
スプレッドシートを使ってトレード戦略を構築する

イントロダクション
スプレッドシートはかなり古い発明品です。 このタイプの最新のプログラムは強力で、表形式で表示されたデータを視覚的に分析することができます。 様々な角度からの分析が可能で、現在ではかなりスピーディーに行われています。 チャート、サマリーテーブル、what-if分析、条件付きセルの書式設定などがあります。
カスタム戦略を分析するために、この力のいくつかを試してみることを提案します。
個人的には、LibreOffice Calcを使っています。:-) しかし、他のスプレッドシートでも同じように使えます。Microsoft Excel、Google Sheetsなどがあります。 現在では、すべての人がお互いに変換することができ、方程式を構築するための同じ原理を特徴としています。
誰かしら何らかの表計算プログラムを使っていると思います。 また、解析したいテキストファイル形式(*.txtまたは*.csv)のデータもあります。 この記事では、そのようなファイルをインポートする方法を説明します。 MetaTraderターミナルのヒストリーを使用しますが、DukascopyやFinamのように、他のデータでも問題ありません。 明らかに、シグナルを確認するための手段が必要です。 これだけで、トレードに応用することができます。
願わくば、様々なカテゴリーのトレーダーに役立つ記事になると思いますので、この手のプログラムを見たことがない人にも理解できるように書いていきたいと思います。 同時に、一部の経験豊富なトレーダーでも馴染みのない問題を網羅します。
テーブルのクイックガイダンス - 初心者向け。
図1は、典型的な表計算プログラムのウィンドウを示します。
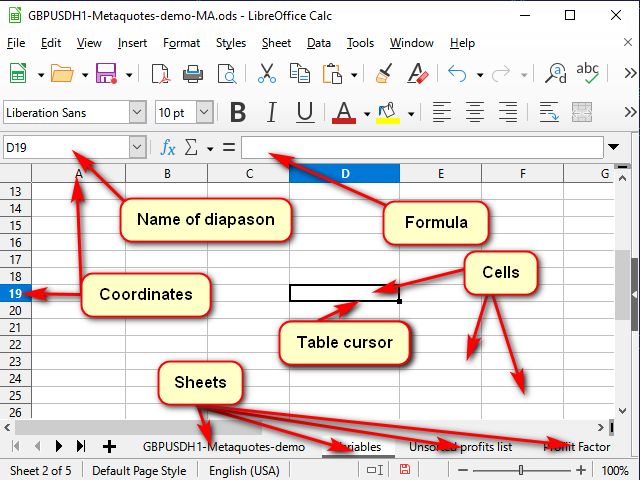
図1. 典型的な表計算プログラムのウィンドウ
どんなテーブルも「シート」のセットとして表示されます。 を、異なるタスクの別々の「タブ」と考えることができます。
1枚1枚が「セル」で構成されています。 各セルは基本的には小さいですが、強力な計算器です。
どのセルを今処理したいかをプログラムに理解させるために、各セルにはチェス盤や戦艦のボードゲームのような座標が表示されています。 座標が一緒になって、ユニークなセル "アドレス "を定義します。 アドレスは、列番号または名前と行番号で構成されます(例えば、図1では、テーブルカーソルによってハイライトされた "D19 "セルが示されている)。 ハイライトされた座標名と名前の行の両方で見ることができます。
アドレスには、座標だけでなく、シートの名前やテーブルファイルの名前まで含まれている場合があります。 通常はセルの名前と同じアドレスを使用します。 しかし、必要に応じて、自分の名前を設定して、このセルや範囲のセルが具体的に何を保存しているのかを明確にすることができます。 名前を名前行で表示(変更)することができます。
セルには、シンプルなデータ(クオートやボリュームのような)またはその値を計算するために使用する" フォーミュラ "のいずれかを含むことができます。
ハイライトされたセルの内容は、「数式行」で見ることができます(変更もできます)。
セル値を編集するには、そのセル値をダブルクリックするか、数式行で修正します。 また、セルをハイライトしてF2. を押すと、新しいテキストを作成する必要がある場合は、セルをハイライトしてすぐにインプットを開始することができます。 ただし、これまでのデータはすべてセルから削除されることを覚えておいてください。
ESC(キーボードの左上隅)を押すと、保存せずに編集をキャンセルできます。 Enter (カーソルが下に移動) または Tab (カーソルが脇に移動) を押して編集を確認できます。
複数のセルが強調表示されている場合、EnterとTabは強調表示された部分のみで動作します。 これを利用して、タスクのスピードアップを図ることができます。
他のボタンやメニューに関しては、かなり把握しやすいと思います。
はじめに: クオートのインポート
ストラテジーをテストするためのデータを用意しておきましょう。 以前言ったように、ターミナルからデータを取ります。 これを行うには、任意のチャートウィンドウでCtrl+Sを押すか、ターミナルメニューでファイル -> 保存を選択します。 ターミナルは、ファイル名とパスをインプットするための通常のシステムウィンドウを提供します。
