
Нейросети — это просто (Часть 80): Генеративно-состязательная модель Трансформера графов (GTGAN)

Введение
Для анализа исходного состояния окружающей среды чаще всего применяются модели, использующие сверточные слои или различные механизмы внимания. Однако сверточным архитектурам не хватает понимания долгосрочных зависимостей в исходных данных, поскольку существуют присущие им индуктивные смещения. Архитектуры на основе механизмов внимания позволяют кодировать долгосрочные или глобальные отношения и изучать весьма выразительные представления функций. С другой стороны, модели свертки графов хорошо используют корреляции локальных и соседних вершин на основе топологии графа. поэтому, имеет смысл объединить сети свертки графов и Трансформеры для моделирования локальных и глобальных взаимодействий для решения поиска оптимальных торговых стратегий.
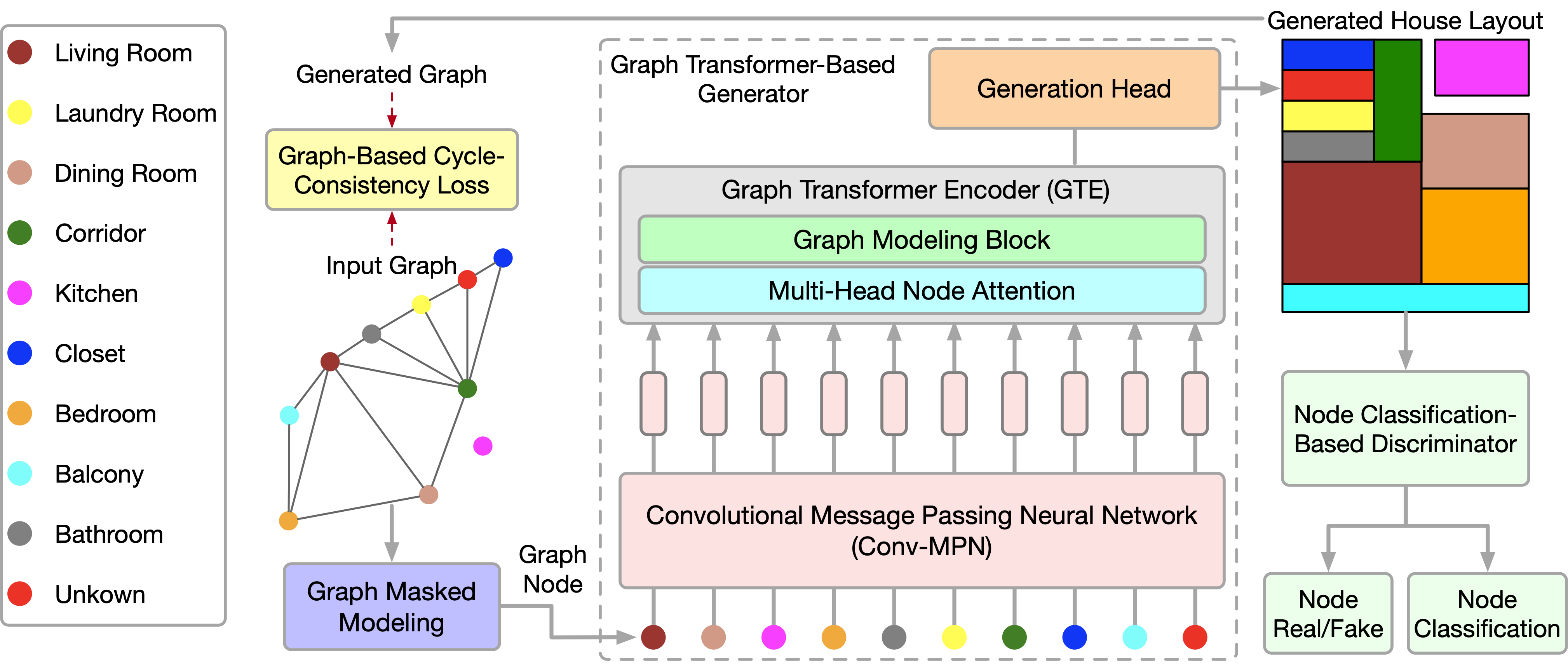
Недавно представленный в статье "Graph Transformer GANs with Graph Masked Modeling for Architectural Layout Generation" алгоритм генеративно-состязательной модели графового трансформера (GTGAN) лаконично объединяет оба указанных подхода. Авторами алгоритма GTGAN решается задача создание реалистичного архитектурного проекта дома из входного графа. И представленная ими модель генератора состоит из трех компонентов: сверточной нейронной сети передачи сообщений (Conv-MPN), энкодера Трансформера графов (GTE) и головки генерации.
Качественные и количественные эксперименты по трем сложным генерациям архитектурного макета с графическими ограничениями с тремя наборами данных, которые были представлены в авторской статье, демонстрируют, что предлагаемый метод может давать результаты, превосходящие представленные ранее алгоритмы.
1. Алгоритм GTGAN
Для описания метода в качестве примера возьмем создание планировки дома. Генератор G получает вектор шума для каждой комнаты и пузырьковую диаграмму в качестве исходных данных. Затем он генерирует план дома, в котором каждая комната представлена в виде прямоугольника, выровненного по оси. Авторы метода представляют каждую пузырьковую диаграмму в виде графа, где каждый узел представляет комнату определенного типа, а каждое ребро представляет пространственную смежность комнат. В частности, генерируем прямоугольник для каждой комнаты. И две связанные в графе комнаты должны быть пространственно смежными, а несвязанные комнаты должны быть пространственно несмежными.
Учитывая пузырьковую диаграмму, сначала генерируем узел для каждой комнаты и инициализируем его с помощью 128 мерного вектор шума, выбранный из нормального распределения. Затем мы объединяем вектор шума с 10 мерным one-hot вектором типа комнаты (tr). Следовательно, мы можем получить 138 мерный вектор gr для представления исходной пузырьковой диаграммы.
![]()
Обратите внимание, что в данном случае используются узлы графа в качестве исходных данных предлагаемого преобразователя.
