Discussão do artigo "Desenvolvendo um EA Multimoeda (Parte 13): Automação da segunda etapa — Seleção de grupos"
Obrigado pelo feedback, vamos seguir em frente.
Alexander, acho que você ainda não descobriu como usar o static. Com sua ajuda, o padrão de design Singleton pode ser facilmente implementado em MQL5 e também em C++. Eu o usei, por exemplo, para a classe CVirtualReceiver na terceira parte. Esse modificador não está de forma alguma relacionado ao gráfico no qual o Expert Advisor será executado. Uma variável ou uma propriedade declarada com esse modificador pode estar relacionada se atribuirmos a ela, por exemplo, o resultado da chamada da função Symbol(). Mas isso não significa que não possamos alterar o valor de tais variáveis posteriormente
Olá, Victor.
Eu uso o SQLiteStudio. Esse programa gratuito expandiu muito sua funcionalidade recentemente, portanto, não encontrei falta de algo necessário nele. No MetaEditor, você pode editar o banco de dados apenas executando consultas SQL. Isso é menos conveniente, é claro.
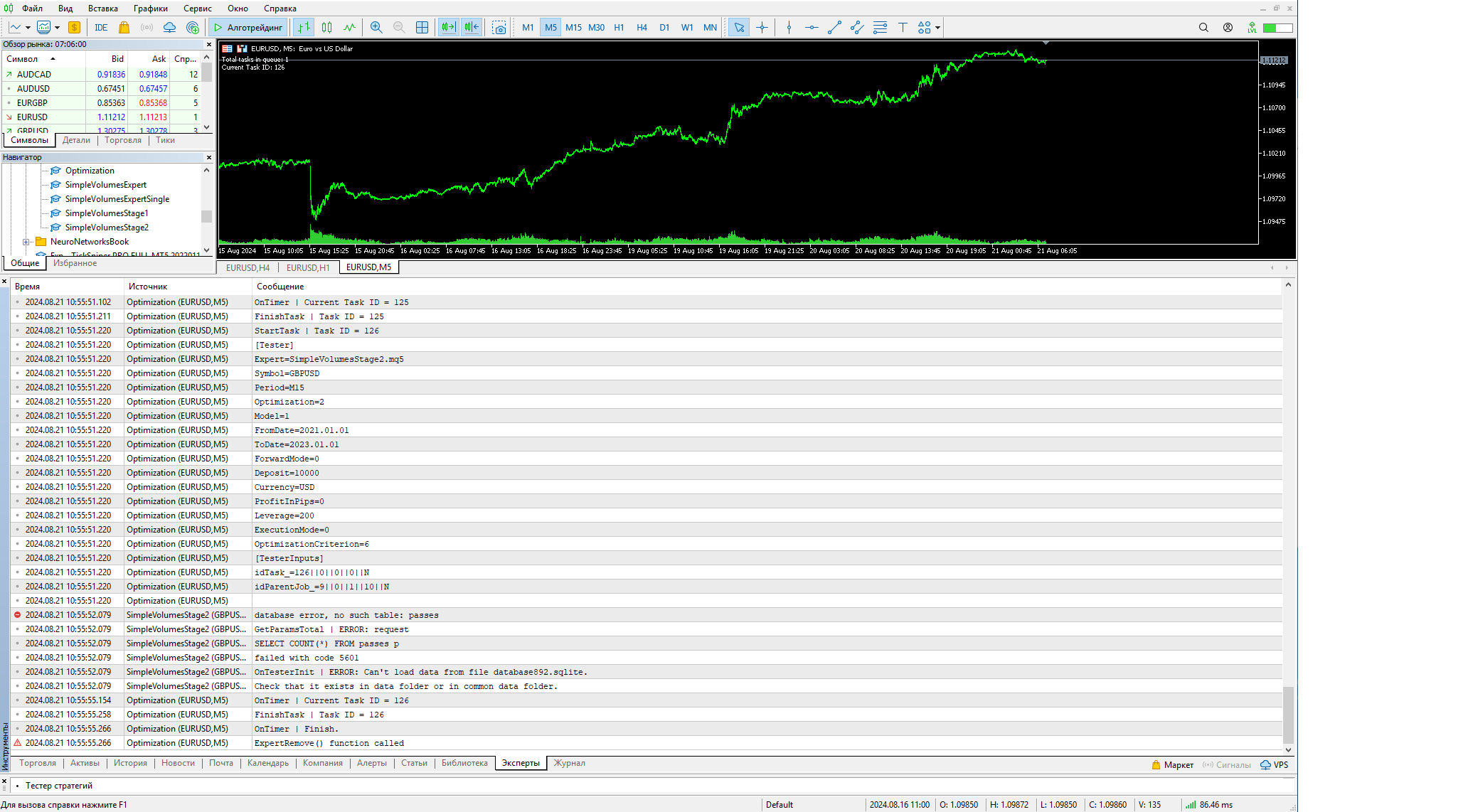
Yuri, obrigado pelo programa, agora posso abrir o banco de dados e editá-lo. E fiz o primeiro estágio dos cálculos, mas o segundo estágio tem um problema: não inicia. Primeiro, executei o primeiro estágio, depois adicionei manualmente uma linha do segundo estágio, como você mostra na captura de tela, e executei duas consultas do seu artigo. As tarefas e os trabalhos apareceram no banco de dados e o Expert Advisor tenta executar o segundo estágio. Mas, por algum motivo, ele não vê os passes do primeiro estágio, embora eles estejam no banco de dados. Talvez eu tenha entendido algo errado (não trabalhei com bases de ninguém).
