
重构经典策略(第十一部分)移动平均线的交叉(二)

我们之前已经讨论过预测移动平均线交叉的概念, 这是原文。我们观察到,移动平均线交叉比直接预测价格变化更容易预测。今天,我们将重新审视这个熟悉的问题,但采用一种完全不同的方法。
我们现在想要彻底研究这对我们的交易程序有多大影响,以及这一方案如何改进您的交易策略。移动平均线交叉是现存最古老的交易策略之一。使用如此广为人知的技术构建盈利策略是一项挑战。然而,我希望在这篇文章中向您展示,“老狗”确实可以学会新把戏。
为了使我们的比较具有实证性,我们首先将在MQL5中为EURGBP货币对构建一个仅使用以下指标的交易策略:
- 两条应用于收盘价的指数移动平均线。一条周期为20,另一条设置为60。
- 随机振荡器,使用默认设置5,3,3,设置为指数移动平均模式,并在CLOSE_CLOSE模式下进行计算。
- 平均真实波动范围指标(ATR),周期为14,用于设置我们的获利和止损水平。
我们将在文章后面详细探讨进行回测时使用的参数。然而,我们将注意回测期间的关键绩效指标,如夏普比率、盈利交易的比例、最大利润和其他重要的绩效指标。
完成后,我们将用从市场数据中学到的算法交易规则替换所有传统的交易规则。我们将训练3个人工智能模型来学习预测:
- 未来波动性:通过训练人工智能模型预测平均真实范围(ATR)读数来实现。
- 价格变化与移动平均线交叉之间的关系:我们将为移动平均线创建2个离散状态,其同一时刻只能处于其中一种状态。这将帮助我们的人工智能模型专注于指标的关键变化以及这些变化对未来价格水平的平均影响。
- 价格变化与随机振荡器之间的关系:这一次我们将创建3个离散状态,随机振荡器同一时刻只能占据其中一种状态。然后我们的模型将学习随机振荡器关键变化的平均影响。
这3个人工智能模型将不会在我们将用于回测的时间段上进行训练。我们的回测将从2022年运行到2024年6月,而我们的人工智能模型将从2011年训练到2021年。确保训练和回测不重叠,以便尽可能接近模型在未见数据上的真实表现。
信不信由你,我们成功了,所有绩效指标得到全面提升。我们的新交易策略更有利可图,夏普比率有所提高,并且在回测期间进行的所有交易中,盈利交易超过一半,即55%。
如果这样一个经典且被广泛使用的策略可以变得更有利可图,我相信这将鼓舞每个读者,他们的策略也可以变得更有利可图,只要能够以正确的方式构建它。
大多数交易者都花费大量时间来创建他们的交易策略,并且几乎不会详细讨论他们视为珍宝的个人策略。因此,移动平均线交叉作为一个常规策略被当做讨论点,这样社区的所有成员都可以将其用作基准。我希望提供一个通用框架,您可以用自己的交易策略来补充,并且按照这个框架进行,您应该会看到自己策略的一些改进。
让我们开始
在开始前,我们先打开MetaEditor IDE环境并通过创建一个交易程序来作为程序的基本框架。
我们想要创建一个简单移动平均线交叉策略,让我们开始吧。首先导入交易类库。
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
定义全局变量。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask;
为我们的技术指标创建句柄。
//+------------------------------------------------------------------+ //| Technical indicator handlers | //+------------------------------------------------------------------+ int slow_ma_handler,fast_ma_handler,stochastic_handler,atr_handler; double slow_ma[],fast_ma[],stochastic[],atr[];
我们还将设定一些变量作为常量。
//+------------------------------------------------------------------+ //| Constants | //+------------------------------------------------------------------+ const int slow_period = 60; const int fast_period = 20; const int atr_period = 14;
一些输入参数需要手动设置。比如交易量和止损。
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Money Management" input int lot_multiple = 5; //Lot size input group "Risk Management" input int atr_multiple = 5; //Stop Loss Width
当系统启动后,我们需要调用一个特别的函数来设置技术指标比保存市场数据。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our technical indicators and fetch market data setup(); //--- return(INIT_SUCCEEDED); }
否则,如果我们不再使用这个交易程序了,就让我们释放这些不需要的资源。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); }
如果市场中没有未平仓头寸,我们就寻找机会下单。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } }
这个函数将初始化我们的技术指标并保存用户设定的交易量大小。
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); }
创建一个函数来保存我们接收到的价格数据。
//+------------------------------------------------------------------+ //| Fetch updated market data | //+------------------------------------------------------------------+ void update(void) { //--- Update our market prices bid = SymbolInfoDouble("EURGBP",SYMBOL_BID); ask = SymbolInfoDouble("EURGBP",SYMBOL_ASK); //--- Copy indicator buffers CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(slow_ma_handler,0,0,1,slow_ma); CopyBuffer(fast_ma_handler,0,0,1,fast_ma); CopyBuffer(stochastic_handler,0,0,1,stochastic); }
