
Klassische Strategien neu interpretieren (Teil XI): Kreuzung gleitender Durchschnitte (II)

Wir wollen nun gründlich untersuchen, wie groß der Unterschied für unsere Handelsanwendungen ist und wie diese Tatsache Ihre Handelsstrategien verbessern kann. Das Kreuzen von gleitenden Durchschnitten ist eine der ältesten Handelsstrategien überhaupt. Es ist eine Herausforderung, eine gewinnbringende Strategie mit einer so weithin bekannten Technik zu entwickeln. Dennoch hoffe ich, Ihnen in diesem Artikel zeigen zu können, dass alte Hunde durchaus neue Tricks lernen können.
Um in unseren Vergleichen empirisch zu sein, werden wir zunächst eine Handelsstrategie in MQL5 für das EURGBP-Paar erstellen und dabei nur die folgenden Indikatoren verwenden:
- 2 Exponentielle gleitende Durchschnitte, angewandt auf den Schlusskurs. Eine mit einer Periode von 20 und die andere mit 60.
- Der Stochastik-Oszillator mit den Standardeinstellungen 5,3,3 wurde auf den Modus „Exponentieller gleitender Durchschnitt“ gesetzt und so eingestellt, dass er seine Berechnungen im Modus CLOSE_CLOSE durchführt.
- Der Average True Range-Indikator mit einer Periode von 14, um unsere Preise für Take-Profit und Stop-Loss festzulegen.
Wir werden die Parameter, unter denen der Backtest durchgeführt wurde, im weiteren Verlauf des Artikels eingehend untersuchen. Wir werden jedoch im Laufe des Backtests wichtige Leistungskennzahlen wie die Sharpe Ratio, den Anteil der profitablen Handelsgeschäfte, den maximalen Gewinn und andere wichtige Leistungskennzahlen beachten.
Sobald dies abgeschlossen ist, werden wir alle alten Handelsregeln sorgfältig durch algorithmische Handelsregeln ersetzen, die aus unseren Marktdaten gelernt wurden. Wir werden 3 KI-Modelle trainieren, um Prognosen zu lernen:
- Künftige Volatilität: Dazu wird ein KI-Modell trainiert, um den ATR-Wert vorherzusagen.
- Beziehung zwischen der Preisänderung und dem Kreuzen der gleitende Durchschnitte: Wir erstellen 2 diskrete Zustände, in denen sich die gleitenden Durchschnitte befinden können. Die gleitenden Durchschnitte können sich jeweils nur in einem Zustand befinden. Dadurch kann sich unser KI-Modell auf die kritischen Veränderungen des Indikators und die durchschnittlichen Auswirkungen dieser Veränderungen auf das künftige Preisniveau konzentrieren.
- Beziehung zwischen der Preisveränderung und dem stochastischen Oszillator: Dieses Mal werden wir 3 diskrete Zustände erzeugen, von denen der stochastische Oszillator jeweils nur einen einnehmen kann. Unser Modell lernt dann die durchschnittliche Wirkung der kritischen Veränderungen im stochastischen Oszillator.
Diese 3 KI-Modelle werden nicht auf einen der Zeiträume trainiert, die wir für unseren Backtest verwenden werden. Unser Backtest wird von 2022 bis Juni 2024 laufen, und unsere KI-Modelle werden von 2011 bis 2021 trainiert. Wir haben darauf geachtet, dass sich Training und Backtesting nicht überschneiden, sodass wir unser Bestes tun können, um der tatsächlichen Leistung des Modells bei Daten, die es noch nicht gesehen hat, nahe zu kommen.
Ob Sie es glauben oder nicht, wir haben alle Leistungskennzahlen in allen Bereichen erfolgreich verbessert. Unsere neue Handelsstrategie war profitabler, wies eine höhere Sharpe Ratio auf und gewann mehr als die Hälfte, nämlich 55 %, aller während des Backtestzeitraums getätigten Handelsgeschäfte.
Wenn eine so alte und weit verbreitete Strategie profitabler gemacht werden kann, sollte dies meiner Meinung nach jeden Leser ermutigen, dass auch seine Strategien profitabler gemacht werden können, wenn man seine Strategie nur richtig aufbaut.
Die meisten Händler arbeiten über lange Zeiträume hinweg hart an der Entwicklung ihrer Handelsstrategien und werden kaum jemals ausführlich über ihre wertvollen persönlichen Strategien sprechen. Daher dient der gleitende Durchschnitt als neutraler Diskussionspunkt, an dem sich alle Mitglieder unserer Gemeinschaft orientieren können. Ich hoffe, dass ich Ihnen einen allgemeinen Rahmen bieten kann, den Sie mit Ihren eigenen Handelsstrategien ergänzen können, und wenn Sie diesen Rahmen entsprechend befolgen, sollten Sie einige Verbesserungen Ihrer eigenen Strategien sehen.
Die ersten Schritte
Für den Einstieg starten wir unsere MetaEditor-IDE und beginnen mit der Erstellung einer Handelsanwendung, die uns als Grundlage dienen soll.
Wir wollen eine einfache Strategie, die das Kreuzen der gleitende Durchschnitte umsetzen, also fangen wir an. Wir importieren zunächst die Handelsbibliothek.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Definition der globalen Variablen.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask;
Erstellen der Handles unserer technischen Indikatoren.
//+------------------------------------------------------------------+ //| Technical indicator handlers | //+------------------------------------------------------------------+ int slow_ma_handler,fast_ma_handler,stochastic_handler,atr_handler; double slow_ma[],fast_ma[],stochastic[],atr[];
Wir werden auch einige unserer Variablen als Konstanten festlegen.
//+------------------------------------------------------------------+ //| Constants | //+------------------------------------------------------------------+ const int slow_period = 60; const int fast_period = 20; const int atr_period = 14;
Einige unserer Eingaben sollten manuell gesteuert werden. So zum Beispiel die Losgröße und der Abstand des Stop-Loss.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Money Management" input int lot_multiple = 5; //Lot size input group "Risk Management" input int atr_multiple = 5; //Stop Loss Width
Wenn unser System geladen ist, rufen wir eine spezielle Funktion auf, um unsere technischen Indikatoren einzurichten und die Marktdaten zu speichern.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our technical indicators and fetch market data setup(); //--- return(INIT_SUCCEEDED); }
Andernfalls, wenn wir die Handelsanwendung nicht mehr verwenden, sollten wir die nicht mehr benötigten Ressourcen freigeben.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); }
Wenn wir keine offenen Positionen auf dem Markt haben, werden wir nach einer Handelsmöglichkeit suchen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } }
Diese Funktion initialisiert unsere technischen Indikatoren und speichert die vom Endnutzer angegebene Losgröße.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); }
Wir werden nun eine Funktion einrichten, um aktualisierte Preisangebote zu speichern, wenn wir sie erhalten.
