
Algoritmo de aprendizado de máquina CatBoost da Yandex sem conhecimento prévio de Python ou R

Prefácio
Este artigo considera como criar modelos que descrevam padrões de mercado com um conjunto limitado de variáveis e a hipótese sobre os padrões de comportamento, usando o algoritmo de aprendizado de máquina CatBoost da Yandex. Para obter o modelo, você não precisa de conhecimento prévio em Python ou R. Além disso, um conhecimento básico de MQL5 já é suficiente — este é exatamente o meu nível. Portanto, eu espero que o artigo sirva como um bom tutorial para um público amplo, auxiliando os interessados em avaliar os recursos de aprendizado de máquina e implementá-lo em seus programas. O artigo fornece pouco conhecimento acadêmico. Se você precisar de informações adicionais, leia a série de artigos de Vladimir Perervenko.
A diferença entre a abordagem clássica e o aprendizado de máquina na negociação
O conceito de Estratégia de Negociação é provavelmente familiar a todos os traders. Além disso, a automação de negociações é um aspecto importante para aqueles que têm a sorte de usar o produto da MetaQuotes. Se eliminarmos o ambiente de negociação no código, a maioria das estratégias implicará principalmente na seleção de desigualdades (na maioria das vezes entre o preço e um indicador no gráfico) ou usarmos os valores do indicador e seus intervalos para a tomada de decisões de entrada (abertura de posição) e saída.
Quase todo desenvolvedor de estratégias de negociação já teve "insights", que levam à adição de mais condições de negociação e novas desigualdades. Cada adição causa uma mudança nos resultados financeiros em um determinado intervalo de tempo. Mas outro intervalo de tempo, tempo gráfico ou instrumento de negociação pode mostrar resultados decepcionantes — o sistema de negociação não é mais eficiente e o trader tem que buscar por novos padrões e condições. Além disso, a adição de cada nova condição reduz o número de negócios.
O processo de busca é geralmente seguido pela otimização das desigualdades usadas para a tomada de decisões de negociação. O processo de otimização verifica uma série de parâmetros que geralmente estão além dos valores dos dados iniciais. Outro caso é quando os valores das desigualdades gerados pela otimização do parâmetro aparecem tão raramente que podem ser considerados um desvio estatístico em vez de um padrão encontrado, embora possam melhorar a curva de equilíbrio ou qualquer outro parâmetro otimizável. Como resultado, a otimização leva ao overfitting (sobreajuste) da ideia heurística implementada na estratégia de negociação com os dados de mercado disponíveis. Tal abordagem não é eficiente em termos de recursos computacionais gastos na busca de uma solução ótima, se a estratégia implica o uso de um grande número de variáveis e seus valores.
Os métodos de aprendizado de máquina podem acelerar a otimização dos parâmetros e os processos de busca de padrões, gerando regras de desigualdade para verificar apenas os valores dos parâmetros que existiam nos dados analisados. Diferentes métodos de criação de modelos usam diferentes abordagens. Porém, geralmente a ideia é limitar a busca de soluções pelos dados disponíveis para treinamento. Em vez de criar desigualdades responsáveis pela lógica de decisão de negociação, o aprendizado de máquina fornece apenas os valores das variáveis contendo informações sobre o preço e os fatores que influenciam na formação do preço. Esses dados são chamados de características (ou preditores).
As características devem influenciar o resultado que desejamos obter por meio de sua busca. O resultado é geralmente expresso como um valor numérico: pode ser um número de classe de classificação ou um ponto definido para regressão. Esse resultado é a variável alvo. Alguns métodos de treinamento não possuem uma variável alvo, como, por exemplo, os métodos de agrupamento, mas nós não trataremos deles neste artigo.
Portanto, nós precisamos de preditores e variáveis alvo.
Preditores
Para os preditores, você pode usar o tempo, o preço OHLC de um instrumento de negociação e seus derivados, ou seja, vários indicadores. Também é possível usar outros preditores, como indicadores econômicos, volume de negócios, contratos em aberto, padrões de book de ofertas, gregas e strike de opções e outras fontes de dados que afetam o mercado. Acredito que além das informações que se formaram pelo momento atual, o modelo deve receber as informações que descrevem o movimento que conduz ao momento atual. Estritamente falando, os preditores devem fornecer informações sobre o movimento dos preços durante um determinado período de tempo.
Eu determino alguns tipos de preditores que descrevem:
- Níveis significativos que podem ser:
- Horizontal (como um preço de abertura da sessão de negociação)
- Linear (por exemplo, um canal de regressão)
- Quebrado (calculado por uma função não linear, por exemplo, médias móveis)
- Preço e níveis de posição:
- Em uma faixa fixa de pontos
- Em uma faixa fixa como porcentagem:
- Em relação ao preço ou nível de abertura do dia
- Relativo ao nível de volatilidade
- Em relação aos segmentos de tendência de diferentes tempos gráficos
- Descrevendo as flutuações de preços (volatilidade)
- Informações sobre o horário do evento:
- O número de barras decorridas desde o início do evento significativo (da barra atual ou do início de um período diferente, como o dia)
- O número de barras que decorreram desde o final do evento significativo (da barra atual ou do início de um período diferente, como o dia)
- O número de barras que passaram desde o início e o fim do evento, que mostra a duração do evento
- A hora atual como número da hora, dia da semana, década ou número do mês, outro
- Informações sobre a dinâmica do evento:
- O número de interseções dos níveis significativos (isso inclui os cálculos levando em consideração a frequência de atenuação/repetição)
- O preço da máxima/mínima no momento do primeiro/último evento (o preço relativo)
- Velocidade do evento em pontos por unidade de tempo
- Convertendo os dados OHLC para outros planos de coordenadas
- Valores dos indicadores do tipo oscilador.
Para os preditores, nós podemos obter informações de diferentes tempos gráficos e instrumentos de negociação relacionados ao que será usado para negociação. Claro, existem muitos mais métodos possíveis para fornecer informações. A única recomendação é fornecer dados suficientes para reproduzir a principal dinâmica dos preços do instrumento de negociação. Uma vez preparado os preditores, você pode usá-los posteriormente para vários propósitos. Isso simplifica muito a busca por um modelo que funcione de acordo com as condições básicas da estratégia de negociação.
O alvo
Neste artigo, nós usaremos um alvo de classificação binária, ou seja, 0 e 1. Esta seleção decorre de uma limitação que será discutida posteriormente. Então, o que pode ser representado por zero e um? Tenho duas variantes:
- a primeira variante: "1" — abre uma posição (ou executa outra ação) e "0" — não abre uma posição (ou não executa outra ação);
- a segunda variante: "1" — abre uma posição de compra (primeira ação) e "0" — abre uma posição de venda (segunda ação).
Para gerar um sinal da variável alvo, nós podemos usar estratégias básicas simples, desde que produzam um número suficiente de sinais para o aprendizado de máquina:
- Abrimos uma posição quando o nível de preço de compra ou venda for ultrapassado (qualquer indicador pode servir como nível);
- Abrimos uma posição na barra N desde o início da hora ou ignoramos a abertura, dependendo da posição do preço em relação ao preço de abertura do dia atual.
Procuramos encontrar uma estratégia básica que permita a geração de um número próximo de zero e uns, pois isso facilitará um melhor aprendizado.
Programa para o Aprendizado de Máquina
Faremos o aprendizado de máquina usando o programa CatBoost, que pode ser baixado neste link. Este artigo tem como objetivo a criação de uma versão independente, que não requer outra linguagem de programação, e desta você só precisa baixar o arquivo exe da versão mais recente, por exemplo catboost-0.24.1.exe.
CatBoost é um algoritmo de aprendizado de máquina de código aberto da conhecida empresa Yandex. Portanto, nós podemos esperar um suporte relevante do produto, melhorias e correções de bugs.
Você pode ver a apresentação de Yandex aqui (habilite as legendas em inglês porque a apresentação é em russo).
Resumindo, o CatBoost constrói um conjunto de árvores de decisão de tal forma que cada árvore subsequente melhora os valores da resposta probabilística total de todas as árvores anteriores. Isso é chamado de aumento do gradiente.
