が削除されました。主に既存のデータベースを操作するため、こちらの方が便利です。データベースを再作成して初期情報を再度入力する必要がある場合は、補助的なCleanDatabaseスクリプトを使用できます。
//+------------------------------------------------------------------+ //| Check connection to the database with the given name | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, int p_common) { // If the database is open, close it if(IsOpen()) { Close(); } // If a file name is specified, save it together with the shared folder flag if(p_fileName != NULL) { s_fileName = p_fileName; s_common = p_common; } // Open the database // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } } return true; }
現在のフォルダのDatabase.mqhファイルに変更を保存します。
第1段階EA
この記事では、第1段階のEAは使用しませんが、一貫性を保つためにいくつかの小さな変更を加えます。まず、前回の記事で追加したリスクマネージャー入力を削除します。第1段階ではリスクマネージャーパラメータを選択しないため、このEAでは必要ありません。次の最適化段階のいずれかのEAにそれらを追加します。非アクティブ状態の初期化文字列からリスクマネージャーオブジェクト自体をすぐに作成します。
また、最適化の最初の段階では、マジックナンバー、取引の固定残高、スケーリング係数などの入力パラメータを変更する必要はありません。したがって、アナウンス時にinputワードをそれらから取り除きます。次のコードを取得します。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int idTask_ = 0; input group "=== Opening signal parameters" input int signalPeriod_ = 130; // Number of candles for volume averaging input double signalDeviation_ = 0.9; // Relative deviation from the average to open the first order input double signaAddlDeviation_ = 1.4; // Relative deviation from the average for opening the second and subsequent orders input group "=== Pending order parameters" input int openDistance_ = 231; // Distance from price to pending order input double stopLevel_ = 3750; // Stop Loss (in points) input double takeLevel_ = 50; // Take Profit (in points) input int ordersExpiration_ = 600; // Pending order expiration time (in minutes) input group "=== Money management parameters" input int maxCountOfOrders_ = 3; // Maximum number of simultaneously open orders ulong magic_ = 27181; // Magic double fixedBalance_ = 10000; double scale_ = 1; datetime fromDate = TimeCurrent(); CAdvisor *expert; // Pointer to the EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CMoney::FixedBalance(fixedBalance_); CMoney::DepoPart(1.0); // Prepare the initialization string for a single strategy instance string strategyParams = StringFormat( "class CSimpleVolumesStrategy(\"%s\",%d,%d,%.2f,%.2f,%d,%.2f,%.2f,%d,%d)", Symbol(), Period(), signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_ ); // Prepare the initialization string for a group with one strategy instance string groupParams = StringFormat( "class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " )", strategyParams, scale_ ); // Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )", 0,0,0,0,0,0 ); // Prepare the initialization string for an EA with a group of a single strategy and the risk manager string expertParams = StringFormat( "class CVirtualAdvisor(\n" " %s,\n" " %s,\n" " %d,%s,%d\n" ")", groupParams, riskManagerParams, magic_, "SimpleVolumesSingle", true ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
