
R-квадрат как оценка качества кривой баланса стратегии

Оглавление
- Введение
- Критика распространенных статистик оценки торговых систем
- Поведение распространенных статистик при теситровании торговых систем
- Требования к критерию тестирования торговой системы
- Линейная регрессия
- Корреляция
- Коэффициент детерминации R^2
- Теорема арксинуса и ее вклад в оценку линейной регрессии
- Сбор эквити стратегии
- Расчет коэффициента детерминации R^2 с помощью AlgLib
- Использование R-квадрат на практике
- Преимущества и ограничения в использовании
- Заключение
Введение
Каждая торговая стратегия нуждается в объективной оценке ее эффективности. Для этого используется обширный ряд статистических параметров. Многие из них просты в расчете и показывают интуитивно понятные метрики. Другие сложнее в построении и в интерпретации значений. Несмотря на все это многообразие, есть очень мало качественных метрик для оценки нетривиальной, но вместе с тем очевидной величины — гладкости линии баланса торговой системы. Данная статья предлагает решение этой проблемы. Рассмотрим подробно такой нетривиальный показатель, как коэффициент детерминации R-квадрат (R^2), рассчитывающий количественную оценку той самой визуально привлекательной, ровной, восходящей линии баланса, к которой стремится каждый трейдер.
Конечно, в терминале MetaTrader 5 уже есть развитый сводный отчет, показывающий основные статистики торговой системы. Однако предоставленных в нем параметров не всегда бывает достаточно. К счастью, MetaTrader 5 предоставляет возможность написать собственный пользовательский параметр оценки, чем мы и займемся. Мы не только построим коэффициент детерминации R^2, но и попытаемся количественно оценить его показания, сравним его с другими критериями оптимизации, выведем закономерности, которым следуют основные статистические оценки.
Критика распространенных статистик оценки торговых систем
Каждый раз, когда мы генерируем торговый отчет или изучаем результаты тестирования торговой системы, перед нами предстают сразу несколько "магических чисел", по анализу которых можно сделать выводы о качестве торговли. Например, так выглядит типичный отчет о тестировании в терминале MetaTrader 5:
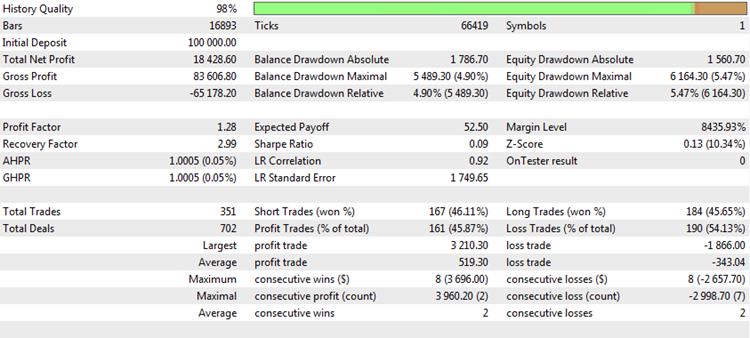
Рис. 1. Результат тестирования торговой стратегии
Он содержит ряд интересных статистик или метрик. Проанализируем наиболее популярные из них и объективно рассмотрим их сильные и слабые стороны.
Чистая прибыль. Метрика показывает, сколько всего денег было заработано либо потеряно за период тестирования или торговли. Это один из важнейших параметров торговли. Основная задача каждого трейдера — максимизация прибыли. Сделать это можно с помощью множества способов, но результирующий итог будет всегда один — это и будет чистая прибыль. Чистая прибыль далеко не всегда зависит от количества сделок и практически не зависит от прочих параметров, хотя обратное утверждение не верно. Таким образом, она является инвариантом по отношению к другим метрикам, и поэтому может использоваться независимо от них. Однако есть у этого показателя и серьезные недостатки.
Во-первых, чистая прибыль напрямую зависит от того, используется капитализация или нет. При использовании капитализации прибыль прирастает нелинейно. Часто наблюдается экспоненциальный, взрывной рост депозита. В этом случае числа, зафиксированные в качестве чистой прибыли на момент окончания тестирования, часто достигают астрономических величин и не имеют ничего общего с реальностью. Если же мы торгуем фиксированным лотом, то приращения депозита более линейны, но даже в этом случае прибыль зависит от выбранного объема. Например, если тестирование, результат которого представлен в таблице выше, происходило фиксированным лотом объемом 0.1 контракта, то 15 757$ полученной прибыли можно считать замечательным результатом. Если же объем сделки был 1.0 лот, то результат тестирования более чем скромный. Именно поэтому опытные тестировщики любят выставлять фиксированный 0.1 или 0.01 лот для рынка Forex. В этом случае минимальное изменение баланса равно одному пункту инструмента, что делает анализ этой характеристики более объективным.
Во-вторых, итоговый результат зависит от длины тестируемого периода или от продолжительности истории торгов. Например, чистая прибыль, указанная в таблице выше, могла быть получена за 1 год, а могла — и за 5 лет. И в каждом случае одна и та же цифра означает совершенно разную эффективность стратегии.
И, в-третьих, общая прибыль фиксируется на момент последней даты. Однако в этот момент может наблюдаться сильная просадка капитала, тогда как неделю назад ее могло еще и не быть. Иными словами, этот параметр сильно зависит от выбранной начальной и конечной точки тестирования или формирования отчета.
Прибыльность. Пожалуй, это самая популярная статистика у профессиональных трейдеров. В то время как новички хотят видеть только итоговую прибыль, профессионалам важно знать оборачиваемость вложенных средств. Если убыток от сделки рассматривать как своеобразное вложение, то прибыльность (ProfitFactor) показывает маржинальность нашей торговли. Например, если мы совершили только две сделки, и на первой из них потеряли 1 000$ а на второй заработали 2 000$, то прибыльность нашей стратегии будет 2 000$/1 000 = 2.0. Это очень хороший показатель. Более того, ProfitFactor не зависит ни от временного диапазона тестирования, ни от объема базового лота. Поэтому его так любят использовать профессионалы. Однако и у него есть недостатки.
Один из них заключается в том, что значения прибыльности сильно зависят от количества сделок. Если сделок мало, то получить ProfitFactor, равный 2.0, или даже 3.0 единицам вполне возможно. Если же сделок очень много, то большой удачей будет прибыльность, равная 1.5 единицам.
