
古典的な戦略を再構築する(第11回):移動平均クロスオーバー(II)

以前、移動平均線のクロスオーバーを予測するというアイデアについて取り上げました。その記事はこちらのリンクからご覧いただけます。私たちは、価格の変化そのものよりも、移動平均線のクロスオーバーの方が予測しやすいことを確認しました。本日は、この馴染みのある問題に対して、まったく異なるアプローチで再び挑戦します。
今回は、このアプローチが取引戦略にどの程度の影響を与えるのか、そしてどのようにして皆さんの取引戦略の改善につながるのかを徹底的に検証していきます。移動平均線のクロスオーバー戦略は、最も古典的な取引戦略のひとつです。しかし、広く知られているがゆえに、この手法を用いて利益を上げる戦略を構築するのは容易ではありません。それでも、本記事を通じて「古い手法でも新しい工夫次第で進化できる」ことをお見せしたいと思います。
比較をより実証的に行うために、まずは以下のインジケーターのみを用いて、MQL5でEUR/GBPペアの取引戦略を構築します。
- 終値に適用する2本の指数移動平均線:1つは期間が20に設定され、もう1つは60に設定されています。
- デフォルト設定の5,3,3が適用されたストキャスティクスオシレーター:指数移動平均モードに設定され、CLOSE_CLOSEモードで計算をおこなうように設定されています。
- 14期間のAverage True Rangeインジケーター:テイクプロフィットとストップロスのレベルを設定します。
バックテストの詳細なパラメータについてはこの記事の後半で詳しく説明します。ただし、バックテストではシャープレシオ、収益性の高い取引の割合、最大利益、その他の重要なパフォーマンス指標に注目して分析をおこないます。
バックテストが完了したら、すべての従来の取引ルールを市場データから学習したアルゴリズム取引ルールに慎重に置き換えます。予測を学習するために3つのAIモデルを訓練します。
- 将来のボラティリティ:ATRの読み取り値を予測するAIモデルを訓練することで実現します。
- 価格の変化と移動平均線のクロスオーバーの関係:移動平均線には2つの離散的な状態を定義し、一度に1つの状態のみに属するようにします。これにより、AIモデルは指標の重要な変化に注目し、それが将来の価格レベルに与える平均的な影響を学習できるようになります。
- 価格の変化とストキャスティクスオシレーターの関係:今回は、ストキャスティクスオシレーターを3つの離散的な状態に分類し、一度に1つの状態のみを取るようにします。モデルは、ストキャスティクスオシレーターの重要な変化の平均的な影響を学習します。
これら3つのAIモデルは、バックテストに使用する期間とは異なるデータで訓練されます。バックテストは2022年から2024年6月まで実行し、AIモデルの学習期間は2011年から2021年までとしました。訓練データとバックテストデータを明確に分けることで、モデルが未知のデータに対してどの程度適応できるのか、より正確に評価できるようにしています。
信じられないかもしれませんが、私たちはすべての主要なパフォーマンス指標を向上させることに成功しました。新しい取引戦略は、収益性が向上し、シャープレシオも改善され、バックテスト期間中に実施したすべての取引の55%で勝利しました。
このような古くから広く知られた取引戦略でも収益性を向上させることができるのであれば、どのような戦略であっても、適切な視点でフレームワークを再構築すれば、さらなる改善の余地があることを示しているのではないでしょうか。
多くのトレーダーは、自分の取引戦略を長年にわたって練り上げており、個人的な戦略について詳しく議論することはほとんどありません。したがって、移動平均線のクロスオーバーは、コミュニティ全体が共通のベンチマークとして活用できる中立的な議題となります。私は、本記事を通じて、読者の皆さんがご自身の取引戦略に応用できる汎用的なフレームワークを提供することを目指しました。このフレームワークを適用することで、皆さんの取引戦略にも何らかの改善がもたらされることを願っています。
はじめに
まず、MetaEditorIDEを起動し、ベースラインとなる取引アプリケーションの構築を開始します。
単純な移動平均クロスオーバー戦略を実装したいので、始めましょう。まず取引ライブラリをインポートします。
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/ja/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
グローバル変数を定義します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask;
テクニカルインジケーターのハンドラを作成します。
//+------------------------------------------------------------------+ //| Technical indicator handlers | //+------------------------------------------------------------------+ int slow_ma_handler,fast_ma_handler,stochastic_handler,atr_handler; double slow_ma[],fast_ma[],stochastic[],atr[];
また、いくつかの変数を定数として固定します。
//+------------------------------------------------------------------+ //| Constants | //+------------------------------------------------------------------+ const int slow_period = 60; const int fast_period = 20; const int atr_period = 14;
入力の一部は手動で制御する必要があります(ロットサイズやストップロスの幅など)。
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Money Management" input int lot_multiple = 5; //Lot size input group "Risk Management" input int atr_multiple = 5; //Stop Loss Width
システムが読み込まれたら、テクニカルインジケーターを設定し、市場データを保存する特別な関数が呼び出されます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our technical indicators and fetch market data setup(); //--- return(INIT_SUCCEEDED); }
それ以外の場合、取引アプリケーションをもう使用していない場合は不要になったリソースを解放します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); }
市場にポジションがない場合は、取引の機会を探します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } }
この関数はテクニカルインジケーターを初期化し、エンドユーザーが指定したロットサイズを保存します。
