
Desarrollamos un asesor experto multidivisa (Parte 13): Automatización de la segunda fase: selección en grupos
Introducción
Tras divagar un poco sobre el gestor de riesgos en el último artículo, hoy devolveremos el foco principal al desarrollo, concretamente, a la automatización de las pruebas. En uno de los artículos anteriores esbozamos varias etapas que deben superarse en el proceso de optimización y búsqueda de los mejores parámetros del EA final. La primera fase, en la que optimizamos los parámetros de una única instancia de estrategia comercial, ya la hemos implementado. Sus resultados se almacenan en una base de datos.
La siguiente etapa consistirá en la selección de buenos grupos de instancias únicas de estrategias comerciales, que al trabajar juntas mejorarán los parámetros comerciales, disminuyendo la reducción, aumentando la linealidad del crecimiento de la curva de balance, etc. En la parte 6 de esta serie de artículos, ya vimos cómo implementar esta etapa manualmente. En primer lugar, seleccionábamos de entre los resultados de la optimización de parámetros de instancias únicas de estrategias comerciales aquellos que eran dignos de mención. Esto podía hacerse usando varios criterios, pero en aquel momento nos limitábamos a eliminar simplemente los resultados con rendimientos negativos. A continuación, probábamos diferentes combinaciones de ocho estrategias comerciales, las combinábamos en un asesor experto y las ejecutábamos en el simulador para evaluar los parámetros de su trabajo conjunto.
A partir de la selección manual, se implementaba la selección automática de combinaciones de parámetros de entrada de instancias únicas de estrategias comerciales, que se seleccionaban de una lista de parámetros almacenados en un archivo CSV. Resultó que incluso en el caso más sencillo, cuando solo ejecutábamos la optimización genética eligiendo ocho combinaciones, se obtenía el resultado deseado.
Ahora vamos a modificar el asesor experto que estaba optimizando la selección de grupos para que pueda utilizar los resultados de la primera etapa de la base de datos. También deberá almacenar sus resultados en una base de datos. Asimismo, veremos cómo crear trabajos para las optimizaciones de la segunda fase añadiendo los registros necesarios a nuestra base de datos.
Transferencia de datos a los agentes de pruebas
Para el anterior experto de selección de grupos buenos, tuvimos que trabajar un poco para asegurarnos de que podíamos realizar optimizaciones utilizando agentes de pruebas remotos. El problema era que el EA optimizado tenía que leer datos de un archivo CSV. Cuando se optimizaba solo en la computadora local, esto no causaba ningún problema: bastaba con colocar el archivo de datos en la carpeta común del terminal, y todos los agentes de prueba locales podían acceder a él.
Pero los agentes de prueba remotos no tienen acceso a ese archivo de datos. Así que usábamos la directiva #property tester_file, que permite transmitir cualquier archivo especificado a todos los agentes de prueba en su carpeta de datos. Cuando se iniciaba la optimización, el archivo de datos se copiaba de la carpeta compartida a la carpeta de datos del agente local que ejecutaba el proceso de optimización. Luego el archivo de datos de la carpeta de datos del agente local se distribuía automáticamente a las carpetas de datos de todos los demás agentes de prueba.
Como ahora disponemos de datos sobre los resultados de la prueba de instancias individuales de estrategias comerciales en una base de datos SQLite, el primer impulso fue hacer lo mismo. Dado que la base de datos SQLite es un único archivo en soporte, puede replicarse de forma similar a los agentes de prueba remotos utilizando la directiva anterior. Pero aquí hay un pequeño matiz: el tamaño del archivo CSV transferido era de unos 2 Mb, mientras que el tamaño del archivo de la base de datos ya supera los 300 Mb.
Esta diferencia se debe a que, en primer lugar, intentamos almacenar en la base de datos toda la información estadística posible sobre cada pasada, mientras que el archivo CSV solo almacenaba unos pocos parámetros estadísticos y los datos sobre los valores de los parámetros de entrada de las instancias de estrategias. Y en segundo lugar, en la base de datos ya hemos recopilado información sobre los resultados de la optimización de estrategias en tres símbolos diferentes y tres marcos temporales distintos para cada símbolo. Es decir, el número de pasadas se ha multiplicado por nueve aproximadamente.
Considerando que cada agente de pruebas obtiene su propia copia del archivo transferido, necesitaremos colocar más de 9 GB de datos en un servidor de 32 núcleos para ejecutar pruebas en él. Si procesamos aún más símbolos y marcos temporales en la primera etapa, el tamaño del archivo de la base de datos aumentará varias veces. Y esto puede agotar el espacio disponible en los discos de los servidores de los agentes, por no hablar de la necesidad de transferir grandes cantidades de datos a través de la red.
