
MQL5で自己最適化エキスパートアドバイザーを構築する(第14回):フィードバックコントローラーにおけるデータ変換を調整パラメータとして捉える

どんな機械学習フレームワークやパイプラインにおいても、前処理は強力でありながら、しばしば軽視されがちな調整パラメータです。
前処理はパイプライン内で重要な調整項目であるにもかかわらず、目立つオプティマイザーや華やかなモデル構造の陰に隠れています。学術研究の多くはこれらに集中しており、前処理手法の効果を研究する時間はほとんど割かれていません。
データに施す前処理は、気づかれないまま、しばしば驚くほど大きくモデル性能に影響します。前処理におけるわずかな改善であっても、時間とともに複利的に作用し、取引アプリケーションの利益やリスクに実質的な影響を及ぼす可能性があります。
あまりにも多くの場合、前処理の作業は急いで済まされ、入力データに対して本当に最適な変換を見つけられているかを十分に検証する時間が取られません。
現代の私たちが依存する高度なオプティマイザーや機械学習アーキテクチャは、取り扱うデータに施す変換によって、気づかれないまま制約を受けることもあれば、逆にその性能を大きく引き出されることもあります。しかし残念ながら、現時点では特定の変換が最適であることを証明できる確立されたフレームワークは存在せず、より適した代替変換が存在しないと自信をもって言える指標もありません。さらに、異なる変換を組み合わせてハイブリッドな解法を構築する研究もほとんど進んでおらず、まさにこの領域に、まだ掘り起こされていない潜在的な性能向上の余地が隠されています。
そこで、本記事の目的は、以前の議論(リンク参照)で慎重に構築したフィードバックコントローラーの効率を向上させることです。
私たちが目指しているのは、単なる収益性の向上にとどまらず、リスクの低減や、より堅牢で、そしてある程度成熟した取引行動が取引アプリケーションに見られるようになることです。本質的には、この取り組みは前処理そのものを独立した調整要素として扱うものであり、適切に扱えば取引アプリケーションの結果を実質的に変えうる要素となり得ます。
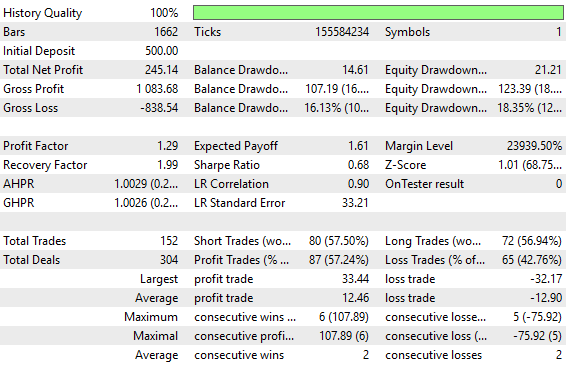
図1:旧バージョンのフィードバックコントローラーによるバックテスト統計
旧バージョンのフィードバックコントローラーの性能は、すべての指標で十分に許容範囲でした。しかし言うまでもなく、入力データに適切な変換を施すための検証に時間をかけることで、信号が十分に表れていなかったために休眠していた戦略の付加価値(アルファ)を引き出せる可能性があることを示します。
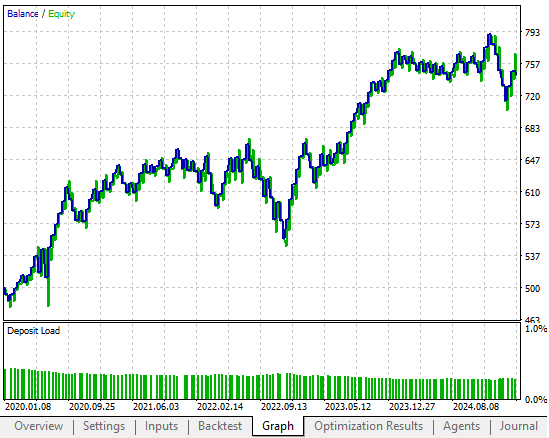
図2:旧エクイティカーブ(入力データに適切な変換を適用することで上回ることを目指す)
データセットに潜む豊富なパターンを露出させないままでは、時間とともに投資家資本が徐々に削られていきます。私たちは、フィードバックコントローラーに供給する入力データに対して、3種類の異なる変換をテストしました。コントロール設定として、前回の議論で用いた未変換(生)データを用いたベンチマークを実行しました。その後、各変換は他の変数をすべて一定に保ちながら、同一の過去データ上で検証されました。性能は、収益性、シャープレシオ、取引件数、総損失、利益取引比率の観点で評価され、3つのテスト間で前処理の効果を公平に比較できるようにしました。
最初にテストした変換は、標準的な統計手法であるzスコアです。Zスコアは、各列の値から平均を引き、その列の標準偏差で割ることで算出されます。この変換では、収益性がベースラインに比べて30%低下しました。これはいかなる指標から見ても魅力的とは言えません。加えて、シャープレシオもベースラインから10%も低下しました。
したがって、zスコア変換は私たちには適していませんでした。次に線形代数の分野から借用した単位スケーリング(Unit Scaling)という変換を適用しました。この変換は行列をそのノルムで割る操作で、今回は行列のL1ノルムを除数として使用しました。L1ノルムでスケーリングした後、収益性はベースライン比で12%改善し、魅力的な結果となりました。さらに、シャープレシオも30%改善しました。
また、総取引件数を減らしつつ収益性を高められることも、取引スキルの良い指標です。この点でも単位スケーリングは効果を示しました。総取引件数は8%減少し、総損失も15%減少しました。最後に、勝率も5%上昇しました。これにより、単位スケーリングがフィードバックコントローラーの性能を確実に改善したという強い確信を得ました。