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); }
次に、更新された価格オファーを受け取ったときにそれを保存する関数を構築します。
//+------------------------------------------------------------------+ //| Fetch updated market data | //+------------------------------------------------------------------+ void update(void) { //--- Update our market prices bid = SymbolInfoDouble("EURGBP",SYMBOL_BID); ask = SymbolInfoDouble("EURGBP",SYMBOL_ASK); //--- Copy indicator buffers CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(slow_ma_handler,0,0,1,slow_ma); CopyBuffer(fast_ma_handler,0,0,1,fast_ma); CopyBuffer(stochastic_handler,0,0,1,stochastic); }
この関数は最終的に取引シグナルをチェックします。シグナルが見つかった場合は、ATR によって設定されたストップロスとテイクプロフィットでポジションに入ります。
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Can we buy? if((fast_ma[0] > slow_ma[0]) && (stochastic[0] > 80)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((fast_ma[0] < slow_ma[0]) && (stochastic[0] < 20)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
これで、取引システムをバックテストする準備が整いました。上記で定義した単純移動平均クロスオーバー取引アルゴリズムを、EURGBPの日足データで訓練します。バックテスト期間は2022年1月初旬から2024年6月末までとなります。Forwardパラメータをfalseに設定します。市場データは、ターミナルがブローカーに要求する必要がある実際のティックを使用してモデル化されます。これにより、テスト結果がその日に発生した市場状況を厳密に再現することが保証されます。
図1:バックテストの設定の一部
図2:バックテストの残りのパラメータ
初回のバックテストの結果は芳しくありませんでした。私たちの取引戦略は、テスト全体を通して損失を出していました。しかし、これは驚くべきことではありません。というのも、移動平均線のクロスオーバーが遅行する取引シグナルであることは既に分かっているからです。下の図3は、テスト中の取引口座の残高をまとめたものです。
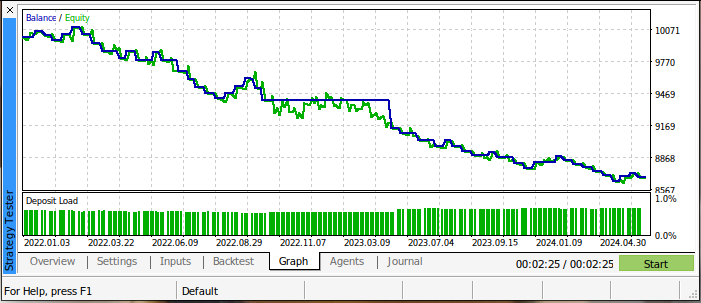
図3:バックテストを実施した際の取引口座の残高
シャープレシオは -5.0 で、実行した全取引の69.57%で損失を出し、平均損失は平均利益を上回っていました。これらは非常に悪いパフォーマンス指標です。この取引システムを現在のまま使用すれば、間違いなく速やかに資金を失うことになるでしょう。
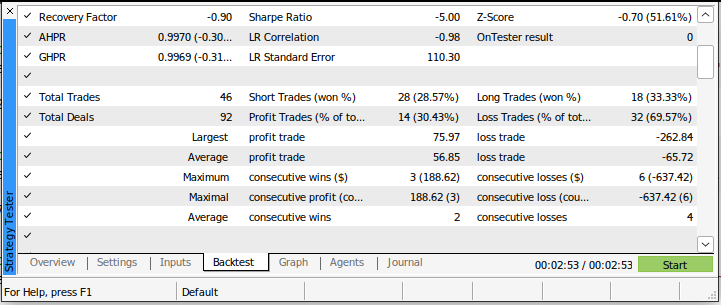
図4:従来の市場取引手法を用いたバックテストの詳細
移動平均線のクロスオーバーとストキャスティクスオシレーターに依存する戦略は、広く活用されており、人間のトレーダーが利用できるような実質的な優位性を持つ可能性は低いと考えられます。ししかし、これはAIモデルが学習できる優位性が存在しないことを意味するわけではありません。私たちは、市場の現在の状態をAIモデルに表現するために、「ダミーエンコーディング」と呼ばれる特別な変換を採用します。
ダミーエンコーディングは、順序のないカテゴリ変数を扱う際に使用され、その変数が取り得る値ごとに1つの列を割り当てます。例えば、MQL5のチームがMetaTrader 5のインストール時にカラーテーマを選択できるようにしたとします。選択肢は「赤」「ピンク」「青」の3つです。この情報を記録するために、「赤」「ピンク」「青」という3つの列を持つデータベースを作成します。インストール時に選択した列には1が設定され、他の列は0のままになります。これがダミーエンコーディングの基本的な仕組みです。
ダミーエンコーディングが強力なのは、情報の表現方法によってはAIモデルが誤った関係性を学習してしまう可能性があるためです。例えば、「1=赤」「2=ピンク」「3=青」と数値で表現すると、AIモデルはデータに存在しない関連性を学習し、「2.5が最適な色である」といった誤った結論を導き出すことがあります。そのため、ダミーエンコーディングを用いることで、AIモデルが与えられたデータにスケールがあると誤認しないようにすることができます。
私たちの移動平均は2つの状態を持ちます。短期移動平均が長期移動平均を上回っている場合、1つ目の状態がアクティブになります。それ以外の場合、2つ目の状態がアクティブになります。一度にアクティブになれるのは1つの状態のみであり、価格が同時に両方の状態にあることは不可能です。同様に、ストキャスティクスオシレーターには3つの状態があります。1つ目は価格がインジケーターの80を超えている場合にアクティブになり、2つ目は価格が20を下回っている場合にアクティブになります。それ以外のケースでは、3つ目の状態がアクティブになります。
アクティブな状態には1を設定し、その他の状態には0を設定します。この変換によって、価格がインジケーターの異なる状態を移行する際のターゲットの平均的な変化を、モデルが学習できるようになります。これは、プロのトレーダーがおこなっていることと近いものです。取引はエンジニアリングとは異なり、ミリ単位の精度を求めるものではありません。むしろ、優れたトレーダーは長い時間をかけて「次に何が起こる可能性が高いのか」を学習していきます。ダミーエンコーディングを活用してモデルを訓練することで、モデルも同様の学習をおこないます。つまり、テクニカルインジケーターの現在の状態を考慮しながら、価格の平均的な変化を学習するようにモデルのパラメータを最適化するのです。
図5:EURGBP日足データの視覚化
