
ニューラルネットワークが簡単に(第80回):Graph Transformer Generative Adversarial Model (GTGAN)

はじめに
環境の初期状態は、畳み込み層や様々なAttentionメカニズムを利用したモデルを用いて分析されることが多いです。しかし、畳み込みアーキテクチャは、固有の帰納バイアスにより、元データの長期的な依存関係を理解することができません。Attentionメカニズムに基づくアーキテクチャは、長期的または大域的な関係の符号化と、表現力の高い特徴量表現の学習を可能にします。一方、グラフ畳み込みモデルは、グラフのトポロジーに基づく局所的および近傍の頂点相関をうまく利用します。したがって、グラフ畳み込みネットワークとTransformerを組み合わせて、局所的および大域的な相互作用をモデル化し、最適な取引戦略の探索を実現することは理にかなっています。
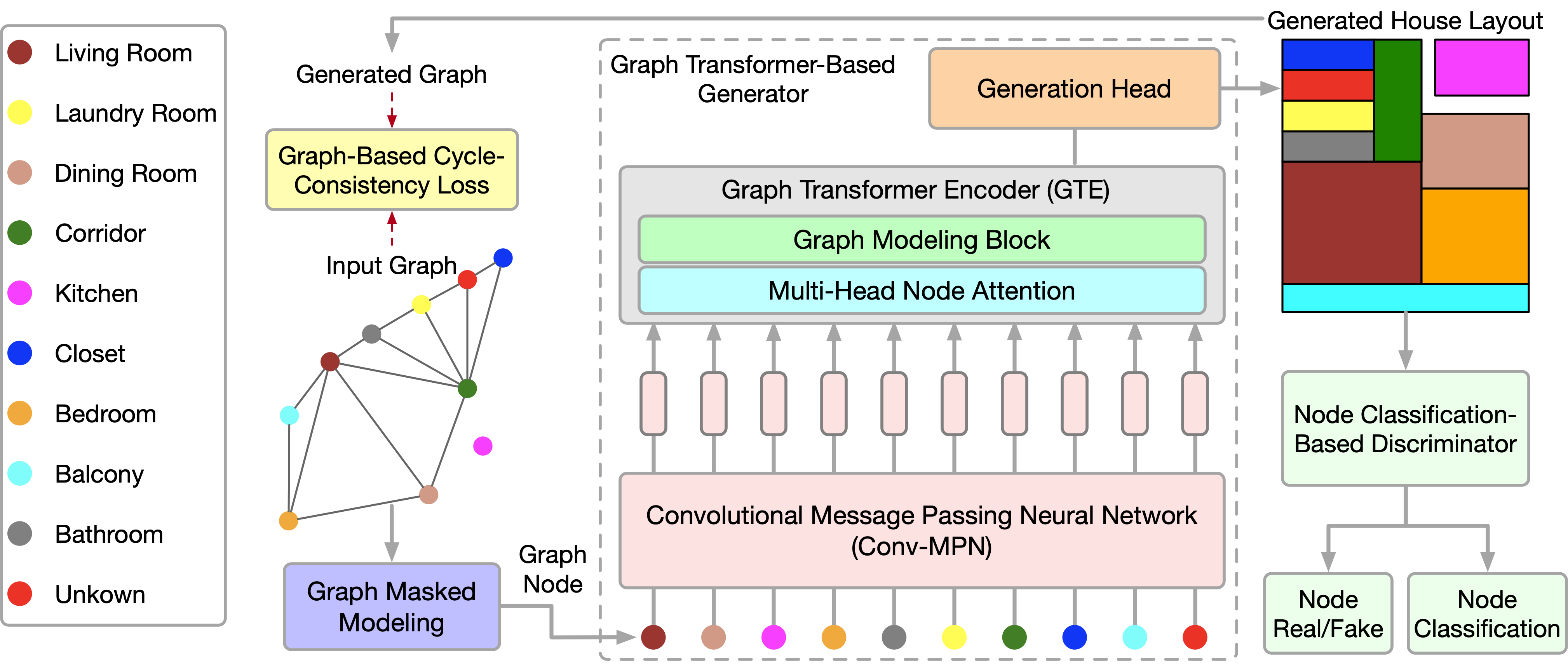
最近発表された論文「Graph Transformer GANs with Graph Masked Modeling for Architectural Layout Generation」では、graph transformer generative adversarial model (GTGAN)のアルゴリズムが紹介されており、この2つのアプローチが簡潔に組み合わされています。GTGANアルゴリズムの作者は、入力グラフから現実的な家の建築デザインを作成するという問題に取り組んでいます。彼らが提示した生成器モデルは、メッセージパッシング畳み込みニューラルネットワーク(message passing convolutional neural network: Conv-MPN)、グラフTransformerエンコーダ(Graph Transformer Encoder: GTE)、生成ヘッドの3つのコンポーネントから構成されています。
論文で紹介された3つのデータセットを用いて、3つの複雑なグラフ制約付きアーキテクチャレイアウト生成に関する定性的および定量的実験をおこなった結果、提案手法がこれまでに発表されたアルゴリズムよりも優れた結果を生成できることが実証されました。
1. GTGANアルゴリズム
この手法を説明するために、家のレイアウトを作ることを例にしてみましょう。生成器Gは、各部屋のノイズベクトルとバブルチャートを入力として受け取ります。そして、各部屋が軸に沿った長方形で表現された家のレイアウトを生成します。この手法の著者は、各バブルチャートをグラフとして表現し、各ノードが特定のタイプの部屋を表し、各辺が部屋の空間的隣接関係を表しています。具体的には、部屋ごとに長方形を生成します。グラフエッジを持つ2つの部屋は空間的に隣接し、グラフエッジを持たない2つの部屋は空間的に非隣接でなければなりません。
バブルダイアグラムが与えられたら、まず各部屋のノードを生成し、正規分布からサンプリングした128次元のノイズベクトルで初期化します。そして、そのノイズベクトルを10次元のルームタイプワンホットベクトル(tr)と組み合わせます。したがって、元のバブルダイアグラムを表す138次元のベクトルgrを得ることができます。
![]()
この場合、グラフノードは提案されたTranformerの入力データとして使用されます。
畳み込みメッセージパッシングブロックConv-MPNは、出力設計空間の3次元テンソルを表します。それらは一般的なラインレイヤーを適用して、grをサイズ16×8×8の特徴量ボリュームgr,l=1に拡張します。ここで、l=1は最初のConv-MPN層から抽出されたオブジェクトです。これは、転置畳み込みを使用して2回アップサンプリングされ、サイズ16x32x32のオブジェクトgr,l=3になります。
Conv-MPN層は、畳み込みメッセージを渡すことで特徴量グラフを更新します。具体的には、以下のステップでgr,l=1を更新します。
- GTEを1つ使用して、入力グラフでつながっている部屋間の長期相関を捕捉する
- 別のGTEを使用して、入力グラフの非連結の部屋間の長期的な依存関係を捉える
- これらは、入力グラフの接続された部屋間で関数を結合する
- 関連性のない部屋にまたがって関数を組み合わせる
- 結合された特徴量に対して畳み込みブロック(CNN)を適用する
このプロセスは次のように定式化できます。
![]()
ここで、N(r)はそれぞれ、連結している部屋と連結していない部屋の集合を表し、「+」と「;」はそれぞれ、ピクセル単位の加算とチャンネル単位の連結を表します。
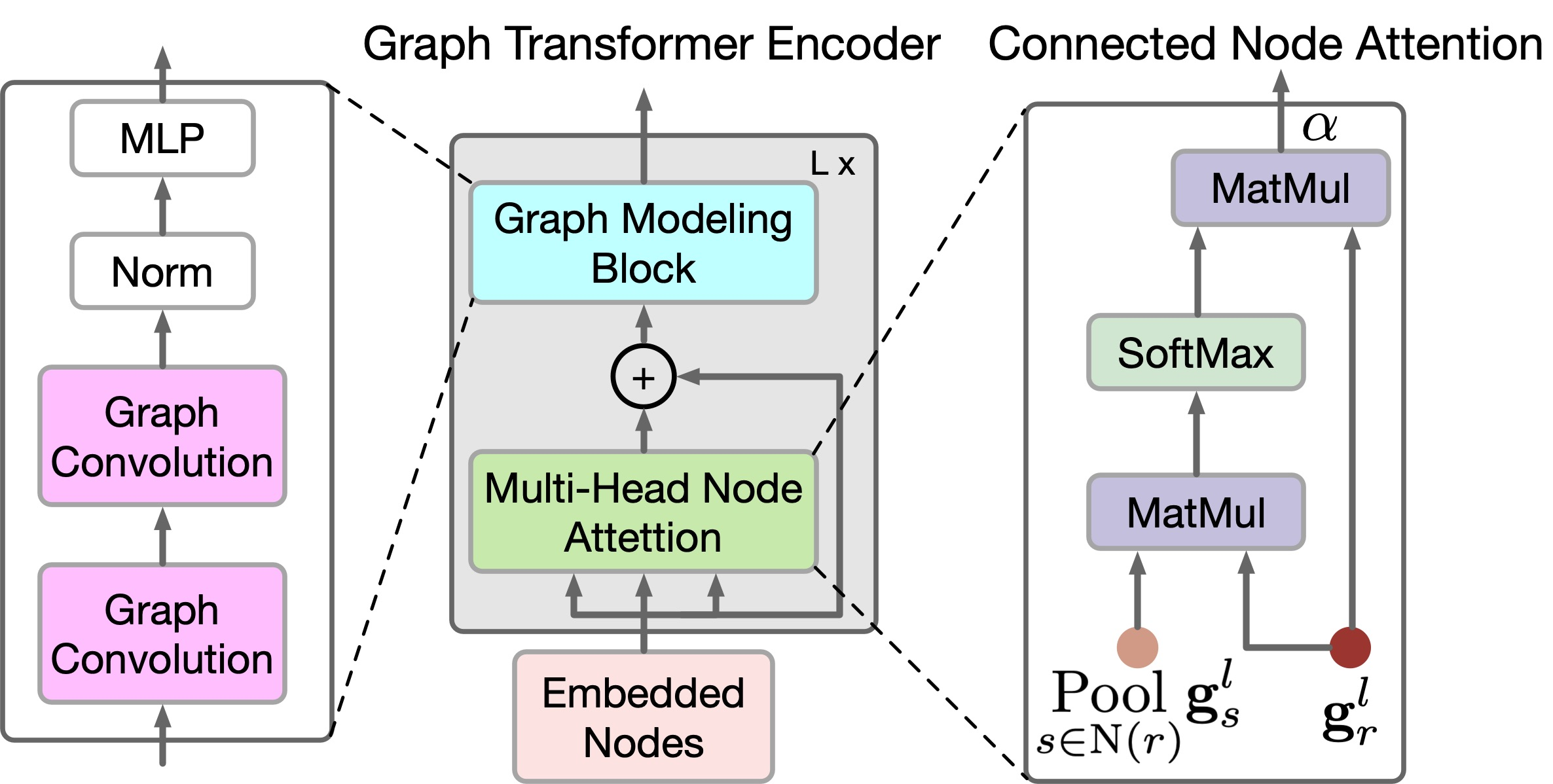
グラフノード間の局所的および大域的な関係を反映するために、この手法の著者は新しいGTEエンコーダを提案しています。GTEは、TransformerのSelf-Attentionとグラフ畳み込みモデルを組み合わせて、それぞれ大域的相関と局所的相関を捉えます。GTGANは位置埋め込みを使用しないことに注意してください。生成された家のレイアウトにおけるノードの位置を示すことがタスクの目的であるためです。
GTGANはMulti-Head Self-AttentionをMulti-HeadノードAttentionに拡張し、接続された部屋/ノード間の大域的相関と、接続されていない部屋/ノード間の大域的依存関係を捉えることを目的としています。この目的のために、この手法の著者は、2つの新しいグラフノードAttentionモジュール、すなわち、連結ノードAttention(Connected Node Attention: CNA)と非連結ノードAttention(Non-connected Node Attention: NNA)を提案しています。どちらのモジュールもネットワークアーキテクチャは同じです。
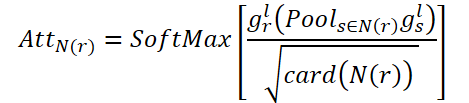
CNAの目的は、接続された部屋全体の大域的相関関係をモデル化することです。AttN(r)は、あるノードが他の連結ノードに与える影響を測定します。そして、転置されたAttN(r)による行列乗算gr,lをおこないます。その後、その結果にスケーリングパラメータɑを掛けます。
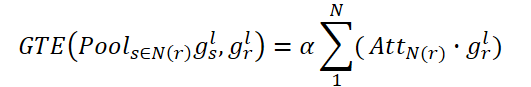
ここでɑは学習可能なパラメータです。
N(r)の各連結ノードは、すべての連結ノードの重み付きの和を表します。このように、CNAは空間グラフ構造の大域的ビューを取得し、接続されたAttentionマップに従って部屋を選択的に調整することができ、家のレイアウト表現と高レベルの意味的一貫性を向上させます。
同様に、NNAは非連結の部屋における大域的関係を捉えることを目的としています。学習可能なパラメータßを使用します。
最後に、gr,lを要素ごとに合計することで、更新されたノードの特徴が、連結と非連結の両方の空間関係を捉えることができます。
![]()
CNAとNNAは、長期的で大域的依存関係を抽出するのには有効ですが、複雑なホームデータ構造におけるきめ細かな局地的情報を把握するのにはあまり有効ではありません。この制限を解決するために、この手法の著者は新しいグラフモデリングブロックを提案しています。
具体的には、上式で生成された特徴量gr,lが与えられると、畳み込みグラフネットワークを用いて局所相関をさらに改善します。
![]()
ここで、Aはグラフの隣接行列、G.C. (•)はグラフの畳み込みを表し、Pは学習可能なパラメータを表します。σは線形ガウス誤差単位(GeLU)です。
大域的グラフ内のノードの関係に関する情報を提供することで、より正確な家のレイアウトを作成することができます。このプロセスを区別するために、この手法の著者は、グランドトゥルースと生成されたグラフの空間的関係に対応する隣接行列に基づく新しい損失関数を提案しています。正確には、グラフは異なる部屋の各ノード間の隣接関係をキャプチャし、提案されたループ一貫性損失関数を通して、グランドトゥルースと生成されたグラフの間の対応関係を保証します。この損失関数は、ノード間の相互関係を正確に維持することを目的としています。一方では、重ならない部分は重ならないものとして予測されなければなりません。一方、隣接ノードは近傍ノードとして予測され、近接係数に対応しなければなりません。