最後に、zスコアと単位スケーリングを組み合わせたハイブリッド変換を試しました。残念ながら、これにより単位スケーリング単独で得られた改善はすべて失われました。収益性はベースライン比で58%低下し、シャープレシオも19%低下しました。したがって、直感に反して、2つの変換を組み合わせるハイブリッドは性能に破壊的であり、追加の構造を学習することはできませんでした。
以上の結果から、前処理は取引用の機械学習モデル構築において単なる手段ではなく、それ自体が独立した戦略であることが明確になります。変換の選択は、気づかないうちに機械学習モデルの性能に影響を与えます。利益を形作り、損失を歪め、そして私たちが直接理解していない形でリスクエクスポージャーを意図せず変化させます。
従来の統計学的学習は、この方向性に対してほとんど指針を与えません。交差検証による分割を通じた試行を除けば、普遍的で合意された基準は存在しません。したがって、前処理パイプラインのベンチマークに時間を投資し、それ自体を高レバレッジの調整パラメータとして扱うことが重要です。
さらに、この考え方は他の研究者や執筆者に対しても、自分たちの領域で適用可能なより多くの変換を探求するインセンティブとなります。画像認識や音声認識などの分野では、機械学習実務者が予測を試みる前に強固で広範な変換パイプラインが構築されることが一般的です。しかし、金融機械学習の分野では、前処理変換の強固なパイプラインを構築するための時間はほとんど割かれていません。
現在の条件下では、総当たりテストが妥当な戦略です。探索を重ねるほど、各変換の特性を理解しやすくなり、観察したすべての変換の中でどの変換が最適かを把握することが可能になります。
現在のベースラインの確認
まず始める前に、私たちが上回ろうとしている制御設定を確認することが重要です。どの最適化作業も、比較対象となるベンチマークやベースラインの性能レベルがなければ解釈が困難です。したがって、まず初期に実装したフィードバックコントローラーを簡単にレビューします。前回の記事を読んだ方には以下のコードは既に馴染みのある内容でしょう。初めての読者向けには、構築したアプリケーションおよび前回の議論からの主要ポイントを強調します。
このアプリケーションは、システム全体で一定に保たれる少数の定義に依存しています。たとえば、使用するテクニカル指標の期間、フィードバックコントローラーが入力を提供できる前に観察する取引日数、そしてコントローラーが入力として受け取る特徴量の総数などです。本例では、フィードバックコントローラーは12個の入力特徴量を使用します。重要なのは、前回の例では、この12個の入力に対していかなる変換、標準化、スケーリングも適用していなかったことです。
アプリケーションは、取引の開始と終了を管理するTradeライブラリ、ローソク足の形成を追跡するTimeライブラリ、最小ロットサイズや現在の買値や売値などの情報を提供するTradeInfoライブラリといった、いくつかのグローバル変数やライブラリに依存しています。
初回の初期化時には、カスタムライブラリの新しいインスタンスを作成し、テクニカル指標を設定し、ほとんどのグローバル変数をデフォルト値で初期化します。アプリケーションの使用が終了すると、動的オブジェクトやテクニカル指標は解放されます。
OnTick関数が呼び出されると、まず完全なローソク足が形成されたかを確認します。形成されていれば、最新の終値で移動平均バッファを更新します。ポジションが開かれていない場合、次に取引ロジックを適用します。このロジックでは、同一期間の高値移動平均と安値移動平均で形成される移動平均チャネルを使用します。価格がチャネルを上抜けた場合に買い、下抜けた場合に売ります。それ以外の場合は待機します。
初めの90日間は、システムがほぼ即時に売買をおこなえるように許可されます。しかしその期間を過ぎると、取引にはフィードバックコントローラーによる予測が必要になります。コントローラーが取引の利益性に自信を持っている場合は許可され、それ以外の場合はシステムは抑制されます。
これがフィードバックコントローラーの本質です。最初の90日間はシステムへの入力を控え、その後、take_snapshotsメソッドでシステム性能の観測を定期的に収集し、fit_snapshotsメソッドでそれらの観測に対する線形解を求めます。解が得られた後、システムは予測をおこなうことができます。
以下が取引戦略のベースラインバージョンです。