下面这个函数将用于最终检查交易信号。如果发现信号,我们将开立头寸,并设置由ATR确定的止损和获利水平。
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Can we buy? if((fast_ma[0] > slow_ma[0]) && (stochastic[0] > 80)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((fast_ma[0] < slow_ma[0]) && (stochastic[0] < 20)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
现在可以开始对我们的交易系统进行回测了。我们将使用上面刚刚定义的简单移动平均线交叉交易算法,在EURGBP日线市场数据上进行训练。回测时间段将从2022年1月开始,一直到2024年6月底。我们会将“Forward”参数设置为false。市场数据将使用真实tick来建模,我们的终端将不得不向我们的经纪商请求这些数据。这将确保测试结果真实模拟当天实际发生的市场条件。
图1:我们用于回测的一些设置
图2:我们用于回测的其余参数
我们最初的回测结果并不令人兴奋。交易策略在整个测试期间都在亏损。然而,这也不足为奇,因为我们已经知道移动平均线交叉是一种延迟的交易信号。下面的图3总结了我们在测试期间的交易账户余额。
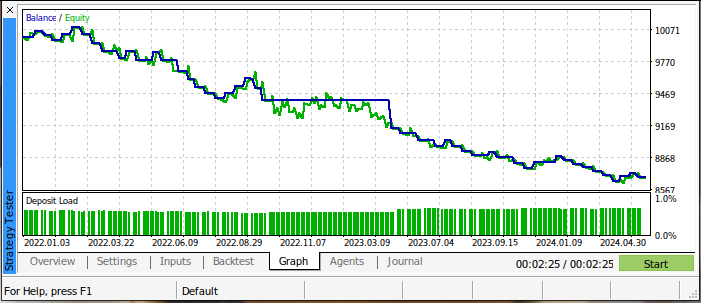
图3:我们在进行回测时的交易账户余额
我们的夏普比率是-5.0,我们在进行的所有交易中亏损了69.57%。平均亏损大于平均盈利。这些都是糟糕的绩效指标。如果我们使用这个交易系统,按照其目前的状态,肯定会迅速损失资金。
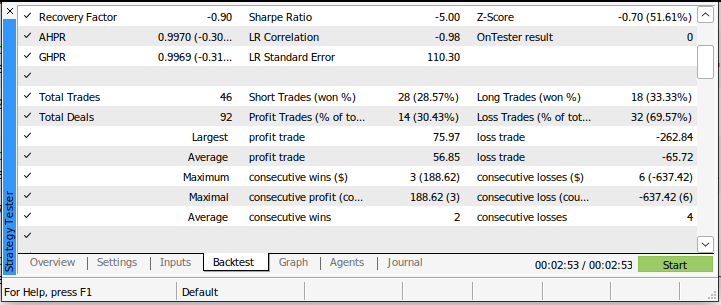
图4:使用传统方法交易市场的回测细节
依赖于移动平均线交叉和随机振荡器的策略已经被广泛利用,作为人类交易者,我们不太可能从中获得任何实质性的优势。但这并不意味着我们的AI模型不能学习到任何实质性的优势。我们将采用一种特殊的转换,称为“虚拟编码”,来向我们的AI模型表示市场的当前状态。
当您有一个无序的分类变量时,会使用虚拟编码,我们为它可能取的每个值分配一列。例如,假设MQL5团队允许您决定您想要的MetaTrader 5安装的颜色主题。您的选项是红色、粉色或蓝色。我们可以通过拥有一个分别名为“红色”、“粉色”和“蓝色”的3列数据库来捕获这些信息。在安装期间您选择的列将被设置为1,其他列将保持0。这就是虚拟编码背后的想法。
虚拟编码之所以强大,是因为如果我们选择了不同的信息表示方式,例如1-红色、2-粉色和3-蓝色,我们的AI模型可能会学到数据中不存在的虚假交互。例如,模型可能会学到2.5可能是最佳颜色。因此,虚拟编码帮助我们以一种确保模型不会隐含地假设它所接收的数据存在某种区间,来向模型呈现分类信息。
我们的移动平均线将有两个状态,当快速移动平均线高于慢速移动平均线时,第一个状态将被激活。否则,第二个状态将被激活。在任何时刻,只能激活一个状态。价格不可能同时处于两种状态。同样,我们的随机振荡器将有3个状态。如果价格对应的指标超过80时,将激活第一个状态;当价格低于20时,将激活第二个状态。否则,将激活第三个状态。
激活的状态将被设置为1,所有其他状态将被设置为0。这种转换将迫使我们的模型学习当价格在指标的不同状态之间移动时,目标的平均变化。这与专业人类交易者所做的非常接近。交易不像工程学,我们不能期望毫米级的精度。相反,最好的人类交易者,随着时间的推移,学会了最有可能发生的事情。使用虚拟编码来训练我们的模型将达到同样的目的。我们的模型将优化其参数,以学习给定技术指标当前状态下的价格平均变化。
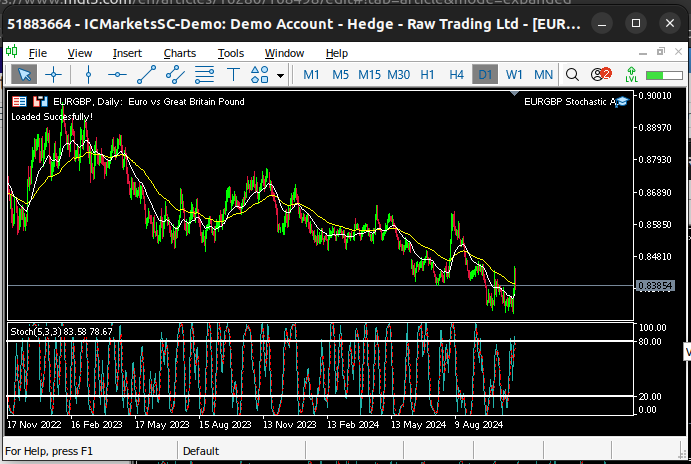
图5:可视化EURGBP日线市场
我们构建AI模型的第一步是获取需要的数据。始终最好获取您将在生产中使用的确切数据。这就是为什么我们将使用这个MQL5脚本从MetaTrader 5终端获取所有市场数据。不同库中指标值的计算方式存在意外差异,可能会使我们在一天结束时得到不满意的结果。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_fast_handler,ma_slow_handler,stoch_handler,atr_handler; double ma_fast[],ma_slow[],stoch[],atr[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator ma_fast_handler = iMA(Symbol(),PERIOD_CURRENT,20,0,MODE_EMA,PRICE_CLOSE); ma_slow_handler = iMA(Symbol(),PERIOD_CURRENT,60,0,MODE_EMA,PRICE_CLOSE); stoch_handler = iStochastic(Symbol(),PERIOD_CURRENT,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR(Symbol(),PERIOD_D1,14); //--- Load the indicator values CopyBuffer(ma_fast_handler,0,0,size,ma_fast); CopyBuffer(ma_slow_handler,0,0,size,ma_slow); CopyBuffer(stoch_handler,0,0,size,stoch); CopyBuffer(atr_handler,0,0,size,atr); ArraySetAsSeries(ma_fast,true); ArraySetAsSeries(ma_slow,true); ArraySetAsSeries(stoch,true); ArraySetAsSeries(atr,true); //--- File name string file_name = "Market Data " + Symbol() +" MA Stoch ATR " + " As Series.csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MA Fast","MA Slow","Stoch Main","ATR"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), ma_fast[i], ma_slow[i], stoch[i], atr[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