Математическое ожидание выигрыша. Очень важная характеристика, указывающая средний результат сделки. Если стратегия прибыльная — матожидание положительное, если убыточная — это отрицательная величина. Если математическое ожидание сопоставимо со спредом или с комиссионными издержками, то возникают сомнения в способности этой стратегии зарабатывать на реальном счете. Обычно в тестере стратегий, в условиях идеального исполнения, математическое ожидание может быть положительным, а сам график баланса — представлять собой ровную восходящую прямую. Однако в реальной торговле, из-за возможных так называемых реквот или проскальзываний, средний результат сделки может оказаться немного хуже теоретически расчетного результата, что критически скажется на результате стратегии и приведет ее к реальным убыткам.
Недостатки есть и здесь. Главный из них опять-таки связан с количеством сделок. Если сделок немного, то получить большое математическое ожидание не составляет труда. При большом количестве сделок матожидание, наоборот, стремится к нулю. Поскольку это линейный показатель, его нельзя использовать в стратегиях, использующих систему управления капиталом. Но профессиональные трейдеры ценят его и используют в линейных системах с фиксированным лотом, сопоставляя с количеством сделок.
Количество сделок. Важный параметр, косвенно или явно влияющий на большинство остальных характеристик. Предположим, что наша торговая система выигрывает в 70% случаев. При этом абсолютные величины выигрыша и проигрыша равны, а других вариантов исхода сделки торговая тактика не допускает. Такая система кажется выдающейся, однако что произойдет, если мы попытаемся измерить ее эффективность лишь по двум последним сделкам? В 70% случаев одна из них будет прибыльной, но вероятность прибыльности обеих сделок — всего 49%. Т.е. более чем в половине случаев результат двух сделок будет нулевым. Следовательно, в половине случаев вся статистика будет говорить о том, что стратегия не зарабатывает. Ее профит-фактор будет равен единице, матожидание и прибыль будут нулевыми, другие параметры тоже укажут на нулевую эффективность.
Именно поэтому количество сделок должно быть достаточно большим. Но что подразумевать под достаточностью? Принято считать, что любая выборка должна содержать как минимум 37 измерений. Это магическое число в статистике, именно оно является нижней границей репрезентативности параметра. Конечно, для оценки торговой системы этого количества сделок недостаточно. Для надежного результата желательно совершить не менее 100 — 150 сделок. Более того, для многих профессиональных трейдеров и этого недостаточно. Они проектируют системы, совершающие не менее 500-1000 сделок, и уже потом, на основании этих результатов, рассматривают возможность запуска системы на реальных торгах.
Поведение распространенных статистических параметров при тестировании торговых систем
Мы разобрали основные параметры статистики торговых систем. Посмотрим, как они показывают себя на практике. При этом заострим внимание на их недостатках, чтобы понять, как предложенное дополнение в виде статистики R^2 поможет их решить. Для этого воспользуемся уже готовым экспертом CImpulse 2.0, работа которого описана в статье "Универсальный торговый эксперт: работа с отложенными ордерами". Он был выбран за простоту и за то, что, в отличие от экспертов из стандартной поставки MetaTrader 5, поддается оптимизации, что для целей нашей статьи крайне важно. К тому же, нам потребуется определенная инфраструктура кодов, которая уже написана для торгового движка CStrategy, поэтому нет необходимости проделывать одну и ту же работу дважды. При этом все исходные коды коэффициента детерминации написаны так, чтобы их легко можно было бы использовать вне CStrategy — например, в сторонних библиотеках или процедурных экспертах.
Чистая прибыль. Как уже было сказано, чистая (или итоговая) прибыль — конечный результат того, что хочет получить трейдер. Чем больше прибыли, тем лучше для нас. Однако не всегда оценка стратегии по ее итоговой прибыли гарантирует успех. Рассмотрим результаты работы стратегии CImpulse 2.0 на паре EURUSD, с периодом тестирования с 2015.01.15 по 2017.10.10:
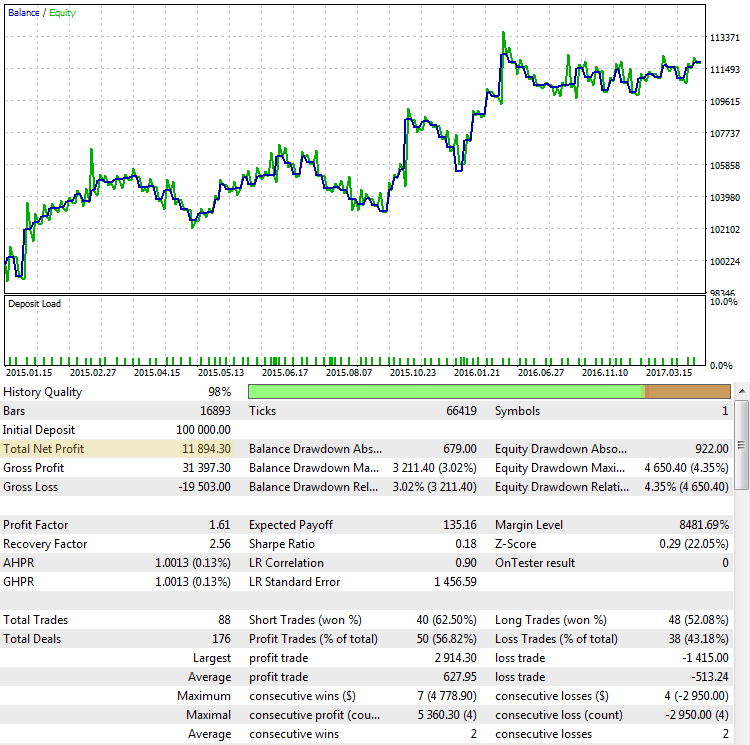
Рис. 2. Стратегия CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 120, StopPercent: 0.67
Как видно, стратегия на этом участке тестирования показывает устойчивый рост итоговой прибыли. Она положительна и составляет 11 894 доллара при торговле одним контрактом. Это хороший результат, но давайте посмотрим, как выглядит другой вариант событий, в котором итоговая прибыль близка к первому случаю:
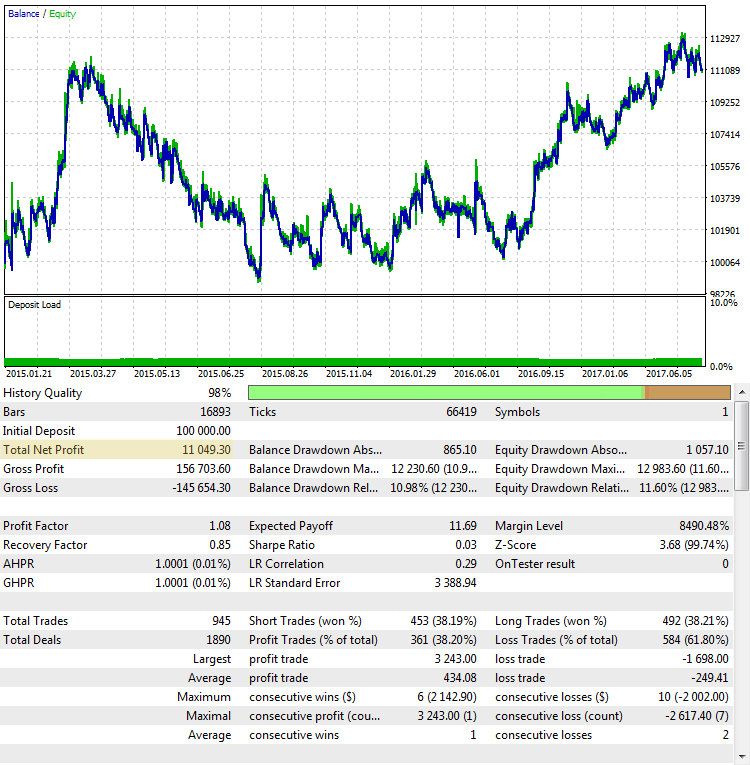
Рис. 3. Стратегия CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 110, StopPercent: 0.24
Несмотря на то, что прибыль в обоих случаях почти одинаковая, можно подумать, что это разные торговые системы. Итоговая прибыль во втором случае и вовсе кажется случайной. Если бы мы закончили тест в середине 2015 года, она была бы около нуля.