以下に著者によるGTGANの可視化を示します。
2. MQL5を使用した実装
GTGAN法の理論的側面について考察した後は、本稿の実践的な部分に移り、MQL5を用いて提案されたアプローチを実装します。
ただし、本手法の著者が解決した問題と、私たちが解決した問題の違いに注意してください。私たちの目的は、値動きチャートを作成することではありません。私エージェントに最適な行動戦略を見つけることです。モデルの出力では、環境の特定の状態におけるエージェントの最適な行動を求めます。一見したところ、私たちの仕事は根本的に異なっています。
しかし、GTGAN法を詳しく見てみると、手法の作者が主にエンコーダ(GTE)に焦点を当てていることがわかります。彼らはエンコーダのアーキテクチャとその訓練の両方に注意を払っています。
この手法の著者は、ノードと連結の両方をランダムにマスキングして、エンコーダの予備訓練をおこなうことを提案しています。彼らは、各ノードとエッジが隣接する接続に潜在的なギャップを残したまま、元のデータの最大40%をマスクすることを提案しています。欠落したデータを復元するために、各ノードとエッジ埋め込みは、その局地的コンテキストを消費し、解釈しなければなりません。つまり、それぞれの投資は、その身近な環境の具体的な詳細を理解しなければなりません。高比ランダムマスキングとそれに続く再構成という提案されたアプローチは、予測に使用される部分グラフのサイズと形状によって課される制限を克服しています。その結果、ノードとエッジの埋め込みは、局所的なコンテキストの詳細を理解することが奨励されます。
さらに、係数の高いノードやエッジが取り除かれた場合、残ったノードやエッジは、グラフ全体を予測することを任務とする部分グラフの集合とみなすことができます。これは、他の自己訓練タスクと比較して、より複雑なグラフ単位の予測タスクであり、通常、予測ターゲットとしてより小さなグラフやコンテキストを使用して、大域的グラフの詳細をキャプチャします。マスキングとグラフ再構成という「集中的な」事前学習タスクは、個々のノード/エッジのレベルでも、グラフ全体のレベルでも、複雑な詳細を捉えることができる優れたノードエッジ埋め込みを学習するための、より広い視点を提供します。
提案システムのエンコーダはブリッジの役割を果たし、可視でマスクされていないノードとエッジの元の属性を、潜在特徴空間における対応する埋め込みに変換します。このプロセスには、提案されたグラフモデリングブロックとマルチヘッドノードAttentionメカニズムを含む、エンコーダのノードとエッジの側面が含まれます。これらの関数は、逐次データを効率的にモデル化する技術として知られるTransformerアーキテクチャの精神に基づいて設計されています。このブロックは、グラフ内の関係の全体的なダイナミクスをカプセル化するロバストな表現を作成するのに役立ちます。
その結果、提案されたエンコーダを使用して、ソースデータの局地的および大域的依存関係を調べることができます。提案するエンコーダアルゴリズムをCNeuronGTEという新しいクラスに実装します。
2.1 GTE エンコーダクラス
GTEエンコーダクラスCNeuronGTEは、ニューラル層ベースクラスCNeuronBaseOCLを継承します。提案されているエンコーダの構造は、これまで検討されてきたTransformerのオプションとは大きく異なっています。そのため、Attentionメカニズムを利用したニューラル層は過去に数多く作られているにもかかわらず、そのうちの1つを継承することを拒否することにしました。作業の過程ではありますが、以前に作成したものを使用します。
新しいクラスの構造体を以下に示します。
class CNeuronGTE : public CNeuronBaseOCL { protected: uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CNeuronConvOCL cQKV; CNeuronSoftMaxOCL cSoftMax; int ScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cW0; CNeuronBaseOCL cAttentionOut; CNeuronCGConvOCL cGraphConv[2]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionInsideGradients(void); public: CNeuronGTE(void) {}; ~CNeuronGTE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronGTE; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
ここにはすでにおなじみのローカル変数があります。
- iHeads
- iWindow
- iUnits
- iWindowKey
機能的な目的は変わりません。メソッドを実装しながら、内部層の目的を理解していきます。
すべての内部オブジェクトを静的に宣言したので、クラスのコンストラクタとデストラクタを空にしておくことができます。クラスコンストラクタでは、ローカル変数の値さえ指定していないことに注意してください。
いつものように、クラスの完全な初期化はInitメソッドでおこなわれます。このメソッドのパラメータには、正しいクラスアーキテクチャを作成するために必要なすべての情報が含まれています。メソッド本体では、親クラスの関連メソッドを呼び出します。このメソッドは、受け取った初期パラメータの必要最小限の制御と、継承されたオブジェクトの初期化を実装しています。
bool CNeuronGTE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
親クラスのメソッドが成功したら、受け取ったデータをローカル変数に保存します。
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); activation = None;
その後、追加したオブジェクトを初期化します。まず、内側の畳み込み層cQKVを初期化します。この層では、3つのエンティティ(Query、Key、Value) の表現をすべて並列スレッドで生成する予定です。ソースデータウィンドウとそのステップのサイズは、1つのシーケンス要素の記述サイズに等しくなります。畳み込みフィルタの数は、シーケンスの1要素の1エンティティの記述ベクトルのサイズにAttentionヘッドの数を掛け、3(エンティティの数)を掛けた積に等しくなります。要素数は解析された配列のサイズに等しくなります。
if(!cQKV.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * 3 * iHeads, iUnits, optimization, iBatch)) return false;
ブロックの安定性を高めるために、SoftMax層を使用して生成されたエンティティを正規化します。
if(!cSoftMax.Init(0, 1, OpenCL, iWindowKey * 3 * iHeads * iUnits, optimization, iBatch)) return false; cSoftMax.SetHeads(3 * iHeads * iUnits);
次のステップは、OpenCLコンテキストに依存係数バッファを作成することです。大きさは通常の2倍です。これは、連結した頂点と連結していない頂点の係数を別々に記録するためです。