Блок сверточная передачи сообщений Conv-MPN представляет собой 3D-тензор в выходном пространстве дизайна. Таким образом, мы применяем общий линейный слой для расширения gr в тематический том gr,l=1 размера 16×8 ×8, где l=1 — это объект, извлеченный из первого слоя Conv-MPN. Он будет дважды подвергнут повышающей дискретизации с использованием транспонированной свертки, чтобы стать объектом gr,l=3 размера 16×32×32.
Слой Conv-MPN обновляет граф пространственных объектов посредством передачи сверточных сообщений. В частности, мы обновляем gr,l=1 в рамках следующих шагов:
- Используем один GTE для регистрации долгосрочных корреляций между комнатами, которые соединены во входном графе;
- Используем другой GTE для фиксации долгосрочных зависимостей между несвязанными комнатами во входном графе;
- Объединяем функции по соединенным комнатам во входном графе;
- Объединяем функции по несвязанным комнатам;
- Применяем сверточный блок (CNN) к объединенному объекту.
Этот процесс можно сформулировать следующим образом:
![]()
где N(r) — обозначают множества комнат, связанных и не связанных; «+» и «;» обозначают попиксельное сложение и поканальную конкатенацию, соответственно.
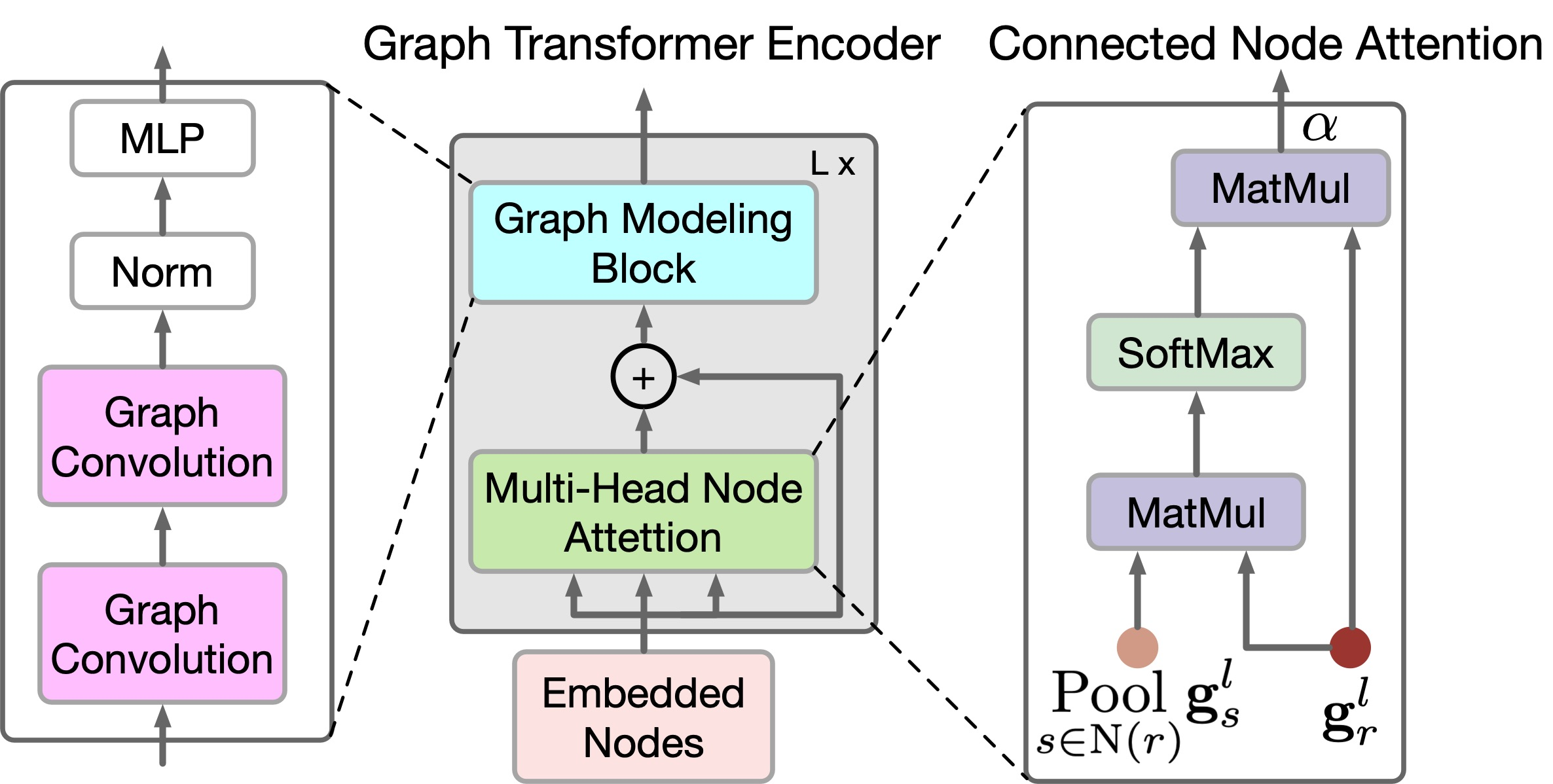
Чтобы отразить локальные и глобальные отношения между узлами графа, авторы метода предлагают новый энкодер GTE. GTE сочетает в себе Self-Attention моделей Transformer и Graph Convolution для захвата глобальных и локальных корреляций, соответственно. Обратите внимание, что в GTGAN не используется позиционное кодирование, поскольку цель поставленной задачи — указать позиции узлов в сгенерированной планировке дома.
В GTGAN расширяется многоголовое Self-Attention в многоголовое внимание к узлам, целью которого является уловить глобальные корреляции между связанными комнатами/узлами и глобальные зависимости между несвязанными комнатами/узлами. С этой целью авторы метода предлагают два новых модуля внимания к узлам графа, а именно: внимание к связанным узлам (CNA) и внимание к несвязанным узлам (NNA). Оба блока имеют одну и ту же сетевую архитектуру.