//+------------------------------------------------------------------+ //| Fetch updated market data | //+------------------------------------------------------------------+ void update(void) { //--- Update our market prices bid = SymbolInfoDouble("EURGBP",SYMBOL_BID); ask = SymbolInfoDouble("EURGBP",SYMBOL_ASK); //--- Copy indicator buffers CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(slow_ma_handler,0,0,1,slow_ma); CopyBuffer(fast_ma_handler,0,0,1,fast_ma); CopyBuffer(stochastic_handler,0,0,1,stochastic); }
Diese Funktion prüft schließlich unser Handelssignal. Wenn das Signal gefunden wird, gehen wir unsere Positionen mit Stop-Loss und Take-Profit ein, die durch die ATR festgelegt werden.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Can we buy? if((fast_ma[0] > slow_ma[0]) && (stochastic[0] > 80)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((fast_ma[0] < slow_ma[0]) && (stochastic[0] < 20)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Wir sind nun bereit, unser Handelssystem einem Backtest zu unterziehen. Wir werden den Handelsalgorithmus des Kreuzens der einfachen gleitenden Durchschnitte, den wir gerade oben definiert haben, auf den Tagesdaten von EURGBP trainieren. Unser Backtesting-Zeitraum wird von Anfang Januar 2022 bis Ende Juni 2024 dauern. Wir setzen den Parameter „Forward“ auf false. Die Marktdaten werden mit echten Ticks modelliert, die unser Terminal von unserem Broker anfordern muss. Auf diese Weise wird sichergestellt, dass unsere Testergebnisse die Marktbedingungen an diesem Tag genau widerspiegeln.
Abb. 1: Einige der Einstellungen für unseren Backtest
Abb. 2: Die übrigen Parameter unseres Backtests
Die Ergebnisse unseres ersten Backtests sind nicht ermutigend. Unsere Handelsstrategie hat während des gesamten Tests Geld verloren. Dies ist jedoch auch nicht überraschend, da wir bereits wissen, dass sich kreuzende gleitende Durchschnitte verzögerte Handelssignale sind. Die folgende Abbildung 3 gibt einen Überblick über den Stand unseres Handelskontos während des Tests.
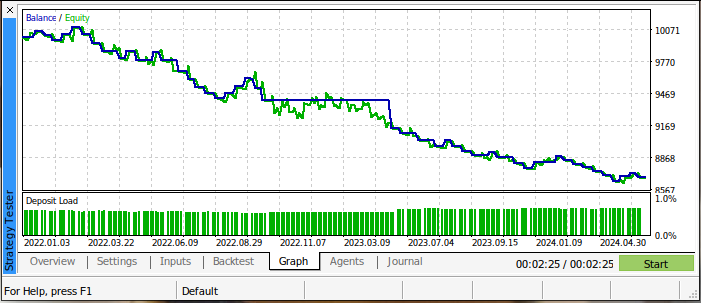
Abb. 3: Der Saldo unseres Handelskontos bei der Durchführung des Backtests
Unsere Sharpe Ratio betrug -5,0, und wir verloren 69,57 % aller von uns getätigten Handelsgeschäfte. Unser durchschnittlicher Verlust war größer als unser durchschnittlicher Gewinn. Dies sind schlechte Leistungsindikatoren. Wenn wir dieses Handelssystem in seiner jetzigen Form verwenden würden, würden wir mit Sicherheit schnell unser Geld verlieren.
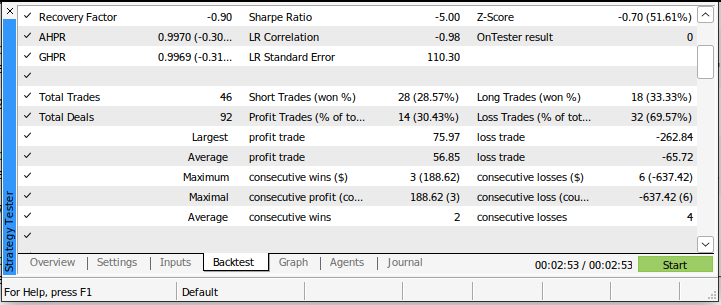
Abb. 4: Die Details unseres Backtests, bei dem wir einen alten Ansatz für den Handel an den Märkten verwendet haben
Strategien, die sich auf das Kreuzen gleitender Durchschnitte und dem Stochastik-Oszillator stützen, wurden bereits ausgiebig genutzt und haben wahrscheinlich keinen wesentlichen Vorteil, den wir als menschliche Händler nutzen können. Das bedeutet aber nicht, dass unsere KI-Modelle keinen materiellen Vorteil erlangen können. Wir werden eine spezielle Transformation anwenden, die als „Dummy-Kodierung“ bekannt ist, um unserem KI-Modell den aktuellen Zustand der Märkte zu präsentieren.
Die Dummy-Kodierung wird verwendet, wenn Sie eine ungeordnete kategoriale Variable haben, und wir weisen eine Spalte für jeden Wert zu, den sie annehmen kann. Stellen Sie sich zum Beispiel vor, das MQL5-Team würde Ihnen erlauben, selbst zu entscheiden, welches Farbthema Sie für Ihre Installation von MetaTrader 5 wählen möchten. Sie haben die Wahl zwischen den Farben Rot, Rosa und Blau. Wir können diese Informationen erfassen, indem wir eine Datenbank mit 3 Spalten mit den Bezeichnungen „Rot“, „Rosa“ und „Blau“ anlegen. Die Spalte, die Sie bei der Installation ausgewählt haben, wird auf 1 gesetzt, die anderen Spalten bleiben 0. Das ist die Idee hinter der Dummy-Kodierung.
Die Dummy-Kodierung ist sehr leistungsfähig, denn wenn wir eine andere Darstellung der Informationen gewählt hätten, z. B. 1-Rot, 2-Rosa und 3-Blau, könnten unsere KI-Modelle falsche Wechselwirkungen in den Daten lernen, die im wirklichen Leben nicht existieren. Das Modell kann zum Beispiel lernen, dass 2 und eine halbe Farbe die optimale Farbe ist. Daher hilft uns die Dummy-Kodierung dabei, unseren Modellen kategoriale Informationen in einer Weise zu präsentieren, die sicherstellt, dass das Modell nicht implizit davon ausgeht, dass es eine Skala für die Daten gibt, die es erhält.
Unsere gleitenden Durchschnitte werden zwei Zustände haben, wobei der erste Zustand aktiviert wird, wenn der schnelle Durchschnitt über dem langsamen liegt. Andernfalls wird der zweite Zustand aktiviert. Zu jedem Zeitpunkt kann nur ein Zustand aktiv sein. Es ist unmöglich, dass sich der Preis in beiden Zuständen gleichzeitig befindet. Ebenso wird unser stochastischer Oszillator 3 Zustände haben. Eine wird aktiv, wenn der Kurs über dem 80er-Wert des Indikators liegt, die zweite wird aktiviert, wenn der Kurs unter dem 20er-Bereich liegt. Andernfalls wird der dritte Zustand aktiviert.
Der aktive Zustand wird auf 1 gesetzt und alle anderen Zustände werden auf 0 gesetzt. Diese Transformation zwingt unser Modell dazu, die durchschnittliche Veränderung des Ziels zu lernen, wenn sich der Preis durch die verschiedenen Zustände unseres Indikators bewegt. Dies entspricht in etwa dem, was professionelle, menschliche Händler tun. Der Handel ist nicht wie die Technik, wir können keine Millimetergenauigkeit erwarten. Vielmehr lernen die besten menschlichen Händler im Laufe der Zeit, was mit hoher Wahrscheinlichkeit als Nächstes passieren wird. Das Training unseres Modells mit der Dummy-Kodierung wird uns zum gleichen Ziel führen. Unser Modell wird seine Parameter so optimieren, dass es die durchschnittliche Preisveränderung in Abhängigkeit vom aktuellen Stand der technischen Indikatoren lernt.
