
機械学習の限界を克服する(第6回):効果的なメモリクロスバリデーション

前回のクロスバリデーションに関する記事では、古典的な手法の概要と、それが時系列データに対してどのように使われ、モデルの最適化や過学習の抑制に役立っているかを説明しました。参考として、その記事へのリンクを掲載しています。また、従来の解釈以上のパフォーマンスが得られる可能性があることにも触れました。本記事では、そうした従来手法の見落とされがちなポイントを掘り下げ、ドメイン特化型の検証によってどのように改善できるのかを見ていきます。
話を分かりやすくするために、ひとつの思考実験をしてみましょう。仮に、あなたが400年後の未来へタイムトラベルできたとします。到着すると、部屋の中にあなたが不在だった期間の毎日分の新聞が山のように積まれています。数世紀分の世界の出来事が詰まった新聞の山です。その横には、起動したままのMetaTrader 5ターミナルがあります。取引を始める前に、あなたはまずこの新聞から世界の状況を学ばなければなりません。
さて、あなたならどの順番で新聞を読みますか。すべてを最初から読む必要があるでしょうか。それとも、直近の情報だけを把握すれば、十分にうまく取引できるでしょうか。どこまで過去に遡れば、その情報はすでに価格に織り込まれており、もはや役に立たなくなるのでしょうか。
これらは、まさにクロスバリデーションによって答えるべき問いです。しかし、従来のクロスバリデーションは、「過去の情報はすべて等しく重要である」という前提のもとで設計されています。私たちは、この前提が本当に正しいのかを検証する、新しい形のクロスバリデーションを提案したいと考えています。
MetaTrader 5を使った検証結果に入る前に、まずはこの問題を整理し、なぜこのアプローチが必要なのかを直感的に理解してもらいましょう。一般的に考えても、部屋にある一番古い新聞から順に読み始めるのは、あまり効率的とは言えません。
図1:市場を記述するすべての過去データを常に使用することが最善なのか
賢明なトレーダーであれば、最新の情報から読み始め、必要に応じて過去へ遡るでしょう。金融市場では、古い情報ほど急速に重要性を失うからです。ここには、金融に特有の微妙な真実があります。それは「情報は減衰する」という事実です。
図2:金融市場では、より新しい情報に高い重みが置かれていると仮定した方が良いのか
自然科学の分野では、情報は減衰しません。ニュートンの重力に関するメモは、数世紀を経た今でも同じ結果を導きます。しかし金融市場では、1950年代に有効だった戦略が、現代では通用しないことが珍しくありません。市場環境は変化し、かつて価値のあった情報は、やがて「価格に織り込まれる」か、あるいは陳腐化します。
ここで重要な問いが生まれます。統計モデルの予測性能は、より多くの過去データを使うことで、常に向上するのでしょうか。私たちの分析結果は、その逆を示唆しています。遠い過去のデータを過剰に与えることで、モデルの精度はむしろ低下する可能性があります。思考実験と同様に、これまでに発行されたすべての新聞を読む必要はなく、現在にとって意味のあるものだけで十分なのです。
熟練した人間のトレーダーは、取引対象となる市場ごとに、最初に記録されたローソク足から分析を始めることはありません。しかし機械学習では、「多ければ多いほど良い」という前提のもと、モデルにそれを強いています。本記事は、この前提に疑問を投げかけ、金融市場に「有効な記憶」、すなわち、それ以上遡っても意味を持たない限界が存在するのかを検証します。
本研究の目的は、学習に用いる過去データ量とアウトオブサンプルでの性能との関係を明らかにすることです。特に、より小さく、より直近のデータサブセットが、全データを用いたモデルと同等、あるいはそれ以上の性能を発揮できるかに注目しました。検証のため、約8年分の市場データを用い、それを半分に分割しました。学習データは10%、20%、30%というように段階的に拡張し、古いデータを順次追加していきました。それぞれのデータ分割に対して1つのモデルを構築し、約4年分の固定されたテストデータに対する誤差を測定しました。
結果は明確でした。アウトオブサンプル誤差が最小となったのは、学習データの100%ではなく、80%のみを使用したモデルでした。それ以上古いデータを追加すると、精度はかえって悪化しました。これは、古い観測値が現在の市場実態を反映していない場合、モデルは「少ないデータからの方が、より良く学習できる」ことを示しています。
モデルの学習に使用するデータ量は、モデル構築に伴うコストの代理変数と考えられます。一般に、使用するデータが多いほど、モデル取得や運用のコストは高くなります。したがって、本研究の知見は、あらゆるレベルの実務家にとって重要な示唆を持ちます。これらを理解することで、計算コストやクラウドインフラ費用を削減し、開発サイクルを短縮し、モデル全体の効率を高めることが可能になります。
Pythonによる分析の開始
ここからは、MetaTrader 5からエクスポートしたデータを用い、私たちが通常使用している標準的なPythonライブラリを使って分析を進めていきます。
#Import the standard python libraries import numpy as np import pandas as pd import seaborn as sns import MetaTrader5 as mt5 import matplotlib.pyplot as plt
それでは、MetaTrader 5ターミナルにログインしましょう。
#Log in to our MT5 Terminal if(mt5.initialize()): #User feedback print("Logged In") else: print("Failed To Log In")
ログインしました。
銘柄の履歴データを取得する前に、まず気配値表示から銘柄を選択する必要があります。
#Fetch Data on the EURUSD Symbol #First select the EURUSD symbol from the Market Watch if(mt5.symbol_select("EURUSD")): #Found the symbol print("Found the EURUSD Symbol")
EURUSDを発見しました。
これでブローカーからクオートを取得できます。
#Fetch the historical EURUSD data we need data = pd.DataFrame(mt5.copy_rates_from_pos("EURUSD",mt5.TIMEFRAME_D1,0,3000)) data
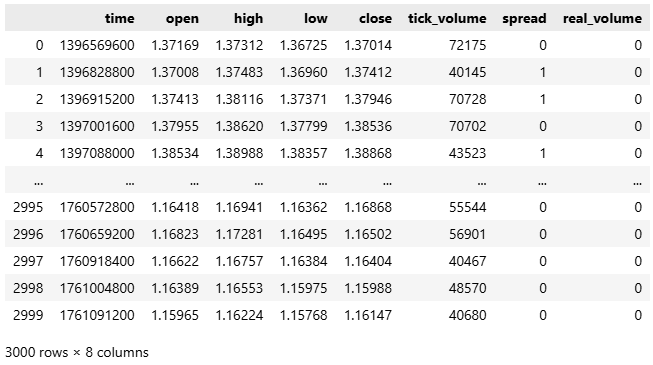
図1:過去のEURUSD市場データの分析を始める
ほとんどのブローカーはLinuxサーバーを実行しているため、慣例によりデータはUNIX時間で届きます。したがって、時間を秒数から、人間が読める年月日形式に変換します。
#Convert the time from seconds to human readable data['time'] = pd.to_datetime(data['time'],unit='s') #Make sure the correct changes were made data
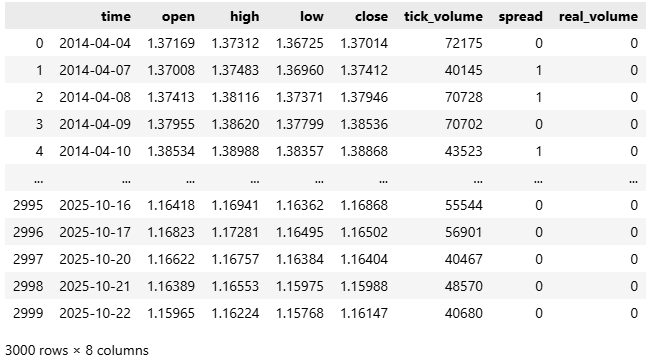
図2:時間の単位を秒から人間が読める形式に変換する
ここで、始値、高値、安値、終値フィードを表す4つの列に注目しましょう。
#Select the OHLC columns data = data.iloc[:,:-3] data
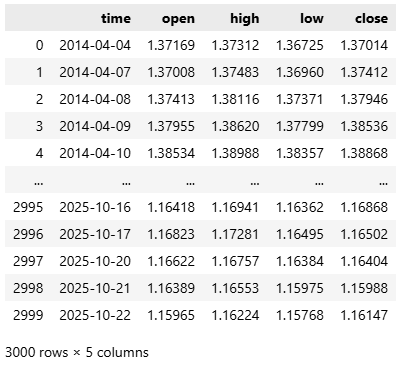
図3:データセットを縮小して、分析を4つの主要な価格レベルに集中できるようにする
次に、未来への一歩を予測する、古典的な時系列予測モデルの構築を始めます。
#Define the classical horizon HORIZON = 1
この設定に従って、データにラベルを付けます。
#Label the data data['Target'] = data['True Close'].shift(HORIZON)
モデルを適合させる際、scikit-learnでは欠損値がエラーの原因となるため、まず欠損行をすべて削除します。
#Drop missing rows data.dropna(inplace=True)
次に、必要な機械学習ライブラリをインポートします。
#Import cross validation tools from sklearn.linear_model import Ridge,LinearRegression from sklearn.metrics import root_mean_squared_error from sklearn.neural_network import MLPRegressor
続いて、データセットを2つの等しい部分に分割します。一方を学習用、もう一方をテスト用とします。
#The big picture of what we want to test train , test = data.iloc[:data.shape[0]//2,:] , data.iloc[data.shape[0]//2:,:]
その後、入力特徴量と出力ターゲットを分離します。
#Define inputs and target X = data.columns[1:-1] y = data.columns[-1]
ワークフローをモジュール化するために、get_model()という関数を定義します。この関数はRandomForestRegressorを返します。ランダムフォレストは、単純なモデルでは捉えきれない複雑かつ非線形な変数間の相互作用を学習できる、非常に強力な推定器です。
#Fetch a new copy of the model def get_model(): return(RandomForestRegressor(random_state=0,n_jobs=-1))
モデルを定義した後、プログラムの主要部分に進みます。ここでは、モデルの性能指標を記録するためのリストを作成し、実行したい反復回数を指定します。この反復回数は任意に調整可能であり、値を大きくするほど、より詳細な洞察が得られます。
各ループの反復において、学習データの使用割合を徐々に増やしながらモデルを学習させます。NumPyのarange関数を用いて、0.1から1.0まで0.1刻みの割合を生成します。それぞれの割合について、利用可能な学習データのうち、最も直近の部分のみを用いてモデルを学習させ、固定されたテストデータセットに対して評価をおこないます。この処理は、学習データ全体が使用されるまで繰り返されます。
すべての反復が完了した後、学習データの使用割合に対するモデル性能をプロットします。グラフ上の赤いマーカーは、テスト誤差が最小となった点を示しており、それは80%の地点で観測されました。これは、利用可能なデータのうち80%のみを用いて学習した場合に、モデルが最良のアウトオブサンプル性能を達成したことを意味します。
重要な点として、この手法は古典的なk分割交差検証とは異なります。本記事の設定では、学習データとテストデータの間に観測値の重複は一切ありません。学習データは単に古いデータを順次追加する形で拡張される一方、テストデータは常に固定されています。100%に到達する前に性能の最小値が観測されたという事実は、最も古いデータが追加的な予測価値を持たなかったことを示唆しています。
結論として、この実験は、より小規模でコストの低いモデル、すなわち、限定された直近のデータのみで学習されたモデルが、全履歴データを用いて学習されたモデルを上回る性能を発揮し得ることを示しています。
#Store our performance error = [] #Define the total number of iterations we wish to perform ITERATIONS = 10 #Let us perform the line search for i in np.arange(ITERATIONS): #Training fraction fraction =((i+1)/10) #Partition the data to select the most recent information partition_index = train.shape[0] - int(train.shape[0]*fraction) train_X_partition = train.loc[partition_index:,X] train_y_partition = train.loc[partition_index:,y] #Fit a model model = get_model() #Fit the model model.fit(train_X_partition,train_y_partition) #Cross validate the model out of sample score = root_mean_squared_error(test.loc[:,y],model.predict(test.loc[:,X])) #Append the error levels error.append(score) #Plot the results plt.title('Improvements Made By Historical Data') plt.plot(error,color='black') plt.grid() plt.ylabel('Out of Sample RMSE') plt.xlabel('Progressivley Fitting On All Historical Data') plt.scatter(np.argmin(error),np.min(error),color='red')
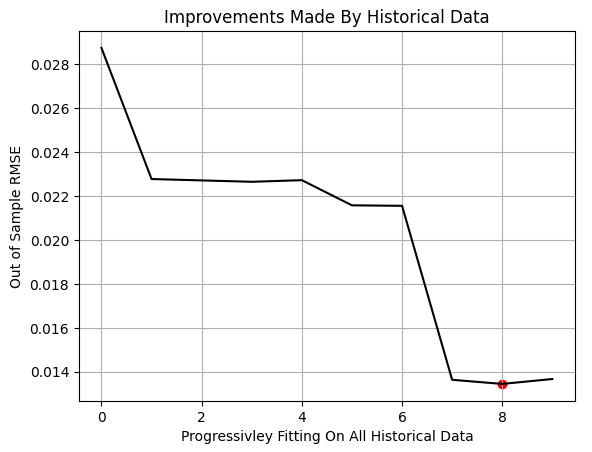
図4:MetaTrader 5ターミナルから得られた結果は、単に過去データを増やすだけでは、必ずしもモデル性能が向上しないことを示している
次に、ラインサーチによって推定された最適な分割インデックスを特定します。
#Let us select the partition of interest partition_index = train.shape[0] - int(train.shape[0]*(0.8))
この手法の結果、学習データに含まれる最初の300件の観測値、すなわち約1年分のデータは、予測において有用ではなかったことが示されました。
train.loc[partition_index:,:]
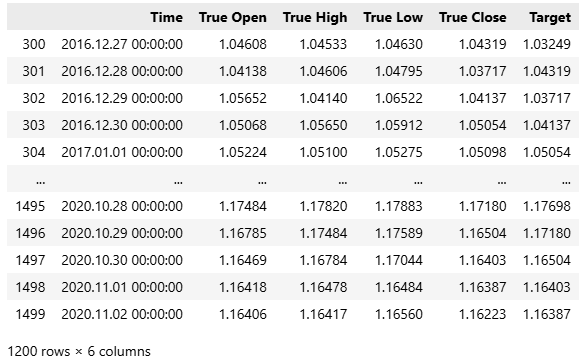
図5:上記のように、学習データの中から、現在の市場にとって最も関連性が高い部分集合を近似的に特定した
以上を踏まえ、以下の2つのモデルの性能を比較します。