ファイルの拡張子が*.csvであれば、通常はすべてうまくいきます。 もし*.txtであれば、ほとんどの場合、を右クリックして"で開く">"別のアプリを選択"を選択するか、システムがデフォルトでメモ帳や他のワープロを使用してこの拡張子のファイルを開くトレンドがあるので、最初にスプレッドシートアプリを開いて、そこからファイルを開く必要があります。
数値を変換するには、変換ウィンドウで適切な列を選択します。 そして、必要に応じて、整数部と分数部の分離器、および桁群の分離器(ボリュームの場合)を示してください。 エクセルでは、「もっと...」ボタンを使って行います。 Calcで、Column TypeリストからEnglish USAを選択します。
まだまだあります。 インポートが成功した後、テーブルに5-7,000行を残すことは理にかなっています。 実は、データが多ければ多いほど、各セルの結果を計算するプログラムの難易度が高くなります。 同時に、推定精度は取るに足らないほど高くなります。 例えば、5,000行のデータと10万行のデータの検証結果を比較した場合、結果の差はわずか1%であったが、後者の場合は計算時間が大幅に増加しました。
表を操作するためのキーボードショートカット
| ショートカット | アクション |
|---|---|
| Ctrl 矢印。 | 最も近い 連続データ行の境界線に移動。 |
| Tab | 入力の確認 と右セルに移動します。 |
| Shift + Tab + タブ。 | 入力の確認 で、左セルに移動します。 |
| Enter | 入力の確認 とセル下に移動します。 |
| Shift + Enter | 入力の確認 とセルの上に移動します。 |
| Ctrl + D | 強調表示された列を上から下へ埋める |
| Shift + Ctrl + 矢印 | 現在ポジションから連続範囲の終了までまでハイライト |
長い列を同じ式で埋める方法
小さな範囲の場合は、図2に示す方法を使用することができます: マウスを「選択マーカー」(テーブルカーソルの右下隅の4角)に移動します。 マウスカーソルが細いクロスに変わったら、このマーカーを目的の行または列にドラッグします。
図2. ドラッグして埋める
しかし、大量のデータの場合、大いに不便でしょう。
そのため、以下のいずれかの方法を使用してください。
方法1. 範囲を限定する
この一連の動作を図3に示します。
図 3. 範囲を限定して埋める
- 範囲の一番上のセルに希望の式をインプットし、インプットを確認します。
- 名前フィールドを使用して、範囲の最下段のセルに移動します。
- Ctrl + Shift + 上矢印を押して、範囲内の最上段のセルに移動し、すべての中間セルを選択します。
- Ctrl + Dを押して、セルにデータをインプットします。
この方法の小さな欠点は、範囲の最下段の番号を知る必要があることです。
方法2. 隣接する連続範囲を使用する
この一連の動作を図4に示します。
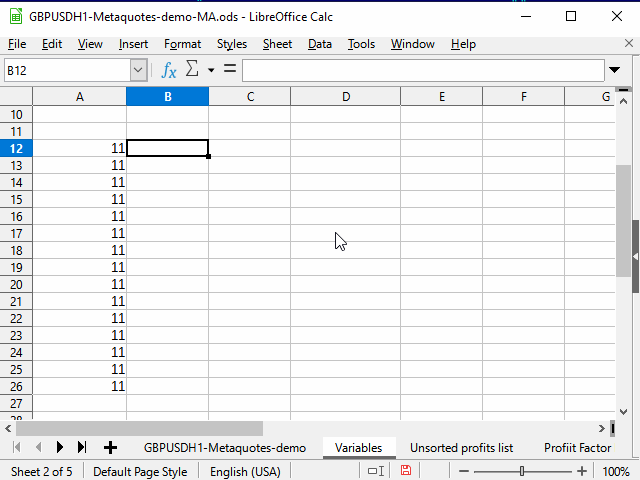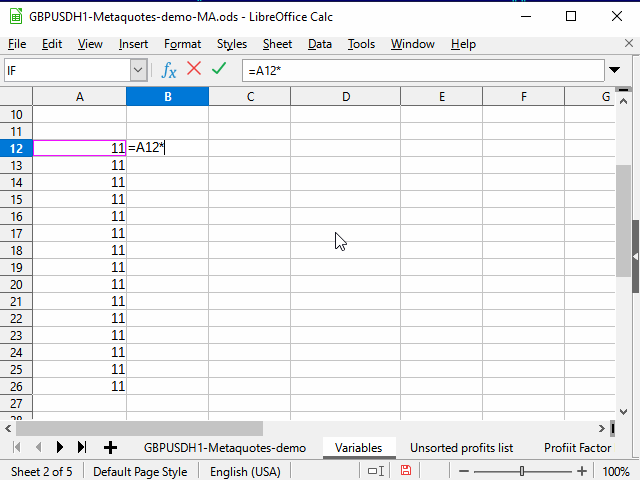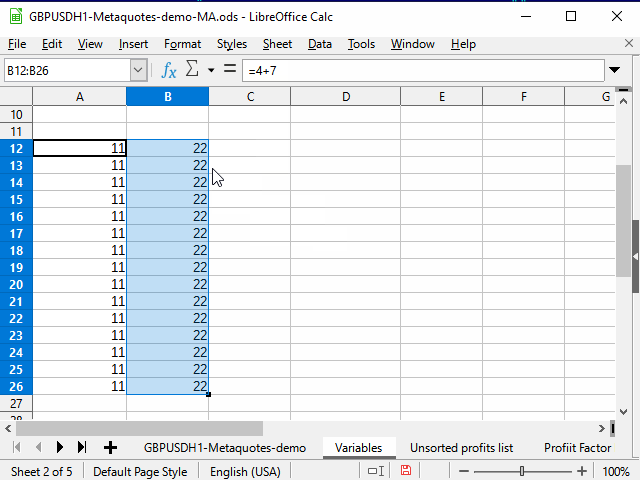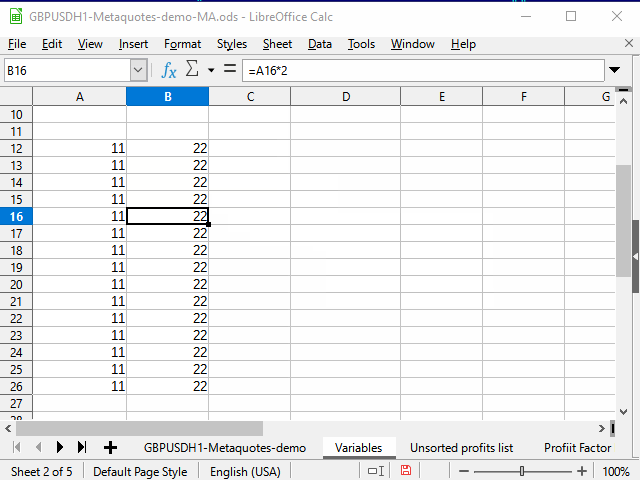
図 4. 隣接する範囲を利用して埋める
- 必要な式があるセルを選択します。
- シフト + 左矢印を押して、隣接するセルを選択します。
- Tabを押して、テーブル カーソルを左のセルに移動します。 ここでは、テーブルカーソルが適用された選択範囲内でのみ移動する関数を使用します。
- Ctrl シフト + 下向き矢印 - 連続範囲の最下行に2つの列を選択します。
- Shift 右矢印 - 左側の列の選択を解除します。 右が選択されたままです。
- Ctrl + D - データで列を埋めます。
図中の方程式の線の内容に注意してください。 リンクを含む式を別のセルにコピーすると、カーソルのポジションに応じてこのリンクが自動的に変化します。 そのため、このようなリンクを「相対的」と呼びます。
コピー中にセル への link を一定に保つ必要がある場合は、リンクを選択して F4 を押してください。 行番号と列名の前に$シンボルが表示され、数式をコピーしても値は変わりません。