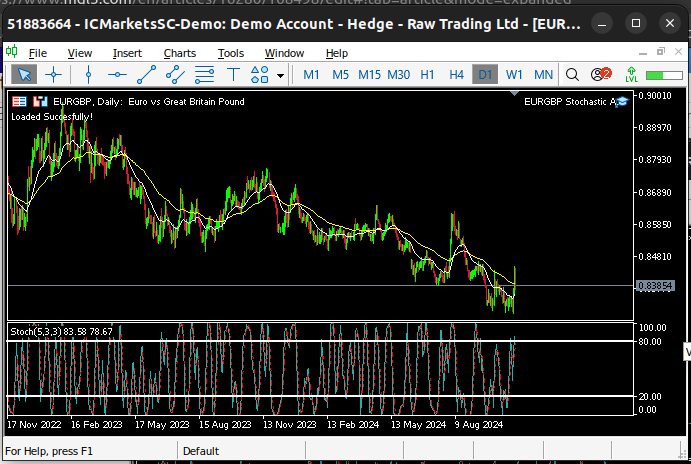
Abb. 5: Visualisierung des EURGBP Tagesmarktes
Der erste Schritt zur Erstellung unserer KI-Modelle besteht darin, die benötigten Daten zu beschaffen. Es ist immer die beste Praxis, die gleichen Daten abzurufen, die Sie auch in der Produktion verwenden werden. Aus diesem Grund werden wir dieses MQL5-Skript verwenden, um alle unsere Marktdaten aus dem MetaTrader 5-Terminal abzurufen. Unerwartete Unterschiede bei der Berechnung der Indikatorwerte in verschiedenen Bibliotheken können dazu führen, dass wir am Ende des Tages unbefriedigende Ergebnisse erhalten.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_fast_handler,ma_slow_handler,stoch_handler,atr_handler; double ma_fast[],ma_slow[],stoch[],atr[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator ma_fast_handler = iMA(Symbol(),PERIOD_CURRENT,20,0,MODE_EMA,PRICE_CLOSE); ma_slow_handler = iMA(Symbol(),PERIOD_CURRENT,60,0,MODE_EMA,PRICE_CLOSE); stoch_handler = iStochastic(Symbol(),PERIOD_CURRENT,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR(Symbol(),PERIOD_D1,14); //--- Load the indicator values CopyBuffer(ma_fast_handler,0,0,size,ma_fast); CopyBuffer(ma_slow_handler,0,0,size,ma_slow); CopyBuffer(stoch_handler,0,0,size,stoch); CopyBuffer(atr_handler,0,0,size,atr); ArraySetAsSeries(ma_fast,true); ArraySetAsSeries(ma_slow,true); ArraySetAsSeries(stoch,true); ArraySetAsSeries(atr,true); //--- File name string file_name = "Market Data " + Symbol() +" MA Stoch ATR " + " As Series.csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MA Fast","MA Slow","Stoch Main","ATR"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), ma_fast[i], ma_slow[i], stoch[i], atr[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Explorative Datenanalyse
Nachdem wir nun unsere Marktdaten aus dem Terminal abgerufen haben, können wir mit der Analyse der Marktdaten beginnen.
#Import the libraries import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Wir lesen die Daten ein,
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv")
fügen ein binäres Ziel hinzu, um die Daten zu visualisieren.
#Let's visualize the data data["Binary Target"] = 0 data.loc[data["Close"].shift(-look_ahead) > data["Close"],"Binary Target"] = 1 data = data.iloc[:-look_ahead,:]
Nun skalieren wir die Daten
#Scale the data before we start visualizing it from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
und verwenden die Plotly-Bibliothek, um die Daten zu visualisieren.
import plotly.express as px
Wir werden sehen, wie gut der langsame und der schnelle Durchschnitt dabei helfen, Aufwärts- und Abwärtsbewegungen des Marktes zu unterscheiden.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average fig = px.scatter_3d( data, x=data.index, y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of Time, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'Time', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
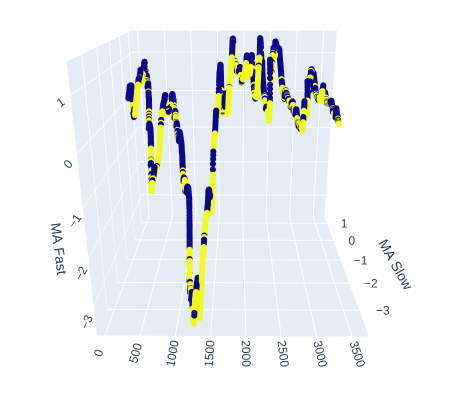
Abb. 6: Visualisierung der Beziehung zwischen den gleitenden Durchschnitten und dem Ziel
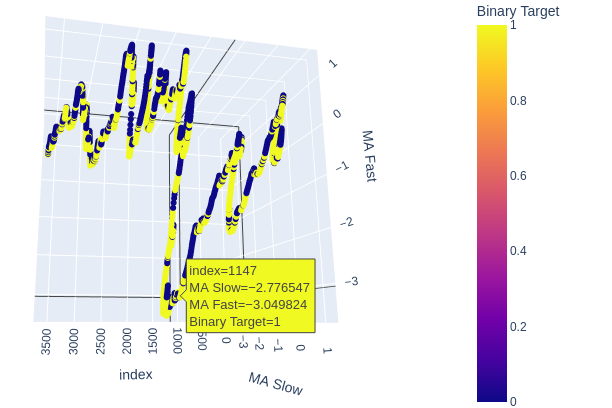
Abb. 7: Unsere gleitenden Durchschnitte scheinen die Auf- und Abwärtsbewegungen der Kurse in einem angemessenen Umfang zu bündeln
Mal sehen, ob sich die Volatilität des Marktes vielleicht auf das Ziel auswirkt. Wir ersetzen die Zeit auf der x-Achse mir den ATR-Wert. Die sich langsam und schnell bewegenden Durchschnitte behalten ihre Positionen bei.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average and the ATR fig = px.scatter_3d( data, x='ATR', y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of ATR, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'ATR', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
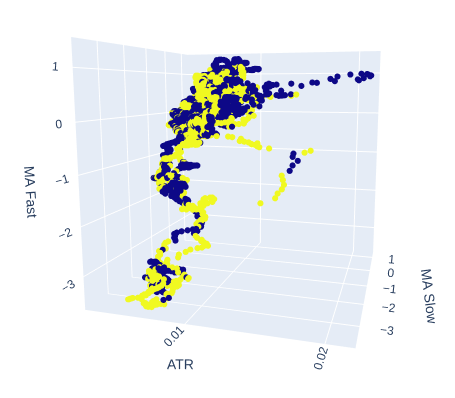
Abb. 8: Die ATR scheint wenig Klarheit in unser Bild vom Markt zu bringen. Vielleicht müssen wir die Volatilitätsanzeige ein wenig umgestalten, damit sie informativer wird.
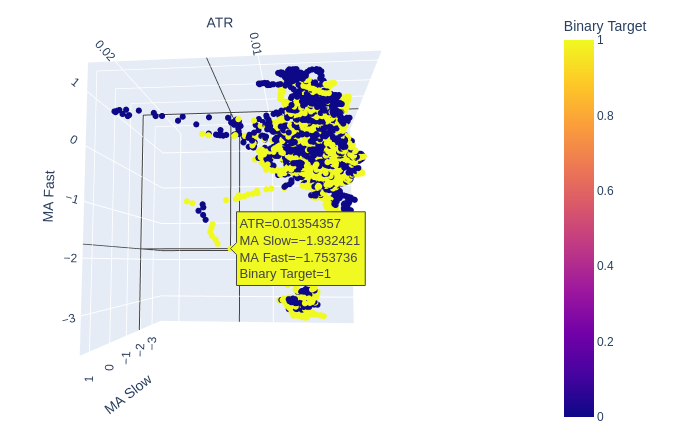
Abb. 9: Die ATR scheint Cluster von Auf- und Abwärtsbewegungen der Kurse aufzuzeigen. Die Cluster sind jedoch klein und treten möglicherweise nicht häufig genug auf, um Teil einer zuverlässigen Handelsstrategie zu sein.