Aqui estão os erros nas capturas de tela. Como executá-lo?
{kind=link}
{kind=link}
Além disso, pelo que entendi desses parâmetros:
input int count_ = 16; // - Número de estratégias no grupo (1 ... 16) input int i1_ = 1; // - Índice de estratégia nº 1 input int i2_ = 2; // - Índice de estratégia nº 2 input int i3_ = 3; // - Índice de Estratégia #3 input int i4_ = 4; // - Índice de Estratégia #4 input int i5_ = 5; // - Índice de Estratégia #5 input int i6_ = 6; // - Índice de Estratégia #6 input int i7_ = 7; // - Índice de Estratégia #7 input int i8_ = 8; // - Índice de Estratégia #8 input int i9_ = 9; // - Índice de Estratégia #9 input int i10_ = 10; // - Índice de Estratégia #10 input int i12_ = 11; // - Índice de Estratégia #11 input int i11_ = 12; // - Índice de estratégias #12 input int i13_ = 13; // - Índice de Estratégia #13 input int i14_ = 14; // - Índice de Estratégia #14 input int i15_ = 15; // - Índice de estratégias #15 input int i16_ = 16; // - Índice de estratégias #16
devem ser pesquisados em cada tarefa da segunda etapa. Mas em que intervalos eles devem ser pesquisados e em que etapa? E o parâmetro count_ em si, pelo que entendi, não deve ser pesquisado?
Para a segunda etapa, um segundo banco de dados deve ser criado automaticamente e enviado para os agentes de teste. Seu nome é especificado na diretiva
#define PARAMS_FILE "database892.stage2.sqlite"
Ele deve ser diferente do nome do banco de dados principal. Na captura de tela, você é informado de que a tabela de passes não está nesse banco de dados, embora se esperasse que ela estivesse lá. Tente entender o trabalho da função CreateTaskDB(), que cria o segundo banco de dados a partir do inicial.
A etapa e os limites da pesquisa de parâmetros do tipo i{N}_ são definidos automaticamente pelo Expert Advisor Optimisation.mq5 com base nas informações do segundo banco de dados.
O parâmetro count_ não precisa ser pesquisado. Ele pode ser alterado para um valor menor, se quisermos selecionar grupos não de 16, mas de um número menor de instâncias. Por exemplo, de 12 ou de 8. Mas, para mim, ele sempre foi igual a 16.
Yuri, não consigo fazer isso funcionar.... O arquivo do banco de dados comum que tenho está especificado como você no banco de dados do consultor892.sqlite, não o alterei e ele está realmente no disco, e o consultor Optimisation.mq5 se conecta a ele e executa tarefas. No Expert Advisor SimpleVolumesStage2.mq5, ele também é especificado. E o arquivo de banco de dados da tarefa é especificado como database892.stage2.sqlite. Pelo que entendi, são arquivos diferentes. O arquivo de banco de dados comum está localizado na pasta Common\Files.
