
Developing a multi-currency Expert Advisor (Part 13): Automating the second stage — selection into groups
Introduction
Having been distracted a bit by the risk manager in the last article, let's get back to the main topic — test automation. In one of the previous articles, we outlined several stages that should be completed while optimizing and searching for the best parameters of the final EA. We have already implemented the first stage, at which we optimized the parameters of a single trading strategy instance. Its results were saved in the database.
The next stage is a selection of good groups of single instances of trading strategies that, when working together, will improve trading parameters — reduce drawdown, increase the linearity of the balance curve growth, and so on. We already looked at how to carry out this stage manually in the sixth part of the series. First, we selected from the results of optimizing the parameters of single trading strategy instances those that deserved attention. This could have been done using various criteria, but at that time we limited ourselves to simply removing results with negative profit. Then, using different methods, we tried to take different combinations of eight instances of trading strategies, combine them in one EA and run them in the tester to evaluate the parameters of their joint work.
Starting with manual selection, we also implemented auto selection of input combinations of single trading strategies instances selected from the list of parameters stored in a CSV file. It turns out that even in the simplest case, the desired result is achieved when we simply run genetic optimization that selects eight combinations.
Let's now modify the EA that performed the group selection optimization so that it can use the results of the first stage from the database. It should also save its results in the database. We will also consider creating tasks for conducting second-stage optimizations by adding the necessary entries to our database.
Transferring data to test agents
For the previous EA for selecting suitable groups, we had to tinker a bit to ensure that optimization could be performed using remote test agents. The problem was that the optimized EA had to read data from a CSV file. This did not cause any problems when optimizing on a local computer only — it was enough to place the data file in the terminal shared folder, and all local test agents could access it.
But remote test agents do not have access to such a file with data. This is why we used the #property tester_file directive, which allows us to pass any specified file to all test agents in their data folder. When optimization was started, the data file was copied from the shared folder to the data folder of the local agent that started the optimization process. The data file from the local agent data folder was then automatically sent to the data folders of all other test agents.
Since we now have data on the results of testing single instances of trading strategies in the SQLite database, my first impulse was to do the same. Since the SQLite database is a single file on the media, it can be replicated to remote test agents in the same way using the above-mentioned directive. But there is a small nuance here — the size of the transferred CSV file was approximately 2 MB, while the size of the database file exceeded 300 MB.
This difference is due to the fact that, firstly, we tried to save the maximum possible amount of statistical information about each pass in the database, and the CSV file stored only a few statistical parameters and data on the values of the input parameters of the strategy instances. Secondly, in our database, we already have information about the results of strategy optimization on three different symbols and three different timeframes for each symbol. In other words, the number of passes increased approximately ninefold.
Considering that each test agent receives its own copy of the transferred file, we would need to place over 9 GB of data on a 32-core server to run a test on it. If we handle an even greater number of symbols and timeframes at the first stage, the size of the file with the database will increase several times. This can lead to the exhaustion of available disk space on agent servers, not to mention the need to transfer large amounts of data over the network.
However, we will either not need most of the stored information about the results of the completed test passes at the second stage, or will not need it all at the same time. In other words, from the entire set of stored values for one pass, we need to extract only the EA initialization string used in this pass. We also plan to collect several groups of single copies of trading strategies — one for each combination of symbol and timeframe. For example, if we search for EURGBP H1 group, we do not need data on passes on symbols other than EURGBP and timeframes other than H1.
So let's do the following: when we start each optimization, we will create a new database with a predefined name and fill it with the minimum information necessary for a given optimization task. We will call the existing database the main database, while the new database being created is to be called the optimization problem database or simply the task database.
The database file will be passed to the test agents since we will specify its name in the #property tester_file directive. When running on the test agent, the optimized EA will work with this extract from the main database. When running on a local computer in the data frame collection mode, the optimized EA will still save the data received from the test agents to the main database.
The implementation of such a workflow will require, first of all, modification of the CDatabase class for handling the database.