取得したコードを現在のフォルダにSimpleVolumesStage1.mq5という新しい名前で保存します。
第2段階EA
この記事の主要ポイントである第2段階のEAの最適化についてお話しします。すでに述べたように、第1段階で取得した取引戦略の単一インスタンスのグループ選択を最適化することが目的です。第6部のOptGroupExpert.mq5 EAをベースとして使用し、必要な変更を加えていきます。
まず、#property tester_fileディレクティブでテストタスクデータベースの名前を設定します。 特定の名前の選択自体は重要ではありません。この名前は、このEA内で1回の最適化実行を実行するためだけに使用されるためです。
#define PARAMS_FILE "database892.stage2.sqlite" #property tester_file PARAMS_FILE
入力で指定されたCSVファイル名の代わりに、メインデータベースの名前を指定します。
input group "::: Selection for the group" sinput string fileName_ = "database892.sqlite"; // - File with the main database
メメインデータベースの「ジョブ」テーブルで定義されている、同じ銘柄と時間枠で動作する取引戦略の単一インスタンスのグループを選択するため、現在のグループに含める取引戦略の単一インスタンスのセットを形成するタスクを持つジョブのIDを指定できるよう、入力項目にその機能を追加します。
input int idParentJob_ = 1; // - Parent job ID
これまでは8つのコピーからなるグループを選択していましたが、今回はその数を16に増やします。この変更をおこなうために、追加の戦略インスタンスインデックス用として新たに8つの入力を追加し、さらにcount_パラメータのデフォルト値を増やします。
input int count_ = 16; // - Number of strategies in the group (1 .. 16) input int i1_ = 1; // - Strategy index #1 input int i2_ = 2; // - Strategy index #2 input int i3_ = 3; // - Strategy index #3 input int i4_ = 4; // - Strategy index #4 input int i5_ = 5; // - Strategy index #5 input int i6_ = 6; // - Strategy index #6 input int i7_ = 7; // - Strategy index #7 input int i8_ = 8; // - Strategy index #8 input int i9_ = 9; // - Strategy index #9 input int i10_ = 10; // - Strategy index #10 input int i12_ = 11; // - Strategy index #11 input int i11_ = 12; // - Strategy index #12 input int i13_ = 13; // - Strategy index #13 input int i14_ = 14; // - Strategy index #14 input int i15_ = 15; // - Strategy index #15 input int i16_ = 16; // - Strategy index #16
現在の最適化タスクのデータベースの作成を処理する別の関数を作成しましょう。関数では、DB::Connect()メソッドを呼び出してタスクデータベースに接続します。データベースには、2つのフィールドを持つ1つのテーブルのみを追加します。
- id_pass:第1段階でのテスターパスID
- params:第1段階でのテスターパスのEA初期化文字列
テーブルがすでに追加されている場合(これが第2段階の最適化の最初の実行ではない場合)、新しい最適化には第1段階からの他のパスが必要になるため、テーブルを削除して再作成します。
次に、メインデータベースに接続し、そこからグループを選択するテストパスのデータを抽出します。メインデータベースファイルの名前は、fileNameパラメータとして関数に渡されます。必要なデータを取得するためのクエリは、passes、tasks、jobs、stagesテーブルを結合し、次の条件を満たす行を返します。
- パスの段階名は「First」である。これは第1段階のことで、この名前で最初の段階に属するパスのみを並び替えできる。
- ジョブIDは、idParentJob関数パラメータで渡されたIDと同じである。
- パス正規化利益が2500を超える。
- 取引数が20を超える;
- シャープ比は2より大きい。
最後の3つの条件はオプションです。これらのパラメータは、第1段階の特定のパスの結果に基づいて選択されたため、一方では、クエリ結果にかなりの数のパスが含まれ、他方では、これらのパスの品質が良好になります。
クエリ結果を取得しながら、タスクデータベースにデータを挿入するためのSQLクエリの配列をすぐに作成します。すべての結果が取得されたら、メインデータベースからタスクデータベースに切り替えて、生成されたすべてのデータ挿入クエリを1つのトランザクションで実行します。その後、メインデータベースに戻ります。