//+------------------------------------------------------------------+ //| Closed Loop Feedback.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ja/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" /** Closed Loop Feedback Control allows us to learn how to control our system's dynamics. It is challenging to perform in action, but worth every effort made towards it. Certain tasks, such as deciding when to increase your lot size, are not always easy to plan explicitly. We can rather observe our average loss size after say, 20 trades at minimum lot. From there, we can calculate how much on average, we expect to lose on any trade. And then set meaningful profit targets to accumulate, before increasing out lot size. We do not always know these numbers ahead of time. Additionally, we can train predictive models, that attempt to learn when our system is loosing and keep us out of loosing trades. The models we desire are not directly predicting the market per say. Rather, they are observing the relationship between a fixed strategy and a dynamic market. After allowing a certain number of observations, the predictive model may be permitted to give inputs that override the original strategy only if the model expects the strategy to lose, yet again. These family of algorithms may one day make it possible for us to truly design strategies that require no tuning parameters at all! I am excited to present this to you, but there is a long road ahead. Let us begin. **/ //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define MA_PERIOD 10 #define OBSERVATIONS 90 #define FEATURES 12 #define ACCOUNT_STATES 3 //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_h_handler,ma_l_handler,atr_handler,scenes,b_matrix_scenes; double ma_h[],ma_l[],atr[]; matrix snapshots,OB_SIGMA,OB_VT,OB_U,b_vector,b_matrix; vector S,prediction; vector account_state; bool predict,permission; //+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; Time *DailyTimeHandler; TradeInfo *TradeInfoHandler; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- DailyTimeHandler = new Time(Symbol(),PERIOD_D1); TradeInfoHandler = new TradeInfo(Symbol(),PERIOD_D1); ma_h_handler = iMA(Symbol(),PERIOD_D1,MA_PERIOD,0,MODE_EMA,PRICE_HIGH); ma_l_handler = iMA(Symbol(),PERIOD_D1,MA_PERIOD,0,MODE_EMA,PRICE_LOW); atr_handler = iATR(Symbol(),PERIOD_D1,14); snapshots = matrix::Ones(FEATURES,OBSERVATIONS); scenes = 0; b_matrix_scenes = 0; account_state = vector::Zeros(3); b_matrix = matrix::Zeros(1,1); prediction = vector::Zeros(2); predict = false; permission = true; //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete DailyTimeHandler; delete TradeInfoHandler; IndicatorRelease(ma_h_handler); IndicatorRelease(ma_l_handler); IndicatorRelease(atr_handler); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(DailyTimeHandler.NewCandle()) { CopyBuffer(ma_h_handler,0,0,1,ma_h); CopyBuffer(ma_l_handler,0,0,1,ma_l); CopyBuffer(atr_handler,0,0,1,atr); double c = iClose(Symbol(),PERIOD_D1,0); if(PositionsTotal() == 0) { account_state = vector::Zeros(ACCOUNT_STATES); if(c > ma_h[0]) { if(!predict) { if(permission) Trade.Buy(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetAsk(),(TradeInfoHandler.GetBid()-(atr[0]*2)),(TradeInfoHandler.GetBid()+(atr[0]*2)),""); } account_state[0] = 1; } else if(c < ma_l[0]) { if(!predict) { if(permission) Trade.Sell(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetBid(),(TradeInfoHandler.GetAsk()+(atr[0]*2)),(TradeInfoHandler.GetAsk()-(atr[0]*2)),""); } account_state[1] = 1; } else { account_state[2] = 1; } } if(scenes < OBSERVATIONS) { take_snapshots(); } else { matrix temp; temp.Assign(snapshots); snapshots = matrix::Ones(FEATURES,scenes+1); //--- The first row is the intercept and must be full of ones for(int i=0;i<FEATURES;i++) snapshots.Row(temp.Row(i),i); take_snapshots(); fit_snapshots(); predict = true; permission = false; } scenes++; } } //+------------------------------------------------------------------+ //| Record the current state of our system | //+------------------------------------------------------------------+ void take_snapshots(void) { snapshots[1,scenes] = iOpen(Symbol(),PERIOD_D1,1); snapshots[2,scenes] = iHigh(Symbol(),PERIOD_D1,1); snapshots[3,scenes] = iLow(Symbol(),PERIOD_D1,1); snapshots[4,scenes] = iClose(Symbol(),PERIOD_D1,1); snapshots[5,scenes] = AccountInfoDouble(ACCOUNT_BALANCE); snapshots[6,scenes] = AccountInfoDouble(ACCOUNT_EQUITY); snapshots[7,scenes] = ma_h[0]; snapshots[8,scenes] = ma_l[0]; snapshots[9,scenes] = account_state[0]; snapshots[10,scenes] = account_state[1]; snapshots[11,scenes] = account_state[2]; } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Fit our linear model to our collected snapshots | //+------------------------------------------------------------------+ void fit_snapshots(void) { matrix X,y; X.Reshape(FEATURES,scenes); y.Reshape(FEATURES-1,scenes); for(int i=0;i<scenes;i++) { X[0,i] = snapshots[0,i]; X[1,i] = snapshots[1,i]; X[2,i] = snapshots[2,i]; X[3,i] = snapshots[3,i]; X[4,i] = snapshots[4,i]; X[5,i] = snapshots[5,i]; X[6,i] = snapshots[6,i]; X[7,i] = snapshots[7,i]; X[8,i] = snapshots[8,i]; X[9,i] = snapshots[9,i]; X[10,i] = snapshots[10,i]; X[11,i] = snapshots[11,i]; y[0,i] = snapshots[1,i+1]; y[1,i] = snapshots[2,i+1]; y[2,i] = snapshots[3,i+1]; y[3,i] = snapshots[4,i+1]; y[4,i] = snapshots[5,i+1]; y[5,i] = snapshots[6,i+1]; y[6,i] = snapshots[7,i+1]; y[7,i] = snapshots[8,i+1]; y[8,i] = snapshots[9,i+1]; y[9,i] = snapshots[10,i+1]; y[10,i] = snapshots[11,i+1]; } //--- Find optimal solutions b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); Print(y.Col(scenes-1)); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); if(prediction[4] > AccountInfoDouble(ACCOUNT_BALANCE)) permission = true; else if((account_state[0] == 1) && (prediction[6] > ma_h[0])) permission = true; else if((account_state[1] == 1) && (prediction[7] < ma_l[0])) permission = true; else permission = false; if(permission) { if(PositionsTotal() == 0) { if(account_state[0] == 1) Trade.Buy(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetAsk(),(TradeInfoHandler.GetBid()-(atr[0]*2)),(TradeInfoHandler.GetBid()+(atr[0]*2)),""); else if(account_state[1] == 1) Trade.Sell(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetBid(),(TradeInfoHandler.GetAsk()+(atr[0]*2)),(TradeInfoHandler.GetAsk()-(atr[0]*2)),""); } } Print("Current Balabnce: ",AccountInfoDouble(ACCOUNT_BALANCE)," Predicted Balance: ",prediction[4]," Permission: ",permission); } //+------------------------------------------------------------------+
アプリケーションのテスト期間も、すべてのテストで固定しておく必要がある重要なパラメータです。前回の議論では、アプリケーションを2020年1月1日から2025年までバックテストしました。したがって、すべてのテストでこの期間を同一に保ちます。

図3:前回フィードバックコントローラーで使用したテスト期間
以下に、前回のフィードバックコントローラーで達成された性能レベルのスクリーンショットを添付します。読者が今回目指す性能レベルと比較できるように、このスクリーンショットは冒頭でも提供しました。
記事の導入部分ではすでに、以前達成された性能レベルと今回目指す性能レベルの主要な違いを包括的にまとめていますが、スクリーンショットを提示することで、読者自身が自由に確認し、検証できる余地も残しています。
図4:ベンチマークが5年間のバックテストで示した性能レベルの詳細分析
以下に示すエクイティカーブは、初回議論において有望な可能性を示しました。しかし、今回提示する例の1つでは、過去に達成された水準よりもはるかに高い収益率で成長が加速していることが確認できます。
図5:フィードバックコントローラーの初期バージョンで生成したエクイティカーブはすでに要求を満たしていた
Zスコア(標準的統計変換)
Zスコア変換は、標準的な統計手法であり、一般的にどのデータセットに対しても最初に試すべき有用な手法とされています。この変換の目的は、各列が持つ異なるスケールや次元、そしてそれらの比率を保持することにあります。これにより、モデルは成長の比較を意味のある一貫した形でおこなえるようになります。スケールを考慮しない場合、モデルは各列の成長やそれが目的変数に与える影響を不釣り合いに判断してしまう可能性があります。Zスコア変換はこれを解決する手法で、各列の平均値を引き、その列の標準偏差で割る操作をおこないます。その結果、各列の平均値は0、標準偏差は1となります。
図6:フィードバックコントローラーの入力データに適用した統計的Zスコア変換の数式
if(PositionsTotal() == 0) { //--- Find optimal solutions //--- Z-Score X = ((X - X.Mean())/X.Std()); b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]);
記事の導入部分で述べた通り、テスト期間はすべてのテストで同一に保たれます。上記の図3に示されているように、2020年1月1日から2025年5月までの期間を使用します。
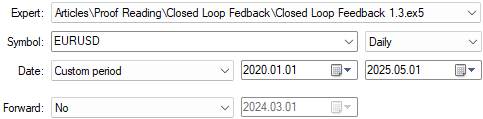
図7:上記で示したバックテスト期間はすべてのテストで同一に維持される
すでに述べた通り、Zスコア変換は5年間のテスト期間において性能向上には寄与しませんでした。実際のところ、主要な性能指標に対して全般的に悪影響を及ぼしました。
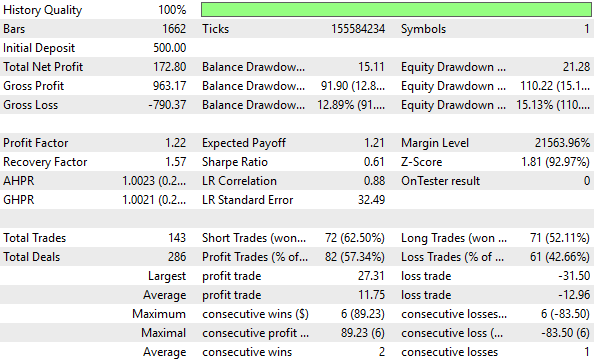