Die 2 gleitenden Durchschnitte und der Stochastik-Oszillator zusammen geben unseren Marktdaten eine ganz neue Struktur.
# Creating a 3D scatter plot of the slow and fast moving average and the stochastic oscillator fig = px.scatter_3d( data, x='MA Fast', y='MA Slow', z='Stoch Main', color='Binary Target', title="3D Scatter Plot of Time, Close Price, and The Stochastic Oscilator", labels={'x': 'Time', 'y': 'Close Price', 'z': 'Stochastic Oscilator'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
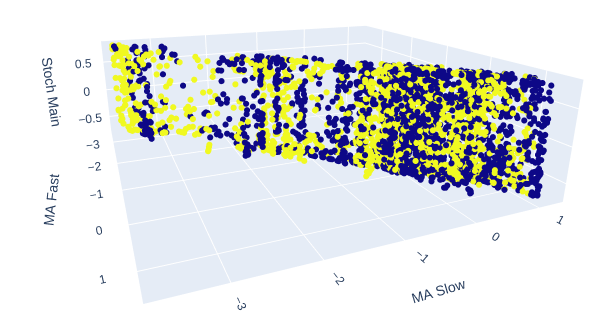
Abb. 10: Der Stochastik-Hauptmesswert und die 2 gleitenden Durchschnitte ergeben einige klar definierte Aufwärts- und Abwärtszonen.
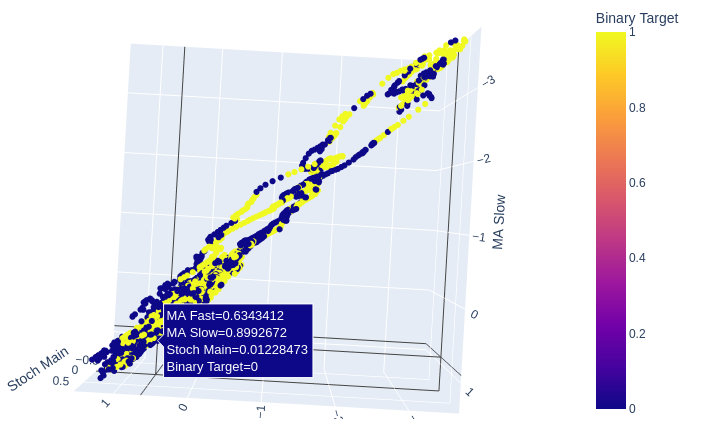
Abb. 11: Die Beziehung zwischen den 2 gleitenden Durchschnitten und der Stochastik ist möglicherweise besser geeignet, um steigende Kursbewegungen aufzudecken als fallende.
Da wir 3 technische Indikatoren und 4 verschiedene Kursnotierungen verwenden, haben unsere Daten 7 Dimensionen, aber wir können höchstens 3 visualisieren. Wir können unsere Daten mithilfe von Techniken zur Dimensionenreduktion in nur 2 Spalten umwandeln. Die Hauptkomponentenanalyse ist ein beliebtes Mittel zur Lösung dieser Art von Problemen. Wir können den Algorithmus verwenden, um alle Spalten unseres ursprünglichen Datensatzes in nur 2 Spalten zusammenzufassen.
Anschließend erstellen wir ein Streudiagramm der beiden Hauptkomponenten und ermitteln, wie gut sie das Ziel für uns sichtbar machen.
# Selecting features to include in PCA features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow']] pca = PCA(n_components=2) pca_components = pca.fit_transform(features.dropna()) # Plotting PCA results # Create a new DataFrame with PCA results and target variable for plotting pca_df = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2']) pca_df['target'] = data['Binary Target'].iloc[:len(pca_components)] # Add target column # Plot PCA results with binary target as hue fig = px.scatter( pca_df, x='PC1', y='PC2', color='target', title="2D PCA Plot of OHLC Data with Target Hue", labels={'PC1': 'Principal Component 1', 'PC2': 'Principal Component 2', 'color': 'Target'} ) # Update layout for custom size fig.update_layout( width=600, # Width of the figure in pixels height=600 # Height of the figure in pixels ) fig.show()
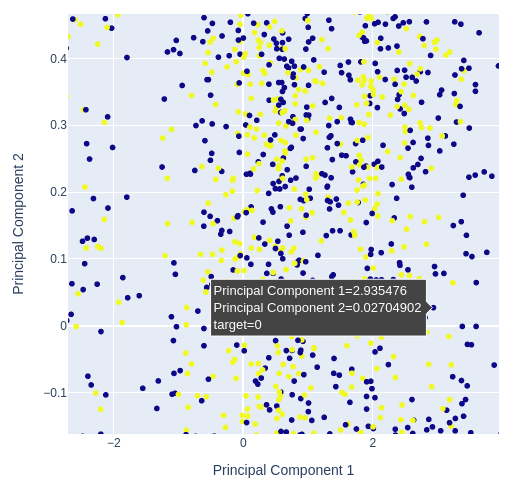
Abb. 12: Vergrößerung eines zufälligen Ausschnitts aus unserem Streudiagramm der ersten beiden Hauptkomponenten, um zu sehen, wie gut sie die Preisschwankungen trennen
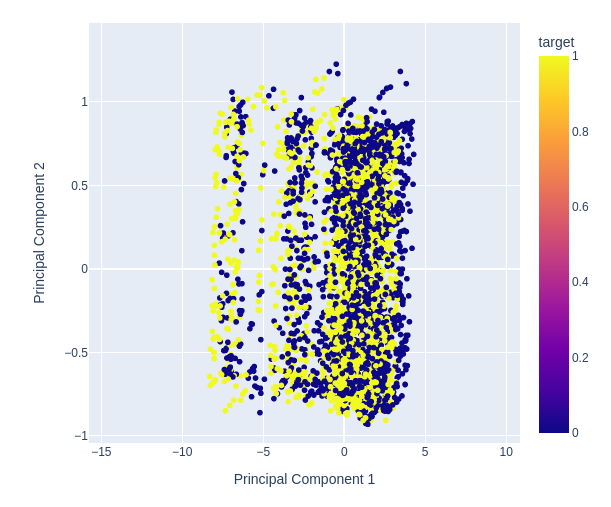
Abb. 13: Die Visualisierung unserer Daten zeigt uns, dass die PCA keine bessere Trennung des Datensatzes bewirkt.
Unüberwachte Lernalgorithmen wie KMeans Clustering können möglicherweise Muster in den Daten erkennen, die für uns nicht offensichtlich sind. Der Algorithmus kernnzeichnet die Daten, die er erhält, ohne Informationen über das Ziel.