//+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Request to obtain the required information from the main database string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE (s.name='First' AND " " j.id_job = %d AND" " p.custom_ontester > 2500 AND " " trades > 20 AND " " p.sharpe_ratio > 2)" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC;", idParentJob); // Execute the request int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return; } // Structure for query results struct Row { string params; } row; // Array for requests to insert data into a new database string queries[]; // Fill the request array: we will only save the initialization strings while(DatabaseReadBind(request, row)) { APPEND(queries, StringFormat("INSERT INTO passes VALUES(NULL, '%s');", row.params)); } // Reconnect to the new database and fill it DB::Connect(PARAMS_FILE, 0); DB::ExecuteTransaction(queries); // Reconnect to the main database DB::Connect(fileName); DB::Close(); }
この関数は2つの場所で呼び出されます。主な呼び出し場所はOnTesterInit()ハンドラであり別の端末チャートで最適化を開始する前に起動されます。そのタスクは、最適化タスクデータベースを作成して入力し、作成されたタスクデータベース内の取引戦略の単一インスタンスのパラメータセットの存在を確認し、単一インスタンスインデックスを列挙するための正しい範囲を設定することです。
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Create a database for a separate stage task CreateTaskDB(fileName_, idParentJob_); // Get the number of strategy parameter sets int totalParams = GetParamsTotal(); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 1; i <= 16; i++) { if(i <= count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 1, 1, totalParams); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 1, 1, totalParams); } } return CVirtualAdvisor::TesterInit(idTask_); }
個別のGetParamsTotal()関数は、単一インスタンスのパラメータセットの数を取得するタスクを担います。その目的は非常に単純です。タスクデータベースに接続し、必要な数量を取得する1つのSQLクエリを実行して、その結果を返します。
//+------------------------------------------------------------------+ //| Number of strategy parameter sets in the task database | //+------------------------------------------------------------------+ int GetParamsTotal() { int paramsTotal = 0; // If the task database is open, if(DB::Connect(PARAMS_FILE, 0)) { // Create a request to get the number of passes for this task string query = "SELECT COUNT(*) FROM passes p"; int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query result struct Row { int total; } row; // Get the query result from the first string if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } return paramsTotal; }
次に、取引戦略の単一インスタンスのパラメータセットをロードするためのLoadParams()関数を書き直します。以前の実装とは異なり、ファイル全体を読み取り、すべてのパラメータセットを含む配列を作成し、この配列から必要なものをいくつか選択しましたが、今回は別の方法でおこないます。この関数に必要なセットインデックスのリストを渡し、タスクデータベースからこれらのインデックスを持つセットのみを抽出するSQLクエリを作成します。データベースから取得したパラメータセット(初期化文字列の形式)を、この関数によって返される単一のコンマ区切りの初期化文字列に結合します。