Sin embargo, la mayor parte de la información almacenada sobre los resultados de las pasadas realizadas por el simulador o bien no la necesitaremos en absoluto en la segunda fase, o bien no la necesitaremos toda a la vez. Es decir, de todo el conjunto de valores almacenados para una pasada necesitaremos extraer solo la cadena de inicialización del EA utilizada en esta pasada. También tenemos previsto recopilar no un grupo de instancias únicas de estrategias comerciales, sino varias: una para cada combinación de símbolo y marco temporal. Esto significa que al buscar, por ejemplo, un grupo EURGBP H1, no necesitaremos datos sobre las pasadas en símbolos distintos de EURGBP y marcos temporales distintos de H1.
Por lo tanto, haremos lo siguiente: al principio de cada optimización, crearemos una nueva base de datos con un nombre predefinido y la rellenaremos con la información mínima necesaria para la tarea de optimización en cuestión. La base de datos ya disponibles la llamaremos base de datos principal, mientras que la base de datos creada la conoceremos por base de datos de la tarea de optimización o simplemente base de datos de la tarea.
El archivo con esta base de datos se transmitirá a los agentes de prueba, ya que especificaremos su nombre en la directiva #property tester_file. El asesor experto optimizado, cuando se ejecute en el agente de prueba, funcionará con este extracto de la base de datos principal. Y cuando se ejecute en una computadora local en el modo de recopilación de frames de datos, el asesor experto optimizado seguirá guardando los datos recibidos de los agentes de prueba en la base de datos principal.
La aplicación de este esquema de trabajo requerirá, en primer lugar, la modificación de la clase CDatabase.
Modificación de CDatabase
Cuando desarrollamos esta clase, desafortunadamente, no previmos que necesitaríamos trabajar con múltiples bases de datos desde el código de un EA. Parecía que, por el contrario, deberíamos asegurarnos de trabajar con una sola base de datos, para no confundirnos sobre dónde guardamos qué. Pero la realidad introduce sus propios ajustes y tenemos que cambiar nuestro enfoque.
Para minimizar las modificaciones por ahora, hemos decidido mantener estática la clase CDatabase. Es decir, no crearemos objetos de esta clase, sino que usaremos sus métodos públicos simplemente como un conjunto de funciones en un espacio de nombres determinado. Al mismo tiempo, seguiremos teniendo la posibilidad de usar propiedades y métodos privados en esta clase.
Para permitir la conexión a diferentes bases de datos, modificaremos el método de apertura Open() renombrándolo a Connect(). La razón de este cambio de nombre es que primero hemos añadido un nuevo método Connect(), y luego ha resultado que en realidad hace el mismo trabajo que el método Open(). Por lo tanto, hemos decidido no utilizar este último método.
La principal diferencia entre el nuevo método y su predecesor es la posibilidad de transmitir el nombre de la base de datos como parámetro. El método Open() siempre abría solo la base de datos con el nombre especificado en la propiedad s_fileName, que era una constante. El nuevo método también mantiene este comportamiento a menos que se le transmita el nombre de la base de datos. Si transmitimos un nombre no vacío al método Connect(), no solo abrirá la base de datos con el nombre transmitido, sino que también lo recordará en la propiedad s_fileName. Por lo tanto, si volvemos a llamar a Connect() sin especificar un nombre, se abrirá la última base de datos abierta.
Además de transmitir el nombre del archivo al método Connect(), también transmitiremos la bandera para usar la carpeta compartida. Esto es necesario porque resulta más cómodo almacenar nuestra base de datos principal en la carpeta de datos comunes del terminal, y la base de datos de tareas en la carpeta de datos del agente de prueba. Por lo tanto, en un caso necesitaremos especificar la bandera DATABASE_OPEN_COMMON en la función de apertura de la base de datos, y en el otro caso no. Para almacenar esta bandera, añadiremos una nueva propiedad estática de la clase s_common. Por defecto, asumiremos que queremos abrir el archivo de base de datos desde una carpeta compartida. El nombre de la base principal lo seguiremos estableciendo como el valor inicial de la propiedad estática s_fileName.
Entonces la descripción de la clase será algo así:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name static int s_common; // Flag for using shared data folder public: static int Id(); // Database connection handle static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB // Connect to the database with a given name and location static bool Connect(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON ); static void Close(); // Closing DB ... }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database892.sqlite"; int CDatabase::s_common = DATABASE_OPEN_COMMON;
En el propio método Connect(), comprobaremos primero si hay alguna base de datos abierta en ese momento. De ser así, la cerraremos. A continuación comprobaremos si se ha establecido el nuevo nombre de archivo de la base de datos. En caso afirmativo, estableceremos el nuevo nombre y la bandera para hacer referencia a la carpeta compartida. Luego seguiremos los pasos necesarios para abrir la base de datos, creando un archivo de base de datos vacío si fuera necesario.