Вот еще один неудачный прогон стратегии, чей итоговый результат, тем не менее, тоже очень близок к первому случаю:
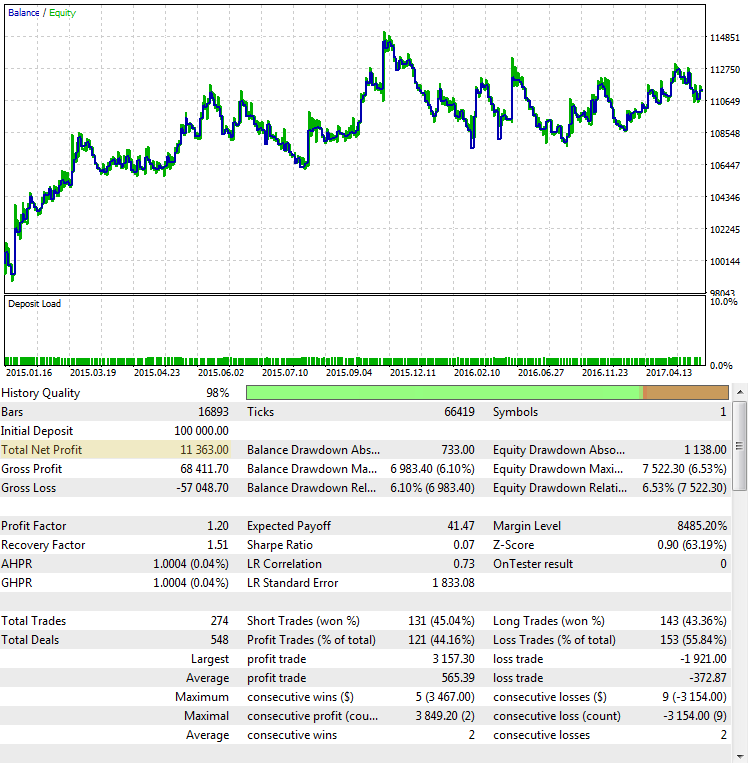
Рис. 4. CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 45, StopPercent: 0.44
На графике хорошо заметно, что основная прибыль была получена в первой половине 2015 года. Затем последовал длительный период стагнации. Такая стратегия — неподходящий кандидат для работы на реальных счетах.
Прибыльность (Profit Factor). Метрика ProfitFactor уже в гораздо меньшей степени зависит от итогового результата. Показатель зависит от каждой сделки и показывает отношение всех выигранных средств ко всем потерянным. Видно, что на рис. 2 ProfitFactor достаточно высок, на рис. 4 он ниже, а на рис. 3 — почти равен границе между прибыльной и убыточной системами. Но, тем не менее, ProfitFactor не является универсальной характеристикой, которую невозможно обмануть. Разберем другие примеры, где показания прибыльности не столь очевидны:
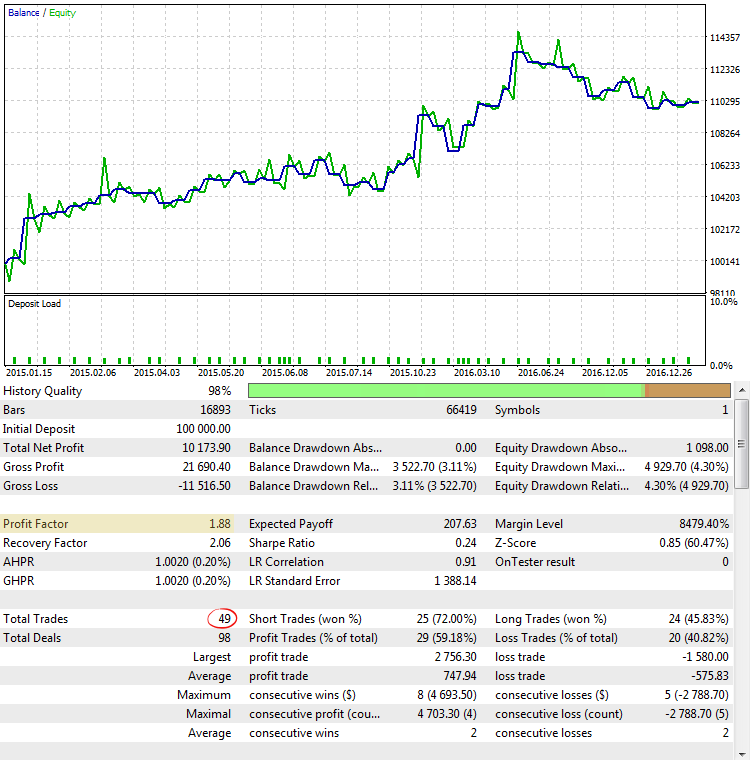
Рис. 5. CImpulse, EURUSD, 1H, 2015.01.15 - 2017.10.01, PeriodMA: 60, StopPercent: 0.82
На рис. 5 мы видим результаты прогона стратегии с одним из самых высоких показателей ProfitFactor. График баланса выглядит весьма неплохо, но полученная статистика вводит нас в заблуждение, ведь из-за очень небольшого количества сделок показания ProfitFactor завышены.