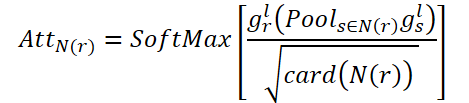
Целью CNA является моделирование глобальных корреляций между соединенными комнатами. AttN(r) измеряет влияние узла на другие соединенные узлы. Затем выполняем матричное умножение gr,l на транспонированную AttN(r). После чего умножаем результат на параметр масштабирования ɑ.
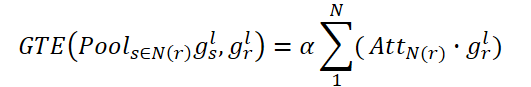
где ɑ — это обучаемый параметр.
При этом каждый подключенный узел в N(r) представляет собой взвешенную сумму всех связанных узлов. Таким образом, CNA получает глобальное представление о структуре пространственного графа и может выборочно корректировать комнаты в соответствии с подключенной картой внимания, улучшая представление планировки дома и семантическую согласованность высокого уровня.
Точно так же NNA стремится охватить глобальные отношения в несвязанных друг с другом комнатах. При этом использует свой обучаемый параметр ß.
Наконец, мы выполняем поэлементное суммирование gr,l, чтобы обновленный объект узла мог фиксировать как связанные, так и несвязанные пространственные отношения.
![]()
Хотя CNA и NNA полезны для извлечения долгосрочных и глобальных зависимостей, они менее эффективны при сборе мелкозернистой локальной информации в сложных структурах данных дома. Чтобы устранить это ограничение, авторы метода предлагают новый блок графового моделирования.
В частности, учитывая особенности gr,l, генерируемый в уравнении выше, дополнительно улучшает локальные корреляции, используя сверточные графовые сети.
![]()
где A обозначает матрицу смежности графа, GC(•) представляет свертку графа, и P обозначает обучаемые параметры. σ — линейная единица гауссовой ошибки (GeLU).
Предоставление информации о взаимоотношениях узлов глобального графа помогает создавать более точные планировки домов. Чтобы дифференцировать этот процесс, авторы метода предлагают новую функцию потерь, основанную на матрице смежности, которая соответствует пространственным отношениям между основным истинным и сгенерированными графами. Точнее, граф фиксируют отношения смежности между каждым узлом в разных комнатах, а затем обеспечивает соответствие между основным истинным и сгенерированными графами посредством предлагаемой функции потерь согласованности цикла. Эта функция потерь направлена на точное поддержание взаимных отношений между узлами. С одной стороны, непересекающиеся части должны прогнозироваться как непересекающиеся. С другой стороны, соседние узлы должны прогнозироваться как соседние и соответствовать коэффициентам близости.
Авторская визуализация GTGAN представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода GTGAN мы переходим к практической части нашей статьи, в которой мы реализуем предложенные подходы средствами MQL5.
Сразу надо обратить внимание на различие задач, решаемых авторами метода и нами. Мы не ставим перед собой цель генерации графика ценового движения. Наша цель — поиск оптимальной стратегии поведения Агента. И на выходе модели мы хотим получить оптимальное действие Агента в отдельно взятом состоянии окружающей среды. На первый взгляд, наши задачи кардинально отличаются.
Но если внимательнее посмотреть на методологию GTGAN, то можно заметить, что основное внимание авторов метода акцентировано на Энкодере (GTE). Здесь большое внимание уделяется как архитектуре энкодера, так и его обучению.
Авторами метода предлагают предварительное обучение Энкодера со случайным маскированием как узлов, так и связей. При этом предлагается маскировать до 40% исходных данных, оставляя каждый узел и ребро с потенциальными пробелами в соседних соединениях. Для восстановления недостающих данных, каждое вложение узла и ребра должно поглощать и интерпретировать свой локальный контекст. То есть каждое вложение должно понимать конкретные детали своего непосредственного окружения. Предложенный подход к случайному маскированию с высоким коэффициентом и последующей реконструкции позволяет покончить с ограничениями, налагаемыми размером и формой подграфов, используемых для прогнозирования. В результате вложения узлов и ребер поощряются к пониманию локальных контекстуальных деталей.
Кроме того, при удалении узлов или ребер с высокими коэффициентами, оставшиеся узлы и ребра можно рассматривать как набор подграфов, задача которых — предсказать весь граф. Это представляет собой более сложную задачу прогнозирования по каждому графу по сравнению с другими задачами самостоятельного предварительного обучения, которые обычно охватывают глобальные детали графа, используя меньшие графы или контекст в качестве целей прогнозирования. Предложенная «интенсивная» задача предварительного обучения по маскировке и перестроению графа дает более широкую перспективу для изучения превосходных вложений узлов и ребер, способных фиксировать сложные детали как на уровне отдельных узлов/ребер, так и на уровне целостного графа.
Энкодер в предлагаемой системе действует как мост, преобразующий исходные атрибуты видимых, немаскированных узлов и ребер в соответствующие им внедрения в пространствах скрытых признаков. Этот процесс включает в себя узловые и граничные аспекты энкодера, которые включают в себя предложенный блок моделирования графа и механизм внимания многоголовых узлов. Эти функции разработаны в духе архитектуры Transformer — метода, известного своей способностью эффективно моделировать последовательные данные. Этот блок помогает создавать надежные представления, которые инкапсулируют целостную динамику отношений внутри графа.
Следовательно, и мы можем использовать предложенный Энкодер для изучения локальных и глобальных зависимостей в исходных данных. Предложенный алгоритм Энкодера мы реализуем в новом классе CNeuronGTE.
2.1 Класс Энкодера GTE
Класс Энкодера GTE CNeuronGTE мы создадим наследником нашего базового класса нейронных слоев CNeuronBaseOCL. Структура предложенного Энкодера настолько отличается от рассмотренных ранее вариантов Трансформера, что несмотря на большое количество ранее созданных нейронных слоев, использующих механизмы внимания, мы решили отказаться от наследования одного из них. Хотя в процессе работы мы и будем использовать ранее созданные наработки.