リンク全体ではなく、特定の列や行だけをそのまま残したい場合もあるでしょう。 この場合、$シンボルを変更不可部分だけに残しておきます(F4を1~2回押しても大丈夫です)。
さて、タスクを加速させる基本的な方法をマスターしたら、次は戦略そのものに移りましょう。
ストラテジー
標準的なEA「ExampleMoving Average」で実装されている戦略を使ってみましょう。
ポジションは、以下の場合に開きます。
- ポジションがなく、
- ロウソクの実体が、移動平均線をクロスした(オープン - МАの片側、クローズ - もう片側)。
ポジションは、以下の場合にクローズされます。
- 開いているポジションがあり、
- ローソクが、オープニングとは逆方向にMAをクロス。
インジケータデータの追加
スプレッドシートを使った計算の特徴は、計算の小計は原則として別々に保存する必要があることです。 これより、方程式の理解や誤差の検出が容易になるとともに、隣接するセルからのデータに基づいて方程式を構築することが容易になります。 その上、そのような「断片化」が新しいアイデアを生み出すこともあります。
でも、タスクに戻りましょう。
インポートして少しフォーマットすると、元のクオートは次のようになります(図5)。
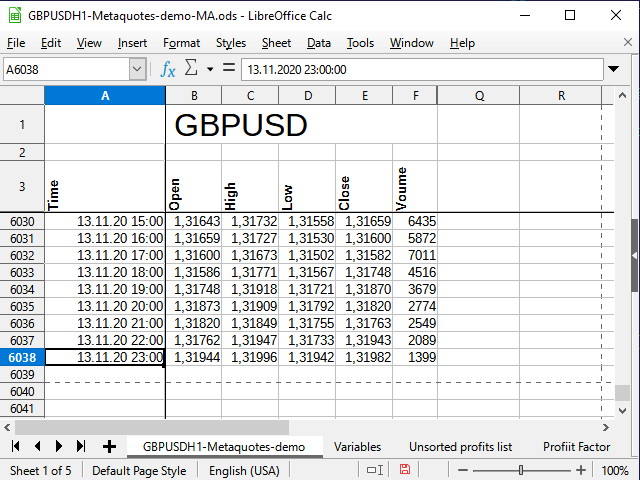
図 5. オリジナルのクオート
テーブル全体の名前とカラム名の間の空白行に注意してください。 この行を使用すると、スプレッドシート・プロセッサは2つのブロックを別々のテーブルとして扱うことができるので、上の範囲のセルを結合しても、下の範囲のセルには異なるフィルタを使用することができます。 このラインを外すと問題が発生する場合があります。
最初の行と列を修正して、現時点では不要な情報を隠すようにしましたが、すべてのデータはテーブルに残っています(方法については、スプレッドシート・プロセッサのヘルプを参照してください)。
日時はAの欄に、始値はBの欄に、などとなっています。 テーブルの直近の行には、6038という番号が付けられています。
戦略構築の第一歩はインジケータの構築です。 インジケータをカスタマイズできるようにするために、別のシートを追加して、そこに変数の表を作成してみましょう。 式を作成する際に何をどこで取るかが明確になるように、名前線を使って各変数に適切な名前を付けていきます。
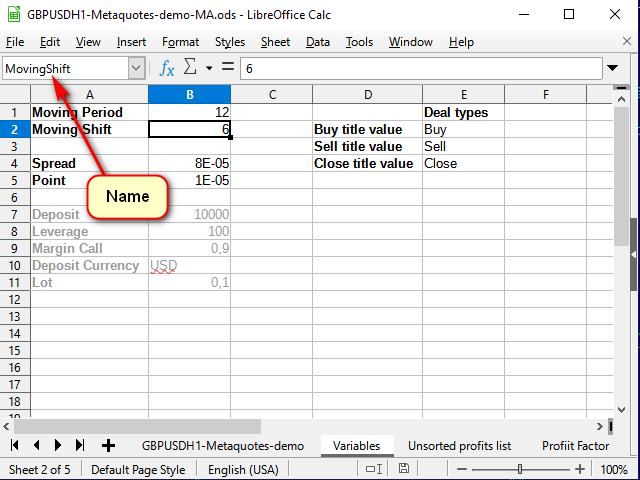
図 6. 可変シート
さて、データシートに戻りましょう。 まず、最終的な式を少しだけ簡略化するために、Gの欄のリストの中にクオートのインデックスを書きます。 行インデックスから3を引いた値になります。
=ROW()-3
G4セルに式を書いた後、MAの計算式が普遍的なままになるように下のセルすべてに拡張します。 MA(オフセット+期間)が既存のデータを超えると、平均値の計算が意味をなさなくなります。
SMAの計算式自体は、メインデータシートのН4に書かれており、以下のようになっています。
=IF( G4>(MovingPeriod+MovingShift), AVERAGE( INDIRECT( "E" & ( ROW()-MovingShift-MovingPeriod) & ":" & "E" & ( ROW()-MovingShift) ) ), "" )
他のセルへのリンクを必要とする式をインプットする際に、マウスでセルを指定することができます。
現在の方程式はIF()関数を呼び出すところから始まります。 ご想像の通り、条件チェック関数です。 And, Or, Notのようなすべてのブール式は、後で必要になった場合に備えて関数にもなります。
関数を呼び出す際には、引数を括弧で指定し、カンマ(この場合のように)かセミコロンで区切って指定します。
IF関数は3つの引数を受け付けます。条件が真の場合の値、条件が偽の場合の値です。
今回は、MA曲線の本格的なポイントを計算するのに十分なデータがあるかどうかを確認するために使ってみました。 データが足りない場合は、空の文字列を保存するだけです。 そうでなければ、ある範囲から平均値を計算します。
インダイレクト関数は、テキスト文字列で設定された範囲の値(または値)を返します。 平均値を計算するために必要な範囲のアドレスは、インプット値に基づいて形成されるべきであるので、まさに必要とするものです。