//+------------------------------------------------------------------+ //| Loading strategy parameter sets | //+------------------------------------------------------------------+ string LoadParams(int &indexes[]) { string params = NULL; // Get the number of sets int totalParams = GetParamsTotal(); // If they exist, then if(totalParams > 0) { if(DB::Connect(PARAMS_FILE, 0)) { // Form a string from the indices of the comma-separated sets taken from the EA inputs // for further substitution into the SQL query string strIndexes = ""; FOREACH(indexes, strIndexes += IntegerToString(indexes[i]) + ","); strIndexes += "0"; // Add a non-existent index so as not to remove the last comma // Form a request to obtain sets of parameters with the required indices string query = StringFormat("SELECT params FROM passes p WHERE id_pass IN(%s)", strIndexes); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query results struct Row { string params; } row; // Read the query results and join them with a comma while(DatabaseReadBind(request, row)) { params += row.params + ","; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } } return params; }
最後に、EAの初期化関数について説明します。資本管理のパラメータ設定に加え、まず、単一の取引戦略インスタンスに対応するパラメータセットのインデックスを必要な数だけ組み立てます。この数はcount_というEA入力で指定され、インデックスはi{N}_という名前で設定されます(ここで、{N}は1から16の値を取ります)。
次に、すべてのインデックスをセット型コンテナ(CHashSet)に格納し、セット内のインデックス数が配列の長さと一致していることを確認します。これにより、重複がないかをチェックできます。もしセット内のインデックス数が配列の長さより少ない場合は、不正な入力と見なされ、このパスは実行されません。
インデックスに問題がなければ、次に現在のEAモードを確認します。もし最適化手順の一部であれば、タスクデータベースは最適化の開始前に確実に作成され、利用可能な状態にあります。一方、通常のテスト実行の場合、タスクデータベースの存在が保証されていないため、CreateTaskDB()関数を呼び出して再作成します。
その後、タスクデータベースから必要なインデックスを持つパラメータセットを、単一の初期化文字列(またはEAオブジェクトの最終的な初期化文字列の一部)としてロードします。最後に、初期化文字列を完成させ、その内容に基づいてEAオブジェクトを作成します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Array of all indices from the EA inputs int indexes_[] = {i1_, i2_, i3_, i4_, i5_, i6_, i7_, i8_, i9_, i10_, i11_, i12_, i13_, i14_, i15_, i16_ }; // Array for indices to be involved in optimization int indexes[]; ArrayResize(indexes, count_); // Copy the indices from the inputs into it FORI(count_, indexes[i] = indexes_[i]); // Multiplicity for parameter set indices CHashSet<int> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 16 // number of instances not in the range 1 .. 16 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // If this is not an optimization, then you need to recreate the task database if(!MQLInfoInteger(MQL_OPTIMIZATION)) { CreateTaskDB(fileName_, idParentJob_); } // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // If nothing is loaded, report an error if(strategiesParams == NULL) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", "database892.sqlite"); return(INIT_PARAMETERS_INCORRECT); } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }現在のフォルダのSimpleVolumesStage2.mq5ファイルに加えた変更を保存します。第2段階で最適化される EAの準備ができました。次に、メインデータベースで最適化の第2段階のタスクの作成を開始しましょう。