探索性数据分析
既然我们已经获取了市场数据,那么让我们开始分析这些数据吧。
#Import the libraries import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
读取数据。
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv")
添加一个二进制目标来帮我们可视化这些数据。
#Let's visualize the data data["Binary Target"] = 0 data.loc[data["Close"].shift(-look_ahead) > data["Close"],"Binary Target"] = 1 data = data.iloc[:-look_ahead,:]
缩放数据。
#Scale the data before we start visualizing it from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
我们使用plotly库来可视化数据。
import plotly.express as px
让我们看看慢速和快速移动平均线在帮助我们区分市场上涨和下跌走势方面表现如何。
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average fig = px.scatter_3d( data, x=data.index, y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of Time, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'Time', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
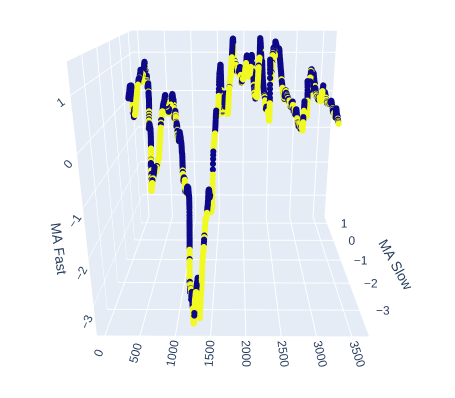
图6:可视化移动平均和目标值之间的关系
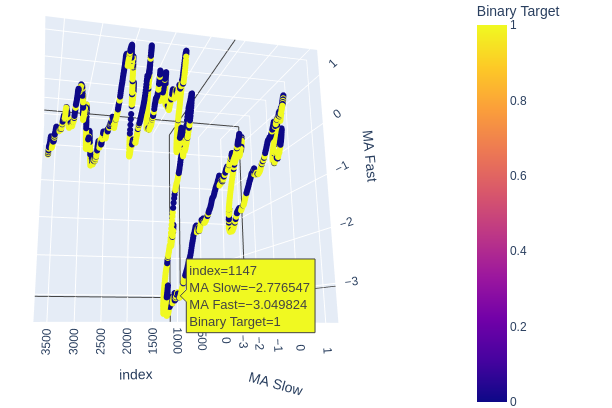
图7 :我们的移动平均线似乎在一定程度上聚集了看涨和看跌的价格走势
让我们看看市场的波动性是否对目标有影响。我们将时间从x轴替换为ATR值,而慢速和快速移动平均线将保持其位置。
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average and the ATR fig = px.scatter_3d( data, x='ATR', y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of ATR, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'ATR', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
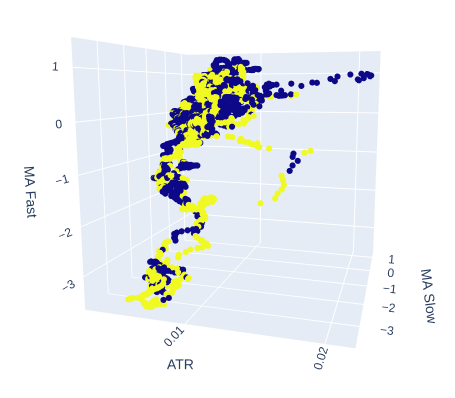
图8 :看来ATR几乎没有增加市场图景的清晰度。我们可能需要稍微转换一下ATR读数,以便使其携带更大的信息量。
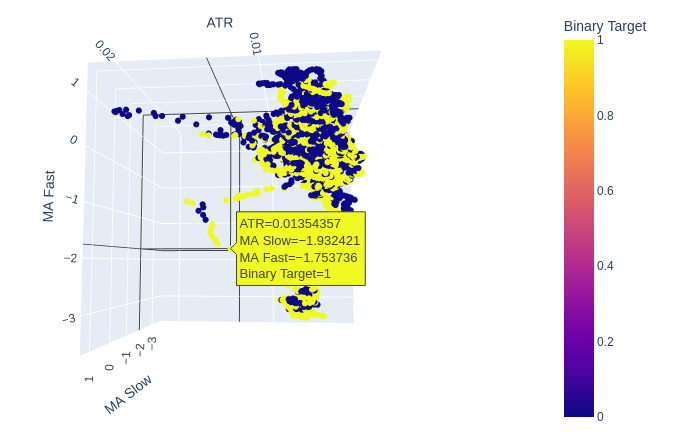
图9 :ATR看上去区分出了看涨和看跌价格走势。然而,这些聚类较小,可能不足以频繁发生,以成为可靠交易策略的一部分。
两个移动平均线和随机振荡器一起给我们的市场数据带来了全新的结构。
# Creating a 3D scatter plot of the slow and fast moving average and the stochastic oscillator fig = px.scatter_3d( data, x='MA Fast', y='MA Slow', z='Stoch Main', color='Binary Target', title="3D Scatter Plot of Time, Close Price, and The Stochastic Oscilator", labels={'x': 'Time', 'y': 'Close Price', 'z': 'Stochastic Oscilator'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
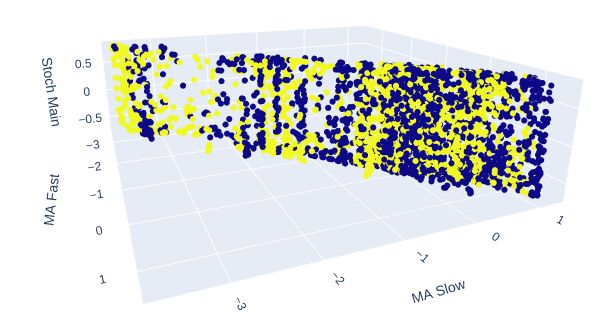
图10 :随机振荡器的主读数和两个移动平均线给出了一些明确定义看涨和看跌的区域。
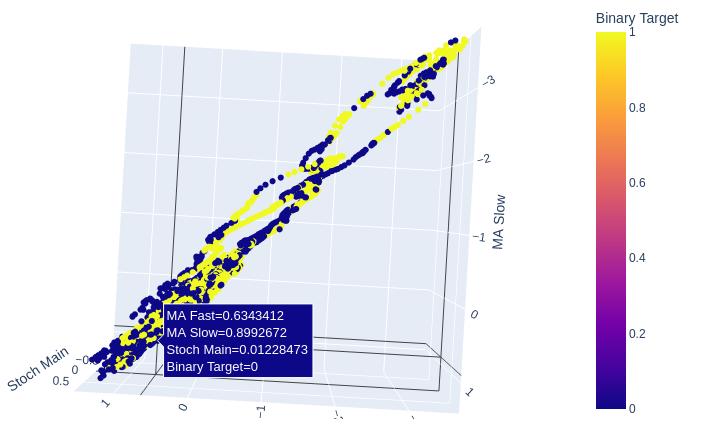
图11 :两个移动平均线和随机振荡器之间的关系可能更适合揭示看涨价格走势,而不是看跌价格走势。
鉴于我们使用了3个技术指标和4个不同的价格报价,数据有7个维度,但我们最多只能可视化3个。我们可以使用降维技术将数据转换为仅两列。主成分分析是解决这类问题的流行选择。我们可以使用该算法将原始数据集中的所有列总结为仅两列。
然后我们将创建两个主成分的散点图,并确定它们如何为我们揭示目标。