表計算プログラムの & シンボルは、2 つの行の連結を表します。 このように、いくつかのパーツからのアドレスを「結合」します。 最初の部分は終値("Е")が位置する列名で、2番目の部分は現在の行番号から平均化長を引いたものからシフトを引いたものとして計算された "リモート "アドレスです。 この表現の3つ目のピースは、範囲の連続性を示すコロンシンボルです。 シフトを考慮した列名と行名が続きます。 あまり強く強調しないことにしました。 アンパサンドのカットインが理解するのに役立つと思います。
この式は、以下のすべての行に拡張する必要があります。
その結果、こんな感じのものが出てきます。
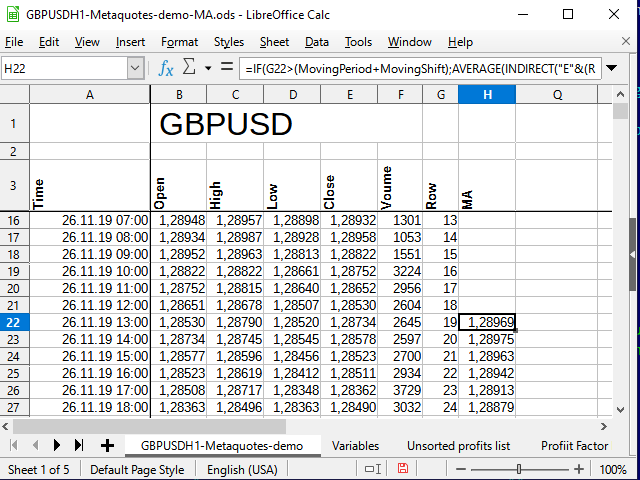
図 7. МА計算を追加した後の表
見ての通り、Н列の数字が出始めたのは、22行目(19番目のインプット)だけです。 その理由は、図6で説明します。
インジケータデータだけでなく、初期データも手に入りました。 戦略を実行する時が来ました。
戦略の実施
シンプルなシグナルの形で戦略を実行していきます。 МАが下向きにクロスしている場合、セルは"-1 "の値を受け取り、そうでない場合は-"1 "の値を受け取ります。 クロスがない場合、セルには空の文字列の値が含まれます。
セルI4に移動します。 セルの基本的な式は次のようになります。
=IF( AND( B4>H4,E4<H4 ),-1 , IF( AND( B4<H4,E4>H4 ), 1 , "") )
チャートで確認してみてください、うまくいっています。 しかし、これはシンプルな反転の方程式です。 トレード状況を追跡することはできません。 これを試してみて、興味深い結果を得ることができますが、今のタスクは、記事の冒頭で説明した戦略を実行することです。 そのため、各足(各行)でのトレード状況を記録する必要があります。
J カラムがかなり適しています。 J4 セルの式は次のようになります。
=IF(AND(I4=-1,J3=""), -1 ,IF(AND(I4=1,J3=""), 1 ,IF(OR(AND(I4="",J3=1),AND(I4="",J3=-1),I4=J3), J3 ,"")))
イベント(クロス点)が発生している場合は、前回のトレードの状況を確認します。 トレードが成立していて、逆方向にクロス点が発生した場合はクローズします。 トレードが決済している場合は、開きます。 それ以外の場合は、ステータスを保存するだけです。
データが該当する期間にこの戦略を実行していたら、どこで売買していたかが一目瞭然になるように、また、戦略を分析するのに便利なように、もう一つのシグナル欄を導入してみましょう。
シグナル名はヘルプから取得でき、変数シート上で作成することができます。
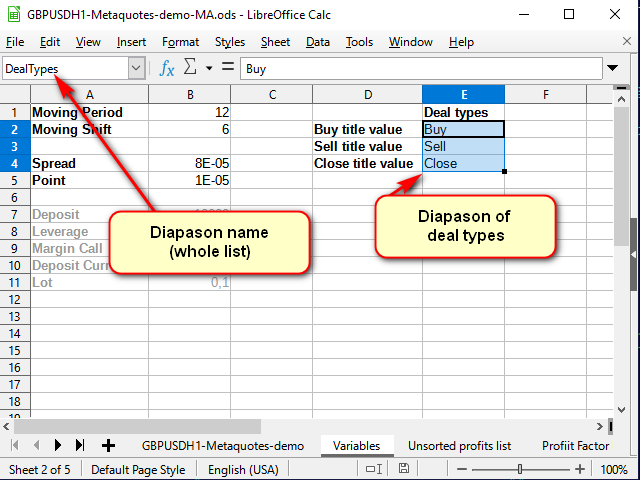
図 8. 取引名のヘルプを追加した後の変数シート
名前の行に注意してください: ここでは、単一のセルではなく、全体の選択範囲に名前を設定します。
これで、メインシート(データ付き)のК4セルに以下のように書けます。
=IF(AND(J3=1,J2=""),INDEX(DealTypes,1),IF(AND(J3=-1,J2=""),INDEX(DealTypes,2),IF(OR(AND(J3="",J2=1),AND(J3="",J2=-1)),INDEX(DealTypes,3),"")))
トレードは、次のローソク足のオープニングで後のシグナルが開かれます。 したがって、この式のインジケータのシフトに注目してください。
取引がなく(ステータス欄の前のセルが空)、シグナルが到着した場合、どのような取引タイプにするかを指定します。 トレードが成立している場合は、その合図に従ってクローズします。
Index 関数は、最初のパラメータとして、検索を行う範囲を指定します。 今回の場合は、名前で設定します。 2番目のパラメータは、範囲内の行のインデックスです。 範囲が複数の列で構成されている場合は、必要な列を設定します。 セミコロンで区切って複数の範囲を指定した場合は、範囲のインデックスも1から始まるように設定します(それぞれ3番目と4番目のパラメータ)。
その結果、この式を下のすべてのセルに拡張し、条件付き書式設定を適用すると(分析中に書式設定は不要なので、より視覚的にアピールするために)、おおよそ次のような結果が得られます。
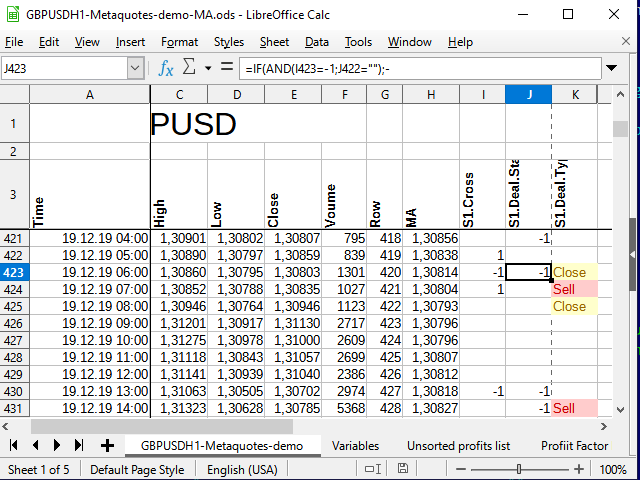