AIモデルを構築するための最初のステップは、必要なデータを取得することです。本番環境で使用するのと同じデータを取得することが常にベストプラクティスです。そのため、このMQL5スクリプトを使用して、MetaTrader 5ターミナルからすべての市場データを取得します。異なるライブラリ間で指標値の計算方法に予期せぬ違いがあると、最終的に満足のいく結果が得られない可能性があります。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_fast_handler,ma_slow_handler,stoch_handler,atr_handler; double ma_fast[],ma_slow[],stoch[],atr[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator ma_fast_handler = iMA(Symbol(),PERIOD_CURRENT,20,0,MODE_EMA,PRICE_CLOSE); ma_slow_handler = iMA(Symbol(),PERIOD_CURRENT,60,0,MODE_EMA,PRICE_CLOSE); stoch_handler = iStochastic(Symbol(),PERIOD_CURRENT,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR(Symbol(),PERIOD_D1,14); //--- Load the indicator values CopyBuffer(ma_fast_handler,0,0,size,ma_fast); CopyBuffer(ma_slow_handler,0,0,size,ma_slow); CopyBuffer(stoch_handler,0,0,size,stoch); CopyBuffer(atr_handler,0,0,size,atr); ArraySetAsSeries(ma_fast,true); ArraySetAsSeries(ma_slow,true); ArraySetAsSeries(stoch,true); ArraySetAsSeries(atr,true); //--- File name string file_name = "Market Data " + Symbol() +" MA Stoch ATR " + " As Series.csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MA Fast","MA Slow","Stoch Main","ATR"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), ma_fast[i], ma_slow[i], stoch[i], atr[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
探索的データ分析
ターミナルから市場データを取得したので、市場データの分析を始めましょう。
#Import the libraries import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
データを読み込みます。
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv")
データを視覚化するためにバイナリターゲットを追加してみましょう。
#Let's visualize the data data["Binary Target"] = 0 data.loc[data["Close"].shift(-look_ahead) > data["Close"],"Binary Target"] = 1 data = data.iloc[:-look_ahead,:]
データをスケーリングします。
#Scale the data before we start visualizing it from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
データを視覚化するためにplotlyライブラリを使用します。
import plotly.express as px
長期移動平均と短期移動平均が、市場の上昇と下降の動きを区別するのにどれだけ役立つかを見てみましょう。
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average fig = px.scatter_3d( data, x=data.index, y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of Time, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'Time', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
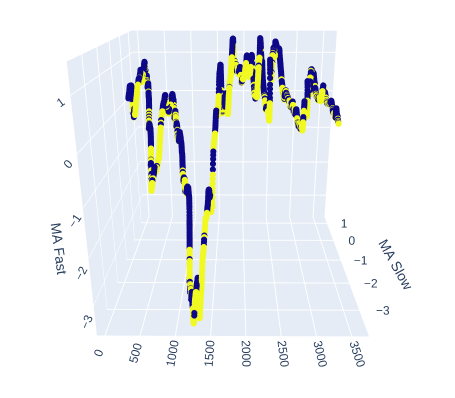
図6:移動平均と目標の関係を視覚化する
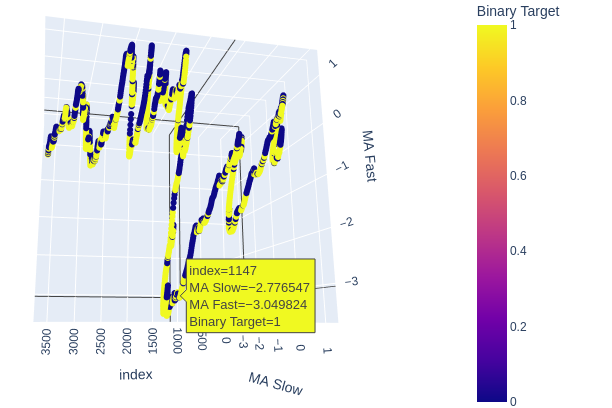
図7:移動平均線は、強気と弱気の価格変動を適度な程度に集約しているように見える
市場のボラティリティがターゲットに影響を及ぼすかどうかを見てみましょう。x軸の時間を置き換えて、代わりにATR値を配置すると、長期移動平均と短期移動平均の位置が維持されます。
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average and the ATR fig = px.scatter_3d( data, x='ATR', y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of ATR, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'ATR', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
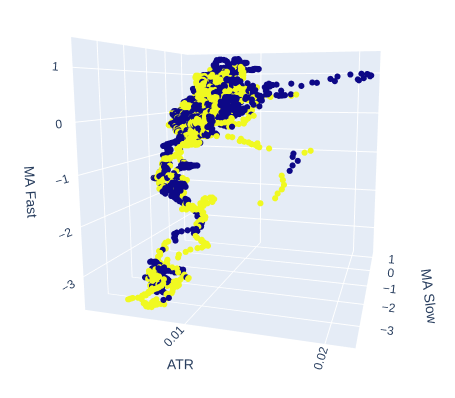
図8:ATRは市場の状況を明確にするのにほとんど役立っていないため、ボラティリティの読み値を少し変換する必要があるかもしれない
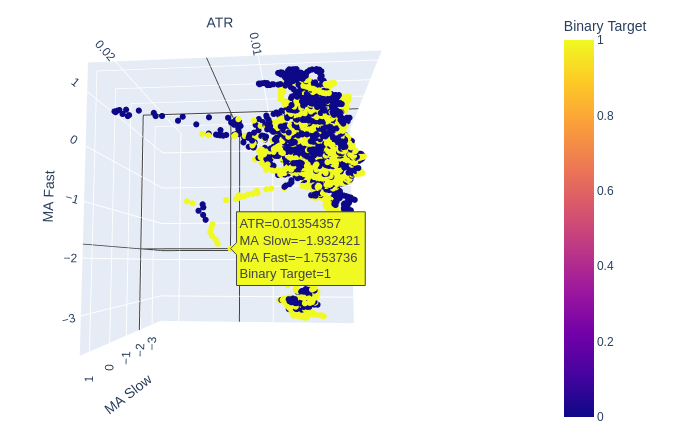
図9:ATRは強気と弱気の価格動向のクラスタを示しているようだが、クラスタは小さく、頻繁に発生しないため、信頼できる取引戦略の一部にはならないかもしれない
2つの移動平均とストキャスティクスオシレーターを組み合わせることで、市場データにまったく新しい構造が与えられます。
# Creating a 3D scatter plot of the slow and fast moving average and the stochastic oscillator fig = px.scatter_3d( data, x='MA Fast', y='MA Slow', z='Stoch Main', color='Binary Target', title="3D Scatter Plot of Time, Close Price, and The Stochastic Oscilator", labels={'x': 'Time', 'y': 'Close Price', 'z': 'Stochastic Oscilator'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
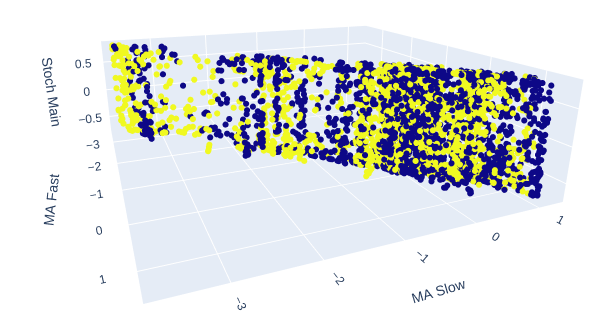
図10:ストキャスティクスのメインの読み値と2つの移動平均線は、明確に定義された強気と弱気のゾーンを示している
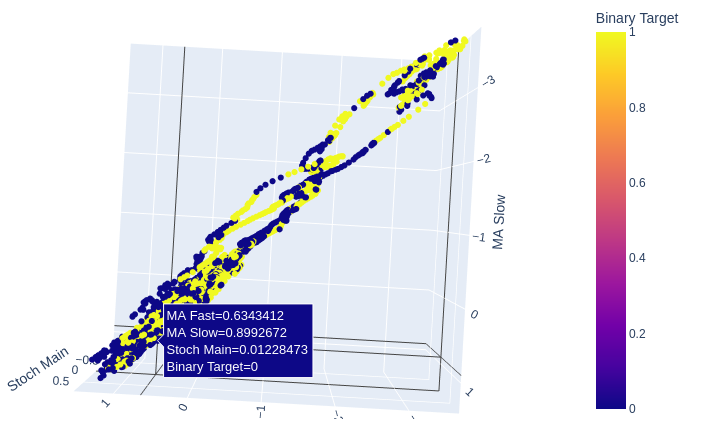
図11:2つの移動平均線とストキャスティクスの関係は、弱気の価格動向よりも強気の価格動向を明らかにするのに適しているかもしれない