Die Idee ist, dass KMeans Clustering 2 Klassen aus unserem Datensatz lernen kann, die unsere 2 Klassen gut trennen. Leider hat KMeans unsere Erwartungen nicht wirklich erfüllt. Wir beobachteten sowohl steigende wie fallende Kursbewegungen in beiden Klassen, die der Algorithmus aus den Daten generierte.
from sklearn.cluster import KMeans # Select relevant features for clustering features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main','ATR']] target = data['Binary Target'].iloc[:len(features)] # Ensure target matches length of features # Apply K-means clustering with 2 clusters kmeans = KMeans(n_clusters=2) clusters = kmeans.fit_predict(features) # Create a DataFrame for plotting with target and cluster labels plot_data = pd.DataFrame({ 'target': target, 'cluster': clusters }) # Plot with seaborn's catplot to compare the binary target and cluster assignments sns.catplot(x='cluster', hue='target',kind='count', data=plot_data) plt.title("Comparison of K-means Clusters with Binary Target") plt.show()
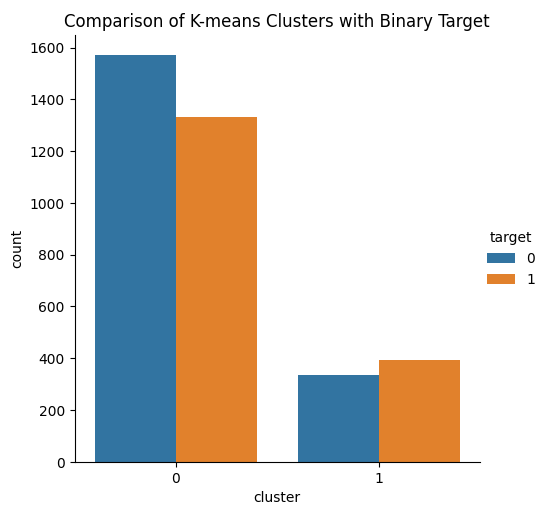
Abb. 14: Visualisierung der 2 Cluster, die unser KMeans aus den Marktdaten gelernt hat.
Wir können auch auf Beziehungen zwischen den Variablen testen, indem wir die Korrelation der einzelnen Eingaben mit unserem Ziel messen. Keiner unserer Inputs hat starke Korrelationskoeffizienten mit unserem Ziel. Bitte beachten Sie, dass dies nicht widerlegt, dass es eine Beziehung gibt, die wir modellieren können.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv") #Add targets data["ATR Target"] = data["ATR"].shift(-look_ahead) data["Target"] = data["Close"].shift(-look_ahead) - data["Close"]
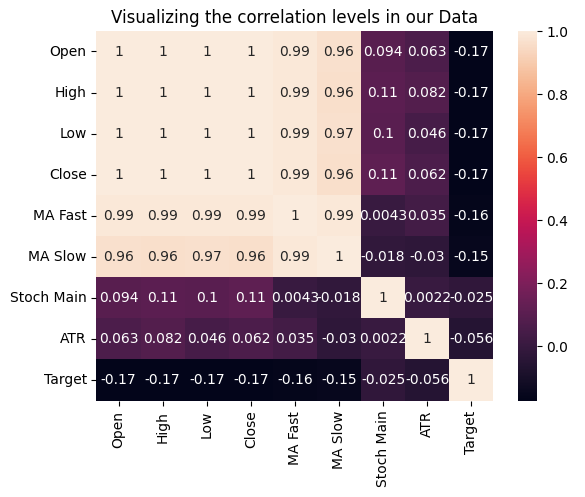
Abb. 15: Visualisierung der Korrelationsniveaus in unserem Datensatz
Nun wollen wir unsere Eingabedaten transformieren. Wir haben 3 Formen, in denen wir unsere Indikatoren verwenden können:
- Der aktuelle Stand.
- Markov-Zustände.
- Differenz zwischen seinem früheren Wert.
Jede Form hat ihre eigenen Vor- und Nachteile. In welcher Form die Daten am besten dargestellt werden, hängt unter anderem davon ab, welcher Indikator modelliert wird und auf welchen Markt der Indikator angewendet wird. Da es keine andere Möglichkeit gibt, die ideale Wahl zu treffen, werden wir eine Brute-Force-Suche über alle möglichen Optionen für jeden Indikator durchführen.
Achten Sie auf die Spalte „Zeit“ in unserem Datensatz. Beachten Sie, dass unsere Daten vom Jahr 2010 bis 2021 reichen. Dies überschneidet sich nicht mit dem Zeitraum, den wir für unseren Backtest verwenden werden.
#Let's think of the different ways we can show the indicators to our AI Model #We can describe the indicator by its current reading #We can describe the indicator using markov states #We can describe the change in the indicator's value #Let's see which form helps our AI Model predict the future ATR value data["ATR 1"] = 0 data["ATR 2"] = 0 #Set the states data.loc[data["ATR"] > data["ATR"].shift(look_ahead),"ATR 1"] = 1 data.loc[data["ATR"] < data["ATR"].shift(look_ahead),"ATR 2"] = 1 #Set the change in the ATR data["Change in ATR"] = data["ATR"] - data["ATR"].shift(look_ahead) #We'll do the same for the stochastic data["STO 1"] = 0 data["STO 2"] = 0 data["STO 3"] = 0 #Set the states data.loc[data["Stoch Main"] > 80,"STO 1"] = 1 data.loc[data["Stoch Main"] < 20,"STO 2"] = 1 data.loc[(data["Stoch Main"] >= 20) & (data["Stoch Main"] <= 80) ,"STO 3"] = 1 #Set the change in the stochastic data["Change in STO"] = data["Stoch Main"] - data["Stoch Main"].shift(look_ahead) #Finally the moving averages data["MA 1"] = 0 data["MA 2"] = 0 #Set the states data.loc[data["MA Fast"] > data["MA Slow"],"MA 1"] = 1 data.loc[data["MA Fast"] < data["MA Slow"],"MA 2"] = 1 #Difference in the MA Height data["Change in MA"] = (data["MA Fast"] - data["MA Slow"]) - (data["MA Fast"].shift(look_ahead) - data["MA Slow"].shift(look_ahead)) #Difference in price data["Change in Close"] = data["Close"] - data["Close"].shift(look_ahead) #Clean the data data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) #Drop the last 2 years of test data data = data.iloc[:((-365*2) - 18),:] data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) data
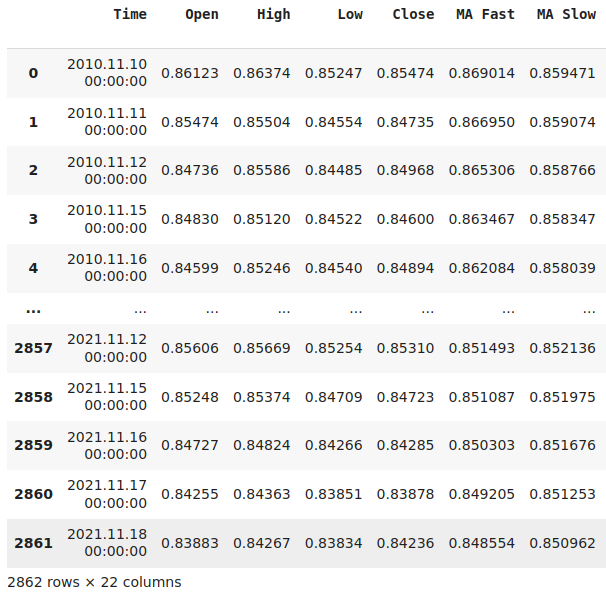
Abb. 16: Visualisierung unserer Marktdaten nach entsprechender Umwandlung
Schauen wir uns an, welche Form der Darstellung für unser Modell am effektivsten ist, um die Preisveränderung angesichts der Veränderung unserer Indikatoren zu lernen. Wir werden einen Baum mit einem Gradient-Boosting-Regressor als das Modell unserer Wahl verwenden.
#Let's see which method of presentation is most effective from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Wir definieren die Parameter unserer Zeitreihen-Kreuzvalidierung.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead) Nun wollen wir einen Schwellenwert festlegen. Jedes Modell, das durch die einfache Verwendung des Schlusskurses zur Vorhersage der Kursveränderung übertroffen werden kann, ist kein gutes Modell.