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits * 2 * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Multi-Head Attentionの結果は、ローカル層cMHAttentionOutに保存します。
if(!cMHAttentionOut.Init(0, 2, OpenCL, iWindowKey * 2 * iHeads * iUnits, optimization, iBatch)) return false;
Multi-Head Attention結果の層のサイズも、先に検討したTransformerの実装の同様の層より2倍大きいことに注意してください。これもまた、連結した頂点と連結していない頂点の両方からデータを書き込めるようにするためです。
さらに、このアプローチでは、スケーリングパラメータɑと ßを訓練するための別の機能を実装する必要はありません。その代わりに、W0層の機能を使用します。この場合、Attentionヘッドと、接続されている頂点と接続されていない頂点の影響が組み合わされます。
if(!cW0.Init(0, 3, OpenCL, 2 * iWindowKey * iHeads, 2 * iWindowKey* iHeads, iWindow, iUnits, optimization, iBatch)) return false;
Attentionブロックの後、元のデータと結果を加え、結果を正規化する必要があります。結果の値はcAttentionOut層に書き込まれる。
if(!cAttentionOut.Init(0, 4, OpenCL, iWindow * iUnits, optimization, iBatch)) return false;
次に、2層ずつのブロックが2つ来る。これには、グラフ畳み込みとフィードフォワードのブロックが含まれる。ループの中で指定されたブロックのオブジェクトを初期化します。
for(int i = 0; i < 2; i++) { if(!cGraphConv[i].Init(0, 5 + i, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cFF[i].Init(0, 7 + i, OpenCL, (i == 0 ? iWindow : 4 * iWindow), (i == 0 ? iWindow : 4 * iWindow), (i == 1 ? iWindow : 4 * iWindow), iUnits, optimization, iBatch)) return false; }
最後に、エラーグラデーションバッファを置き換えてみましょう。
if(cFF[1].getGradient() != Gradient) { if(!!Gradient) delete Gradient; Gradient = cFF[1].getGradient(); } //--- return true; }
これでメソッドは終了。
クラスを初期化した後、クラスのフィードフォワードパスのアルゴリズムを整理します。ここでは、新しいカーネルGTEFeedForwardを作成するOpenCLプログラムから始めます。このカーネルの中で、連結ノードと非連結ノードの依存関係を分析します。GTGAN法では、GTEFeedForwardカーネル本体に、CNAとNNAの機能を実装しています。
しかし、実装に移る前に、どのノードを連結とみなし、どのノードを非連結とみなすかを決めておきましょう。最初に知っておかなければならないのは、この実装のノードは1つのバーのパラメータを記述したものだということです。ここでは時系列分析を扱っています。したがって、隣接する2本のバーを直接つなぐことはできません。したがって、バーXtについては、バーXt-1とXt+1だけがつながっています。バーXt-1とXt+1は、その間にバーXtがあるのでつながっていません。
これで、実施に移ることができます。パラメータでは、カーネルはデータ交換バッファへのポインタを受け取ります。
__kernel void GTEFeedForward(__global float *qkv, __global float *score, __global float *out, int dimension) { const size_t cur_q = get_global_id(0); const size_t units_q = get_global_size(0); const size_t cur_k = get_local_id(1); const size_t units_k = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
カーネル本体では、タスク空間でスレッドを識別します。この場合、私たちは3次元のタスク空間を扱っており、そのうちの1つはローカルグループにまとめられています。
次のステップは、データバッファ内の混合物を決定することです。
int shift_q = dimension * (cur_q + h * units_q); int shift_k = (cur_k + h * units_k + heads * units_q); int shift_v = dimension * (h * units_k + heads * (units_q + units_k)); int shift_score_con = units_k * (cur_q * 2 * heads + h) + cur_k; int shift_score_notcon = units_k * (cur_q * 2 * heads + heads + h) + cur_k; int shift_out_con = dimension * (cur_q + h * units_q); int shift_out_notcon = dimension * (cur_q + units_q * (h + heads));
ここでは2次元のローカル配列を宣言します。2次元目は、連結ノードと非連結ノードに対して2つの要素を持ちます。
const uint ls_score = min((uint)units_k, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE][2];
次のステップは、依存係数の決定です。まず、対応するQueryテンソルとKeyテンソルを掛け合わせます。それを次元のルートで割り、指数値を取ます。
//--- Score float scr = 0; for(int d = 0; d < dimension; d ++) scr += qkv[shift_q + d] * qkv[shift_k + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f));
次に、解析された配列要素がつながっているかどうかを判断し、その結果を必要なバッファ要素に保存します。
if(cur_q == cur_k) { score[shift_score_con] = scr; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = scr; } } else { if(abs(cur_q - cur_k) == 1) { score[shift_score_con] = scr; score[shift_score_notcon] = 0; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = 0; } } else { score[shift_score_con] = 0; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = 0; local_score[cur_k][1] = scr; } } } barrier(CLK_LOCAL_MEM_FENCE);