# Selecting features to include in PCA features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow']] pca = PCA(n_components=2) pca_components = pca.fit_transform(features.dropna()) # Plotting PCA results # Create a new DataFrame with PCA results and target variable for plotting pca_df = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2']) pca_df['target'] = data['Binary Target'].iloc[:len(pca_components)] # Add target column # Plot PCA results with binary target as hue fig = px.scatter( pca_df, x='PC1', y='PC2', color='target', title="2D PCA Plot of OHLC Data with Target Hue", labels={'PC1': 'Principal Component 1', 'PC2': 'Principal Component 2', 'color': 'Target'} ) # Update layout for custom size fig.update_layout( width=600, # Width of the figure in pixels height=600 # Height of the figure in pixels ) fig.show()
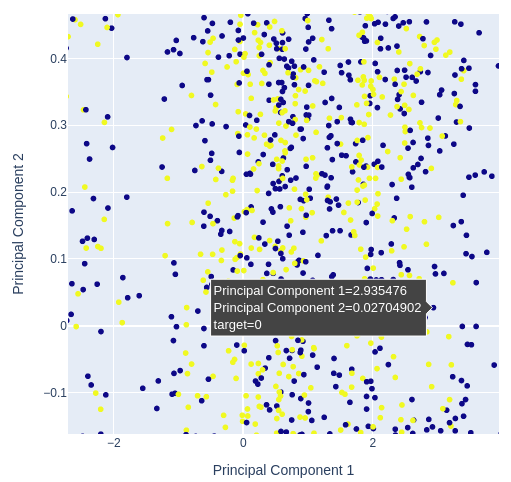
图12 :放大两个主成分散点图的随机部分,看看它们如何分离价格波动。
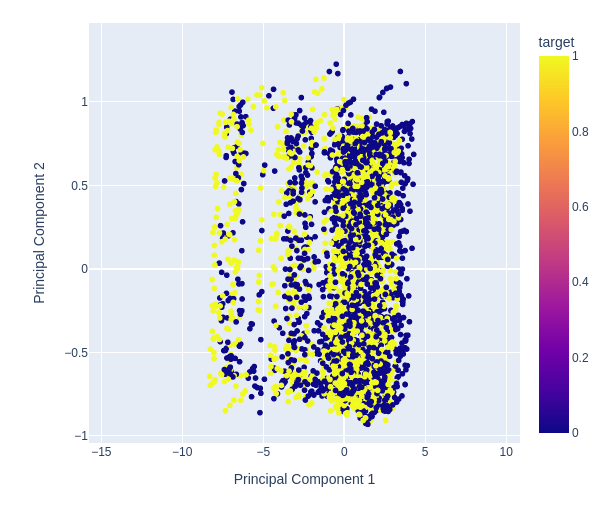
图13 :可视化我们的数据,PCA并没有更好地分离数据集。
像KMeans聚类这样的无监督学习算法可能能够学习到未知数据中的模式。该算法将为其提供的数据创建标签,而无需任何有关目标的信息。
思路是这样的,我们的KMeans聚类算法可以从数据集中学习到两个类型,这将很好地分离我们的两个聚类。不幸的是,KMeans算法并没有真正达到我们的期望。我们观察到在算法生成的数据的两个类别中,都存在看涨和看跌的价格走势。
from sklearn.cluster import KMeans # Select relevant features for clustering features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main','ATR']] target = data['Binary Target'].iloc[:len(features)] # Ensure target matches length of features # Apply K-means clustering with 2 clusters kmeans = KMeans(n_clusters=2) clusters = kmeans.fit_predict(features) # Create a DataFrame for plotting with target and cluster labels plot_data = pd.DataFrame({ 'target': target, 'cluster': clusters }) # Plot with seaborn's catplot to compare the binary target and cluster assignments sns.catplot(x='cluster', hue='target',kind='count', data=plot_data) plt.title("Comparison of K-means Clusters with Binary Target") plt.show()
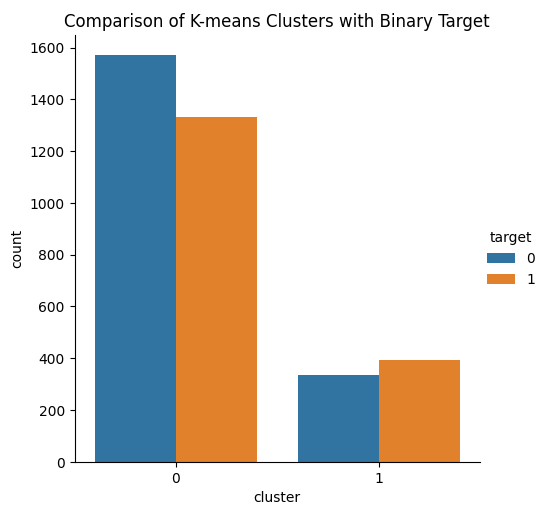
图14 :可视化KMeans算法对市场数据进行学习后的两个聚类
我们还可以通过测量每个输入与目标的相关性来测试变量之间的关系。没有一个输入与目标之间有强相关系数。请注意,这并不代表不存在可用于建模的相关性。
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv") #Add targets data["ATR Target"] = data["ATR"].shift(-look_ahead) data["Target"] = data["Close"].shift(-look_ahead) - data["Close"]
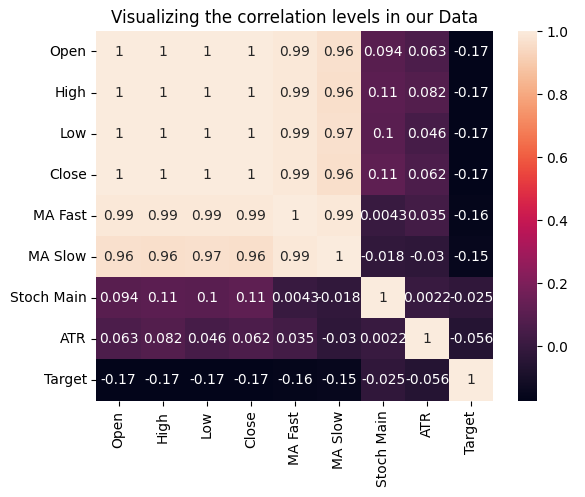
图15 :可视化我们数据集中的相关性水平
现在让我们转换输入数据。我们可以以三种形式使用指标:
- 当前读数。
- 马尔可夫状态。
- 与其过去值的差。
每种形式都有其自身的一些优势和劣势。呈现数据的最佳形式将根据诸如正在建模的指标以及指标所应用的市场等因素而有所不同。由于没有其他方法可以确定理想的选择,我们将对每个指标的所有可能选项进行穷举搜索。
注意我们数据集中的“时间”列。请注意,我们的数据从2010年运行到2021年。这并不与我们将用于回测的时期重叠?
#Let's think of the different ways we can show the indicators to our AI Model #We can describe the indicator by its current reading #We can describe the indicator using markov states #We can describe the change in the indicator's value #Let's see which form helps our AI Model predict the future ATR value data["ATR 1"] = 0 data["ATR 2"] = 0 #Set the states data.loc[data["ATR"] > data["ATR"].shift(look_ahead),"ATR 1"] = 1 data.loc[data["ATR"] < data["ATR"].shift(look_ahead),"ATR 2"] = 1 #Set the change in the ATR data["Change in ATR"] = data["ATR"] - data["ATR"].shift(look_ahead) #We'll do the same for the stochastic data["STO 1"] = 0 data["STO 2"] = 0 data["STO 3"] = 0 #Set the states data.loc[data["Stoch