Структура нового класса представлена ниже.
class CNeuronGTE : public CNeuronBaseOCL { protected: uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CNeuronConvOCL cQKV; CNeuronSoftMaxOCL cSoftMax; int ScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cW0; CNeuronBaseOCL cAttentionOut; CNeuronCGConvOCL cGraphConv[2]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionInsideGradients(void); public: CNeuronGTE(void) {}; ~CNeuronGTE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronGTE; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Здесь мы видим уже знакомые нам локальные переменные:
- iHeads;
- iWindow;
- iUnits;
- iWindowKey.
Их функциональная нагрузка остается прежней. А с назначением внутренних слоев мы познакомимся в процессе реализации методов.
Все внутренние объекты мы объявили статическими, что позволяет нам оставить пустыми конструктор и деструктор класса. Обратите внимание, что в конструкторе класса мы даже не указываем значение локальных переменных.
Полная инициализация класса, как всегда, осуществляется в методе Init. В параметрах данного метода мы получаем всю необходимую информацию для создания корректной архитектуры класса. А в теле метода мы сразу вызываем одноименный метод родительского класса, в котором осуществляется минимально необходимый контроль полученных исходных параметров и инициализация унаследованных объектов.
bool CNeuronGTE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
После успешного выполнения метода родительского класса мы сохраняем полученные данные в локальные переменные.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); activation = None;
И инициализируем добавленные объекты. Первым мы инициализируем внутренний сверточный слой cQKV. В нем мы планируем генерировать представление всех 3 сущностей (Query, Key и Value) в параллельных потоках. Размер окна исходных данных и его шага равно размеру описания одного элемента последовательности. А количество фильтров свертки равно произведению размера вектора описания одной сущности одного элемента последовательности помноженного на количество голов внимания и на 3 (количество сущностей). Количество элементов равно размеру анализируемой последовательности.
if(!cQKV.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * 3 * iHeads, iUnits, optimization, iBatch)) return false;
Для повышения стабильности работы блока, мы нормализуем сгенерированные сущности с использованием слоя SoftMax.
if(!cSoftMax.Init(0, 1, OpenCL, iWindowKey * 3 * iHeads * iUnits, optimization, iBatch)) return false; cSoftMax.SetHeads(3 * iHeads * iUnits);
Следующим шагом мы создадим буфер коэффициентов зависимости в контексте OpenCL. Его размер в 2 раза больше обычного, чтобы отдельно записать коэффициенты для связанных и несвязанных вершин.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits * 2 * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Результаты многоголового внимания мы будем сохранять в локальном слое cMHAttentionOut.
if(!cMHAttentionOut.Init(0, 2, OpenCL, iWindowKey * 2 * iHeads * iUnits, optimization, iBatch)) return false;
Обратите внимание, что размер слоя результатов многоголового внимания так же в 2 раза превышает аналогичный слой рассмотренных ранее реализаций Трансформера. Это также сделано для возможности записи данных как связанных, так и не связанных вершин.
Кроме того, такой подход позволяет нам не выводить в отдельный функционал обучение параметров масштабирования ɑ и ß. Вместо них мы воспользуемся функционалом слоя W0. В данном случае он объединит головы внимания, а так же влияние связанных и не связанных вершин.
if(!cW0.Init(0, 3, OpenCL, 2 * iWindowKey * iHeads, 2 * iWindowKey* iHeads, iWindow, iUnits, optimization, iBatch)) return false;
После блока внимания нам предстоит сложить и результаты с исходными данными и нормализовать результаты. Полученные значения мы запишем в слой cAttentionOut.
if(!cAttentionOut.Init(0, 4, OpenCL, iWindow * iUnits, optimization, iBatch)) return false;
Далее идут 2 блока по 2 слоя в каждом. Это блок графовой свертки и FeedForward. Объекты указанных блоков мы инициализируем в цикле.
for(int i = 0; i < 2; i++) { if(!cGraphConv[i].Init(0, 5 + i, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cFF[i].Init(0, 7 + i, OpenCL, (i == 0 ? iWindow : 4 * iWindow), (i == 0 ? iWindow : 4 * iWindow), (i == 1 ? iWindow : 4 * iWindow), iUnits, optimization, iBatch)) return false; }
Напоследок осуществим подмену буфера градиентов ошибки.
if(cFF[1].getGradient() != Gradient) { if(!!Gradient) delete Gradient; Gradient = cFF[1].getGradient(); } //--- return true; }
И завершим работу метода.
После инициализации класса мы переходим к организации алгоритма прямого прохода класса. И тут мы сначала обращаем свой взор на нашу OpenCL программу, в которой нам предстоит создать новый кернел GTEFeedForward. В рамках данного кернела мы будем анализировать зависимости как связанных, так и не связанных узлов. В методологии метода GTGAN, в теле кернела GTEFeedForward мы реализуем функционал CNA и NNA.
Но, прежде чем перейти к реализации, давайте определимся какие узлы мы считаем связанные, а какие нет. Первое, что надо знать — узлами в нашей реализации являются описания параметров одного бара. Мы имеем дело с анализом тайм-серии. Следовательно, на прямую связанными у нас могут быть только 2 последующих бара. Отсюда, для бара Xt связанными являются только бары Xt-1 и Xt+1. При этом бары Xt-1 и Xt+1 не связаны между собой, так как между ними есть бар Xt.
С этим моментом определились и теперь переходим к реализации. В параметрах кернел получает указатели на буферы обмена данными.
__kernel void GTEFeedForward(__global float *qkv, __global float *score, __global float *out, int dimension) { const size_t cur_q = get_global_id(0); const size_t units_q = get_global_size(0); const size_t cur_k = get_local_id(1); const size_t units_k = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
В теле кернела мы идентифицируем поток в пространстве задач. В данном случае мы имеем дело с 3 мерным пространством задач, одно из которых объединено в локальную группу.