Проверим это утверждение двумя способами. Первый способ: выясним зависимость ProfitFactor от количества сделок. Для этого оптимизируем стратегию CImpulse в тестере стратегий на широком диапазоне параметров:

Рис. 6. Оптимизация CImpulse на широком диапазоне параметров
Cохраним результаты оптимизации:
Рис. 7. Экспорт результатов оптимизации
Теперь можно построить график зависимости показателя ProfitFactor от количества сделок. Например, в Excel для этого достаточно выделить соответствующие столбцы, и нажать кнопку построения точечной диаграммы на вкладке Диаграммы:
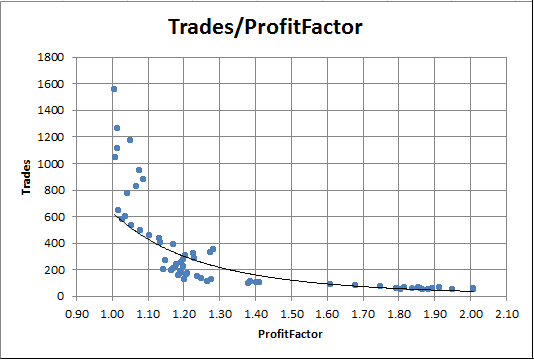
Рис. 8. Зависимость ProfitFactor от количества сделок
На графике четко видно, что в прогонах с высокой прибыльностью всегда очень мало сделок. И наоборот, при большом количестве сделок прибыльность практически равна единице.
Второй способ определить, что показания ProfitFactor'a в данном случае зависят от количества сделок, а не от качества стратегии, связан с проведением тестирования вне выборки (Out Of Sample или OOS). Кстати, это один из самых надежных способов определения робастности полученных результатов. Робастность — мера устойчивости статистического метода в оценках. Тестировать методом OOS эффективно не только ProfitFactor, но и другие показатели. Для наших целей выберем те же параметры, но другое временное окно — с 2012.01.01 по 2015.01.01:
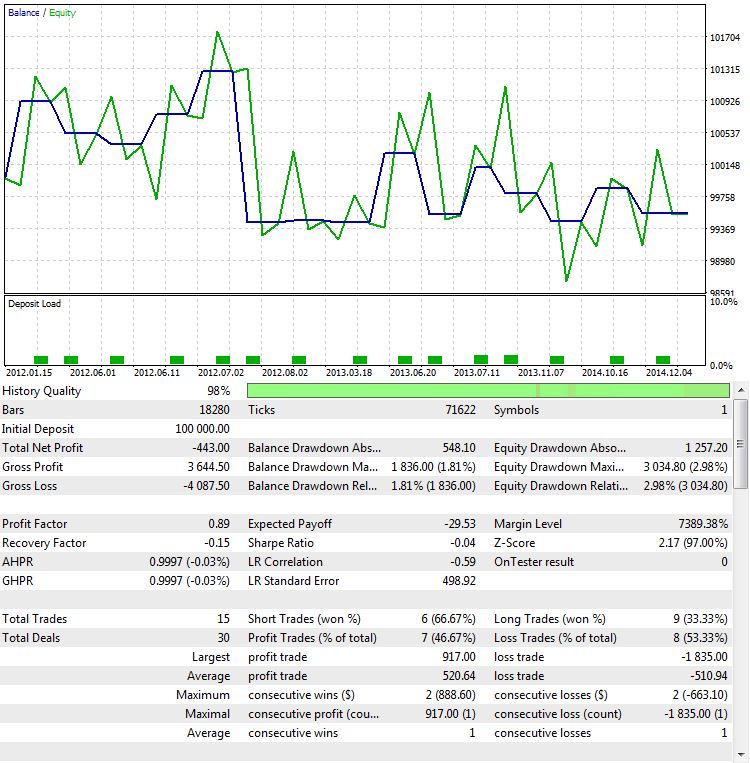
Рис. 9. Тестирование стратегии вне выборки
Как видно, поведение стратегии становится диаметрально противоположным. Вместо прибыли она генерирует убыток. Это закономерный итог, ведь при таком малом количестве сделок мы практически всегда получаем случайный результат. Это значит, что случайный выигрыш в одном временном периоде компенсируется проигрышем в другом, что хорошо иллюстрирует рис. 9.
Математическое ожидание выигрыша. Не будем долго останавливаться на этом параметре, т.к. его слабые места аналогичны ProfitFactor'у. Вот график зависимости матожидания от количества сделок:
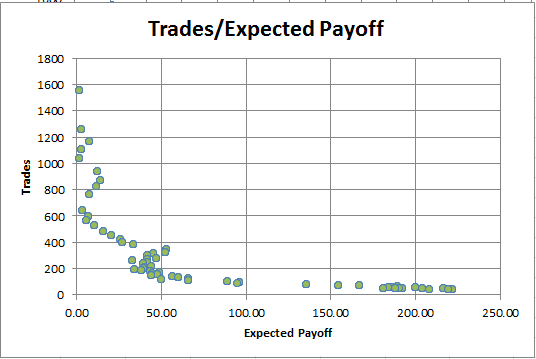
Рис. 10. Зависимость математического ожидания от количества сделок
Видим, что чем больше совершается сделок, тем меньше математическое ожидание. Эта зависимость всегда соблюдается как для прибыльных, так и для убыточных стратегий. Поэтому матожидание не может служить единственным критерием оптимальности TC.
Требования к критерию тестирования торговой системы
Рассмотрев основные критерии статистической оценки торговой системы, мы делаем вывод, что у каждого критерия есть ограничения по применению, и для каждого можно подобрать контрпример, где статистика будет показывать хороший результат, а сама стратегия — нет.
Идеальных критериев, определяющих робастность торговой системы, не бывает. Но можно сформулировать свойства, которыми должен обладать сильный статистический критерий.