第2段階のタスクの作成
最適化の第2段階を作成しましょう。これをおこなうには、段階テーブルに新しい行を追加し、以下のように値を入力します。

図1:第2段階を含む「段階」テーブル行
現在、第2段階のid_stageの値を2に設定し、nameの値をSecondにする必要があります。第2段階のジョブを作成するためには、第1段階のすべてのジョブを取得し、同じ銘柄と時間枠に基づいて第2段階に対応するジョブを作成する必要があります。tester_inputsフィールドの値は文字列として形成され、対応する第1段階のジョブのIDがidParentJob_ EA入力に設定されます。
これをおこなうには、メインデータベースで次のSQLクエリを実行します。
INSERT INTO jobs SELECT NULL, 2 AS id_stage, j.symbol, j.period, 'idParentJob_=' || j.id_job || '||0||1||10||N' AS tester_inputs, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='First';
これを一度だけ実行すれば、既存の第1段階のジョブすべてに対して第2段階のジョブが作成されます。
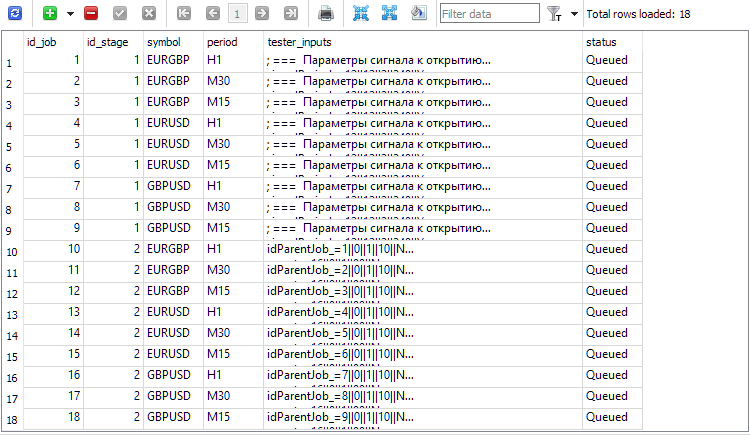
図2:第2段階のジョブのエントリが追加された(id_job = 10 ..18)
最適化の第1段階はすでに完了していると述べましたが、メインデータベースの第1段階とそのタスクの両方がQueuedステータスになっていることにお気づきかもしれません。これは一見矛盾しているように思えるかもしれません。はい、確かにそうです。少なくとも今のところはそうです。実際には、作業に含まれる最適化タスクが完了したときにジョブの状態や段階の状態が更新される処理がまだおこなわれていません。これを修正する方法は2通り考えられます。
- 最適化EAに追加コードを加えて、各最適化タスクが完了した際に、そのタスクのみならずジョブと段階の状態も更新するかどうかを確認するチェックをおこなう方法。
- データベースにタスク変更イベントを追跡するトリガーを追加し、このイベントが発生した際にジョブと段階の状態を更新する方法。
そのため、現時点では、すでに実装したタスクのステータスだけを更新し、ジョブの作成と第2段階の開始に注力します。第1段階とは異なり、第2段階では1つの基準のみを使用します。今回は「平均正規化年間利益」を基準とし、この基準を設定するために最適化基準フィールドでインデックス6を選択します。
次のSQLクエリを使用して、最適化基準6を持つすべてのジョブの第2段階のタスクを作成できます。
INSERT INTO tasks SELECT NULL, j.id_job AS id_job, 6 AS optimization, NULL AS start_date, NULL AS finish_date, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='Second';
まず、第2段階で実行されたタスクに対応する新しいエントリをタスクテーブルに追加してみましょう。その後、任意の端末チャートにOptimization.ex5 EAを追加し、端末がすべての最適化タスクを完了するまで待機します。実行時間は、EA自体の処理時間、テスト間隔の長さ、銘柄と時間枠の数、そしてもちろん、最適化に参加するエージェントの数によって大きく異なります。
このプロジェクトで使用されたEAでは、32のエージェントを使用して、3つの銘柄と3つの時間枠を対象に最適化がおこなわれました。最適化は2021年と2022年の2年間を対象としており、すべての第2段階の最適化タスクは約5時間で完了しました。結果を見てみましょう。
指定パスのEA
タスクを簡素化するため、既存のEAにいくつかの小さな変更を加えてみましょう。passes_入力を実装し、このEAで1つのグループにまとめる戦略セットのコンマ区切りIDを指定します。
次に、EA初期化メソッドでは、メインデータベースからこれらのパスのパラメータ(戦略グループの初期化文字列)を取得し、EA内のEAオブジェクトの初期化文字列に代入します。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input string passes_ = "734469,735755,736046,736121,761710,776928,786413,795381"; // - Comma-separated pass IDs ulong magic_ = 27183; // - Magic bool useOnlyNewBars_ = true; // - Work only at bar opening datetime fromDate = TimeCurrent(); CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect()) { // Form a request to receive passes with the specified IDs string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " WHERE id_pass IN (%s);" , passes_); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // If no parameter sets are found, abort the test if(strategiesParams == NULL) { return INIT_FAILED; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
結果として得られた結合されたEAを、現在のフォルダにあるSimpleVolumesExpert.mq5ファイルに保存します。