Следующим этапом мы определяем смешения в буферах данных.
int shift_q = dimension * (cur_q + h * units_q); int shift_k = (cur_k + h * units_k + heads * units_q); int shift_v = dimension * (h * units_k + heads * (units_q + units_k)); int shift_score_con = units_k * (cur_q * 2 * heads + h) + cur_k; int shift_score_notcon = units_k * (cur_q * 2 * heads + heads + h) + cur_k; int shift_out_con = dimension * (cur_q + h * units_q); int shift_out_notcon = dimension * (cur_q + units_q * (h + heads));
Тут же мы объявим 2 мерный локальный массив. Во втором измерении 2 элемента для связанных и несвязанных узлов.
const uint ls_score = min((uint)units_k, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE][2];
Следующим этапом нам предстоит определить коэффициенты зависимости. Вначале мы умножим соответствующие тензора Query и Key. Разделим на корень из размерности и возьмем экспоненциальное значение.
//--- Score float scr = 0; for(int d = 0; d < dimension; d ++) scr += qkv[shift_q + d] * qkv[shift_k + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f));
Определим связанные ли анализируемые элементы последовательности и результат сохраним в необходимый элемент буфера.
if(cur_q == cur_k) { score[shift_score_con] = scr; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = scr; } } else { if(abs(cur_q - cur_k) == 1) { score[shift_score_con] = scr; score[shift_score_notcon] = 0; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = 0; } } else { score[shift_score_con] = 0; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = 0; local_score[cur_k][1] = scr; } } } barrier(CLK_LOCAL_MEM_FENCE);
Теперь мы можем найти сумму коэффициентов по каждому из элементов последовательности.
for(int k = ls_score; k < units_k; k += ls_score) { if((cur_k + k) < units_k) { local_score[cur_k][0] += score[shift_score_con + k]; local_score[cur_k][1] += score[shift_score_notcon + k]; } } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(cur_k < count) { if((cur_k + count) < units_k) { local_score[cur_k][0] += local_score[cur_k + count][0]; local_score[cur_k][1] += local_score[cur_k + count][1]; local_score[cur_k + count][0] = 0; local_score[cur_k + count][1] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); barrier(CLK_LOCAL_MEM_FENCE);
И приведем сумму коэффициентов зависимости к 1 по каждому элементу последовательности. Для этого достаточно разделить значение каждого элемента на соответствующую сумму.
score[shift_score_con] /= local_score[0][0]; score[shift_score_notcon] /= local_score[0][1]; barrier(CLK_LOCAL_MEM_FENCE);
Когда найдены коэффициенты зависимости, мы можем определить результаты влияния связанных и не связанных узлов.
shift_score_con -= cur_k; shift_score_notcon -= cur_k; for(int d = 0; d < dimension; d += ls_score) { if((cur_k + d) < dimension) { float sum_con = 0; float sum_notcon = 0; for(int v = 0; v < units_k; v++) { sum_con += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_con + v]; sum_notcon += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_notcon + v]; } out[shift_out_con + cur_k + d] = sum_con; out[shift_out_notcon + cur_k + d] = sum_notcon; } } }
После успешного выполнения всех итераций мы завершаем работу кернела и возвращаемся к работе над основной программой. Здесь мы сначала создадим метод AttentionOut вызова выше созданного кернела. Это метод, который будет вызываться из другого метода, этого же класса. Работает только с внутренними объектами и не содержит параметров.
В теле метода мы сначала проверяем актуальность указателя на объект класса работы с контекстом OpenCL.
bool CNeuronGTE::AttentionOut(void) { if(!OpenCL) return false;
После чего определим пространство задач и размер рабочих групп. В данном случае мы используем 3 мерное пространство задач с объединением по 1 измерению в рабочие группы.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits, 1};
Затем передадим в кернел необходимые параметры.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_qkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_GTEFeedForward, def_k_gteff_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И поставим кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_GTEFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
При этом не забываем на каждом шаге контролировать процесс выполнения операций. А после завершения работы метода возвращаем логическое значения результаты работы метода, что позволит контролировать процесс в вызывающей программе.
После завершения подготовительной работы мы создадим верхнеуровневый метод прямого прохода нашего класса CNeuro.nGTE::feedForward. В параметрах данного метода, аналогично многим одноименным методам других ранее рассмотренных классов, мы получаем указатель на объект предшествующего слоя, буфер которого содержит исходные данные для работы нашего метода.
bool CNeuronGTE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.FeedForward(NeuronOCL)) return false;
Однако, в теле метода мы не проверяем актуальность полученного указателя, а сразу вызываем аналогичный метод прямого прохода объекта формирования сущностей Query, Key и Value. В теле вызываемого метода уже реализованы все необходимые контроли. И после успешного формирования сущностей, о чем мы можем судить по результату работы вызванного метода, мы нормализуем полученные данные в слое SoftMax.
if(!cSoftMax.FeedForward(GetPointer(cQKV))) return false;
Далее мы воспользуемся выше созданным методом AttentionOut и определим влияние связанных и не связанных вершин.
if(!AttentionOut()) return false;
Размерность результатов многоголового внимания мы понизим до величины тензора исходных данных.
if(!cW0.FeedForward(GetPointer(cMHAttentionOut))) return false;
После чего сложим и нормализуем данные.
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), iWindow, true)) return false;
На этом этапе мы завершили блок многоголового внимания и переходим к блоку графовой свертки GC. Здесь мы используем 2 слоя CrystalGraph Convolutional Network. И для реализации функционала нам достаточно последовательно вызвать их методы прямого прохода.
if(!cGraphConv[0].FeedForward(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].FeedForward(GetPointer(cGraphConv[0]))) return false;
Далее следует блок FeedForward.
if(!cFF[0].FeedForward(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].FeedForward(GetPointer(cFF[0]))) return false;
И в завершении метода мы ещё раз суммируем и нормализуем результаты.
if(!SumAndNormilize(cAttentionOut.getOutput(), cFF[1].getOutput(), Output, iWindow, true)) return false; //--- return true; }
После реализации прямого прохода мы переходим к организации процесса обратного прохода. И здесь мы снова начинаем работу с создания нового кернела GTEInsideGradients на стороне OpenCL программы. В параметрах кернел получает указатели на необходимые для работы буфера данных. А все размерности мы получаем из пространства задач.