- Независимость по отношению к длительности тестируемого периода. Многие параметры торговой стратегии зависят от того, насколько долог период тестирования. Например, чем больше тестируемый период для прибыльной стратегии, тем больше итоговая прибыль. Зависит от длительности и фактор восстановления. Он рассчитывается как отношение итоговой прибыли к максимальной просадке. Поскольку от периода зависит прибыль, то и фактор восстановления тоже растет с увеличением периода тестирования. Инвариантность (независимость) по отношению к периоду нужна, чтобы сравнивать эффективность разных стратегий на разных периодах тестирования;
- Независимость от конечной точки тестирования. Например, если стратегия "играет" на том, что просто-напросто пересиживает убытки, конечная точка тестирования может кардинально менять итоговый баланс. Если тестирование завершено в момент такого "пересиживания", вариационный убыток (equity) становится балансом, и на счете образуется значимая просадка. Показатель должен быть защищен от таких махинаций и давать объективную картину работы торговой системы.
- Простота интерпретации. Все параметры торговой системы являются количественными, т.е. каждый показатель характеризует конкретная цифра. Эта цифра должна быть интуитивно понятна. Чем проще интерпретация полученного значения, тем параметр более доступен для восприятия. Также желательно, чтобы параметр находился в определенных границах, поскольку анализировать большие и потенциально бесконечные числа бывает очень сложно.
- Репрезентативные результаты при малом количестве сделок. Это, пожалуй, самое сложное требование в списке характеристик хорошей метрики. Все статистические методы зависят от количества измерений. Чем их больше, тем более устойчива получаемая статистика. Полностью решить эту проблему на малой выборке, конечно же, нельзя. Однако можно сгладить эффекты, проявляющиеся из-за недостатка данных. Для этого целей мы разработаем два вида функции оценки R-квадрат: одна реализация будет строить этот критерий на основе имеющихся сделок, другая — рассчитает критерий на основе незафиксированной прибыли стратегии (equity).
Прежде чем непосредственно перейти к описанию коэффициента детерминации R^2, разберемся подробнее с его компонентами. Так мы поймем смысл этого параметра и принципы, на которых он построен.
Линейная регрессия
Линейной регрессией называется линейная зависимость одной переменной y от другой независимой переменной x, выраженная формулой y = ax+b. В этой формуле а — множитель, b — коэффициент смещения. В действительности независимых переменных может быть несколько, и такую регрессионную модель называют мультирегрессионной. Однако мы рассмотрим только самый простой случай.
Линейную зависимость можно наглядно представить в виде простого графика. Возьмем дневной график EURUSD с 2017.06.21 по 2017.09.21. Этот участок выбран не случайно: именно в этот период времени на этой валютной паре наблюдался умеренный восходящий тренд. В MetaTrader это выглядит так:
Рис. 11. Ценовая динамика EURUSD с 21.06.2017 по 21.08.2017, дневной таймфрейм
Сохраним эти ценовые данные и построим на их основе график, например, в Excel:
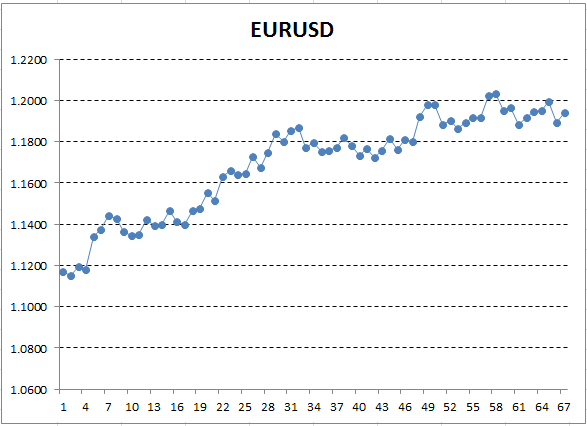
Рис. 12. Курс EURUSD (цены закрытия) в виде графика в Excel
Ось Y здесь соответствует цене, а ось X — порядковому номеру измерения (на порядковые номера мы заменили даты). На полученном графике восходящий тренд виден невооруженным глазом, однако нам надо получить количественную интерпретацию этого тренда. Простейший способ — провести прямую линию, которая наиболее точно будет подогнана под исследуемый тренд. Она и называется линейной регрессией. Например, провести линию можно так:
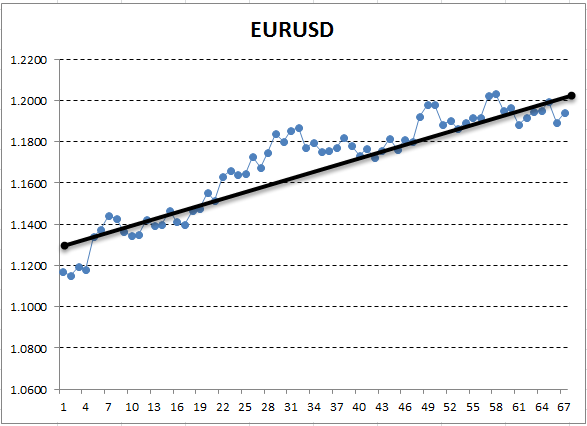
Рис. 13. Линейная регрессия описывающая восходящий тренд, проведенная вручную
Если график достаточно ровный, можно провести такую линию, от которой его точки отклоняются на минимальное расстояние. И напротив, для графика с большой амплитудой нельзя подобрать линию, которая бы точно описывала изменения на нем. Связано это с тем, что у линейной регрессии всего два коэффициента. Действительно, из курса геометрии мы знаем, что для построения прямой достаточно всего двух точек. Благодаря этому, прямую линию непросто подстроить под "кривой" график. Это ценное свойство, которое нам поможет в дальнейшем.
Но как выяснить, как правильно провести прямую? С помощью математических методов можно оптимально рассчитать коэффициенты линейной регрессии так образом, что все имеющиеся точки будут иметь минимальную сумму расстояний до этой линии. Поясним это на следующим графике. Допустим у нас есть 5 произвольных точек и две линии, которые проходят через них. Из них нужно выбрать ту, чья сумма расстояний до точек будет меньше:
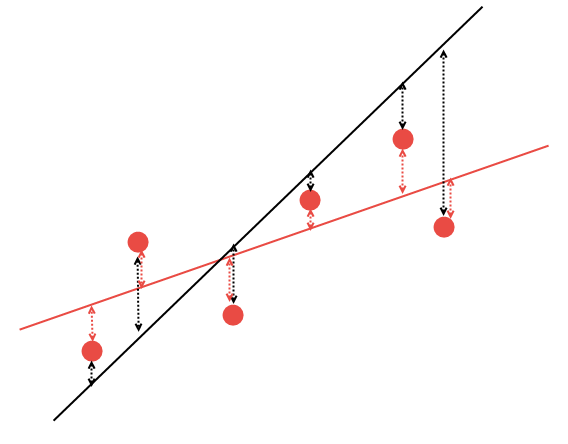
Рис. 14. Выбор наиболее подходящей линейной регрессии
Очевидно, что из двух вариантов линейной регрессии красная прямая лучше описывает наши данные: точки №2 и №6 существенно ближе к красной линии, чем к черной. Остальные точки приблизительно равноудалены как от черной, так и от красной линии. Математически можно рассчитать координаты линии, которая будет лучше всего описывать эту закономерность. Не будем рассчитывать эти коэффициенты самостоятельно, а воспользуемся готовой математической библиотекой AlgLib.
