
PythonやRの知識が不要なYandexのCatBoost機械学習アルゴリズム

まえがき
この記事では、ヤンデックスの機械学習アルゴリズム「CatBoost」を用いて、限られた変数セットで相場のパターンを記述したモデルを作成し、行動パターンに関する仮説を立てる方法について考察します。 このモデルを取得するためには、PythonやRの知識は必要ありません。 さらに、MQL5の基本的な知識があれば十分です - まさに私のレベルです。 したがって、この記事が、機械学習の評価やプログラムへの実装に興味のある人たちの手助けとなり、幅広い人たちの良いチュートリアルとなることを期待しています。 この記事を読む際、学術的な知識はほとんど必要ありません。 プラスとなる情報が必要な場合は、Vladimir Perervenkoの一連の記事をお読みください。
トレーディングにおける古典的なアプローチと機械学習の差
トレーディングストラテジーの概念は、おそらくほとんどのトレーダーが精通しています。 さらに、トレードの自動化は、MetaQuotesのプロダクトを使用している人にとって重要な側面です。 コード内のトレード環境を排除すると、ほとんどの戦略は主に不等号の選択を暗示している(チャート上の価格とインジケータの間にあることが多い)か、インジケータの値とそのレンジを使ってエントリー(ポジション・オープニング)とエグジットの判断をしていることになります。
ほとんどすべてのトレード戦略開発者がこれまでに経験したことのある洞察力が、より多くのトレード条件や新たな不平等につながっています。 このような各追加は、一定の時間間隔で業績に変化をもたらします。 しかし、別の時間間隔、時間枠、またはトレードツールは、失望の結果を招くことがあります。トレードシステムは、もはや効率的ではなく、トレーダーは、新しいパターンと条件を探索する必要があります。 さらに、各新規条件を追加することで、トレード数を減らすことができます。
探索プロセスは、通常、トレードの意思決定に使用する不等式の最適化に続いて行われます。 最適化処理では、初期データ値を超えていることが多く、多くのパラメータをチェックします。 別のケースとしては、パラメータ最適化によって生成された不等式の値が、バランス曲線や他の最適化可能なパラメータを改善する可能性があるにも関わらず、発見されたパターンではなく、統計的な偏差とみなすことができるほど稀に現れる場合があります。 その結果、最適化は、利用可能な相場データにトレード戦略で実装されたヒューリスティックなアイデアのオーバーフィットにつながります。 このようなアプローチは、多数の変数とその値の使用を意味する場合、最適解の探索に費やす計算リソースの点で効率的ではありません。
機械学習法は、分析データ上に存在するパラメータ値のみをチェックする不等式ルールを生成することで、パラメータの最適化やパターン検索のプロセスを高速化することができます。 モデルの作成方法が異なると、異なるアプローチを使用することになります。 しかし、一般的には、トレーニングに利用可能なデータでソリューション検索を制限するという考え方が一般的です。 機械学習では、売買判断ロジックの原因となる不等式を作るのではなく、価格と価格形成に影響を与える要因に関する情報を含む変数の値のみを提供します。 このようなデータは、特徴量(または予測値)と呼ばれています。
特徴量は、ポーリングによって得たい結果に影響を与えなければなりません。 結果は通常、数値で表現されます:分類のクラス番号や回帰の設定点の値になります。 そのような結果がターゲット変数となります。 学習法の中には、例えばクラスタリング法のように、ターゲット変数を持たないものもありますが、この記事では扱いません。
よって、予測変数と目標変数が必要なのです。
予測変数
予測には、時間を使用することができます。トレードツールとそのデリバティブのOHLC価格は、様々な指標です。 また、経済インジケータ、トレード量、建玉、オーダーブックパターン、オプション・ストライク・グリークスなど、相場に影響を与える他のデータソースなどの予測を使用することも可能です。 今の瞬間に形成された情報に加えて、今の瞬間につながる動きを記述した情報をモデルが受け取るべきだと思います。 厳密に言えば、予測は一定期間の値動きに関する情報を提供しなければなりません。
記述するタイプの予測因子を決定します。
- 可能性のある有意なレベル。
- 水平(トレード所の始値など)
- 線形(例えば、回帰チャネル)
- ブロークン(非線形関数、例えば移動平均などで計算されたもの)
- 価格とレベルの位置。
- ポイントで固定された範囲内
- 割合として一定の範囲:
- 日の始値や水準を基準にした相対性
- ボラティリティ・レベルとの相対的な関係
- 異なるTFのトレンドセグメントとの相対的な関係
- 価格変動(ボラティリティ)の描写
- イベント時間の情報。
- 重要なイベントの開始から経過した小節の数(現在の小節から、または日などの別の期間の開始から)
- 重要なイベントの終了から経過した小節の数(現在の小節から、または日などの別の期間の開始から)
- イベントの開始と終了から経過した足の数で、イベントの持続時間を示します。
- 現在の時刻を時間番号、曜日、10年または月の番号、その他の番号で表示します。
- イベントダイナミクスに関する情報を掲載します。
- 有意レベルのクロス点の数(減衰・繰り返し回数を考慮した計算を含む)。
- 最初/直近のイベントの瞬間の最高/最安値(相対価格)
- 時間単位でのポイント数でのイベント速度
- OHLCデータの他の座標平面への変換
- オシレータ型インジケータの値。
予測については、異なるタイムフレームやトレードに使用するものに関連するトレードツールから情報を取ることができます。 もちろん、情報提供の方法はもっとたくさん考えられます。 唯一の推奨事項は、トレード商品の主要な価格ダイナミクスを再現するのに十分なデータを提供することです。 予測変数を一度用意しておけば、さらに様々な用途に活用できます。 これより、基本的なトレード戦略の条件に応じて動作するモデルの検索が大幅に簡素化されます。
ターゲット
今回は、2値分類対象です。つまり 、 0と1です。 この選択は、後述する制限に由来します。 では、0と1は何を表すことができるのでしょうか? 2つのバリアントがあります。
- 最初のバリアント: "1" - ポジションを開く (または別のアクションを実行する) と "0" - ポジションを開かない (または別のアクションを実行しない)。
- 2番目のバリアント: "1" - 買いポジション(最初のアクション)と "0" - 売りポジション(2番目のアクション)をオープンします。
目標変数シグナルを生成するために、機械学習の十分な数のシグナルを生成することを条件に、シンプルな基本戦略を使用することができます。
- 買いまたは売りの価格レベルがクロスしたときにポジションを開く(どのインジケータでもレベルとして機能します)。
- 現在の日中の始値に対する価格の相対的な位置に応じて、時間の初めからN足のポジションをオープンするか、オープンを無視するかを選択します。
より良い学習を促進するので、ほぼ同じような数のゼロと1の生成を可能にする基本的な戦略を見つけるようにしてください。
機械学習ソフトウェア
このリンクでダウンロードできるCatBoostソフトを使って機械学習を行います。 この記事では、他のプログラミング言語を必要としない独立したバージョンを作成することを目的としており、最新バージョンのexeファイルをダウンロードする必要があります。例えばcatboost-0.24.1.exeです。
CatBoostは、よく知られたYandex社のオープンソースの機械学習アルゴリズムです。 そのため、関連するプロダクトサポート、改善、バグフィックスが期待できます。
Yandex ここでプレゼンテーションを見ることができます(プレゼンテーションはロシア語なので英語字幕を有効にしてください)。
要するに、CatBoost は、トレーリングの各ツリーが前のツリーのすべての確率応答の合計値を改善するような方法で、決定ツリーのアンサンブルを構築します。 これをグラデーションブーストといいます。
機械学習のデータの準備
予測変数と対象変数を含むデータをサンプルと呼びます。 列として予測変数の列挙を含むデータ配列で,各行はその時点での予測変数の値を示す測定モーメントです。 文字列に記録された測定値は、特定の時間間隔で得られてもよいし、様々なオブジェクト、例えば画像を表すこともできます。 通常、ファイルはCSV形式で、カラムの値とヘッダ(オプション)には条件分離器 を使用します。
この例では、以下のような予測変数を使用してみましょう。
- 時間/時/時の端数/曜日
- バーの相対ポジション
- オシレーター
ターゲット変数はMAのクロスにあるシグナルで、次の足では手付かずのままです。 価格がMAの上にある場合は買いです。 価格がMAを下回っている場合は、売りです。 シグナルが到着するたびに、既存のポジションを閉じる必要があります。 ターゲット変数は、ポジションを建てるかどうかを表示します。
スクリプトを使ってターゲット変数と予測変数を生成するのはお勧めしません。 代わりにエキスパートアドバイザを使用すると、サンプルを生成する際にコード内の論理エラーを検出したり、データ到着の詳細なシミュレーションを行うことができます。これは、実際のトレードでデータが到着する方法に似ています。 さらに、対象変数が異なるシンボルで動作する場合には、異なる商品の異なる開始時間を考慮することができるようになりますし、データの受信と処理の遅延を考慮するだけでなく、アルゴリズムが未来を見ないようにするために、インジケータのリペイントやトレーニングに適していないロジックをキャッチするために、考慮することができます。 その結果、実際にモデルを適用した場合、予測変数はリアルタイムでバー上で計算されることになります。
アルゴリズムトレーダーの中には、特に機械学習を使用している人もいますが、標準的なインジケータは遅れて価格から派生しているため、新しい情報を提供しないため、ほとんど役に立たないと言います。 確かに、ニューラルネットワークの可能性は大きいですが、多くの場合、ほとんどの普通のトレーダーが利用できない計算能力を必要とします。 さらに、このようなニューラルネットワークの学習には時間がかかります。 決定ツリーベースの機械学習法は、インプットデータを変換しないので、新しい数学的実体の生成においてニューラルネットワークに対抗することはできません。 しかし、特に大規模で異質なデータ配列において、直接的な依存関係を識別する必要がある場合には、ニューラルネットワークよりも効率的であると考えられています。 実際、ニューラルネットワークの目的は、新しいパターン、すなわち相場を記述するパラメータを生成することです。 判断ツリーベースのモデルは、そのようなパターンの集合の中からパターンを特定することを目的とします。 ターミナルから標準的なインジケータを予測器として使用することで、異なる国の異なるトレード所や店頭相場で何千人ものトレーダーが使用しているパターンを取ることができます。 したがって、最終的にトレードツールに影響を与えるインジケータ値にトレーダーの行動の反対依存性を識別できると仮定することができます。 オシレータは使ったことがないので、結果を見てみると面白そうです。
標準ターミナル配信から以下の表示を使用します。
- アクセラレーターオシレーター
- 平均方向運動指数(ADX)
- ウェルズ・ワイルダーの平均方向移動指数
- 真の平均範囲(ATR)
- ベアーパワー
- ブルパワー
- 商品チャネル指数(CCI)
- チャイキンオシレータ
- デマーカー
- フォースインデックス
- ゲーターオシレーター
- 相場円滑化指数
- モメンタム
- マネーフロー指数(MFI)
- オシレータの移動平均
- 移動平均線 収束・ダイバージェンス(MACD)
- 相対強度指数(RSI)
- 相対活力指数(RVI)
- 標準偏差
- ストキャスティクス
- 3倍指数移動平均線オシレータ
- ウィリアムズのパーセンテージレンジ
- 変数指数 ダイナミック平均
- ボリューム
インジケータは、MetaTrader5で利用可能なすべての時間枠(1日枠まで)で計算されます。
この記事を書いているときに、以下のインジケータの値がターミナルのテスト開始日に強く依存していることがわかりましたので、除外することにしました。 インジケータに異なる足の値の差を使用することは可能ですが、この記事の範囲を超えています。
除外されたインジケータのリスト。
- オーサムオシレータ
- オンバランスボリューム