たとえば、次のSQLクエリを使用して、第2段階のベストパスのIDを取得できます。
SELECT p.id_pass, j.symbol, j.period, p.custom_ontester, p.profit, p.profit_factor, p.sharpe_ratio, p.equity_dd, p.params FROM ( SELECT p0.*, ROW_NUMBER() OVER (PARTITION BY id_task ORDER BY custom_ontester DESC) AS rn FROM passes p0 ) AS p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage WHERE rn = 1 AND s.name = 'Second';
このクエリでは、メインデータベースのテーブルを再度結合し、「Second」という段階に属するパスを選択できるようにします。また、passsテーブルを、同じタスクIDを持つセクションに分割されたコピーと結合します。各セクション内では、行に番号を付け、最適化基準値(custom_ontester)の降順で並べ替えます。セクション内の行インデックスは、rn列に格納されます。最終結果では、各セクションの最初の行(最適化基準値が最高の行)のみが残ります。

図3:第2段階の各ジョブで最高成績を収めたパスIDのリスト
最初の列id_passのIDを、結合されたEAのpassing_入力に置き換えてみましょう。テストを実行すると、次の結果が得られます。
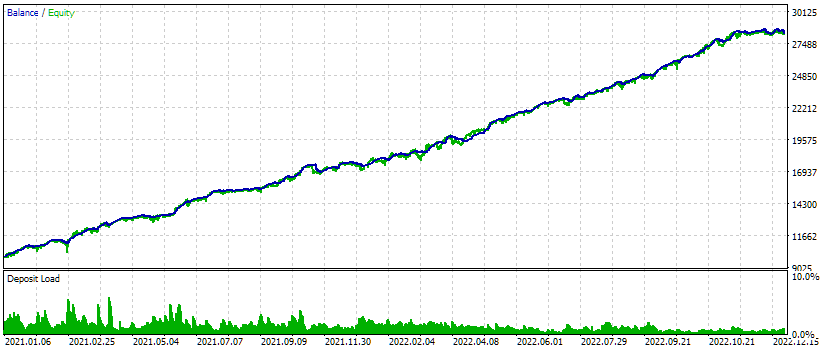

図4:3つの銘柄と3つの時間枠の複合EAのテスト結果
このテスト間隔では、エクイティグラフは非常に良好に見えます。成長率は期間全体を通じてほぼ一定で、ドローダウンも許容範囲内で予想通りです。しかし、私がより興味を持っているのは、さまざまなシンボルと時間枠の取引戦略を組み合わせ、最適なグループを選んだEA初期化文字列をほぼ自動的に生成できるようになった点です。
結論
計画されていた最適化手順の第2段階が草案の形で実装されました。さらに利便性を向上させるために、取引戦略を最適化するプロジェクトの作成および管理をおこなうための専用のWebインターフェイスを開発することを検討すると良いでしょう。多くの利便性の向上を実装する前に、今はそれに気を取られることなく、計画した通りにパス全体を実行することが合理的です。また、実装オプションを開発している過程で、前進するにつれて新たに生じる状況に応じて元の計画に調整を加えることはよくあることです。
ここまででは、比較的短い期間で第1段階と第2段階の最適化のみをおこないました。もちろん、テスト間隔を延ばしてすべてを再度最適化することは望ましいでしょう。また、第2段階でのクラスタリングの接続は試みていません。これは本連載第6回で最適化プロセスの加速を実現した方法ですが、MQL5での実装は難しく、PythonやRでは簡単に追加できるため、実行するには多くの開発労力が必要です。
次にどの方向に進むべきか決めるのは難しいですが、今日は少し休憩して、明日には不明なことが明らかになることを期待しています。
ご清聴ありがとうございました。またすぐにお会いしましょう。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14892
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは。
パート16 以前は、記事から1つずつファイルをダウンロードし、変更されたものを更新するという、まさにそのようなことをしなければなりませんでした。パート16から、各記事にはプロジェクトフォルダの完全なアーカイブが添付されるようになりました。
こんにちは。
パート16 以前は、記事からファイルを1つずつダウンロードし、変更されたものを更新するという、まさにそのような作業を行う必要がありました。パート16から、各記事にはプロジェクトフォルダの完全なアーカイブが添付されるようになりました。
ご回答ありがとうございました。
またまたこんにちは、
私は2つの問題を抱えています。
Part13のコードを使用して、Optimizerをコンパイルしようとしたところ、DB::Open()の識別子が1.00にあり、データベースの1.03にはないというエラーが発生しました。
1.00のコードを1.03にコピーすると、このエラーは解消されましたが、明らかにデータベース・オブジェクトにあるId()に対して未確認の識別子が生成されました。
もう1つのエラーは、私のTerminalのArticlesタブに、あなたの記事のPart13が最後の英語版としてリストされていることです。あなたのリンクをたどると、Article16に加えて、Part20が公開されています。
これらの記事は両方ともキリル文字で、英語に翻訳しようとすると、全く別のページが英語で表示されます。 これはMultitesterのダウンロード時にも発生しました。
あなたの素晴らしいスレッドに従うにあたり、何かお勧めの方法はありますか?
こんにちは。
記事は最初にロシア語で書かれ、3~4カ月ほど遅れて英語などに翻訳されます。ですから、パート16が英語で発表されるまで待つことができます。記事アドレスの "ru "を "en "に置き換えても、自動翻訳は行われず、翻訳者によって作成された英語版の記事につながります。翻訳がまだMetaQuotesによって行われていない場合、そのようなページは存在しないというエラーが表示されます。
コンパイル中に表示されるエラーについてのご質問は、恐れ入りますが、お力になるのは難しいです。パート13を公開した時点で最新だったバージョンのリポジトリから、プロジェクトフォルダの アーカイブをここに添付することができます。しかしそこでは、翻訳された記事のコードとは異なり、ファイル内のコメントはすべて英語ではありません。
ラグを明確にしてくれて本当にありがとう。 パート16に進み、システムをダウンロードしてから、もう一度トライしてみようと思う。 13と16の間に組み込まれた変更のリスクは承知しているが、どんなコンフリクトも解決できると期待している。 また連絡するよ。