Корреляция
После того, как линейная регрессия рассчитана, нам надо рассчитать корреляцию между этой линией и данными, на которых она рассчитывается. Корреляция — это статистическая взаимосвязь двух и более случайных величин. Случайность величин в данном случае означает, что измерения этих величин не зависят друг от друга. Корреляция измеряется от -1.0 до +1.0. Значение, близкое к нулю, означает, что взаимосвязи между измеряемыми величинами нет. Значение +1.0 указывает на прямую зависимость, -1.0 — на обратную. Корреляцию рассчитывают по нескольким разным формулам. Мы воспользуемся коэффициентом корреляции Пирсона:
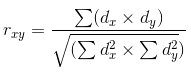
dx и dy в формуле соответствуют дисперсиям, рассчитанным для случайных величин x и y. Дисперсия — это мера вариации признака. В самых общих чертах ее можно описать как сумму квадратов расстояний между данными и линейной регрессией.
Коэффициент корреляции данных с их линейной регрессией показывает, насколько хорошо прямая линия описывает эти данные. Если точки данных находятся на большом расстоянии от линии, то дисперсия высокая, а корреляция — низкая, и наоборот. Интерпретировать корреляцию очень легко: нулевое значение говорит о том, что взаимосвязь между регрессией и данными отсутствует; значение, приближающееся к единице — о том, что есть сильная прямая зависимость.
В отчете терминала MetaTrader есть специальная статистическая метрика. Она называется LR Correlation и показывает корреляцию между линией баланса и линейной регрессией, найденной для этой линии. Если линия баланса ровная — то и приближение к прямой линии будет хорошим. В этом случае коэффициент LR Correlation будет близок к 1.0 или, по крайней мере, выше 0.5. Если линия баланса будет нестабильной — значит, подъемы будут перемежаться спадами, а коэффициент корреляции стремится к нулю.
LR Correlation — интересный параметр. Но в статистике не принято напрямую, через коэффициент корреляции, сравнивать данные и описывающую их регрессию. Причину этого мы обсудим в следующем разделе.
Коэффициент детерминации R^2
Способ расчета коэффициента детерминации R^2 аналогичен способу расчета LR Correlation. Но итоговое число дополнительно возводится в квадрат. Оно может принимать значения от 0.0 до +1.0. Эта цифра показывает долю объясненных значений от общей выборки. В качестве объясняющей модели служит линейная регрессия. Строго говоря, объясняющей моделью не обязательно может быть линейная регрессия, можно использовать и другие. Но только для линейной модели показания R^2 не требуют дальнейшей обработки. В более сложных моделях, как правило, аппроксимация лучше и значения R^2 требуется дополнительно занижать специальными "штрафами" для более адекватной оценки.
Разберемся подробнее с тем, что показывает объясняющая модель. Для этого проведем небольшой эксперимент: воспользуемся специализированным языком программирования R-Project и сгенерируем случайное блуждание, для которого рассчитаем требуемый коэффициент. Случайное блуждание — это процесс, чьи характеристики весьма схожи с реальными финансовыми инструментами. Чтобы его получить, достаточно последовательно складывать несколько случайных чисел, распределенных по нормальному закону.
Исходный код на языке программирования R, с подробным объяснением того, что мы делаем:
x <- rnorm(1000) # Сгенерируем 1000 случайных чисел, распределенных между собой по нормальному закону распределения # Их дисперсия равна единице, а математическое ожидание нулю rwalk <- cumsum(x) # Кумулятивно просуммируем эти числа, получив классический график случайного блуждания plot(rwalk, type="l", col="darkgreen") # Отобразим данные в виде линейного графика rws <- lm(rwalk~c(1:1000)) # Построим линейную модель y=a*x+b, где x - номер измерения, а y — значение вектора сгенерированного блуждания title("Line Regression of Random Walk") abline(rws) # Отобразим получившуюся линейную регрессию на графике
Функция rnorm каждый раз возвращает разные данные, поэтому если вы захотите повторить данный эксперимент, то вид графика у вас будет иным.
Результат выполнения представленного кода:

Рис. 15. Случайное блуждание и линейная регрессия для него.
Получившийся график похож на график произвольного финансового инструмента. Мы рассчитали линейную регрессию для него и вывели в виде черной линии на графике. На первый взгляд, она весьма посредственно описывает динамику случайного блуждания. Но нам нужна количественная оценка качества линейной регрессии. Для этого воспользуемся функцией summary, которая выводит обобщенную статистику по регрессионной модели:
summary(rws) Call: lm(formula = rwalk ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.038404 0.001013 37.92 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.5903, Adjusted R-squared: 0.5899 F-statistic: 1438 on 1 and 998 DF, p-value: < 2.2e-16
Здесь нас больше всего интересует одно число — R-squared или R-квадрат. Эта метрика показывает значение 0.5903. Следовательно, линейная регрессия объясняет 59,03% всех значений, а остальные 41% остаются необъясненными.