CDatabase modification
When developing this class, I have not foreseen that we would need to work with several databases from the code of a single EA. On the contrary, it seemed that we should ensure that we work with only one database, so as not to get confused later about what we store and where. But reality makes its own adjustments, and we have to change our approach.
To minimize edits, I decided to leave the CDatabase class static for now. In other words, we will not create class objects, but will use its public methods simply as a set of functions in a given namespace. At the same time, we will still have the ability to use private properties and methods in this class.
To enable connection to different databases, we modify the Open() method renaming it to Connect(). The renaming happened because the new Connect() method was added first, then it turned out that it actually does the same job as Open(). Therefore, we decided to abandon the latter.
The main difference between the new method and its predecessor is the ability to pass the database name as a parameter. The Open() method always opened only the database with the name specified in the s_fileName property, which was a constant. The new method also retains this behavior if you do not pass a database name to it. If we pass a non-empty name to the Connect() method, then it will not only open the database with the passed name, but also save it in the s_fileName property. So the repeated call of Connect() without specifying a name will open the last opened database.
In addition to passing the file name to the Connect() method, we will also pass the flag of using the shared folder. This is necessary because it is more convenient to store our main database in the common terminal data folder, while the task database is stored in the test agent data folder. Therefore, in one case we will need to specify the DATABASE_OPEN_COMMON flag in the database open function in some case. Let's add a new static class s_common to store the flag. By default, we will assume that we want to open the database file from the shared folder. The main base name is still set as the initial value of the s_fileName static property.
Then the class description will look something like this:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name static int s_common; // Flag for using shared data folder public: static int Id(); // Database connection handle static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB // Connect to the database with a given name and location static bool Connect(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON ); static void Close(); // Closing DB ... }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database892.sqlite"; int CDatabase::s_common = DATABASE_OPEN_COMMON;
In the Connect() method itself, we will first check if any database is currently open. If yes, we will close it. Next, we will check if a new database file name has been specified. If yes, then set a new name and flag for accessing the shared folder. After this, we perform the steps to open the database, creating an empty database file if necessary.
At this point, we have removed the forced filling of the newly created database with tables and data by calling the Create() method, as it was done before. Since we are already working mostly with an existing database, this will be more convenient. If we still need to recreate and fill the database with initial information again, we can use the auxiliary CleanDatabase script.
//+------------------------------------------------------------------+ //| Check connection to the database with the given name | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, int p_common) { // If the database is open, close it if(IsOpen()) { Close(); } // If a file name is specified, save it together with the shared folder flag if(p_fileName != NULL) { s_fileName = p_fileName; s_common = p_common; } // Open the database // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } } return true; }
Save the changes in the Database.mqh file of the current folder.
First stage EA
In this article, we will not use the first stage EA, but for the sake of consistency we will make some minor changes to it. First, we will remove the risk manager inputs added in the previous article. We will not need them in this EA, since at the first stage we will definitely not select the risk manager parameters. We will add them to an EA of one of the following optimization stages. We will immediately create the risk manager object itself from the initialization string in an inactive state.
Also, at the first stage of optimization, we do not need to vary such input parameters as a magic number, fixed balance for trading and scaling factor. So let's take the input word away from them when announced. We get the following code:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int idTask_ = 0; input group "=== Opening signal parameters" input int signalPeriod_ = 130; // Number of candles for volume averaging input double signalDeviation_ = 0.9; // Relative deviation from the average to open the first order input double signaAddlDeviation_ = 1.4; // Relative deviation from the average for opening the second and subsequent orders input group "=== Pending order parameters" input int openDistance_ = 231; // Distance from price to pending order input double stopLevel_ = 3750; // Stop Loss (in points) input double takeLevel_ = 50; // Take Profit (in points) input int ordersExpiration_ = 600; // Pending order expiration time (in minutes) input group "=== Money management parameters" input int maxCountOfOrders_ = 3; // Maximum number of simultaneously open orders ulong magic_ = 27181; // Magic double fixedBalance_ = 10000; double scale_ = 1; datetime fromDate = TimeCurrent(); CAdvisor *expert; // Pointer to the EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CMoney::FixedBalance(fixedBalance_); CMoney::DepoPart(1.0); // Prepare the initialization string for a single strategy instance string strategyParams = StringFormat( "class CSimpleVolumesStrategy(\"%s\",%d,%d,%.2f,%.2f,%d,%.2f,%.2f,%d,%d)", Symbol(), Period(), signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_ ); // Prepare the initialization string for a group with one strategy instance string groupParams = StringFormat( "class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " )", strategyParams, scale_ ); // Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )", 0,0,0,0,0,0 ); // Prepare the initialization string for an EA with a group of a single strategy and the risk manager string expertParams = StringFormat( "class CVirtualAdvisor(\n" " %s,\n" " %s,\n" " %d,%s,%d\n" ")", groupParams, riskManagerParams, magic_, "SimpleVolumesSingle", true ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Save the obtained code under the new name SimpleVolumesStage1.mq5 in the current folder.