ここで、数列の各要素の係数の和を求めることができます。
for(int k = ls_score; k < units_k; k += ls_score) { if((cur_k + k) < units_k) { local_score[cur_k][0] += score[shift_score_con + k]; local_score[cur_k][1] += score[shift_score_notcon + k]; } } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(cur_k < count) { if((cur_k + count) < units_k) { local_score[cur_k][0] += local_score[cur_k + count][0]; local_score[cur_k][1] += local_score[cur_k + count][1]; local_score[cur_k + count][0] = 0; local_score[cur_k + count][1] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); barrier(CLK_LOCAL_MEM_FENCE);
次に、数列の各要素について、依存係数の和を1にします。これをおこなうには、単純に各要素の値を対応する合計で割ります。
score[shift_score_con] /= local_score[0][0]; score[shift_score_notcon] /= local_score[0][1]; barrier(CLK_LOCAL_MEM_FENCE);
依存係数が見つかれば、連結ノードと非連結ノードの影響を判断することができます。
shift_score_con -= cur_k; shift_score_notcon -= cur_k; for(int d = 0; d < dimension; d += ls_score) { if((cur_k + d) < dimension) { float sum_con = 0; float sum_notcon = 0; for(int v = 0; v < units_k; v++) { sum_con += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_con + v]; sum_notcon += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_notcon + v]; } out[shift_out_con + cur_k + d] = sum_con; out[shift_out_notcon + cur_k + d] = sum_notcon; } } }
すべての反復を成功させたら、カーネル操作を完了し、メインプログラムの作業に戻ります。ここではまず、上で作成したカーネルを呼び出すためのAttentionOutメソッドを作成します。これは、同じクラスの別のメソッドから呼び出されるメソッドです。内部オブジェクトに対してのみ機能し、パラメータは含みません。
メソッド本体では、まず、OpenCLコンテキストで動作するクラスオブジェクトへのポインタの妥当性をチェックします。
bool CNeuronGTE::AttentionOut(void) { if(!OpenCL) return false;
そして、タスクスペースと作業グループのサイズを決定します。この場合、3次元のタスク空間を1次元の作業グループにグループ分けして使用します。
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits, 1};
そして必要なパラメータをカーネルに渡します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_qkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_GTEFeedForward, def_k_gteff_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_GTEFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
各ステップで操作を制御することを忘れないでください。そしてメソッドが完了したら、メソッドの結果を論理値として返します。これにより、呼び出しプログラム内のプロセスを制御できるようになります。
準備作業を終えたら、CNeuro.nGTE::feedForwardクラスのトップレベルのフィードフォワードパスメソッドを作成します。このメソッドのパラメータには、先に説明した他のクラスの関連メソッドと同様に、前の層のオブジェクトへのポインタを受け取ります。そのバッファには、メソッド操作の初期データが含まれています。
bool CNeuronGTE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.FeedForward(NeuronOCL)) return false;
しかし、メソッド本体では、受け取ったポインタの関連性は確認せず、Query、Key、Valueの各エンティティを形成するオブジェクトに対して、類似のフィードフォワードメソッドを即座に呼び出します。必要なすべての制御は、呼び出されたメソッドの本体にすでに実装されています。呼び出されたメソッドの結果によって判断できるエンティティの形成が成功した後、受信したデータをSoftMax層で正規化します。
if(!cSoftMax.FeedForward(GetPointer(cQKV))) return false;
次に、上記で作成したAttentionOutメソッドを用いて、接続されている頂点と接続されていない頂点の影響力を決定します。
if(!AttentionOut()) return false;
Multi-Head Attentionの結果の次元を、元データのテンソルの値に縮小します。
if(!cW0.FeedForward(GetPointer(cMHAttentionOut))) return false;
その後、データを追加して正規化します。
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), iWindow, true)) return false;
この段階でMulti-Head Attentionブロックを完了し、グラフ畳み込みブロックGCに進みます。ここでは2層のCrystalGraph Convolutional Networkを使用しています。機能を実装するには、それらのダイレクトパスメソッドを順次呼び出すだけです。
if(!cGraphConv[0].FeedForward(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].FeedForward(GetPointer(cGraphConv[0]))) return false;
次はFeedForwardブロックです。
if(!cFF[0].FeedForward(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].FeedForward(GetPointer(cFF[0]))) return false;
そしてメソッドの最後に、もう一度結果を加算して正規化します。
if(!SumAndNormilize(cAttentionOut.getOutput(), cFF[1].getOutput(), Output, iWindow, true)) return false; //--- return true; }