En este punto, hemos eliminado el rellenado forzoso de la base de datos recién creada con tablas y datos usando la llamada al método Create(), como se hacía antes. Como ya estamos trabajando principalmente con una base de datos existente, resultará más cómodo hacerlo de esta manera. Si aún así necesita volver a crear y rellenar la base de datos con la información inicial, podrá usar el script auxiliar CleanDatabase.
//+------------------------------------------------------------------+ //| Check connection to the database with the given name | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, int p_common) { // If the database is open, close it if(IsOpen()) { Close(); } // If a file name is specified, save it together with the shared folder flag if(p_fileName != NULL) { s_fileName = p_fileName; s_common = p_common; } // Open the database // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } } return true; }
Luego guardaremos los cambios realizados en el archivo Database.mqh en la carpeta actual.
Asesor experto de la primera etapa
Para este artículo, no utilizaremos al asesor de la primera etapa, pero por coherencia, también le haremos pequeñas modificaciones. En primer lugar, eliminaremos los parámetros de entrada del gestor de riesgos añadidos como parte del artículo de la semana pasada. No los necesitaremos en este asesor experto, ya que definitivamente no seleccionaremos los parámetros del gestor de riesgos en la primera etapa. Los añadiremos al EA de algunas de las próximas etapas de optimización. El propio objeto de gestor de riesgos lo crearemos inmediatamente a partir de la cadena de inicialización en estado inactivo.
Además, en la primera fase de optimización, no necesitaremos variar los parámetros de entrada como el número mágico, el balance fijo para negociar y el factor de escala. Así que les quitaremos la palabra input en la declaración. Obtendremos el siguiente código:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int idTask_ = 0; input group "=== Opening signal parameters" input int signalPeriod_ = 130; // Number of candles for volume averaging input double signalDeviation_ = 0.9; // Relative deviation from the average to open the first order input double signaAddlDeviation_ = 1.4; // Relative deviation from the average for opening the second and subsequent orders input group "=== Pending order parameters" input int openDistance_ = 231; // Distance from price to pending order input double stopLevel_ = 3750; // Stop Loss (in points) input double takeLevel_ = 50; // Take Profit (in points) input int ordersExpiration_ = 600; // Pending order expiration time (in minutes) input group "=== Money management parameters" input int maxCountOfOrders_ = 3; // Maximum number of simultaneously open orders ulong magic_ = 27181; // Magic double fixedBalance_ = 10000; double scale_ = 1; datetime fromDate = TimeCurrent(); CAdvisor *expert; // Pointer to the EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CMoney::FixedBalance(fixedBalance_); CMoney::DepoPart(1.0); // Prepare the initialization string for a single strategy instance string strategyParams = StringFormat( "class CSimpleVolumesStrategy(\"%s\",%d,%d,%.2f,%.2f,%d,%.2f,%.2f,%d,%d)", Symbol(), Period(), signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_ ); // Prepare the initialization string for a group with one strategy instance string groupParams = StringFormat( "class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " )", strategyParams, scale_ ); // Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )", 0,0,0,0,0,0 ); // Prepare the initialization string for an EA with a group of a single strategy and the risk manager string expertParams = StringFormat( "class CVirtualAdvisor(\n" " %s,\n" " %s,\n" " %d,%s,%d\n" ")", groupParams, riskManagerParams, magic_, "SimpleVolumesSingle", true ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
El código obtenido lo guardaremos en un archivo con el nuevo nombre SimpleVolumesStage1.mq5 en la carpeta actual.
Asesor experto de la segunda etapa
Es hora de abordar el asesor experto principal de este artículo, el EA de optimización de la segunda etapa. Como ya hemos mencionado, se ocupará de optimizar la selección de un grupo de estrategias comerciales de instancia única obtenidas en la primera etapa. Tomemos como base el asesor experto OptGroupExpert.mq5 de la sexta parte y le haremos los cambios necesarios.
En primer lugar, estableceremos el nombre de la base de datos de la tarea de prueba en la directiva #property tester_file. La elección de un nombre específico no es esencial, ya que solo se utilizará para iniciar la optimización y solo dentro de este EA.