- 古典的モデル:利用可能なすべてのデータで学習し、1ステップ先を予測するモデルです。
- 現代版:すべての過去データのうち、最適と判断された分割部分のみで学習し、複数ステップ先の予測を目的とするモデルです。
まず、古典的な設定に従ってベースラインとなる性能水準を確立します。そのために、新しいモデルを初期化します。
#Prepare the baseline model
model = LinearRegression() 次に、古典的アプローチに沿って、学習データ全体を用いてモデルを学習させます。
#Fit the baseline model on all the data
model.fit(train.loc[:,X],train.loc[:,y]) 続いて、モデルをONNX (Open Neural Network Exchange)形式にエクスポートする準備をおこないます。ONNXは、学習環境に依存せずに機械学習モデルを表現・展開できるフレームワーク非依存の形式であり、異なるプラットフォーム上での実行を可能にします。
#Prepare to export to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
必要な依存関係を読み込んだ後、モデルの入力および出力の形状を定義します。
#Define ONNX model input and output dimensions initial_types = [("FLOAT INPUT",FloatTensorType([1,4]))] final_types = [("FLOAT OUTPUT",FloatTensorType([1,1]))]
convert_sklearn関数を用いて、scikit-learnモデルをONNXのプロトタイプ形式に変換します。
#Convert the model to its ONNX prototype onnx_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
最後に、onnx.save()を用いて、変換後のONNXモデルをディスクに保存します。
#Save the ONNX model onnx.save(onnx_proto,"EURUSD Baseline LR.onnx")
MQL5で始める
この段階で、ベースラインとなる性能ベンチマークを確立する準備が整いました。最初のステップとして、両方のテストを通じて固定されるシステム定数を定義します。これにより、性能差が生じた場合でも、それがモデル設計の違いのみに起因することを保証できます。//+------------------------------------------------------------------+ //| Information Decay.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ja/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define SYMBOL "EURUSD" #define SYSTEM_TIMEFRAME PERIOD_D1 #define SYSTEM_DATA COPY_RATES_OHLC #define TOTAL_MODEL_INPUTS 4 #define TOTAL_MODEL_OUTPUTS 1 #define ATR_PERIOD 14 #define PADDING 2
次に、ONNXモデルを読み込みます。このベースラインモデルは、すべての履歴データを用いて学習され、1ステップ先を予測するように構成されていることを思い出してください。
//+------------------------------------------------------------------+ //| System resources we need | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD Baseline LR.onnx" as const uchar onnx_buffer[];
続いて、必要なライブラリを読み込みます。これには、売買執行用のライブラリと、最小ロットサイズや現在のBid価格とAsk価格など、取引に不可欠な情報を取得するための独自ユーティリティライブラリが含まれます。
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; TradeInfo *TradeHelper;
また、アプリケーション全体で使用するグローバル変数を定義します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; vectorf onnx_inputs,onnx_output; MqlDateTime current_time,time_stamp; int atr_handler; double atr[];
セットアップが完了したら、アプリケーションの初期化フェーズに進みます。ここでは、プログラムのヘッダで定義されたバッファからONNXモデルのインスタンスを生成します。まず、モデルハンドルが有効であるかを確認し、エラーチェックをおこないます。無効なハンドルが検出された場合は、エラーメッセージを表示して初期化を中断します。有効であれば、モデルの入力および出力の形状を定義します。この段階で発生したエラーも同様にユーザーへ通知されます。 初期化が正常に完了した場合には、現在時刻などの主要なグローバル変数を初期化し、新しいクラスインスタンスを生成し、アプリケーションが依存するテクニカル指標を初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Create the ONNX model from its buffer onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DATA_TYPE_FLOAT); //--- Check for errors if(onnx_model == INVALID_HANDLE) { //--- User feedback Print("An error occured loading the ONNX model:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Setup the ONNX handler input shape else { //--- Define the I/O shapes ulong input_shape[] = {1,4}; ulong output_shape[] = {1,1}; //--- Attempt to set input shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { //--- User feedback Print("Failed to specify the correct ONNX model input shape:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Attempt to set output shape if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { //--- User feedback Print("Failed to specify the correct ONNX model output shape:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Mark the current time TimeLocal(current_time); TimeLocal(time_stamp); //--- Setup the trade helper TradeHelper = new TradeInfo(SYMBOL,SYSTEM_TIMEFRAME); //--- Setup our technical indicators atr_handler = iATR(Symbol(),SYSTEM_TIMEFRAME,ATR_PERIOD); //--- Success return(INIT_SUCCEEDED); } }
アプリケーションの使用が終了した際には、実行中に確保されたリソースを適切に解放します。具体的には、ONNXモデル、テクニカル指標、ならびに動的に生成されたオブジェクトを解放し、メモリリークを防止します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(onnx_model); IndicatorRelease(atr_handler); delete(TradeHelper); }
アプリケーションの主要なロジックはOnTick()関数内に実装されています。新しい市場価格が到着するたびに、TimeLocal()関数を用いて現在時刻を更新します。この関数は、MetaTrader 5ターミナルを実行しているコンピュータのローカル時刻を返します。その後、current_time.day_of_yearとtime_stamp.day_of_yearを比較します。
time_stampは初期化時にのみ更新されているため、この条件は1日が完全に経過した場合にのみ成立します。条件が成立すると、タイムスタンプを現在時刻に更新し、テクニカル指標のバッファを更新し、ONNXモデルに入力および出力するためのベクトルを準備します。
次に、OnnxRun()コマンドを使用してモデルから新たな予測を取得します。この関数は、ONNXモデルのインスタンス、モデルの属性を指定するフラグ、そして準備された入力ベクトルと出力ベクトルを引数として受け取ります。
予測が得られた後、その結果をユーザーに表示します。未決済のポジションが存在しない場合は、モデルの出力に基づいて取引を実行します。一方で、モデルが予測を返さなかった場合には、エラーが発生した旨をユーザーに通知します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check for updated candles TimeLocal(current_time); //--- Periodic one day test if(current_time.day_of_year != time_stamp.day_of_year) { //--- Update the time stamp TimeLocal(time_stamp); //--- Update technical indicators CopyBuffer(atr_handler,0,0,1,atr); //--- Prepare a prediction from our model onnx_inputs = vectorf::Zeros(TOTAL_MODEL_INPUTS); onnx_inputs[0] = (float) iOpen(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[1] = (float) iHigh(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[2] = (float) iLow(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[3] = (float) iClose(Symbol(),SYSTEM_TIMEFRAME,0); //--- Also prepare the outputs onnx_output = vectorf::Zeros(TOTAL_MODEL_OUTPUTS); //--- Fetch a prediction from our model if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_inputs,onnx_output)) { //--- Give user feedback Comment("Trading Day: ",time_stamp.year," ",time_stamp.mon," ",time_stamp.day_of_week,"\nForecast: ",onnx_output[0]); //--- Check if we have an open position if(PositionsTotal() == 0) { //--- Long condition if(onnx_output[0] > iClose(SYMBOL,SYSTEM_TIMEFRAME,0)) Trade.Buy(TradeHelper.MinVolume(),SYMBOL,TradeHelper.GetAsk(),TradeHelper.GetBid()-(atr[0]*PADDING),TradeHelper.GetBid()+(atr[0]*PADDING),""); //--- Short condition if(onnx_output[0] < iClose(SYMBOL,SYSTEM_TIMEFRAME,0)) Trade.Sell(TradeHelper.MinVolume(),SYMBOL,TradeHelper.GetBid(),TradeHelper.GetAsk()+(atr[0]*PADDING),TradeHelper.GetAsk()-(atr[0]*PADDING),""); } //--- Manage our open position else { //--- This control branch remains empty for now } } //--- Something went wrong else { Comment("Failed to obtain a prediction from our model. ",GetLastError()); } } } //+------------------------------------------------------------------+
最後に、先ほど定義したすべてのシステム定数を未定義とします。
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef SYMBOL #undef SYSTEM_DATA #undef SYSTEM_TIMEFRAME #undef ATR_PERIOD #undef PADDING #undef TOTAL_MODEL_INPUTS #undef TOTAL_MODEL_OUTPUTS
アプリケーションの定義が完了したため、ここからテストを開始します。評価は、先に特定した5年間のバックテスト期間にわたって実施します。まず、構築したベースライン版のアプリケーションを選択し、それに対応する学習期間を設定します。

図6:バックテスト期間として選択した日付は、図3で特定した学習期間の外側に位置している
次に、バックテストを実行するためのエミュレーション条件を指定します。前述のとおり、実際の市場環境を忠実に再現するため、リアルティックに基づく「全ティック」を使用します。また、遅延設定はランダム遅延とし、ライブ取引環境における予測不可能性を信頼性高く再現します。

図7:選択したバックテスト条件は、実際の市場環境が持つ混沌とした性質を再現することを目的としている
ベースライン性能を確認したところ、初期バージョンのアプリケーションは、5年間のバックテスト期間において合計90ドルの利益を計上しました。この結果は決して壊滅的ではありませんが、優れているとも言えません。詳細に分析すると、取引構成において深刻な特徴が確認されました。バックテスト全期間を通じて、ロングポジションが一切実行されていなかったのです。すべての取引はショートポジションのみでした。この挙動は開発段階では想定されておらず、なぜモデルがこのように振る舞ったのかについて、明確な説明は得られていません。さらに、戦略の正答率は約50%と、ほぼ偶然に等しい水準でした。より深刻なのは、期待値が負であった点であり、これは長期的には資金を失う可能性が高いことを示しています。
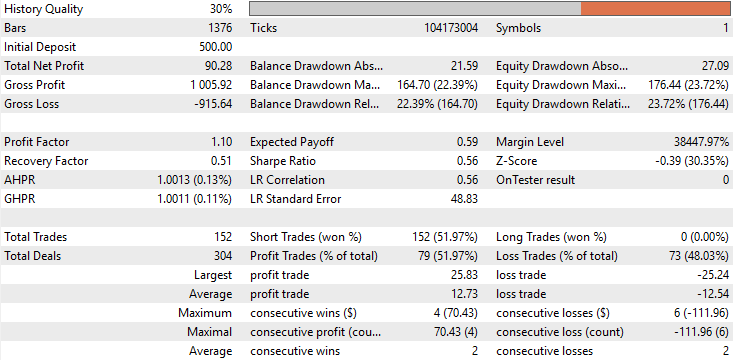
図8:実施したバックテスト結果に対する詳細な統計分析
エクイティカーブを確認すると、テスト期間全体を通じて大きなボラティリティと不安定性が見られます。2022年11月付近に差し掛かると、口座残高の増加は停止し、その後バックテスト期間内の約3年間にわたって、長期の横ばい状態に入ります。総合的に見て、ベースラインモデルは口座残高を有意に成長させることができず、長期的な有効性に対する信頼性は低いと言わざるを得ません。
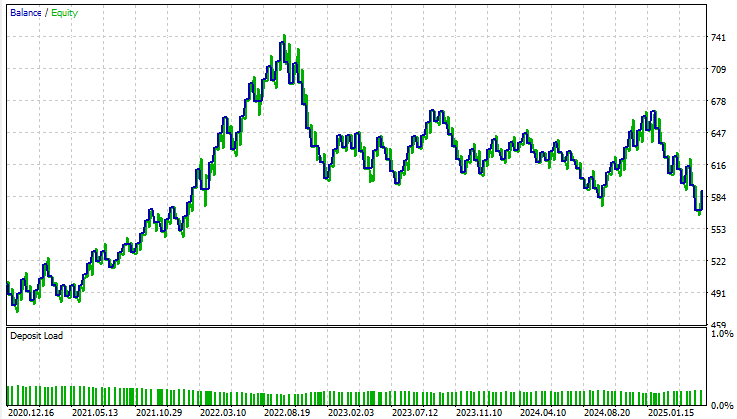
図9:統計モデル構築における従来のガイドラインに従った場合に得られたエクイティカーブの可視化
ONNXモデルの修正
古典的設定に基づいて得られたベースライン性能を確立したところで、次に従来の枠組みを超えて、ONNXモデルを修正し、プロのトレーダーが実際におこなう取引行動をより反映させます。 最初の大きな変更点は、従来の設計哲学からの逸脱です。これまでのモデルは1ステップ先の予測のみをおこなうものでしたが、今回のモデルは10ステップ先を予測するように設計します。人間のトレーダーはローソク足単位で取引するわけではなく、将来の市場動向を俯瞰的に捉えた上で行動します。モデルも同様に、先を見越した直感を反映させる必要があります。HORIZON = 10 次に、クロスバリデーション手法を用いて推定された最適なデータ分割を特定します。
#Let us select the partition of interest partition_index = train.shape[0] - int(train.shape[0]*(0.8)) train.loc[partition_index:,:]
その後、新たなモデルを読み込みます。アーキテクチャはベースラインモデルと同一です。
#Prepare the improved baseline model
model = LinearRegression() 新しいモデルは、この最適分割のデータのみを用いて学習させます。
#Fit the improved baseline model
model.fit(train.loc[partition_index:,X],train.loc[partition_index:,y]) 学習が完了したら、この改良版モデルをONNXプロトタイプ形式に変換します。なお、モデルの複雑さはベースラインモデルと同じです。
#Convert the model to its ONNX prototype onnx_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
最後に、ONNXモデルをファイルとして保存します。
#Save the ONNX model onnx.save(onnx_proto,"EURUSD Improved Baseline LR.onnx")
初期結果の改善
ユーザーが注意すべき点として、修正が必要なのはアプリケーションのヘッダーにあるONNXファイルのリソース参照のみです。その他のシステム部分は変更せず、従来通り動作します。//+------------------------------------------------------------------+ //| System resources we need | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD Improved Baseline LR.onnx" as const uchar onnx_buffer[];
次に、この改良版アプリケーションを選択し、ベースラインモデルと同じ5年間のバックテスト期間で評価します。重要なこととして、バックテスト条件(ランダム遅延やティックベースの実行など)は、図7で使用した条件と完全に同一に保ち、比較可能性を確保します。
図10:改良版アプリケーションを選択し、改善の効果を比較する
詳細な性能統計を分析すると、両アプリケーションの差は一目瞭然です。改良モデルの総純利益は約90ドルから330ドルへと、3倍以上に増加しました。 また、初期の取引分布の偏りも完全に修正されました。ベースライン版では、すべての取引がショートポジションのみであり、モデルの挙動に意図しない偏りが見られました。これに対し、改良版ではロングとショートの取引がバランス良く配置されており、実際の人間トレーダーの意思決定プロセスに近い形となっています。
さらに、正答率も約52%からほぼ60%に向上し、モデル内部の意思決定ロジックがより一貫性を持ち、精度が高まったことが示唆されます。
しかし、最も驚くべき点は、取引回数自体は両モデルで同一であったことです。バックテスト期間中、両バージョンとも正確に152件の取引を実行しました。それにもかかわらず、改良モデルは総純利益で3倍以上の成果を上げており、効率性の明確な向上が示されています。言い換えれば、同じ取引回数でありながら、改良モデルははるかに高い収益を生み出しました。さらに、シャープレシオや期待値も大幅に上昇しており、資本配分や取引タイミングがより賢明になったことを裏付けています。
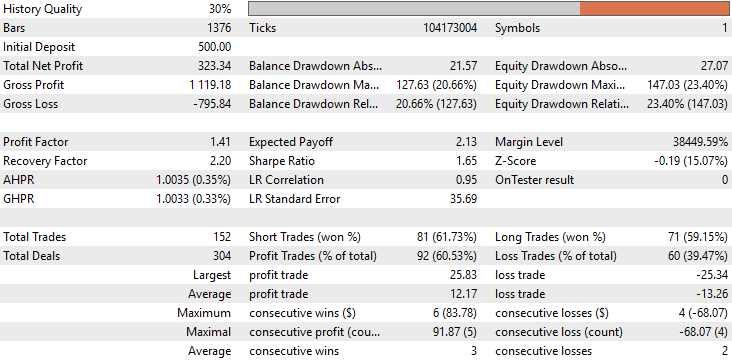
図11:分析結果の詳細から、今回おこなった変更が適切であったことが確認される
改良版が生成したエクイティカーブを確認すると、その差は顕著です。初期アプリケーションで見られた、ほぼ3年間続いた長期の横ばい期間は完全に解消されています。改良モデルでは、着実かつ安定した成長が示されており、以前のバージョンに存在した構造的制約や盲点が効果的に解消されたことが確認できます。この結果は非常に励みとなるものであり、導入した改良が実際に有意な影響を与えたことを裏付けています。
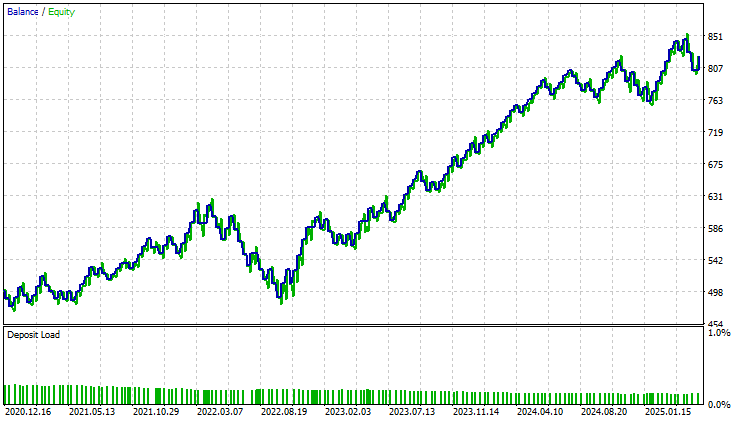
図12:改良版によるエクイティカーブは、5年間のテスト期間を通じてシステムに安定性をもたらしたことを示している
結論
本記事をお読みになった読者は、アルゴリズム取引における統計学習の本質について、すぐに活用可能な洞察を得られたはずです。重要なポイントの一つは、従来の統計原則に盲目的に従うことが、必ずしもアルゴリズムトレーダーにとって有益ではないということです。単に「ビッグデータ」のヒューリスティックを借用しても、そのまま私たちのドメインで通用するわけではありません。私たちのドメインでは、データの重要性は現在に強く依存しているためです。
また、本記事では、過剰に複雑または非効率なモデルを取得することで浪費されかねない資本を節約するための実践的な指針も示しました。ここで得られた洞察は、単に資本支出を削減するだけでなく、計算リソース、開発時間、先進的な機械学習システムの展開に伴うインフラコストなど、さまざまな面で実際の節約につながります。
さらに、読者は古典的クロスバリデーションのパラダイムに内在する盲点についても、より明確な認識を持つことができたでしょう。しばしば、私たちは、含めるデータすべてが本当に目的達成に寄与しているかどうかを見落としがちです。本記事で示した分析は、古典的統計学習ではほとんど指針のない、新たな形の過学習を明らかにしています。利用可能な全データを用いてモデルを学習させること自体が、認識されていない非効率の原因になり得ることを示しています。これらの教訓を総合すると、アルゴリズム取引向けに、より効果的で効率的、かつ収益性の高い機械学習モデルを構築するための指針が得られます。
| ファイル名 | ファイルの説明 |
|---|---|
| Information Decay Baseline.mq5 | 古典的機械学習パラダイムを用いて構築したベースライン取引アプリケーション |
| Information Decay Improved Baseline.mq5 | 本稿で導入したドメイン特化型手法(EMCV: Effective Memory Cross-Validation)を用いて改良したアプリケーション |
| Limitations of Cross Validation 1.ipynb | 市場データの分析とONNXモデル構築に使用したJupyter Notebook |
| EURUSD Baseline LR.onnx | 古典的ベストプラクティスに従って構築したONNXモデル |
| EURUSD Improved Baseline LR.onnx | 本稿で紹介した新しいドメイン特化ベストプラクティスに従い、古典的ベンチマークを上回る性能を発揮した改良ONNXモデル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20010
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索