フィードフォワードパスを実装した後、バックプロパゲーションプロセスの整理に移ります。ここでも、OpenCLプログラム側で新しいカーネルGTEInsideGradientsを作成することから始めます。パラメータで、カーネルは操作に必要なデータバッファへのポインタを受け取ります。タスクスペースからすべての寸法を得ます。
__kernel void GTEInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
フィードフォワードパスカーネルと同様に、このカーネルを3次元タスク空間で実行します。ただし、今回はワーキンググループは編成しません。カーネル本体では、すべての次元のタスク空間で現在のスレッドを識別します。
カーネルのアルゴリズムは3つのブロックに分けられます。
- 価値勾配
- クエリ勾配
- キー勾配
バックプロパゲーションパスは、フィードフォワードパスとは逆の順序で整理します。そこでまず、Valueエンティティの誤差勾配を定義します。このブロックでは、まずデータバッファのオフセットを決定します。
//--- Calculating Value's gradients { int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units + u) + d;
次に、連結ノードと非連結ノードの誤差勾配を収集するサイクルを編成します。結果は、エンティティ誤差勾配のグローバルバッファqkv_gの対応する要素に保存されます。
float sum = 0; for(uint i = 0; i <= units; i ++) { sum += gradient[shift_out_con + i * dimension] * scores[shift_score_con + i * step_score]; sum += gradient[shift_out_notcon + i * dimension] * scores[shift_score_notcon + i * step_score]; } qkv_g[shift_v] = sum; }
第2ステップでは、Queryエンティティの誤差勾配を計算します。最初のブロックと同様に、まずデータバッファのオフセットを計算します。
//--- Calculating Query's gradients { int shift_q = dimension * (u + h * units) + d; int shift_out_con = dimension * (h * units + u) + d; int shift_out_notcon = dimension * (u + units * (h + heads)) + d; int shift_score_con = units * h; int shift_score_notcon = units * (heads + h); int shift_v = dimension * (h * units + 2 * heads * units);
しかし、誤差勾配の計算は少し複雑になります。まず、依存係数行列のレベルで誤差勾配を決定し、その微分をSoftMax関数で調整する必要があります。そうして初めて、誤差の勾配を目的のエンティティのレベルに移すことができます。そのためには、入れ子ループのシステムを作る必要があります。
float grad = 0; for(int k = 0; k < units; k++) { int shift_k = (k + h * units + heads * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + k]; float sc_notcon = scores[shift_score_notcon + k]; for(int v = 0; v < units; v++) for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_con + dim] * ((float)(k == v) - sc_con); sc_g += scores[shift_score_notcon + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_notcon + dim] * ((float)(k == v) - sc_notcon); } grad += sc_g * qkv[shift_k]; }
ループシステムの全反復が完了したら、全誤差勾配をグローバルデータバッファの適切な要素に転送します。
qkv_g[shift_q] = grad; }
カーネルの最後のブロックでは、Keyエンティティの誤差勾配を定義します。この場合、前のブロックと同様のアルゴリズムを作成します。しかし、この場合、別の次元の依存係数行列から誤差勾配を取ります。
//--- Calculating Key's gradients { int shift_k = (u + (h + heads) * units) + d; int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units); float grad = 0; for(int q = 0; q < units; q++) { int shift_q = dimension * (q + h * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + u + q * step_score]; float sc_notcon = scores[shift_score_notcon + u + q * step_score]; for(int g = 0; g < units; g++) { for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_con + g * dimension + dim] * ((float)(u == g) - sc_con); sc_g += scores[shift_score_notcon + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_notcon + g * dimension+ dim] * ((float)(u == g) - sc_notcon); } } grad += sc_g * qkv[shift_q]; } qkv_g[shift_k] = grad; } }
説明したカーネルを呼び出すために、CNeuronGTE::AttentionInsideGradientsメソッドを作成します。その構築アルゴリズムは、CNeuronGTE::AttentionOutメソッドに似ています。従って、今は詳しく検討しません。添付ファイルに、この記事で使用したすべてのプログラムの完全なコードがありますので、そちらで勉強されることをお勧めします。
誤差勾配分布の全プロセスは、CNeuronGTE::calcInputGradientsメソッドに記述されています。このメソッドは、パラメータで、誤差勾配を渡す前のニューラル層のオブジェクトへのポインタを受け取ります。
bool CNeuronGTE::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false;
データバッファを置き換えることで、後続のニューラル層のバックプロパゲーションメソッドに取り組む際に、誤差勾配をフィードフォワードブロックの最終層のバッファに直接受け取ることができます。そのため、過度にデータをコピーする必要はありません。バックプロパゲーションメソッドでは、FeedForwardブロックの層を通して誤差勾配を伝搬することからすぐに始めます。