Second stage EA
It is time to get down to the main point of this article — to the second optimization stage EA. As already mentioned, it will be engaged in optimizing the selection of a group of single instances of trading strategies obtained in the first stage. Let's use the OptGroupExpert.mq5 EA from the sixth part as a basis and make the necessary changes to it.
First, set the name of the test task database in the #property tester_file directive. The choice of a specific name is not important, since it will only be used to perform one optimization run and only within this EA.
#define PARAMS_FILE "database892.stage2.sqlite" #property tester_file PARAMS_FILE
Instead of the CSV file name specified in the inputs, we will now specify the name of our main database:
input group "::: Selection for the group" sinput string fileName_ = "database892.sqlite"; // - File with the main database
Since we want to select groups of single instances of trading strategies working on the same symbol and timeframe, which in turn are defined in the main database in the 'jobs' table, we will add to the inputs the ability to specify the ID of the job whose tasks formed the set of single instances of trading strategies for selection into the current group:
input int idParentJob_ = 1; // - Parent job ID
Previously, we used a selection of groups of eight copies, but now we will increase their number to sixteen. To do this, add eight more inputs for additional strategy instance indices and increase the default value for the count_ parameter:
input int count_ = 16; // - Number of strategies in the group (1 .. 16) input int i1_ = 1; // - Strategy index #1 input int i2_ = 2; // - Strategy index #2 input int i3_ = 3; // - Strategy index #3 input int i4_ = 4; // - Strategy index #4 input int i5_ = 5; // - Strategy index #5 input int i6_ = 6; // - Strategy index #6 input int i7_ = 7; // - Strategy index #7 input int i8_ = 8; // - Strategy index #8 input int i9_ = 9; // - Strategy index #9 input int i10_ = 10; // - Strategy index #10 input int i12_ = 11; // - Strategy index #11 input int i11_ = 12; // - Strategy index #12 input int i13_ = 13; // - Strategy index #13 input int i14_ = 14; // - Strategy index #14 input int i15_ = 15; // - Strategy index #15 input int i16_ = 16; // - Strategy index #16
Let's create a separate function that will handle the creation of a database for the current optimization task. In the function, we will connect to the task database by calling the DB::Connect() method. We will add only one table with two fields to the database:
- id_pass — tester pass id at first stage
- params — EA initialization string for the tester pass at the first stage
If the table has already been added earlier (this is not the first run of the second stage optimization), then we will delete and recreate it, since we will need other passes from the first stage for the new optimization.
Then we connect to the main database and extract from it the data of those test passes we will now select a group from. The name of the main database file is passed to the function as the fileName parameter. The query to retrieve the required data joins the passes, tasks, jobs and stages tables and returns the rows that satisfy the following conditions:
- The stage name for the pass is "First". This is what we called the first stage, and by this name we can sort only the passes that belong to the first stage;
- job ID is equal to the ID passed in the idParentJob function parameter;
- pass normalized profit exceeds 2500;
- number of trades exceeds 20;
- Sharpe ratio is greater than 2.
The last three conditions are optional. Their parameters were selected based on the results of specific passes of the first stage so that, on the one hand, we would have quite a few passes included in the query results, and on the other hand, these passes would be of good quality.
