
機械学習における量子化(第2回):データの前処理、テーブルの選択、CatBoostモデルの訓練

はじめに
この記事では、ツリーモデルの構築における量子化の実際の応用について考察します。複雑な数式は使用しません。これは「機械学習における量子化(第1回):理論、コード例、CatBoostでの実装解析」に続く連載記事ですので、まずは第1回の内容を理解することを強くお勧めします。今回は次のことについて話します。
- 前半では、MQL5で実装された、データ例を前処理する方法を検討します。
- 後半では、データ量子化の実現可能性に関する情報を提供する実験をおこないます。
1. その他のデータ前処理法
Q_Error_Selectionスクリプトの機能を説明する例を使用して、実装したデータ前処理法について考えてみましょう。
簡単に言えば、Q_Error_Selectionスクリプトの目的は、train.csvファイルからサンプルを読み込み、内容を行列に転送し、データを前処理し、量子化テーブルを交互に読み込み、復元されたデータの各予測子の元の値に早退した誤差を評価することです。各量子化テーブルの評価結果は配列に保存されます。すべてのオプションを確認した後、各予測子の誤差を含む要約テーブルを作成し、指定された基準に従って各予測子の量子化テーブルに最適なオプションを選択します。要約量子化テーブル(CatBoost設定を含むファイル)を作成して保存しましょう。このテーブルには、訓練用のリストから除外された予測子がその列の通し番号とともに追加されます。また、選択したスクリプト設定に応じて付随ファイルも作成します。
以下にグループごとにリストしたスクリプト設定を詳しく見てみましょう。
データの読み込み
- サンプルディレクトリ1
- 量子化ディレクトリ2
1サンプルを含む CSV ファイルが配置されている設定ディレクトリを含むディレクトリへのパスを指定します。以下、このディレクトリを「プロジェクトディレクトリ」と呼びます。
2 サンプルを含む CSV ファイルが配置されている設定ディレクトリを含むディレクトリへのパスを指定します。
スパイク処理の構成
- スパイク確認を使用する1
- スパイク変換方式2
- スパイク値を分割に近い値に変換する2.1
- スパイク値をスパイクの範囲外の無作為な値に変換する2.2
- スパイクに対処した後にデータを置き換える3
- 変換されたスパイクを含む「訓練」サンプルを保存する/保存しない4
- スパイクに関する情報をサブサンプルに追加する5
- 多数のスパイクを含む行を削除する5.1
- サンプル文字列内の予測子の外れ値の最大割合5.2
1trueを選択すると、スパイク処理が有効になります。ここでは、予測子の稀な値がスパイクとみなされます。まれな値は統計的に重要ではない可能性がありますが、通常、モデルではこれが考慮されていないため、分類確率の推定ルールに疑問が生じる可能性があります。図1は、そのようなスパイクを示しています。スパイクと通常のデータを分ける境界を設定することで、外れ値を1つに集約できるようになります。これにより、統計的信頼性が向上し、通常のデータと同様にデータを操作したり、訓練から完全に除外したりすることができます。
2スパイク変換メソッドの 1 つを選択します。これを使用すると、予測子の値が変更され、この例が訓練サンプルで考慮され、異常なものとして除外されなくなります。スパイクを決定するために、数値系列の各辺のデータの2.5%を使用しました。以前に遭遇した同一の数値がグループ化され、ランクがグループに割り当てられました。次のランクが2.5%を超える場合、前のランクがスパイクのある最後のランクとみなされます。ランクが少ない予測子はカテゴリカルとみなされ、スパイクを処理しません。カテゴリカル予測子のリスト形式の情報は、「..\CB\Categ.txt」プロジェクトディレクトリを基準とした次のパスに保存されます。スパイクを識別する一般的な方法は、スリー シグマ ルールです。これは、データ領域の左右の平均値から3標準偏差のインデントが作成され、この境界の外側にあるものはすべてスパイクと見なされます。以下のグラフでは、中心、中心からの3シグマの差、および合計の3本の水平線が黒で表示されています。グラフ上の青い線は境界を示し、私が提案するアルゴリズムに従って、頻繁に発生するデータがその境界内に配置されます。
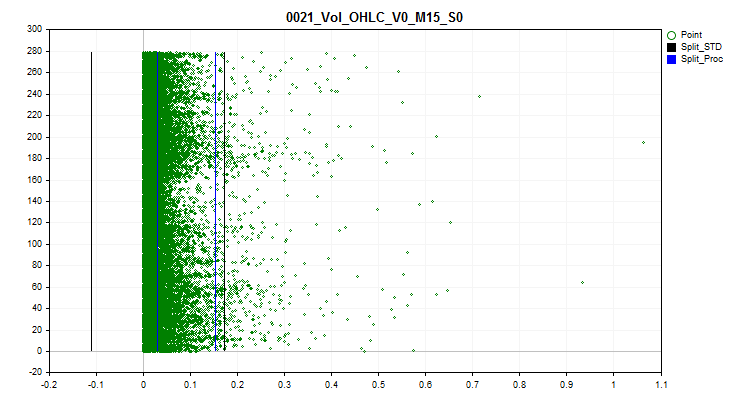
図1:スパイク定義の制限の決定
2.1この方法では、すべてのスパイク値が境界 (分割) に近い値に置き換えられます。このアプローチにより、スパイク境界内の量子化テーブルによる近似の推定を歪めないようにすることができます。
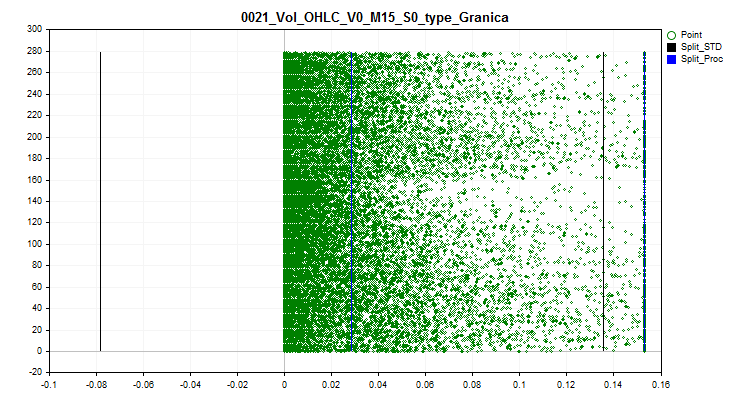
図2:スパイク値を分割に近い値に変換
2.2この方法は、通常のデータの境界内のランクに従って、すべてのスパイク値を無作為な値に置き換えます。このアプローチにより、量子化テーブルによる近似を推定する際の誤差を解消することが可能になります。
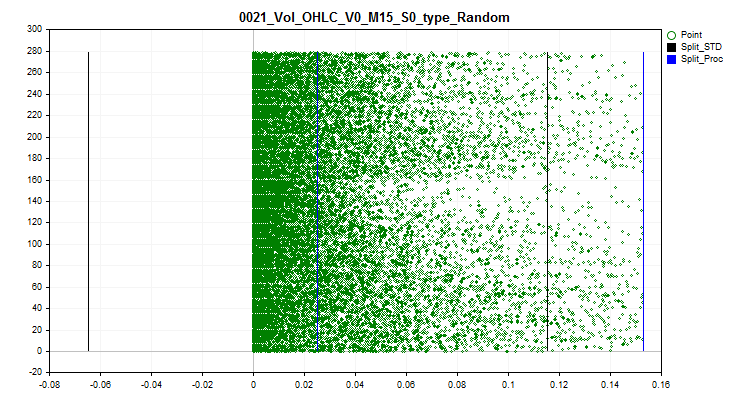
図3:スパイク値はスパイクの外側の範囲で無作為な値に変換される
3変換されたスパイクを考慮して量子化テーブルを評価および選択する必要がある場合は、trueを選択します。この機能を有効にすると、元のデータの行列形式の配列が変更され、スパイクのある予測子の値が、スパイク変換方法に従って選択された値に設定されます。
4train.csvサンプルを保存できます。「..\CB\Q_Vibros_Viborka」ディレクトリに保存されます。これは、CatBoostを使用して量子化を実行するために必要になる場合があります。データはすでに変換されたものに変更されているため、量子化テーブルは異なる場合があります。また、これにより、量子化テーブルによる近似の品質を評価するときに、最小誤差閾値を達成するためにセパレータ(分割)の数を減らすことも可能になる場合があります。
5 このパラメータをアクティブにして変数をtrueに設定すると、train.csv、test.csv、exam.csvサブサンプルを含むファイルが順次読み込まれます。サブサンプルの各行で、スパイク領域内の予測値の数がカウントされ、その合計結果が追加で作成されたProc_Vibros列に記録されます。変更された選択内容は、「..\CB\ADD_Drop_Info_Viborka」ディレクトリに保存されます。
この設定が有効かどうかに関係なく、プロジェクトディレクトリ「..\CB\Proc_Vibros_Train.csv」には別のファイルが作成されます。このファイルには、trainサンプルのスパイクに関する情報のみが含まれています。
5.1この設定を有効にすると、スパイクのある行が選択から削除されます。場合によっては、スパイクのないデータでモデルを訓練してみる価値があります。
5.2外れ値を含む行を削除する場合は、値がスパイク定義領域にあった予測子の割合を評価する価値があります。
相関推定の構成
- 相関推定を使用して予測子を排除する1
- 相関予測子の除外方法で、選択する選択方法 (予測子の除外)を定義する2
- 予測子の後方選択2.1
- 一般化予測子の選択2.2
- まれな予測因子の選択2.3
- 相関比3
1trueを選択すると、ピアソン相関推定が有効になります。この機能の結果、「../CB」に予測子相関テーブルが取得されます。ファイル名は、「Corr_Matrix_」名と「Corr_Matrix_70.csv」相関比サイズで構成されます。相関性の高い予測子は除外されます。
2予測子の除外方法は3つから選択できます。
2.1この方法では、相関のある予測子を逆順に検索し、以前の予測子が存在する場合は、予測子を含む現在の列が訓練から除外されます。
2.2この方法は、各予測子と相関する予測子の数を推定し、多数の予測子と相関する予測子を繰り返し選択し、それに相関する他の予測子を排除します。ここでのロジックは、他の予測子に関する情報が最も多く含まれる情報を持つ予測子を選択するというものです。したがって、データの一般化が得られます。
2.3この方法は前の方法と似ていますが、ここでは他の予測子との類似性が最も低い予測子を選択します。ここでは、その逆、つまり固有のデータを持つ予測子を見つける試みがおこなわれています。
3ここで、ピアソン相関比を示す必要があります。指定された比率値に達するか、それを超えた場合にのみ、予測子は類似しているとみなされ、サンプルから除外されます。
時間的に不安定な予測子の処理の構成
- サンプルの各部分の平均値の検定を使用する1
- サブサンプルの平均拡散率2
1trueを選択すると、サンプルの1/10部分ごとの予測指標の平均値の変動の確認が有効になります。このテストにより、時間の経過とともに指標が大きくシフトする予測子を除外できます。このような予測子は、理論上、訓練の妨げになります。このような予測子の例を図4に示し、視覚的な評価を図5に示します。この予測子の例は、実際には平均価格値を示すiVIDyA(Variable Index Dynamic Average、変数インデックス動的平均)指標に基づいて構築されており、モデルでの使用により、特定の絶対価格での動作の訓練がおこなわれます。
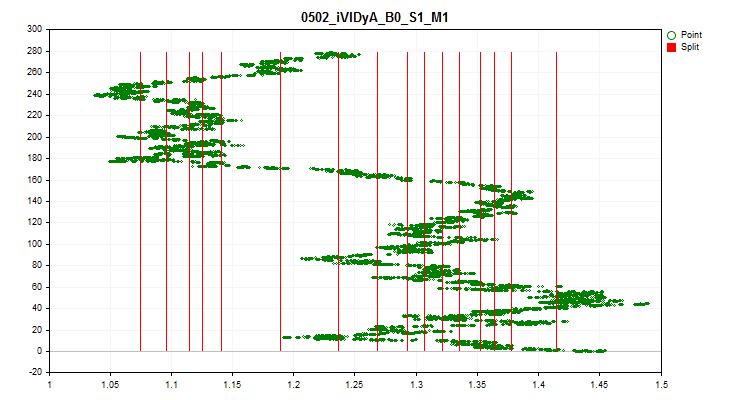
図4:iVIDyA_B0_S1_M1予測子は大幅な変化を示す
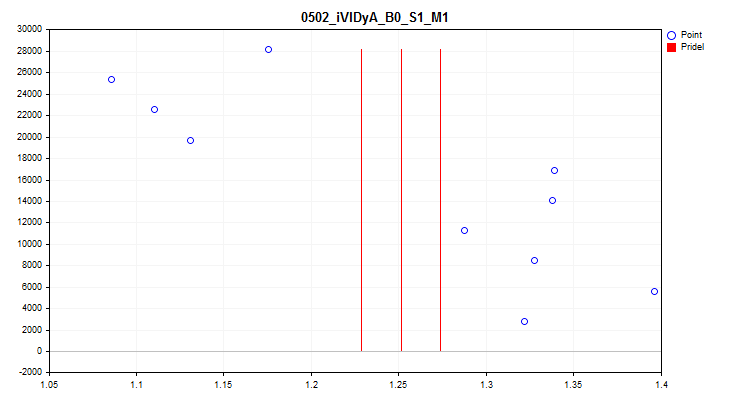
図5:iVIDyA_B0_S1_M1予測子 (平均スプレッド)
2ここでは、範囲の幅が各境界の割合として示されており、期間全体の平均値に対する予測値の全範囲から決定されます。
均一量子化テーブルの作成の構成
- 均一量子化テーブルの作成1
- 元のデータを分割 (量子化) する間隔の数2
1trueを選択すると、サンプル内のすべての予測子に対して均一な量子化テーブルを作成するアルゴリズムが有効になります。テーブルは Q_Bitプロジェクトのサブディレクトリに保存されます。
2予測値を分割する間隔の数を設定します。
無作為な要素を使用した量子化テーブルの作成の構成
- 無作為な量子化テーブルを作成する1
- 乱数発生器の初期番号2
- 最適なオプションを見つけるための反復回数3
- 元のデータを分割(量子化)する間隔の数4
1trueを選択すると、サンプル内のすべての予測子に対して無作為な量子化テーブルを作成するアルゴリズムが有効になります。テーブルはQ_Randomプロジェクトに保存されます。
2この数値により、ランダム生成の結果を再現可能にすることができます。数値を変更することで、生成される数値の順序を変更できます。
3アルゴリズムは、テーブルが無作為に生成されるたびに近似誤差を評価し、最適なオプションを選択します。試行回数が増えるほど、最も成功するオプションが見つかる可能性が高くなります。
4予測値を分割する間隔の数を設定します。
量子化テーブルの選択の構成
- 量子化テーブルの選択を開始する1
- 閾値を使用して予測子を選択する2
- 最大許容量子化誤差3
1trueを選択すると、プロジェクトのQサブディレクトリから量子化テーブルを検索して評価するアルゴリズムが有効になります。それ以外の場合、プログラムは動作を停止します。このスクリプト関数を実行すると、次の2つのディレクトリが作成されます。
「..\CB\Setup」ディレクトリには、次の3つのファイルが含まれます。
- Auxiliary.txt:除外された予測子のインデックス番号を含む補助ファイル
- Quant_CB.csv:訓練に参加する予測子の量子化テーブルを含むファイル
- Test_CB_Setup_0_000000000:CatBoostの情報が含まれるファイル(訓練から除外される列とターゲット列として考慮される列)
Test_Errorディレクトリには、arr_Svod.csvファイルが含まれます。これには、異なる量子化テーブルを使用した場合の各予測子の再構成(近似)誤差の計算結果の概要が含まれています。最初の列には予測子のリスト、つまり特定の量子化テーブルを適用した場合のその後の結果が含まれ、最後の列には最良の結果を示した量子化テーブルのインデックスが含まれます。最良の結果は、Quant_CB.csv要約量子化テーブルの作成に使用されました。
2 falseの場合、再構成 (近似) 誤差のみが量子化テーブルの評価に使用され、最小の誤差を生成するテーブルが選択されます。
trueの場合、再構成 (近似) 誤差を量子化テーブルの分割数で割った値が量子化テーブルの評価に使用されます。このアプローチにより、過剰な量子化を避けるために、推定中に量子化テーブルの数を考慮することができます。テーブルは、その誤差が次の設定パラメータで指定された誤差よりも低い場合にのみ選択に参加します。
3 ここでは、予測値を再構築 (近似) する際の最大許容誤差を示します。
変換された選択範囲の保存を構成する
- サンプルを変換して保存する1
- データ変換オプション:2
- インデックスとして保存する2.1
- 重心として保存する2.2
1trueの場合、サンプル(3つのCSVファイル) が変換され、「..\CB\Index_Viborka」プロジェクトサブディレクトリに保存されます。この設定により、量子化テーブルが元々提供されていなかったマシン訓練 アルゴリズムで量子化テーブルを使用できるようになります。別の使用例は、使用されるデータ ソースに関する競合情報の漏洩を防ぐために、予測子のスコアを開示せずにモデル訓練 データを公的に共有することです。さらに、インデックスの形式で保存すると、サンプル ファイルが占有するディスク領域の量が大幅に削減され、サンプルを操作するためのRAMの量も削減されます。
2最終的な量子化要約テーブルを適用した後に予測値を変換するための 2 つのオプションのいずれかを選択します。
2.1予測子番号が含まれる量子化テーブル セグメントのインデックスを保存します。
2.2予測値の数値が含まれる 2 つの境界間の値を保存します。
グラフ保存の設定
- グラフを保存する1
- グラフ幅2
- グラフの高さ3
- 凡例のフォントサイズ4
1trueの場合、グラフの作成保存機能が有効になります。サンプル内の各予測子に関する情報を含むグラフィックファイルがGraphicsディレクトリに作成されます。ファイル名は、予測子の番号で始まり、サンプル列ヘッダーの予測子の名前と条件付きグラフの名前が続きます。iCCI_B0_S1_M1予測子に対して取得されたグラフを見てみましょう。
- 最初のグラフは、特定の間隔での予測値の密度を示します。密度が高くなるほど、この間隔でのグラフ曲線はより強く上向きになります。X軸は予測値、Y軸はその値で並べられた観測値です。グラフを使用すると、特定の間隔に該当するサンプル内の観測値の密度を推定し、スパイクを確認できます。
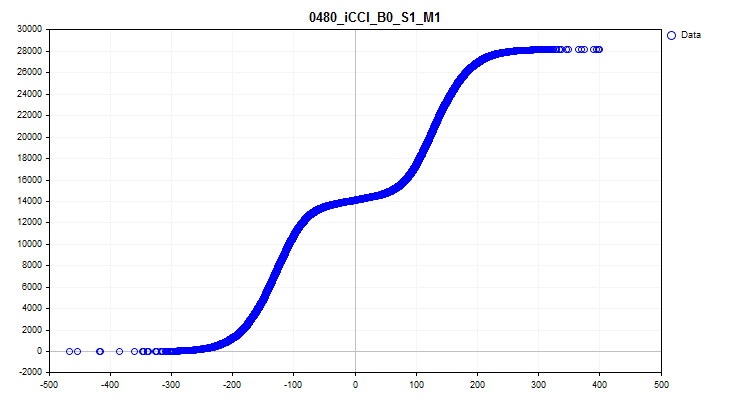
図6:予測値の密度
- 2つ目のグラフは、ターゲット「0」と「1」で予測子の値がどの間隔で観測されたかを示します。その結果、0の値は青で表示され、1の値は赤で表示されます。したがって、どの予測間隔でターゲット値がより大きく表現されているかを確認することができます。ここに表示されているグラフよりも幅の広いグラフを作成することをお勧めします。
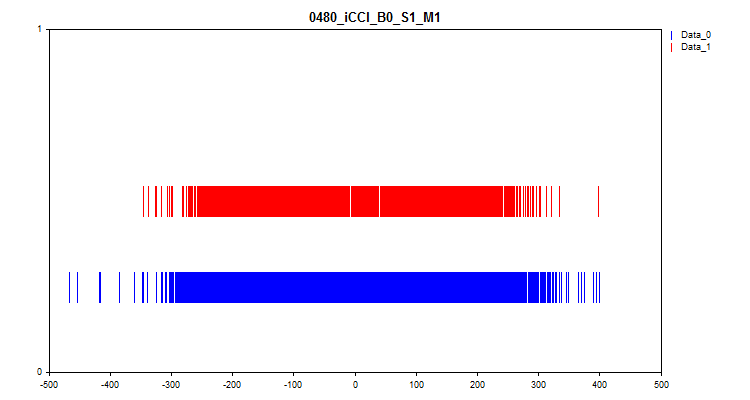
図7:予測値とターゲットマーキングの対応
- 3つ目のグラフは、サンプル内のすべての観測値からの観測値の割合をプロットするY軸のヒストグラムを作成します。グラフを使用すると、スパイクを評価し、分布密度についての推測をおこなうことができます。
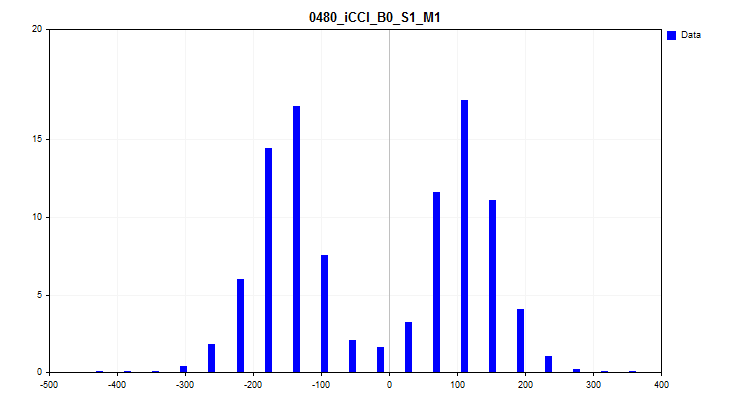
図8:分布密度ヒストグラム
- 4つ目のグラフは、予測尺度範囲の値を時系列で満たしていることを示し、最終的な量子化のために選択されたレベルも示しています。X軸は予測子の値、Y軸は100個の観測値のグループの数です。
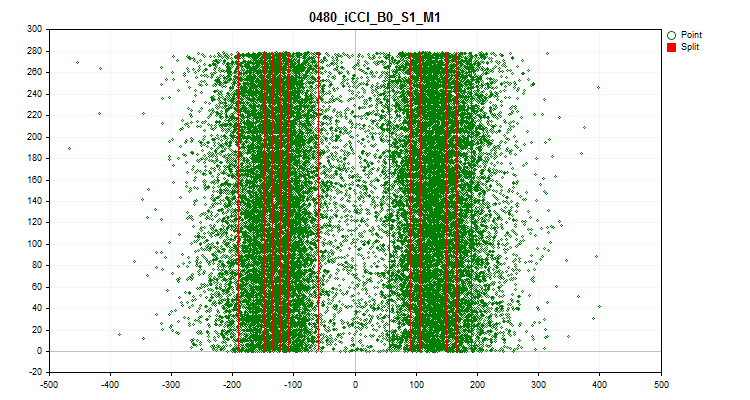
図9:量子化テーブル
- 5つ目のグラフは、10標本化間隔にわたる平均予測値を示します。散布が広い場合は、予測子を除外することをお勧めします。X軸は予測子の値、Y軸はN個の観測値のグループの数です。
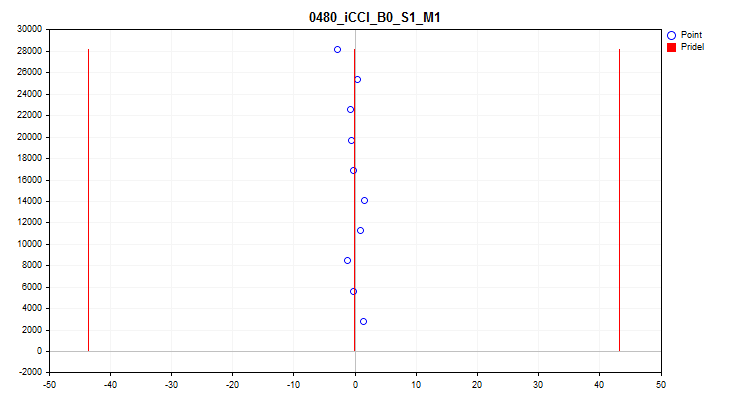
図10:平均値スプレッド
- 6つ目のグラフは、推定されたスパイクを示します。グラフには3本の黒い線があります。これは平均値と、プラスとマイナスの3つの標準偏差です。青い境界は、サンプル範囲の最初と最後から測定された観測値の2.5%に近い境界です。X軸は予測子の値、Y軸は固定数の観測値を持つグループの番号です。
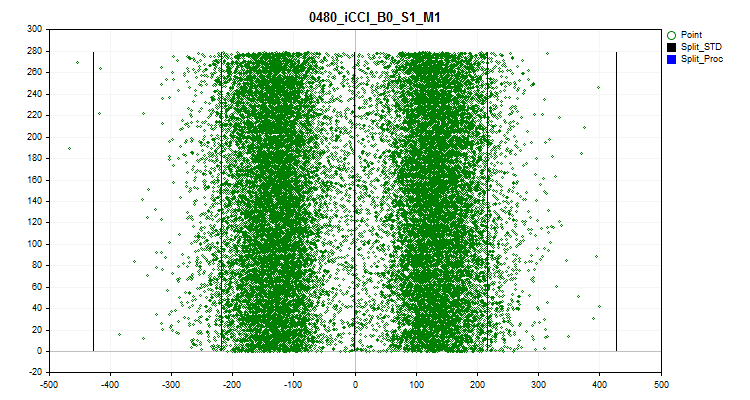
図11:スパイク
2グラフの幅 (ピクセル単位)
3 グラフの高さ(ピクセル単位)
4 グラフの凡例の曲線シンボルのフォントサイズとサイズ
設定シナリオの検索の構成
- 設定シナリオを実行する1
1埋め込みアルゴリズムに従って設定の検索をアクティブにします。詳細は以下をご覧ください。
2.量子化の効果を比較実験で評価する
実験の設定:目的
かなりの機能を備えたツールがあるので、その機能を評価するときが来ました。次の差し迫った質問に対する答えを得る実験をおこなってみましょう。
- 予測子用の量子化テーブルの選択に関するこれらすべてのアクションや操作には意味があるのでしょうか。デフォルトのCatBoost設定を使用する方が簡単でないでしょうか。
- デフォルトのCatBoost設定と同様の結果を達成するには、最小分割 (境界) がいくつ必要でしょうか。
- 「均一」や「ランダム」などの量子化方法を使用する必要がありますか。
- 量子化テーブルの選択方法に大きな違いはありますか。
これらの質問に答えるには、Q_Error_Selectionスクリプトのさまざまな設定を使用して取得されたさまざまな量子化テーブルを使用して訓練を実行する必要があります。次の設定を試してみることをお勧めします。
選択方法
- 量子化テーブルの評価には、再構成 (近似) 誤差のみを使用
- 量子化テーブルの評価には、再構成(近似)誤差を量子化テーブルの分割数で割った値を使用(最大誤差は1%)
- 量子化テーブルの評価には、再構成(近似)誤差を量子化テーブルの分割数で割った値を使用(最大誤差は 0.5%)
量子化テーブルのソース
- CatBoostを使用して取得されたテーブル
- 均一量子化法により得られたテーブル
- ランダム分割法を使用して取得されたテーブル
量子化テーブルの設定
- 1:ソースディレクトリ内の使用可能なすべての量子化テーブルを使用
- 2:16の分割または間隔を持つ量子化テーブルのみをを使用
- 3:32の分割または間隔を持つ量子化テーブルのみを使用
- 4:64の分割または間隔を持つ量子化テーブルのみを使用
- 5:128の分割または間隔を持つ量子化テーブルのみを使用
- 6:256の分割または間隔を持つ量子化テーブルのみを使用
すべての設定の組み合わせが図12の形式で表に表示されます。コードでは、このタスクは3つのネストされたループの形式で実装されており、[設定シナリオを反復処理する]という設定内の変数をtrueに設定することでアクティブ化される対応する設定を変更します。
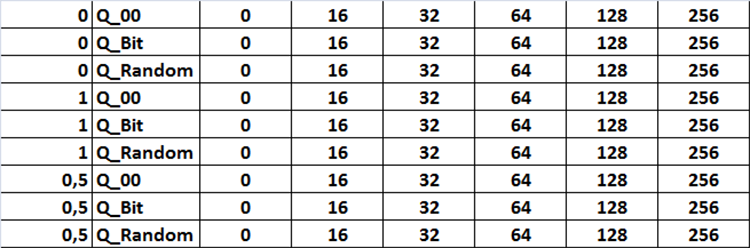
図12:検索設定の組み合わせ一覧表
設定の各組み合わせで101個のモデルを訓練し、シードパラメータを0から800まで8段階で移動します。これにより、無作為な結果を除外するために、得られた結果を平均して設定を評価できるようになります。
これらは、比較分析に使用することを提案するパラメータです。
- Profit_Avr:すべてのモデルの平均利益
- MO_Avr:モデルの平均数学的期待値
- Precision_Avr:モデルの平均分類精度
- Recall_Avr:モデルのリコールの平均完全性
- N_Exam_Model:3000ユニットを超える利益を示したモデルの平均数
- Profit_Max:すべてのモデルの平均最大利益
指標を計算した後、それらを合計し、指標の数で割ることを提案します。したがって、量子化テーブルの選択の設定の品質の一般的な指標を取得します。これを単にQ_Avrと呼びます。
実験用のデータを準備する
サンプルを入手するには、「PythonやRの知識が不要なYandexのCatBoost機械学習アルゴリズム」でCatBoost について説明したときに使用したのと同じEAとスクリプトを使用します。
次の設定を使用しました。
A.テスターの設定
- 銘柄: EURUSD
- 時間枠: M1
- 2010年1月1日から2023年9月1日まで
B.CB_Exp EA戦略設定
- 期間:104
- 時間枠:2分
- MA法: 平滑化
- 価格計算ベース: 終値
サンプルを受け取り、それを3つの部分(訓練、テスト、試験)に分割した後、記事の前半で説明したのと同様の方法で量子化テーブルを取得する必要があります。これを実現するために、CB_Batスクリプト(この記事に添付)を変更しました。ここで、「オブジェクトの検索」設定で Brut_Quantilization_gridを選択すると、スクリプトによって_01_Quant_All.txtファイルが作成されます。範囲を検索するための設定は変わりません。変数の初期値と最終値、および変更手順が設定されます。8から256まで8ステップで検索してみました。スクリプト操作の結果、すべてのタイプの量子化テーブルを取得するためのコマンドが、指定された数の境界で準備されます。量子化テーブルファイルの命名構造は、「量子」セマンティックファイル名の形式のファイル名、区切り文字の数、および分割タイプの通し番号です。パラメータはアンダースコアでリンクされ、ファイル自体はプロジェクトの設定ディレクトリと同じQディレクトリに保存されます。
quant_"+IntegerToString(Seed,3,'0')+"_"+IntegerToString(ENUM_feature_border_type_NAME(Q),0)+".csv";
スクリプトを実行した後、結果の_01_Quant_All.txtファイルの拡張子を*.batに変更し、スクリプトで以前に指定したCatBoostバージョンをファイルのあるディレクトリに配置し、ファイルをダブルクリックして実行します。
スクリプトが作業を終了すると、一連のファイルがQサブディレクトリに表示されます。これらは引き続き作業を続ける量子化テーブルです。
図13:Qサブディレクトリの内容
Q_Error_Otborスクリプトを使用して、間隔数16、32、64、128、256で均一および無作為な量子化テーブルを生成します。適切なファイルがQ_BitディレクトリとQ_Randomディレクトリに表示されます。Qディレクトリのコピーをプロジェクトディレクトリに作成し、新しいディレクトリにQ_00という名前を付けます。
これで、訓練 タスクパッケージを作成するために必要なものがすべて揃いました。Q_Error_Otborスクリプトを起動し、「Search settings scenarios」パラメータをtrueに切り替えて、[OK]をクリックします。スクリプトは、コードで指定されたシナリオに従って、量子化テーブルと訓練設定を含むファイルを作成します。
訓練中にCatBoost設定の各構成に量子化テーブルを使用するために、スクリプトは設定ファイルの名前をQuant_CB.csv量子化テーブルの名前に追加します。
CB_Bat_v_02スクリプトを使用して訓練用のファイルを取得しましょう。8ステップで0から800までシードを検索することを選択し、プロジェクトディレクトリを指定しました。
次に、訓練ファイルを少し編集して、ファイル名Quant_CB.csvをQuant_CB_%%a.csvに置き換える必要があります。この変更により、設定の名前を変数として使用できるようになり、その数によって訓練 サイクルの数が決まります。作成したファイルを設定プロジェクトディレクトリにコピーし、ファイル_00_Start.txtを_00_Start.batに名前変更し、_00_Start.batをダブルクリックして訓練を開始します。
実験結果の評価
訓練が完了したら、CB_Calc_Svodスクリプトを使用して各モデルのメトリクスを計算します。スクリプトの設定については、以前の記事で詳しく説明したので、繰り返しません。
また、デフォルトの量子化テーブル設定で101個のモデルを訓練しました。結果は次のとおりです。
- Profit_Avr=2810.17
- МО_Avr=28.33
- Precision _Avr=0.3625
- Recall_Avr=0.023
- N_Exam_Model=43
-
Profit_Max=8026
一般的な結論を導き出す前に、各パラメータの結果の表とグラフを詳しく見てみましょう。
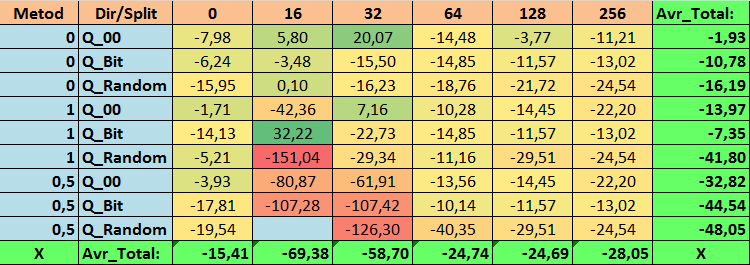
表14:Profit_Avrパラメータの要約値
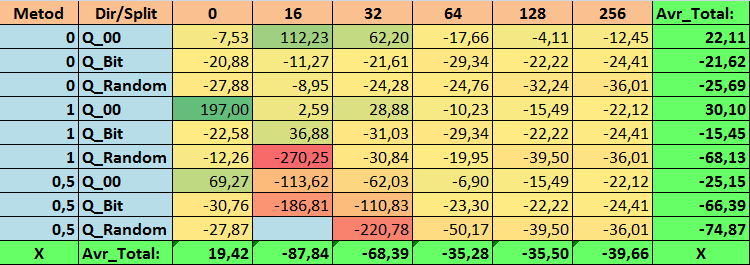
表15:MO_Avrパラメータの要約値
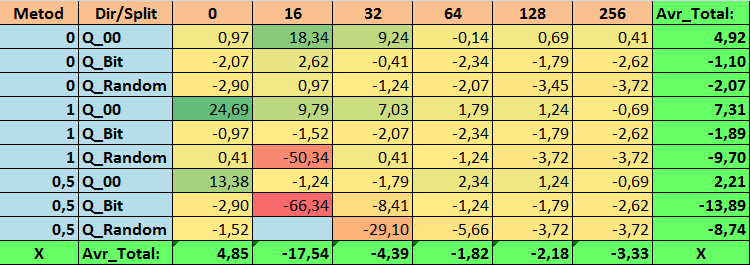
表16:Precision_Avrパラメータの要約値
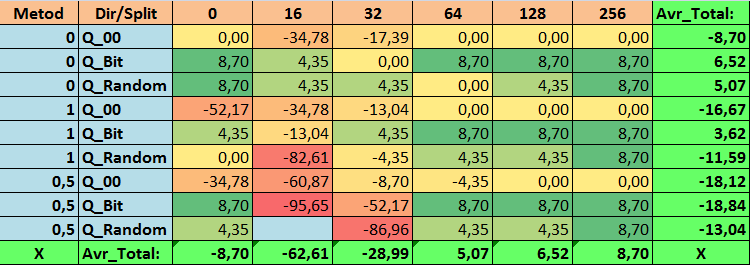
表17:Recall_Avrパラメータの要約値
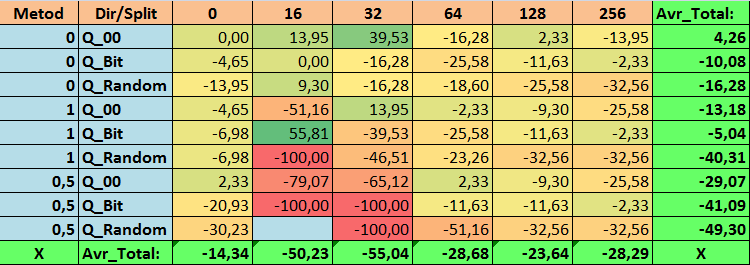
表18:N_Exam_Modelパラメータの要約値
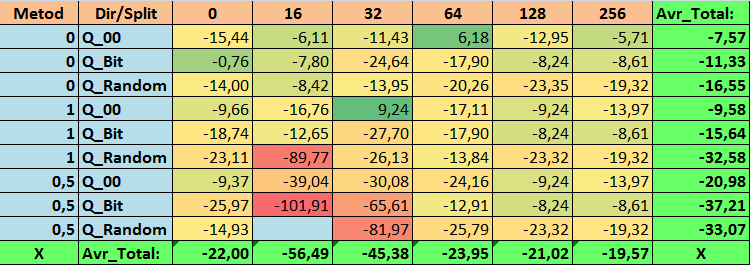
表19:Profit_Maxパラメータの要約値

表20:Q_Avrパラメータの要約値
有益な表を確認したところ、パラメータの広がりが非常に大きいことがわかりました。これは、設定全体が訓練の結果に及ぼす影響を示しています。無作為に分割を設定して取得したテーブル(Q_Random)は、他の方法で作成した量子化テーブルと比較して最も弱い結果を示したことがわかります。興味深いことに、Recall_Avrメトリクスを除いて、分割数の増加は一般にメトリクスのパフォーマンスの低下につながることがわかります。これはおそらく、量子セグメント内の情報が非常に分散しているため、訓練中の数学的操作(モデルの信頼性の向上で終了)だけでなく、精度の低下、ひいては平均利益の低下につながるという事実によるものと考えられます。デフォルトで254の分割を使用して、モデルがどのようにして正常に訓練されるのかと疑問に思われるかもしれません。 実際、私はGreedyLogSumと呼ばれるデフォルトのグリッド構築メソッドを使用しています。これは、前に見たように、均一ステップでグリッドを構築しません。グリッドは均一に構築されていないため、グリッド構築の品質を評価するために私たちがよく選択する指標は、均一なグリッドよりも悪い結果を示します。その結果、すべてのCatBoostメソッドによって取得されたセットから量子化テーブルを選択するときに、GreedyLogSumなどのメソッドが選択されることはほとんどありません。この方法が選択された頻度に関する統計を確認することもできます。例えば、(0;Q_00;256)の組み合わせの場合、これは2408個の予測子のうち121個のみに当てはまります。なぜ予測範囲の極端な部分がこれほど重要になるのでしょうか。コメントにあなたの仮説を書いてください。
多数の分割を含むテーブルや、分割を無作為に設定する方法を使用したテーブルでは、あまり良い結果が得られませんでした。しかし、量子化テーブルの選択方法の違いについては何が言えるでしょうか。悪いニュースから始めましょう。0.5%の誤差の要件は、16~64のテーブル値にとっては高すぎることが判明しました。その結果、訓練に参加した予測子の数は当初よりも大幅に減りましたが、同時に、多数の分割を含むテーブルはこの閾値を正常に超えることができましたが、すでに示唆したように、これは効率的ではありませんでした。ただし、利用可能なすべてのテーブルから選択した場合、結果は比較的バランスのとれたテーブル(特にCatBoostテーブルのセット)でした。同時に、要件がそれほど厳しくない(近似誤差が最小1%)予測子の選択方法は、より注目に値する解決策であることがわかりました。
さて、提起された質問に答えることに移りましょう。結局のところ、質問に答えることがこの実験の目標です。
答え
1. CatBoostのデフォルトの量子化テーブルは、データに関して客観的に良好な結果を示していますが、大幅に改善できることが判明しました。量子化テーブルを取得するための最適な方法のメトリクスを見てみましょう。
- Profit _Avr - (1;Q_Bit;16)の組み合わせは、基本設定を32.22%超えています。
- MO_Avr - (1;Q_00;0)の組み合わせが基本設定を197.00%超えています。