if(!cFF[0].calcInputGradients(GetPointer(cGraphConv[1]))) return false;
その後、同様にグラフ畳み込みブロックを通して誤差勾配を伝播させます。
if(!cGraphConv[1].calcInputGradients(GetPointer(cGraphConv[0]))) return false; if(!cGraphConv[1].calcInputGradients(GetPointer(cAttentionOut))) return false;
このステップでは、2つのスレッドからの誤差勾配を組み合わせます。
if(!SumAndNormilize(cAttentionOut.getGradient(), Gradient, cW0.getGradient(), iWindow, false)) return false;
次に、Attentionヘッドに誤差勾配を分布させます。
if(!cW0.calcInputGradients(GetPointer(cMHAttentionOut))) return false;
そして、Attentionブロックを通じてそれを伝播させます。
if(!AttentionInsideGradients()) return false;
3つのエンティティ(Query、Key、Value)の誤差勾配は、1つの連結バッファに含まれるため、すべてのエンティティを一度に並列処理できます。まず、データを正規化するために使用したSoftMax関数の微分によって誤差勾配を調整します。
if(!cSoftMax.calcInputGradients(GetPointer(cQKV))) return false;
次に、誤差勾配を前の層のレベルに伝播させます。
if(!cQKV.calcInputGradients(prevLayer)) return false;
ここでは、2つ目のデータストリームから誤差勾配を加えるだけです。
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
メソッドを完成させます。
誤差勾配を分布させた後すべきことは、誤差を最小化するようにモデルパラメータを更新することです。このクラスの学習可能なパラメータはすべて内部オブジェクトに含まれています。したがって、パラメータを調整するためには、内部オブジェクトの対応するメソッドを順次呼び出すことになります。
bool CNeuronGTE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cMHAttentionOut))) return false; if(!cGraphConv[0].UpdateInputWeights(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].UpdateInputWeights(GetPointer(cGraphConv[0]))) return false; if(!cFF[0].UpdateInputWeights(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].UpdateInputWeights(GetPointer(cFF[0]))) return false; //--- return true; }
これで、新しいCNeuronGTEクラスのメソッドの説明は終わりです。ファイル操作メソッドを含むすべてのクラスサービスメソッドは、添付ファイルで見ることができます。いつものように、添付ファイルには記事作成に使用したすべてのプログラムの完全なコードが含まれています。
2.2 モデルアーキテクチャ
新しいクラスを作ったら、モデルの作成に移ります。そのアーキテクチャを作り、訓練します。GTGAN法によれば、エンコーダの事前学習が必要です。そこで、モデルアーキテクチャの記述を作成するための2つのメソッドを作成します。最初のメソッドCreateEncoderDescriptionsでは、事前学習のみに使用するエンコーダアーキテクチャとエンコーダアーキテクチャの記述を作成します。
bool CreateEncoderDescriptions(CArrayObj *encoder, CArrayObj *decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
エンコーダに1本のローソク足の説明を与えます。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
得られたデータは、バッチ正規化層を使用して正規化します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
その後、最後のバーの埋め込みを作成し、スタックに追加します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
ここで注意すべきなのは、埋め込みを1層でおこなっていた従来の研究とは異なり、Conv-MPNメッセージ伝送ブロックに関するGTGAN法作者からの提案を参考に、埋め込みを2段階に分けて作成したことです。そのため、埋め込み層の後に別の畳み込み層が続き、状態埋め込みを生成する作業が完了します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
次に、事前学習段階で、表現学習中のデータをマスクするためにDropOut層を追加します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count*prev_wout; descr.probability= 0.4f; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
次のステップでは、提案アルゴリズムから少し逸脱し、位置符号化を追加します。これは、割り当てられた仕事に大きな違いがあるためです。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
この後、新しいエンコーダをループで8層追加します。
//--- layer 6 - 14 for(int i = 0; i < 8; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronGTE; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!encoder.Add(descr)) { delete descr; return false; } }
デコーダアーキテクチャは大幅に短くなります。エンコーダの結果をモデルの入力に送ります。
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count * prev_wout; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
それらを畳み込み層に通してみましょう。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count=prev_count; descr.window = prev_wout; descr.step=prev_wout; descr.window_out=EmbeddingSize/4; descr.optimization = ADAM; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
SoftMaxを使用して正規化します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