While retrieving query results, we immediately create an array of SQL queries to insert data into the task database. Once all the results have been retrieved, we switch from the main database to the task database and execute all the generated data insertion queries in one transaction. After this, we switch back to the main database.
//+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Request to obtain the required information from the main database string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE (s.name='First' AND " " j.id_job = %d AND" " p.custom_ontester > 2500 AND " " trades > 20 AND " " p.sharpe_ratio > 2)" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC;", idParentJob); // Execute the request int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return; } // Structure for query results struct Row { string params; } row; // Array for requests to insert data into a new database string queries[]; // Fill the request array: we will only save the initialization strings while(DatabaseReadBind(request, row)) { APPEND(queries, StringFormat("INSERT INTO passes VALUES(NULL, '%s');", row.params)); } // Reconnect to the new database and fill it DB::Connect(PARAMS_FILE, 0); DB::ExecuteTransaction(queries); // Reconnect to the main database DB::Connect(fileName); DB::Close(); }
This function will be called in two places. Its main place of call is the OnTesterInit() handler, which is launched before the start of optimization on a separate terminal chart. Its task is to create and fill the optimization task database, check the presence of parameter sets of single instances of trading strategies in the created task database and set the correct ranges for enumerating single instance indices:
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Create a database for a separate stage task CreateTaskDB(fileName_, idParentJob_); // Get the number of strategy parameter sets int totalParams = GetParamsTotal(); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 1; i <= 16; i++) { if(i <= count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 1, 1, totalParams); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 1, 1, totalParams); } } return CVirtualAdvisor::TesterInit(idTask_); }
The separate GetParamsTotal() function gets the task of obtaining the number of parameter sets of single instances. Its objective is very simple: connect to the task database, execute one SQL query to obtain the required quantity and return its result:
//+------------------------------------------------------------------+ //| Number of strategy parameter sets in the task database | //+------------------------------------------------------------------+ int GetParamsTotal() { int paramsTotal = 0; // If the task database is open, if(DB::Connect(PARAMS_FILE, 0)) { // Create a request to get the number of passes for this task string query = "SELECT COUNT(*) FROM passes p"; int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query result struct Row { int total; } row; // Get the query result from the first string if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } return paramsTotal; }
Next, we will rewrite the LoadParams() function for loading sets of parameters of single instances of trading strategies. Unlike the previous implementation, when we read the entire file, created an array with all the parameter sets, and then selected several necessary ones from this array, now we will do it differently. We will pass this function a list of the required set indexes and form a SQL query that will extract only the sets with these indices from the task database. We will combine the parameter sets obtained from the database (in the form of initialization strings) into a single comma-separated initialization string, which will be returned by this function:
//+------------------------------------------------------------------+ //| Loading strategy parameter sets | //+------------------------------------------------------------------+ string LoadParams(int &indexes[]) { string params = NULL; // Get the number of sets int totalParams = GetParamsTotal(); // If they exist, then if(totalParams > 0) { if(DB::Connect(PARAMS_FILE, 0)) { // Form a string from the indices of the comma-separated sets taken from the EA inputs // for further substitution into the SQL query string strIndexes = ""; FOREACH(indexes, strIndexes += IntegerToString(indexes[i]) + ","); strIndexes += "0"; // Add a non-existent index so as not to remove the last comma // Form a request to obtain sets of parameters with the required indices string query = StringFormat("SELECT params FROM passes p WHERE id_pass IN(%s)", strIndexes); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query results struct Row { string params; } row; // Read the query results and join them with a comma while(DatabaseReadBind(request, row)) { params += row.params + ","; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } } return params; }
Finally, it is time for the EA initialization function. In addition to setting the capital management parameters, we first assemble an array of the required number of indices of parameter sets of single trading strategy instances. The required quantity is specified in the count_ EA input, while the indices themselves are set in the inputs with the names i{N}_, where {N} takes values from 1 to 16.
We then check the resulting array of indices for duplicates by placing all indices into a set-type container (CHashSet) and ensuring that the set has the same number of indices as the array. If this is the case, then all indices are unique. If the set has fewer indices than the array had, report incorrect inputs and do not run this pass.