図8:Zスコア変換によって得られた性能指標の詳細分析では顕著な改善は確認できない
前回の議論で用いた制御設定は、下記に示すZスコア変換によるエクイティカーブよりも収益性が高い結果となりました。したがって、この変換は元のデータに存在していたシグナルを破壊してしまったと結論づけることができます。
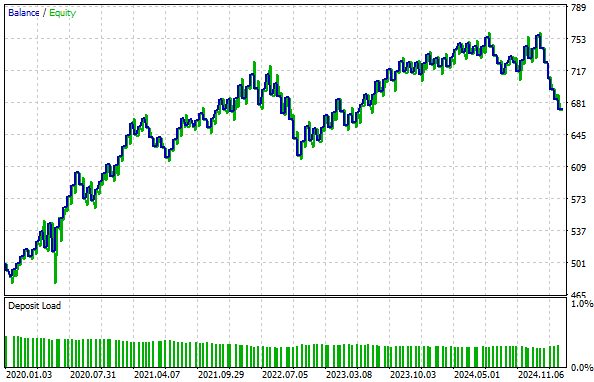
図9:Zスコア変換によって生成されたエクイティカーブは、制御設定で生成したエクイティカーブを上回ることができなかった
単位スケーリング(標準的線形代数変換)
単位スケーリングの考え方は線形代数学の分野から借用されたものです。この概念を十分に理解するためには少し背景が必要です。というのも、ここでの議論では標準的な方法で適用しているわけではないからです。そのため、この考え方に初めて触れる読者のために、簡単な導入を示す必要があります。
数値のリスト、たとえばMQL5での単純な配列に10個の数値があるとします。この配列の「大きさ」を測る方法はいくつもあります。線形代数では、この大きさをオブジェクトのノルムと呼びます。そのオブジェクトはベクトルや行列である場合もありますが、この単純な例では数値の配列のみを考えます。ここでは「配列」と「ベクトル」という言葉をほぼ同義で使います。
配列の大きさを定義する方法はいくつかあります。
- 現在の要素数で測る方法
- 最大容量として保持できる要素数で測る方法
- 現在の全要素の値を合計して測る方法
この問題を回避するために、加算前に変換を適用できます。たとえば、各数値の絶対値を取る、あるいは二乗してから加算する、といった方法です。これらの異なるアプローチは、Lpノルムと呼ばれるノルムのファミリーを形成します。
このファミリーで重要なノルムの1つがL1ノルムです。L1ノルムとは、配列の全要素の絶対値の合計です。数学的には、下記の図10に示されます。
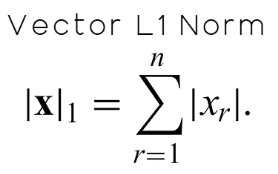
図10:ベクトルのL1ノルムは全要素の絶対値の合計として定義される
L1ノルムを計算した後、配列のすべての値をこのノルムで割ります。この操作が線形代数における単位スケーリングであり、ノルムが1となるよう正規化されたベクトルを得ることができます。つまり、再度ノルムを計算すると結果は正確に1となります。
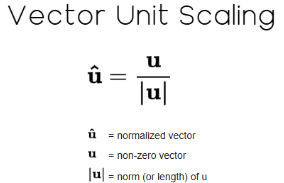
図11:ベクトルの単位スケーリングは線形代数での標準的変換である
ベクトルに対しては、この手法は比較的単純です。しかし、私たちの場合は状況が少し異なり、単なるベクトルではなく行列を扱います。議論の冒頭で述べたように、私たちのデータ行列Xは12個の特徴量を持っています。この場合、行列のL1ノルムを用いる必要があります。行列のL1ノルムはベクトルのL1ノルムと同一ではありませんが、関連性があります。
現行のMQL5ドキュメントによれば、執筆時点で行列のL1ノルムは「MATRIX_NORM_P1は行列の横方向ベクトルのp1ノルムの最大値として定義される」とされています。
この定義は正確ですが、初めてこの概念に触れる読者には直感的に理解しにくいかもしれません。そこで、より実践的な手順として説明すると、まず行列の各行についてL1ノルムを計算し、その後、L1ノルムが最大の行を特定します。この最大値が行列全体のL1ノルムとなります。この手順はMQL5ドキュメントの定義に沿ったものであり、数学的には図12に示す表記で表されます。
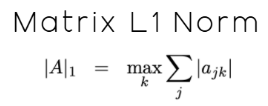
図12:行列のL1ノルムはベクトルのL1ノルムと同一ではないが関連している
L1ノルムを計算した後、データセットのすべての列をこの値で割ります。これにより、データに単位スケーリングの変形が適用されます。
if(PositionsTotal() == 0) { //--- Find optimal solutions //--- We Must Take The Additional Steps Needed To Standardize & Scale Our Inputs X = X/X.Norm(MATRIX_NORM_P1); b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]);
前述の通り、公平な比較を確保するために、すべてのバックテスト期間はすべてのテストで同一に維持します。