__kernel void GTEInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
Аналогично кернелу прямого прохода, данный кернел мы будем запускать в 3 мерном пространстве задач. Только на этот раз без организации рабочих групп. В теле кернела мы идентифицируем текущий поток в пространстве задач по всем измерениям.
Алгоритм нашего кернела можно условно разделить на 3 блока:
- Градиент Value;
- Градиент Query;
- Градиент Key.
Обратный проход мы организовываем в порядке обратном к прямому проходу. И первым определяем градиент ошибки для сущности Value. В данном блоке мы сначала определяем смещения в буферах данных.
//--- Calculating Value's gradients { int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units + u) + d;
После чего организуем цикл сбора градиентов ошибки по связанным и не связанным узлам. А результат сохраним в соответствующий элемент глобального буфера градиентов ошибки сущностей qkv_g.
float sum = 0; for(uint i = 0; i <= units; i ++) { sum += gradient[shift_out_con + i * dimension] * scores[shift_score_con + i * step_score]; sum += gradient[shift_out_notcon + i * dimension] * scores[shift_score_notcon + i * step_score]; } qkv_g[shift_v] = sum; }
На втором этапе мы посчитаем градиенты ошибки для сущности Query. Аналогично первому блоку, мы сначала рассчитаем смещения в буферах данных.
//--- Calculating Query's gradients { int shift_q = dimension * (u + h * units) + d; int shift_out_con = dimension * (h * units + u) + d; int shift_out_notcon = dimension * (u + units * (h + heads)) + d; int shift_score_con = units * h; int shift_score_notcon = units * (heads + h); int shift_v = dimension * (h * units + 2 * heads * units);
А вот расчет градиента ошибки будет немного сложнее. Дело в том, что сначала нам нужно определить градиент ошибки на уровне матрицы коэффициентов зависимости и скорректировать его производную функции SoftMax. И только потом перенести градиент ошибки до уровня искомой сущности. Для этого нам потребуется организовать целую систему вложенных циклов.
float grad = 0; for(int k = 0; k < units; k++) { int shift_k = (k + h * units + heads * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + k]; float sc_notcon = scores[shift_score_notcon + k]; for(int v = 0; v < units; v++) for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_con + dim] * ((float)(k == v) - sc_con); sc_g += scores[shift_score_notcon + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_notcon + dim] * ((float)(k == v) - sc_notcon); } grad += sc_g * qkv[shift_k]; }
После завершения всех итераций системы циклов мы переносим суммарный градиент ошибки в соответствующий элемент глобального буфера данных.
qkv_g[shift_q] = grad; }
В заключительном блоке нашего кернела мы определим градиент ошибки для сущности Key. В данном случае мы создаем алгоритм аналогичный предыдущему блоку. Только в данном случае мы берем градиент ошибки с матрицы коэффициентов зависимости в другом измерении.
//--- Calculating Key's gradients { int shift_k = (u + (h + heads) * units) + d; int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units); float grad = 0; for(int q = 0; q < units; q++) { int shift_q = dimension * (q + h * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + u + q * step_score]; float sc_notcon = scores[shift_score_notcon + u + q * step_score]; for(int g = 0; g < units; g++) { for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_con + g * dimension + dim] * ((float)(u == g) - sc_con); sc_g += scores[shift_score_notcon + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_notcon + g * dimension+ dim] * ((float)(u == g) - sc_notcon); } } grad += sc_g * qkv[shift_q]; } qkv_g[shift_k] = grad; } }
Для вызова описанного кернела мы создадим метод CNeuronGTE::AttentionInsideGradients. Алгоритм его построения аналогичен методу CNeuronGTE::AttentionOut. И мы не будем сейчас останавливаться на его детальном рассмотрении. Я предлагаю Вам самостоятельно ознакомиться с ним во вложении, где вы найдете полный код всех программ, используемых при подготовке данной статьи.
А полный процесс распределения градиента ошибки верхнеуровнево описан в методе CNeuronGTE::calcInputGradients. В параметрах данный метод получает указатель на объект предыдущего нейронного слоя, которому предстоит передать градиент ошибки.
bool CNeuronGTE::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false;
Здесь стоит напомнить, что благодаря нашему, уже не раз используемому, подходу с подменой буферов данных. При работе метода обратного прохода последующего нейронного слоя мы получили градиент ошибки сразу в буфер последнего слоя блока FeedForward. Поэтому нам нет необходимости излишнего копирования данных. И в методе обратного прохода мы начинаем сразу с распределения градиента ошибки через слои блока FeedForward.
if(!cFF[0].calcInputGradients(GetPointer(cGraphConv[1]))) return false;
После чего мы аналогично проводим градиент ошибки через блок графовой свертки.
if(!cGraphConv[1].calcInputGradients(GetPointer(cGraphConv[0]))) return false; if(!cGraphConv[1].calcInputGradients(GetPointer(cAttentionOut))) return false;
На этом этапе мы объединяем градиент ошибки с 2 потоков.
if(!SumAndNormilize(cAttentionOut.getGradient(), Gradient, cW0.getGradient(), iWindow, false)) return false;
После чего распределяем градиент ошибки по головам внимания.
if(!cW0.calcInputGradients(GetPointer(cMHAttentionOut))) return false;
И проводим через блок внимания.
if(!AttentionInsideGradients()) return false;
Напомню, что градиент ошибки по всем 3 сущностям (Query, Key, Value) содержится в 1 конкатенированном буфере, что позволяет нам параллельно обрабатывать сразу все сущности. Сначала мы скорректируем градиент ошибки на производную функции SoftMax, которой мы нормализовывали данные.
if(!cSoftMax.calcInputGradients(GetPointer(cQKV))) return false;
А затем опустим градиент ошибки до уровня предыдущего слоя.
if(!cQKV.calcInputGradients(prevLayer)) return false;
Здесь нам остается лишь добавить градиент ошибки со второго потока данных.