#Our baseline accuracy forecasting the change in price using current price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Close"]],data.loc[:,"Target"],cv=tscv))
-0.14861941262441164
Bei den meisten Problemen können wir immer besser abschneiden, wenn wir die Preisänderung und nicht nur den aktuellen Kurswert verwenden.
#Our accuracy forecasting the change in price using current change in price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in Close"]],data.loc[:,"Target"],cv=tscv))
-0.1033528767401429
Unser Modell kann noch besser abschneiden, wenn wir ihm stattdessen den stochastischen Oszillator geben.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Stoch Main"]],data.loc[:,"Target"],cv=tscv))
-0.09152071417994265
Aber ist das das Beste, was wir tun können? Was würde passieren, wenn wir stattdessen unser Modell, die Veränderung des stochastischen Oszillators, angeben würden? Unsere Fähigkeit, die Preisentwicklung vorherzusagen, wird besser!
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in STO"]],data.loc[:,"Target"],cv=tscv))
-0.07090156075020868
Was glauben Sie, was passiert, wenn wir jetzt unseren Dummy-Codierungsansatz durchführen? Wir haben 3 Spalten erstellt, die uns einfach sagen, in welchem Zustand sich der Indikator befindet. Unsere Fehlerquoten sinken. Dieses Ergebnis ist sehr interessant, da wir viel besser abschneiden als ein Händler, der versucht, Preisänderungen anhand des aktuellen Preises oder des aktuellen Wertes des Stochastik-Oszillators vorherzusagen. Wir wissen jedoch nicht, ob dies auf alle möglichen Märkte zutrifft. Wir sind davon überzeugt, dass dies nur für den EURGBP-Markt auf dem täglichen Zeitrahmen zutrifft.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"],cv=tscv))
Beurteilen wir nun unsere Genauigkeit bei der Vorhersage von Kursveränderungen anhand der aktuellen Werte der beiden gleitenden Durchschnitte. Die Ergebnisse sehen nicht gut aus, unsere Fehlerquoten sind höher als unsere Genauigkeit, wenn wir nur den Close-Preis zur Vorhersage der zukünftigen Preisänderung verwenden. Dieses Modell sollte aufgegeben werden und ist für den Einsatz in der Produktion nicht geeignet.
#Our accuracy forecasting the change in price using the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA Slow","MA Fast"]],data.loc[:,"Target"],cv=tscv))
Wenn wir unsere Daten so transformieren, dass wir die Veränderung der gleitenden Durchschnittswerte sehen können, werden unsere Ergebnisse besser. Es ist jedoch immer noch besser, ein einfacheres Modell zu verwenden, das nur den aktuellen Schlusskurs zugrunde legt.
#Our accuracy forecasting the change in price using the change in the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in MA"]],data.loc[:,"Target"],cv=tscv))
Wenn wir jedoch unsere Dummy-Codierungstechnik auf die Marktdaten anwenden, übertreffen wir jeden Händler auf demselben Markt, der gewöhnliche Kursnotierungen im täglichen Zeitrahmen verwendet. Unsere Fehlerquoten schrumpfen auf einen bisher nicht gekannten Tiefstand. Dieser Wandel ist gewaltig. Erinnern Sie sich daran, dass es dem Modell hilft, sich mehr auf die kritischen Veränderungen im Wert des Indikators zu konzentrieren, im Gegensatz zum Erlernen der genauen Zuordnung jedes möglichen Wertes, den unser Indikator annehmen kann.
#Our accuracy forecasting the change in price using the state of moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"],cv=tscv))
Für Leser, die sich zum ersten Mal mit diesem Thema beschäftigen, ist dieser Abschnitt besonders wichtig. Als Menschen neigen wir dazu, Muster zu erkennen, auch wenn sie nicht existieren. Nach dem, was Sie bisher gelesen haben, haben Sie vielleicht den Eindruck, dass Dummy-Codierung immer Ihr bester Freund ist. Dies ist jedoch nicht der Fall. Beobachten Sie, was passiert, wenn wir versuchen, unser endgültiges KI-Modell zu optimieren, das den zukünftigen ATR-Wert vorhersagen soll.
Vergleichen Sie die Ergebnisse, die Sie jetzt sehen werden, nicht mit den Ergebnissen, die wir gerade besprochen haben. Die Einheiten des Ziels haben sich geändert. Daher ist ein direkter Vergleich zwischen unserer Genauigkeit bei der Vorhersage von Kursveränderungen und unserer Genauigkeit bei der Vorhersage des zukünftigen ATR-Wertes praktisch nicht sinnvoll.
Wir schaffen im Wesentlichen eine neue Schwelle. Unsere Genauigkeit bei der Vorhersage der ATR auf der Grundlage früherer ATR-Werte ist unsere neue Basislinie. Jede Technik, die zu einem größeren Fehler führt, ist nicht optimal und sollte aufgegeben werden.
#Our accuracy forecasting the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR"]],data.loc[:,"ATR Target"],cv=tscv))
Bislang konnten wir heute feststellen, dass unsere Fehlerquoten immer dann sanken, wenn wir unserem Modell die Differenz der Daten im Gegensatz zu den Daten in ihrer aktuellen Form übergaben. Doch dieses Mal war der Fehler noch schlimmer.
#Our accuracy forecasting the ATR using the change in the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in ATR"]],data.loc[:,"ATR Target"],cv=tscv))
-0.5916640039518372
Zusätzlich haben wir den ATR-Indikator mit einer Dummy-Kodierung versehen, um anzuzeigen, ob er gestiegen oder gefallen ist. Unsere Fehlerquoten waren immer noch inakzeptabel. Daher werden wir unseren ATR-Indikator so verwenden, wie er ist, und der Stochastik-Oszillator und unsere gleitenden Durchschnitte werden als Dummy kodiert.
#Our accuracy forecasting the ATR using the current state of the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR 1","ATR 2"]],data.loc[:,"ATR Target"],cv=tscv))
Exportieren nach ONNX
Open Neural Network Exchange (ONNX) ist ein Open-Source-Protokoll, das eine universelle Darstellung für alle Modelle des maschinellen Lernens definiert. Dadurch können wir Modelle in jeder beliebigen Sprache entwickeln und gemeinsam nutzen, solange diese Sprache die ONNX-API vollständig unterstützt. ONNX ermöglicht es uns, die gerade entwickelten KI-Modelle zu exportieren und sie direkt in unseren KI-Modellen zu verwenden, um unsere Handelsentscheidungen zu treffen, im Gegensatz zur Verwendung fester Handelsregeln.
#Load the libraries we need import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Wir definieren die Eingabeform der einzelnen Modelle,
#Define the input shapes #ATR AI initial_types_atr = [('float_input', FloatTensorType([1, 1]))] #MA AI initial_types_ma = [('float_input', FloatTensorType([1, 2]))] #STO AI initial_types_sto = [('float_input', FloatTensorType([1, 3]))]
passen jedes Modell an alle Daten an, die wir haben
#ATR AI Model atr_ai = GradientBoostingRegressor().fit(data.loc[:,["ATR"]],data.loc[:,"ATR Target"]) #MA AI Model ma_ai = GradientBoostingRegressor().fit(data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"]) #Stochastic AI Model sto_ai = GradientBoostingRegressor().fit(data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"])
und speichern die ONNX-Modelle.