- アキュムレーション/ディストリビューション
CSV テーブルを扱うには、Aliaksandr Hryshynによる素晴らしいライブラリ CSV fast.mqh を使います。 ライブラリの特徴。
- 表の作成、ファイルからの読み込み、ファイルへの保存を行います。
- セルアドレスに基づいて、任意のテーブルセルに情報を読み書きします。
- テーブルの列は、異なるデータタイプを格納できるので、RAMの消費を節約できます。
- テーブルセクションは、指定されたアドレスから別のテーブルの指定されたアドレスに全体をコピーすることができます。
- 任意のテーブル列によるフィルタリングが可能です
- 列セルで指定された値に応じて、降順と昇順の複数レベルのソートが可能です
- 列の再インデックス化と非表示を可能にします。
- 他にも便利で使い勝手の良い関数がたくさんあります。
EAのコンポーネント
基本的な戦略。
シグナルを発生させる基本的なストラテジーとして、シンプルな条件のストラテジーを使うことにしました。 これによると、以下の条件を満たした場合に相場参入を行う必要があります。
- 価格移動平均線を超えた。
- 条件1を満たした後、初めてのときの価格は、前回の足でクロスしたMAには触れなかった。
これは私が00年代前半に作った最初の戦略です。 トレンドクラスに属するシンプルなストラテジーです。 適切なトレードヒストリーでは良好な結果を示します。 機械学習を利用して、フラット部のダマシエントリーを減らしてみましょう。
シグナルジェネレーターは以下のようになっています。
//+-----------------------------------------------------------------+ //| Returns a buy or Sell signal - basic strategy | //+-----------------------------------------------------------------+ bool Signal() { // Reset position opening blocking flag SellPrIMA=false; // Open a pending sell order BuyPrIMA=false; // Open a pending buy order SellNow=false; // Open a market sell order BuyNow=false; // Open a market buy order bool Signal=false;// Function operation result int BarN=0; // The number of bars on which MA is not touched if(iOpen(Symbol(),Signal_MA_TF,0)>MA_Signal(0) && iLow(Symbol(),Signal_MA_TF,1)>MA_Signal(1)) { for(int i=2; i<100; i++) { if(iLow(Symbol(),Signal_MA_TF,i)>MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)<MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)>=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x))break;// Signal has already been processed on this cycle if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x)) { BarN=x; BuyNow=true; break; } } } } } if(iOpen(Symbol(),Signal_MA_TF,0)<MA_Signal(0) && iHigh(Symbol(),Signal_MA_TF,1)<MA_Signal(1)) { for(int i=2; i<100; i++) { if(iHigh(Symbol(),Signal_MA_TF,i)<MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)>MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)<=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x))break;// Signal has already been processed on this cycle if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x)) { BarN=x; SellNow=true; break; } } } } } if(BuyNow==true || SellNow==true)Signal=true; return Signal; }
予測値の取得
予測値は関数を使って取得します(そのコードは以下に添付します)。 しかし、多くのインジケータに対してできる方法を紹介します。 インジケータのシグナルレベルを決定することができる第1および第2の形成された足、および15のシフトを持つ足 - インジケータの動きのダイナミクスを理解することができます。3点でインジケータの値を使用します。 もちろん、情報の入手方法を簡略化したものであり、大幅に拡大することができます。
すべての予測変数は、コンピュータの RAM に形成されたテーブルに書き込まれます。このテーブルは1行で、後でCatBoostモデルインタプリタへのインプット数値データベクトルとして使用します。
#include "CSV fast.mqh"; // Class for working with tables CSV *csv_CB=new CSV(); // Create a table class instance, in which current predictor values will be stored //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CB_Tabl();// Creating a table with predictors return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Create a table with predictors | //+------------------------------------------------------------------+ void CB_Tabl() { //--- Columns for oscillators Size_arr_Buf_OSC=ArraySize(arr_Buf_OSC); Size_arr_Name_OSC=ArraySize(arr_Name_OSC); Size_TF_OSC=ArraySize(arr_TF_OSC); for(int n=0; n<Size_arr_Buf_OSC; n++)SummBuf_OSC=SummBuf_OSC+arr_Buf_OSC[n]; Size_OSC=3*Size_TF_OSC*SummBuf_OSC; for(int S=0; S<3; S++)// Loop by the number of shifts { string Shift="0"; if(S==0)Shift="1"; if(S==1)Shift="2"; if(S==2)Shift="15"; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { name_P=arr_Name_OSC[o]+"_B"+IntegerToString(b,0)+"_S"+Shift+"_"+arr_TF_OSC[T]; csv_CB.Add_column(dt_double,name_P);// Add a new column with a name to identify a predictor } } } } } //+------------------------------------------------------------------+ //--- Call predictor calculation //+------------------------------------------------------------------+ void Pred_Calc() { //--- Get information from oscillator indicators double arr_OSC[]; iOSC_Calc(arr_OSC); for(int p=0; p<Size_OSC; p++) { csv_CB.Set_value(0,s(),arr_OSC[p],false); } } //+------------------------------------------------------------------+ //| Get values of oscillator indicators | //+------------------------------------------------------------------+ void iOSC_Calc(double &arr_OSC[]) { ArrayResize(arr_OSC,Size_OSC); int n=0;// Indicator handle index int x=0;// Total number of iterations for(int S=0; S<3; S++)// Loop by the number of shifts { n=0; int Shift=0; if(S==0)Shift=1; if(S==1)Shift=2; if(S==2)Shift=15; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { arr_OSC[x++]=iOSC(n, b,Shift); } n++;// Mark shift to the next indicator handle for calculation } } } } //+------------------------------------------------------------------+ //| Get the value of the indicator buffer | //+------------------------------------------------------------------+ double iOSC(int OSC, int Bufer,int index) { double MA[1]= {0.0}; int handle_ind=arr_Handle[OSC];// Indicator handle ResetLastError(); if(CopyBuffer(handle_ind,0,index,1,MA)<0) { PrintFormat("Failed to copy data from the OSC indicator, error code %d",GetLastError()); return(0.0); } return (MA[0]); }
サンプルの蓄積とマーキング。
サンプルを作成して保存するには、csv_CBテーブルからcsv_Arhivテーブルにコピーして予測値を蓄積します。
前回のシグナルの日付を読み取り、トレードのインプットとエグジットの価格を決定し、結果を定義し、応じて適切なラベルが割り当てられます。"1" - 正、"0" - 負。 シグナルで行われたトレードの種類もマークしておきましょう。 これにより、さらにバランスチャートを構築することができます。"1" - 買いと "-1" - 売り。 また、ここではトレードの結果を計算してみましょう。 買いと売りの結果を持つ別の列は、結果に使用します:基本的な戦略がより困難であるか、または結果に影響を与える可能性があるポジション管理の要素がある場合に便利です。