#define PARAMS_FILE "database892.stage2.sqlite" #property tester_file PARAMS_FILE
En lugar del nombre del archivo CSV que especificamos en los parámetros de entrada, ahora especificaremos el nombre de nuestra base de datos principal:
input group "::: Selection for the group" sinput string fileName_ = "database892.sqlite"; // - File with the main database
Como queremos seleccionar grupos de instancias únicas de estrategias comerciales que trabajen con el mismo símbolo y marco temporal, y que, a su vez, se definan en la base de datos principal en la tabla de trabajos (jobs), añadiremos a los parámetros de entrada la posibilidad de especificar el identificador del trabajo cuyas tareas han formado un conjunto de instancias únicas de estrategias comerciales que se seleccionarán en el grupo actual:
input int idParentJob_ = 1; // - Parent job ID
Antes usábamos una selección de grupo de ocho instancias, pero ahora aumentaremos el número a dieciséis. Para ello, añadiremos ocho parámetros de entrada más para los índices adicionales de instancias de estrategias y aumentaremos el valor por defecto del parámetro count_:
input int count_ = 16; // - Number of strategies in the group (1 .. 16) input int i1_ = 1; // - Strategy index #1 input int i2_ = 2; // - Strategy index #2 input int i3_ = 3; // - Strategy index #3 input int i4_ = 4; // - Strategy index #4 input int i5_ = 5; // - Strategy index #5 input int i6_ = 6; // - Strategy index #6 input int i7_ = 7; // - Strategy index #7 input int i8_ = 8; // - Strategy index #8 input int i9_ = 9; // - Strategy index #9 input int i10_ = 10; // - Strategy index #10 input int i12_ = 11; // - Strategy index #11 input int i11_ = 12; // - Strategy index #12 input int i13_ = 13; // - Strategy index #13 input int i14_ = 14; // - Strategy index #14 input int i15_ = 15; // - Strategy index #15 input int i16_ = 16; // - Strategy index #16
Luego crearemos una función independiente que se encargará de crear la base de datos de la tarea de optimización actual. En ella, nos conectaremos a la base de datos de tareas, creándola en el caso de que no exista, en la carpeta de datos del terminal llamando al método DB::Connect(). Añadiremos solo una tabla con dos campos a esta base:
- id_pass — identificador de la pasada del simulador en la primera etapa
- params — cadena de inicialización del asesor experto para esta pasada del simulador en la primera etapa
Si la tabla ya se ha añadido anteriormente (es decir, no se trata de la primera ejecución de la optimización de la segunda etapa), la eliminaremos y la volveremos a crear, ya que necesitaremos otras pasadas de la primera etapa para la nueva optimización.
A continuación nos conectaremos a la base de datos principal y recuperaremos los datos de esas pasadas de simulador de las que vamos a seleccionar el grupo. El nombre de archivo de la base de datos básica se transmitirá a esta función como parámetro fileName. La consulta para recuperar los datos requeridos unirá las tablas passes, tasks, jobs y stages y retornará filas que cumplirán las siguientes condiciones:
- el nombre de la etapa para la pasada será igual a "First". Así nombramos la primera etapa, y con este nombre podremos filtrar solo las pasadas pertenecientes a la primera etapa;
- el identificador de trabajo será igual al identificador transmitido en el parámetro idParentJob de la función;
- el valor del beneficio normalizado de la pasada será superior a 2500;
- el número de transacciones será superior a 20;
- el ratio de Sharpe será superior a 2.
Las tres últimas condiciones no son obligatorias. Sus parámetros se han ajustado a los resultados de pasadas específicas de la primera etapa para que, por un lado, tengamos bastantes pasadas en los resultados de la consulta y, por otro, estas pasadas sean de buena calidad.
Durante la extracción de los resultados de la consulta, crearemos directamente un array de consultas SQL para insertar datos en la base de datos de tareas. Cuando se recuperan todos los resultados, pasaremos de la base de datos principal a la base de datos de tareas y ejecutaremos todas las consultas de inserción de datos generadas en una única transacción. Después, regresaremos a la base de datos principal.
