Integrando modelos de ML ao Testador de estratégias (Parte 3): Gerenciamento de Arquivos CSV(II)

Introdução
Este artigo se concentra na terceira parte da integração do testador de estratégias com Python. Ele apresenta a construção da classe CFileCSV para gerenciamento eficiente de arquivos CSV, incluindo exemplos e códigos para ajudar os leitores a entender como essa classe pode ser implementada na prática.
Bom, mas o que exatamente é um CSV? Alguns podem estar se perguntando.
CSV (Comma Separated Values) é um formato de arquivo simples e amplamente utilizados para armazenamento e troca de dados. Ele consiste em uma tabela onde cada linha representa uma entrada de dados e cada coluna representa um campo dessa entrada. Os valores são separados por um delimitador, o que permite uma fácil leitura e escrita por diversas ferramentas e linguagens de programação.
Esse formato surgiu no início da década de 1970, tendo sido utilizado inicialmente em sistemas mainframe. Não há um idealizador específico para o formato CSV, pois ele é uma convenção simples e amplamente utilizada.
O CSV é muito utilizado para importar e exportar dados em muitos aplicativos, como planilhas eletrônicas, bancos de dados e aplicativos de análise de dados, etc. Ele é uma escolha popular devido à sua facilidade de uso e entendimento, além de ser compatível com muitos sistemas e ferramentas. Ele é especialmente útil quando se precisa compartilhar dados entre aplicativos diferentes, como por exemplo, transferir dados de um sistema para outro.
Os principais benefícios do uso de CSV incluem sua facilidade de uso e compatibilidade com muitas ferramentas. No entanto, ele também possui algumas limitações, como a falta de suporte para tipos de dados complexos e a capacidade limitada de lidar com conjuntos de dados muito grandes. Além disso, a falta de um padrão universal para o formato CSV pode levar a problemas de compatibilidade entre aplicativos diferentes. É importante também mencionar que é possível que os dados possam ser perdidos ou alterados acidentalmente devido a falta de validação dos dados. No geral, o CSV é uma opção flexível e fácil de usar para armazenar e compartilhar dados, mas é importante considerar suas limitações e tomar medidas para garantir a precisão dos dados.
Motivação
A criação da classe CFileCSV surgiu a partir da necessidade de integrar o ambiente do Strategy Tester do Meta Trade 5 com Python. Enquanto estava desenvolvendo minhas estratégias de negociação usando modelos de aprendizado de máquina, eu me deparei com a limitação de utilizar esses modelos criados no Python. Isso porque, ou eu precisaria construir uma biblioteca de aprendizado de máquina em MQL5, o que não era o meu objetivo principal, ou teria que criar um Expert Advisor feito apenas no Python.
Embora a linguagem MQL5 possua recursos para construção de bibliotecas de aprendizado de máquina, eu não queria gastar tempo e esforço desenvolvendo uma biblioteca desse tipo, pois meu objetivo principal era a exploração de dados e construção de modelos de forma ágil e eficiente.
Eu estava buscando algo mais intermediário. Eu queria poder aproveitar as vantagens dos modelos de machine learning criados no Python, mas também queria poder aplicá-los diretamente em minhas negociações em MQL5. Isso me levou a buscar uma maneira de contornar essa limitação e encontrar uma solução para a integração dos dois ambientes.
A ideia era criar um sistema de troca de mensagens, onde o Meta Trader e o Python pudessem se comunicar entre si. Isso permitiria o controle de inicialização, o envio de dados do Meta Trader 5 para o Python e o envio de previsões do Python para o Meta Trader 5. A classe CFileCSV foi idealizada com o objetivo de facilitar essa comunicação, permitindo que os dados sejam armazenados e carregados de forma eficiente.
Introdução à classe CFileCSV
A classe CFileCSV é uma classe de operações com arquivos CSV (Comma Separated Values) que herda de CFile, fornecendo funcionalidades específicas para trabalhar com arquivos CSV. O objetivo desta classe é facilitar a leitura e escrita de arquivos CSV, tornando-o mais fácil de lidar com tipos de dados variados.
Um dos principais benefícios de se usar arquivos CSV é a facilidade de compartilhamento e importação/exportação de dados. Eles podem ser abertos e editados com facilidade em programas como o Excel ou Google Sheets, e também podem ser lidos por muitas linguagens de programação diferentes. Além disso, eles não possuem um formato específico, o que significa que eles podem ser lidos e escritos por diferentes demandas.