//+-----------------------------------------------------------------+ //| The function copies predictors to archive | //+-----------------------------------------------------------------+ void Copy_Arhiv() { int Strok_Arhiv=csv_Arhiv.Get_lines_count();// Number of rows in the table int Stroka_Load=0;// Starting row in the source table int Stolb_Load=1;// Starting column in the source table int Stroka_Save=0;// Starting row to write in the table int Stolb_Save=1;// Starting column to write in the table int TotalCopy_Strok=-1;// Number of rows to copy from the source. -1 copy to the last row int TotalCopy_Stolb=-1;// Number of columns to copy from the source, if -1 copy to the last column Stroka_Save=Strok_Arhiv;// Copy the last row csv_Arhiv.Copy_from(csv_CB,Stroka_Load,Stolb_Load,TotalCopy_Strok,TotalCopy_Stolb,Stroka_Save,Stolb_Save,false,false,false);// Copying function //--- Calculate the financial result and set the target label, if it is not the first market entry int Stolb_Time=csv_Arhiv.Get_column_position("Time",false);// Find out the index of the "Time" column int Vektor_P=0;// Specify entry direction: "+1" - buy, "-1" - sell if(BuyNow==true)Vektor_P=1;// Buy entry else Vektor_P=-1;// Sell entry csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+1,Vektor_P,false); if(Strok_Arhiv>0) { int Stolb_Target_P=csv_Arhiv.Get_column_position("Target_P",false);// Find out the index of the "Time" column int Load_Vektor_P=csv_Arhiv.Get_int(Strok_Arhiv-1,Stolb_Target_P,false);// Find out the previous operation type datetime Load_Data_Start=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv-1,Stolb_Time,false));// Read the position opening date datetime Load_Data_Stop=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv,Stolb_Time,false));// Read the position closing date double F_Rez_Buy=0.0;// Financial result in case of a buy operation double F_Rez_Sell=0.0;// Financial result in case of a sell operation double P_Open=0.0;// Position open price double P_Close=0.0;// Position close price int Metka=0;// Label for target variable P_Open=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Start,false)); P_Close=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Stop,false)); F_Rez_Buy=P_Close-P_Open;// Previous entry was buying F_Rez_Sell=P_Open-P_Close;// Previous entry was selling if((F_Rez_Buy-comission*Point()>0 && Load_Vektor_P>0) || (F_Rez_Sell-comission*Point()>0 && Load_Vektor_P<0))Metka=1; else Metka=0; csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+2,Metka,false);// Write label to a cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+3,F_Rez_Buy,false);// Write the financial result of a conditional buy operation to the cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+4,F_Rez_Sell,false);// Write the financial result of a conditional sell operation to the cell csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+2,-1,false);// Add a negative label to the labels to control labels } }
モデルを使用
ここでダウンロードできるAliaksandr Hryshynの "Catboost.mqh" クラスを使って、CatBoost モデルを使用して受信したデータを解釈してみましょう。
デバッグ用に「csv_Chek」というテーブルを追加して、必要に応じてCatBoostモデルの値を保存するようにしました。
//+-----------------------------------------------------------------+ //| The function applies predictors in the CatBoost model | //+-----------------------------------------------------------------+ void Model_CB() { CB_Siganl=1; csv_CB.Get_array_from_row(0,1,Solb_Copy_CB,features); double model_result=Catboost::ApplyCatboostModel(features,TreeDepth,TreeSplits,BorderCounts,Borders,LeafValues); double result=Logistic(model_result); if (result<Porog || result>Pridel) { BuyNow=false; SellNow=false; CB_Siganl=0; } if(Use_Save_Result==true) { int str=csv_Chek.Add_line(); csv_Chek.Set_value(str,1,TimeToString(iTime(Symbol(),PERIOD_CURRENT,0),TIME_DATE|TIME_MINUTES)); csv_Chek.Set_value(str,2,result); } }
選択範囲をファイルに保存します。
テストパスの最後にテーブルを保存し、小数点以下の区切り文字をカンマで指定します。
//+------------------------------------------------------------------+ // Function writing predictors to a file | //+------------------------------------------------------------------+ void Save_Pred_All() { //--- Save predictors to a file if(Save_Pred==true) { int Stolb_Target=csv_Arhiv.Get_column_position("Target_100",false);// Find out the index of the Target_100 column csv_Arhiv.Filter_rows_add(Stolb_Target,op_neq,-1,true);// Exclude lines with label "-1" in target variable csv_Arhiv.Filter_rows_apply(true);// Apply filter csv_Arhiv.decimal_separator=',';// Set a decimal separator string name=Symbol()+"CB_Save_Pred.csv";// File name csv_Arhiv.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save the file up to 5 characters } //--- Save the model values to a debug file if(Use_Save_Result==true) { csv_Chek.decimal_separator=',';// Set a decimal separator string name=Symbol()+"Chek.csv";// File name csv_Chek.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save file up to 5 decimal places } }
ストラテジー設定のカスタム品質スコア
次に、基本モデルで使用するインジケータの適切な設定を見つける必要があります。 そこで、トレードの最小値を決定し、利益の出るトレードの割合を返すストラテジーテスターの値を計算してみましょう。 より多くのオブジェクトがトレーニング(トレード)に利用可能であればあるほど、サンプルはより良いバランスのとれたものになります(50%に利益のあるトレードの割合を閉じる)。 カスタム変数は以下の関数で計算します。
//+------------------------------------------------------------------+ //| Custom variable calculating function | //+------------------------------------------------------------------+ double CustomPokazatelf(int VariantPokazatel) { double custom_Pokazatel=0.0; if(VariantPokazatel==1) { double Total_Tr=(double)TesterStatistics(STAT_TRADES); double Pr_Tr=(double)TesterStatistics(STAT_PROFIT_TRADES); if(Total_Tr>0 && Total_Tr>15000)custom_Pokazatel=Pr_Tr/Total_Tr*100.0; } return(custom_Pokazatel); }
メインコード部の実行頻度を制御します。
トレードの判断は、新足のオープン時に発生させる必要があります。 以下の関数で確認します。
//+-----------------------------------------------------------------+ //| Returns TRUE if a new bar has appeared on the current TF | //+-----------------------------------------------------------------+ bool isNewBar() { datetime tm[]; static datetime prevBarTime=0; if(CopyTime(Symbol(),Signal_MA_TF,0,1,tm)<0) { Print("%s CopyTime error = %d",__FUNCTION__,GetLastError()); } else { if(prevBarTime!=tm[0]) { prevBarTime=tm[0]; return true; } return false; } return true; }
トレーディング関数:
このEAは、トレードクラス「cPoza6」を使用します。 このアイデアは私が開発し、主な実装はVasiliy Pushkaryovが提供しました。 以前、モスクワトレード所のクラスをテストしましたが、そのコンセプトが完全に実装されていませんでした。 そのため、ヒストリーを扱うための関数が必要です。 今回の記事では、口座型チェックを無効にしてみました。 なので、気をつけてください。 このクラスは元々ネッティングアカウント用に開発されたものですが、今回のEAではその運用で十分で、読者はこの記事の中で機械学習を学ぶことができます。
ここでは、関数の記述がないエキスパートアドバイザのコードを示します(わかりやすくするために)。
補助関数を含まず、上記の関数の記述を削除すると、このステップではEAコードは以下のようになります。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Check the correctness of model response interpretation values if(Porog>=Pridel || Pridel<=Porog)return(INIT_PARAMETERS_INCORRECT); if(Use_Pred_Calc==true) { if(Init_Pred()==INIT_FAILED)return(INIT_FAILED);// Initialize indicator handles CB_Tabl();// Creating a table with predictors Solb_Copy_CB=csv_CB.Get_columns_count()-3;// Number of columns in the predictor table } // Declare handle_MA_Slow handle_MA_Signal=iMA(Symbol(),Signal_MA_TF,Signal_MA_Period,1,Signal_MA_Metod,Signal_MA_Price); if(handle_MA_Signal==INVALID_HANDLE) { PrintFormat("Failed to create handle of the handle_MA_Signal indicator for the symbol %s/%s, error code %d", Symbol(),EnumToString(Period()),GetLastError()); return(INIT_FAILED); } //--- Create a table to write model values - for debugging purposes if(Use_Save_Result==true) { csv_Chek.Add_column(dt_string,"Data"); csv_Chek.Add_column(dt_double,"Rez"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(Save_Pred==true)Save_Pred_All();// Call a function to write predictors to a file delete csv_CB;// Delete the class instance delete csv_Arhiv;// Delete the class instance delete csv_Chek;// Delete the class instance } //+------------------------------------------------------------------+ //| Test completion event handler | //+------------------------------------------------------------------+ double OnTester() { return(CustomPokazatelf(1)); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Operations are only executed when the next bar appears if(!isNewBar()) return; //--- Get information on trading environment (deals/orders) OpenOrdersInfo(); //--- Get signal from the basic strategy if(Signal()==true) { //--- Calculate predictors if(Use_Pred_Calc==true)Pred_Calc(); //---Apply the CatBoost model if(Use_Model_CB==true)Model_CB(); //--- If there is an open position at the signal generation time, close it if(PosType!="0")ClosePositions("Close Signal"); //--- Open a new position if (BuyNow==true)OpenPositions(BUY,1,0,0,"Open_Buy"); if (SellNow==true)OpenPositions(SELL,1,0,0,"Open_Sell"); //--- Copy the table with the current predictors to the archive table if(Save_Pred==true)Copy_Arhiv(); } }
外部EAの設定。
さて、ここまでEAの関数コードを考えてきましたが、EAがどのような設定をしているのか見てみましょう。
1. 予測子を使ってアクションを設定します。
- "Calculate predictors" - 選択範囲を保存するか、CatBoostモデルを適用したい場合は "true "に設定します。
- "Save predictors" — さらなる学習のために予測変数をファイルに保存したい場合は、"true "にセットする。;
- "Volume type in indicators" - ボリュームタイプに設定。
- "Show predictor indicators on a chart" - インジケータを可視化したい場合はtrueに設定します。
- "Commission and spread in points to calculate target" - ターゲットラベルのコミッションとスプレッドを考慮に入れたり、マイナーなポジティブトレードをフィルタリングしたりするために使用します。
2. 基本的なストラテジーシグナルのMAインジケータのパラメータです。
- "Period";
- "Timeframe";
- "MA methods";
- "Calculation price";
3. CatBoostモデルのアプリケーションパラメータ。
- "Apply CatBoost model on data" - トレーニングしたモデルでエキスパートアドバイザをコンパイルした後、"true "に設定することができます。
- "Threshold for classifying one by the model" - モデル値が1と解釈される閾値。
- "Limit for classifying one by the model" - モデル値が1と解釈されるリミット。
- "Save model value to file" - モデルの正しさを確認するためにファイルを取得したい場合は "true "に設定します。
正しい基本戦略の設定を見つける
さて、 基本的な戦略インジケータを最適化してみましょう。 ストラテジー設定の質を評価するためのカスタム基準を選択してください。 M1の時間枠で、01.06.2014と31.10.2020の間の時間範囲でOtkritie Broker(シンボルは「Si Splice」と呼ばれています)からスプライスされたUSDRUB_TOM Si先物取引を使用してテストを行いました。 テストモード:M1 OHLCシミュレーション。
EAの最適化パラメータ:
- "Period":8から256まで、8段階
- "Timeframe": M1からD1,ノーステップ;
- "MA methods":SMAからLWMAまで、ステップなし;。
- "Calculation price":CLOSEからWEIGHTEDへ。

図1 「最適化結果」
これらの結果から、カスタムパラメータ-好ましくは35%以上、トレード数15000以上(多ければ多いほど良い)の値を選択する必要があります。 オプションで、他のエコノメトリック変数を分析することができます。
機械学習を利用したトレード戦略の作成の可能性を実証するために、以下のセットを用意しました。
- "Period": 8;
- "Timeframe": 2 分;
- "MA methods ":線形加重;
- "Calculation price":高値。
1回のテストを実行して、結果のチャートを確認します。

図2 "ラーニング前のバランス"
このようなストラテジーの設定は、トレードではほとんど使えません。 このシグナルはノイズが多く、誤りとなるエントリーが多いです。 それらを排除してみましょう。 シグナルをフィルタリングするために様々なインジケータの複数のパラメータをテストし、その結果、インジケータ値が存在しないか、または稀に(統計的に重要ではない)インジケータ値が存在する領域で余分な計算能力を費やす人とは異なり、インジケータ値が実際に情報を提供した領域でのみタスクを行います。
EAの設定を変更して計算し、予測値を保存しておきましょう。 その後、単一のテストを実行します。
予測子を使ってアクションを設定します。
- "Calculate predictors" - "true "に設定。
- "Save predictors" - "true "に設定。
- "Volume type in indicators" - ボリュームタイプに設定。
- "Show predictor indicators on a chart" - "false "を使用します。
- "Commission and spread in points to calculate target" - 50に設定します。
その他の設定はそのままにしておきます。 ストラテジーテスターで1つのテストを実行してみましょう。 現在では、約2000個のインジケータバッファのデータを計算して収集しているため、計算はよりゆっくりと行われています。
エージェントの実行パスでファイルを検索 (私の場合は、ポータブルモードを使用しているので、"F:\FX\Otkritie Broker_Demo\Tester\Agent-127.0.0.1-3002\MQL5\Files", " 3002")は、エージェントの動作に使用するスレッドを意味します。 テーブルを含むファイルが正常に開かれれば、すべてが正常です。
図3「予測値表の概要」
サンプルの分割
さらなるトレーニングに、サンプルを3つの部分に分割してファイルに保存します。
- train.csv - トレーニングに使用するサンプル.
