MQL5言語での自動売買ロボットのプログラミング例に関する記事
エキスパートアドバイザーはプログラミングの「頂点」であり、それぞれの自動取引の開発者の求めたゴールです。このセクションの記事を読んで、ご自分の自動売買ロボットを作成してください。記述された手順に従うことにより、どのように自動取引システムを作成し、デバッグし、テストするかを学びます。
記事はMQL5プログラミングを教えるだけでなく、どのようにトレーディングアイデアとテクニックを導入するかを示します。どのようにトレーリングストップをプログラムするか、どのように資金管理を適用するか、どのようにインディケータ値を取得するかなど、さらに多くのことを学べます。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索

MQL5経済指標カレンダーを使った取引(第8回):ニュース駆動型バックテストの最適化 - スマートなイベントフィルタリングと選択的ログ
本記事では、スマートなイベントフィルタリングと選択的ログ出力を用いて経済カレンダーを最適化し、ライブおよびオフラインモードでのバックテストをより高速かつ明確に実施できるようにします。イベント処理を効率化し、ログを重要な取引やダッシュボードイベントに絞ることで、戦略の可視化を向上させます。これらの改善により、ニュース駆動型取引戦略のテストと改善をシームレスにおこなえるようになります。
MQL5での取引戦略の自動化(第17回):ダイナミックダッシュボードで実践するグリッドマーチンゲールスキャルピング戦略
本記事では、グリッドマーチンゲールスキャルピング戦略(Grid-Mart Scalping Strategy)を探究し、MQL5による自動化と、リアルタイム取引インサイトを提供するダイナミックダッシュボードの構築をおこないます。本戦略のグリッド型マーチンゲールロジックとリスク管理機能を詳述し、さらに堅牢なパフォーマンスのためのバックテストおよび実運用展開についても案内します。

MQL5取引ツール(第2回):インタラクティブな取引アシスタントの強化:動的視覚フィードバックの導入
この記事では、取引アシスタントツール(Trade Assistant Tool)をアップグレードし、ドラッグ&ドロップ可能なパネル機能やホバー効果を追加して、インターフェースをより直感的で応答性の高いものにします。ツールを改良してリアルタイムの注文設定を検証し、市場価格に対して正確な取引構成が可能となるようにします。また、これらの改善をバックテストし、その信頼性を確認します。
MQL5取引ツール(第1回):インタラクティブで視覚的なペンディングオーダー取引アシスタントツールの構築
この記事では、FX取引におけるペンディングオーダーの設置を簡素化するために開発した、MQL5によるインタラクティブ取引アシスタントツール(Trade Assistant Tool)について紹介します。まず概念設計を説明し、チャート上でエントリー、ストップロス、テイクプロフィット水準を視覚的に設定できるユーザーフレンドリーなGUIに焦点を当てます。さらに、MQL5での実装およびバックテストのプロセスを詳述し、このツールの信頼性を確認します。そして、後続のパートで発展的な機能を追加するための基盤を整えます。

バックテスト結果を改善するための生のコードの最適化と調整
MQL5コードを強化するために、ロジックの最適化、計算の精緻化、実行時間の短縮をおこない、バックテストの精度を向上させましょう。パラメータの微調整、ループの最適化、非効率の排除によって、より高いパフォーマンスを実現します。

外国為替におけるポートフォリオ最適化:VaRとマーコウィッツ理論の統合
FXにおけるポートフォリオ取引はどのように機能するのでしょうか。マーコウィッツのポートフォリオ理論による資産配分最適化と、VaRモデルによるリスク最適化はどのように統合できるのでしょうか。ポートフォリオ理論に基づいたコードを作成し、一方では低リスクを確保し、もう一方では受け入れ可能な長期的収益性を得ることを試みます。

3D反転パターンに基づくアルゴリズム取引
3Dバーによる自動売買の新しい世界を発見します。多次元の価格バー上で自動売買ロボットはどのように見えるのでしょうか。3Dバーの「黄色のクラスタ」はトレンドの反転を予測できるのでしょうか。多次元取引はどのように見えるのでしょうか。