3つのテクニカルインジケーターと4つの異なる価格クオートを使用しているため、データには7つの次元がありますが、視覚化できるのは最大で3次元までです。次元削減技術を使用することで、データを2つの列に変換できます。主成分分析は、このような問題を解決するために一般的に使用される手法です。このアルゴリズムを用いることで、元のデータセットのすべての列を2つの列にまとめることが可能です。
その後、2つの主成分の散布図を作成し、それらがターゲットをどの程度適切に表現しているかを評価します。
# Selecting features to include in PCA features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow']] pca = PCA(n_components=2) pca_components = pca.fit_transform(features.dropna()) # Plotting PCA results # Create a new DataFrame with PCA results and target variable for plotting pca_df = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2']) pca_df['target'] = data['Binary Target'].iloc[:len(pca_components)] # Add target column # Plot PCA results with binary target as hue fig = px.scatter( pca_df, x='PC1', y='PC2', color='target', title="2D PCA Plot of OHLC Data with Target Hue", labels={'PC1': 'Principal Component 1', 'PC2': 'Principal Component 2', 'color': 'Target'} ) # Update layout for custom size fig.update_layout( width=600, # Width of the figure in pixels height=600 # Height of the figure in pixels ) fig.show()

図12:最初の2つの主成分の散布図からランダムな部分を拡大し、それらが価格変動をどの程度分離できているかを確認する
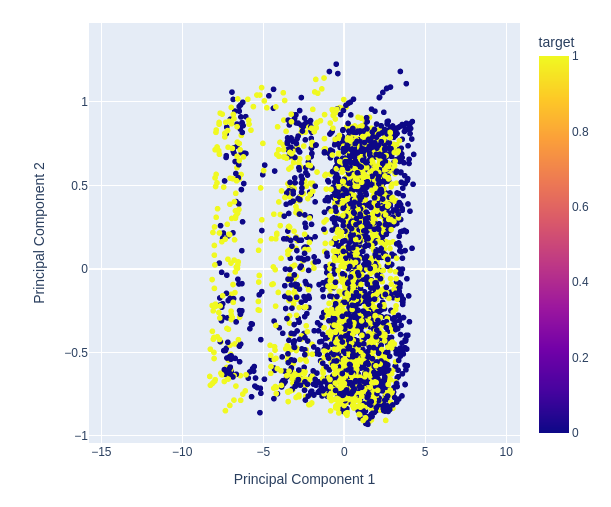
図13:データを視覚化すると、PCAではデータセットの分離が改善されないことがわかる
KMeansクラスタリングのような教師なし学習アルゴリズムは、私たちには明らかではないデータ内のパターンを学習できる可能性があります。アルゴリズムはターゲットに関する情報なしで、与えられたデータにラベルを付けます。
このアイデアは、KMeansクラスタリングアルゴリズムがデータセットから2つのクラスを学習し、2つのクラスを適切に分けるというものです。残念ながら、KMeansアルゴリズムは私たちの期待に応えませんでした。データから生成されたアルゴリズムでは、両クラスにわたって強気と弱気の価格変動が観察されました。
from sklearn.cluster import KMeans # Select relevant features for clustering features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main','ATR']] target = data['Binary Target'].iloc[:len(features)] # Ensure target matches length of features # Apply K-means clustering with 2 clusters kmeans = KMeans(n_clusters=2) clusters = kmeans.fit_predict(features) # Create a DataFrame for plotting with target and cluster labels plot_data = pd.DataFrame({ 'target': target, 'cluster': clusters }) # Plot with seaborn's catplot to compare the binary target and cluster assignments sns.catplot(x='cluster', hue='target',kind='count', data=plot_data) plt.title("Comparison of K-means Clusters with Binary Target") plt.show()
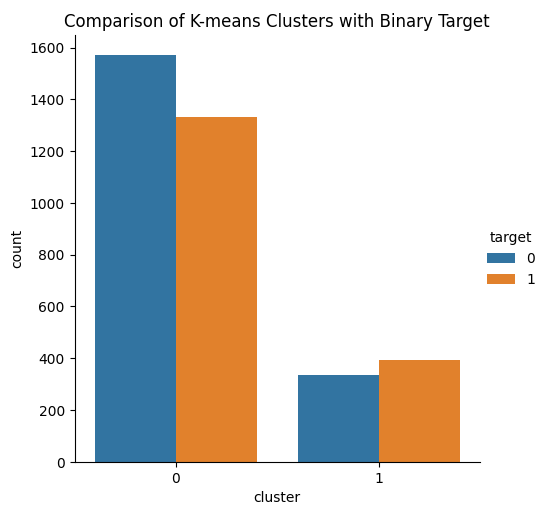
図14:2つのクラスタを視覚化すると、KMeansアルゴリズムは市場データから学習したことがわかる
各入力とターゲットの相関関係を測定することで、変数間の関係性をテストすることもできます。入力のいずれもターゲットと強い相関係数を持っていませんが、これはモデル化できる関係の存在を否定するものではないことに注意してください。
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv") #Add targets data["ATR Target"] = data["ATR"].shift(-look_ahead) data["Target"] = data["Close"].shift(-look_ahead) - data["Close"]
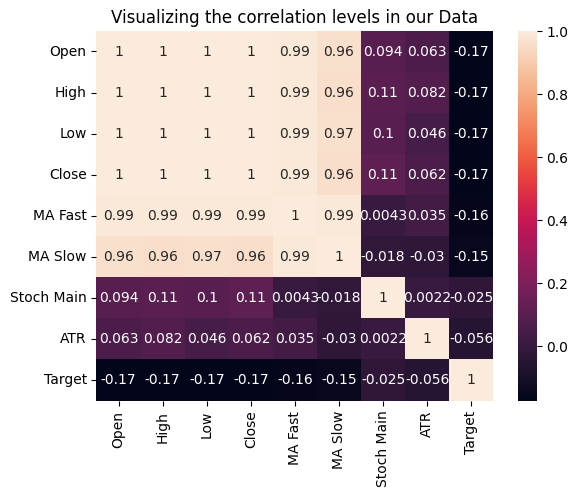
図15:データセットの相関レベルを視覚化する
では、入力データを変換してみましょう。インジケーターを使用できる形式は3つあります。
- 現在の値
- マルコフ状態
- 過去の値との差
それぞれの形式には、独自の長所と短所があります。データを表示する最適な形式は、どの指標がモデル化されているか、どの市場に指標が適用されているかなどの要因によって異なります。理想的な選択を決定する他の方法がないため、各インジケーターのすべての可能なオプションに対して総当たり検索を実行します。
データセットの「時間」列に注目してください。私たちのデータは2010年から2021年までを対象としていることに注意してください。これはバックテストに使用する期間と重複していないでしょうか。