#Save the ONNX models onnx.save(convert_sklearn(atr_ai, initial_types=initial_types_atr),"EURGBP ATR.onnx") onnx.save(convert_sklearn(ma_ai, initial_types=initial_types_ma),"EURGBP MA.onnx") onnx.save(convert_sklearn(sto_ai, initial_types=initial_types_sto),"EURGBP Stoch.onnx")
Implementierung in MQL5
Wir werden denselben Handelsalgorithmus verwenden, den wir bisher entwickelt haben. Wir werden nur die festen Regeln ändern, die wir ursprünglich vorgegeben haben, und stattdessen unserer Handelsanwendung erlauben, ihre Handelsgeschäfte zu platzieren, wenn unsere Modelle uns ein klares Signal geben. Außerdem werden wir zunächst die von uns entwickelten ONNX-Modelle importieren.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the AI Modules | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP MA.onnx" as const uchar ma_onnx_buffer[]; #resource "\\Files\\EURGBP ATR.onnx" as const uchar atr_onnx_buffer[]; #resource "\\Files\\EURGBP Stoch.onnx" as const uchar stoch_onnx_buffer[];
Definieren wir nun die globalen Variablen, die die Prognosen unseres Modells speichern werden.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask; long atr_model,ma_model,stoch_model; vectorf atr_forecast = vectorf::Zeros(1),ma_forecast = vectorf::Zeros(1),stoch_forecast = vectorf::Zeros(1);
Wir müssen auch unser Deinitialisierungsverfahren aktualisieren. Unser Modell sollte auch die Ressourcen freigeben, die von unseren ONNX-Modellen verbraucht wurden.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); OnnxRelease(atr_model); OnnxRelease(ma_model); OnnxRelease(stoch_model); }
Die Erstellung von Vorhersagen aus unseren ONNX-Modellen ist nicht so aufwendig wie das Training der Modelle. Um unsere Handelsalgorithmen schnell zu testen, wird es jedoch teuer, für jeden Tick eine KI-Vorhersage zu erhalten. Unsere Backtests werden viel schneller sein, wenn wir stattdessen alle 5 Minuten Vorhersagen von unseren KI-Modellen abrufen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- Only on new candles static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_M5,0); if(time_stamp != current_time) { time_stamp = current_time; //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } } }
Wir müssen auch die Funktion aktualisieren, die für die Einrichtung unserer technischen Indikatoren zuständig ist. Die Funktion richtet unsere KI-Modelle ein und überprüft, ob die Modelle korrekt geladen wurden.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); //--- Create our onnx models atr_model = OnnxCreateFromBuffer(atr_onnx_buffer,ONNX_DEFAULT); ma_model = OnnxCreateFromBuffer(ma_onnx_buffer,ONNX_DEFAULT); stoch_model = OnnxCreateFromBuffer(stoch_onnx_buffer,ONNX_DEFAULT); //--- Validate our models if(atr_model == INVALID_HANDLE || ma_model == INVALID_HANDLE || stoch_model == INVALID_HANDLE) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } //--- Set the sizes of our ONNX models ulong atr_input_shape[] = {1,1}; ulong ma_input_shape[] = {1,2}; ulong sto_input_shape[] = {1,3}; if(!(OnnxSetInputShape(atr_model,0,atr_input_shape)) || !(OnnxSetInputShape(ma_model,0,ma_input_shape)) || !(OnnxSetInputShape(stoch_model,0,sto_input_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } ulong output_shape[] = {1,1}; if(!(OnnxSetOutputShape(atr_model,0,output_shape)) || !(OnnxSetOutputShape(ma_model,0,output_shape)) || !(OnnxSetOutputShape(stoch_model,0,output_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } }
In unserem früheren Handelsalgorithmus haben wir unsere Positionen einfach eröffnet, solange die Indikatoren für uns stimmten. Stattdessen eröffnen wir unsere Positionen, wenn unsere KI-Modelle uns ein klares Handelssignal geben. Darüber hinaus werden unsere Preise für Take-Profit und Stop-Loss dynamisch an die erwartete Volatilität angepasst. Wir hoffen, dass wir mit Hilfe der KI einen Filter geschaffen haben, der uns profitablere Handelssignale liefert.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Predict future ATR values vectorf atr_model_input = vectorf::Zeros(1); atr_model_input[0] = (float) atr[0]; //--- Predicting future price using the stochastic oscilator vectorf sto_model_input = vectorf::Zeros(3); if(stochastic[0] > 80) { sto_model_input[0] = 1; sto_model_input[1] = 0; sto_model_input[2] = 0; } else if(stochastic[0] < 20) { sto_model_input[0] = 0; sto_model_input[1] = 1; sto_model_input[2] = 0; } else { sto_model_input[0] = 0; sto_model_input[1] = 0; sto_model_input[2] = 1; } //--- Finally prepare the moving average forecast vectorf ma_inputs = vectorf::Zeros(2); if(fast_ma[0] > slow_ma[0]) { ma_inputs[0] = 1; ma_inputs[1] = 0; } else { ma_inputs[0] = 0; ma_inputs[1] = 1; } OnnxRun(stoch_model,ONNX_DEFAULT,sto_model_input,stoch_forecast); OnnxRun(atr_model,ONNX_DEFAULT,atr_model_input,atr_forecast); OnnxRun(ma_model,ONNX_DEFAULT,ma_inputs,ma_forecast); Comment("ATR Forecast: ",atr_forecast[0],"\nStochastic Forecast: ",stoch_forecast[0],"\nMA Forecast: ",ma_forecast[0]); //--- Can we buy? if((ma_forecast[0] > 0) && (stoch_forecast[0] > 0)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr_forecast[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((ma_forecast[0] < 0) && (stoch_forecast[0] < 0)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr_forecast[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Wir werden unseren Backtest über denselben Zeitraum wie zuvor durchführen, also von Anfang Januar 2022 bis Juni 2024. Wir erinnern uns, dass wir beim Training unseres KI-Modells keine Daten im Bereich des Backtests hatten. Wir werden den Test mit demselben Symbol, dem Paar EURGBP, auf demselben Zeitrahmen, dem täglichen Zeitrahmen, durchführen.
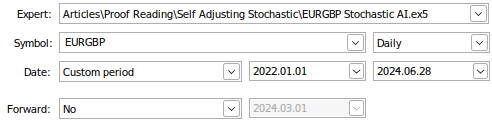
Abb. 17: Backtesting unseres AI-Modells
Wir werden alle anderen Parameter des Backtests so festlegen, dass unsere Tests im Wesentlichen identisch sind. Wir versuchen im Wesentlichen, den Unterschied zu isolieren, der dadurch entsteht, dass unsere Entscheidungen von unseren KI-Modellen getroffen werden.
Abb. 18: Die übrigen Parameter unseres Backtests
Unsere Handelsstrategie war während des Testzeitraums profitabler! Das ist eine gute Nachricht, denn den Modellen wurden die Daten, die wir für den Backtest verwenden, nicht angezeigt. Daher können wir positive Erwartungen haben, wenn wir dieses Modell für den Handel mit einem echten Konto verwenden.
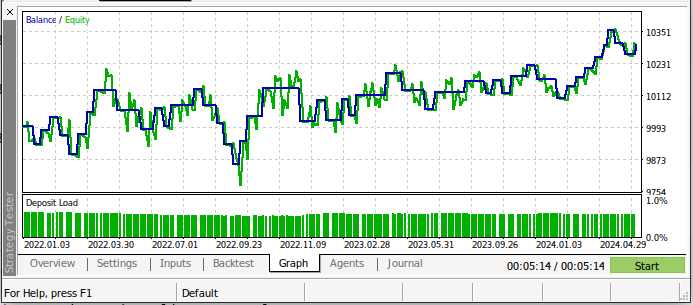
Abb. 19: Die Ergebnisse des Backtests unseres KI-Modells mit den Testdaten
Das neue Modell platzierte während des Backtests weniger Handelsgeschäfte, hatte aber einen höheren Anteil an Gewinnern als unser alter Handelsalgorithmus. Darüber hinaus ist unsere Sharpe Ratio jetzt positiv und nur 44 % unserer Trades waren Verlustgeschäfte.