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
И завершаем работу метода.
После распределения градиента ошибки нам остается лишь обновить параметры модели для минимизации ошибки. Все обучаемые параметры нашего класса содержатся во внутренних объектах. Поэтому для корректировки параметров мы будем последовательно вызывать соответствующие методы внутренних объектов.
bool CNeuronGTE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cMHAttentionOut))) return false; if(!cGraphConv[0].UpdateInputWeights(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].UpdateInputWeights(GetPointer(cGraphConv[0]))) return false; if(!cFF[0].UpdateInputWeights(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].UpdateInputWeights(GetPointer(cFF[0]))) return false; //--- return true; }
На этом мы завершаем рассмотрение методов нашего нового класса CNeuronGTE. А со всеми метода обслуживания класса. в том числе и работы с фалами, я предлагаю Вам самостоятельно ознакомиться во вложении. Там, как всегда, Вы можете найти полный код всех программ, используемых при подготовке статьи.
2.2 Архитектура моделей
После создания нового класса мы переходим к работе над нашими моделями. Созданию их архитектуры и обучения. Здесь надо напомнить, что методом GTGAN предусматривается предварительное обучение Энкодера. Поэтому, мы создадим 2 метода создания описания архитектуры моделей. В первом методе CreateEncoderDescriptions мы создадим описания архитектуры Энкодера и Декодека, используемого только для предварительного обучения представлений.
bool CreateEncoderDescriptions(CArrayObj *encoder, CArrayObj *decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
На вход Энкодера мы подаем описание одной свечи.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные данные нормализуем с помощью слоя пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы создаем эмбединг последнего бара и добавляем его в стек.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь следует обратить внимание, что в отличие от предыдущих работ, в которых эмбединг создавался одним слоем, мы воспользовались предложениями метода GTGAN в части блока передачи сообщений Conv-MPN и разбили процесс создания эмбединга на 2 этапа. И за слоем эмбединга мы поставили еще один сверточный слой, который завершает работу по генерации эмбедингов состояний.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Далее мы поставим слой DropOut для маскирования данных в процессе обучения представлений на стадии предварительного обучения.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count*prev_wout; descr.probability= 0.4f; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
На следующем шаге мы немного отступим от предложенного алгоритма и добавим позиционное кодирование. Это обусловлено значительными отличиями в поставленных задачах.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы в цикле добавим 8 слоев нового энкодера.
//--- layer 6 - 14 for(int i = 0; i < 8; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronGTE; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!encoder.Add(descr)) { delete descr; return false; } }
Архитектура Декодера будет значительно короче. На вход модели мы подаем результаты работы Энкодера.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count * prev_wout; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Пропустим их через слой свертки.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count=prev_count; descr.window = prev_wout; descr.step=prev_wout; descr.window_out=EmbeddingSize/4; descr.optimization = ADAM; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
И нормализуем функцией SoftMax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
На выходе Декодера создадим полносвязный слой с количеством элементов равным результатам слоя Эмбединга.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*EmbeddingSize/2; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
В результате из моделей мы составили ассиметричный Автоэнкодер, который будет обучаться на восстановление данных в стеке слоя Эмбединга. Выбор латентного состояния слоя Эмбединга сделан не случайно. В процессе обучения мы бы хотели акцентировать внимание Энкодера на полном наборе исторических данных, а не только последней свечи.
Архитектуру Актера и Критика мы опишем в методе CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В архитектуре Актера я так же решил добавить немного духа эксперимента. На вход модели мы подаем описание текущего состояния счета.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полносвязный слой создаст нам некий эмбединг полученного состояния.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее мы добавим блок из 3 слоев Кросс-Внимания, в которых оценим зависимости текущего состояния нашего счета и состояния окружающей среды.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные результаты обрабатываются 2 полносвязными слоями.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И на выходе Актера генерируем его стохастическую политику.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель Критика была перенесена практически без изменений из предыдущей работы. На вход модели подаем результаты работы Энкодера.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = GPTBars*EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
К полученным данным добавляем действия Актера.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type=defNeuronConcatenate; descr.window=prev_count; descr.step = NActions; descr.count=LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
И составляем блок принятия решений из 2 полносвязных слоев.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 Советник обучения представлений
После создания Архитектуры моделей мы переходим к построению советников их обучения. И первым мы создадим советник предварительного обучения представлений "...\Experts\GTGAN\StudyEncoder.mq5". Структура советника во многом заимствована из предыдущих работ. И в целях сокращения объема статьи мы остановимся только на методе непосредственного обучения моделей Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
В теле метода мы сначала сгенерируем вектор вероятностей выбора проходов из буфера воспроизведения опыта на основе их результативности.
Далее мы объявим локальные переменные.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Затем мы организовываем систему циклов обучения моделей. В теле внешнего цикла мы сэмплируем траекторию и начальное состояние обучения на ней.
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - batch)); if(state <= 0) { iter--; continue; }
Очищаем буфер Энкодера и определяем конечное состояние пакета обучения.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total);
После завершения подготовительной работы мы организовываем вложенный цикл непосредственного обучения моделей.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Здесь мы загружаем из буфера воспроизведения опыта описание текущего состояния окружающей среды и вызываем метод прямого прохода Энкодера.
//--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
За ним следует прямой проход Декодера.
if(!Decoder.feedForward((CNet*)GetPointer(Encoder),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После прямого прохода нам необходимо определить целевые показатели обучения модели. Самообучение автоэнкодера осуществляется на восстановление исходных данных. Как мы обсуждали ранее, в процессе нашего обучения модели представлений мы будем использовать скрытое состояния со слоя эмбедингов. Загрузим эти данные в локальный буфер.
Encoder.GetLayerOutput(LatentLayer,Result);
И передадим их в качестве целевых значений для оптимизации параметров наших моделей.
if(!Decoder.backProp(Result,(CBufferFloat*)NULL) || !Encoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Теперь нам остается лишь проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После успешного завершения процесса обучения модели представления мы очищаем поле комментариев на графике.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); ExpertRemove(); //--- }
Выводим в журнал результаты обучения и инициализируем процесс завершения работы советника.
На данном этапе мы можем воспользоваться обучающей выборкой из предыдущих работ и запустить процесс обучения модели представления. А пока модель обучается, мы переходим к созданию советника обучения политики Актера.
2.4 Советник обучения политики Актера
Для обучения политики поведения Актера мы создадим советник "...\Experts\GTGAN\Study.mq5". Здесь следует отметить, что в процессе обучения мы будем использовать 3 модели, а обучать только 2 (Актера и Критика). Модель Энкодера была обучена на предыдущем этапе.
CNet Encoder; CNet Actor; CNet Critic;
В методе инициализации советника мы сначала загружаем базу примеров.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
После чего пытаемся загрузить предварительно обученные модели. И в данном случае, ошибка загрузки предварительно обученного Энкодера является критичной для работы программы.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Can't load pretrained Encoder"); return INIT_FAILED; }
А вот при ошибке загрузки Актера и/или Критика мы создаем новые модели, инициализированные случайными параметрами.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor) || !Critic.Create(critic)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Все модели мы переносим в единый контекст OpenCL.
OpenCL = Encoder.GetOpenCL(); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
И обязательно отключаем режим обучения Энкодера.
Encoder.TrainMode(false);
Напомню, что в его архитектуре используется слой DropOut, который случайным образом маскирует данные. В процессе же эксплуатации модели нам необходимо отключить маскирование, которое осуществляется отключением режима обучения модели.
Далее мы осуществляем минимально необходимый контроль архитектуры моделей.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Инициализируем вспомогательные буфера данных.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
И генерируем событие начала обучения моделей.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Сам же процесс обучения моделей, как обычно, организован в методе Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
В теле метода, как и в предыдущем советнике, мы сначала генерируем вектор вероятностей выбора траекторий из буфера воспроизведения опыта на основе их доходности. И инициализируем локальные переменные. После чего организовываем систему циклов обучения моделей.
В теле внешнего цикла мы сэмплируем траекторию из буфера воспроизведения опыта и состояние начала процесса обучения на ней.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand()*MathRand() / MathPow(32767, 2))*(Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Очищаем стек Энкодера и определяем последнее состояния пакета обучения.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
После завершения подготовительной работы мы организовываем вложенный цикл непосредственного обучения моделей.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
В теле вложенного цикла мы загружаем описание анализируемого состояния счета из буфера воспроизведения опыта и осуществляем прямой проход Энкодера.
Далее, для осуществления прямого прохода Актера нам предстоит загрузить описание состояния счета из буфера воспроизведения опыта.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Тут же мы добавляем временную метку текущего состояния.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
И осуществляем прямой проход Актера.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount),1,false,GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
А затем Критика.
//--- Critic if(!Critic.feedForward((CNet *)GetPointer(Encoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Целевые значения для обеих моделей мы берем из буфера воспроизведения опыта. Сначала мы осуществляем обратный проход Актера.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
А затем Критика с передачей градиента ошибки Актеру.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
В обоих случаях мы не обновляем параметры Энкодера.
После успешного завершения обратного прохода обеих моделей мы информируем пользователя о ходе процесса обучения и переходим к следующей итерации системы циклов.
//--- if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После завершения процесса обучения мы очищаем поле комментариев на графике.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Результаты обучения выводим в журнал и инициализируем процесс завершения работы советника.
На этом мы завершаем рассмотрение программ обучения моделей. Программы взаимодействия с окружающей средой были перенесены из предыдущей статьи с минимальными корректировками. И я предлагаю Вам ознакомиться с ними во вложении, где Вы можете найти полный код всех программ, используемых при подготовке статьи.
3. Тестирование
В предыдущих разделах данной статьи мы познакомились с новым методом GTGAN и провели большую работу по реализации предложенных подходов средствами MQL5. И в данной части статьи мы, как обычно, осуществляем тестирование проделанной работы с оценкой полученных результатов на реальных данных в тестере стратегий MetaTrader 5. Обучение и тестирование моделей осуществлялось на исторических данных инструмента EURUSD тайм-фрейм H1. Обучение моделей осуществляется на историческом отрезке за первые 7 месяцев 2023 года. Тестирование обученной модели осуществляется на данных августа 2023 года.
Созданные в данной статье модели работают с исходными данными, аналогично моделям из предыдущих статей. Вектора действий Актера и вознаграждений за совершенные переходы в новое состояние так же идентичны предыдущим статьям. Поэтому, для обучения моделей мы можем воспользоваться буфером воспроизведения опыта, собранным в процессе обучения моделей из предыдущих статей. Для этого достаточно переименовать файл в "GTGAN.bd".
Обучение моделей осуществляется в 2 этапа. Сначала мы обучаем Энкодер (модель представлений). А затем обучается политика поведения Актера. Надо сказать, что разделение процесса обучения на 2 этапа оказывает положительное влияние. Модели обучаются довольно быстро и стабильно.
По результатам обучения можно сказать, что модель быстро научилась обобщать и придерживаться политики действий из буфера воспроизведения опыта. К сожалению, в моем буфере воспроизведения опыта было мало положительных проходов. И модель выучила политику близкую к средней из обучающей выборке, которая, увы, не дает положительного результата. Думаю стоит попробовать обучать модель на положительных проходах.
Заключение
В данной статье мы познакомились с алгоритмом GTGAN, который был представлен в январе 2024 года для решения сложных архитектурных задач. Для своих целей мы попытались заимствовать подходы разностороннего анализа текущего состояния в Энкодере GTE, который лаконично соединяет преимущество методов внимания и сверточных графовых моделей.
В практической части статьи мы реализовали предложенные подходы средствами MQL5 и протестировали полученные модели на реальных данных в тестере стратегий MetaTrader 5.
Результаты тестирования указывают на необходимость дополнительной работы с предложенными подходами.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения модели представлений. |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования