
機械学習の限界を克服する(第5回):時系列交差検証の簡単な概要

これまでの関連連載では、市場の振る舞いによって生じる問題に対処するためのさまざまな戦術を取り上げてきました。しかし本連載では、戦略に適用しようとする機械学習アルゴリズムそのものに起因する問題に焦点を当てます。こうした問題の多くは、モデルのアーキテクチャ、モデル選択に用いるアルゴリズム、性能評価のために定義する損失関数、そしてそれらと同種の要素から生じます。
機械学習モデルを構成するあらゆる要素は、アルゴリズム取引に機械学習を適用しようとする過程において、意図せず障害を生み出す可能性があります。そのため、私たち一人ひとりがこれらの制約を理解し、コミュニティとして新たな解決策を構築し、新しい基準を定義していくことが重要です。
アルゴリズム取引で用いられる機械学習モデルは、検証やテストの方法に起因する特有の課題に直面します。その中でも重要なステップの一つが、時系列交差検証です。これは、時間順に並んだ未観測データに対してモデルの性能を評価する手法です。
通常の交差検証とは異なり、時系列データはシャッフルできません。シャッフルをおこなうと、未来の情報が過去に漏れてしまうためです。この制約により、時系列データにおけるリサンプリングはより複雑になり、バイアス、分散、ロバスト性の間に特有のトレードオフが生じます。
本記事では、時系列データにおける交差検証を紹介し、それが過学習を防ぐ上で果たす役割を解説します。また、限られたデータしかない状況においても、信頼性の高いモデルを学習させる方法を示します。2年間の小規模なデータセットを用い、適切な交差検証をおこなうことで、単純な線形モデルと比較してディープニューラルネットワークの性能がどのように改善されたかを実例として示します。
本記事の目的は、一般的に用いられている時系列交差検証手法の価値と限界の両方を明らかにし、次回以降でおこなう、より深い議論への基盤を築くことにあります。
MQL5 におけるデータ取得
ここでは、手動で作成したMQL5スクリプトを使い、MetaTrader 5ターミナルから履歴データを取得する流れを説明します。スクリプトはまず、書き出し先となるファイル名を変数として保持するところから始めます。
次に、取得するデータ量をユーザーが指定できるよう、入力パラメータとしてバー数を定義します。この値を実行時に変更できるようにするため、スクリプトヘッダには「#property script_show_inputs」を設定しておく必要があります。
必要な設定が揃ったら、ファイルへの書き込み処理を開始します。FileOpen関数を使用してファイルハンドラを作成します。この関数では、ファイルの種類、操作モード、そして区切り文字の指定をおこないます。
そのため、スクリプト冒頭で定義したファイル名に加え、適切なファイル操作フラグとファイルタイプ、区切り文字としてカンマを指定してFileOpenを呼び出します。
続いて、取得するバー数から過去に向かって処理するforループを用意します。最初のループでは、CSVファイルに出力するカラム名を書き込みます。それ以降のループでは、各時点のマーケットデータを取得し、過去から現在へ向かって時系列順に書き出していきます。
このように処理することで、CSVファイルは先頭に最も古いデータが配置され、末尾に最新のデータが並ぶ構成になります。
//+------------------------------------------------------------------+ //| Fetch_Data | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- File name string file_name = Symbol() + " Detailed Market Data As Series.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size; //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Pythonによるデータ分析
CSVファイルの書き出しが完了したら、次のステップとしてデータ分析を開始します。まずはPandas、NumPy、Matplotlibといった基本的なPythonライブラリを読み込みます。
#Import basic libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt
MQL5スクリプトで作成したデータを読み込む際は、以下の例のように、CSVファイルのパスを自身の環境に合わせて指定してください。
#Read in the data data = pd.read_csv("/ENTER/YOUR/PATH/HERE/EURUSD Detailed Market Data As Series.csv")
この例では、限られたデータセットであっても交差検証を用いることで複雑なモデルを適合できることを示したいため、直近2年分のデータのみを使用し、それ以前のデータはすべて除外します。
data = data.iloc[(365*2):,:] data.reset_index(drop=True,inplace=True)
次に、どれくらい先の未来を予測するかを定義します。
#Define a forecast horizon HORIZON = 1
続いて、モデルに入力する特徴量を準備します。ここでは差分系列を使用します。これは現在の値から過去の値を引くことで作成します。また、予測対象となるラベルも同時にデータセットへ追加します。その後、欠損値をすべて削除します。
#Let us start by following classical rules data['True Close Diff'] = data['True Close'] - data['True Close'].shift(HORIZON) data['True Open Diff'] = data['True Open'] - data['True Open'].shift(HORIZON) data['True High Diff'] = data['True High'] - data['True High'].shift(HORIZON) data['True Low Diff'] = data['True Low'] - data['True Low'].shift(HORIZON) #Add the target data['Target'] = data['True Close'] - data['True Close'].shift(-HORIZON) data.dropna(inplace=True) data.reset_index(inplace=True,drop=True)
データを可視化してみましょう。
#Let's visualize the data
plt.plot(data['True Close'],color='black')
plt.grid()
plt.title('EURUSD Data From 2023 - 2024')
plt.xlabel('Time')
plt.ylabel('EURUSD Exchange Rate') 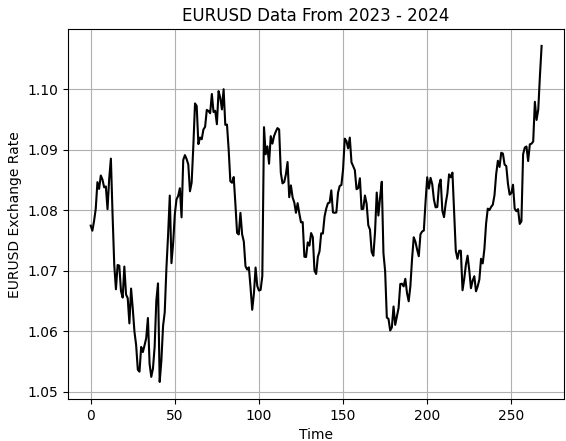
図1:2023年〜2024年におけるEURUSD履歴データの可視化
次に、データセットを2つに分割します。前半を学習用データ、後半をテスト用データとして使用します。
#Partition the data train , test = data.iloc[:data.shape[0]//2,:] , data.iloc[data.shape[0]//2:,:]
その後、入力データとターゲットをそれぞれ分離します。
#Differenced inputs X = train.iloc[:,5:-4].columns y = 'Target'
続いて、機械学習モデルと評価指標を読み込み、モデルの性能を評価できるようにします。
#Load a machine learning library from sklearn.neural_network import MLPRegressor from sklearn.linear_model import LinearRegression,Ridge from sklearn.metrics import root_mean_squared_error
記事冒頭で述べたとおり、まずはベースライン(コントロール)として線形モデルを定義します。
#Start the model model = Ridge(alpha=1e-7)
モデルを適合させます。
model.fit(train.loc[:,X],train.loc[:,y])
最後に、テストデータに対して予測をおこない、その結果を保存します。このとき、テストデータを用いてモデルを再学習させないことが重要です。これは、後ほどMetaTrader 5上でバックテストをおこない、モデルを正しく評価するためです。
test['Predictions'] = model.predict(test.loc[:,X])
次に、モデルの妥当性を定性的に評価します。アウトオブサンプルデータに対する予測結果と、実際に観測された価格水準をプロットして比較します。可視化の結果を見ると、モデルは将来の価格挙動をある程度は捉えており、予測値も実際のターゲットの推移と概ね整合しています。一方で、価格変動の細かな揺らぎについては、十分に捉えきれていない場面も確認できます。
plt.plot(test.loc[:,'Target'],color='black') plt.plot(test.loc[:,'Predictions'],color='red',linestyle=':') plt.legend(['Target','Predictions']) plt.title('Visualizing Model Accuracy Out of Sample') plt.xlabel('Time') plt.ylabel('EURUSD Exchange Rate') plt.grid()
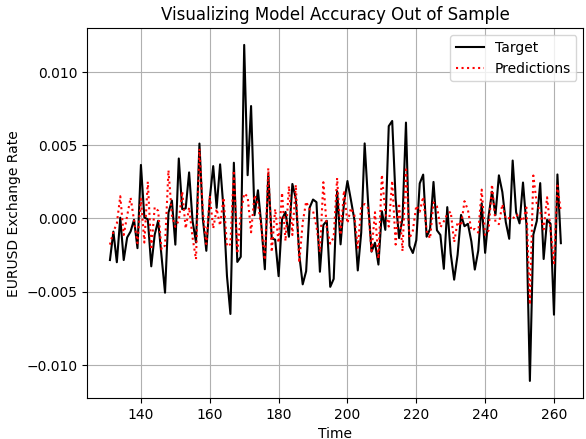
図2:シンプルな線形モデルによるアウトオブサンプル精度の可視化
さらに、モデルの予測値と実際のターゲットとの相関を確認すると、その水準はあまり高くありません。本モデルが生成した相関係数は0.58であり、性能としてはやや不十分であることが分かります。
test.loc[:,['Target','Predictions']].corr().iloc[0,1]
0.5826364163824712
ONNXへの変換
ONNX (Open Neural Network Exchange) は、異なるフレームワーク間で機械学習モデルを構築および展開できるオープンソースのプロトコルです。これは言語非依存であり、ONNX APIをサポートする言語でモデルを学習し、同じくONNXをサポートする別の言語へエクスポートして展開することができます。これにより、同一のモデルを複数のシステムで使用することが可能になります。
これらの利点は、ONNX APIが広く採用されていることによって実現されています。そのため、まずONNXライブラリと、scikit-learnモデルをONNX表現に変換するための変換ライブラリをインポートします。ONNX表現とは、モデルを記述する数学的な計算グラフのことです。このグラフは、元の実装へ容易に変換することができます。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
ONNXライブラリをインポートした後、モデルが受け取る入力と返す出力の形状を定義します。
initial_types = [("FLOAT INPUT",FloatTensorType([1,4]))] final_types = [("FLOAT OUTPUT",FloatTensorType([1,1]))]
次に、学習済みの各モデルをONNXプロトタイプへ変換します。
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) model2_proto = convert_sklearn(model2,initial_types=initial_types,target_opset=12)
続いて、ONNXのsaveメソッドを使用して、これらのプロトタイプを.onnxファイルとして保存します。
onnx.save(model_proto,"EURUSD LR D1 DIFFERENCED.onnx") onnx.save(model2_proto,"EURUSD LR 2 D1 RAW.onnx")
ベンチマーク性能レベルの定義
まず、先ほど作成したONNXバッファを読み込みます。
//-- Load the onnx buffer #resource "\\Files\\EURUSD LR D1 DIFFERENCED.onnx" as const uchar onnx_buffer[];
次に、予測結果の保存やモデルハンドラなど、ONNXモデルに関連するグローバル変数を定義します。
//--- Global variables long onnx_model; vector onnx_inputs,onnx_output;
その後、ポジション管理やリスク管理をおこなうためにTradeライブラリを読み込みます。
//--- Libraries #include <Trade\Trade.mqh> CTrade Trade;
モデルが初めて初期化される際に、OnnxCreateFromBuffer()メソッドを使って準備をおこないます。このメソッドは次の2つのパラメータを受け取ります。
- ファイルから作成したONNXバッファ
-
初期化引数(ここでは、ONNXのデータ型をfloatとして指定します。float型の入力および出力は安定しており、ONNXで広く使用されています。)
その後、Python側で定義したものと一致するように、モデルの入力および出力の形状を設定します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the ONNX model onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Set the input shape of the model ulong model_input[] = {1,4}; OnnxSetInputShape(onnx_model,0,model_input); ulong model_output[] = {1,1}; OnnxSetOutputShape(onnx_model,0,model_output); //--- return(INIT_SUCCEEDED); }
アプリケーション終了時には、ONNXモデルに割り当てられたリソースを解放します。これはMQL5における良い実装慣習です。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up dedicated ONNX resources OnnxRelease(onnx_model); }
新しい価格を受信するたびに、まずポジションが存在しないかを確認します。ポジションが存在しない場合、ONNXモデルから予測を取得し、どのポジションを取るかを判断します。
そのために、入力ベクトルを期待される形状、ここではサイズ4にリサイズします。各入力値は処理されたうえでfloat型にキャストされます。また、BidやAskなどの市場データも取得します。paddingという変数は、ストップロスの幅を決定します。
次に、モデルの予測結果を格納するためのベクトルを用意します。これは長さ1である必要があります。その後、OnnxRun()を使用して予測を取得し、ターミナルに出力したうえで、実際の市場価格と比較し、売買シグナルを生成します。
これは、機械学習モデルを取引システムで使用する際の典型的な方法です。すでにポジションが開かれている場合は、ストップロスまたはテイクプロフィットに到達するまで待機します。これにより、モデルの精度と一貫性を評価できます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check if we have no open positions if(PositionsTotal() ==0) { //--- Prepare the model inputs onnx_inputs.Resize(4); onnx_inputs[0] = (float) iClose(Symbol(),PERIOD_D1,0) - iClose(Symbol(),PERIOD_D1,1); onnx_inputs[1] = (float) iOpen(Symbol(),PERIOD_D1,0) - iOpen(Symbol(),PERIOD_D1,1); onnx_inputs[2] = (float) iHigh(Symbol(),PERIOD_D1,0) - iHigh(Symbol(),PERIOD_D1,1); onnx_inputs[3] = (float) iLow(Symbol(),PERIOD_D1,0) - iLow(Symbol(),PERIOD_D1,1); //--- Market data double ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); double bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); double padding = 5e-3; //--- Store the model's prediction onnx_output.Resize(1); if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_inputs,onnx_output)) { Print("Model forecast: ",onnx_output[0]); //--- Buy setup if(onnx_output[0] > iClose(Symbol(),PERIOD_D1,0)) Trade.Buy(0.01,Symbol(),ask,ask-padding,ask+padding,""); //--- Sell setup else if(onnx_output[0] < iClose(Symbol(),PERIOD_D1,0)) Trade.Sell(0.01,Symbol(),bid,bid+padding,bid-padding,""); } } //--- Otherwise, if we do have open positions else if(PositionsTotal()>0) { //--- Then Print("Position Open"); } } //+------------------------------------------------------------------+
通常どおり、まずバックテストに使用する期間を明示します。Pythonではデータセットを半分に分割し、テストセットに対してモデルを学習させていなかったことを思い出してください。これらと同じ期間をMetaTrader 5での検証に使用します。これにより、ディープニューラルネットワークで上回ることを目指すための健全なベンチマークが得られます。

図3:コントロールバックテストに必要な期間の選択
また、実運用に近い条件を再現するため、ランダム遅延設定を選択します。
図4:想定される展開条件を再現するバックテスト条件の選択
取引戦略によって生成されたエクイティカーブを分析すると、バックテスト期間の前半では立ち上がりが遅かったものの、最終的には利益を上げていることが分かります。
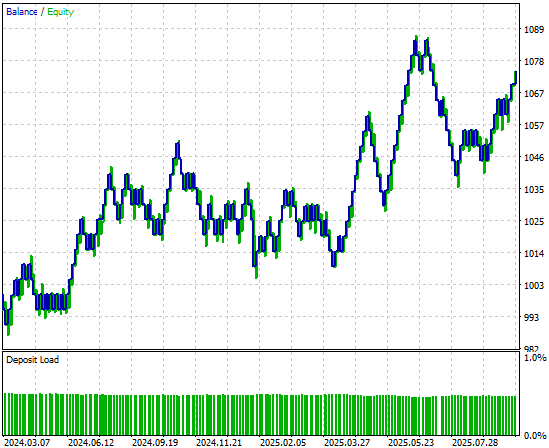
図5:シンプルな線形モデルによって生成されたエクイティカーブは有望だが、さらなる性能向上の余地がある
詳細な性能統計を見ると、まだ改善の余地があることが分かります。たとえば、ショートエントリーの成績は特に悪く、精度は約50%と、ほぼランダムに近い水準です。 一方で、ロングエントリーについては、モデルが比較的うまく機能していることも確認できます。
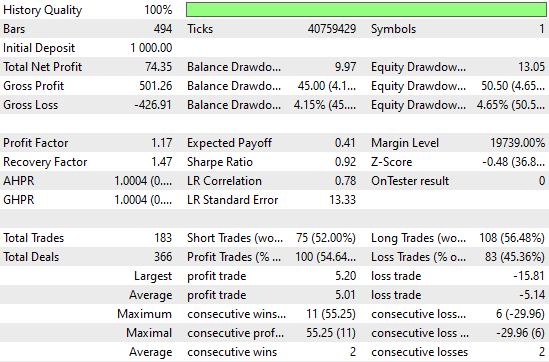
図6:アウトオブサンプルデータに対してシンプルなRidgeモデルを評価した際に得られた詳細統計の可視化
初期結果の改善
次に、これらの初期結果を改善していきます。まず、scikit-learnライブラリから適切なリサンプリング手法であるRandomizedSearchCVとTimeSeriesSplitをインポートします。これら2つは、時系列データのリサンプリングにおいて併用可能です。
from sklearn.model_selection import RandomizedSearchCV,TimeSeriesSplit
次に、5分割のTimeSeriesSplitオブジェクトを作成し、各分割間のギャップを予測ホライズンと同じ値に設定します。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) その後、交差検証のすべての反復処理で共通となる基本設定を持つニューラルネットワークを作成します。
nn = MLPRegressor(random_state=0,shuffle=False,early_stopping=False,max_iter=1000)
次に、ディープニューラルネットワーク用のパラメータ辞書を作成します。これらの各パラメータは試行および比較され、最適なモデルを特定するために使用されます。
distributions = dict(activation=['identity','logistic','tanh','relu'], alpha=[100,10,1,1e-1,1e-2,1e-3,1e-4,1e-5,1e-6,1e-7], hidden_layer_sizes=[(4,40,20,10,2),(4,100,200,500,100,4),(4,20,40,20,4,2),(4,10,50,10,4),(4,4,4,4)], solver=['adam','sgd','lbfgs'], learning_rate = ['constant','invscaling','adaptive'] )
続いて、ランダムサーチ手法を使用します。この手法は、すべてのパラメータ組み合わせの中から制御された回数の反復を実行します。入力空間全体を網羅的に探索するのではなく、n_iterパラメータを調整することで探索の厳密さを制御できます。
rscv = RandomizedSearchCV(nn,distributions,random_state=0,n_iter=50,n_jobs=-1,scoring='neg_mean_squared_error',cv=tscv)
交差検証を実行するには、先ほど作成したRandomizedSearchCVオブジェクトに対してfit()メソッドを呼び出し、結果をニューラルネットワーク探索手順に対応する変数へ格納します。
nn_search = rscv.fit(train.loc[:,X],train.loc[:,y])
探索が完了したら、交差検証によって得られた最適なパラメータを取得します。
nn_search.best_params_
{'solver': 'lbfgs',
'learning_rate': 'adaptive',
'hidden_layer_sizes':(4, 40, 20, 10, 2),
'alpha':0.0001,
'activation': 'identity'}
次に、これらのパラメータを使用して新しいモデルを初期化し、学習データに対して適合させます。
model = MLPRegressor(random_state=0,shuffle=False,early_stopping=False,max_iter=1000,solver='lbfgs',learning_rate='adaptive',hidden_layer_sizes=(4, 40, 20, 10, 2),alpha=0.0001,activation='identity') model.fit(train.loc[:,X],train.loc[:,y])
最後に、モデルをONNXプロトタイプへ変換します。
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
最後に、ニューラルネットワークのONNXファイルをドライブに保存し、おこなった改善をテストできるようにします。
onnx.save(model_proto,'EURUSD NN D1.onnx')
改善内容の実装
以前のアプリケーションの大部分はそのまま使用できるため、ここでは改善されたモデルを反映するために更新が必要な数行のコードにのみ注目します。変更が必要なのはヘッダファイル内のリソースパスのみで、先ほど作成した新しいニューラルネットワークモデルを指すように更新する必要があります。
//-- Load the onnx buffer #resource "\\Files\\EURUSD NN D1.onnx" as const uchar onnx_buffer[];
これが完了したら、同じバックテスト期間を使って新しいアプリケーションのパフォーマンスを確認できます。公平な比較をおこなうため、以前と同じ日付を選択します。
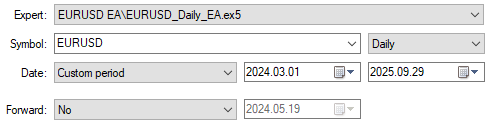
図7:同一のテスト期間で取引をおこなう新しく改善されたディープニューラルネットワークアプリケーションの選択
詳細な性能統計を分析すると、すでに顕著な変化が確認できます。総純利益は大きく増加しており、それに伴ってシステムが生成する取引シグナルの数も増えています。これは、ニューラルネットワークが以前のバージョンよりも多くの取引をおこないながら、同程度の精度を維持したまま収益性を向上させたことを意味します。これらは非常に印象的な改善点です。
図8:確立したコントロールベンチマークと比較して大幅に改善された性能水準
最後に、新しいバージョンのアプリケーションによって生成されたエクイティカーブを見ると、初期のバックテストで成長を停滞させていた保ち合い期間が、ニューラルネットワークによって生み出された力強く急激な上昇トレンドに置き換わっていることが明確に分かります。これにより、今後に向けてより信頼性が高く堅牢な売買シグナルの源が得られます。
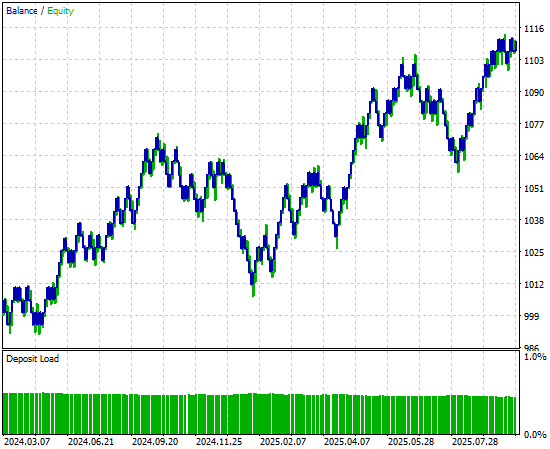
図9:時系列交差検証によって改善された戦略が生成するエクイティカーブの可視化
結論
本記事では、時系列交差検証手法を適切に適用した場合に得られる強みについて概説しました。読者は、時系列交差検証が、過学習のリスクを軽減すること、より良いモデルパラメータの調整および探索をおこなうこと、複数の候補モデルの中から最適な手法を選定すること、そして、まだ観測していないデータに対するモデルのテスト誤差を推定することに有効である、という点を理解できたはずです。
本記事を通じて繰り返し述べてきたとおり、これらのユースケースは決して網羅的なものではありません。時系列交差検証がモデリングパイプラインにもたらす利点をすべて取り上げることは不可能です。
しかし、ここまで議論を進めてきた今、読者はより深い問いを立てる準備が整っているはずです。本記事で示した性能水準は、ここで紹介したシンプルなK-Fold手法よりも、さらに厳密な時系列交差検証を用いることで改善できるのでしょうか。こうした問いは、今後さらに探究する価値が十分にあります。
次回以降の議論では、ウォークフォワード時系列交差検証などの代替的な交差検証手法を取り上げ、K-Foldアプローチと比較していきます。この比較を通じて、なぜある手法が別の手法よりも適している場合があるのかを考察します。そして、それがどのような状況で当てはまるのかを理解するためには、まず、良い交差検証が私たちにもたらすものを明確に把握しておく必要があります。
| ファイル名 | ファイルの説明 |
|---|---|
| Fetch_Data.mq5 | MetaTrader 5ターミナルから履歴データを取得するためのカスタムMQL5スクリプト |
| The_Limitations_of_AI_Model_Selection.ipynb | MetaTrader 5ターミナルから取得した市場データを分析するためのJupyter Notebook |
| EURUSD_LR_D1_DIFFERENCED.onnx | ベンチマークモデルとして作成した線形回帰ONNXモデル。 |
| EURUSD_NN_D1.onnx | ベンチマークを上回るために作成したディープニューラル ネットワークONNXモデル |
| EURUSD_Daily_EA.mq5 | 時系列交差検証を使用して最適化したディープニューラル ネットワーク強化取引アプリケーション |
| EURUSD_Daily_EA_3.mq5 | データセットが限られている中で、上回ろうと意図したベンチマークトレーディングアプリケーション |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/19775
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索