#Let's think of the different ways we can show the indicators to our AI Model #We can describe the indicator by its current reading #We can describe the indicator using markov states #We can describe the change in the indicator's value #Let's see which form helps our AI Model predict the future ATR value data["ATR 1"] = 0 data["ATR 2"] = 0 #Set the states data.loc[data["ATR"] > data["ATR"].shift(look_ahead),"ATR 1"] = 1 data.loc[data["ATR"] < data["ATR"].shift(look_ahead),"ATR 2"] = 1 #Set the change in the ATR data["Change in ATR"] = data["ATR"] - data["ATR"].shift(look_ahead) #We'll do the same for the stochastic data["STO 1"] = 0 data["STO 2"] = 0 data["STO 3"] = 0 #Set the states data.loc[data["Stoch Main"] > 80,"STO 1"] = 1 data.loc[data["Stoch Main"] < 20,"STO 2"] = 1 data.loc[(data["Stoch Main"] >= 20) & (data["Stoch Main"] <= 80) ,"STO 3"] = 1 #Set the change in the stochastic data["Change in STO"] = data["Stoch Main"] - data["Stoch Main"].shift(look_ahead) #Finally the moving averages data["MA 1"] = 0 data["MA 2"] = 0 #Set the states data.loc[data["MA Fast"] > data["MA Slow"],"MA 1"] = 1 data.loc[data["MA Fast"] < data["MA Slow"],"MA 2"] = 1 #Difference in the MA Height data["Change in MA"] = (data["MA Fast"] - data["MA Slow"]) - (data["MA Fast"].shift(look_ahead) - data["MA Slow"].shift(look_ahead)) #Difference in price data["Change in Close"] = data["Close"] - data["Close"].shift(look_ahead) #Clean the data data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) #Drop the last 2 years of test data data = data.iloc[:((-365*2) - 18),:] data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) data
図16:市場データを変換して視覚化する
指標の変化を考慮して、モデルが価格の変化を学習するのにどの表示形式が最も効果的かを見てみましょう。選択モデルとして、勾配ブースティング回帰ツリーを使用します。
#Let's see which method of presentation is most effective from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
時系列交差検証のパラメータを定義します。
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)次に閾値を設定します。終値のみを使用して価格の変化を予測することでパフォーマンスが向上するモデルは、良いモデルとは言えません。
#Our baseline accuracy forecasting the change in price using current price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Close"]],data.loc[:,"Target"],cv=tscv))
-0.14861941262441164
ほとんどの問題では、現在の価格の読み取り値だけではなく、価格の変化を使用することで、常にパフォーマンスを向上させることができます。
#Our accuracy forecasting the change in price using current change in price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in Close"]],data.loc[:,"Target"],cv=tscv))
-0.1033528767401429
代わりに確率的オシレーターを使用すると、モデルのパフォーマンスがさらに向上します。
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Stoch Main"]],data.loc[:,"Target"],cv=tscv))
-0.09152071417994265
しかし、これが私たちにできる最善のことなのでしょうか。代わりに、ストキャスティクスオシレーターの変化をモデルに与えたらどうなるでしょうか。価格変動を予測する能力が向上します。
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in STO"]],data.loc[:,"Target"],cv=tscv))
-0.07090156075020868
今、ダミーエンコーディングアプローチを実行すると何が起こると思いますか。インジケーターがどの状態にあるかを簡単に示すために3つの列を作成しました。エラー率が低下します。この結果は非常に興味深いもので、現在の価格やストキャスティクスオシレーターの現在の読み取り値に基づいて価格の変化を予測しようとしているトレーダーよりもはるかに優れたパフォーマンスを発揮しています。ただし、これがすべての市場に当てはまるかどうかはわかりません。日次時間枠のEURGBP市場で当てはまることだけを確信できます。
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"],cv=tscv))
ここで、2つの移動平均の現在値を使用して、価格の変化を予測する精度を評価してみましょう。結果は良くないようです。終値のみを使用して将来の価格の変化を予測する精度よりも誤差率が高くなっています。このモデルは生産に使用するには適しておらず、放棄する必要があります。
#Our accuracy forecasting the change in price using the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA Slow","MA Fast"]],data.loc[:,"Target"],cv=tscv))
移動平均値の変化を確認できるようにデータを変換すると、結果は改善しますが、現在の終値のみを取得するより単純なモデルを使用する方がまだ良いでしょう。
#Our accuracy forecasting the change in price using the change in the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in MA"]],data.loc[:,"Target"],cv=tscv))