//+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Request to obtain the required information from the main database string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE (s.name='First' AND " " j.id_job = %d AND" " p.custom_ontester > 2500 AND " " trades > 20 AND " " p.sharpe_ratio > 2)" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC;", idParentJob); // Execute the request int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return; } // Structure for query results struct Row { string params; } row; // Array for requests to insert data into a new database string queries[]; // Fill the request array: we will only save the initialization strings while(DatabaseReadBind(request, row)) { APPEND(queries, StringFormat("INSERT INTO passes VALUES(NULL, '%s');", row.params)); } // Reconnect to the new database and fill it DB::Connect(PARAMS_FILE, 0); DB::ExecuteTransaction(queries); // Reconnect to the main database DB::Connect(fileName); DB::Close(); }
Esta función se llamará en dos lugares. Su principal lugar de llamada se encuentra en el manejador OnTesterInit(), que se iniciará antes de comenzar la optimización en un gráfico de terminal independiente. Su tarea consistirá en crear y rellenar la base de datos del problema de optimización, comprobar la existencia de conjuntos de parámetros de instancias de estrategias comerciales únicas en la base de datos de la tarea creada y establecer los rangos correctos de los índices de instancia única que deben enumerarse:
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Create a database for a separate stage task CreateTaskDB(fileName_, idParentJob_); // Get the number of strategy parameter sets int totalParams = GetParamsTotal(); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 1; i <= 16; i++) { if(i <= count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 1, 1, totalParams); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 1, 1, totalParams); } } return CVirtualAdvisor::TesterInit(idTask_); }
Asignaremos la tarea de obtención del número de conjuntos de parámetros de instancias únicas de estrategias comerciales a la función independiente GetParamsTotal(). Su tarea es muy sencilla: conectarse a la base de datos de tareas, ejecutar una única consulta SQL para obtener la cantidad requerida y retornar su resultado:
//+------------------------------------------------------------------+ //| Number of strategy parameter sets in the task database | //+------------------------------------------------------------------+ int GetParamsTotal() { int paramsTotal = 0; // If the task database is open, if(DB::Connect(PARAMS_FILE, 0)) { // Create a request to get the number of passes for this task string query = "SELECT COUNT(*) FROM passes p"; int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query result struct Row { int total; } row; // Get the query result from the first string if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } return paramsTotal; }
A continuación, reescribiremos la función de carga de conjuntos de parámetros de instancias individuales de estrategias comerciales LoadParams(). A diferencia de la implementación anterior, en la que leíamos el archivo completo, creábamos un array con todos los conjuntos de parámetros y luego seleccionábamos algunos de los necesarios de este array, ahora haremos las cosas de forma diferente. Luego transmitiremos a esta función la lista de índices requeridos de los conjuntos y formaremos una consulta SQL que extraerá solo los conjuntos con estos índices de la base de datos de tareas. Después concatenaremos los conjuntos de parámetros (como cadenas de inicialización) obtenidos de la base de datos en una única cadena de inicialización, que será devuelta por esta función:
//+------------------------------------------------------------------+ //| Loading strategy parameter sets | //+------------------------------------------------------------------+ string LoadParams(int &indexes[]) { string params = NULL; // Get the number of sets int totalParams = GetParamsTotal(); // If they exist, then if(totalParams > 0) { if(DB::Connect(PARAMS_FILE, 0)) { // Form a string from the indices of the comma-separated sets taken from the EA inputs // for further substitution into the SQL query string strIndexes = ""; FOREACH(indexes, strIndexes += IntegerToString(indexes[i]) + ","); strIndexes += "0"; // Add a non-existent index so as not to remove the last comma // Form a request to obtain sets of parameters with the required indices string query = StringFormat("SELECT params FROM passes p WHERE id_pass IN(%s)", strIndexes); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Data structure for query results struct Row { string params; } row; // Read the query results and join them with a comma while(DatabaseReadBind(request, row)) { params += row.params + ","; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } } return params; }
Por último, será el turno de la función de inicialización del EA. Además de establecer los parámetros de gestión de capital, al principio montaremos un array con el número correcto de índices de conjuntos de parámetros de instancias de estrategias comerciales individuales. El número requerido se especificará en el parámetro de entrada count_, mientras que los propios índices se especificarán en los parámetros de entrada con nombres como i{N}_, donde {N} tomará valores de 1 a 16.
A continuación, comprobaremos si hay duplicados en el array de índices resultante colocando todos los índices en un contenedor de tipo conjunto (CHashSet) y comprobando que el conjunto contenga el mismo número de índices que el array. Si es así, todos los índices serán únicos. Si hay menos índices en el conjunto que los que había en el array, informaremos de que los parámetros de entrada son incorrectos y no ejecutaremos esta pasada.
Si todo está bien con los índices, comprobaremos el modo en el que se está ejecutando actualmente el asesor experto. Si se trata de una pasada como parte del procedimiento de optimización, entonces la base de datos de tareas se ha creado definitivamente antes de que comenzara la optimización y ahora está disponible. Si se trata de una sola pasada regular del simulador, no podremos garantizar la existencia de la base de datos de tareas, por lo que simplemente la recrearemos llamando a la función CreateTaskDB().