図 9. トレードのシグナル
戦略を分析する
戦略の収益性を分析するためには、トレード期間中の価格による移動距離を計算する必要があります。 一番簡単なのは、数段階に分けて行うことです。
まず、トレード価格を選択します。 トレードが開かれている場合は、シグナル(L)の隣の列に価格を設定し、トレードが決済するまで、一連の各セルにコピーします。 トレードがない場合は、セルに空行が書き込まれます。 L4セル内の式。
=IF(K4=INDEX(DealTypes;1);B4+Spread;IF(K4=INDEX(DealTypes;2); B4 ;IF(OR(K4=INDEX(DealTypes;3);N(L3)=0); "" ;L3)))
シグナルセル(К4)に「買い」の文字がある場合、トレードの始値はローソク足の始値にスプレッドを加えたものになります。 k単語が "売り "の場合は、 "クローズ"(または前の列のセルに数字が含まれていない場合) - 空の文字列、および同じ列の前のセルが数字である場合は、シグナルの列には単語が含まれていない間に、前のセルをコピーして、ロウソク足の始値を書きます。
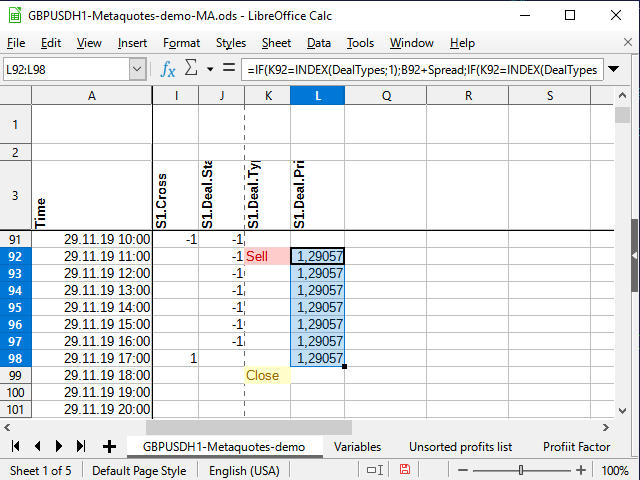
図 10. 取引始値
このように、決済時のトレード利益を計算することができるようになります。
必ず下の式を拡張してください。
隣接する欄の始値と終値の差をすぐに計算することができました。 その代わり、もっとトリッキーなことをします。 Nコラムの差分を計算して、ユニークなデータだけを選別できるようにし、その後にその頻度を計算していきます。
現在の一番シンプルな査定事例では、戦略の効率性を評価することが目的なので、資金の管理は一切使いません。 そのため、価格差をpips単位で計算すれば十分です。 例えば
=IF(K4=INDEX(DealTypes;3);IF(I3=-1;ROUND((B4-L3)/Point);ROUND((L3-B4)/Point)); "" )
平均条件を確認する代わりに、( B3 -L3)*I3を乗算すればよいことは明らかですが、初心者には視覚的にわかりにくいでしょう。
そして、いよいよトリックの時間です。 М列では、トレード範囲に関するすべての一意なインプットに番号を付け、一意でないものは番号を付けずに残します。
=IF(N4<>"";IF(COUNTIF(N$3:N4;N4)=1;MAX(M3:M$4)+1;"");"")
外部条件は明確です: 右のセル ( N4 ) が空でなければ、一意であるかどうかをチェックし、必要であれば番号を付け、そうでなければ空の文字列を残します。
しかし、ナンバリングはどうやって行うのでしょうか。
Countif関数は、セル値が2番目のパラメータで指定された条件に対応することを条件に、指定された範囲内の数字の量をカウントします。 M71セルについて式が計算されたとします。 N71のセルには、番号531が含まれています(図11参照)。 この数字は今まで見たことがないです。
条件セルに作用シンボルが表示されていない場合は、2つの値の等価性を確認したいと想定します。 数はそれ自体に等しい( N71 =N71)、ので計算してみましょう。 計算は常にN$3セルから始まり(3の数の前にドルシンボルがあることに注意)、現在のセル(式にはドルシンボルはありません)まで計算されます。 N$3:N71の範囲全体を見て、この範囲内の531個の数字の合計数を数えてみてください。 今まではそのような数字はなかったので、合計で1(今見つかったものだけ)となります。 条件が満たされていることを意味します。 したがって、次の範囲を取ります:式が配置されている列は、数字の最初のセル(M$4)から現在のもの(M70)の前のセルまでの最初のセルから始まります。 以前にそこに数字があった場合は、その中で一番大きいものを取って、そこに1を足してください。 そうでなければ、最大のものは0であり、応じて、最初のシーケンス番号は準備ができています!
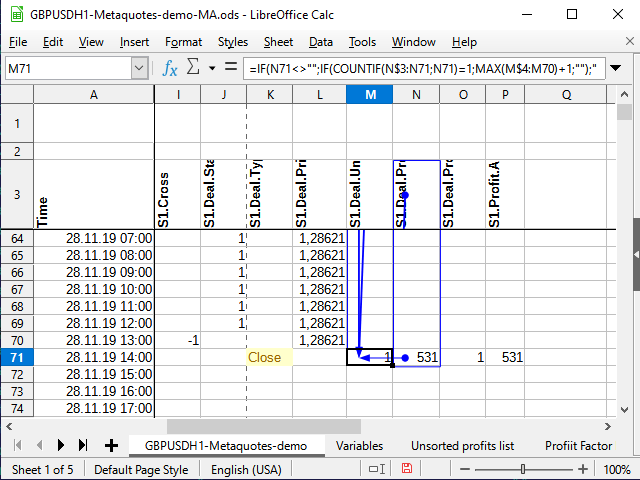
図 11. ナンバリング 影響を受けるセル(範囲最終点)
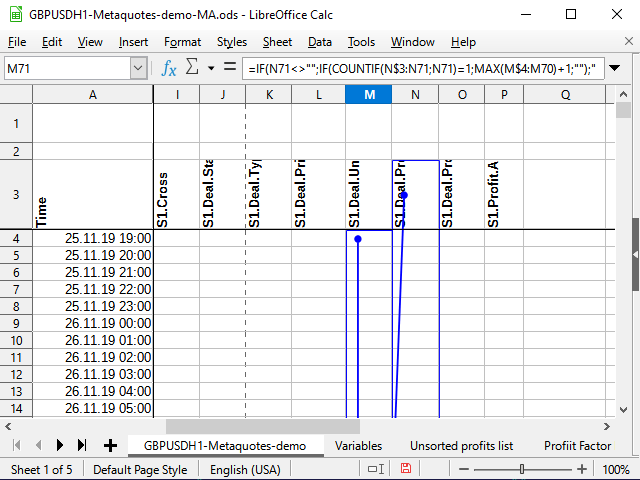
図 12. ナンバリング(レンジ起点)