しかし、ダミーエンコーディング手法を市場データに適用すると、日次時間枠で通常の価格見積もりを使用している同じ市場のどのトレーダーよりも優れたパフォーマンスを発揮し始めます。誤差率は、これまでにないほど低い水準まで低下しました。この変革は強力です。これは、インジケーターが取る可能性のある各値の正確なマッピングを学習するのではなく、モデルがインジケーターの値の重要な変化に重点を置くのに役立つことを思い出してください。
#Our accuracy forecasting the change in price using the state of moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"],cv=tscv))
このトピックを初めて学習する読者にとって、このセクションは特に重要です。人間は、たとえパターンが存在しない場合でも、パターンを見出す傾向があります。ここまで読んできた内容から、ダミーエンコーディングは常に最良の味方であるという印象を受けたかもしれませんが、実際にはそうではありません。これから、将来のATR値を予測する最終的なAIモデルを最適化しようとすると、何が起こるかを観察してみましょう。
今から示す結果を、これまで議論してきた結果と比較しないでください。ターゲットの単位が変わっているため、価格変動の予測精度と将来のATR値の予測精度を直接比較することには実用的な意味がありません。
ここで本質的に新しい閾値を設定することになります。過去のATR値を用いてATRを予測する際の精度が、新たなベースラインとなります。これより誤差が大きくなる手法は最適ではなく、採用すべきではありません。
#Our accuracy forecasting the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR"]],data.loc[:,"ATR Target"],cv=tscv))
これまでのところ、現在の形式のデータではなく、データの差分をモデルに渡すたびに、エラー率が減少することを確認しました。しかし、今回は誤差がさらに悪化しました。
#Our accuracy forecasting the ATR using the change in the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in ATR"]],data.loc[:,"ATR Target"],cv=tscv))
-0.5916640039518372
さらに、ATRインジケーターが上昇しているか下降しているかを示すために、ATRインジケーターをダミーエンコードしました。誤差率は依然として許容範囲を超えていました。したがって、ATRインジケーターをそのまま使用し、ストキャスティクスオシレーターと移動平均はダミーエンコードされます。
#Our accuracy forecasting the ATR using the current state of the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR 1","ATR 2"]],data.loc[:,"ATR Target"],cv=tscv))
ONNXへのエクスポート
Open Neural Network Exchange (ONNX)は、すべての機械学習モデルのユニバーサル表現を定義するオープンソースプロトコルです。これにより、その言語がONNXAPIのサポートを完全に拡張している限り、どの言語でもモデルを開発して共有できるようになります。ONNXを使用すると、固定の取引ルールを使用するのではなく、開発したAIモデルをエクスポートし、AIモデルで直接使用して取引の決定をおこなうことができます。
#Load the libraries we need import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
各モデルの入力形状を定義します。
#Define the input shapes #ATR AI initial_types_atr = [('float_input', FloatTensorType([1, 1]))] #MA AI initial_types_ma = [('float_input', FloatTensorType([1, 2]))] #STO AI initial_types_sto = [('float_input', FloatTensorType([1, 3]))]
保有するすべてのデータに各モデルを適合させます。
#ATR AI Model atr_ai = GradientBoostingRegressor().fit(data.loc[:,["ATR"]],data.loc[:,"ATR Target"]) #MA AI Model ma_ai = GradientBoostingRegressor().fit(data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"]) #Stochastic AI Model sto_ai = GradientBoostingRegressor().fit(data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"])
ONNXモデルを保存します。
#Save the ONNX models onnx.save(convert_sklearn(atr_ai, initial_types=initial_types_atr),"EURGBP ATR.onnx") onnx.save(convert_sklearn(ma_ai, initial_types=initial_types_ma),"EURGBP MA.onnx") onnx.save(convert_sklearn(sto_ai, initial_types=initial_types_sto),"EURGBP Stoch.onnx")
MQL5での実装
これまで開発してきたのと同じ取引アルゴリズムを使用します。当初指定した固定ルールのみを変更し、モデルが明確なシグナルを出すたびに取引アプリケーションが取引を実行できるようにします。さらに、開発したONNXモデルをインポートすることから始めます。
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/ja/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the AI Modules | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP MA.onnx" as const uchar ma_onnx_buffer[]; #resource "\\Files\\EURGBP ATR.onnx" as const uchar atr_onnx_buffer[]; #resource "\\Files\\EURGBP Stoch.onnx" as const uchar stoch_onnx_buffer[];
ここで、モデルの予測を保存するグローバル変数を定義します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask; long atr_model,ma_model,stoch_model; vectorf atr_forecast = vectorf::Zeros(1),ma_forecast = vectorf::Zeros(1),stoch_forecast = vectorf::Zeros(1);