デコーダの出力には、埋め込み層の結果と同じ要素数の全結合層を作成します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*EmbeddingSize/2; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
その結果、モデルから非対称オートエンコーダをコンパイルし、埋め込み層のスタックでデータを復元するように訓練しました。埋め込み層の潜伏状態の選択は意図的におこなわました。訓練プロセスでは、エンコーダの注意を最後のローソク足だけでなく、履歴データのフルセットに集中させたいと思います。
CreateDescriptionsメソッドで、ActorとCriticのアーキテクチャを説明しましょう。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Actorの建築には、ちょっとした実験精神も加えることにしました。このモデルには、口座の現在の状態を入力します。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
全結合層は、結果として得られる状態のある種の埋め込みを作成してくれます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、3つのCross-Attention層のブロックを追加します。この層では、口座の現在の状態と環境の状態の依存関係を評価します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
得られた結果は2つの全結合層で処理されます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Actorの出力で、確率的政策を生成します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticのモデルは、前作からほぼそのままコピーされています。エンコーダ操作の結果をモデルの入力に送ります。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = GPTBars*EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
受信したデータにActorのアクションを追加します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type=defNeuronConcatenate; descr.window=prev_count; descr.step = NActions; descr.count=LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
そして、2つの全結合層から意思決定ブロックを構成します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 表現学習アドバイザー
モデルアーキテクチャを作成した後、それを訓練するためのEAの構築に移ります。まず、Representation pre-training EA「...\Experts\GTGAN\StudyEncoder.mq5」を作成します。EAの構成は過去の作品からほぼコピーしています。また、記事を短くするため、ここではモデルの訓練メソッドTrainのみに焦点を当てることにします。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
メソッドの本体では、まず、経験再生バッファからパスを選択する確率のベクトルを、そのパフォーマンスに基づいて生成します。
次にローカル変数を宣言します。
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
そして、モデルの訓練ループのシステムを組織します。外側ループの本体では、軌跡とその軌跡の学習の初期状態をサンプリングします。
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - batch)); if(state <= 0) { iter--; continue; }
エンコーダバッファをクリアし、訓練パッケージの最終状態を決定します。
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total);
準備作業が完了したら、モデルの直接訓練の入れ子ループを組織します。
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
ここでは、経験再生バッファから環境の現在の状態の説明をロードし、エンコーダのフィードフォワードメソッドを呼び出します。
//--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
続いてデコーダのフィードフォワードパスが続きます。
if(!Decoder.feedForward((CNet*)GetPointer(Encoder),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
フィードフォワードパスの後、モデルの訓練ターゲットを定義する必要があります。元のデータを復元するために、オートエンコーダの自己学習がおこなわれます。先に説明したように、ビューモデルの訓練では、埋め込み層の隠れた状態を使用します。このデータをローカルバッファに読み込んでみましょう。
Encoder.GetLayerOutput(LatentLayer,Result);
そして、それをモデルのパラメータを最適化するための目標値として渡します。
if(!Decoder.backProp(Result,(CBufferFloat*)NULL) || !Encoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
あとは、学習プロセスの進捗状況をユーザーに知らせ、ループシステムの次の反復に進むだけです。
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
モデルの訓練が成功したら、チャートのコメント欄を消去します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); ExpertRemove(); //--- }
訓練結果をログに印刷し、EA作業を終了するプロセスを開始します。
この段階で、過去の研究による訓練データセットを使用し、表現モデルの訓練プロセスを開始することができます。モデルを訓練している間に、Actor方策訓練EAの作成に移ります。
2.4 Actor方策訓練EA
Actorの行動方策を学習するために、EA「...\Experts\GTGAN\Study.mq5」を作成します。ここで注意しなければならないのは、訓練の過程で3つのモデルを使用し、2つ(ActorとCritic)だけを訓練するということです。エンコーダモデルは前のステップで訓練されました。
CNet Encoder; CNet Actor; CNet Critic;
EAの初期化メソッドでは、まず例のアーカイブをアップロードします。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
次に、事前に訓練されたモデルを読み込んでみます。この場合、事前に訓練されたエンコーダを読み込む際のエラーは、プログラムの動作にとって致命的ですが、
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Can't load pretrained Encoder"); return INIT_FAILED; }
ActorやCriticの読み込みにエラーがあった場合は、ランダムなパラメータで初期化された新しいモデルを作成します。