- test.csv - 学習結果を制御するために利用されるサンプル.
- exam.csv - トレーニング結果を評価するサンプル.
サンプルを分割するには、スクリプトCB_CSV_to3x.mq5を使用します。
トレーディングモデルの作成を行うディレクトリへのパスと、サンプルを含むファイル名を指定します。
もう一つ作成されたファイルはTest_CB_Setup_0_000000000で、0から始まる列のインデックスを指定します。 今回のサンプルのファイルの内容は以下の通りです。
2408 Auxiliary 2409 Auxiliary 2410 Label 2411 Auxiliary 2412 Auxiliary
スクリプトで用意したサンプルがある場所にファイルを配置します。
CatBoostパラメータ
CatBoostには、トレーニング結果に影響を与える様々なパラメータや設定があります。 ここでは、モデル学習結果に大きな影響を与え、CB_Batスクリプトで設定できる主なパラメータ(もしあればキー)について言及します。
- "Project directory" - Setup "サンプルが置かれているディレクトリへのパスを指定します。
- "CatBoost exe file name" - バージョンcatboost-0.24.1.1.exeを使用します。
- "Boosting type (Model boosting scheme)" - の2つのブーストオプションが選択されています。
- Ordered - 小スケールデータセットの品質は向上していますが、速度はスローかもしれません。
- Plain — 古典的なグラデーションブーストスキーム。
- "Tree depth" (深さ) - 対称的な決定ツリーの深さ, 開発者は6から10の間の値を推奨します。
- "Maximum iterations (trees)" - 機械学習の問題を解く際に構築できるツリーの最大数であり、学習後のツリーの数はこれよりも少なくてもよいです。 テストまたは検証サンプルでモデルの改善が見られない場合,学習率パラメータの変化に比例して繰り返し回数を変更すべきです。
- "Learning rate" - スロープステップ速度。すなわち、各決定ツリーを構築する際の一般化基準. 値が低いほどトレーニングは遅くなり、精度も高くなりますが、時間がかかり、繰り返し回数も多くなるので、「最大繰り返し回数(ツリー)」の変更を忘れないようにしましょう。
- "Method for automated calculation of target class weights" (class-weights) - このパラメータは,各クラスの例の数だけ不均衡なサンプルの学習を改善することができます. 3種類のバランスの取り方。
- None - すべてのクラスの加重が 1 に設定されます。
- Balanced - 総重量に基づくクラスの加重
- SqrtBalanced - 各クラスのオブジェクトの総数に基づくクラスの加重.
- "Method for selecting object weights" (ブートストラップ型) - このパラメータは,新しいツリーを構築するために予測子が検索されたときに,オブジェクトがどのように計算されるかを担当します. 以下のようなオプションがあります。
- Bayesian;
- Bernoulli;
- MVS;
- No;
- "Range of random weights for object selection" (bagging-temperature) - 予測子探索の対象物の計算にベイズ法を選択した場合に使用します。 このパラメータは、ツリーの予測変数を選択する際にランダム性を指定し、オーバーフィットを回避してパターンを見つけるのに役立ちます。 パラメータはゼロから無限大までの値を取ることができます。
- "Frequency to sample weights and objects when building trees" (サンプリング周波数) - ツリーを構築する際に予測変数の再評価の頻度を変更できるようにします。 サポートされている値。
- PerTree - 各新しいツリーを構築する前
- PerTreeLevel - ツリーの新しいスプリットを選択する前
- "Random subspace method (rsm) - 学習ステップ1=100%で分析された予測変数の割合. このパラメータを減少させると、学習プロセスが高速化され、ランダム性が追加されますが、最終モデルの繰り返し回数(ツリー)が増加します。
- "L2 regularization" (l2-leaf-reg) - 理論的には,このパラメータはオーバーフィッティングを減らすことができます.
- "The random seed used for training" (random-seed) - 通常,トレーニング開始時にランダムな加重係数を生成します。 私の経験では、このパラメータはモデルトレーニングに大きく影響します。
- "The amount of randomness to score the tree structure (ランダム強度" - このパラメータは、ツリーを作成する際のスリットスコアに影響を与え、モデルの品質を向上させるために最適化します。
- "Number of gradient steps to select a value from the list" (leaf-estimation-iterations) - ツリーがすでに建てられているときに葉をカウントします。 数歩先のスロープを数えることができます - このパラメータは、トレーニングの質と速度に影響を与えます。
- "The quantization mode for numerical features" (feature-border-type) - このパラメータは,サンプルオブジェクトの異なる量子化アルゴリズムに対応しています. このパラメータはモデルのトレーニング性に大きく影響します。 サポートされている値。
- Median,
- Uniform,
- UniformAndQuantiles,
- MaxLogSum,
- MinEntropy,
- GreedyLogSum,
- "The number of splits for numerical features" (ボーダーカウント) - このパラメータは,各予測変数の値範囲全体の分割数を担当します. 分割数は実際には少ないのが普通です。 パラメータが大きいほど分割が狭くなる→サンプルの割合が低くなる。 学習の種と品質に大きく影響します。
- "Save borders to a file" (output-border-file) - 量子化の境界線をファイルに保存して、その後のトレーニングで使用するための解析に使用できます。 モデルが作成されるたびにデータが保存されるため、学習速度に影響を与えます。
- "Error score metrics for learning correction" (loss-function) - モデルを学習する際にエラースコアを評価するために使用する関数. 結果に大きな影響を与えていることに気づいていません。 2つの選択肢があります。
- Logloss;
- CrossEntropy;
- "The number trees without improvements to stop training" (od-wait) - トレーニングがすぐに止まる場合は、待機数を増やすようにしてください。 また、学習速度が変化するときのパラメータを変更します:速度が低いほど、トレーニングを完了する前に改善を待つ時間が長くなります。
- "Error score metric function to training" (eval-metric) - リストからメトリックを選択することができます. サポートされているメトリクス。
- Logloss;
- CrossEntropy;
- Precision;
- Recall;
- F1;
- BalancedAccuracy;
- BalancedErrorRate;
- MCC;
- Accuracy;
- CtrFactor;
- NormalizedGini;
- BrierScore;
- HingeLoss;
- HammingLoss;
- ZeroOneLoss;
- Kappa;
- WKappa;
- LogLikelihoodOfPrediction;
- "Sample object" - 学習のモデルパラメータを選択することができます。 オプション:
- No
- Random-seed - トレーニングに使用する値
- Random-strength - ツリー構造を評価するためのランダム性の量
- Border-count - 分割数
- l2-Leaf-reg - L2 正規化
- Bagging-temperature - オブジェクトを選択するためのランダムな加重の範囲
- Leaf_estimation_iterations - リストから値を選択するためのスロープステップの数.