Это очень чувствительный показатель, хорошо реагирующий на ровную гладкую линию данных. Чтобы проиллюстрировать сказанное, продолжим наш эксперимент: внесем в наши случайные данные устойчивую компоненту роста. Для этого изменим среднее значение или математическое ожидание на величину, равную 1/20 дисперсии первоначальных сгенерированных данных:
x_trend1 <- x+(sd(x)/20.0) # Найдем стандартное отклонение значений x, разделим его на 20.0 и полученную величину прибавим к каждому значению x # Каждое такое измененное значение x будет храниться в новом векторе значений x_trend1 rwalk_t1 <- cumsum(x_trend1) # Кумулятивно просуммируем эти числа, получив график смещенного случайного блуждания plot(rwalk_t1, type="l", col="darkgreen") # Отобразим данные в виде линейного графика title("Line Regression of Random Walk #2") rws_t1 <- lm(rwalk_t1~c(1:1000))# Построим линейную модель y=a*x+b, где x - номер измерения, а y — значение вектора сгенерированного блуждания abline(rws_t1) # Отобразим получившуюся линейную регрессию на графике
Получившийся график уже гораздо ближе к прямой линии:
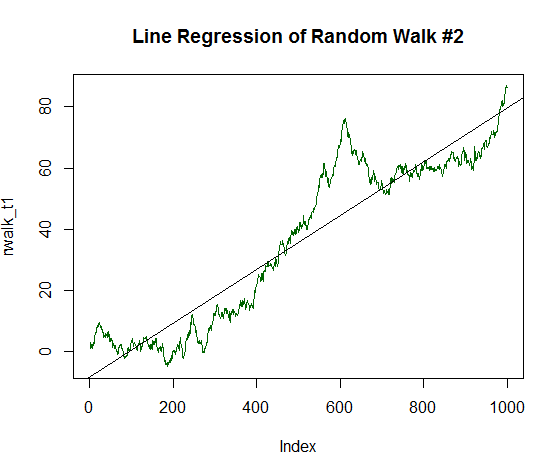
Рис. 16. Случайное блуждание c положительным математическим ожиданием, равным 1/20 его дисперсии.
Статистика по нему следующая:
summary(rws_t1) Call: lm(formula = rwalk_t1 ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.087854 0.001013 86.75 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.8829, Adjusted R-squared: 0.8828 F-statistic: 7526 on 1 and 998 DF, p-value: < 2.2e-16
Как видно, R-квадрат уже значительно выше и показывает значение 0.8829. Не будем останавливаться на достигнутом, увеличим детерминированную компоненту нашего графика в два раза, до величины 1/10 стандартного отклонения первоначальных значений. Код этой обработки аналогичен предыдущему, но делить нужно на 10.0 а не на 20.0. Новый график уже почти полностью напоминает прямую линию:
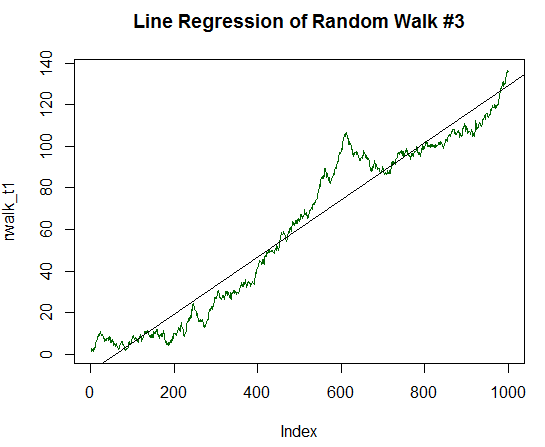
Рис. 17. Случайное блуждание c положительным математическим ожиданием, равным 1/10 его дисперсии.
Рассчитаем его статистику:
Call: lm(formula = rwalk_t1 ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 4 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.137303 0.001013 135.59 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.9485, Adjusted R-squared: 0.9485 F-statistic: 1.838e+04 on 1 and 998 DF, p-value: < 2.2e-16
R-квадрат стал еще выше и составил 0.9485. Этот график уже очень сильно напоминает динамику баланса желанной прибыльной торговой стратегии. Но не будем останавливаться на достигнутом. Увеличим математическое ожидание до 1/5 стандартного отклонения:
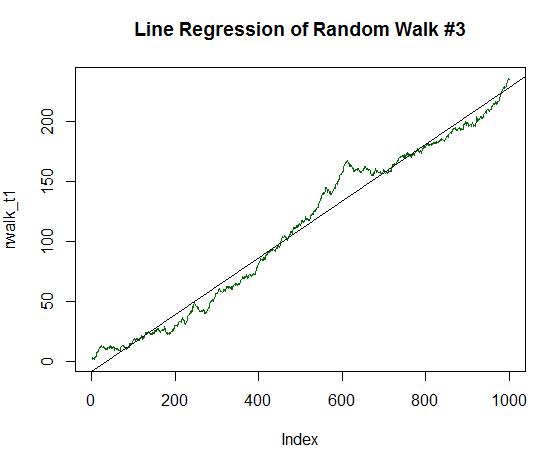
Рис. 18. Случайное блуждание c положительным математическим ожиданием, равным 1/5 его дисперсии.
Его статистика следующая:
Call: lm(formula = rwalk_t1 ~ c(1:1000)) Residuals: Min 1Q Median 3Q Max -16.082 -6.888 -1.593 4.174 30.787 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -8.187185 0.585102 -13.99 <2e-16 *** c(1:1000) 0.236202 0.001013 233.25 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.244 on 998 degrees of freedom Multiple R-squared: 0.982, Adjusted R-squared: 0.982 F-statistic: 5.44e+04 on 1 and 998 DF, p-value: < 2.2e-16
Как видно, R-квадрат уже практически равен единице. На графике невооруженным глазом заметно, что наши случайные данные в виде зеленой линии практически полностью ложатся на ровную прямую линию.
Теорема арксинуса и ее вклад в оценку линейной регрессии
Существует математическое доказательство того, что случайный процесс со временем все дальше удаляется от своей первоначальной точки. Оно получило название первой и второй теорем арксинуса. Мы не будем их подробно описывать, определим лишь следствие этих теорем.
Исходя из них, тренды в случайных процессах скорее неизбежны, чем маловероятны. Иными словами, случайных трендов на таких процессах наблюдается больше, чем случайных флуктуаций вблизи первоначальной точки. Это очень важное свойство, которое дает существенный вклад в оценку статистических метрик. Особенно это заметно для коэффициента линейной регрессии (LR Correlation). Тренды лучше описываются линейной регрессией, чем флэты. Связано это с тем, что тренды содержат больше движения в одну сторону, которое похоже на ровную линию.