A classe CFileCSV possui quatro métodos públicos principais: Open, WriteHeader, WriteLine e Read. também possui dois métodos privados auxiliares, que são usados para transformar matrizes ou arrays em strings e escrever esses valores no arquivo.
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
Ao usar esta classe, é importante lembrar que ela é projetada para trabalhar com arquivos CSV específicos. Se os dados no arquivo não estiverem no formato esperado, os resultados podem ser imprevisíveis. Além disso, é importante garantir que o arquivo esteja aberto antes de tentar escrever nele, e que ele tenha permissão para ser escrito.
Um exemplo de utilização da classe CFileCSV seria a criação de um arquivo CSV a partir de uma matriz de dados. Primeiro, criaríamos uma instância da classe e abriríamos o arquivo com o método Open, especificando o nome do arquivo e as flags de abertura. Em seguida, usaríamos o método WriteHeader para escrever um cabeçalho no arquivo e o método WriteLine para escrever as linhas de dados na matriz. A seguir, uma função que ilustra esses passos:
#include "FileCSV.mqh" void CreateCSVFile(string fileName, string &headers[], string &data[][]) { // Cria um objeto da classe CFileCSV CFileCSV csvFile; // Verifica se o arquivo pode ser aberto para escrita em formato ANSI if(csvFile.Open(fileName, FILE_WRITE|FILE_ANSI)) { int rows = ArrayRange(data, 0); int cols = ArrayRange(data, 1); int headerSize = ArraySize(headers); //Verifica se o número de colunas no array de dados é igual ao número de elementos no array de cabeçalhos e se o número de linhas no array de dados é maior que zero if(cols != headerSize || rows == 0) { Print("Error: Invalid number of columns or rows. Data array must have the same number of columns as the headers array and at least one row."); return; } // Escreve o cabeçalho no arquivo csvFile.WriteHeader(headers); // Escreve as linhas de dados no arquivo csvFile.WriteLine(data); // Fecha o arquivo csvFile.Close(); } else { // Exibe uma mensagem de erro caso o arquivo não possa ser aberto Print("Error opening file!"); } }
Este método tem como objetivo criar um arquivo CSV a partir de um array de cabeçalhos e um array de dados. Ele inicia criando um objeto da classe CFileCSV, em seguida, verifica se o arquivo pode ser aberto para escrita em formato ANSI. Se o arquivo puder ser aberto, ele verifica se o número de colunas no array de dados é igual ao número de elementos no array de cabeçalhos e se o número de linhas no array de dados é maior que zero. Se essas condições forem atendidas, o método escreve o cabeçalho no arquivo usando o método WriteHeader() e em seguida escreve as linhas de dados usando o método WriteLine(). Por fim, o método fecha o arquivo. Caso o arquivo não possa ser aberto, uma mensagem de erro é exibida.
Esse método será mostrado em exemplo em breve, mas é importante notar que sua implementação pode ser estendida para atender outras necessidades. Por exemplo, pode-se adicionar mais validações, como verificar se o arquivo já existe antes de tentar abri-lo, ou adicionar opções para escolher o delimitador a ser usado.
A classe CFileCSV fornece uma maneira fácil e conveniente de lidar com arquivos CSV, tornando a leitura e escrita de dados nesses arquivos mais simples. No entanto, é importante ter cuidado ao usá-lo, garantindo que os arquivos estejam no formato esperado e verificando os retornos dos métodos para garantir que eles tenham sido executados com sucesso.
Implementação
Como dito anteriormente, a classe CFileCSV possui quatro métodos públicos principais: Open, WriteHeader, WriteLine e Read. E existem também dois métodos auxiliares privados, os quais possuem uma sobrecarga de nomes: ToString.
-
O método Open(const string file_name,const int open_flags, const short delimiter=';') é usado para abrir um arquivo CSV. Ele recebe como parâmetros o nome do arquivo, as flags de abertura (como FILE_WRITE ou FILE_READ) e o delimitador a ser usado no arquivo (o padrão é ';'). Ele chama o método Open da classe base CFile e armazena o delimitador especificado em uma variável privada. Ele retorna um inteiro indicando se a operação foi bem-sucedida ou não.
int CFileCSV::Open(const string file_name,const int open_flags, const short delimiter=';') { m_delimiter=delimiter; return(CFile::Open(file_name,open_flags|FILE_CSV|delimiter)); }
- O método WriteHeader(const T &values[]) é usado para escrever um cabeçalho no arquivo CSV aberto. Ele recebe como parâmetro um array de valores que representam os cabeçalhos das colunas no arquivo. Ele usa o método ToString para transformar o array em uma string e escreve essa string no arquivo usando o método FileWrite da classe base CFile. Ele retorna um inteiro indicando o número de bytes escritos no arquivo.
template<typename T> uint CFileCSV::WriteHeader(const T &values[]) { string header=ToString(values); //--- check handle if(m_handle!=INVALID_HANDLE) return(::FileWrite(m_handle,header)); //--- failure return(0); }
-
O método WriteLine(const T &values[][]) é usado para escrever linhas de dados em um arquivo CSV aberto. Ele recebe como parâmetro uma matriz de valores que representam as linhas de dados no arquivo. Ele percorre cada linha da matriz, usando o método ToString para transformar cada linha em uma string e concatenando essas strings em uma única string. Ele escreve essa string no arquivo usando o método FileWrite da classe base CFile. Ele retorna um inteiro indicando o número de bytes escritos no arquivo.
template<typename T> uint CFileCSV::WriteLine(const T &values[][]) { int len=ArrayRange(values, 0); if(len<1) return 0; string lines=""; for(int i=0; i<len; i++) if(i<len-1) lines += ToString(i, values) + "\n"; else lines += ToString(i, values); if(m_handle!=INVALID_HANDLE) return(::FileWrite(m_handle, lines)); return 0; }
-
O método Read(void) é usado para ler o conteúdo de um arquivo CSV aberto. Ele usa o método FileReadString da classe base CFile para ler o conteúdo do arquivo linha por linha e armazená-lo em uma única string. Ele retorna a string contendo o conteúdo do arquivo.
string CFileCSV::Read(void) { string res=""; if(m_handle!=INVALID_HANDLE) res = FileReadString(m_handle); return res;
Os métodosToString são métodos privados auxiliares da classe CFileCSV que são usados para transformar matrizes ou arrays em strings e escrever esses valores no arquivo.
-
O método ToString(const int row, const T &values[][]) é usado para transformar uma matriz em uma string. Ele recebe como parâmetro a linha da matriz que deve ser transformada e a matriz em si. Ele percorre cada elemento da linha da matriz, adicionando-o à string resultante. O delimitador é adicionado ao final de cada elemento, exceto para o último elemento da linha.
template<typename T> string CFileCSV::ToString(const int row, const T &values[][]) { string res=""; int cols=ArrayRange(values, 1); for(int x=0; x<cols; x++) if(x<cols-1) res+=values[row][x] + ShortToString(m_delimiter); else res+=values[row][x]; return res; }
-
O método ToString(const T &values[]) é usado para transformar um array em uma string. Ele percorre cada elemento do array, adicionando-o à string resultante. O delimitador é adicionado ao final de cada elemento, exceto para o último elemento do array.
template<typename T> string CFileCSV::ToString(const T &values[]) { string res=""; int len=ArraySize(values); if(len<1) return res; for(int i=0; i<len; i++) if(i<len-1) res+=values[i] + ShortToString(m_delimiter); else res+=values[i]; return res; }
Esses métodos são utilizados pelos métodos WriteHeader e WriteLine para transformar os valores passados como parâmetro em strings e escrever essas strings no arquivo aberto. Eles são usados para garantir que os valores sejam escritos no arquivo no formato esperado, separados pelo delimitador especificado. Eles são fundamentais para garantir que os dados sejam escritos corretamente e de forma organizada no arquivo CSV.
Além disso, esses métodos permitem que a classe CFileCSV seja flexível e possa lidar com diferentes tipos de dados, pois eles são implementados como templates. Isso significa que esses métodos podem ser usados com qualquer tipo de dado que possa ser convertido em uma string, incluindo números inteiros, ponto flutuante, strings, etc. Isso torna a classe CFileCSV muito versátil e fácil de usar.
É importante notar que esses métodos são implementados de forma a garantir que os valores sejam escritos no arquivo no formato esperado. Eles adicionam o delimitador ao final de cada elemento, exceto para o último elemento da linha ou array. Isso garante que os valores sejam separados corretamente no arquivo CSV, o que é essencial para a leitura e interpretação dos dados no arquivo.
Exemplo de utilização do método ToString(const int row, const T &values[][]):
int data[2][3] = {{1, 2, 3}, {4, 5, 6}}; string str = csvFile.ToString(1, data); //str -> "4;5;6"
Neste exemplo, a segunda linha da matriz data é passada para o método ToString. O método percorre cada elemento da linha, adicionando-o à string resultante e adicionando o delimitador ao final de cada elemento, exceto para o último elemento da linha. A string resultante seria "4;5;6".
Exemplo de utilização do método ToString(const T &values[]):
string headers[] = {"Name", "Age", "Gender"}; string str = csvFile.ToString(headers); //str -> "Name;Age;Gender"
Neste exemplo, o array headers é passado para o método ToString. O método percorre cada elemento do array, adicionando-o à string resultante e adicionando o delimitador ao final de cada elemento, exceto para o último elemento do array. A string resultante seria "Name;Age;Gender".
Estes são apenas exemplos de como os métodos ToString e ToString podem ser utilizados. Eles podem ser aplicados a qualquer tipo de dado que possa ser convertido em uma string, mas é importante mencionar que eles só são acessíveis dentro da classe CFileCSV pois são declarados como privados.
Complexidade Algorítmica
Como a complexidade algorítmica pode ser medida e utilizada para otimizar o desempenho de algoritmos e sistemas?
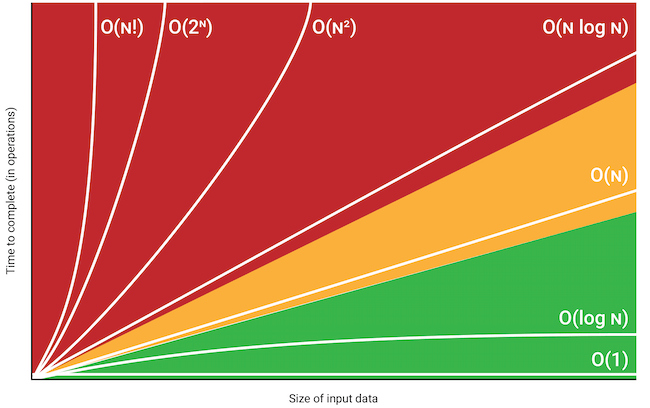
O Big O é uma ferramenta fundamental na análise de algoritmos, e sua utilidade tem sido reconhecida desde os primórdios da ciência da computação. Embora tenha sido formalmente definido na década de 60, o conceito de Big O ainda é amplamente utilizado na atualidade. Ele permite que os programadores avaliem a complexidade de um algoritmo de forma aproximada, com base em sua entrada e na quantidade de operações necessárias para executá-lo. Com isso, é possível comparar diferentes algoritmos e identificar aqueles que oferecem o melhor desempenho para determinadas tarefas.
A necessidade de uso de Big O surge a partir do crescimento exponencial dos dados e a complexidade dos problemas a serem resolvidos. Com a evolução da tecnologia, a quantidade de dados gerados diariamente aumentou significativamente e, consequentemente, a necessidade de algoritmos mais eficientes para lidar com esses dados. Big O permite que os desenvolvedores e pesquisadores possam comparar e avaliar diferentes algoritmos para encontrar a melhor opção de acordo com as necessidades de cada problema.
O conceito de Big O é baseado na noção de que, para um algoritmo, o tempo de execução cresce de acordo com uma função matemática específica, geralmente uma função polinomial. A notação Big O é usada para representar essa função e pode ser escrita como O(f(n)), onde f(n) é a função de complexidade do algoritmo.
Exemplos de notações Big O incluem:
- O(1), que representa um algoritmo de tempo constante, independente do tamanho dos dados.
- O(n), que representa um algoritmo de tempo linear, onde o tempo de execução cresce de acordo com o tamanho dos dados.
- O(n^2), que representa um algoritmo de tempo quadrático, onde o tempo de execução cresce de acordo com o quadrado do tamanho dos dados.
- O(log n), que representa um algoritmo de tempo logarítmico, onde o tempo de execução cresce de acordo com o logaritmo do tamanho dos dados.
Big O é uma ferramenta importante para entender e comparar a eficiência de diferentes algoritmos. Ele ajuda nas tomadas de decisões informadas sobre qual algoritmo usar para resolver um problema específico e otimizar o desempenho de seus sistemas.
A complexidade de tempo de cada método da classe CFileCSV varia dependendo do tamanho dos dados passados como parâmetro.
- O método Open tem complexidade O(1), pois ele realiza uma única operação de abertura de arquivo, independentemente do tamanho dos dados.
- O método Read tem complexidade O(n), onde n é o tamanho do arquivo. Ele lê todo o conteúdo do arquivo e armazena em uma string.
- O método WriteHeader tem complexidade O(n), onde n é o tamanho do array passado como parâmetro. Ele transforma o array em uma string e escreve essa string no arquivo.
- O método WriteLine tem complexidade O(mn), onde m é o número de linhas da matriz e n é o número de elementos em cada linha. Ele percorre cada linha da matriz, transformando-a em uma string e escrevendo essa string no arquivo.
É importante notar que essas complexidades são aproximadas, pois podem ser afetadas por outros fatores, como o tamanho do buffer de escrita do arquivo, o sistema de arquivos, etc. Além disso, esses impactos de Big O são para o pior cenário, se os dados passados para os metodos forem muito grandes, a complexidade pode ser maior.
Em resumo, a classe CFileCSV tem uma complexidade de tempo razoável e é eficiente para trabalhar com arquivos de tamanhos razoáveis. No entanto, se estiver lidando com arquivos muito grandes, pode ser necessário considerar outras abordagens ou otimizar a classe para lidar com esses casos de uso específicos.
Exemplo de utilização
//+------------------------------------------------------------------+ //| exemplo_2.mq5 | //| Copyright 2022, Lethan Corp. | //| https://www.mql5.com/pt/users/14134597 | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Lethan Corp." #property link "https://www.mql5.com/pt/users/14134597" #property version "1.00" #include "FileCSV.mqh" CFileCSV csvFile; string fileName = "dados.csv"; string headers[] = {"Timestamp", "Close", "Last"}; string data[1][3]; //Função OnInit int OnStart(void) { //Preenchendo o array 'data' com os valores de timestamp, Bid, Ask, Indicador1 e Indicador2 data[0][0] = TimeToString(TimeCurrent()); data[0][1] = DoubleToString(iClose(Symbol(), PERIOD_CURRENT, 0), 2); data[0][2] = DoubleToString(SymbolInfoDouble(Symbol(), SYMBOL_LAST), 2); //Abrindo o arquivo CSV if(csvFile.Open(fileName, FILE_WRITE|FILE_ANSI)) { //Escrevendo o cabeçalho csvFile.WriteHeader(headers); //Escrevendo as linhas com os dados csvFile.WriteLine(data); //Fechando o arquivo csvFile.Close(); } else { Print("Erro ao abrir o arquivo!"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+
Este código é uma implementação da classe CFileCSV em MQL5. Ele inclui as seguintes funcionalidades:
- Tratamento de erro para caso o arquivo não possa ser aberto.
- Abrir um arquivo CSV com o nome especificado e com as permissões de escrita
- Escrever um cabeçalho (headers) no arquivo, especificado como uma matriz de strings
- Escrever dados, especificado como uma matriz de strings, no arquivo
- Fechar o arquivo depois de ter escrito tudo.
Conclusão
Em resumo, a classe CFileCSV fornece uma maneira fácil e conveniente de lidar com arquivos CSV, usando métodos para abrir, escrever cabeçalhos e linhas, bem como ler um arquivo CSV. Os métodos Open, WriteHeader, WriteLine e Read são fundamentais para garantir a correta manipulação dos arquivos CSV, eles garantem que os dados sejam escritos de forma organizada e possam ser lidos corretamente. Gostaria de agradecer por sua leitura e informar que na próxima sessão, vamos discutir como utilizar modelos de aprendizado de máquina através da troca de arquivos utilizando a classe CFileCSV que foi apresentada nesta sessão.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Guia Prático MQL5 — Serviços
Guia Prático MQL5 — Serviços
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso