
取引におけるトレンド基準

はじめに
すべてのトレーダーは「トレンドはあなたの友達である」というフレーズを知っています。実際、トレンドに沿った価格変動は非常に大きな利益をもたらすことがあります。トレンドトレーディングは、価格の動きが同じ方向に継続するという仮定に基づいています。このタイプの取引における主な問題は、トレンドの開始と終了のタイミングを十分な精度で判断することです。
現在、トレンドパラメータを定義して計算するための多くのアプローチがあります。本記事では、その中でも特に興味深いものを見ていき、実践への応用を試みます。
平滑化とトレンド
価格の動きは、単純なモデルで表現できます。時間に依存する決定的な要素があり、さらに、予測不可能に振る舞うランダムな要素が加わります。トレーダーが直面する課題の一つは、このランダム要素の影響を何とか減らすことです。
最も単純なフィルターの一つは単純移動平均(SMA)です。しかし、この指標には一つ大きな欠点があります。それは遅延が生じることです。ここで、トレンドをシミュレーションし、期間3のSMAを適用してみます。
| トレンド | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| SMA | - | - | 1 | 2 | 3 | 4 |
次に、この遅延を取り除く方法を試してみます。SMAの式は次の通りです。
![]()
ここに、1バーあたりの平均価格変化に等しい補正を加えます。
![]()
新しい指標の比率がどのように変化するかを見てみましょう。
![]()
この比率を用いた指標は、トレンドをより正確に捉えます。この指標を任意の価格数に一般化できます。期間4の指標計算は次のようになります。
まず、SMAの値を求めます。
![]()
平均価格変化に対する補正が2つあります。
![]()
![]()
言い換えると、SMAの中心に対する平均価格変化を計算します。すると、指標の式は次のようになります。
![]()
特に短期間では、この指標とSMAの差が顕著に現れます。
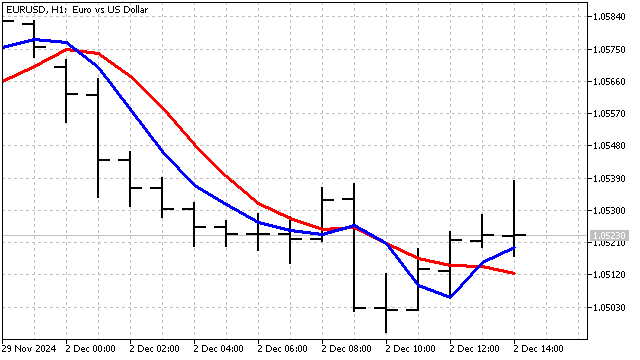
このアプローチの主な欠点は、指標期間を選択する明確な基準がないことです。トレーダーは、自身の判断に基づき任意に期間を選択する必要があります。
次に、期間に依存しない指標を作成してみます。Vという時系列があり、1ステップ先を予測したいとします。予測には最も単純な方法を使用します。すなわち、過去の動きが未来を決定づけると仮定します。たとえば、Vの初期値がある場合、1ステップ先の予測はこの値に等しくなります。
![]()
新しいVの値が現れると、予測値とVの半和を計算します。この結果が次のステップの予測値になります。
![]()
言い換えると、時系列の新しい値が現れるたびに予測が調整されます。この予測方法は、比率0.5の指数平滑化に相当します。
次に予測アプローチを少し変更します。予測変化が同じ強度で起こると仮定します。
![]()
言い換えると、すべての予測値は線形トレンド上に属します。この原理に基づく指標の式は次の通りです。
![]()
この指標は再帰的です。つまり、現在の指標値を計算するには過去の値を使用します。しかし、このままでは不安定になります。比率の一つが1だからです。この問題を解決するために、Indicator[i+1]にも同じ再帰を適用します。
![]()
この指標は現在、2期間のSMAと過去の指標速度の半分から構成されます。さらに指標をより堅牢にするために、もう一つ変更を加えます。
![]()
これは、期間3の類似EMAと比較した新しい指標の様子です。
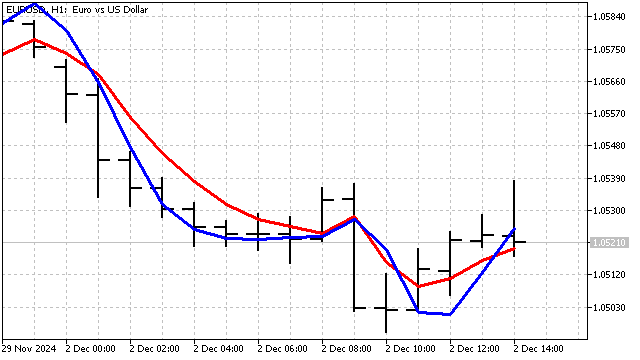
残念ながら、ノイズを完全に抑えることはほぼ不可能です。しかし、価格変動におけるトレンド成分を識別することは十分に可能です。両方の指標はトレンドパラメータの変化に敏感であり、遅延は最小限に抑えられます。これらの指標は、価格平滑化のために単独で、あるいは他の指標のデータ源として使用することもできます。
トレンドの基準
トレンドの基準は、むしろ「ランダム性の基準」と呼ぶ方が正確です。その適用の本質は極めてシンプルです。この基準を使えば、価格系列のランダム性の度合いを確認できます。基準が系列がランダムではないことを示す場合、それはトレンドであると言えます。ここでは、考えられる基準とそれらをテクニカル分析でどのように活用できるかを見ていきます。
アッベの基準:この基準は、分散を2つの異なる方法で計算することに基づいています。通常の標本分散はトレンドに敏感です。一方、アラン分散ではトレンドの影響がほぼゼロになります。これらの分散を比較することで、価格変動に対するトレンド成分の寄与を推定できます。
この基準を取引で使うために、計算方法を少し変更します。
![]()
この基準はトレンドの存在のみを示します。トレンドの方向は、別の方法で判断する必要があります。
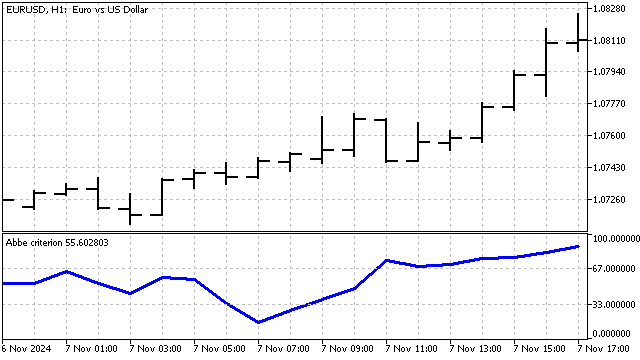
この基準は、トレンド変化の瞬間を特定するのに役立ちます。
一次差分の符号基準:この基準は非常にシンプルで直感的です。N個の価格を取得し、それらを連続するペアに分けます。ペアの数はN-1になります。それぞれのペアに対して符号関数を適用します。
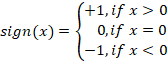
その後、基準値を算出します。
![]()
RSIでも同じアプローチが用いられていますが、上下の価格変動は符号を無視して別々に計算されます。
この統計の欠点は、符号の出現順序を区別しないことです。言い換えると、価格を入れ替えても同じ結果になります。この欠点を解消するために、符号の出現順に応じて重みを付与します。すると基準の計算は次のようになります。
![]()
これにより、符号列は一意となり、2つの時系列が類似している場合にのみ同じ結果が得られます。
この基準をテクニカル分析でどのように使用できるかを見てみましょう。この基準で得られる値は、厳密に限定された範囲内に収まります。直感では、ゼロに近い値がより一般的である可能性があります。しかし、必要な検証をおこなう方が望ましいです。
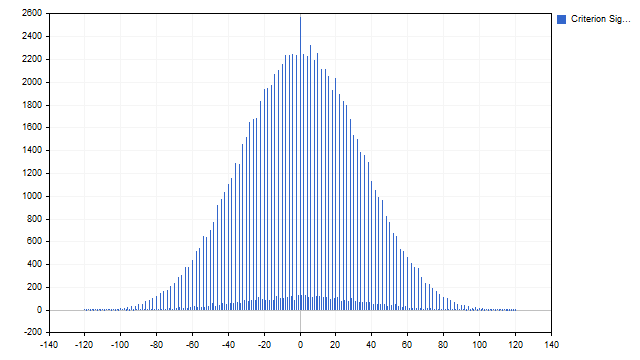
この仮定は正しいことがわかりました。厳密な取引の言葉では、経験的確率関数を得たことになります。この特徴から何が学べるでしょうか。買われすぎ/売られすぎのレベルを設定できます。ここではこのレベルを33%に設定しました。指標は、最低値および最高値の1/3を判別します。残りの中間の1/3はフラットです。指標自体は次のようになります。
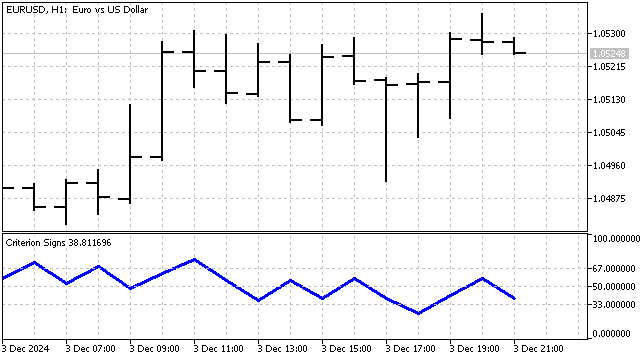
符号基準は非パラメトリックです。このような基準の主な利点は、安定性が高く、急激な価格変動に対して鈍感であることです。
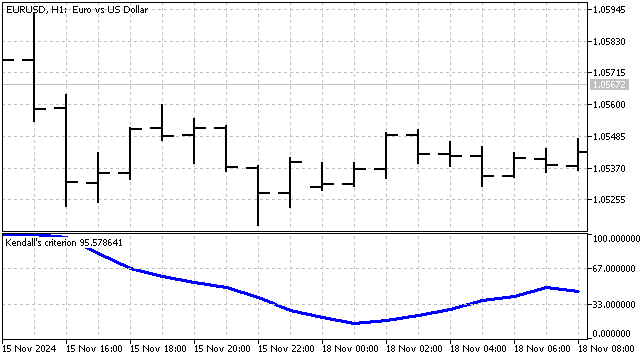
ケンドールの基準:この基準も符号関数に基づいています。しかし、符号関数の適用方法はやや異なります。
この基準の計算は二段階で行います。まず、各価格について、それ以前のすべての価格との符号の合計を求めます。
![]()
次に、これらの値の総和を求めます。
![]()
この基準では、すべての価格の組み合わせに対して上昇と下降の回数を比較します。これにより、トレンドの方向と強さをより正確に評価できます。
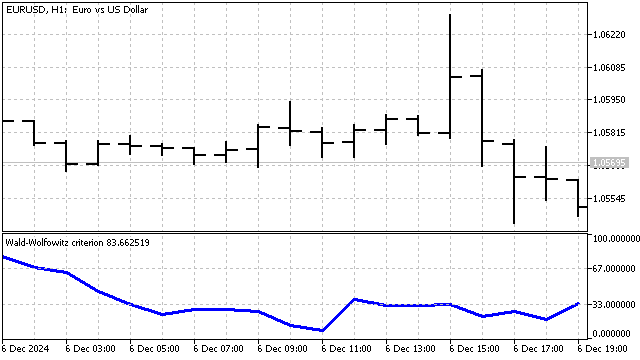
Wald-Wolfowitz順位検定:この基準を計算するには、各価格の順位を知る必要があります。順位は、現在の価格より低い価格の数です。たとえば、次の5つの価格値を考えます。
| インデックス | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 価格 | 1.05702 | 1.05910 | 1.05783 | 1.05761 | 1.05657 |
| 順位 | 1 | 4 | 3 | 2 | 0 |
インデックス0の価格はインデックス4の価格より高いため、順位は1になります。インデックス1の価格は他のすべての価格より高く、その順位は4です。他の価格も同様に計算します。
この基準の本質は極めてシンプルです。価格がトレンドを形成する場合、順位も整理されます。逆に、順位がランダムに混ざっている場合は、価格が不規則に動いていることを示します。この例では、価格は部分的に順序付けられており、トレンドの存在を示している可能性があります。
基準値は次の式で計算されます。
![]()
本質的に、この基準は自己相関関数の堅牢なバリエーションです。この基準に基づいて構築された指標は次のようになります。
Foster-Stewart基準:この基準では、平均と分散の両方におけるトレンドの存在を同時に評価できます。トップ値およびボトム値の記録数をカウントすることに基づいています。各価格に対して、2つの変数HとLを求めます。
変数Hは、現在の価格がこれまでのすべての価格より高い場合1となります。変数Lは、現在の価格がこれまでのすべての価格より低い場合1となります。それ以外の場合、これらの変数は0です。基準パラメータは次のように計算されます。
![]()
![]()
Tパラメータはトレンドの強さと方向を示します。Dパラメータはアッベ基準に似ており、トレンドの存在のみを示します。これらのパラメータは、単独でも組み合わせても使用できます。
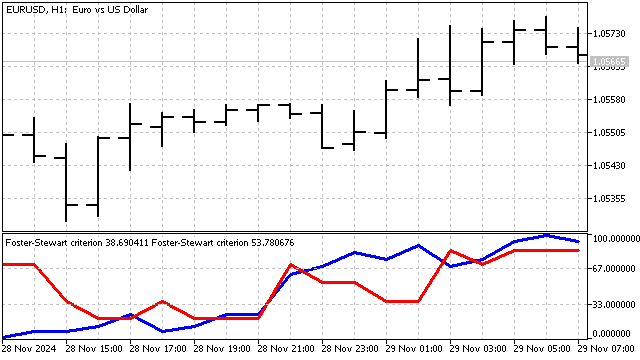
この基準は、2つのパラメータを同時に考慮するように近代化することも可能です。古典的なバージョンでは、TまたはDの値が十分に大きければトレンドが成立しているとみなせます(もちろんTは絶対値を取る必要があります)。したがって、トレンド発生時には、これらのパラメータの積がゼロから大きく逸脱します。このアプローチにより、最も強いトレンドを特定できます。
次に、これらの基準を取引でどのように活用できるかを見ていきます。
取引戦略
残念ながら、トレンド基準はトレンドの始まりについては何も示してくれません。示すのは、トレンドが発生したという事実だけです。この性質を取引に応用することが可能です。すなわち、強いトレンドの後には、価格の動きの方向が反対に変わる可能性があるということです。
この仮定を使って、シンプルな戦略を作成できます。トレンド基準がある最小値に達した場合は、買いポジションを開きます。売りポジションを開く場合は、基準が最大値に達したときです。言い換えると、トレンド基準は買われすぎ/売られすぎの状態を判断するために使用されます。このアプローチは有望に見えます。
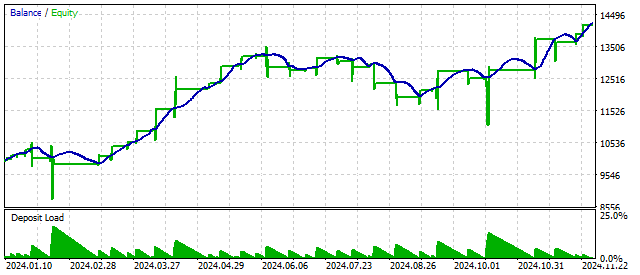