図11では、与えられたセルに影響を与えているセルを表示する内蔵の解析ツールを使ってみました。 矢印の付いたドットは範囲の開始または「正確な」セルを示し、長方形は範囲を示します。 矢印が連続していて、正確にN$3から始まることを明確にするために、図12を添付しました。その上、値の2つの列を追加します:結果の型と取引 "モジュール"。
結果のタイプには、数字を使用しています:買いトレード - 1、売りトレード - 2. この場合、トレード結果として損益が出たかどうかによって、結果がプラスになることもあれば、マイナスになることもあります。 これより、最終的な分析式を短くすることができます。
ここで、О4セルに書き込まれた式を示します。=IF(AND(N(N4)>0;I3=-1); 1 ;IF(AND(N(N4)<0;I3=-1); -1 ;IF(AND(N(N4)>0;I3=1); 2 ;IF(AND(N(N4)<0;I3=1); -2 ;""))))
「モジュール」とは、符号を考慮せずに損益の額を表したものです。 これは、トレード決済のシグナルが届くまで、価格が一方向にどこまで進んだかを記述したものです。 SLやTPを選ぶ際の参考になります(本来の戦略には不要なものであっても)。
=IF(N4<>"";ABS(N4);"")
頻度(確率)チャートを作成するためには、トレード結果データを昇順に並べるのが良いでしょう。 元のデータは時間でソートされていて、他の方法でソートできないので、別のシートにコピーします。
各固有の利益結果が固有の番号(М列)を持つことを考えると、ソートされていないデータを新しいシートにコピーする方法は少なくとも2つあります。
その一つが、М列の標準フィルタを使って「空でない」セルを選択し、N列のデータをコピーして、専用のペースト(値のみ)を使って別のシートに貼り付けるだけです。
2つ目の方法は、式を利用する方法です。 その利点は、元のデータ(他のテスト範囲を使用することにした場合、同じ変数や他のもの)が変化したときにデータ自体が変化することです。 デメリットは、やはり仕分けができないことでしょう。 でもソートするには、コピー/ペーストを使用する必要があります。
ソートされたデータとソートされていないデータが同じシート上にあると、データをコピーするアクションが少し少なくて済むので便利です。 そこで、ソートされていないデータを式を使ってコピーし、ソートに再び手動でコピーするというオプションを示します。
新しい利益データシートで、А2の式を作成します。
=VLOOKUP( ROW(1:1);'GBPUSDH1-Metetaquotes-demo'.$M$3:$N$6038; 2)
Row(1:1) 関数は、最初の行の番号を返します。 セルを下向きに塗りつぶしすると、行番号が変化し、応じて2列目、3列目などの番号が表示されます。
Vlookupは、範囲 (2番目のパラメータ)の最初の列にある何らかの値 (1番目のパラメータ)を探し、同じ検出された行にある値を、3番目のパラメータで指定された列(場合、指定された範囲の2列目)にあるにも関わらず返します。 つまり、1から始まるN列から番号付き(一意)の数値がすべてコピーされます。
標準フィルタでメインシートの直近の数字を定義した後、範囲制限法で残りのデータを全てコピーします。
以下の動作は、図13のアニメーションに示されています。
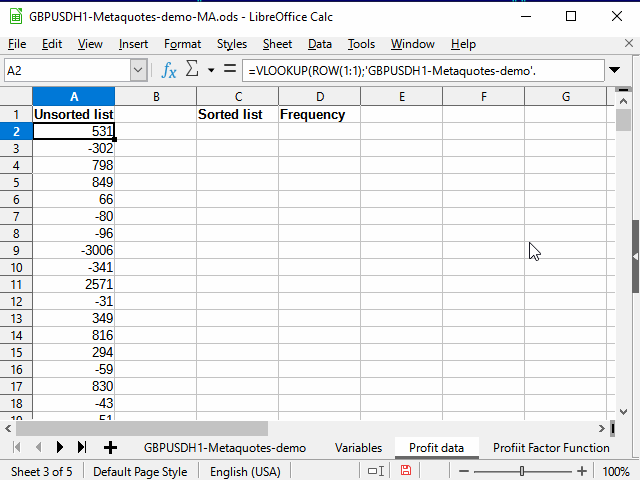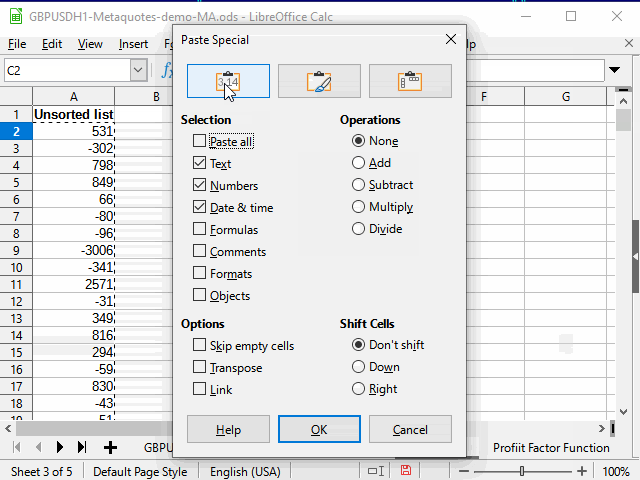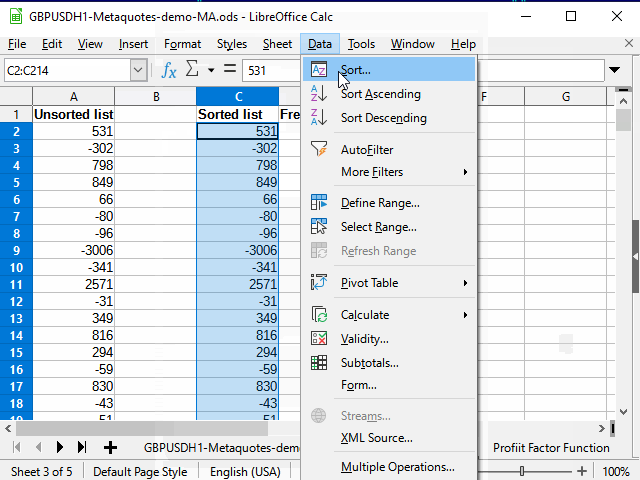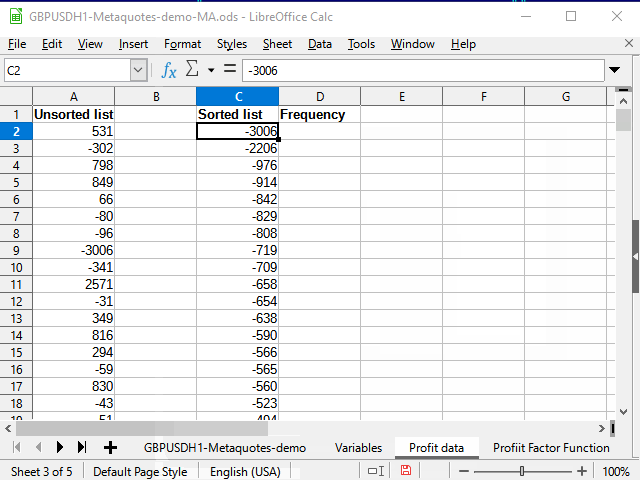
図13。 ソートのデータのコピー
利益のあるトレードと利益のないトレードの頻度を記述する必要があります、すなわち、確率シリーズを構築します。
同じシートのD2セル(利益データ)には、次のような式を書くことができます。
=COUNTIF('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;C2)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)
各利益値の頻度(または確率)を記載します。
Count関数は、区間内の数値の数を計算し、Countifは条件を満たす場合に同様の処理を行います(この場合、C列のセルの値と等しい値を持つセルのみを計算します)。
通常はインターバル変動シリーズを行うことをお勧めします。 理論的にはかなりの取引数になると言えます。
間隔の大きさは、式を使って計算することをお勧めします。
=(MAX($'Profit data'.C2:$'Profit data'.C214)-MIN($'Profit data'.C2:$'Profit data'.C214))/(1+3,222*LOG10(COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)))
この式を'変数 '.E7セルに入れて「間隔」と名付けました。 このインターバルが大きすぎることが判明しました。 一般的に確率がどのように分布しているのかが不明確だったので、4で割ってみました。 最終的には344という数字の方が目的には合っていることがわかりました。
'Profit data' シートでは、ソートされたリストの最初の番号を F2 にコピーしました。
=C2
他のすべてのセルは式で埋められています。
=F2+Interval
直近の値が最大トレード値を超えるまでセルを埋めていきました。
G2 セルには次の式があります。
=COUNTIFS('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;">="&F2;'GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;"<"&F3)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038)
CountifS (Countifとは異なり)では、複数の条件を "AND "演算子と組み合わせて受け付けることができます。 あとは同じです。
2つの系列が構築されると、すぐにそのチャート表示を見たくなります。 幸いなことに、どの表計算プロセッサでもを実現することができます。
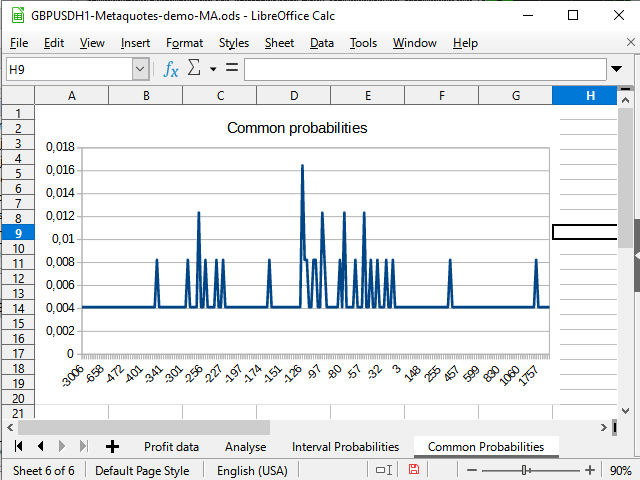
図 14. "即時"確率分布チャート
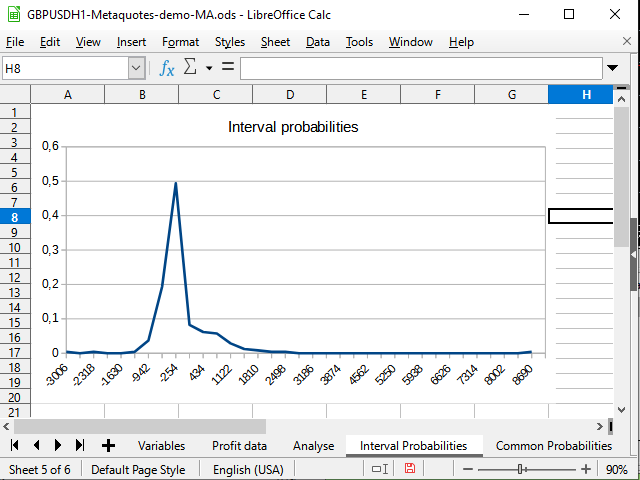
図 15. 完成した取引の確率の区間分布のチャート
図14は、確率密度の負のシフトを示します。 図15は、-942から2154に明確に見える天井があり、8944にスパイク(1つのトレード)があることを示します。
分析シートは、特に難しいことはないと思います(分析されたことをすべて考慮して)。
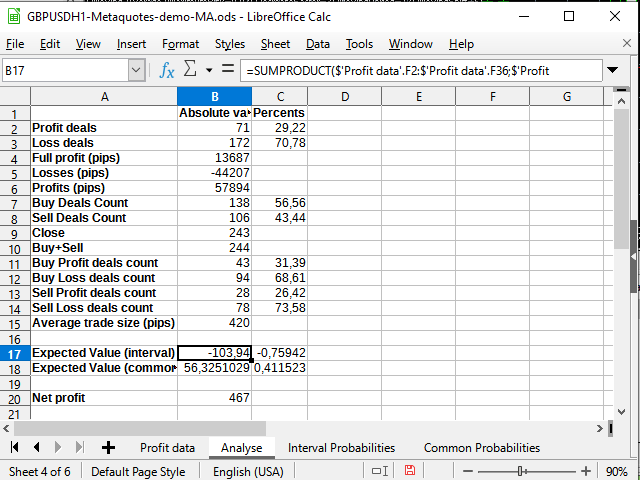
図 16. 統計計算
ここで唯一新しいのは、2つの区間をパラメータとして受け入れ、区間のメンバの積の和を返すSumproduct関数を使用することです(例えば、1行目から1行目、2行目から2行目、など)。 この関数を使って、期待されるペイオフを計算してみました。 以上の複雑な統合方法は適用しないことにしました。
期待されるペイオフは、得られた利益よりも大幅に少なく、割合的には0前後で変動します。
このように、この戦略は機能しますが、大きなドローダウンに悩まされる可能性があります。 おそらく、強いトレンドの間に完全に動作します(〜9000 pipsのサージは、とても孤独ではなかった場合は、興味深いものに見えるでしょう)、しかし、レンジは、ほとんど可能性が高く、その手数料を取るでしょう。 ストラテジーは、TP(約420~500pips)などのペンディングオーダーを導入するか、トレンドフィルタを導入するかのいずれかの方法で、深刻な修正が必要となります。 改善にはさらなる調査が必要です。
テスターでの戦略の実行
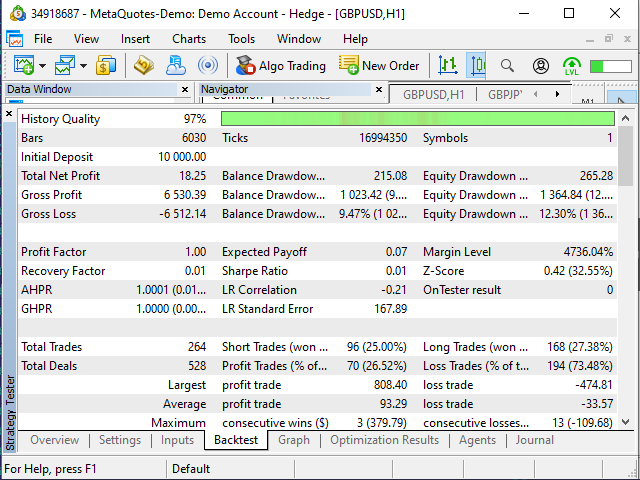
図 17. "例:移動平均"EAテスト結果
正直、EAの結果には驚きました。 テーブルがを閉じることを示唆したトレードを開いたという事実とその逆は、その決定が多かれ少なかれデータに基づいている可能性があるので、おそらく正常と考えられるかもしれません(例えば、テーブルでは、25.11.2019は19:00に開始し、EAに一日の初めから開始するタスクを与えている間)。
これよりも、以下のような感じの取引があったことに驚きました...。
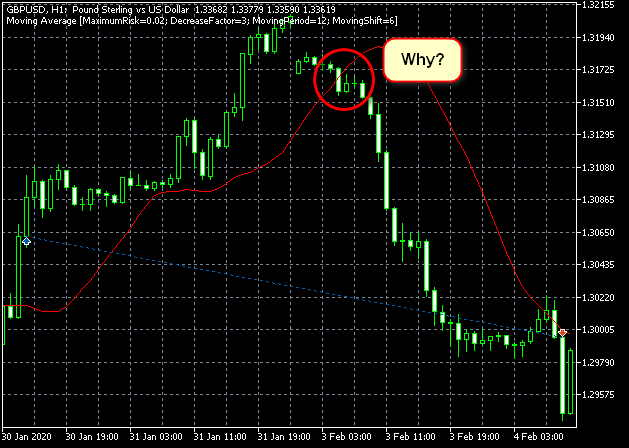
図 18. アルゴリズムの理解が間違っていてもいいのでしょうか。 それともテスターに何か問題があるのでしょうか?