If all is well with the indices, then check the current EA mode. If the pass is a part of the optimization procedure, then the task database was definitely created before the optimization started and is now available. If this is a regular single test run, then we cannot guarantee the existence of the task database, so we will simply recreate it by calling the CreateTaskDB() function.
After that, load parameter sets with the required indices from the task database in the form of a single initialization string (or rather, a part of it, which we will substitute into the final initialization string of the EA object). All that remains is to form the final initialization string and create an EA object from it.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Array of all indices from the EA inputs int indexes_[] = {i1_, i2_, i3_, i4_, i5_, i6_, i7_, i8_, i9_, i10_, i11_, i12_, i13_, i14_, i15_, i16_ }; // Array for indices to be involved in optimization int indexes[]; ArrayResize(indexes, count_); // Copy the indices from the inputs into it FORI(count_, indexes[i] = indexes_[i]); // Multiplicity for parameter set indices CHashSet<int> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 16 // number of instances not in the range 1 .. 16 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // If this is not an optimization, then you need to recreate the task database if(!MQLInfoInteger(MQL_OPTIMIZATION)) { CreateTaskDB(fileName_, idParentJob_); } // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // If nothing is loaded, report an error if(strategiesParams == NULL) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", "database892.sqlite"); return(INIT_PARAMETERS_INCORRECT); } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }Save the changes made to the SimpleVolumesStage2.mq5 file in the current folder. The EA to be optimized in the second stage is ready. Now let's start creating tasks for the second stage of optimization in the main database.
Creating second stage tasks
First, let's create the second stage of optimization itself. To do this, add a new row to the stages table and fill its values as follows:

Fig. 1. 'stages' table rows with the second stage
Currently, we need id_stage value for the second stage, which is 2, and the value of name for the second stage we made equal to Second. To create the jobs of the second stage, we need to take all the jobs of the first stage and create a corresponding work of the second stage with the same symbol and timeframe. The value of the tester_inputs field is formed as a string, in which the ID of the corresponding first stage job is set to the idParentJob_ EA input.
To do this, execute the following SQL query in the main database:
INSERT INTO jobs SELECT NULL, 2 AS id_stage, j.symbol, j.period, 'idParentJob_=' || j.id_job || '||0||1||10||N' AS tester_inputs, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='First';
We only need to execute it once, and the second stage jobs will be created for all the existing first stage jobs:
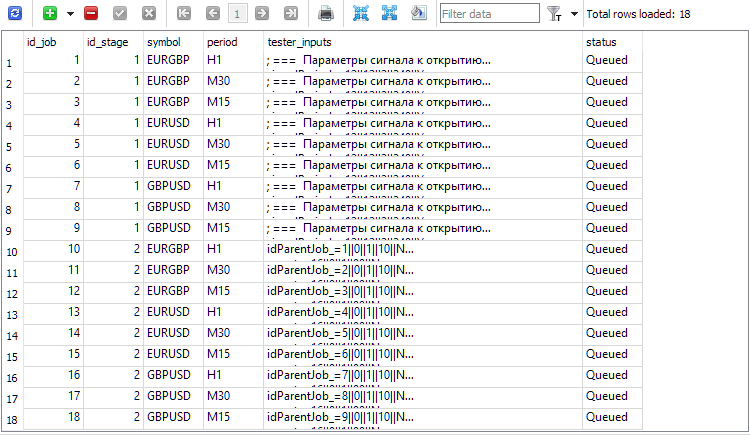
Fig. 2. Added entries for the second stage jobs (id_job = 10 .. 18)
You may have noticed that both the first stage and the tasks of the first stage in the main database have the Queued status, although I said that we have already completed the first stage of optimization. Seems like a contradiction. Yes, indeed. At least for now. The fact is that we have not yet taken care of updating the states of the jobs upon completion of all optimization tasks included in the work, and the states of the stages upon completion of all jobs included in the stages. We can fix this in two ways:
- by adding additional code to our optimizing EA, so that when each optimization task is completed, checks are performed to see if the states of not only tasks, but also jobs and stages need to be updated;
- by adding a trigger to the database that tracks the task change event. When this event occurs, the trigger code will need to check for the need to update the states of jobs and stages, and update them.