Tentei inserir verificações na função GetParamsTotal e especificar a variável fileName na função DB::Connect, eis o código:
//+------------------------------------------------------------------+ //| Número de conjuntos de parâmetros de estratégia no banco de dados de tarefas //+------------------------------------------------------------------+ int GetParamsTotal(const string fileName) { int paramsTotal = 0; PrintFormat(__FUNCTION__" 1 "); // Se o banco de dados de tarefas estiver aberto, então if(DB::Connect(fileName, 0)) { PrintFormat(__FUNCTION__" 2 "); // Criar uma consulta para obter o número de passes para essa tarefa string query = "SELECT COUNT(*) FROM passes p"; PrintFormat(__FUNCTION__" 3 "); int request = DatabasePrepare(DB::Id(), query); PrintFormat(__FUNCTION__" 4 "); if(request != INVALID_HANDLE) { // Estrutura de dados para o resultado da consulta PrintFormat(__FUNCTION__" 5 "); struct Row { int total; } row; PrintFormat(__FUNCTION__" 6 "); // Obter o resultado da consulta a partir da primeira linha if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } PrintFormat(__FUNCTION__" 7 "); return paramsTotal; }
Ao ser executado no registro, a saída é a seguinte:
2024.08.21 22:05:27.964 Optimization (EURUSD,M5) idTask_=124||0||0||0||N 2024.08.21 22:05:27.964 Optimization (EURUSD,M5) idParentJob_=7||0||1||10||N 2024.08.21 22:05:27.964 Optimization (EURUSD,M5) 2024.08.21 22:05:29.096 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 1 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 2 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 3 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) database error, no such table: passes 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 4 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal | ERROR: request 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) SELECT COUNT(*) FROM passes p 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) failed with code 5039 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 7 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) OnTesterInit | ERROR: Can't load data from file database892.sqlite. 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) Check that it exists in data folder or in common data folder. 2024.08.21 22:05:32.900 Optimization (EURUSD,M5) OnTimer | Current Task ID = 124 2024.08.21 22:05:33.008 Optimization (EURUSD,M5) FinishTask | Task ID = 124 2024.08.21 22:05:33.022 Optimization (EURUSD,M5) StartTask | Task ID = 125 2024.08.21 22:05:33.022 Optimization (EURUSD,M5) [Tester]
Onde o número do erro ainda pode escrever 5602. Pelo que entendi, ele tropeça na função DatabasePrepare.
A única coisa que mudei foi o nome do arquivo de database.sqlite para database892.sqlite e mudei o nome do orientador do primeiro estágio no banco de dados para o atual nesta parte e, depois de executar o primeiro estágio, adicionei a linha do segundo estágio à tabela de estágios e executei dois conjuntos de comandos do seu artigo. Não alterei mais nada. Há cerca de 388.000 linhas com passes na tabela de passes.
O erro ocorre antes, mas não é relatado, pois tudo está bem do ponto de vista da execução do programa.
Essa mensagem
2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) database error, no such table: passes
diz diretamente que não há tabela de passes no segundo banco de dados e que estamos tentando obter dados dela. É por isso que devemos lidar com a função que deve criá-la - CreateTaskDB().
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Desenvolvendo um EA Multimoeda (Parte 13): Automação da segunda etapa — Seleção de grupos foi publicado:
A primeira etapa do processo automatizado de otimização já foi implementada. Para diferentes símbolos e timeframes, realizamos a otimização com base em vários critérios e armazenamos as informações dos resultados de cada execução em um banco de dados. Agora, vamos nos dedicar à seleção dos melhores grupos de conjuntos de parâmetros encontrados na primeira etapa.
A próxima etapa é a seleção de grupos eficazes de instâncias individuais das estratégias de trading, que, ao trabalharem juntas, possam melhorar os parâmetros de negociação — reduzir a retração, aumentar a linearidade do crescimento do saldo, e assim por diante. Na sexta parte do ciclo de artigos, exploramos essa etapa manualmente. Inicialmente, selecionamos dos resultados da otimização aqueles parâmetros das instâncias individuais das estratégias de trading que mereciam atenção. Esse processo poderia seguir vários critérios, mas limitamo-nos à remoção dos resultados com lucro negativo. Em seguida, experimentamos diversas combinações de oito instâncias de estratégias de trading, agrupando-as em um único EA e executando testes para avaliar os parâmetros de desempenho conjunto.
Após iniciar com a seleção manual, implementamos a seleção automática de combinações de parâmetros de entrada das instâncias individuais das estratégias de trading, que eram retiradas de uma lista armazenada em um arquivo CSV. Constatamos que, mesmo no caso mais simples, ao executar a otimização genética com oito combinações, os resultados desejados eram alcançados.
Agora, vamos modificar o EA que realiza a otimização da seleção de grupos, para que ele possa usar os resultados da primeira etapa do banco de dados. Seus resultados também deverão ser armazenados no banco de dados. Analisaremos, ainda, a criação de tarefas para realizar otimizações da segunda etapa por meio da adição de registros necessários em nosso banco de dados.
Autor: Yuriy Bykov