Main"] > 80,"STO 1"] = 1 data.loc[data["Stoch Main"] < 20,"STO 2"] = 1 data.loc[(data["Stoch Main"] >= 20) & (data["Stoch Main"] <= 80) ,"STO 3"] = 1 #Set the change in the stochastic data["Change in STO"] = data["Stoch Main"] - data["Stoch Main"].shift(look_ahead) #Finally the moving averages data["MA 1"] = 0 data["MA 2"] = 0 #Set the states data.loc[data["MA Fast"] > data["MA Slow"],"MA 1"] = 1 data.loc[data["MA Fast"] < data["MA Slow"],"MA 2"] = 1 #Difference in the MA Height data["Change in MA"] = (data["MA Fast"] - data["MA Slow"]) - (data["MA Fast"].shift(look_ahead) - data["MA Slow"].shift(look_ahead)) #Difference in price data["Change in Close"] = data["Close"] - data["Close"].shift(look_ahead) #Clean the data data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) #Drop the last 2 years of test data data = data.iloc[:((-365*2) - 18),:] data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) data
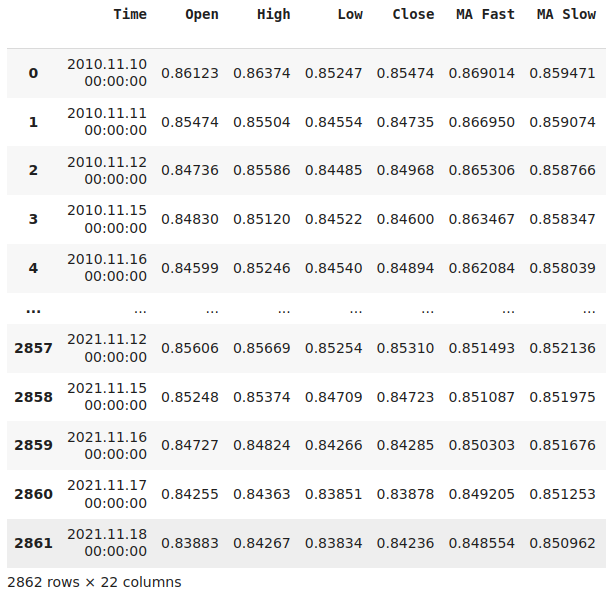
图16 :可视化我们转换后的市场数据
让我们看看哪种呈现形式最有效,以便模型能够根据指标的变化学习价格的变化。我们将使用梯度提升回归树作为模型的选项。
#Let's see which method of presentation is most effective from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
定义时间序列验证的参数。
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)现在让我们设置一个阈值。任何模型,如果宣称仅仅通过使用收盘价来预测价格变化就能效果卓著,那它都不会是一个好的模型。
#Our baseline accuracy forecasting the change in price using current price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Close"]],data.loc[:,"Target"],cv=tscv))
-0.14861941262441164
在大多数问题中,我们总是可以通过使用价格变化,而不是仅仅当前的价格读数,来取得更好的表现。
#Our accuracy forecasting the change in price using current change in price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in Close"]],data.loc[:,"Target"],cv=tscv))
-0.1033528767401429
如果我们取而代之的是将随机振荡器提供给模型,我们的模型表现甚至会更好。
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Stoch Main"]],data.loc[:,"Target"],cv=tscv))
-0.09152071417994265
然而,这真的是我们能做到的最好结果吗?如果我们给模型提供随机振荡器的变化,而不是随机振荡器本身,会发生什么呢?我们预测价格变化的能力会变得更好!
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in STO"]],data.loc[:,"Target"],cv=tscv))
-0.07090156075020868
你觉得如果我们现在采用虚拟编码的方法,会发生什么呢?我们创建了3列,仅仅是为了告诉我们指标处于哪种状态。我们的误差率缩小了。这个结果非常有趣,我们比那些试图根据当前价格或随机振荡器的当前读数来预测价格变化的交易者表现得要好得多。但请记住,我们不知道这是否适用于所有可能的市场。我们只确信这在EURGBP市场的日线时间框架上是成立的。
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"],cv=tscv))
让我们现在评估一下使用两个移动平均线的当前读数预测价格变化的准确性。结果看起来不太好,我们的误差率比仅仅使用收盘价来预测未来价格变化的准确性还要高。这个模型应该被放弃,不适合在生产环境中使用。
#Our accuracy forecasting the change in price using the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA Slow","MA Fast"]],data.loc[:,"Target"],cv=tscv))
如果我们转换我们的数据,以便可以看到移动平均线值的变化,结果会变得更好。然而,我们仍然会比使用一个只取当前收盘价的简单模型表现得更好。
#Our accuracy forecasting the change in price using the change in the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in MA"]],data.loc[:,"Target"],cv=tscv))
然而,如果我们对市场数据应用虚拟编码技术,我们将开始超越在同一市场使用普通日线价格报价的任何交易者。我们的误差率缩小到了前所未见的新低。这种转换是强大的。回想一下,它有助于模型更多地关注指标值的关键变化,而不是学习我们的指标可能取的每个可能值的确切映射。