All that remains is to create tasks for each job, and then the second stage can be launched. Unlike the first stage, here we will not use several tasks with different optimization criteria within one job. Let's use only one criterion — the average normalized annual profit. To set this criterion, we need to select index 6 in the optimization criterion field.
We can create second-stage tasks for all jobs with optimization criterion 6 using the following SQL query:
INSERT INTO tasks SELECT NULL, j.id_job AS id_job, 6 AS optimization, NULL AS start_date, NULL AS finish_date, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='Second';
Let's run it once and get in the tasks table new entries corresponding to the tasks performed in the second stage. After that, add the Optimization.ex5 EA to any terminal chart and wait till the terminal completes all optimization tasks. Execution time can vary greatly depending on the EA itself, the length of the testing interval, the number of symbols and timeframes and, of course, the number of agents involved .
For the EA used in this project, all second-stage optimization tasks were completed in approximately 5 hours on a 2-year interval (2021 and 2022) with optimization across three symbols and three timeframes on 32 agents. Let's have a look at the results.
EA for specified passes
To simplify our task, let's make some small changes to the existing EA. We will implement the passes_ input, in which we will indicate the comma-separated IDs, the strategy sets from which we would like to combine into one group in this EA.
Then, in the EA initialization method, we just need to get the parameters (initialization strings of strategy groups) of these passes from the main database and substitute them into the initialization string of the EA object in the EA:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input string passes_ = "734469,735755,736046,736121,761710,776928,786413,795381"; // - Comma-separated pass IDs ulong magic_ = 27183; // - Magic bool useOnlyNewBars_ = true; // - Work only at bar opening datetime fromDate = TimeCurrent(); CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect()) { // Form a request to receive passes with the specified IDs string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " WHERE id_pass IN (%s);" , passes_); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // If no parameter sets are found, abort the test if(strategiesParams == NULL) { return INIT_FAILED; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Save the resulting combined EA in the SimpleVolumesExpert.mq5 file of the current folder.
We can get the IDs of the best passes of the second stage, for example, using the following SQL query:
SELECT p.id_pass, j.symbol, j.period, p.custom_ontester, p.profit, p.profit_factor, p.sharpe_ratio, p.equity_dd, p.params FROM ( SELECT p0.*, ROW_NUMBER() OVER (PARTITION BY id_task ORDER BY custom_ontester DESC) AS rn FROM passes p0 ) AS p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage WHERE rn = 1 AND s.name = 'Second';
In this query, we again combine our tables from the main database so that we can select those passes that belong to the stage named "Second". We also combine the passes table with its copy, which is divided into sections with the same task ID. Inside each section, the rows are numbered and sorted in descending order of our optimization criterion value (custom_ontester). The row index in the sections falls within the rn column. In the end result, we leave only the first rows from each section - the ones with the highest optimization criterion value.

Fig. 3. The list of pass IDs for the best results in each job of the second stage
Let's substitute the IDs from the first column id_pass to the passes_ input of the combined EA. Run the test and get the following results:
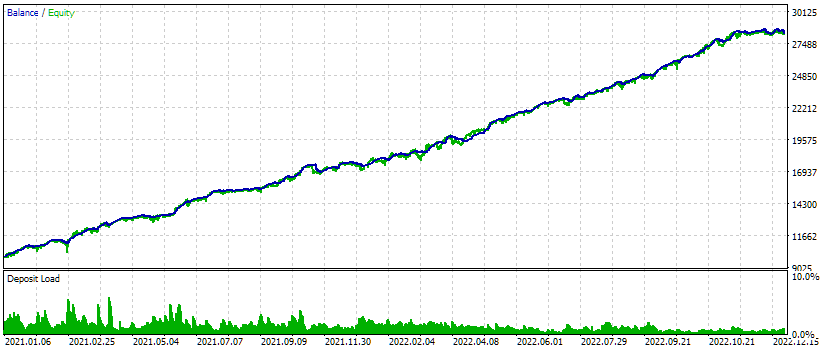

Fig. 4. Test results of the combined EA for three symbols and three timeframes
On this test interval, the equity graph looks quite good: the growth rate remains approximately the same throughout the entire interval, the drawdown is within the acceptable expected limits. But I am more interested in the fact that we can now almost automatically generate an EA initialization string that combines several of the best groups of single instances of trading strategies for different symbols and timeframes.