ほとんどの場合、十分に検索しておらず、アルゴリズムでそのような動作の理由を見つけることができませんでした。
2つ目の奇妙な事実は、EAはテーブルが示唆したよりも20以上のトレードを行ったということです。 しかし、これにもかかわらず、結果は不思議なほどものに近いです。
| テスターのEA | 表 |
|---|---|
| 期待ペイオフ - +0.07 (ほぼ0)。 | 期待ペイオフ - -0.76 — +0.41 (0付近で変動)。 |
| 儲かる/儲からないトレード - 26.52%/73.48% | 儲かる/儲からないトレード - 29.22%/70.78% (8%のトレード数の差を考慮すると、ここでは3%の差は取るに足らないと考えられます)。 |
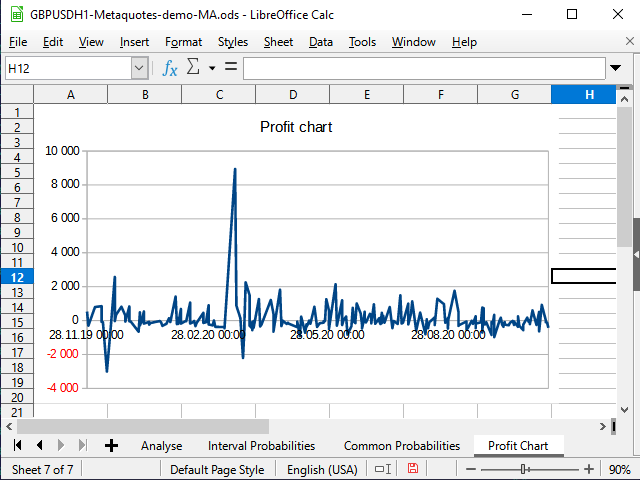
図 19. 表の収益性チャート
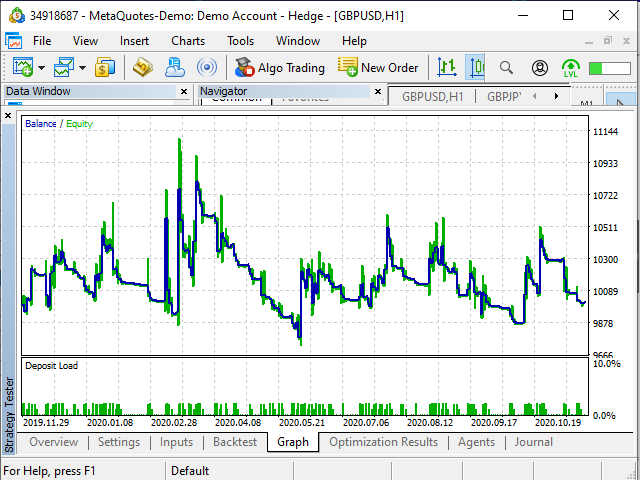
図 20. テスターの収益性チャート
テーブルの準備と数字いじりに30分ほどかかりました。 EAを開発する代わりに、既プロダクトのものを使うことにしました。 大まかなラインでアルゴリズムを把握するのに10分ほどかかりました。 しかし、おそらく使わないだろうということを理解するために、新しいEAを書く必要はありません...。 EAの開発は、その戦略に価値があることを実感して初めて合理的なものとなります。 今のところ裁量トレードの方が好きです。:-)
結論
スプレッドシートは、特にプログラミングのスキルがない人にとってはもちろん、プロトタイプを素早く作成して、後からMQLに変換したいと思っている人にとっても、テストや戦略を練るのに良いツールだと考えられます。
もちろん、スプレッドシートプロセッサの方程式は、プログラムコードに似ていることがあり、フォーマットはそこでは視覚的に明確ではありません。
しかし、スプレッドシートの明快さ、新しいアイデアを即座にテストする関数、影響を与えるセルのハイライト、あらゆる種類の図など、スプレッドシートは欠かせないツールとなっています。
表にトレードのログを保存したり、インポートできるようにしておけば、スプレッドシートプロセッサーを使用して戦略を改善したり、トレードのミスを発見したりすることができます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/8699
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 トレーディングにおけるニューラルネットワークの実用化。 Python (パートI)
トレーディングにおけるニューラルネットワークの実用化。 Python (パートI)
 手動チャートおよび取引ツールキット(第II部)チャートグラフィック描画ツール
手動チャートおよび取引ツールキット(第II部)チャートグラフィック描画ツール
 パターン検索への総当たり攻撃アプローチ(第II部): イマージョン
パターン検索への総当たり攻撃アプローチ(第II部): イマージョン
 トランスダクション・アクティブ機械学習におけるスロープブースト
トランスダクション・アクティブ機械学習におけるスロープブースト
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
オレフ・フェドロフ
この記事を書いてくれてありがとう。私は75歳以上で、エクセルの基本的な知識はあります。しかし、35年以上トレーディングに携わってきたおかげで、データセットや、確率の研究をするためにそれらをどのように使うかを理解しています。
私たちは、楽しみながら脳を活性化させるために小口でトレードしている高齢者のグループです。証明可能性の研究からアイデアを創造し、実行することで、活動的で幸せな時間を過ごしています。
だから、私はあなたの記事を歓迎します。拍手を送りたい。
1.MT5の履歴データを、スプレッドシートが 設計したとおりに使用でき、データを生成できる形式で生成するツールを教えてください。
現在、インジケーターにエクスポートボタンがあれば、csvファイルを生成することができ、それをExcelシートとして保存し、分析を行っています。
他のインジケーターのロジックを使用し、新しいスプレッドシートの列を作成するために変更することができる、あらかじめ作成された形式のファイルでcsvデータを生成することができるcsv作成mqlインジケーターがあると聞いています。
このインジケーターはどこで購入できますか?
2.エクセルでこのようなヒートマップを作成し、確率調査を行いたいのですが。新しい記事でこれを教えてもらえますか?
例このようなヒートマップを作成したいのですが。インジケータでcsvファイルを生成した後、それをエクセルに変換し、フィルタリングして、この添付ファイルのようなヒートマップやその他のレポートを作成するには、どのようにステップ・バイ・ステップで行えばよいでしょうか?
ありがとうございました。