図13:すべてのテストで使用したバックテスト期間は固定されたままである
すでにご存じの通り、単位スケーリングの変形はベンチマークに対して性能を実質的に向上させ、これまで達成できなかった新たな高みへと引き上げました。この変換によりデータ内のシグナルが明確に表れ、モデルはより意味のあるパターンを検出できるようになりました。すべての変換がこのように機能するわけではありませんが、効果を発揮した場合は測定可能な改善を生み出します。そして測定可能な改善こそが、真に価値のある改善です。
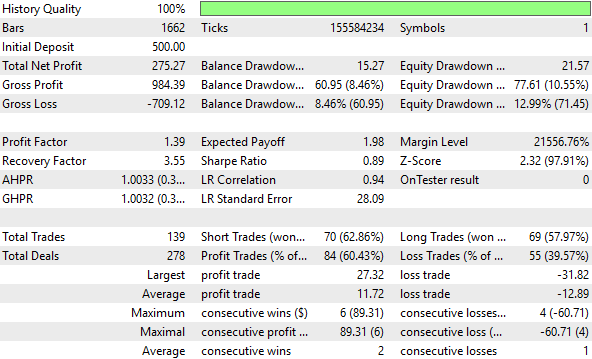
図14:改良されたフィードバックコントローラーによって達成された性能レベルの詳細分析
作成されたエクイティカーブを確認すると、収益性は最大800に達し、以前の設定では達成できなかった水準に到達しています。さらに、導入部分で述べた通り、口座残高が500から700に成長するまでにかかる時間がほぼ3分の1に短縮されており、成長速度が著しく向上しています。
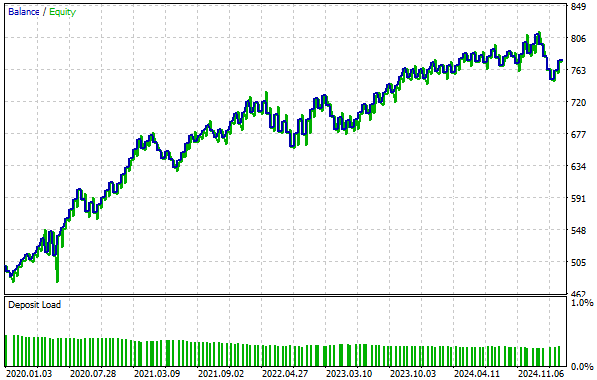
図15:新たに生成されたエクイティカーブは、初期のフィードバックコントローラーよりもさらに速く上昇している
ハイブリッドアプローチ(単位スケーリングとZスコア)
本記事のこの段階において、導入部で述べた通り、変換に関する正式な規則は定められていません。この分野では、アイデアを試し性能を観察する以外にほとんど手段がないため、「総当たり攻撃」によるテストは十分に妥当と考えられます。この直感に基づき、より強力な成果を期待して、2つの変換を組み合わせる試みをおこないました。
if(PositionsTotal() == 0) { //--- Find optimal solutions //--- We Must Take The Additional Steps Needed To Standardize & Scale Our Inputs X = X/X.Norm(MATRIX_NORM_P1); X = ((X-X.Mean())/X.Std()); b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]);
残念ながら、このハイブリッドアプローチは概ね収益性に乏しい結果となりました。初めは有望に見えたものの、2つの変換を組み合わせたことにより、主要な性能指標すべてに悪影響を与えました。
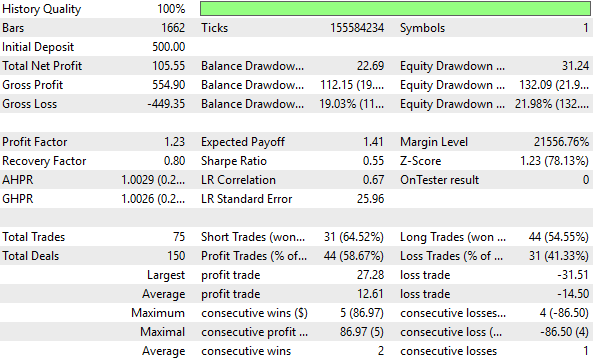
図16:ハイブリッドアプローチは、このテスト全体で観察された最も低い性能レベルを示した
総取引のうち利益が出た割合はわずかに上昇し、ハイブリッド設定で57.24%から58.67%となりましたが、これは意味のある改善とは言えません。さらに、ハイブリッド戦略によって生成されたエクイティカーブは500から600の間に停滞しており、口座残高が時間とともに成長することはありません。したがって、この変換は入力データに存在していたシグナルを破壊し、モデルにとって価値のある関係性をもはや露出させないと結論づけられます。
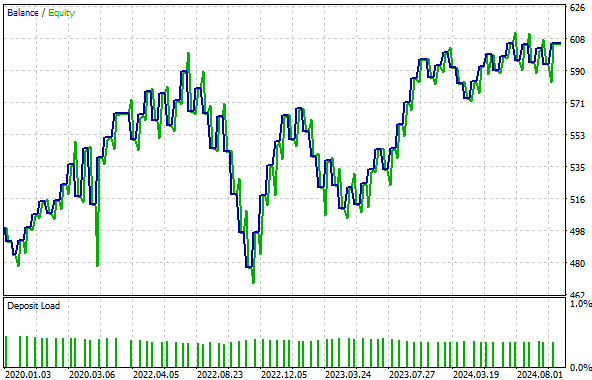
図17:取得したエクイティカーブはもはや成長せず、むしろ収益性の低い状態で停滞している
結論
本議論を通じて、読者には、機械学習モデルに入力するデータに適用する前処理について新たな理解を得ていただきたいと思います。前処理の段階は、機械学習パイプラインにおける高いレバレッジを持つ調整パラメータであり、注意深く粘り強く適用することで初めて有益な成果をもたらすものであると認識していただければ幸いです。
データセットに適用可能な変換は数多く存在しますが、残念ながらどの変換が最適かを常に把握できるわけではなく、特定の変換が有効かどうかを即座に判断することも容易ではありません。しかし、本記事で示したように、制御されたフレームワークを用い、まずベンチマークとなる性能レベルを設定し、その上で各アイデアを一貫して比較検証することで、元データに隠れていた構造やパターンを明らかにすることが可能です。
したがって、読者には可能な限り多くの変換に触れ、さまざまなアプローチを試し、性能を真に向上させる方法を発見することが重要です。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/19382
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索