#Our accuracy forecasting the change in price using the state of moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"],cv=tscv))
对于第一次学习这个主题的读者来说,这一部分特别重要。作为人类,我们倾向于看到模式,即使它们不存在。你到目前为止所读到的内容可能会给你留下这样的印象,即虚拟编码总是你最好的朋友。然而,事实并非如此。观察一下,当我们试图优化最终的人工智能模型,用该模型预测未来的ATR读数时,会发生什么。
不要将你现在将看到的结果与我们刚刚讨论的结果进行比较。目标的单位已经改变。因此,从实际意义上讲,比较我们预测价格变化的准确性和我们预测未来ATR值的准确性是没有意义的。
我们本质上是在创建一个新的阈值。我们使用之前的ATR值预测ATR的准确性是我们的新基准。任何导致误差更大的技术都不是最优的,应该被放弃。
#Our accuracy forecasting the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR"]],data.loc[:,"ATR Target"],cv=tscv))
到目前为止,今天,我们观察到,每当我们将数据的变化传递给模型,而不是当前的数据本身时,我们的误差率就会降低。然而,这一次,我们的误差变得更糟了。
#Our accuracy forecasting the ATR using the change in the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in ATR"]],data.loc[:,"ATR Target"],cv=tscv))
-0.5916640039518372
此外,我们对ATR指标进行了虚拟编码,以表示它是否在上升或下降。误差率仍然不可接受。因此,我们将使用ATR指标的原始形式,而随机振荡器和移动平均线将被虚拟编码。
#Our accuracy forecasting the ATR using the current state of the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR 1","ATR 2"]],data.loc[:,"ATR Target"],cv=tscv))
导出到ONNX
开放神经网络交换(ONNX)是一个开源协议,它为所有机器学习模型定义了一种通用表示形式。这使得我们能够在任何语言中开发和共享模型,只要该语言完全支持ONNX API。ONNX允许我们将刚刚开发的人工智能模型导出,并直接在我们的交易决策中使用这些模型,而不是使用固定的交易规则。
#Load the libraries we need import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
定义每个模型的输入格式。
#Define the input shapes #ATR AI initial_types_atr = [('float_input', FloatTensorType([1, 1]))] #MA AI initial_types_ma = [('float_input', FloatTensorType([1, 2]))] #STO AI initial_types_sto = [('float_input', FloatTensorType([1, 3]))]
在我们有的所有数据上拟合每个模型。
#ATR AI Model atr_ai = GradientBoostingRegressor().fit(data.loc[:,["ATR"]],data.loc[:,"ATR Target"]) #MA AI Model ma_ai = GradientBoostingRegressor().fit(data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"]) #Stochastic AI Model sto_ai = GradientBoostingRegressor().fit(data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"])
保存ONNX模型。
#Save the ONNX models onnx.save(convert_sklearn(atr_ai, initial_types=initial_types_atr),"EURGBP ATR.onnx") onnx.save(convert_sklearn(ma_ai, initial_types=initial_types_ma),"EURGBP MA.onnx") onnx.save(convert_sklearn(sto_ai, initial_types=initial_types_sto),"EURGBP Stoch.onnx")
用MQL5来实现
我们将使用到目前为止开发的相同交易算法。我们只会改变最初给出的固定规则,允许我们的程序在模型给我们一个明确的信号时进行交易。此外,我们将从导入我们开发的ONNX模型开始。
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the AI Modules | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP MA.onnx" as const uchar ma_onnx_buffer[]; #resource "\\Files\\EURGBP ATR.onnx" as const uchar atr_onnx_buffer[]; #resource "\\Files\\EURGBP Stoch.onnx" as const uchar stoch_onnx_buffer[];
现在定义用于存储我们模型预测值的全局变量。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask; long atr_model,ma_model,stoch_model; vectorf atr_forecast = vectorf::Zeros(1),ma_forecast = vectorf::Zeros(1),stoch_forecast = vectorf::Zeros(1);
我们还需要更新反初始化函数。还需要释放被ONNX模型占用的资源。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); OnnxRelease(atr_model); OnnxRelease(ma_model); OnnxRelease(stoch_model); }
从我们的ONNX模型中获取预测并不像训练模型那样耗费资源。然而,为了快速回测我们的交易算法,每tick获取一个人工智能的预测将变得非常耗时。如果我们每5分钟从人工智能模型中获取一次预测,我们的回测会快得多。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- Only on new candles static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_M5,0); if(time_stamp != current_time) { time_stamp = current_time; //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } } }
我们还需要更新负责设置技术指标的函数。该函数将设置我们的人工智能模型,并验证模型是否已正确加载。
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); //--- Create our onnx models atr_model = OnnxCreateFromBuffer(atr_onnx_buffer,ONNX_DEFAULT); ma_model = OnnxCreateFromBuffer(ma_onnx_buffer,ONNX_DEFAULT); stoch_model = OnnxCreateFromBuffer(stoch_onnx_buffer,ONNX_DEFAULT); //--- Validate our models if(atr_model == INVALID_HANDLE || ma_model == INVALID_HANDLE || stoch_model == INVALID_HANDLE) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } //--- Set the sizes of our ONNX models ulong atr_input_shape[] = {1,1}; ulong ma_input_shape[] = {1,2}; ulong sto_input_shape[] = {1,3}; if(!(OnnxSetInputShape(atr_model,0,atr_input_shape)) || !(OnnxSetInputShape(ma_model,0,ma_input_shape)) || !(OnnxSetInputShape(stoch_model,0,sto_input_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } ulong output_shape[] = {1,1}; if(!(OnnxSetOutputShape(atr_model,0,output_shape)) || !(OnnxSetOutputShape(ma_model,0,output_shape)) || !(OnnxSetOutputShape(stoch_model,0,output_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } }
在我们之前的交易算法中,只要指标信号与我们的规则一致,就简单地开仓。现在,我们将改为在我们的人工智能模型给我们一个明确的交易信号时开仓。此外,获利和止损水平将动态设置为预期的波动性水平。希望我们已经创建了一个使用人工智能的过滤器,它将给我们带来更有利可图的交易信号。
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Predict future ATR values vectorf atr_model_input = vectorf::Zeros(1); atr_model_input[0] = (float) atr[0]; //--- Predicting future price using the stochastic oscilator vectorf sto_model_input = vectorf::Zeros(3); if(stochastic[0] > 80) { sto_model_input[0] = 1; sto_model_input[1] = 0; sto_model_input[2] = 0; } else if(stochastic[0] < 20) { sto_model_input[0] = 0; sto_model_input[1] = 1; sto_model_input[2] = 0; } else { sto_model_input[0] = 0; sto_model_input[1] = 0; sto_model_input[2] = 1; } //--- Finally prepare the moving average forecast vectorf ma_inputs = vectorf::Zeros(2); if(fast_ma[0] > slow_ma[0]) { ma_inputs[0] = 1; ma_inputs[1] = 0; } else { ma_inputs[0] = 0; ma_inputs[1] = 1; } OnnxRun(stoch_model,ONNX_DEFAULT,sto_model_input,stoch_forecast); OnnxRun(atr_model,ONNX_DEFAULT,atr_model_input,atr_forecast); OnnxRun(ma_model,ONNX_DEFAULT,ma_inputs,ma_forecast); Comment("ATR Forecast: ",atr_forecast[0],"\nStochastic Forecast: ",stoch_forecast[0],"\nMA Forecast: ",ma_forecast[0]); //--- Can we buy? if((ma_forecast[0] > 0) && (stoch_forecast[0] > 0)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr_forecast[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((ma_forecast[0] < 0) && (stoch_forecast[0] < 0)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr_forecast[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