- "Initial variable value" - 学習開始集合
- "End variable value" - 学習終了集合
- "Step" - 値変更ステップ
- "Classification result presentation type"(prediction-type) - モデルの応答がどのように記述されるか - トレーニングには影響せず,サンプルでモデルを適用する際にトレーニング後に使用する.
- Probability
- Class
- RawFormulaVal
- Exponent
- LogProbability
- "The number of trees in the model, 0 - all" - 分類に使用するモデルのツリーの数を指定することで、モデルをサンプルに適用したときの分類品質の変化を評価することができます。
- "Model analysis method" (fstr-type) - 様々なモデル解析手法により、あるモデルの予測変数の有意性を評価することができます。 これらについての意見をお聞かせください。 サポートされているオプション。
- PredictionValuesChange - オブジェクトの値が変化したときに予測がどのように変化するか
- LossFunctionChange - オブジェクトが除外されたときに予測がどのように変化するか
- InternalFeatureImportance
- Interaction
- InternalInteraction
- ShapValues
このスクリプトでは、多くのモデル設定パラメータを検索することができます。 そのためには、NONE以外のオブジェクトを選択し、開始値、終了値、ステップを指定します。
学習戦略
学習戦略を3段階に分けて考えています。
- 基本的な設定は、モデル内のツリーの深さや数、学習率、クラス加重など、学習プロセスを開始するためのパラメータです。 パラメータは検索されません。ほとんどの場合、スクリプトによって生成されたデフォルトの設定で十分です。
- 最適な分割パラメータの検索 - CatBoostは、グリッドの境界に沿って値の範囲を検索するために予測変数テーブルを前処理するので、学習がより良いグリッドを見つける必要があります。 8~512の範囲ですべてのグリッドタイプを繰り返し処理するのは理にかなっています。
- 再びスクリプトを設定し、見つかった予測器の量子化グリッドを指定し、その後、さらなるパラメータに移動することができます。 普段は1~1000の範囲の「シード」しか使っていません。
この記事の、最初の「攻略法を学ぶ」段階では、CB_Batの初期設定を使用します。 分割方法は "MinEntropy "に設定され、グリッドは16のステップで16から512までのパラメータをテストします。
上記のパラメータを設定するために、学習モデルに必要なキーと補助ファイルを含むテキストファイルを作成する "CB_Bat "スクリプトを使用してみましょう。
- _00_Dir_All.txt - 補助ファイル
- _01_Train_All.txt - トレーニングの設定
- _02_Rezultat_Exam.txt - テストサンプルモデルによる分類を記録するための設定
- _02_Rezultat_test.txt - テストサンプルモデルによる分類を記録するための設定
- _02_Rezultat_Train.txt - 学習サンプルモデルによる分類を記録するための設定
- _03_Metrik_Exam.txt - テストサンプルモデルの各ツリーのメトリクスを記録するための設定
- _03_Metrik_Test.txt - テストサンプルモデルの各ツリーのメトリクスを記録するための設定
- _03_Metrik_Train.txt - 学習サンプルモデルの各ツリーのメトリクスを記録するための設定.
- _04_Analiz_Exam.txt - テストサンプルモデルの予測変数の重要度の評価を記録するための設定
- _04_Analiz_Test.txt - テストサンプルモデルの予測変数の重要度の評価を記録するための設定
- _04_Analiz_Train.txt - 学習サンプルモデルの予測器重要度の評価を記録するための設定
トレーニング後に順次アクションを実行するファイルを1つ作成することができます。 しかし、CPU使用率を最適化するために(CatBoostの初期バージョンでは特に重要だった)、トレーニング後に6つのファイルを起動します。
モデルトレーニング
ファイルの準備ができたら、"_00_Dir_All.txt "ファイルの名前を"_00_Dir_All.bat "に変更して実行してください。
これで、プロジェクトディレクトリには、以下の内容の "Setup "フォルダがあります。
- _00_Dir_All.bat - 補助ファイル
- _01_Train_All.bat - トレーニングの設定
- _02_Rezultat_Exam.bat - テストサンプルモデルによる分類を記録するための設定
- _02_Rezultat_test.bat - テストサンプルモデルによる分類を記録するための設定
- _02_Rezultat_Train.bat - 学習サンプルモデルによる分類を記録するための設定
- _03_Metrik_Exam.bat - テストサンプルモデルの各ツリーのメトリクスを記録するための設定
- _03_Metrik_Test.bat - テストサンプルモデルの各ツリーのメトリクスを記録するための設定
- _03_Metrik_Train.bat - 学習サンプルモデルの各ツリーのメトリクスを記録するための設定.
- _04_Analiz_Exam.bat - テストサンプルモデルの予測変数の重要度の評価を記録するための設定
- _04_Analiz_Test.bat - テストサンプルモデルの予測変数の重要度の評価を記録するための設定
- _04_Analiz_Train.bat - 学習サンプルモデルに対する予測変数の重要度の評価を記録するための設定
- catboost-0.24.1.exe - CatBoostモデルのトレーニング用実行ファイル
- train.csv - トレーニングに利用されるサンプル.
- test.csv - 学習結果を制御するために利用されるサンプル.