追加のフィルターを使用することで、戦略のパフォーマンスを向上させることができます。アッベ基準はそのようなフィルタとして利用可能です。ここで改めて説明すると、この基準はトレンドの存在のみを判断します。トレンドの方向は、別の方法で判断する必要があります。たとえば、価格変動の平均速度を使ってトレンドを判断します。
![]()
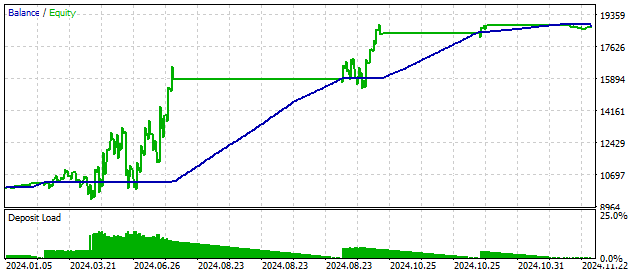
得られた値があるレベルを上回るか下回る場合に、トレンドが確立していると見なします。この仮定を確認するために、アッベ基準を使用します。基準値が一定のレベルを超えていれば、トレンドの仮定は正しいと判断できます。ポジションの開閉は前の例と同様におこないます。この戦略の結果は次のようになります。
Foster-Stewart基準を使用すると、トレンドの存在と方向の両方を同時に評価できます。言い換えると、この基準はシグナルとフィルタの両方として機能することができます。この基準の適用により、次のような結果が得られます。
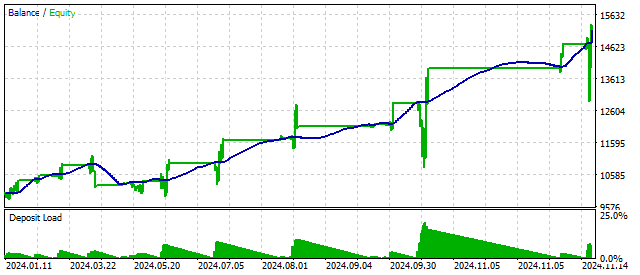
さらに近代化されたバージョンでは、異なる結果を得ることも可能です。
トレンド基準の使用は十分に妥当ですが、いくつかの課題も伴います。
- 偽シグナルの数を減らすために、追加のフィルタを使用する必要があります。
- リスクや証拠金の負担を減らすために、ポジションを閉じるための個別のルールが必要です。
- トレンド基準は処理する価格の数に敏感な場合があります。そのため、適用には時系列の事前平滑化が必要な場合があります。短期間の場合は、平滑化が必須です。
結論
現在、トレンド基準は数十種類存在します。これらの基準を活用することは、市場状況の分析と取引の両方において有用です。
この記事を書くにあたり、以下のプログラムを使用しました。
| 名前 | 種類 | 詳細 |
|---|---|---|
| tSMA | 指標 | SMAのトレンド類似物
|
| tEMA | 指標 | 期間3のEMAのトレンド類似物 |
| Abbe criterion | 指標 | Abbe criterion |
| Criterion Signs | 指標 | 最初の差異の符号の基準 |
| scr Criterion Signs | スクリプト | 符号基準値の分布を評価可能
|
| Kendall's criterion | 指標 | Kendall's criterion |
| Foster-Stewart criterion | 指標 | Foster-Stewart criterion
|
| Foster-Stewart criterion I | 指標 | Foster-Stewart基準の近代化版 |
| Wald-Wolfowitz criterion | 指標 | Wald-Wolfowitz criterion |
| EA 3 criterions | EA | 3つの基準に従った自動売買
|
| EA Abbe criterion | EA |
|
| EA Foster-Stewart criterion | EA |
|
| EA Foster-Stewart criterion I | EA |
|
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16678
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
やってみますピボット・ポイントの定義など、他にも興味深い基準がいくつかある。もっと簡単に説明する方法を考えなければならない。
テスターの何が問題なのかわからない。