Preparação dos Dados para o Aprendizado de Máquina
Os dados que contêm os preditores e a variável de destino são chamados de amostra. Ela é uma matriz de dados contendo uma enumeração dos preditores como colunas, em que cada linha é uma medição que mostra os valores do preditor naquele momento. As medidas registradas na linha podem ser obtidas em determinados intervalos de tempo ou podem representar vários objetos, por exemplo imagens. Normalmente, o arquivo tem um formato CSV, que usa um separador condicional para os valores da coluna e dos cabeçalhos (opcionalmente).
Vamos usar os seguintes preditores em nosso exemplo:
- Horário / horas / frações de horas / dia da semana
- A posição relativa das barras
- Osciladores
A variável alvo é um sinal na interseção de uma MA, que permanece sem contato com a mesma na próxima barra. Se o preço estiver acima da MA, nós compramos. Se o preço estiver abaixo do MA, nós vendemos. Cada vez que chega um sinal, uma posição existente deve ser fechada. A função objetivo mostrará se nós devemos abrir uma posição ou não.
Eu não recomendo usar um script para gerar a função objetivo e os preditores. Em vez disso, usaremos um Expert Advisor, que permitirá a detecção de erros lógicos no código ao gerar uma amostra, bem como uma simulação detalhada da chegada dos dados - isso será semelhante ao processo de chegada dos dados em uma negociação real. Além disso, você poderá levar em consideração diferentes horários de abertura de diferentes instrumentos, se a função objetivo trabalhar com símbolos diferentes, bem como levar em consideração o atraso na recepção e processamento dos dados, para evitar que o algoritmo olhe para o futuro, para capturar o redesenho do indicador e a lógica inadequada para o treinamento. Como resultado, os preditores serão calculados na barra em tempo real, quando o modelo for aplicado na prática.
Alguns traders algorítmicos, especialmente aqueles que usam aprendizado de máquina, afirmam que os indicadores padrão são em sua maioria inúteis, já que atrasam e são derivados do preço, o que significa que eles não fornecem nenhuma informação nova, enquanto as redes neurais podem criar qualquer indicador. Na verdade, as possibilidades das redes neurais são grandes, mas muitas vezes exigem o poder de computação que não está disponível para a maioria dos traders. Além disso, requer tempo para o aprendizado dessas redes neurais. Os métodos de aprendizado de máquina baseados em árvore de decisão não podem competir com as redes neurais na criação de novas entidades matemáticas, uma vez que não transformam os dados de entrada. Mas são consideradas mais eficientes do que as redes neurais quando é necessário identificar dependências diretas, especialmente em matrizes de dados grandes e heterogêneas. Na verdade, o objetivo das redes neurais é gerar novos padrões, ou seja, parâmetros que descrevem o mercado. Os modelos baseados em árvore de decisão visam identificar padrões entre os conjuntos de tais padrões. Ao usar indicadores padrão da plataforma como um preditor, nós tomamos o padrão usado por milhares de traders em diferentes mercados de bolsa e OTC em diferentes países. Portanto, nós podemos assumir que nós seremos capazes de identificar uma dependência oposta do comportamento do trader nos valores dos indicadores, o que eventualmente afeta o instrumento de negociação. Eu nunca usei osciladores antes, então será interessante para eu ver o resultado.
Serão usados os seguintes indicadores da biblioteca padrão da plataforma:
- Accelerator Oscillator
- Average Directional Movement Index
- Average Directional Movement Index by Welles Wilder
- Average True Range
- Bears Power
- Bulls Power
- Commodity Channel Index
- Chaikin Oscillator
- DeMarker
- Force Index
- Gator
- Market Facilitation Index
- Momentum
- Money Flow Index
- Moving Average of Oscillator
- Moving Averages Convergence/Divergence
- Relative Strength Index
- Relative Vigor Index
- Standard Deviation
- Stochastic Oscillator
- Triple Exponential Moving Averages Oscillator
- Williams' Percent Range
- Variable Index Dynamic Average
- Volume
Os indicadores são calculados para todos os tempos gráficos disponíveis na MetaTrader 5, até o diário.
Ao escrever este artigo, eu descobri que os valores dos seguintes indicadores dependem fortemente da data de início do teste no terminal, por isso eu decidi removê-los. É possível usar a diferença entre os valores em barras diferentes para esses indicadores, mas isso está além deste artigo.
A lista de indicadores removidos:
- Awesome Oscillator
- On Balance Volume
- Accumulation/Distribution
Para trabalhar com as tabelas em CSV, nós usaremos a maravilhosa biblioteca CSV fast.mqh de Aliaksandr Hryshyn. A biblioteca apresenta:
- A criação de tabelas, leitura a partir de um arquivo e gravação em um arquivo.
- Ler e gravar informações em qualquer célula da tabela com base no endereço da célula.
- As colunas da tabela podem armazenar diferentes tipos de dados, o que economiza o consumo de RAM.
- As seções da tabela podem ser copiadas inteiramente dos endereços especificados para o endereço especificado de outra tabela.
- Fornece a filtragem por qualquer coluna da tabela.
- Fornece a classificação multinível em ordem decrescente e crescente, de acordo com os valores especificados nas células da coluna.
- Permite reindexar as colunas e ocultá-las.
- Existem outros recursos úteis e fáceis de usar.
Componentes do Expert Advisor
Estratégia básica:
Eu decidi usar uma estratégia com condições simples como estratégia básica para gerar o sinal. Segundo a estratégia, a entrada no mercado deve ser realizada desde que sejam atendidas as seguintes condições:
- O preço ultrapassar a média móvel do preço.
- Depois que a condição 1 for atendida, o preço pela primeira vez não tocou a MA cruzada na barra anterior.
Essa foi minha primeira estratégia, que criei no início dos anos 2000. Ela é uma estratégia simples que pertence à classe de tendência. Ele mostra bons resultados nas partes apropriadas do histórico de negociação. Vamos tentar reduzir o número de entradas falsas em áreas lateralizadas usando o aprendizado de máquina.
O gerador do sinal é o seguinte:
//+-----------------------------------------------------------------+ //| Returns a buy or Sell signal - basic strategy | //+-----------------------------------------------------------------+ bool Signal() { // Reset position opening blocking flag SellPrIMA=false; // Open a pending sell order BuyPrIMA=false; // Open a pending buy order SellNow=false; // Open a market sell order BuyNow=false; // Open a market buy order bool Signal=false;// Function operation result int BarN=0; // The number of bars on which MA is not touched if(iOpen(Symbol(),Signal_MA_TF,0)>MA_Signal(0) && iLow(Symbol(),Signal_MA_TF,1)>MA_Signal(1)) { for(int i=2; i<100; i++) { if(iLow(Symbol(),Signal_MA_TF,i)>MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)<MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)>=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x))break;// Signal has already been processed on this cycle if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x)) { BarN=x; BuyNow=true; break; } } } } } if(iOpen(Symbol(),Signal_MA_TF,0)<MA_Signal(0) && iHigh(Symbol(),Signal_MA_TF,1)<MA_Signal(1)) { for(int i=2; i<100; i++) { if(iHigh(Symbol(),Signal_MA_TF,i)<MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)>MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)<=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x))break;// Signal has already been processed on this cycle if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x)) { BarN=x; SellNow=true; break; } } } } } if(BuyNow==true || SellNow==true)Signal=true; return Signal; }
Obtendo os valores do preditor:
Os preditores serão obtidos usando-se funções (seu código está anexado abaixo). No entanto, eu vou mostrar como isso pode ser feito facilmente para um grande número de indicadores. Nós usaremos os valores do indicador em três pontos: a primeira e a segunda barra formada, que permite determinar o nível do sinal do indicador, e uma barra com deslocamento de 15 - permitindo entender a dinâmica do movimento do indicador. Claro, esta é uma maneira simplificada de obter informações, podendo ser significativamente expandida.
Todos os preditores serão gravados em uma tabela que é formada na RAM do computador. A tabela possui uma linha; ela será usada posteriormente como um vetor de dados numéricos de entrada para o interpretador do modelo CatBoost
#include "CSV fast.mqh"; // Class for working with tables CSV *csv_CB=new CSV(); // Create a table class instance, in which current predictor values will be stored //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CB_Tabl();// Creating a table with predictors return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Create a table with predictors | //+------------------------------------------------------------------+ void CB_Tabl() { //--- Columns for oscillators Size_arr_Buf_OSC=ArraySize(arr_Buf_OSC); Size_arr_Name_OSC=ArraySize(arr_Name_OSC); Size_TF_OSC=ArraySize(arr_TF_OSC); for(int n=0; n<Size_arr_Buf_OSC; n++)SummBuf_OSC=SummBuf_OSC+arr_Buf_OSC[n]; Size_OSC=3*Size_TF_OSC*SummBuf_OSC; for(int S=0; S<3; S++)// Loop by the number of shifts { string Shift="0"; if(S==0)Shift="1"; if(S==1)Shift="2"; if(S==2)Shift="15"; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { name_P=arr_Name_OSC[o]+"_B"+IntegerToString(b,0)+"_S"+Shift+"_"+arr_TF_OSC[T]; csv_CB.Add_column(dt_double,name_P);// Add a new column with a name to identify a predictor } } } } } //+------------------------------------------------------------------+ //--- Call predictor calculation //+------------------------------------------------------------------+ void Pred_Calc() { //--- Get information from oscillator indicators double arr_OSC[]; iOSC_Calc(arr_OSC); for(int p=0; p<Size_OSC; p++) { csv_CB.Set_value(0,s(),arr_OSC[p],false); } } //+------------------------------------------------------------------+ //| Get values of oscillator indicators | //+------------------------------------------------------------------+ void iOSC_Calc(double &arr_OSC[]) { ArrayResize(arr_OSC,Size_OSC); int n=0;// Indicator handle index int x=0;// Total number of iterations for(int S=0; S<3; S++)// Loop by the number of shifts { n=0; int Shift=0; if(S==0)Shift=1; if(S==1)Shift=2; if(S==2)Shift=15; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { arr_OSC[x++]=iOSC(n, b,Shift); } n++;// Mark shift to the next indicator handle for calculation } } } } //+------------------------------------------------------------------+ //| Get the value of the indicator buffer | //+------------------------------------------------------------------+ double iOSC(int OSC, int Bufer,int index) { double MA[1]= {0.0}; int handle_ind=arr_Handle[OSC];// Indicator handle ResetLastError(); if(CopyBuffer(handle_ind,0,index,1,MA)<0) { PrintFormat("Failed to copy data from the OSC indicator, error code %d",GetLastError()); return(0.0); } return (MA[0]); }
Acumulação e marcação da amostra:
Para criar e salvar uma amostra, nós vamos acumular os valores do preditor copiando-os da tabela csv_CB para a tabela csv_Arhiv.
Lemos a data do sinal anterior, determinamos o preço de entrada e saída da negociação e definimos o resultado, de acordo com o qual o rótulo apropriado é atribuído: "1" — positivo, "0" — negativo. Vamos também marcar o tipo de negócio realizado pelo sinal. Isso ajudará a construir o gráfico de saldo: "1" — compra e "-1" — venda. Além disso, vamos calcular aqui o resultado financeiro de uma operação de negociação. Separamos as colunas com os resultados de compra e venda que serão usadas para o resultado financeiro: ele é adequado quando a estratégia básica é mais difícil ou tem elementos de gerenciamento de posição que podem afetar o resultado.
//+-----------------------------------------------------------------+ //| The function copies predictors to archive | //+-----------------------------------------------------------------+ void Copy_Arhiv() { int Strok_Arhiv=csv_Arhiv.Get_lines_count();// Number of rows in the table int Stroka_Load=0;// Starting row in the source table int Stolb_Load=1;// Starting column in the source table int Stroka_Save=0;// Starting row to write in the table int Stolb_Save=1;// Starting column to write in the table int TotalCopy_Strok=-1;// Number of rows to copy from the source. -1 copy to the last row int TotalCopy_Stolb=-1;// Number of columns to copy from the source, if -1 copy to the last column Stroka_Save=Strok_Arhiv;// Copy the last row csv_Arhiv.Copy_from(csv_CB,Stroka_Load,Stolb_Load,TotalCopy_Strok,TotalCopy_Stolb,Stroka_Save,Stolb_Save,false,false,false);// Copying function //--- Calculate the financial result and set the target label, if it is not the first market entry int Stolb_Time=csv_Arhiv.Get_column_position("Time",false);// Find out the index of the "Time" column int Vektor_P=0;// Specify entry direction: "+1" - buy, "-1" - sell if(BuyNow==true)Vektor_P=1;// Buy entry else Vektor_P=-1;// Sell entry csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+1,Vektor_P,false); if(Strok_Arhiv>0) { int Stolb_Target_P=csv_Arhiv.Get_column_position("Target_P",false);// Find out the index of the "Time" column int Load_Vektor_P=csv_Arhiv.Get_int(Strok_Arhiv-1,Stolb_Target_P,false);// Find out the previous operation type datetime Load_Data_Start=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv-1,Stolb_Time,false));// Read the position opening date datetime Load_Data_Stop=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv,Stolb_Time,false));// Read the position closing date double F_Rez_Buy=0.0;// Financial result in case of a buy operation double F_Rez_Sell=0.0;// Financial result in case of a sell operation double P_Open=0.0;// Position open price double P_Close=0.0;// Position close price int Metka=0;// Label for target variable P_Open=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Start,false)); P_Close=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Stop,false)); F_Rez_Buy=P_Close-P_Open;// Previous entry was buying F_Rez_Sell=P_Open-P_Close;// Previous entry was selling if((F_Rez_Buy-comission*Point()>0 && Load_Vektor_P>0) || (F_Rez_Sell-comission*Point()>0 && Load_Vektor_P<0))Metka=1; else Metka=0; csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+2,Metka,false);// Write label to a cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+3,F_Rez_Buy,false);// Write the financial result of a conditional buy operation to the cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+4,F_Rez_Sell,false);// Write the financial result of a conditional sell operation to the cell csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+2,-1,false);// Add a negative label to the labels to control labels } }
Aplicação do modelo:
Vamos usar a classe "Catboost.mqh" por Aliaksandr Hryshyn, que pode ser baixada aqui, para interpretar os dados recebidos usando o modelo CatBoost.
Eu adicionei a tabela "csv_Chek" para depuração, na qual o valor do modelo CatBoost será salvo quando necessário.
//+-----------------------------------------------------------------+ //| The function applies predictors in the CatBoost model | //+-----------------------------------------------------------------+ void Model_CB() { CB_Siganl=1; csv_CB.Get_array_from_row(0,1,Solb_Copy_CB,features); double model_result=Catboost::ApplyCatboostModel(features,TreeDepth,TreeSplits,BorderCounts,Borders,LeafValues); double result=Logistic(model_result); if (result<Porog || result>Pridel) { BuyNow=false; SellNow=false; CB_Siganl=0; } if(Use_Save_Result==true) { int str=csv_Chek.Add_line(); csv_Chek.Set_value(str,1,TimeToString(iTime(Symbol(),PERIOD_CURRENT,0),TIME_DATE|TIME_MINUTES)); csv_Chek.Set_value(str,2,result); } }
Salvando uma seleção em um arquivo:
Salvamos a tabela no final da passagem do teste, especificamos o separador decimal como uma vírgula
//+------------------------------------------------------------------+ // Function writing predictors to a file | //+------------------------------------------------------------------+ void Save_Pred_All() { //--- Save predictors to a file if(Save_Pred==true) { int Stolb_Target=csv_Arhiv.Get_column_position("Target_100",false);// Find out the index of the Target_100 column csv_Arhiv.Filter_rows_add(Stolb_Target,op_neq,-1,true);// Exclude lines with label "-1" in target variable csv_Arhiv.Filter_rows_apply(true);// Apply filter csv_Arhiv.decimal_separator=',';// Set a decimal separator string name=Symbol()+"CB_Save_Pred.csv";// File name csv_Arhiv.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save the file up to 5 characters } //--- Save the model values to a debug file if(Use_Save_Result==true) { csv_Chek.decimal_separator=',';// Set a decimal separator string name=Symbol()+"Chek.csv";// File name csv_Chek.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save file up to 5 decimal places } }
Indicador de qualidade personalizado para os ajustes da estratégia:
Em seguida, nós precisamos encontrar as configurações adequadas para o indicador, que é utilizado pelo modelo básico. Portanto, vamos calcular um valor para o testador de estratégia, que determina o mínimo de negociações e retorna o percentual de negociações lucrativas. Quanto mais objetos estiverem disponíveis para treinamento (negociações), melhor será o equilíbrio da amostra (quanto mais próximo de 50% for o percentual de negociações lucrativas), melhor será o treinamento. A variável personalizada é calculada na função abaixo.
//+------------------------------------------------------------------+ //| Custom variable calculating function | //+------------------------------------------------------------------+ double CustomPokazatelf(int VariantPokazatel) { double custom_Pokazatel=0.0; if(VariantPokazatel==1) { double Total_Tr=(double)TesterStatistics(STAT_TRADES); double Pr_Tr=(double)TesterStatistics(STAT_PROFIT_TRADES); if(Total_Tr>0 && Total_Tr>15000)custom_Pokazatel=Pr_Tr/Total_Tr*100.0; } return(custom_Pokazatel); }
Controlando a frequência de execução da parte principal do código:
As decisões de negociação devem ser geradas em uma nova abertura da barra. Isso será verificado pela seguinte função:
//+-----------------------------------------------------------------+ //| Returns TRUE if a new bar has appeared on the current TF | //+-----------------------------------------------------------------+ bool isNewBar() { datetime tm[]; static datetime prevBarTime=0; if(CopyTime(Symbol(),Signal_MA_TF,0,1,tm)<0) { Print("%s CopyTime error = %d",__FUNCTION__,GetLastError()); } else { if(prevBarTime!=tm[0]) { prevBarTime=tm[0]; return true; } return false; } return true; }
Funções de negociação:
O Expert Advisor usa a classe de negociação "cPoza6". A ideia foi desenvolvida por mim, e a implementação principal foi fornecida por Vasiliy Pushkaryov. Eu testei a classe na Bolsa de Valores de Moscou, mas seu conceito não foi totalmente implementado. Então, eu convido a todos a melhorá-lo - ou seja, ele precisa de funções para trabalhar com o histórico. Para este artigo, eu desativei as verificações do tipo de conta. Portanto, tenha cuidado. A classe foi desenvolvida originalmente para contas do tipo netting, mas sua operação será suficiente no Expert Advisor, permitindo que os leitores estudem o aprendizado de máquina neste artigo.
Aqui está o código do Expert Advisor sem descrições das funções (para maior clareza).
Se nós não incluirmos algumas funções auxiliares e removermos as descrições das funções acima, o código do EA será o seguinte nesta etapa:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Check the correctness of model response interpretation values if(Porog>=Pridel || Pridel<=Porog)return(INIT_PARAMETERS_INCORRECT); if(Use_Pred_Calc==true) { if(Init_Pred()==INIT_FAILED)return(INIT_FAILED);// Initialize indicator handles CB_Tabl();// Creating a table with predictors Solb_Copy_CB=csv_CB.Get_columns_count()-3;// Number of columns in the predictor table } // Declare handle_MA_Slow handle_MA_Signal=iMA(Symbol(),Signal_MA_TF,Signal_MA_Period,1,Signal_MA_Metod,Signal_MA_Price); if(handle_MA_Signal==INVALID_HANDLE) { PrintFormat("Failed to create handle of the handle_MA_Signal indicator for the symbol %s/%s, error code %d", Symbol(),EnumToString(Period()),GetLastError()); return(INIT_FAILED); } //--- Create a table to write model values - for debugging purposes if(Use_Save_Result==true) { csv_Chek.Add_column(dt_string,"Data"); csv_Chek.Add_column(dt_double,"Rez"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(Save_Pred==true)Save_Pred_All();// Call a function to write predictors to a file delete csv_CB;// Delete the class instance delete csv_Arhiv;// Delete the class instance delete csv_Chek;// Delete the class instance } //+------------------------------------------------------------------+ //| Test completion event handler | //+------------------------------------------------------------------+ double OnTester() { return(CustomPokazatelf(1)); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Operations are only executed when the next bar appears if(!isNewBar()) return; //--- Get information on trading environment (deals/orders) OpenOrdersInfo(); //--- Get signal from the basic strategy if(Signal()==true) { //--- Calculate predictors if(Use_Pred_Calc==true)Pred_Calc(); //---Apply the CatBoost model if(Use_Model_CB==true)Model_CB(); //--- If there is an open position at the signal generation time, close it if(PosType!="0")ClosePositions("Close Signal"); //--- Open a new position if (BuyNow==true)OpenPositions(BUY,1,0,0,"Open_Buy"); if (SellNow==true)OpenPositions(SELL,1,0,0,"Open_Sell"); //--- Copy the table with the current predictors to the archive table if(Save_Pred==true)Copy_Arhiv(); } }
Configurações do Expert Advisor externo:
Agora que nós consideramos o código das funções do EA, vamos ver quais configurações o EA possui:
1. Configurando as ações com os preditores:
- "Calculate predictors" — definimos como "true" se desejamos salvar a seleção ou aplicar o modelo CatBoost;
- "Save predictors" — definimos como "true" se desejamos salvar os preditores em um arquivo para treinamento adicional;
- "Volume type in indicators" — definimos o tipo de volume: ticks ou volume real;
- "Show predictor indicators on a chart" — definimos como "true" se desejamos visualizar o indicador;
- "Commission and spread in points to calculate target" — ele é usado para levar em conta a comissão e o spread nos rótulos alvo, bem como para filtrar os negócios positivos menores;
2. Parâmetros do indicador MA para o sinal da estratégia básica:
- "Period" - Período;
- "Timeframe" - Tempo gráfico;
- "MA methods" - Métodos da MA;
- "Calculation price" - Preço para cálculo;
3. Parâmetros da aplicação do modelo CatBoost:
- "Apply CatBoost model on data" — pode ser definido como "true" após o treinamento e compilação do Expert Advisor com o modelo treinado;
- "Threshold for classifying one by the model" — o limiar no qual o valor do modelo será interpretado como um;
- "Limit for classifying one by the model" — o limite até o qual o valor do modelo será interpretado como um;
- "Save model value to file" — definimos como "true" se desejamos obter um arquivo para verificar a exatidão do modelo.
Buscando as configurações corretas para a estratégia básica
Agora, vamos otimizar o indicador estratégia da básica. Selecionamos um critério personalizado para avaliar a qualidade das configurações da estratégia. Eu realizei os testes usando a série contínua dos contratos futuros de USDRUB_TOM da corretora Otkritie (o símbolo é chamado de "Si Splice") no intervalo de tempo entre 01/06/2014 até 31/10/2020, com o tempo gráfico M1. Modo de teste: simulação OHLC M1.
Parâmetros de otimização do Expert Advisor:
- "Period": de 8 até 256 com passo de 8;
- "Timeframe": de M1 até D1, sem passo;
- "MA methods": de SMA até LWMA, sem passo;
- "Calculation price": de CLOSE até WEIGHTED.

Fig. 1 "Resultados da otimização"
A partir desses resultados, nós precisamos selecionar os valores com um parâmetro personalizado alto — de preferência 35% ou mais, com um número de negociações de 15000 ou maior (quanto maior, melhor). Opcionalmente, outras variáveis econométricas podem ser analisadas.
Eu preparei o seguinte conjunto para demonstrar o potencial de criação das estratégias de negociação usando o aprendizado de máquina:
- "Period": 8;
- "Timeframe": 2 Minutos;
- "MA methods": Ponderado linear;
- "Calculation price": Máxima do preço.
Executamos um único teste e verificamos o gráfico de resultados.

Fig. 2 "Saldo antes do aprendizado"
Essas configurações da estratégia dificilmente podem ser usadas na negociação. O sinal possui muito ruído e tem muitas entradas falsas. Vamos tentar eliminá-los. Ao contrário daqueles que testam vários parâmetros de vários indicadores para filtrar um sinal e, portanto, gastam recursos computacionais extra em áreas onde não havia valor do indicador ou era muito raro (o que é estatisticamente insignificante), nós trabalharemos apenas com as áreas onde os valores do indicador realmente fornecem informações.
Vamos alterar as configurações do EA para calcular e salvar os preditores. Em seguida, executamos um único teste:
Configurando as ações com os preditores:
- "Calculate predictors" — definimos para "true";
- "Save predictors" — definimos para "true";
- "Volume type in indicators" — definimos o tipo de volume: ticks ou volume real;
- "Show predictor indicators on a chart" — definimos "false";
- "Commission and spread in points to calculate target" — definimos para 50.
As demais configurações permanecem inalteradas. Vamos fazer um único teste no Testador de Estratégia. Os cálculos são executados mais lentamente, porque agora nós calculamos e coletamos os dados de quase 2000 buffers de indicadores, bem como calculamos outros preditores.
Encontramos o arquivo no caminho de execução do agente (Eu uso no modo portátil, então o meu é "F:\FX\Otkritie Broker_Demo\Tester\Agent-127.0.0.1-3002\MQL5\Files", "3002 " significa a thread usada para a operação do agente) e verificamos o seu conteúdo. Se o arquivo com a tabela for aberto com sucesso, então está tudo bem.
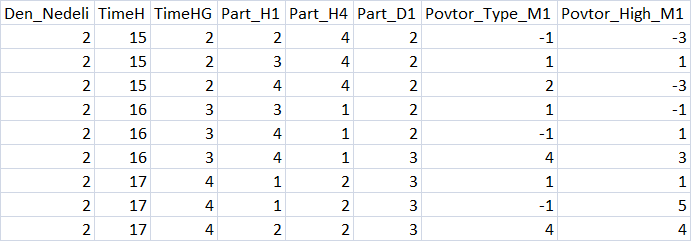
Fig. 3 "Resumo da tabela de preditores"
Dividindo a Amostra
Para mais treinamento, dividimos a amostra em três partes e salvamos estas nos arquivos:
- train.csv — a amostra usada para treinamento
- test.csv — a amostra a ser usada para controlar o resultado do treinamento e para interromper o treinamento
- exam.csv — a amostra para avaliar o resultado do treinamento
Para dividir a amostra, usamos o script CB_CSV_to3x.mq5.
Devemos especificar o caminho para o diretório que se criará o modelo de negociação e o nome do arquivo que contém a amostra.
Outro arquivo criado é o Test_CB_Setup_0_000000000 — ele especifica os índices de colunas começando com 0, aos quais pode ser aplicada a seguinte condição: desabilitar o rótulo "Auxiliary" e marcar a coluna alvo com "Label". O conteúdo do arquivo para nossa amostra é o seguinte:
2408 Auxiliary 2409 Auxiliary 2410 Label 2411 Auxiliary 2412 Auxiliary
O arquivo está localizado no mesmo local onde se encontra a amostra preparada pelo script.
Parâmetros do CatBoost
O CatBoost tem vários parâmetros e configurações que afetam o resultado do treinamento; eles são todos explicados aqui. Eu mencionarei aqui os parâmetros principais (e suas chaves, se houver), que têm maior efeito nos resultados de treinamento do modelo e que podem ser configurados no script CB_Bat:
- "Project directory" — define o caminho para o diretório onde a amostra "Setup" está localizada;
- "CatBoost exe file name" — Eu usei a versão catboost-0.24.1.exe; você deve especificar a versão que está usando;
- "Boosting type (Model boosting scheme)" — duas opções de aumento são selecionadas:
- Ordered — melhor qualidade em pequenos conjuntos de dados, mas pode ser mais lento.
- Plain — o esquema clássico de aumento do gradiente.
- "Tree depth" (depth) — a profundidade da árvore de decisão simétrica, os desenvolvedores recomendam os valores entre 6 e 10;
- "Maximum iterations (trees)" — o número máximo de árvores que podem ser construídas ao resolver problemas de aprendizado de máquina; o número de árvores após o aprendizado pode ser menor. Se nenhuma melhoria do modelo aparecer em uma amostra de teste ou validação, o número de iterações deve ser alterado em proporção a uma mudança no parâmetro da taxa de aprendizagem;
- "Learning rate" — velocidade do gradiente, ou seja, critério de generalização ao construir cada árvore de decisão subsequente. Quanto menor o valor, mais lento e preciso será o treinamento, mas isso levará mais tempo e produzirá mais iterações, portanto, não se esqueça de alterar o "Maximum number of iterations (trees)";
- "Method for automated calculation of target class weights" (class-weights) — este parâmetro permite melhorar o treinamento de uma amostra não balanceada por meio de uma série de exemplos em cada classe. Três métodos de balanceamento diferentes:
- None — todos os pesos das classes são definidos como 1
- Balanced — peso da classe com base no peso total
- SqrtBalanced — peso da classe com base no número total de objetos em cada classe
- "Method for selecting object weights" (bootstrap-type) — o parâmetro é responsável por como os objetos são calculados quando os preditores são pesquisados para construir uma nova árvore. As seguintes opções estão disponíveis:
- Bayesian;
- Bernoulli;
- MVS;
- No;
- "Range of random weights for object selection" (bagging-temperature) — é usado quando o método Bayesiano é selecionado para calcular o objeto para a pesquisa do preditor. Este parâmetro adiciona aleatoriedade ao selecionar os preditores para a árvore, o que ajuda a evitar overfitting (sobreajuste) e a encontrar padrões. Os parâmetros podem assumir um valor de zero a infinito.
- "Frequency to sample weights and objects when building trees" (sampling-frequency) — permite alterar a frequência de reavaliação do preditor ao construir as árvores. Valores suportados:
- PerTree — antes de construir cada nova árvore
- PerTreeLevel — antes de escolher cada nova divisão de uma árvore
- "Random subspace method (rsm) — o percentual de preditores analisados por etapa de treinamento 1=100%. Uma diminuição no parâmetro acelera o processo de treinamento, adiciona alguma aleatoriedade, mas aumenta o número de iterações (árvores) no modelo final;
- "L2 regularization" (l2-leaf-reg) — teoricamente, este parâmetro pode reduzir o overfitting; afeta a qualidade do modelo resultante;
- "The random seed used for training" (random-seed) — geralmente é o gerador de coeficientes de peso aleatórios no início do treinamento. Pela minha experiência, este parâmetro afeta significativamente o treinamento do modelo;
- "The amount of randomness to score the tree structure (random-strength)" — este parâmetro afeta a pontuação da bifurcação ao criar uma árvore, otimize-a para melhorar a qualidade do modelo;
- "Number of gradient steps to select a value from the list" (leaf-estimation-iterations) — as folhas são contadas quando a árvore já está construída. Elas podem ser contadas alguns passos à frente do gradiente - este parâmetro afeta a qualidade e velocidade do treinamento;
- "The quantization mode for numerical features" (feature-border-type) — este parâmetro é responsável por diferentes algoritmos de quantização nos objetos de amostra. O parâmetro afeta muito a treinabilidade do modelo. Valores suportados:
- Median,
- Uniform,
- UniformAndQuantiles,
- MaxLogSum,
- MinEntropy,
- GreedyLogSum,
- "The number of splits for numerical features" (border-count) — este parâmetro é responsável pelo número de divisões de todo o intervalo do valor de cada preditor. O número de divisões geralmente é menor. Quanto maior for o parâmetro, mais estreito será a divisão -> menor será o percentual de exemplos. Ele afeta significativamente a aprendizagem da semente (seed) e qualidade;
- "Save borders to a file" (output-borders-file) — as bordas de quantização podem ser salvas em um arquivo para análise posterior, sendo usada no treinamento subsequente. Isso afeta a velocidade de aprendizagem, pois salva os dados sempre que um modelo é criado;
- "Error score metrics for learning correction" (loss-function) — uma função a ser usada para avaliar a pontuação do erro ao treinar um modelo. Eu não notei influência significativa nos resultados. Duas opções são possíveis:
- Logloss;
- CrossEntropy;
- "The number trees without improvements to stop training" (od-wait) — se o treinamento parar rapidamente, tente aumentar o número de espera. Altere também o parâmetro quando a velocidade de aprendizagem muda: quanto menor a velocidade, mais esperamos as melhorias antes de concluir o treinamento;
- "Error score metric function to training" (eval-metric) — permite escolher uma métrica da lista, segundo a qual a árvore será truncada e o treinamento será interrompido. Métricas suportadas:
- Logloss;
- CrossEntropy;
- Precision;
- Recall;
- F1;
- BalancedAccuracy;
- BalancedErrorRate;
- MCC;
- Accuracy;
- CtrFactor;
- NormalizedGini;
- BrierScore;
- HingeLoss;
- HammingLoss;
- ZeroOneLoss;
- Kappa;
- WKappa;
- LogLikelihoodOfPrediction;
- "Sample object" — permite selecionar um parâmetro de modelo para treinamento. Opções:
- No
- Random-seed — valor usado para treinamento
- Random-strength — a quantidade de aleatoriedade para avaliar a estrutura da árvore
- Border-count — número de divisões
- l2-Leaf-reg — regularização L2
- Bagging-temperature — faixa de pesos aleatórios para a seleção dos objetos
- Leaf_estimation_iterations — número de passos do gradiente para a seleção de um valor da lista
- "Initial variable value" — define onde o treinamento começa
- "End variable value" — define onde o treinamento termina
- "Step" — passo de alteração do valor
- "Classification result presentation type"(prediction-type) — como as respostas do modelo serão escritas - não afeta o treinamento, usado após o treinamento, ao aplicar o modelo com as amostras:
- Probability
- Class
- RawFormulaVal
- Exponent
- LogProbability
- "The number of trees in the model, 0 - all" — o número de árvores no modelo a ser usado para classificação, permite avaliar uma mudança na qualidade da classificação quando o modelo é aplicado nas amostras
- "Model analysis method" (fstr-type) — vários métodos de análise do modelo permitem a avaliação da significância do preditor para um determinado modelo. Por favor, compartilhe suas ideias sobre eles. Opções suportadas:
- PredictionValuesChange — como a previsão muda quando o valor do objeto se altera
- LossFunctionChange — como a previsão muda quando o objeto é excluído
- InternalFeatureImportance
- Interaction
- InternalInteraction
- ShapValues
O script permite buscar vários parâmetros de configurações do modelo. Para fazer isso, selecionamos um objeto diferente de NONE e especificamos o valor inicial, o valor final e o passo.
Estratégia de Aprendizagem
Eu divido a estratégia de aprendizagem em três fases:
- As configurações básicas são os parâmetros responsáveis pela profundidade e o número de árvores no modelo, bem como pela taxa de treinamento, os pesos das classes e outras configurações para iniciar o processo de treinamento. Esses parâmetros não são buscados; na maioria dos casos, as configurações padrão geradas pelo script são suficientes.
- Busca pelos parâmetros de divisão ideais — o CatBoost pré-processa a tabela de preditores para buscar intervalos de valores ao longo dos limites da grade e, portanto, nós precisamos encontrar uma grade em que o treinamento seja melhor. Faz sentido iterar em todos os tipos de grade com um intervalo de 8-512; eu uso incrementos de passo em cada valor: 8, 16, 32 e assim por diante.
- Configuramos novamente o script, especificamos a grade de quantização do preditor encontrado e, depois disso, podemos passar para outros parâmetros. Normalmente, eu só uso o "Seed" na faixa de 1-1000.
Neste artigo, para o primeiro estágio da "estratégia de aprendizagem", nós usaremos as configurações padrão CB_Bat. O método de divisão será definido como "MinEntropy", a grade testará os parâmetros de 16 a 512 com um passo de 16.
Para configurar os parâmetros descritos acima, vamos utilizar o script "CB_Bat" que criará os arquivos de texto contendo as chaves necessárias para os modelos de treinamento, bem como um arquivo auxiliar:
- _00_Dir_All.txt - arquivo auxiliar
- _01_Train_All.txt - configurações para o treinamento
- _02_Rezultat_Exam.txt - configurações para registrar a classificação pelos modelos de amostra de validação
- _02_Rezultat_test.txt - configurações para registrar a classificação pelos modelos de amostra de teste
- _02_Rezultat_Train.txt - configurações para registrar a classificação pelos modelos de amostra de aprendizagem
- _03_Metrik_Exam.txt - configurações para registrar as métricas de cada árvore dos modelos de amostra de validação
- _03_Metrik_Test.txt - configurações para registrar as métricas de cada árvore dos modelos de amostra de teste
- _03_Metrik_Train.txt - configurações para registrar as métricas de cada árvore dos modelos de amostra de treinamento
- _04_Analiz_Exam.txt - configurações para registrar a avaliação da importância do preditor para os modelos de amostra de validação
- _04_Analiz_Test.txt - configurações para registrar a avaliação da importância do preditor para os modelos de amostra de teste
- _04_Analiz_Train.txt - configurações para registrar a avaliação da importância do preditor para os modelos de amostra de treinamento
Nós poderíamos criar um arquivo que executaria as ações após o treinamento sequencial. Mas, para otimizar a utilização da CPU (o que era especialmente importante nas versões anteriores do CatBoost), eu executo 6 arquivos após o treinamento.
Modelo de Treinamento
Quando os arquivos estiverem prontos, renomeie o arquivo "_00_Dir_All.txt" para "_00_Dir_All.bat" e execute-o - ele criará os diretórios necessários para localizar os modelos e mudará a extensão de outros arquivos para "bat".
Agora nosso diretório de projeto contém a pasta "Setup" com o seguinte conteúdo:
- _00_Dir_All.bat - arquivo auxiliar
- _01_Train_All.bat - configurações para treinamento
- _02_Rezultat_Exam.bat - configurações para registrar a classificação pelos modelos de amostra de validação
- _02_Rezultat_test.bat - configurações para registrar a classificação pelos modelos de amostra do teste
- _02_Rezultat_Train.bat - configurações para registrar a classificação pelos modelos de amostra de aprendizagem
- _03_Metrik_Exam.bat - configurações para registrar as métricas de cada árvore dos modelos de amostra de validação
- _03_Metrik_Test.bat - configurações para registrar as métricas de cada árvore dos modelos de amostra de teste
- _03_Metrik_Train.bat - configurações para registrar as métricas de cada árvore dos modelos de amostra de treinamento
- _04_Analiz_Exam.bat - configurações para registrar a avaliação da importância do preditor para os modelos de amostra de validação
- _04_Analiz_Test.bat - configurações para registrar a avaliação da importância do preditor para os modelos de amostra de teste
- _04_Analiz_Train.bat - configurações para registrar a avaliação da importância do preditor para os modelos de amostra de treinamento
- catboost-0.24.1.exe - arquivo executável para treinar os modelos CatBoost
- train.csv - a amostra a ser usada para treinamento
- test.csv — a amostra a ser usada para controlar o resultado do treinamento e para interromper o treinamento
- exam.csv - a amostra para avaliar os resultados
- Test_CB_Setup_0_000000000//Arquivo com informações sobre as colunas da amostra usadas para treinamento
Executamos o arquivo "_01_Train_All.bat" e observamos o processo de treinamento.