- exam.csv - 結果を評価するサンプル
- Test_CB_Setup_0_000000000/学習に使用したサンプルカラムの情報を持つファイル
「01_Train_All.bat」を実行して、トレーニングの様子を見てみましょう。
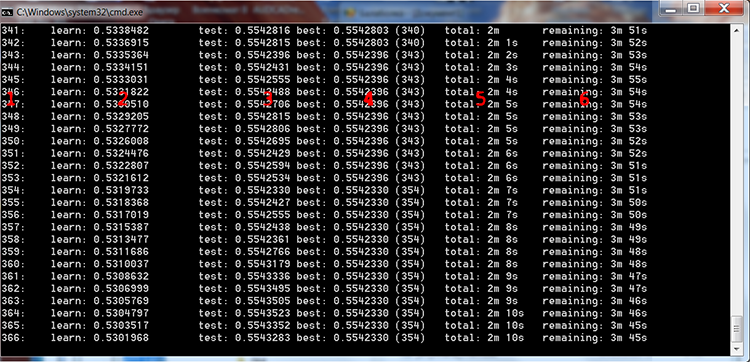
図4 CatBoostのトレーニングプロセス
上の図に赤い数字を入れて、列の説明をしてみました。
- 繰り返しの数に等しいツリーの数
- 選択された損失関数を学習サンプル上で計算した結果
- 選択された損失関数を制御サンプルに計算した結果
- 選択された損失関数をコントロールサンプル上で計算した最良の結果
- モデル学習を開始してからの実際の経過時間
- 設定で指定された全てのツリーがトレーニングされた場合のトレーニング終了までの残り時間の目安
スクリプトの設定で検索範囲を選択すると、ファイルの内容に応じて必要な回数だけループでモデルが学習されます。
FOR %%a IN (*.) DO ( catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 16 --feature-border-type MinEntropy --output-borders-file quant_4_00016.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type MinEntropy --output-borders-file quant_4_00032.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 48 --feature-border-type MinEntropy --output-borders-file quant_4_00048.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 64 --feature-border-type MinEntropy --output-borders-file quant_4_00064.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 80 --feature-border-type MinEntropy --output-borders-file quant_4_00080.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_96\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 96 --feature-border-type MinEntropy --output-borders-file quant_4_00096.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_112\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 112 --feature-border-type MinEntropy --output-borders-file quant_4_00112.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_128\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 128 --feature-border-type MinEntropy --output-borders-file quant_4_00128.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_144\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 144 --feature-border-type MinEntropy --output-borders-file quant_4_00144.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-DIr ..\Rezultat\RS_160\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 160 --feature-border-type MinEntropy --output-borders-file quant_4_00160.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
トレーニングが完了したら、残りの6つのバットファイルを一度に起動し、ラベルと統計値の形でトレーニング結果を得ます。
学習成果の明示的評価
CB_Calc_Svod.mq5スクリプトを使用して、モデルのメトリック変数とその財務結果を取得してみましょう。
このスクリプトには、テストサンプルの最終的なバランスでモデルを選択するためのフィルタがあります。バランスがある値よりも高ければ、サンプルからバランスチャートを作成し、サンプルをmqhに変換してCatBoostモデルプロジェクトの別のディレクトリに保存することができます。
スクリプトが完了するのを待ちます - この場合、新しく作成された "Analiz "にCB_Svod.csvファイルとモデル名によるバランスチャート(設定でプロットが選択されている場合)が表示され、さらにmqh形式に変換されたモデルを含む "Models_mqh "ディレクトリが表示されます。
CB_Svod.csvファイルには、各サンプルのモデルのメトリクスと結果があります。
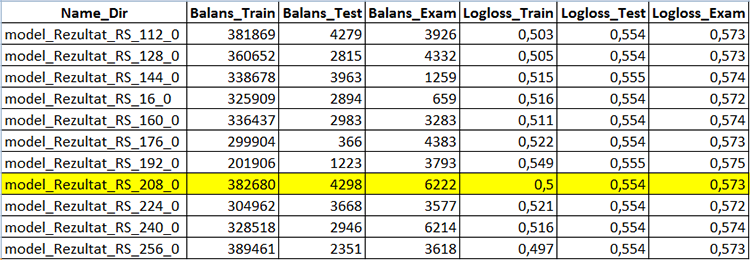
図5 モデル作成結果を格納したテーブルの一部 - CB_Svod.csv
モデルがトレーニングされたディレクトリの Models_mqh サブディレクトリから好きなモデルを選択し、エキスパートアドバイザ ディレクトリに追加します。 EAコードの先頭にある空のバッファのある行を「//」でコメントしてください。 あとはモデルファイルをEAに接続するだけです。
//If the CatBoost model is in an.mqh file, comment the below line //uint TreeDepth[];uint TreeSplits[];uint BorderCounts[];float Borders[];double LeafValues[];double Scale[];double Bias[]; #include "model_RS_208_0.mqh"; // Model file
エキスパートアドバイザをコンパイルした後、"Apply CatBoost model on data "の設定を "true "にし、サンプル保存を無効にして、以下のパラメータでStrategy Testerを実行します。
1. 予測子を使ってアクションを設定します。
- "Calculate predictors" - "true "に設定。
- "Save predictors" - "false "に設定
- "Volume type in indicators" - トレーニングで使用したボリュームタイプを設定します。
- "Show predictor indicators on a chart" - "false "を使用する
- "Commission and spread in points to calculate target" - 以前の値を使用して、準備ができているモデルには影響しません
2. 基本的なストラテジーシグナルのMAインジケータのパラメータです。
- "Period": 8;
- "Timeframe": 2 分;
- "MA methods ":線形加重;
- "Calculation price":高値。
3. CatBoostモデルのアプリケーションパラメータ。
- "Apply CatBoost model on data" - "true "に設定
- "Threshold for classifying one by the model" - 0.5のまま
- "Limit for classifying one by the model" - 1
- "Save model value to file" - "false "のまま
サンプル期間全体で以下の結果が得られました。
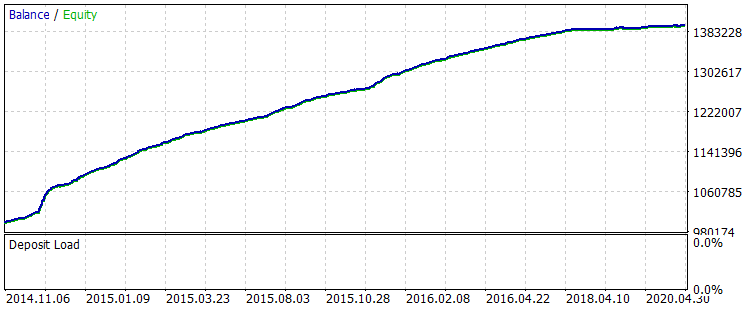
図6 トレーニング後の 2014.01.06.2014~2020.31.10.2020の期間のバランス
トレーニング期間外の区間2019.01.08.2019から31.10.2020までの2つのバランスチャートを比較してみましょう - トレーニング前とトレーニング後のexam.csvサンプルに対応します。
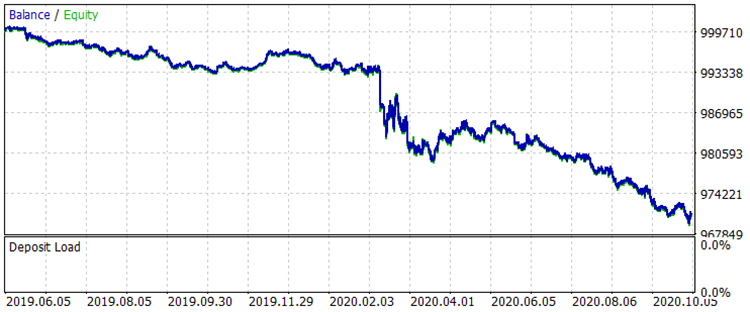
図7 期間中のトレーニング前のバランス2019年01月08日~2020年31月10日。
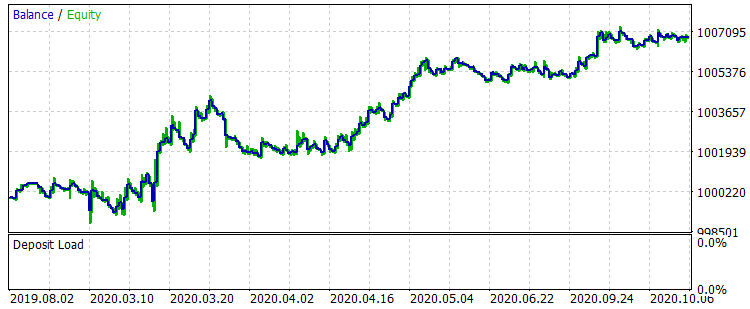
図8 期間中のトレーニング後のバランス01.08.2019~31.10.2020。
結果はあまり印象的ではありませんが、メインのトレードルールである「損切りを避ける」が観察されていることに注目しましょう。 CB_Svod.csvファイルから別のモデルを選択しても、得られた最も失敗したモデルの決算は-25ポイント、全モデルの平均決算は3889.9ポイントなので、効果はプラスになります。
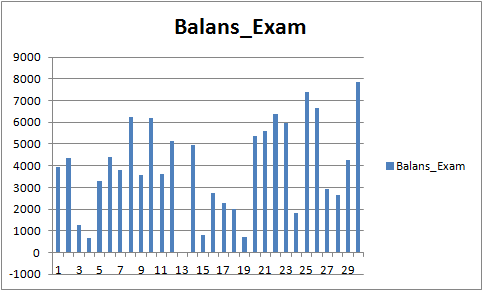
図9 学習したモデルの財務結果 期間 01.08.2019 - 31.10.2020
予測因子の分析
各モデルディレクトリ(私の場合はMQL5F\Files\CB_Stat_03p50Q\Rezultat\RS_208result_4_Test_CB_Setup_0_000000000)には、3つのファイルがあります。
- Analiz_Train - 学習サンプルでの予測変数の重要度の分析
- Analiz_Test - テスト(検証)サンプルでの予測変数の重要性の分析
- Analiz_Exam - テスト(トレーニング外)サンプルにおける予測因子の重要度の分析
学習用ファイル生成時に選択した「モデル解析方法」によって内容が異なります。 「PredictionValuesChange」で内容を見てみましょう。
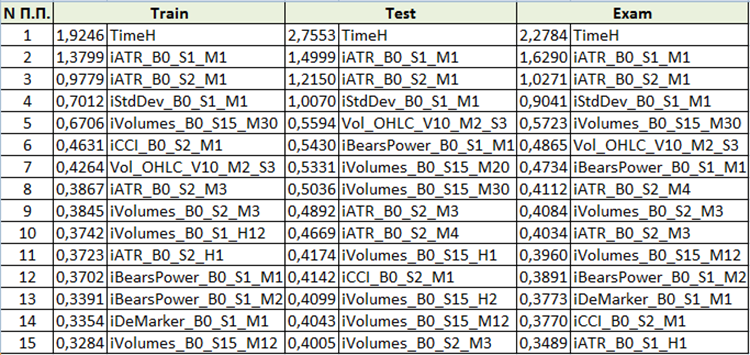
図10 予測変数の重要度分析のまとめ表
予測変数の重要性の評価に基づいて、最初の4つの予測変数が結果としてのモデルにとって一貫して重要であると結論づけることができます。 予測変数の重要性は、モデル自体だけでなく、元のサンプルにも依存することに注意してください。 このサンプルで予測変数が十分な値を持っていなかったのであれば、客観的に評価することはできません。 この方法では、予測器の重要性の一般的な考え方を理解することができます。 ただし、トレードシンボルをベースにしたサンプルを扱う場合は注意が必要です。
結論
- スロープブーストのような機械学習手法の有効性は、ストラテジーのパフォーマンスを向上させるために、パラメータの無限の繰り返しと、手動で追加のトレード条件を作成する場合と比較することができます。
- 標準的なMetaTrader5のインジケータは、機械学習を目的とした場合に便利です。
- CatBoost - ラッパを持つ高品質なライブラリで、PythonやRを学習することなくグラデーションブーストを効率的に利用できます。
結論
この記事の目的は、機械学習に注目してもらうことです。 詳細な方法論の記述と提供された再現ツールが、新たな機械学習ファンの出現につながることを心から願っています。 機械学習に関する新しいアイデア、特に予測因子の探索方法についての理想的なアイデアを見つけるために、団結しましょう。 モデルの品質はインプットデータとターゲットに依存しており、お互いの努力を合わせることで、より早く目的の結果を得ることができます。
記事やコードに含まれるエラーを報告していただくのは大歓迎です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/8657
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 外国為替取引の背後にある基本的な数学
外国為替取引の背後にある基本的な数学
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
もしこれを別のEAに適用するとしたら、注文を出す前にcatboostモデルを適用するだけで、他はすべてそのままにしておくのでしょうか。 それともmodel_CB()やcopy_arhiv()を修正する必要があるのでしょうか。 CBモデルが適用されているときは注文を開いていないようです。
Signal()関数で入力シグナルを追加または変更できます。
CatBoostモデルをトレーニングしましたか?
すべて正しく行ったのであれば、うまくいくはずです。
EAが反対のシグナルでポジションを閉じたり、減らしたり、反転させたりした場合、モデルを使ってそれらをフィルタリングしますか?それとも、単に新規注文が始まらないようにフィルタリングしますか?
EAが反対のシグナルでポジションを閉じたり、減らしたり、反転させたりした場合、モデルを使ってそれらをフィルタリングしますか?それとも、単に新規注文が始まらないようにフィルタリングしますか?
私はその考えが理解できませんでした:「モデルを使用してそれらをフィルタリングしたいのですか?
モデルの助けを借りて、ポジションを建てるためのシグナルは記事の中でフィルタリングされます。
私はその考えが理解できなかった:「モデルを使ってフィルタリングしたいのですか?
モデルの助けを借りて、ポジションを建てるためのシグナルは記事の中でフィルタリングされます。
もしEAに反対のシグナルがあれば、注文をクローズすることができます。 もしboostが理論的に偽のシグナルを減らすことができれば、反対のシグナルが注文をクローズすれば、catboostは偽の注文をクローズするのを減らし、その結果、注文をより長くオープンしたままにし、より大きな利益を達成することができます。 例えば、次のような場合です。MAがクロスしたときに注文を出す。ストップロスは50ピップス、TPは50。しかし、SLまたはTPを設定する前にMAがクロスし、EAは注文をクローズするようにプログラムされています。 このシグナルが誤報であった場合、TPまで上昇する可能性があったのに、利益を早くクローズしすぎたことになります。 では、catboostはそのような誤報の一定割合をフィルタリングできたのでしょうか?すべてのEAが反対シグナルでポジションを閉じるわけではありません。多くのEAはSlとTPが固定されているだけです。 だからこの質問をしたのです。 EAの中にはこのような機能を持つものがあるからです。
EAに反対シグナルがあれば、注文をクローズすることができます。 もしboostが理論的に偽シグナルを減らすことができれば、反対シグナルが注文をクローズすれば、catboostは偽の注文がクローズするのを減らし、その結果、注文をより長くオープンしたままにし、より大きな利益を達成することができます。 例えば。MAがクロスしたときに注文を出す。ストップロスは50ピップス、TPは50。しかし、SLまたはTPを設定する前にMAがクロスし、EAは注文をクローズするようにプログラムされています。 このシグナルが誤報であった場合、TPまで上昇する可能性があったのに、利益を早くクローズしすぎたことになります。 では、catboostはそのような誤報の一定割合をフィルタリングできたのでしょうか?すべてのEAが反対シグナルでポジションを閉じるわけではありません。多くのEAはSlとTPが固定されているだけです。 だからこの質問をしたのです。 EAの中にはこのような機能を持つものがあるからです。
会話の内容は理解できました。
プログラム的には実装は簡単ですが、ランダム性との勝負になります。実際、モデルのRecall指数はかなり低く、つまりモデルは全イベントの10%以上を認識しないため、正反対のポジションが未確認のパターンのためにオープンしないことが多いのです。これはとりわけ予測変数に関係している。この記事では、CatBoostモデルを実装するためのアルゴリズムを示す。予測子でモデルを強化することが必要であり、そうすればあなたの提案するアプローチはより正当化されるでしょう。