取引におけるニューラルネットワーク:Segment Attentionを備えたパラメータ効率重視Transformer(最終回)
前回の記事では、PSformerフレームワークの理論的側面について議論しました。このフレームワークは、従来のTransformerアーキテクチャに、パラメータ共有(PS)メカニズムと時空間Segment Attention (SegAtt)という2つの主要な革新をもたらします。本稿では、前回に引き続き、提案された手法をMQL5を用いて実装する作業について説明します。

取引におけるニューラルネットワーク:Segment Attentionを備えたパラメータ効率重視Transformer (PSformer)
この記事では、新しいPSformerフレームワークを紹介します。これは、従来のTransformerアーキテクチャを多変量時系列予測の問題に適応させたものです。本フレームワークは、パラメータ共有(PS)機構とSegment Attention機構(SegAtt)の2つの主要な革新に基づいています。

取引におけるニューラルネットワーク:シャープネス低減によるTransformerの効率向上(最終回)
SAMformerは、長期の時系列予測におけるTransformerモデルの主要な欠点、すなわち学習の複雑さや小規模データセットでの汎化性能の低さに対して解決策を提供します。その浅いアーキテクチャとシャープネス認識型最適化により、不適切な局所解に陥ることを防ぎます。本記事では、MQL5を用いたアプローチの実装を続け、実際的な価値を評価していきます。

取引におけるニューラルネットワーク:シャープネス低減によるTransformerの効率向上(SAMformer)
Transformerモデルの学習には大量のデータが必要であり、小規模データセットに対しては汎化性能が低いため、学習はしばしば困難です。SAMformerフレームワークは、この問題を回避し、不良な局所最小値に陥ることを防ぐことで解決を助けます。これにより、限られた学習データセットにおいてもモデルの効率が向上します。

初心者からプロまでMQL5をマスターする(第6回):エキスパートアドバイザー開発の基礎
この記事は初心者向け連載の続きです。今回はエキスパートアドバイザー(EA)開発の基本原理について解説します。2つのEAを作成します。1つ目はインジケーターを使わず、予約注文で取引をおこなうEA。2つ目は標準の移動平均線(MA)インジケーターを利用し、成行価格で取引をおこなうEAです。ここでは、前回までの記事の内容をある程度理解していることを前提としています。

取引におけるニューラルネットワーク:時系列予測のためのTransformerの最適化(LSEAttention)
LSEAttentionフレームワークは、Transformerアーキテクチャの改善を提供します。この手法は、特に長期の多変量時系列予測のために設計されました。提案されたアプローチは、従来のTransformerでよく遭遇するエントロピーの崩壊や学習の不安定性の問題を解決するために応用可能です。

取引におけるニューラルネットワーク:双曲潜在拡散モデル(最終回)
HypDiffフレームワークで提案されているように、双曲潜在空間における初期データのエンコーディングに異方性拡散プロセスを用いることで、現在の市場状況におけるトポロジー的特徴を保持しやすくなり、分析の質を向上させることができます。前回の記事では、提案されたアプローチの実装をMQL5を用いて開始しました。今回はその作業を継続し、論理的な完結に向けて進めていきます。

取引におけるニューラルネットワーク:双曲潜在拡散モデル(HypDiff)
この記事では、異方性拡散プロセスを用いた双曲潜在空間における初期データのエンコーディング手法について検討します。これにより、現在の市場状況におけるトポロジー的特徴をより正確に保持でき、分析の質が向上します。

取引におけるニューラルネットワーク:方向性拡散モデル(DDM)
本稿では、前向き拡散過程においてデータ依存的な異方性および方向性を持つノイズを活用するDirectional Diffusion Models(DDM、方向性拡散モデル)について議論し、意味のあるグラフ表現を捉える手法を紹介します。

取引におけるニューラルネットワーク:NAFSによるノード依存型グラフ表現
NAFS (Node-Adaptive Feature Smoothing)手法を紹介します。これは、パラメータの学習を必要としない非パラメトリックなノード表現生成手法です。NAFSは、各ノードの近傍ノードに基づいて特徴量を抽出し、それらを適応的に統合することで最終的なノード表現を生成します。

取引におけるニューラルネットワーク:対照パターンTransformer(最終回)
本連載の前回の記事では、Atom-Motif Contrastive Transformer (AMCT)フレームワークについて取り上げました。これは、対照学習を用いて、基本要素から複雑な構造に至るまでのあらゆるレベルで重要なパターンを発見することを目的とした手法です。この記事では、MQL5を用いたAMCTアプローチの実装を引き続き解説していきます。