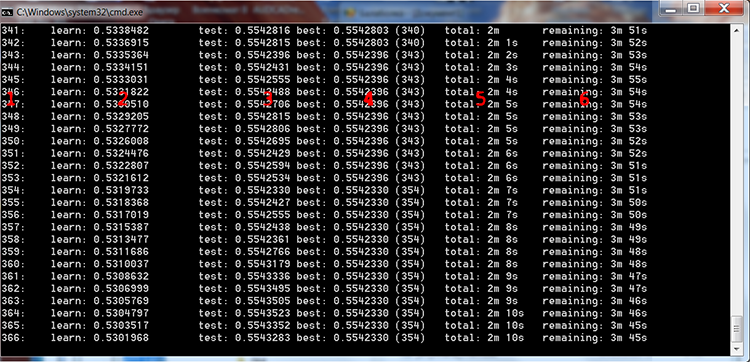
Fig. 4 Processo de treinamento do CatBoost
Eu adicionei os números vermelhos na figura acima para descrever as colunas:
- O número de árvores, igual ao número de iterações
- O resultado do cálculo da função de perda selecionada na amostra de treinamento
- O resultado do cálculo da função de perda selecionada na amostra de controle
- O melhor resultado do cálculo da função de perda selecionada na amostra de controle
- O tempo real decorrido desde o início do treinamento do modelo
- Tempo estimado restante até o final do treinamento se todas as árvores especificadas pelas configurações forem treinadas
Se nós selecionarmos um intervalo de busca nas configurações do script, os modelos serão treinados em um loop quantas vezes forem necessárias de acordo com o conteúdo do arquivo:
FOR %%a IN (*.) DO ( catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 16 --feature-border-type MinEntropy --output-borders-file quant_4_00016.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type MinEntropy --output-borders-file quant_4_00032.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 48 --feature-border-type MinEntropy --output-borders-file quant_4_00048.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 64 --feature-border-type MinEntropy --output-borders-file quant_4_00064.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 80 --feature-border-type MinEntropy --output-borders-file quant_4_00080.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_96\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 96 --feature-border-type MinEntropy --output-borders-file quant_4_00096.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_112\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 112 --feature-border-type MinEntropy --output-borders-file quant_4_00112.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_128\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 128 --feature-border-type MinEntropy --output-borders-file quant_4_00128.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_144\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 144 --feature-border-type MinEntropy --output-borders-file quant_4_00144.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_160\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 160 --feature-border-type MinEntropy --output-borders-file quant_4_00160.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
Quando o treinamento for concluído, nós iniciamos todos os 6 arquivos bat restantes de uma vez, para obter os resultados do treinamento na forma de rótulos e valores estatísticos.
Avaliação Expressa dos Resultados de Aprendizagem
Vamos usar o script CB_Calc_Svod.mq5 para obter as variáveis das métricas dos modelos e seus resultados financeiros.
Este script possui um filtro para selecionar os modelos pelo saldo final na amostra de avaliação: se o saldo for superior a um determinado valor, então o gráfico de saldo pode ser construído a partir da amostra e a amostra convertida para mqh e salva em um diretório separado do projeto do modelo CatBoost.
Aguardamos a conclusão do script - neste caso você verá o recém-criado "Analiz" contendo o arquivo CB_Svod.csv, e os gráficos de saldo pelo nome do modelo, se sua plotagem foi selecionada nas configurações, bem como o diretório "Models_mqh" contendo os modelos convertidos para o formato mqh.
O arquivo CB_Svod.csv conterá as métricas de cada modelo da amostra individual, junto com os resultados financeiros.
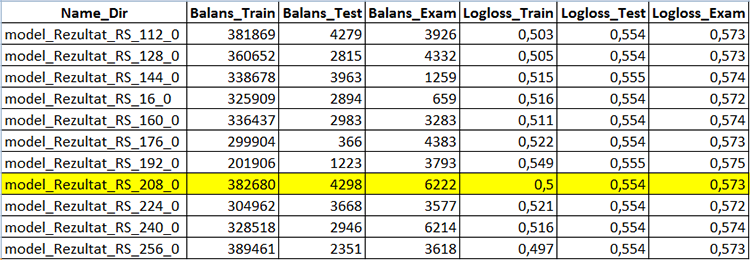
Fig. 5 Parte da tabela contendo os resultados da criação do modelo - CB_Svod.csv
Selecione o modelo de sua preferência no subdiretório Models_mqh do diretório no qual nossos modelos foram treinados e adicione-o ao diretório do Expert Advisor. Comente a linha com buffers vazios no início do código do EA usando "//". Agora, nós só precisamos conectar o arquivo do modelo ao EA:
//If the CatBoost model is in an mqh file, comment the below line //uint TreeDepth[];uint TreeSplits[];uint BorderCounts[];float Borders[];double LeafValues[];double Scale[];double Bias[]; #include "model_RS_208_0.mqh"; // Model file
Depois de compilar o Expert Advisor, definimos a configuração "Apply CatBoost model on data" para "true", desativamos o salvamento da amostra e executamos o Testador de Estratégia com os seguintes parâmetros.
1. Configurando as ações com os preditores:
- "Calculate predictors" — definimos para "true";
- "Save predictors" — definimos para "false"
- "Volume type in indicators" — definimos o tipo de volume que usamos no treinamento
- "Show predictor indicators on a chart" — definimos "false"
- "Commission and spread in points to calculate target" — usamos o valor anterior, ele não afeta o modelo pronto
2. Parâmetros do indicador MA para o sinal da estratégia básica:
- "Period": 8;
- "Timeframe": 2 Minutos;
- "MA methods": Ponderado linear;
- "Calculation price": Máxima do preço.
3. Parâmetros da aplicação do modelo CatBoost:
- "Apply CatBoost model on data" — definimos para "true"
- "Threshold for classifying one by the model" — deixamos 0.5
- "Limit for classifying one by the model" — deixamos 1
- "Save model value to file" — deixamos "false"
O seguinte resultado foi recebido para todo o período da amostra.
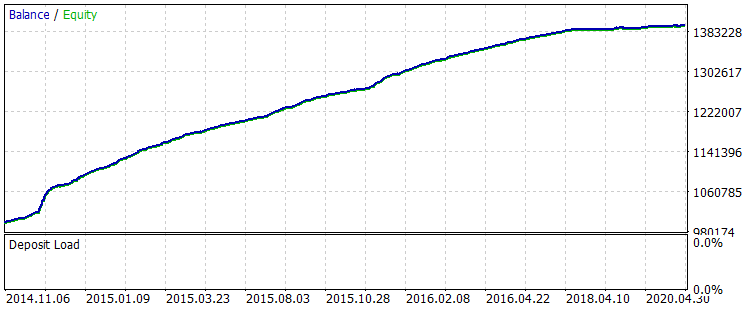
Fig. 6 Saldo após o treinamento por um período de 01.06.2014 - 31.10.2020
Vamos comparar os dois gráficos de saldo no intervalo de 01.08.2019 à 31.10.2020, que está fora do período de treinamento, que corresponde à amostra exam.csv, antes e depois do treinamento.
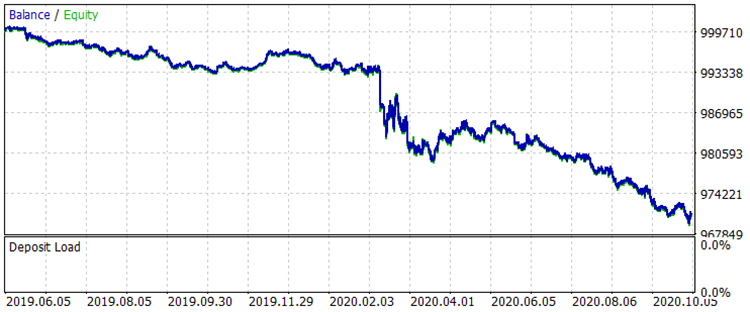
Fig. 7 Saldo antes do treino para o período 01.08.2019 - 31.10.2020
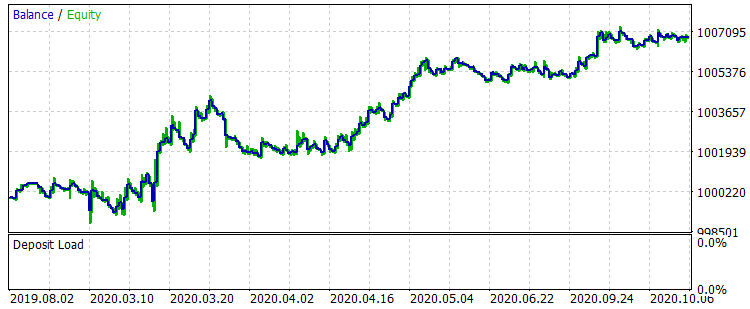
Fig. 8 Saldo após o treinamento para o período 01.08.2019 - 31.10.2020
Os resultados não são muito impressionantes, mas pode-se notar que a principal regra de negociação "evitar perda de dinheiro" é observada. Mesmo se escolhermos outro modelo do arquivo CB_Svod.csv, o efeito ainda seria positivo, pois o resultado financeiro do modelo mais malsucedido que obtivemos é de -25 pontos, e o resultado financeiro médio de todos os modelos é de 3889.9 pontos.