初期化解除プロシージャも更新する必要があります。ONNXモデルによって使用されていたリソースも解放する必要があります。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); OnnxRelease(atr_model); OnnxRelease(ma_model); OnnxRelease(stoch_model); }
ONNXモデルから予測を取得するには、モデルの訓練ほどコストがかかりません。しかし、取引アルゴリズムを迅速にバックテストするには、すべてのティックでAIの予測を取得するのは負担になります。代わりに、5分ごとにAIモデルから予測を取得すれば、バックテストの速度を大幅に向上させることができます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- Only on new candles static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_M5,0); if(time_stamp != current_time) { time_stamp = current_time; //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } } }
テクニカルインジケーターの設定を担当する関数も更新する必要があります。この関数はAIモデルを設定し、モデルが正しくロードされたことを検証します。
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); //--- Create our onnx models atr_model = OnnxCreateFromBuffer(atr_onnx_buffer,ONNX_DEFAULT); ma_model = OnnxCreateFromBuffer(ma_onnx_buffer,ONNX_DEFAULT); stoch_model = OnnxCreateFromBuffer(stoch_onnx_buffer,ONNX_DEFAULT); //--- Validate our models if(atr_model == INVALID_HANDLE || ma_model == INVALID_HANDLE || stoch_model == INVALID_HANDLE) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } //--- Set the sizes of our ONNX models ulong atr_input_shape[] = {1,1}; ulong ma_input_shape[] = {1,2}; ulong sto_input_shape[] = {1,3}; if(!(OnnxSetInputShape(atr_model,0,atr_input_shape)) || !(OnnxSetInputShape(ma_model,0,ma_input_shape)) || !(OnnxSetInputShape(stoch_model,0,sto_input_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } ulong output_shape[] = {1,1}; if(!(OnnxSetOutputShape(atr_model,0,output_shape)) || !(OnnxSetOutputShape(ma_model,0,output_shape)) || !(OnnxSetOutputShape(stoch_model,0,output_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } }
以前の取引アルゴリズムでは、指標が一致する限り、単にポジションを開いていました。今では、AIモデルが明確な取引シグナルを出した場合、代わりにポジションを開きます。さらに、私たちのテイクプロフィットレベルと損失停止レベルは、予想されるボラティリティレベルに合わせて動的に設定されます。うまくいけば、AIを使用して、より収益性の高い取引シグナルを提供するフィルタを作成できるようになります。
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Predict future ATR values vectorf atr_model_input = vectorf::Zeros(1); atr_model_input[0] = (float) atr[0]; //--- Predicting future price using the stochastic oscilator vectorf sto_model_input = vectorf::Zeros(3); if(stochastic[0] > 80) { sto_model_input[0] = 1; sto_model_input[1] = 0; sto_model_input[2] = 0; } else if(stochastic[0] < 20) { sto_model_input[0] = 0; sto_model_input[1] = 1; sto_model_input[2] = 0; } else { sto_model_input[0] = 0; sto_model_input[1] = 0; sto_model_input[2] = 1; } //--- Finally prepare the moving average forecast vectorf ma_inputs = vectorf::Zeros(2); if(fast_ma[0] > slow_ma[0]) { ma_inputs[0] = 1; ma_inputs[1] = 0; } else { ma_inputs[0] = 0; ma_inputs[1] = 1; } OnnxRun(stoch_model,ONNX_DEFAULT,sto_model_input,stoch_forecast); OnnxRun(atr_model,ONNX_DEFAULT,atr_model_input,atr_forecast); OnnxRun(ma_model,ONNX_DEFAULT,ma_inputs,ma_forecast); Comment("ATR Forecast: ",atr_forecast[0],"\nStochastic Forecast: ",stoch_forecast[0],"\nMA Forecast: ",ma_forecast[0]); //--- Can we buy? if((ma_forecast[0] > 0) && (stoch_forecast[0] > 0)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr_forecast[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((ma_forecast[0] < 0) && (stoch_forecast[0] < 0)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr_forecast[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