取引におけるニューラルネットワーク:対照パターンTransformer
Contrastive Transformerは、個々のローソク足のレベルと、全体のパターンに基づいて市場を分析するよう設計されています。これにより、市場トレンドのモデリングの質が向上します。さらに、ローソク足とパターンの表現を整合させるために対照学習を用いることで、自己調整が促され、予測の精度が高まります。

取引におけるニューラルネットワーク:パターンTransformerを用いた市場分析
モデルを使用して市場の状況を分析する場合、主にローソク足に注目します。しかし、ローソク足パターンが将来の価格変動を予測するのに役立つことは長い間知られていました。この記事では、これら両方のアプローチを統合できる方法について説明します。

取引におけるニューラルネットワーク:相対エンコーディング対応Transformer
自己教師あり学習は、ラベル付けされていない大量のデータを分析する効果的な手段となり得ます。この手法の効率性は、モデルが金融市場特有の特徴に適応することで実現され、従来手法の有効性も向上します。本記事では、入力間の相対的な依存関係や関係性を考慮した新しいAttention(注意)機構を紹介します。


Metatrader 5のWebsockets — Windows APIを使用した非同期クライアント接続
この記事では、MetaTraderプログラム向けに非同期のWebSocketクライアント接続を可能にするカスタムDLL(ダイナミックリンクライブラリ)の開発について解説します。

取引チャート上で双三次補間を用いたリソース駆動型画像スケーリングによる動的MQL5グラフィカルインターフェイスの作成
本記事では、取引チャート上で高品質な画像スケーリングを実現するために、双三次補間(バイキュービック補間)を使用した動的なMQL5グラフィカルインターフェイスについて解説します。カスタムオフセットによる動的な中央配置やコーナーアンカーなど、柔軟なポジショニングオプションも紹介します。

MQL5での取引戦略の自動化(第16回):ミッドナイトレンジブレイクアウト+Break of Structure (BoS)のプライスアクション
本記事では、MQL5を用いて「ミッドナイトレンジブレイクアウト + Break of Structure (BoS)」戦略を自動化し、ブレイクアウトの検出および取引実行のコードを詳細に解説します。エントリー、ストップ、利益確定のためのリスクパラメータを正確に定義し、実際の取引に活用できるようバックテストおよび最適化もおこないます。

MQL5での取引戦略の自動化(第15回):プライスアクションハーモニックCypherパターンの可視化
この記事では、CypherハーモニックパターンのMQL5における自動化について探究し、その検出方法とMetaTrader 5チャート上での可視化を詳しく解説します。スイングポイントを特定し、フィボナッチに基づいたパターンを検証し、明確な視覚的注釈とともに取引を実行するエキスパートアドバイザー(EA)を実装します。記事の最後では、効果的な取引のためのバックテストおよび最適化方法についても説明します。

MQL5でのカスタム市場レジーム検出システムの構築(第2回):エキスパートアドバイザー
この記事では、第1回で紹介したレジーム検出器を用いて、適応型のエキスパートアドバイザー(EA)、MarketRegimeEAを構築する方法を詳しく解説しています。このEAは、トレンド相場、レンジ相場、またはボラティリティの高い相場に応じて、取引戦略やリスクパラメータを自動的に切り替えます。実用的な最適化、移行時の処理、多時間枠インジケーターも含まれています。

MQL5で取引管理者パネルを作成する(第10回):外部リソースベースのインターフェイス
本日は、MQL5の機能を活用して、BMP形式の画像などの外部リソースを利用し、トレーディング管理パネル用に独自のスタイルを持ったホームインターフェイスを作成します。ここで紹介する手法は、画像やサウンドなど複数のリソースを一括でパッケージ化して配布する際に特に有効です。このディスカッションでは、こうした機能をどのように実装し、New_Admin_Panel EAにおいてモダンで視覚的に魅力的なインターフェイスを提供するかを一緒に見ていきましょう。