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor) || !Critic.Create(critic)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
すべてのモデルを1つのOpenCLコンテキストに転送します。
OpenCL = Encoder.GetOpenCL(); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
必ずエンコーダ訓練モードをオフにしてください。
Encoder.TrainMode(false);
そのアーキテクチャは、データをランダムにマスクするDropOut層を使用しています。モデルを操作する間、マスキングを無効にする必要がありますが、これはモデルの訓練モードを無効にすることでおこないます。
次に、モデルアーキテクチャの必要最小限の制御を実装します。
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
補助データバッファを初期化します。
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
そして、モデルの訓練を開始するためのイベントを生成します。
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
モデルを訓練するプロセスは、通常通りTrainメソッドで構成されます。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
メソッドの本体では、前のEAと同様に、まず、経験再生バッファから軌道を選択するための確率のベクトルを、その収益性に基づいて生成します。ローカル変数の初期化もおこないます。そして、モデルの訓練ループのシステムを組織します。
外側ループの本体では、経験再生バッファと学習プロセスの開始状態から軌跡をサンプリングします。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand()*MathRand() / MathPow(32767, 2))*(Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
エンコーダスタックをクリアし、訓練パッケージの最後の状態を決定します。
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
準備作業が完了したら、モデルの直接訓練の入れ子ループを組織します。
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
入れ子ループの本体では、口座の分析された状態の記述を経験再生バッファから読み込み、エンコーダを直接通過するように実装します。
次に、Actorのフィードフォワードパスを実装するために、経験再生バッファから口座状態の説明を読み込む必要があります。
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
ここでは、現在の状態のタイムスタンプを追加します。
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
次に、フィードフォワードのActorパスを実行します。
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount),1,false,GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Criticのフィードフォワード
//--- Critic if(!Critic.feedForward((CNet *)GetPointer(Encoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
経験再生バッファから両モデルの目標値を取り出します。まず、Actorに対してバックプロパゲーションをおこないます。
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
その後、Criticのリバースパスを実行し、誤差勾配をActorに転送します。
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
どちらの場合も、エンコーダのパラメータは更新しません。
両方のモデルの後方パスが正常に完了すると、訓練の進捗状況をユーザーに通知し、ループシステムの次の反復に移ります。
//--- if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
訓練が完了したら、チャートのコメント欄を消去します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
訓練結果をログに表示し、EAを終了するプロセスを開始します。
これで、モデル訓練プログラムについてのトピックを終えます。環境相互作用プログラムは、前回の記事からコピーし、最小限の調整を加えたものです。この記事で使用されているすべてのプログラムの完全なコードについては、添付ファイルをご覧ください。
3. 検証
この記事の前のセクションでは、新しいGTGAN法を知り、MQL5を使用して提案されたアプローチを実装するために多くの作業をおこないました。この部分では、いつものようにMetaTrader 5のストラテジーテスターで、実際のデータを使用してテストし、得られた結果を評価します。モデルはEURUSD H1の履歴データを使用して訓練およびテストされます。これには、2023年の最初の7ヶ月間の過去データによるモデル訓練が含まれます。訓練の後、2023年8月からのデータでテストがおこなわれます。
この記事で作成したモデルは、以前の記事で紹介したモデルと同様に、ソースデータを使用して動作します。Actorのアクションのベクトルと、新しい状態への遷移が完了したときの報酬も、前回の記事と同じです。そのため、モデルの訓練には、過去の記事からモデルの訓練過程で収集された経験再生バッファを使用することができます。ファイル名をGTGAN.bdに変更するだけです。
モデルは2段階で学習されます。まず、エンコーダ(表現モデル)を訓練します。そして、Actorの行動方策を訓練します。学習プロセスを2段階に分けることは、プラスに働くと言わなければなりません。モデルたちの訓練は非常に速く、安定しています。
学習結果から、モデルは経験再生バッファからの行動方針を素早く汎化し、遵守することを学習したと言えます。残念ながら、私の経験再生バッファにはポジティブなパスは少なかったです。そのため、モデルは訓練サンプルの平均に近い方策を学習しましたが、残念ながら良い結果は得られませんでした。プラスのパスでモデルを訓練してみる価値はあると思います。
結論
この記事では、複雑なアーキテクチャ問題を解決するために2024年1月に発表されたGTGANアルゴリズムについて説明しました。ここでの目的のために、エンコーダGTEにおける現状を包括的に分析したアプローチを借りようとしました。このアプローチは、Attention法と畳み込みグラフモデルの利点を簡潔に組み合わせたものです。
この記事の実践的な部分では、MQL5を使用して提案されたアプローチを実装し、MetaTrader 5のストラテジーテスターで実際のデータを使用して結果のモデルをテストしました。
テスト結果は、提案されたアプローチに関して追加作業が必要であることを示唆しています。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | 表現モデル学習EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14445
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索