- Precision_Avr - (1;Q_00;0)の組み合わせは、基本設定を24.69%超えています。
- Recall_Avr – ここにはたくさんの組み合わせがあります。いずれも基本設定を8.7%超えています。
- N_Exam_Model - (1;Q_Bit;16)の組み合わせは、基本設定を55.81%超えています。
- N_Profit_Max - (1;Q_00;32) の組み合わせは、基本設定を 9.24%超えています。
したがって、この質問に対して客観的に肯定的な答えを与えることができます。私たちにとって重要なメトリクスの結果を向上させることができる、最適な量子化テーブルを選択することは価値があります。
2.このサンプルでは、Q_Avrパラメータの適切な値を取得するには、16分割だけで十分であることがわかりました。例えば、(1;Q_Bit;16)の場合は16.28、(0;Q_00;16)の場合は18.24となります。
3.統一された方法は非常に効率的であることがわかりました。特に興味深いのは、(1;Q_Bit;16)の組み合わせで最も多くのモデルを取得でき、基本設定を 55.81%上回ったという事実です。基本設定を36.88%上回り、数学的期待の点で最高の結果の1つを示したことを考えると、量子化テーブルを選択するとき、および機械学習に関連する他のプロジェクトに実装するときに、この方法を使用する価値があると思います。ランダム分割法によって取得されたテーブルに関しては、量子化テーブルを選択するための特定の基準の閾値を通過できない場合、このアプローチは(おそらく選択的に)慎重に使用する必要があります。予測子の量子セグメントへの最適な分割を見つけるには、10,000のオプションでは十分ではない可能性があります。
4.実験結果が示したように、量子化テーブルの選択方法は結果に大きな影響を与えます。ただし、1つの実験だけでは、いずれかの方法のみを使用することを自信を持って推奨するには不十分です。さまざまな方法とその設定により、モデルはさまざまな量子化テーブルを選択することで、サンプル内のデータのさまざまな部分に注意を集中させることができ、最適解を見つけるのに役立ちます。
結論
この記事では、量子化テーブルを選択するためのアルゴリズムを理解し、量子化テーブルの選択の実現可能性を評価するために大規模な実験を実施しました。データ前処理の他の方法は、コードを分析したり、これらの方法の効率を評価したりすることなく、表面的に確認されました。一連の実験を実施してその結果を説明するのは、多大な労力を要する作業です。この記事が読者の興味を引くならば、他の記事で実験や説明をおこなうかもしれません。
この記事ではバランスチャートを使用していません。モデルの優れた例はいくつかありますが、より多くの予測子を使用して、金融市場での実際の取引のためのモデルを選択し、構築することをお勧めします。
量子化テーブルを選択するために近似スコアが使用されましたが、データの均一性と有用性を評価できる他のスコアを試してみる価値はあります。
| # | ファイル | 詳細 |
|---|---|---|
| 1 | Q_Error_Otbor.mq5 | データの前処理と各予測子の量子化テーブルの選択を担当するスクリプト |
| 2 | CB_Bat_v_02.mq5 | CatBoostを使用してモデルを訓練するためのタスクを生成するスクリプト(新バージョン2.0) |
| 3 | CSV fast.mqh | CSVファイルを操作するためのクラス。プログラムコードのすべての著作権はAliaksandr Hryshynに属します。不足しているファイルをここからダウンロードしてください。 |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13648
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 ニューラルネットワークの実験(第7回):指標の受け渡し
ニューラルネットワークの実験(第7回):指標の受け渡し
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索