MQL5経済指標カレンダーを使った取引(第7回):リソースベースのニュースイベント分析による戦略テストの準備
この記事では、MQL5の取引システムをストラテジーテスターでの検証に対応するため、経済指標カレンダーのデータをリソースとして埋め込み、ライブ環境ではないテスト分析に活用する方法を解説します。イベントの読み込みと、時間・通貨・影響度に基づくフィルタリングを実装し、最終的にストラテジーテスター内でその動作を検証します。これにより、ニュースに基づいた戦略の効果的なバックテストが可能になります。

ダイナミックマルチペアEAの形成(第2回):ポートフォリオの分散化と最適化
ポートフォリオの分散化と最適化とは、複数の資産に戦略的に投資を分散しながら、リスク調整後のパフォーマンス指標に基づいてリターンを最大化する理想的な資産配分を選定する手法です。
PythonとMQL5を使用した特徴量エンジニアリング(第4回):UMAP回帰によるローソク足パターン認識
次元削減手法は、機械学習モデルのパフォーマンスを向上させるために広く用いられています。ここでは、UMAP (Uniform Manifold Approximation and Projection)という比較的新しい手法について説明します。UMAPは、古い手法に見られるデータの歪みや人工的な構造といった欠点を明確に克服することを目的として開発されました。UMAPは非常に強力な次元削減技術であり、似たローソク足を新たに効果的にグループ化できるため、アウトオブサンプル(未知データ)に対する誤差率を低減し、取引パフォーマンスを向上させることができます。

手動バックテストを簡単に:MQL5でストラテジーテスター用のカスタムツールキットを構築する
この記事では、ストラテジーテスターでの手動バックテストを簡単におこなうための、カスタムMQL5ツールキットの設計について紹介します。設計と実装に焦点を当て、特にインタラクティブな取引操作の仕組みについて詳しく解説します。その後、このツールキットを使って、戦略を効果的にテストする方法を実演します。
MQL5での取引戦略の自動化(第14回):MACD-RSI統計手法を用いた取引レイヤリング戦略
この記事では、MACDおよびRSIインジケーターと統計的手法を組み合わせた取引レイヤリング戦略を紹介します。このアプローチは、MQL5による自動売買において、ポジションを動的にスケーリングすることを目的としています。カスケード構造による戦略のアーキテクチャを解説し、主要なコードセグメントを通じて実装方法を詳述します。さらに、パフォーマンスを最適化するためのバックテスト手順についても案内します。最後に、この戦略が持つ可能性と、今後の自動売買戦略への発展性について考察します。

MQL5で取引管理者パネルを作成する(第9回):コード編成(V):AnalyticsPanelクラス
この議論では、リアルタイムの市場データや取引口座情報の取得方法、さまざまな計算の実行、そしてその結果をカスタムパネルに表示する方法について探ります。これを実現するために、パネル作成を含むこれらすべての機能をカプセル化したAnalyticsPanelクラスの開発にさらに深く取り組みます。この取り組みは、モジュラー設計の原則とコード構造のベストプラクティスを用い、高度な機能を導入するNew Admin Panel EAの継続的な拡張の一環です。

