MQL5言語での自動売買ロボットのプログラミング例に関する記事
エキスパートアドバイザーはプログラミングの「頂点」であり、それぞれの自動取引の開発者の求めたゴールです。このセクションの記事を読んで、ご自分の自動売買ロボットを作成してください。記述された手順に従うことにより、どのように自動取引システムを作成し、デバッグし、テストするかを学びます。
記事はMQL5プログラミングを教えるだけでなく、どのようにトレーディングアイデアとテクニックを導入するかを示します。どのようにトレーリングストップをプログラムするか、どのように資金管理を適用するか、どのようにインディケータ値を取得するかなど、さらに多くのことを学べます。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索

Candlestick Trend Constraintモデルの構築(第10回):戦略的ゴールデンクロスとデスクロス(EA)
移動平均線のクロスオーバーに基づくゴールデンクロスおよびデッドクロス戦略は、長期的な市場トレンドを見極める上で最も信頼性の高い指標の一つであることをご存知でしょうか。ゴールデンクロスは、短期移動平均線が長期移動平均線を上回るときに強気トレンドの到来を示します。一方、デッドクロスは、短期移動平均線が長期線を下回ることで弱気トレンドの兆候を示します。これらの戦略は非常にシンプルでありながら効果的ですが、手動で運用すると機会の逸失やエントリーの遅れが発生しやすいという課題があります。
MQL5での取引戦略の自動化(第3回):ダイナミック取引管理のためのZone Recovery RSIシステム
この記事では、MQL5を使ってZone Recovery RSI EAシステムを構築し、RSIシグナルによって取引を開始し、損失を管理するためのリカバリーストラテジーを実装します。取引エントリー、リカバリーロジック、ポジション管理を自動化するために、ZoneRecoveryクラスを作成します。この記事の最後では、EAのパフォーマンスを最適化し、その有効性を高めるためのバックテストの洞察を紹介します。

スイングエントリーモニタリングEAの開発
年末が近づくと、多くの長期トレーダーは市場の過去を振り返り、その動きや傾向を分析して、将来の動向を予測しようとします。この記事では、MQL5を用いて長期エントリーの監視をおこなうエキスパートアドバイザー(EA)の開発について解説します。手動取引や自動監視システムの不在によって、長期的な取引チャンスを逃してしまうという課題に取り組むことが本稿の目的です。今回は、特に取引量の多い通貨ペアの一つを例に挙げ、効果的な戦略を立案しながらソリューションを構築していきます。

MQL5でのファイル操作の習得:基本的なI/OからカスタムCSVリーダーの構築まで
この記事では、取引ログ、CSVの処理、外部データの統合など、MQL5における基本的なファイル操作テクニックに焦点を当て、概念的な理解と実践的なコーディングガイドの両面から解説します。読者は、カスタムCSVインポート用のクラスを段階的に構築する方法を学び、実践的なスキルを身につけることができます。

ニュース取引が簡単に(第6回):取引の実施(III)
この記事では、IDに基づいて個々のニュースイベントをフィルターする関数を実装します。さらに、以前のSQLクエリを改善し、追加情報が提供されたり、クエリの実行時間が短縮されるようになります。さらに、これまでの記事で作成したコードを機能的なものにします。

MQL5での取引戦略の自動化(第2回):一目均衡表とオーサムオシレーターを備えた雲抜けシステム
この記事では、一目均衡表とオーサムオシレーター(Awesome Oscillator)を活用し、「雲抜け戦略」を自動化するエキスパートアドバイザー(EA)を作成します。インジケーターハンドルの初期化、ブレイクアウト条件の検出、自動売買におけるエントリーおよびエグジットの実装手順について、段階的に解説します。さらに、トレーリングストップやポジション管理ロジックを組み込むことで、EAのパフォーマンスと市場適応力を高める方法にも触れます。
プライスアクション分析ツールキットの開発(第5回):Volatility Navigator EA
市場の方向性を判断するのは簡単ですが、いつエントリーするかを知るのは難しい場合があります。連載「プライスアクション分析ツールキットの開発」の一環として、エントリーポイント、テイクプロフィットレベル、ストップロスの配置を提供する別のツールを紹介できることを嬉しく思います。これを実現するために、MQL5プログラミング言語を利用しました。この記事では、各ステップについて詳しく見ていきましょう。

プライスアクション分析ツールキットの開発(第4回):Analytics Forecaster EA
チャート上に表示された分析済みのメトリックを見るだけにとどまらず、Telegramとの統合によってブロードキャストを拡張するという、より広い視点へと移行しています。この機能強化により、Telegramアプリを通じて、重要な結果がモバイルデバイスに直接配信されるようになります。この記事では、この新たな取り組みを一緒に探っていきましょう。

Candlestick Trend Constraintモデルの構築(第9回):マルチ戦略エキスパートアドバイザー(III)
連載第3回へようこそ。今回は、日足のトレンドに沿った最適なエントリーポイントを特定する戦略として、ダイバージェンスの活用について詳しく解説します。また、トレーリングストップロスに似た、しかし独自の機能を備えたカスタム利益ロック機構もご紹介します。さらに、Trend Constraint EAを高度化し、既存の取引条件を補完する形で新たなエントリー条件を追加します。今後も、MQL5を活用したアルゴリズム開発の実践的な応用方法を深掘りし、実際に使えるテクニックや洞察を継続的にお届けしていきます。

MQL5経済指標カレンダーを使った取引(第5回):レスポンシブコントロールとフィルターボタンでダッシュボードを強化する
この記事では、ダッシュボードの制御を改善するために、通貨ペアフィルター、重要度レベル、時間フィルター、キャンセルオプションのボタンを作成します。これらのボタンは、ユーザーのアクションに動的に応答するようにプログラムされており、シームレスな操作を可能にします。また、ダッシュボードにリアルタイムの変更を反映するために、ユーザーの行動を自動化します。これにより、パネルの全体的な機能性、モビリティ、応答性が向上します。

MQL5で取引管理者パネルを作成する(第8回):分析パネル
今日は、管理パネルEAに統合された専用ウィンドウ内に、便利な取引メトリクスを組み込む方法について掘り下げていきます。本稿では、MQL5を活用して分析パネル(Analytics Panel)を開発する方法に焦点を当て、そのパネルが取引管理者にもたらすデータの価値について解説します。この開発プロセスは教育的意義が大きく、初心者・経験者を問わず開発者にとって有益な学びを提供します。この機能は、高度なソフトウェアツールを通じて取引マネージャーを支援する本連載の可能性を示す好例です。さらに、取引管理パネル(Trading Administrator Panel)の機能拡張の一環として、PieChartクラスとChartCanvasクラスの実装についても取り上げます。
MQL5経済指標カレンダーを使った取引(第4回):ダッシュボードでのリアルタイムニュース更新の実装
この記事では、リアルタイムのニュース更新機能を実装することで、経済指標カレンダーダッシュボードを強化し、市場情報を常に最新かつ実用的な状態に保ちます。MQL5におけるライブデータ取得技術を統合し、ダッシュボード上のイベントを継続的に更新することで、インターフェイスの応答性を向上させます。このアップデートにより、ダッシュボードから最新の経済ニュースに直接アクセスでき、最新データに基づいて取引判断を最適化できるようになります。

取引量による取引の洞察:OHLCチャートを超えて
取引量分析と機械学習技術、特にLSTMニューラルネットワークを組み合わせたアルゴリズム取引システムです。価格変動を中心に据えた従来の取引アプローチとは異なり、このシステムは市場の動きを予測するために取引量パターンとその導関数を重視します。この方法論には、取引量導関数分析(一次導関数および二次導関数)、取引量パターンのLSTM予測、および従来のテクニカル指標という3つの主要コンポーネントが組み込まれています。
MQL5で取引管理者パネルを作成する(第6回):取引管理パネル(II)
この記事では、多機能管理パネルの取引管理パネル(Trade Management Panel)を強化します。コードを簡素化し、読みやすさ、保守性、効率性を向上させる強力なヘルパー関数を導入します。また、追加のボタンをシームレスに統合し、インターフェイスを強化して、より幅広い取引タスクを処理する方法も紹介します。ポジションの管理、注文の調整、ユーザーとのやり取りの簡素化など、このガイドは、堅牢でユーザーフレンドリーな取引管理パネルの開発に役立ちます。

MQL5経済指標カレンダーを使った取引(第3回):通貨、重要度、時間フィルターの追加
この記事では、MQL5経済カレンダーダッシュボードにフィルターを実装し、通貨、重要度、時間ごとにニュースイベントの表示を絞り込みます。まず、各カテゴリのフィルター基準を設定し、それをダッシュボードに組み込むことで、関連するイベントのみが表示されるようにします。最後に、各フィルターが動的に更新され、トレーダーにとって必要な、焦点を絞ったリアルタイムの経済情報が提供されるようにします。

MQL5で取引管理者パネルを作成する(第7回):信頼できるユーザー、回復、暗号化
チャートの更新や管理パネル(Admin Panel) EAとのチャットに新しいペアを追加する際、または端末を再起動するたびにトリガーされるセキュリティプロンプトは、時に煩わしく感じられることがあります。このディスカッションでは、ログイン試行回数を追跡して信頼できるユーザーを識別する機能を検討し、実装します。一定回数の試行に失敗した場合、アプリケーションは高度なログイン手続きに移行し、パスコードを忘れたユーザーが回復できるようにします。さらに、管理パネルに暗号化を効果的に統合してセキュリティを強化する方法についても取り上げます。

プライスアクション分析ツールキットの開発(第2回): Analytical Commentスクリプト
プライスアクションを簡素化するというビジョンに沿って、市場分析を大幅に強化し、十分な情報に基づいた意思決定を支援する新しいツールを導入できることを嬉しく思います。このツールは、前日の価格、重要な支持と抵抗のレベル、取引量などの主要なテクニカル指標を表示し、チャート上に視覚的なヒントを自動的に生成します。

MQL5での取引戦略の自動化(第1回):Profitunityシステム(ビル・ウィリアムズ著「Trading Chaos」)
この記事では、ビル・ウィリアムズのProfitunityシステムを詳しく分析し、その核心となる構成要素や、市場の混乱の中での独自の取引アプローチを解説します。MQL5用いたシステムの実装方法を、主要なインジケーターやエントリー/エグジットシグナルの自動化に焦点を当てながら説明します。さらに、戦略のテストと最適化をおこない、さまざまな市場環境におけるパフォーマンスについて考察します。

PythonからMQL5へ:量子に着想を得た取引システムへの旅
この記事では、量子に着想を得た取引システムの開発について検討し、Pythonプロトタイプから実際の取引のためのMQL5実装への移行について説明します。このシステムは、量子シミュレーターを使用した従来のコンピューター上で実行されますが、重ね合わせや量子もつれなどの量子コンピューティングの原理を使用して市場の状態を分析します。主な機能には、8つの市場状態を同時に分析する3量子ビットシステム、24時間のルックバック期間、および市場分析用の7つのテクニカル指標が含まれます。精度率は控えめに思えるかもしれませんが、適切なリスク管理戦略と組み合わせると大きな優位性が得られます。
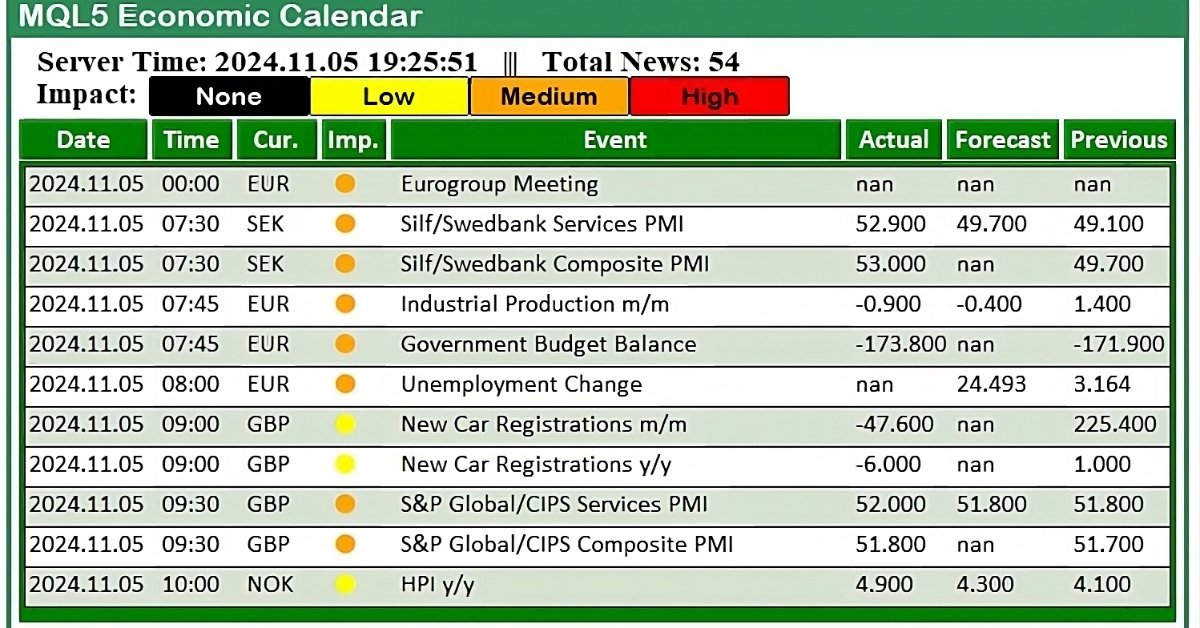
MQL5経済指標カレンダーを使った取引(第2回):ニュースダッシュボードパネルの作成
この記事では、MQL5経済指標カレンダーを使用して、取引戦略を強化するための実用的なニュースダッシュボードパネルを作成します。まず、イベント名、重要度、タイミングなどの重要な要素に焦点を当ててレイアウトを設計し、その後、MQL5内でのセットアップに進みます。最後に、最も関連性の高いニュースのみを表示するフィルタリングシステムを実装し、トレーダーが影響力のある経済イベントに迅速にアクセスできるようにします。

古典的な戦略を再構築する(第11回):移動平均クロスオーバー(II)
移動平均とストキャスティクスオシレーターは、トレンドに従う取引シグナルを生成するために使用できます。ただし、これらのシグナルは価格変動が発生した後にのみ観察されます。AIを使用することで、テクニカルインジケーターに内在するこの遅れを効果的に克服できます。この記事では、既存の取引戦略を改善できるような、完全に自律的なAI搭載のエキスパートアドバイザー(EA)を作成する方法を説明します。最も古い取引戦略であっても、改善することは可能です。
MQL5で取引管理者パネルを作成する(第6回):多機能インターフェイス(I)
取引管理者の役割はTelegram通信だけにとどまらず、注文管理、ポジション追跡、インターフェイスのカスタマイズなど、さまざまな制御アクティビティにも携わります。この記事では、MQL5の複数の機能をサポートするためにプログラムを拡張するための実用的な洞察を共有します。このアップデートは、主にコミュニケーションに重点を置くという現在のAdminパネルの制限を克服し、より幅広いタスクを処理できるようにすることを目的としています。

取引におけるニューラルネットワーク:複雑な軌道予測法(Traj-LLM)
この記事では、自動運転車の動作の分野における問題を解決するために開発された興味深い軌道予測方法を紹介します。この手法の著者は、さまざまな建築ソリューションの最良の要素を組み合わせました。