Conclusion
So, the second stage of our planned optimization procedure is also implemented in the form of a draft. For further convenience, it would be good to create a separate web interface for creating and managing projects to optimize trading strategies. Before we start implementing various quality-of-life improvements, it would be reasonable to go through the entire planned path without being distracted by things we can do without for now. Moreover, while developing implementation options, we are often forced to make some adjustments to the original plan due to new circumstances that emerge as we move forward.
We have now only performed the first and second stage optimization over a relatively short time interval. It would be desirable, of course, to extend the test interval and optimize everything again. We also have not tried to connect clustering at the second stage, which we tried in the sixth part of the series achieving acceleration of the optimization process. But this would require much more development effort, since we would have to develop a mechanism for automatically performing actions that are difficult to implement in MQL5, but are very easy to add in Python or R.
It is hard to decide which way we should take the next step. So let's take a little break, so that things that are unclear today will become clear tomorrow.
Thank you for your attention! See you soon!
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/14892
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.
 Client in Connexus (Part 7): Adding the Client Layer
Client in Connexus (Part 7): Adding the Client Layer
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Hello.
Before Part 16, you had to do exactly that: download files from articles one by one and update those that have been modified. Starting with Part 16, each article is accompanied by a complete archive of the project folder.
Hello.
Before Part 16, you had to do exactly that: download files from articles one by one and update those that have been modified. Starting with Part 16, each article is accompanied by a complete archive of the project folder.
Thank you for this answer/ I am going to get started right away
Hi Again,
I am having two problems.
Using Part 13 code, when I tried to compile Optimizer, I received an unidentified identifier for DB::Open() which was in 1.00 and not in 1.03 of database.
Copying the code from 1.00 into 1.03 cleared that error but produced an unidentified identified for Id() which is clearly in the database object.
The other error is the Articles tab in my Terminal lists Part 13 of your articles as the last English version. If I follow your link, I find that in addition to Article 16, you have published Part20.
Both of these articles are in Cyrillic and when I try to translate them into English, a totally different page is presented in English. This also occurred during the download of Multitester.
Do you have any suggestions to assist me in following your excellent thread?
Hello.
Articles are initially written in Russian, and translated into English and other languages later with a lag of about three to four months. So you can just wait until Part 16 is published in English. Replacing "ru" with "en" in the article address does not include automatic translation, but leads to the English version of the article created by translators. If the translation is not already done by MetaQuotes, you will get an error that such a page does not exist.
With questions about the errors you get during compilation, I'm afraid it will be difficult for me to help you. I can attach here an archive of the project folder from the repository of the version that was the latest at the moment of publishing Part 13. But there, unlike the code in the translated articles, all comments in the files will not be in English.
Hello.
Articles are initially written in Russian, and translated into English and other languages later with a lag of about three to four months. So you can just wait until Part 16 is published in English. Replacing "ru" with "en" in the article address does not include automatic translation, but leads to the English version of the article created by translators. If the translation is not already done by MetaQuotes, you will get an error that such a page does not exist.
With questions about the errors you get during compilation, I'm afraid it will be difficult for me to help you. I can attach here an archive of the project folder from the repository of the version that was the latest at the moment of publishing Part 13. But there, unlike the code in the translated articles, all comments in the files will not be in English.
Thanks so much for the clarification of the lag. I think I am going to Part 16 and download the system and then try again again. I know I run a risk of changes incorporated between 13 & 16 but I am hopeful I can resolve any conflicts. I'll keep you posted.