Después, cargaremos los conjuntos de parámetros con los índices requeridos desde la base de datos de tareas como una única cadena de inicialización (o más bien, una parte suya, que sustituiremos en la cadena de inicialización final del objeto de asesor experto). Todo lo que nos quedará es formar la cadena de inicialización final y crear un objeto asesor experto a partir de ella.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Array of all indices from the EA inputs int indexes_[] = {i1_, i2_, i3_, i4_, i5_, i6_, i7_, i8_, i9_, i10_, i11_, i12_, i13_, i14_, i15_, i16_ }; // Array for indices to be involved in optimization int indexes[]; ArrayResize(indexes, count_); // Copy the indices from the inputs into it FORI(count_, indexes[i] = indexes_[i]); // Multiplicity for parameter set indices CHashSet<int> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 16 // number of instances not in the range 1 .. 16 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // If this is not an optimization, then you need to recreate the task database if(!MQLInfoInteger(MQL_OPTIMIZATION)) { CreateTaskDB(fileName_, idParentJob_); } // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // If nothing is loaded, report an error if(strategiesParams == NULL) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", "database892.sqlite"); return(INIT_PARAMETERS_INCORRECT); } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Luego guardaremos los cambios realizados en un archivo llamado SimpleVolumesStage2.mq5 en la carpeta actual. El asesor experto que se optimizará en la segunda fase ya está listo. Ahora empezaremos a crear las tareas para la segunda fase de optimización en la base de datos principal.
Creación de tareas de la segunda etapa
En primer lugar, crearemos la segunda etapa de optimización propiamente dicha. Para ello, añadiremos una nueva fila a la tabla stages de la base de datos principal y rellenaremos sus valores de esta manera:

Fig. 1. Fila de la tabla stages con la segunda etapa.
Por ahora, de aquí necesitaremos el valor id_stage para la segunda etapa, que será 2, y el valor name para la segunda etapa, que hemos establecido igual a "Second". Para crear los trabajos (jobs) de la segunda etapa, deberemos tomar todos los trabajos de la primera etapa y para cada uno de ellos crear el trabajo correspondiente de la segunda etapa con el mismo símbolo y marco temporal. Luego formaremos el valor del campo tester_inputs como una cadena que establecerá el valor de identificador del trabajo correspondiente de la primera etapa en el parámetro de entrada del asesor idParentJob_.
Para ello, ejecutaremos una consulta SQL de este tipo en la base de datos principal:
INSERT INTO jobs SELECT NULL, 2 AS id_stage, j.symbol, j.period, 'idParentJob_=' || j.id_job || '||0||1||10||N' AS tester_inputs, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='First';
Solo tendremos que ejecutarla una vez, y el trabajo de la segunda fase se creará para todo el trabajo existente de la primera fase:
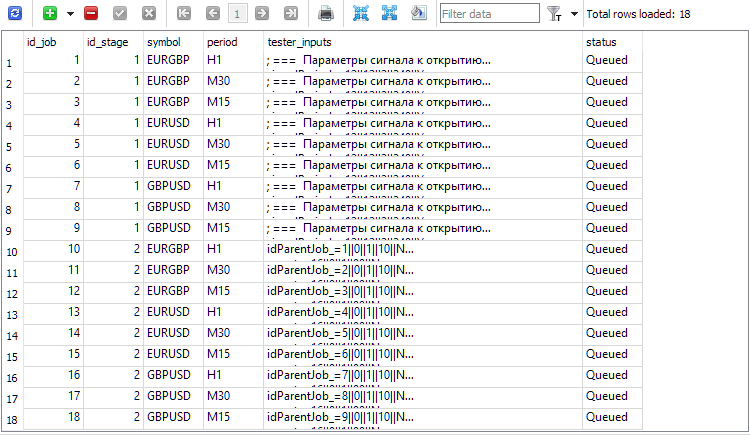
Fig. 2. Registros añadidos para los trabajos de la segunda etapa (id_job = 10 . 18)
Otra cosa que deberemos considerar. El lector atento habrá observado que tanto la primera etapa como las tareas de la primera etapa tienen el estado "Queued" en la base de datos principal, aunque hayamos dicho que ya hemos completado la primera etapa de optimización. ¿No existe aquí una contradicción? Por desgracia, así es. De momento. La cuestión es que aún no nos hemos ocupado de actualizar los estados de los trabajos cuando finalizan todas las tareas de optimización incluidas en estos, ni los estados de las etapas cuando finalizan todos los trabajos incluidos en las etapas. Hay dos formas de hacerlo:
- añadiendo código adicional a nuestro EA optimizador para que, cuando se complete cada tarea de optimización, se compruebe si es necesario actualizar el estado no solo de las tareas, sino también de las actividades y las etapas;
- añadiendo un trigger a la base de datos que rastree el evento de cambio de tarea. Cuando se produce este evento, el trigger tendrá que comprobar si los estados de las actividades y las etapas necesitan ser actualizados y ocuparse de actualizarlos.
Queda por crear tareas para cada trabajo, y ya podremos comenzar la segunda etapa. A diferencia de la primera etapa, en la segunda no usaremos múltiples tareas con diferentes criterios de optimización dentro del mismo trabajo. Utilizaremos un único criterio, nuestro criterio del beneficio medio anual normalizado. Para fijar este criterio, tendremos que seleccionar el índice 6 en el campo de criterio de optimización.