MQL5で取引管理者パネルを作成する(第9回):コード編成(IV):取引管理パネルクラス
このディスカッションでは、New_Admin_Panel EAにおけるTradeManagementPanelの最新版について解説します。このアップデートでは、組み込みクラスを活用することで、ユーザーフレンドリーな取引管理インターフェイスを提供するようにパネルが強化されました。パネルには、新規ポジションのオープン用取引ボタンや、既存のポジションおよび指値注文の管理用コントロールが含まれています。特に注目すべき機能は、インターフェイス上から直接ストップロス(SL)やテイクプロフィット(TP)を設定できるリスク管理機能が統合された点です。このアップデートにより、大規模なプログラムにおけるコードの整理が改善され、端末上では複雑になりがちな注文管理ツールへのアクセスが簡素化されました。
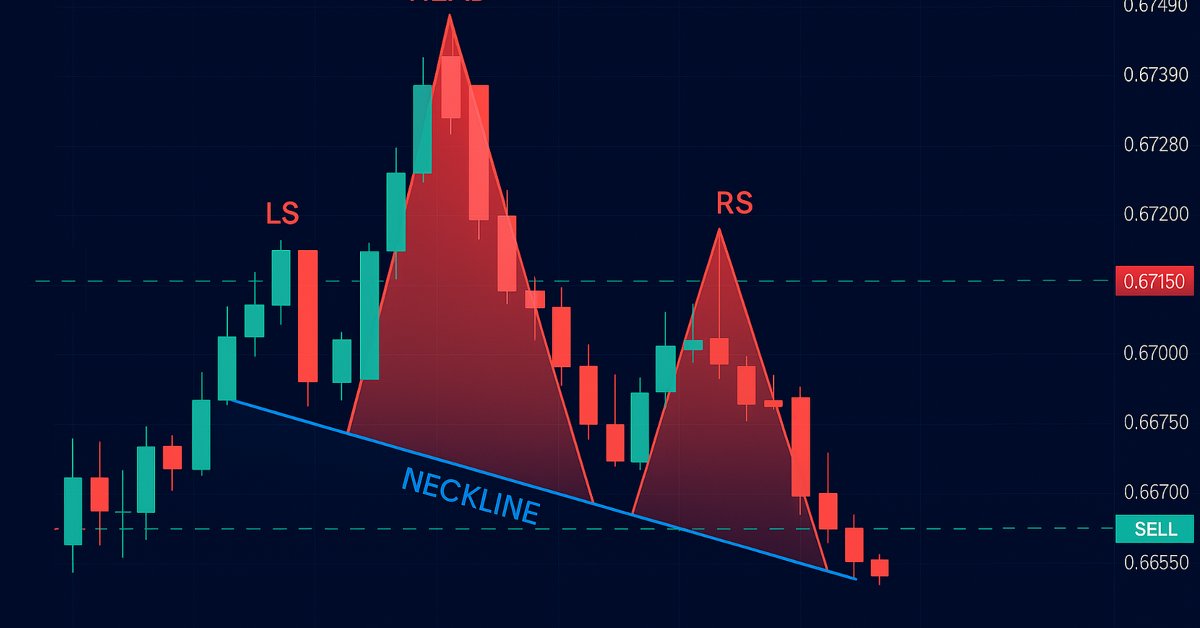
MQL5での取引戦略の自動化(第13回):三尊天井取引アルゴリズムの構築
この記事では、三尊天井(Head and Shoulders)パターンの検出と売買をMQL5で自動化します。その構造を分析し、検出および取引をおこなうエキスパートアドバイザー(EA)を実装し、バックテストでその結果を検証します。このプロセスを通じて、改良の余地を残しつつも実用的な取引アルゴリズムが明らかになります。

MQL5入門(第14回):初心者のためのカスタムインジケーター作成ガイド(III)
MQL5でチャートオブジェクトを使ってハーモニックパターンインジケーターを構築する方法を学びましょう。スイングポイントの検出、フィボナッチリトレースメントの適用、そしてパターン認識の自動化について解説します。
MQL5で自己最適化エキスパートアドバイザーを構築する(第6回):自己適応型取引ルール(II)
本記事では、より良い売買シグナルを得るために、RSIのレベルと期間を最適化する方法を探ります。最適なRSI値を推定する手法や、グリッドサーチと統計モデルを用いた期間選定の自動化について紹介します。最後に、Pythonによる分析を活用しながら、MQL5でソリューションを実装します。私たちのアプローチは、複雑になりがちな問題をシンプルに解決することを目指した、実用的かつ分かりやすいものです。

MQL5での取引戦略の自動化(第12回):Mitigation Order Blocks (MOB)戦略の実装
本記事では、スマートマネー取引向けにオーダーブロックの自動検出をおこなうMQL5取引システムを構築します。戦略のルールを明確にし、そのロジックをMQL5で実装し、さらに取引を効果的に執行するためにリスク管理も統合します。最後に、システムのパフォーマンスを評価するためにバックテストをおこない、最適な結果を得るための改良を加えます。

MQL5で取引管理者パネルを作成する(第9回):コード編成(III)コミュニケーションモジュール
MQL5インターフェイス設計における最新の進展を、再設計されたコミュニケーションパネルの公開とともに詳しく解説します。また、モジュール化の原則に基づいて新しい管理パネルを構築するシリーズも引き続き展開していきます。この記事では、CommunicationsDialogクラスを段階的に開発し、それをDialogクラスから継承する方法を丁寧に解説します。さらに、開発には配列およびListViewクラスを活用します。MQL5開発スキルを高めるための実用的な知見を得るために、ぜひ記事を読み、コメント欄でディスカッションにご参加ください。