ありがとう、試してみるよ。それを検出するための基準や数学的なメカニズムの説明はどこにあるんだい?科学的な情報源のようですが.
ありがとう、試してみるよ。その検出の基準や数学的なメカニズムについての説明はどこにありますか?科学的な情報源のようですが.
多くの文献がありますが、すべての基準はほとんどあちこちに散らばっています。ここに様々な基準の良い選択がある
私はあなたの論文で述べられているWald-Wolfowitzトレンド基準の実用的な適用に取り組んでいます。私が理解しているように、Wald-Wolfowitz基準はデータのランダム性/定常性の仮説を検証します。エキスパートアドバイザーのコードでは、インジケータが何を返すかを理解することが重要です。
インジケータは、ウォルド・ウォルフォウィッツ基準に基づいて、一連の価格(この場合はオープン値)がランダムである確率(パーセント)を計算します。
結果はバッファ buffer[0] に保存され、確率のパーセンテージ (0 から 100 まで) を表します。
値が100%に近いほど、ランダムである(傾向がない)確率が高い。
0%に近いほど、非ランダム性(トレンドまたはクラスタリングの存在)の確率が高くなります。
計算ロジック:
このインディケータは、選択した期間( iPeriod )のオープン値をランク付けし、ランクに基 づいて統計値を計算し、CDF (経験分布関数)を使用してパーセンテージ値に変換します:
グラフのレベル:
indicator_level1=33とindicator_level2=67は、解釈のためのベンチマークです:
<33% - 強い非ランダム性(傾向の可能性)。
<33% - 強い非ランダム性(トレンドの可能性) >67% - 高いランダム性(横ばい)。
この記事の指標の解釈は正しいですか?
私はあなたの論文で述べられているWald-Wolfowitzトレンド基準の実用的な適用に取り組んでいます。私が理解しているように、Wald-Wolfowitz基準はデータのランダム性/定常性の仮説を検証します。エキスパート・アドバイザーの取引コードでは、インジケータが具体的に何を返すのかを理解することが重要です。
このインジケータは、ウォルド・ウォルフォウィッツ基準に基づいて、一連の価格(この場合はオープン値)がランダムである確率(パーセント)を計算するというのが正しい理解でしょうか。
結果はバッファbuffer[0]に保存され、パーセンテージの確率を表します(0から100まで)。
値が100%に近いほど、ランダムである(トレンドがない)確率が高くなります。
値が0%に近いほど、非ランダム性(傾向またはクラスタリングの存在)の確率が高くなります。
計算ロジック:
このインジケータは、選択した期間( iPeriod )のオープン値をランク付けし、ランクに基づいて統計値を計算し、CDF (経験分布関数)を使用してパーセンテージ値に変換します:
グラフのレベル
indicator_level1=33とindicator_level2=67は、解釈のためのベンチマークです:
<33% - 強い非ランダム性(傾向の可能性)。
>67% - 高いランダム性(横ばい)。
この記事の指標の解釈は正しいですか?
はい、すべて正しく理解しています。ただ、私が33と67のレベルを設定したのは、いくつかのレベルが必要だったからです。他のレベル、例えば25と80を設定することもできます。
はい、すべて正しく理解しています。ただ、私がレベル33と67を設定したのは、単にいくつかのレベルが必要だったからだ。他のレベル、例えば25と80を設定することもできる。
ご回答ありがとうございました。