Podemos crear las tareas de segunda etapa para todos los trabajos con el criterio de optimización 6 utilizando esta consulta SQL:
INSERT INTO tasks SELECT NULL, j.id_job AS id_job, 6 AS optimization, NULL AS start_date, NULL AS finish_date, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='Second';
La ejecutaremos una vez y obtendremos nuevas entradas en la tabla (tasks) que se corresponderán con las tareas realizadas en la segunda etapa. Después de eso, añadiremos el asesor experto Optimisation.ex5 a cualquier gráfico del terminal y nos ocuparemos de otras cosas hasta que el terminal complete todas las tareas de optimización. Los tiempos de ejecución pueden variar mucho en función del propio EA, la duración del intervalo de prueba, el número de símbolos y marcos temporales y, por supuesto, el número de agentes implicados.
Para el EA usado en este proyecto, en un intervalo de 2 años (2021 y 2022), con optimización para tres símbolos y tres marcos temporales con 32 agentes, todas las tareas de optimización de la segunda etapa se han completado en unas 5 horas. Veamos los resultados.
Asesor experto para las pasadas especificadas
Para que nos resulte más fácil, crearemos otro EA, o mejor dicho, realizaremos pequeños cambios en el existente. Así implementaremos en este el parámetro de entrada passes_, en el que especificaremos los identificadores separados por comas de los pasadas del simulador, a saber, los conjuntos de estrategias que nos gustaría combinar en un grupo en este asesor experto.
A continuación, en el método de inicialización del EA solo tendremos que obtener los parámetros (cadenas de inicialización de grupos de estrategias) de estas pasadas de la base de datos principal y sustituirlos en la cadena de inicialización del objeto de asesor experto en este EA:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input string passes_ = "734469,735755,736046,736121,761710,776928,786413,795381"; // - Comma-separated pass IDs ulong magic_ = 27183; // - Magic bool useOnlyNewBars_ = true; // - Work only at bar opening datetime fromDate = TimeCurrent(); CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect()) { // Form a request to receive passes with the specified IDs string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " WHERE id_pass IN (%s);" , passes_); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // If no parameter sets are found, abort the test if(strategiesParams == NULL) { return INIT_FAILED; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Guardaremos el asesor experto combinado resultante en el archivo SimpleVolumesExpert.mq5 en la carpeta actual.
Para obtener los identificadores de las mejores pasadas de la segunda etapa, podremos utilizar, por ejemplo, esta consulta SQL:
SELECT p.id_pass, j.symbol, j.period, p.custom_ontester, p.profit, p.profit_factor, p.sharpe_ratio, p.equity_dd, p.params FROM ( SELECT p0.*, ROW_NUMBER() OVER (PARTITION BY id_task ORDER BY custom_ontester DESC) AS rn FROM passes p0 ) AS p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage WHERE rn = 1 AND s.name = 'Second';
En ella, volveremos a utilizar la combinación de nuestras tablas de la base de datos principal para poder seleccionar aquellas pasadas que pertenecen a la etapa denominada "Second", es decir, a la segunda. También aplicaremos la unión de la tabla passes a su copia, que se dividirá en secciones con el mismo ID de tarea, y dentro de cada sección las filas se clasificarán según el valor descendente de nuestro criterio de optimización (custom_ontester) y se numerarán. El número de fila de las secciones irá en la columna rn. En el resultado final, solo conservaremos las primeras filas de cada partición, es decir, las que tengan el mayor valor del criterio de optimización.

Fig. 3. Lista de identificadores de pasadas para las mejores métricas en cada trabajo de la segunda etapa
Tomaremos los valores de los identificadores de la primera columna id_pass y los sustituiremos en el parámetro de entrada passes_ del EA combinado. Luego realizaremos la prueba y obtendremos los siguientes resultados:
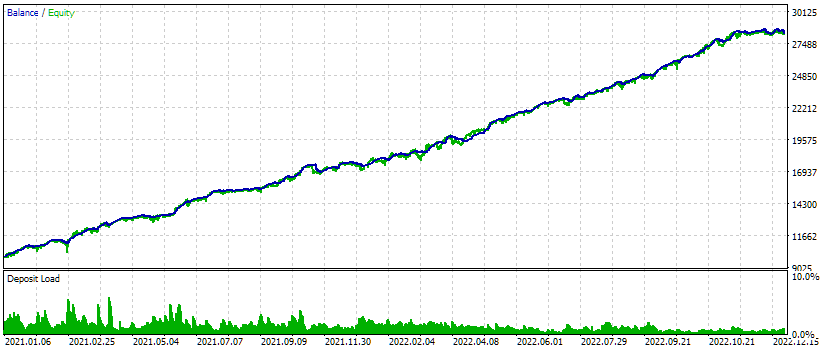

Fig. 4. Resultados de la prueba del asesor experto combinado para tres símbolos y tres marcos temporales.
En este intervalo de prueba, el aspecto del gráfico de crecimiento de los fondos es bastante bueno: la tasa de crecimiento se mantiene aproximadamente igual a lo largo de todo el intervalo, y la reducción se encuentra dentro de la reducción esperada aceptable. Pero eso no es lo que más nos interesa ahora, sino el hecho de que ahora podemos generar casi automáticamente la cadena de inicialización de un EA que combina varios de los mejores grupos de estrategias comerciales de instancia única para diferentes símbolos y marcos temporales.
Conclusión
Así pues, la segunda etapa de nuestro procedimiento de optimización previsto también la hemos aplicado como un borrador temporal. Para mayor comodidad, sería conveniente crear una interfaz web independiente para crear y gestionar proyectos de optimización de estrategias comerciales. Pero antes de embarcarnos en diversos tipos de mejoras relacionadas con la comodidad, sería deseable superar por completo el camino previsto, sin distraernos con cosas de las que podemos prescindir por el momento. Además, durante la elaboración de los borradores a implementar, a menudo tenemos que introducir algunos ajustes en el plan original debido a nuevas circunstancias que surgen sobre la marcha.
Ahora solo hemos realizado la optimización de la primera y la segunda etapa en un intervalo de tiempo relativamente pequeño. Obviamente, resulta aconsejable ampliar el intervalo de prueba y optimizarlo todo de nuevo. Además, aún no hemos probado en la segunda etapa la clusterización que ya probamos en la sexta parte del ciclo de artículos, cuando logramos acelerar el proceso de optimización en comparación con la optimización sin clusterización. No obstante, esto requeriría mucho más esfuerzo de desarrollo, pues tendríamos que desarrollar un mecanismo para la ejecución automática de acciones bastante difícil de implementar en MQL5, pero muy fácil en Python o R.
Resulta complicado decidir en qué dirección dar el siguiente paso. Así que haremos una pequeña pausa, y quizá lo que hoy no estaba claro mañana se vuelva transparente.
¡Gracias por su atención y hasta la próxima!
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14892
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola.
Antes de la Parte 16, tenías que hacer exactamente eso: descargar los archivos de los artículos uno por uno y actualizar los que se hubieran modificado. A partir de la Parte 16, cada artículo va acompañado de un archivo completo de la carpeta del proyecto.
Hola.
Antes de la Parte 16, tenías que hacer exactamente eso: descargar los archivos de los artículos uno por uno y actualizar los que se hubieran modificado. A partir de la Parte 16, cada artículo va acompañado de un archivo completo de la carpeta del proyecto.
Gracias por esta respuesta/ Voy a empezar ahora mismo
Hola de nuevo,
Estoy teniendo dos problemas.
Usando el código de la Parte 13, cuando intenté compilar Optimizer, recibí un identificador no identificado para DB::Open() que estaba en la 1.00 y no en la 1.03 de la base de datos.
Copiando el código de la 1.00 en la 1.03 desapareció ese error pero produjo un identificado no identificado para Id() que está claramente en el objeto de base de datos.
El otro error es que en la pestaña Artículos de mi Terminal aparece la Parte 13 de sus artículos como la última versión en inglés. Si sigo su enlace, encuentro que además del Artículo 16, han publicado la Parte20.
Ambos artículos están en cirílico y cuando intento traducirlos al inglés, se presenta una página totalmente diferente en inglés. Esto también ocurrió durante la descarga de Multitester.
¿Tiene alguna sugerencia para ayudarme a seguir su excelente hilo?
Hola.
Los artículos se escriben inicialmente en ruso, y se traducen al inglés y a otros idiomas más tarde, con un desfase de unos tres o cuatro meses. Así que puede esperar a que se publique la Parte 16 en inglés. La sustitución de "ru" por "en" en la dirección del artículo no incluye la traducción automática, sino que lleva a la versión inglesa del artículo creada por traductores. Si la traducción no está ya hecha por MetaQuotes, obtendrá un error de que tal página no existe.
Con las preguntas sobre los errores que se obtienen durante la compilación, me temo que será difícil para mí ayudarte. Puedo adjuntar aquí un archivo de la carpeta del proyecto del repositorio de la versión que era la última en el momento de publicar la Parte 13. Pero allí, a diferencia del código de los artículos traducidos, todos los comentarios de los archivos no estarán en inglés.
Muchas gracias por la aclaración del retraso. Creo que voy a la Parte 16 y descargar el sistema y luego vuelva a intentarlo de nuevo. Sé que corro el riesgo de los cambios incorporados entre 13 y 16, pero tengo la esperanza de que puedo resolver cualquier conflicto. Te mantendré informado.