我们将使用与之前相同的回测时间段,从2022年1月开始,一直到2024年6月。回想一下,当我们训练人工智能模型时,并没有使用回测范围内的任何数据。我们将使用相同的交易品种进行测试,即在相同的日线时间框架上进行EURGBP货币对的交易。
图17 :回测我们的人工智能模型
我们将固定回测的所有其他参数,使测试保持一致性。本质上是试图辨别出由人工智能模型做决策所带来的差异。
图18:我们用于回测的其余参数
我们的交易策略在测试期间更有利可图!这是个好消息,因为模型并没有接触到用于回测的数据。因此,我们可以对使用这个模型进行真实账户交易抱有积极的期望。
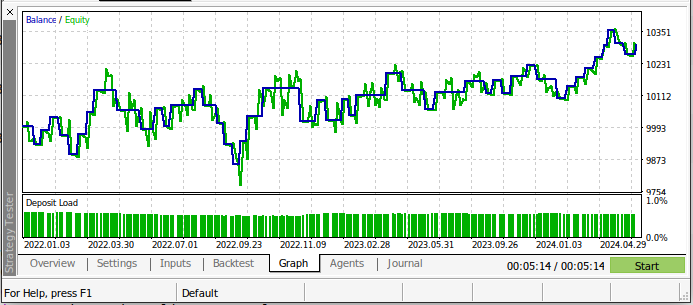
图19 :在测试数据上回测人工智能模型的结果
新模型在回测期间进行了较少的交易,但它比我们旧的交易算法有更高比例的盈利交易。此外,我们的夏普比率现在是正的,只有44%的交易是亏损的。
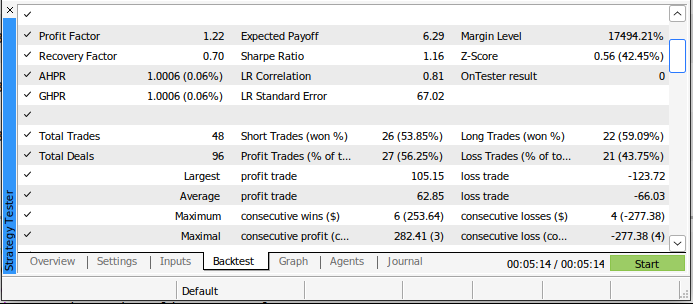
图20 :回测人工智能驱动的交易策略的详细结果
结论
希望在阅读了这篇文章之后,您会同意我的观点,即人工智能确实可以用来改进我们的交易策略。即使是古老的经典交易策略,也可以通过人工智能重新构想,并提升到新的性能水平。看来诀窍在于巧妙地转换指标数据,以帮助模型有效地学习。我们今天展示的虚拟编码技术对我们帮助很大。但我们不能得出结论说,这在所有可能得市场中都是最佳选择。有可能虚拟编码技术是我们对某一组市场所能做出的最佳选择。然而,我们可以自信地得出结论,移动平均线交叉策略确实可以有效地通过人工智能进行改进。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/16280
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

感谢 Gamu。我很喜欢您的出版物,并尝试通过复制您的步骤来学习。
我遇到了一些问题,希望能对其他人有所帮助。
1) 我使用您提供的脚本对 EURGBP_Stochastic 日线进行了测试,结果只产生了 2 个订单,夏普比率为 0.02。我相信我的设置与您相同,但在 2 个经纪商上只产生了 2 个订单。
2)给其他人提个醒,如有必要,您可能需要修改符号设置以匹配您的经纪商(例如,将 EURGBP 改为 EURGBP.i)。
3)接下来,当我尝试导出数据时,我得到的 ATR 数组超出范围,我相信这是因为我的数组中没有 100000 条记录(如果我将其改为 677),我可以相应地得到一个有 677 行的文件。也许你也可以在下载中加入数据提取脚本。
4) 我从您的文章中复制了代码,并在 Python 中进行了尝试,但得到的错误信息是 look_ahead 未定义 ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: name 'look_ahead' is not defined
5) 当我加载您的 Juypiter 笔记本时,我发现它需要设置前瞻 #让我们预测未来的 20 步
look_ahead = 20 ,之后我只使用了你的附带文件,但却出现了以下错误,可能与只有 677 行有关。
在开始可视化之前,我运行了 #Scale 数据
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
结果出现了一个错误,我不知道如何解决
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning:试图在 DataFrame 的片段副本上设置值。请尝试使用 .loc[row_indexer,col_indexer] = value 代替它。 请参阅文档中的注意事项:https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
感谢 Gamu。我很喜欢您的出版物,并试着模仿您的步骤来学习。
我遇到了一些问题,希望这能帮助其他人。
1) 我使用您提供的脚本对 EURGBP_Stochastic 日线进行了测试,结果只产生了 2 个订单,夏普比率为 0.02。我相信我的设置与您相同,但在 2 个经纪商上只产生了 2 个订单。
2)作为对其他人的提醒,如有必要,您可能需要修改符号设置以匹配您的经纪商(例如,将 EURGBP 改为 EURGBP.i)。
3)接下来,当我尝试导出数据时,我得到的 ATR 数组超出范围,我相信这是因为我的数组中没有 100000 条记录(如果我将其改为 677),我可以相应地得到一个有 677 行的文件。也许您也可以在下载中加入数据提取脚本。
4)我从您的文章中复制了代码,并在 Python 中进行了尝试,但得到的错误信息是 look_ahead 未定义 ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: name 'look_ahead' is not defined
5) 当我加载您的 Juypiter 笔记本时,我发现它需要设置展望 #让我们预测未来 20 步的情况
look_ahead = 20 , 之后我只使用了你的附带文件,但却出现了以下错误,可能与只有 677 行有关。
在开始可视化之前,我运行了 #Scale 数据
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
这给了我一个错误,我不知道如何解决
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning:试图在 DataFrame 的片段副本上设置值。请尝试使用 .loc[row_indexer,col_indexer] = value 代替它。 请参阅文档中的注意事项:https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
你好,尼尔,我相信你很好。
感谢 Gamu,是的,我知道有很多活动部件,我会看看这是否能解决我的问题。
谢谢 Gamu 感谢您的建议,是的,我知道有很多活动部件,我会看看这是否能解决我的问题。