取引におけるニューラルネットワーク:状態空間モデル
これまでにレビューしたモデルの多くは、Transformerアーキテクチャに基づいています。ただし、長いシーケンスを処理する場合には非効率的になる可能性があります。この記事では、状態空間モデルに基づく時系列予測の別の方向性について説明します。

取引におけるニューラルネットワーク:独立したチャネルへのグローバル情報の注入(InjectTST)
最新のマルチモーダル時系列予測方法のほとんどは、独立チャネルアプローチを使用しています。これにより、同じ時系列の異なるチャネルの自然な依存関係が無視されます。2つのアプローチ(独立チャネルと混合チャネル)を賢く使用することが、モデルのパフォーマンスを向上させる鍵となります。




取引におけるニューラルネットワーク:時系列予測のための軽量モデル
軽量な時系列予測モデルは、最小限のパラメータ数で高いパフォーマンスを実現します。これにより、コンピューティングリソースの消費を抑えつつ、意思決定の迅速化が可能となります。こうしたモデルは軽量でありながら、より複雑なモデルと同等の予測精度を達成できます。

取引におけるニューラルネットワーク:Adam-mini最適化によるメモリ消費量の削減
モデルの訓練と収束プロセスの効率を向上させるためのアプローチの1つが、最適化手法の改良です。Adam-miniは、従来のAdamアルゴリズムを改良し、より効率的な適応型最適化を実現することを目的とした手法です。

取引におけるカオス理論(第1回):金融市場における導入と応用、リアプノフ指数
カオス理論は金融市場に適用できるでしょうか。この記事では、従来のカオス理論とカオスシステムがビル・ウィリアムズが提案した市場のカオスの概念とどのように異なるかについて考察します。

取引におけるニューラルネットワーク:時空間ニューラルネットワーク(STNN)
この記事では、時空間変換を活用し、今後の価格変動を効果的に予測する手法について解説します。STNNの数値予測精度を向上させるために、データの重要な側面をより適切に考慮できる連続アテンションメカニズムが提案されています。
取引におけるニューラルネットワーク:二重アテンションベースのトレンド予測モデル
前回の記事で取り上げた時系列の区分線形表現の活用について、引き続き議論します。本日は、この手法を他の時系列分析手法と組み合わせることで、価格動向の予測精度を向上させる方法を探ります。

取引におけるニューラルネットワーク:時系列の区分線形表現
本記事は、これまでの公開記事とはやや異なる内容となっています。本記事では、時系列データの代替的な表現について解説します。時系列の区分的線形表現とは、小さな区間ごとに線形関数を用いて時系列データを近似する手法です。

ニューラルネットワークが簡単に(第97回):MSFformerによるモデルの訓練
さまざまなモデルアーキテクチャの設計を検討する際、モデルの訓練プロセスには十分な注意が払われないことがよくあります。この記事では、そのギャップを埋めることを目指します。

多通貨エキスパートアドバイザーの開発(第14回):リスクマネージャーにおける適応型ボリューム変更
以前開発されたリスクマネージャーには基本的な機能のみが含まれていました。取引戦略のロジックに干渉することなく取引結果を向上させるために、どのような開発の可能性があるかを検討してみましょう。
MQL5経済指標カレンダーを使った取引(第1回):MQL5経済指標カレンダーの機能をマスターする
この記事では、まず、MQL5経済指標カレンダーの基本機能を理解し、それを取引に活用する方法を探ります。次に、MQL5で経済指標カレンダーの主要機能を実装し、取引の判断に役立つニュースを取得する方法を説明します。最後に、この情報を活用して取引戦略を効果的に強化する方法を紹介します。

ニュース取引が簡単に(第5回):取引の実施(II)
この記事では、取引管理クラスを拡張し、ニュースイベントを取引するための買い逆指値注文(買いストップ注文)と売り逆指値注文(売りストップ注文)を追加します。また、オーバーナイト取引を防ぐために、これらの注文に有効期限の制約を実装します。さらに、逆指値注文(ストップ注文)を使用する際に発生しうるスリッページ、特にニュースイベント中に発生する可能性のあるスリッページを防止または最小限に抑えるために、スリッページ関数をエキスパートアドバイザー(EA)に組み込みます。

Controlsクラスを使用してインタラクティブなMQL5ダッシュボード/パネルを作成する方法(第2回):ボタンの応答性の追加
この記事では、ボタンの応答性を有効にすることで、静的なMQL5ダッシュボードパネルをインタラクティブなツールへと変換することに焦点を当てます。GUIコンポーネントの機能を自動化し、ユーザーのクリックに適切に反応する方法を探究します。この記事の最後には、ユーザーのエンゲージメントと取引体験を向上させる動的なインターフェイスを構築します。
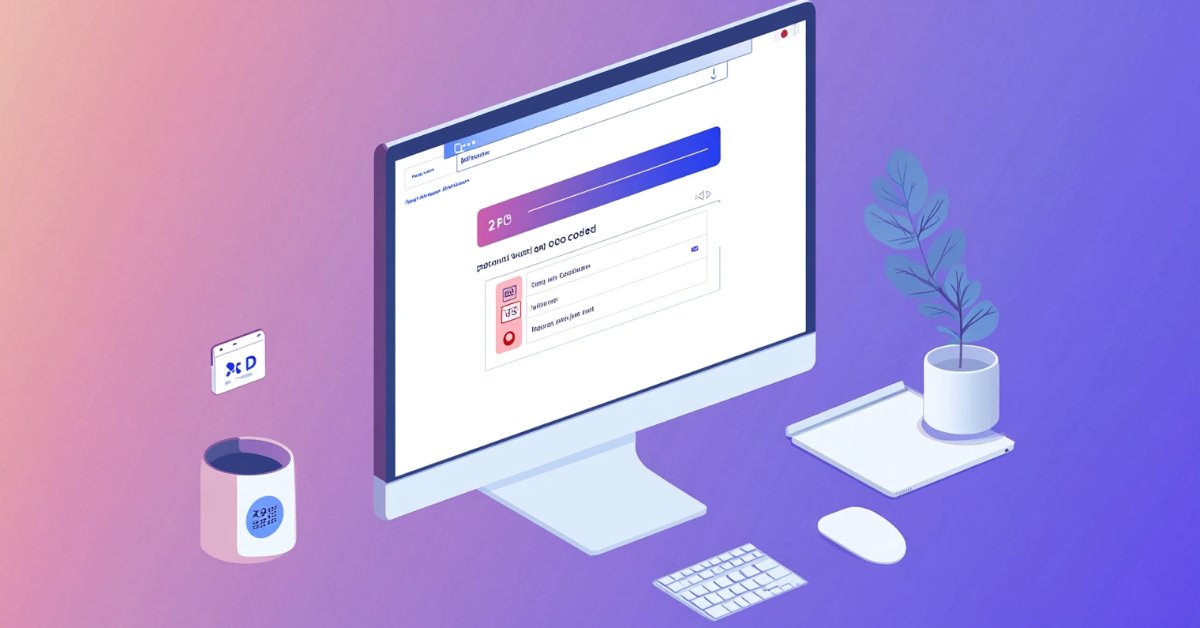
MQL5で取引管理者パネルを作成する(第5回):2要素認証(2FA)
本日は、現在開発中の取引管理パネルのセキュリティ強化について説明します。Telegram APIを統合し、2要素認証(2FA)を実現する新しいセキュリティ戦略にMQL5を実装する方法を探ります。このディスカッションでは、MQL5を活用してセキュリティ対策を強化する方法について貴重な洞察を得ることができます。さらに、MathRand関数の機能に焦点を当て、セキュリティフレームワーク内でどのように効果的に活用できるかを検討します。さらに詳しく知りたい方は、読み続けてください。