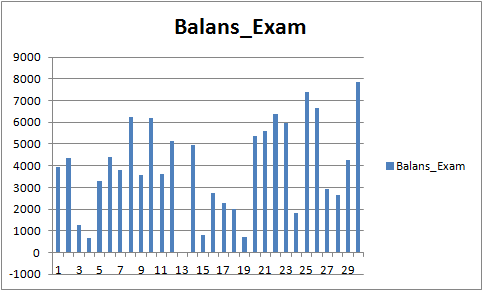
Fig. 9 Resultado financeiro dos modelos treinados para o período 01.08.2019 - 31.10.2020
Análise dos Preditores
Cada diretório do modelo (para mim MQL5\Files\CB_Stat_03p50Q\Rezultat\RS_208\result_4_Test_CB_Setup_0_000000000) possui 3 arquivos:
- Analiz_Train — análise da importância do preditor na amostra de treinamento
- Analiz_Test — análise da importância do preditor na amostra de teste (validação)
- Analiz_Exam — análise da importância do preditor na amostra de validação (fora do treinamento)
O conteúdo será diferente, dependendo do "Método de análise do modelo" selecionado ao gerar os arquivos para treinamento. Vamos ver o conteúdo com "PredictionValuesChange".
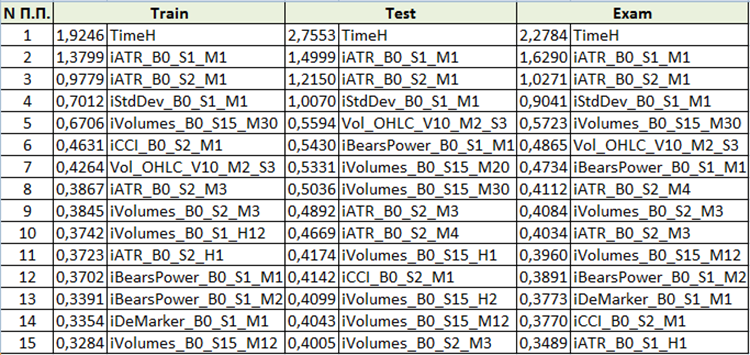
Fig. 10 Tabela de resumo da análise de importância do preditor
Com base na avaliação da importância do preditor, nós podemos concluir que os primeiros quatro preditores são consistentemente importantes para o modelo resultante. Observe que a importância do preditor depende não apenas do modelo em si, mas também da amostra original. Se o preditor não teve valores suficientes nesta amostra, então ele não pode ser avaliado objetivamente. Este método permite entender a ideia geral da importância do preditor. No entanto, tenha cuidado com isso ao trabalhar com amostras baseadas em símbolos de negociação.
Conclusões
- A eficácia dos métodos de aprendizado de máquina, como o aumento do gradiente, pode ser comparada à de uma iteração infinita de parâmetros e à criação manual de condições de negociação adicionais em um esforço para melhorar o desempenho da estratégia.
- Os indicadores padrão da MetaTrader 5 podem ser úteis para fins de aprendizado de máquina.
- CatBoost — é uma biblioteca de alta qualidade possuindo um "wrapper", que permite o uso eficiente do aumento de gradiente sem aprender Python ou R.
Conclusão
O objetivo deste artigo é chamar sua atenção para o aprendizado de máquina. Eu realmente espero que a descrição detalhada da metodologia e as ferramentas de reprodução fornecidas levem ao aparecimento de novos fãs de aprendizado de máquina. Vamos nos unir em um esforço para encontrar novas ideias sobre aprendizado de máquina, em particular ideais sobre como buscar preditores. A qualidade de um modelo depende dos dados de entrada e da meta e, unindo nossos esforços, nós podemos alcançar o resultado desejado com mais rapidez.
Você é mais que bem-vindo para relatar os erros contidos em meu artigo e código.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8657
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Reamostragem avançada e seleção de modelos CatBoost pelo método de força bruta
Reamostragem avançada e seleção de modelos CatBoost pelo método de força bruta
 Força bruta para encontrar padrões (Parte II): Imersão
Força bruta para encontrar padrões (Parte II): Imersão
 WebSocket para MetaTrader 5
WebSocket para MetaTrader 5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Se você fosse aplicar isso a um EA diferente, bastaria aplicar o modelo catboost antes de a ordem ser colocada e deixar todo o resto igual, ou precisaria modificar o model_CB() ou copy_arhiv()? Não parece estar abrindo ordens quando o modelo CB é aplicado.
Você pode adicionar ou alterar o sinal de entrada na função Signal().
Você treinou o modelo CatBoost?
Se você fez tudo certo, ele deve funcionar.
Sim, eu treinei o modelo. E se o EA fechar, reduzir ou reverter posições no sinal oposto, você deseja filtrá-las usando o modelo ou simplesmente filtrar a abertura de novas ordens?
Sim, eu treinei o modelo. E se o EA fechar, reduzir ou reverter posições no sinal oposto, você deseja filtrá-las usando o modelo ou simplesmente filtrar a abertura de novas ordens?
Não entendi o pensamento: " você deseja filtrar essas ordens usando o modelo ".
Com a ajuda do modelo, os sinais para abrir uma posição são filtrados no artigo.
Não entendi o pensamento: " você quer filtrar aqueles que usam o modelo ".
Com a ajuda do modelo, os sinais para abrir uma posição são filtrados no artigo.
Se o seu EA tiver um sinal oposto, ele poderá fechar as ordens. Se o boost puder, teoricamente, reduzir os sinais falsos. Se o sinal oposto fechar as ordens, o catboost reduzirá o fechamento das ordens falsas e o resultado será que você deixará as ordens abertas por mais tempo e obterá maior lucro. Por exemplo. Você coloca uma ordem quando sua MA cruza. Seu stoploss é de 50 pips e o TP é de 50. No entanto, a MA cruza de volta antes de você atingir seu SL ou TP, e o seu EA está programado para fechar a ordem quando isso acontecer: isso é chamado de fechar (ou reduzir, ou reverter) no sinal oposto. Agora, se esse sinal for um alarme falso, então você fecha seu lucro muito cedo, quando poderia ter subido até seu TP. Então, o catboost poderia ter filtrado uma certa porcentagem desses sinais falsos? Essa é a minha pergunta: nem todos os EAs fecham posições com o sinal oposto. Muitos têm apenas um Sl e um TP fixos. É por isso que fiz essa pergunta, porque alguns EAs têm essa funcionalidade.
Se o seu EA tiver um sinal oposto, ele poderá fechar as ordens. Se o boost puder, teoricamente, reduzir os sinais falsos, se o sinal oposto fechar as ordens, o catboost reduzirá o fechamento das ordens falsas e o resultado será que você deixará as ordens abertas por mais tempo e obterá maior lucro. Por exemplo. Você coloca uma ordem quando sua MA cruza. Seu stoploss é de 50 pips e o TP é de 50. No entanto, a MA cruza de volta antes de você atingir seu SL ou TP, e o seu EA está programado para fechar a ordem quando isso acontecer: isso é chamado de fechar (ou reduzir, ou reverter) no sinal oposto. Agora, se esse sinal for um alarme falso, então você fecha seu lucro muito cedo, quando poderia ter subido até seu TP. Então, o catboost poderia ter filtrado uma certa porcentagem desses sinais falsos? Essa é a minha pergunta: nem todos os EAs fecham posições com o sinal oposto. Muitos têm apenas um Sl e um TP fixos. É por isso que fiz essa pergunta, porque alguns EAs têm essa funcionalidade.
Eu entendi o motivo da conversa.
Programaticamente, é fácil de implementar, mas será um jogo com aleatoriedade. O fato é que o índice Recall nos modelos é bastante baixo, ou seja, o modelo não reconhece mais de 10% de todos os eventos, o que significa que a posição oposta muitas vezes não é aberta devido a um padrão não identificado. Isso está relacionado, entre outras coisas, aos preditores. O artigo mostra o algoritmo para implementar modelos CatBoost. É necessário fortalecer o modelo com preditores para que sua abordagem proposta seja mais justificada.