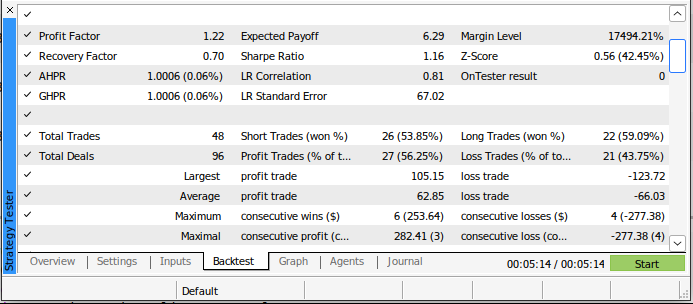
Abb. 20: Detaillierte Ergebnisse aus dem Backtesting unserer KI-gestützten Handelsstrategie
Schlussfolgerung
Nach der Lektüre dieses Artikels werden Sie mir hoffentlich zustimmen, dass KI tatsächlich zur Verbesserung unserer Handelsstrategien eingesetzt werden kann. Selbst die älteste klassische Handelsstrategie kann mithilfe von KI neu konzipiert und auf ein neues Leistungsniveau gebracht werden. Die Kunst besteht offenbar darin, Ihre Indikatordaten intelligent zu transformieren, damit die Modelle effektiv lernen können. Die heute vorgestellte Dummy-Codierungstechnik hat uns sehr geholfen. Wir können jedoch nicht davon ausgehen, dass dies die beste Wahl für alle möglichen Märkte ist. Es ist möglich, dass die Dummy-Codierungstechnik die beste Wahl für eine bestimmte Gruppe von Märkten ist. Wir können jedoch mit Zuversicht feststellen, dass die gleitenden Durchschnitte mit Hilfe von KI effektiv umgestaltet werden können.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16280
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Vielen Dank, Gamu. Ich genieße Ihre Veröffentlichungen und versuche zu lernen, indem ich Ihre Schritte reproduziere.
Ich habe einige Probleme hoffentlich kann dies anderen helfen.
1) meine Tests mit Ihnen EURGBP_Stochastic täglich mit dem Skript geliefert produziert nur 2 Aufträge und anschließend Sharpe Ratio von 0,02 . Ich glaube, ich habe die gleichen Einstellungen wie Sie, aber bei 2 Brokern werden nur 2 Orders erzeugt.
2) als Vorwarnung für andere müssen Sie eventuell die Symboleinstellungen an Ihren Broker anpassen (z.B. EURGBP an EURGBP.i), falls nötig
3) als nächstes, wenn ich versuche, die Daten zu exportieren, erhalte ich ein Array außerhalb des Bereichs für die ATR, was meiner Meinung nach daran liegt, dass ich keine 100000 Datensätze in mein Array bekomme (wenn ich es auf 677 ändere), kann ich dementsprechend eine Datei mit 677 Zeilen erhalten. für mich ist der Standardwert für maximale Balken in einem Diagramm 50000, wenn ich das auf 100000 ändere, ist meine Array-Größe nur 677, aber möglicherweise habe ich eine schlechte Einrichtung. Vielleicht könnten Sie auch das Datenextraktionsskript in Ihren Download aufnehmen.
4) Ich habe den Code aus Ihrem Artikel kopiert, um ihn in Python auszuprobieren. Ich erhalte einen Fehler look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: Name 'look_ahead' ist nicht definiert
5) Als ich Ihr Juypiter-Notizbuch lud, stellte ich fest, dass es eine Vorausschau benötigte #Lassen Sie uns 20 Schritte in die Zukunft voraussagen
look_ahead = 20 , Danach habe ich nur noch die von Ihnen beigefügte Datei verwendet, aber ich bleibe bei folgendem Fehler hängen, der möglicherweise damit zusammenhängt, dass ich nur 677 Zeilen habe.
Ich lasse #Scale die Daten laufen, bevor wir sie visualisieren
from sklearn.preprocessing import RobustScaler
Skalierer = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
was mir eine Fehlermeldung gibt, die ich nicht verstehe, wie ich sie lösen kann
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Es wird versucht, einen Wert auf eine Kopie eines Slice aus einem DataFrame zu setzen. Versuchen Sie es stattdessen mit .loc[row_indexer,col_indexer] = value Beachten Sie die Hinweise in der Dokumentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Vielen Dank, Gamu. Ich genieße Ihre Veröffentlichungen und versuche zu lernen, indem ich Ihre Schritte reproduziere.
Ich habe einige Probleme hoffentlich kann dies anderen helfen.
1) meine Tests mit Ihnen EURGBP_Stochastic täglich mit dem Skript geliefert produziert nur 2 Aufträge und anschließend Sharpe Ratio von 0,02 . Ich glaube, ich habe die gleichen Einstellungen wie Sie, aber auf 2 Brokern produziert es nur 2 Aufträge.
2) als Vorwarnung für andere müssen Sie die Symboleinstellungen ggf. an Ihren Broker anpassen (z.B. EURGBP an EURGBP.i)
3) als nächstes, wenn ich versuche, die Daten zu exportieren, erhalte ich ein Array außerhalb des Bereichs für die ATR, was meiner Meinung nach daran liegt, dass ich keine 100000 Datensätze in mein Array bekomme (wenn ich es auf 677 ändere), kann ich dementsprechend eine Datei mit 677 Zeilen erhalten. für mich ist der Standardwert für maximale Balken in einem Diagramm 50000, wenn ich das auf 100000 ändere, ist meine Array-Größe nur 677, aber möglicherweise habe ich eine schlechte Einrichtung. Vielleicht könnten Sie auch das Datenextraktionsskript in Ihren Download aufnehmen.
4) Ich habe den Code aus Ihrem Artikel kopiert, um ihn in Python auszuprobieren. Ich erhalte einen Fehler look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: Name 'look_ahead' ist nicht definiert
5) Als ich Ihr Juypiter-Notizbuch lud, stellte ich fest, dass es eine Vorausschau benötigte #Lassen Sie uns 20 Schritte in die Zukunft voraussagen
look_ahead = 20 , Danach habe ich nur die von Ihnen beigefügte Datei verwendet, aber ich bleibe bei dem folgenden Fehler hängen, der möglicherweise damit zusammenhängt, dass ich nur 677 Zeilen habe.
Ich führe #Scale the data aus, bevor wir mit der Visualisierung beginnen.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
was zu einer Fehlermeldung führt, deren Lösung ich nicht verstehe
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Es wird versucht, einen Wert auf eine Kopie eines Slice aus einem DataFrame zu setzen. Versuchen Sie es stattdessen mit .loc[row_indexer,col_indexer] = value Beachten Sie die Hinweise in der Dokumentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Was gibt's, Neil? Ich hoffe, es geht dir gut.
Danke Gamu Ich weiß das zu schätzen, ja ich weiß, dass es viele bewegliche Teile gibt, ich werde sehen, ob dies meine Probleme lösen wird
Vielen Dank Gamu Ich weiß das zu schätzen, ja ich weiß, dass es viele bewegliche Teile gibt, ich werde sehen, ob dies meine Probleme lösen wird