バックテストは、2022年1月初旬から2024年6月まで、これまでと同じ期間にわたって実施します。AIモデルを訓練していたとき、バックテストの範囲内にデータがなかったことを思い出してください。同じ銘柄、EURGBPペアを同じ時間枠、日次時間枠でテストします。
図17:AIモデルのバックテスト
テストが本質的に同一になるように、バックテストの他のすべてのパラメータを修正します。ここでは本質的に、AIモデルによって意思決定がおこなわれることで生じる違いを分離しようとしています。
図18:バックテストの残りのパラメータ
私たちの取引戦略はテスト期間中にさらに利益を上げました!これは素晴らしいニュースです。というのも、バックテストで使用しているデータはモデルに事前に与えられていないためです。したがって、このモデルを実際の口座で運用する際にも、ポジティブな期待を持つことができます。
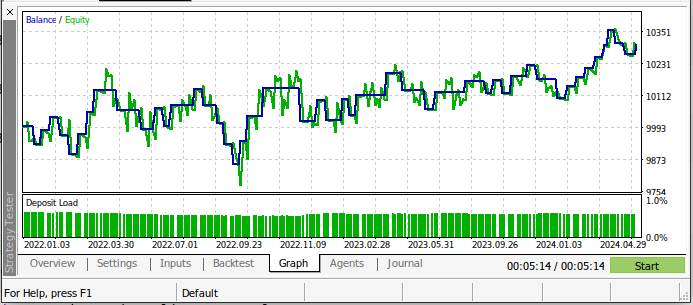
図19:テスト日におけるAIモデルのバックテストの結果
新しいモデルでは、バックテストでの取引回数は減りましたが、古い取引アルゴリズムよりも勝率が高くなりました。さらに、シャープレシオはプラスに転じ、損失となった取引は全体の44%にとどまりました。
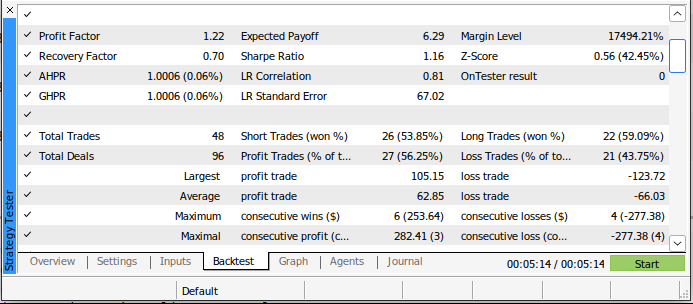
図20:AIを活用した取引戦略のバックテストの詳細な結果
結論
この記事を読んで、AIが本当に取引戦略の改善に役立つことを実感していただけたのではないでしょうか。最も古典的な取引戦略でさえ、AIを活用することで再構築され、パフォーマンスを新たな次元へと引き上げることができます。重要なのは、インジケーターデータをどのように変換し、モデルに効果的に学習させるかという点です。今回紹介したダミーエンコーディングの手法は、大きな助けとなりました。しかし、これがすべての市場において最適な手法であるとは限りません。ある特定の市場では、ダミーエンコーディングが最も効果的な選択肢となる可能性がありますが、一概には言えません。ただ、移動平均線のクロスオーバー戦略は、AIによって大幅に改善できることは間違いないと言えるでしょう。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/16280
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ありがとう、Gamu 。私はあなたの出版物を楽しみ、あなたのステップを再現することによって学ぼうとしています。
私はいくつかの問題を抱えています。
1) EURGBP_Stochastic dailyを使用し、提供されたスクリプトでテストしたところ、2つの注文しか出ず、シャープレシオは0.02でした。私はあなたと同じ設定をしていると思いますが、2つのブローカーでは2つの注文しか出ません。
2) 他の方への注意として、必要であれば、ブローカーに合わせてシンボル設定を変更する必要があるかもしれません(例えば、EURGBPをEURGBP.iに)。
3) 次に、データをエクスポートしようとすると、ATRの範囲外の配列が表示されます。これは、配列に100000レコードが入らないためだと思います(677に変更すると)。もしかしたら、データ抽出スクリプトもダウンロードに含めることができるかもしれません。
4)あなたの記事からコードをコピーしてPythonで試してみましたが、look_aheadが定義されていないというエラーが出ました ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:].
NameError: 'look_ahead' という名前が定義されていません。
5) あなたのJuypiterノートブックをロードしたとき、先読みを設定する必要があることがわかりました。
look_ahead = 20 , この後、同梱のファイルのみを使用しましたが、677行しかないためか、以下のエラーに引っかかっています。
可視化を開始する前に、#データのスケーリングを実行しました。
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow', 'Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow', 'Stoch Main']])
とすると、解決方法がわからないエラーが発生する。
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning:値を DataFrame からのスライスのコピーに設定しようとしています。https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main]]))
ありがとう、Gamu 。私はあなたの出版物を楽しみ、あなたのステップを再現することで学ぼうとしています。
私はいくつかの問題を抱えていますが、これが他の人の助けになることを願っています。
1) EURGBP_Stochastic dailyを使用し、提供されたスクリプトでテストしたところ、2つの注文しか出ず、シャープレシオは0.02でした。私はあなたと同じ設定をしていると思いますが、2つのブローカーで2つの注文しか出ません。
2) 他の方への注意事項として、必要に応じて、ブローカーに合わせてシンボル設定を変更する必要があるかもしれません(例:EURGBPをEURGBP.iに)。
3) 次に、データをエクスポートしようとすると、ATRの範囲外の配列が表示されます。これは、配列に100000レコードが入らないためだと思います(677に変更すると)。もしかしたら、データ抽出スクリプトもダウンロードに含めることができるかもしれません。
4)あなたの記事からコードをコピーしてPythonで試してみましたが、look_aheadが定義されていないというエラーが出ました ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:].
NameError: 名前 'look_ahead' は定義されていません。
5) あなたのJuypiterノートブックをロードしたとき、先読みを設定する必要があることがわかりました。
look_ahead = 20 , この後、同梱のファイルのみを使用しましたが、677行しかないためか、以下のエラーに引っかかっています。
可視化を開始する前に、#データのスケーリングを実行しました。
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow', 'Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow', 'Stoch Main']])
というエラーが出て、解決方法がわかりません。
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning:値を DataFrame からのスライスのコピーに設定しようとしています。https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main]]))
ニール、元気だと信じているよ。
Gamuさん、ありがとうございます。可動部分が多いことは承知しています。
そうだね、可動部分が多いのは分かっている。