Раз трендов в случайных процессах больше, чем флэтов — следовательно, и LR Correlation в целом будет завышать свои значения. Чтобы убедиться в этом неочевидном эффекте, попробуем сгенерировать 10000 независимых случайных блужданий, с дисперсией 1.0 и нулевым математическим ожиданием. Рассчитаем для каждого такого графика LR Correlation, а затем построим распределение этих значений. Для этих целей напишем простой тестовый скрипт на языке программирования R:
sample_r2 <- function(samples = 100, nois = 1000) { lags <- c(1:nois) r2 <- 0 # R^2 rating lr <- 0 # Line Correlation rating for(i in 1:samples) { white_nois <- rnorm(nois) walk <- cumsum(white_nois) model <- lm(walk~lags) summary_model <- summary(model) r2[i] <- summary_model$r.squared*sign(walk[nois]) lr[i] <- (summary_model$r.squared^0.5)*sign(walk[nois]) } m <- cbind(r2, lr) }
Наш скрипт рассчитывает как LR Correlation, так и R^2. Разницу между ними мы увидим чуть позже. В скрипт внесено небольшое дополнение. Получившийся коэффициент корреляции мы будем умножать на итоговый знак синтетического графика. Если мы закончили с результатом меньше нуля, корреляция будет отрицательной, если больше — положительной. Сделано это для того, чтобы легко и быстро отделить отрицательные исходы от положительных, не прибегая при этом к другим статистикам. Именно так работает LR Correlation в MetaTrader 5, по такому же принципу будет строиться и R^2.
Итак, построим распределение LR Correlation для 10 000 независимых примеров, каждый из которых состоит из 1 000 измерений:
ms <- sample_r2(10000, nois=1000) hist(ms[,2], breaks = 30, col="darkgreen", density = 30, main = "Distribution of LR-Correlation")
Получившийся график явно свидетельствует о верности нашего определения:
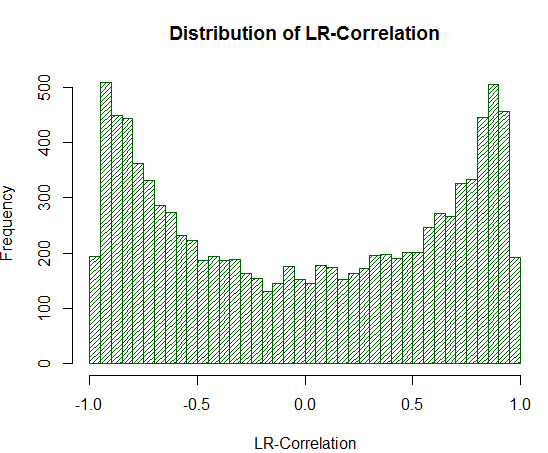
Рис. 19. Распределение LR-Correlation для 10 000 случайных блужданий
Как видно из эксперимента, значения LR-Correlation существенно завышены в области +/- 0.75 - 0.95. Это означает, что LR-Correlation довольно часто ложно дает высокую положительную оценку там, где ее не должно быть.
Теперь рассмотрим, как ведет себя R^2 на той же самой выборке:
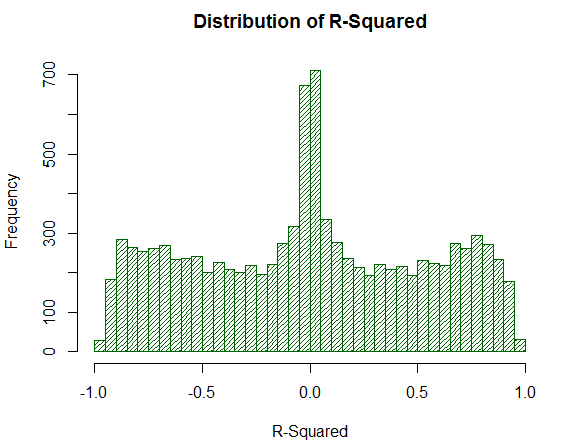
Рис. 20. Распределение R^2 для 10 000 случайных блужданий
Значение R-квадрат уже не завышено, хотя его распределение равномерно. Удивительно то, что простым математическим действием (возведением во вторую степень) мы полностью убрали нежелательные краевые эффекты распределения. Именно по этой причине анализировать LR-Correlation напрямую нельзя — необходимо дополнительное математическое преобразование. Также обратите внимание, что R^2 значительную долю анализируемых виртуальных балансов стратегий перемещает в точку вблизи нуля, в то время как LR-Correlation дает им устойчивые средние оценки. Это положительное свойство.
Сбор эквити стратегии
Теперь, когда мы разобрали теорию, нам осталось реализовать R-квадрат в терминале MetaTrader. Конечно, мы могли бы пойти простым путем и рассчитать его для исторических сделок. Однако мы введем дополнительное улучшение. Как уже было сказано, любой статистический параметр должен быть устойчив к малому количеству сделок. К сожалению R-квадрат, как и любая другая статистика, может необоснованно завышать свое значение, если сделок на счете мало. Чтобы этого избежать, рассчитаем его на значениях equity — незафиксированной прибыли. Идея в том, что если советник совершает всего 20 сделок за год, то очень трудно понять, насколько он эффективен. Скорее всего, его результат случаен. Но если измерять состояния баланса этого советника с заданной периодичностью — например, один раз в час, то точек для построения статистики наберется уже достаточное количество. В данном случае это будет больше 6 000 измерений.
Кроме того, такое измерение противодействует системам, которые не фиксируют свой вариационный убыток, скрывая его. Эквити стратегии проседает, а баланс — нет. Статистика, рассчитанная по балансу, не сигнализирует о наступлении проблем. Однако метрика, рассчитанная с учетом незафиксированной прибыли/убытка, отразит объективную ситуацию со счетом.
Эквити стратегии соберем необычным способом. Дело в том, что для сбора этих значений надо учитывать два основных момента:
- Частоту сбора статистики
- Определение событий, при поступлении которых надо делать проверку средств.
Например, торговый эксперт работает только по таймеру, на таймфрейме H1. Тестируется он в режиме "Только цены открытия". Следовательно, для такого эксперта нельзя собирать данные чаще, чем раз в час, а скрининг этих данных можно делать только при событии OnTimer. Самым эффективным решением будет просто воспользоваться мощью движка CStrategy. Дело в том, что CStrategy собирает все события в единый обработчик событий, а отслеживание нужного таймфрейма в нем происходит автоматически. Таким образом, оптимальным решением будет написать специальный агент-стратегию, которая рассчитывает всю нужную статистику. Создавать ее будет менеджер стратегий CManagerList. Класс будет добавлять в список стратегий своего агента, а тот будет следить за изменениями на счете.
Приведем исходный код этого агента:
//+------------------------------------------------------------------+ //| UsingTrailing.mqh | //| Copyright 2017, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2017, Vasiliy Sokolov." #property link "https://www.mql5.com" #include "TimeSeries.mqh" #include "Strategy.mqh" //+------------------------------------------------------------------+ //| Интегрируется в виде эксперта в портфель стратегий и записывает | //| эквити портфеля | //+------------------------------------------------------------------+ class CEquityListener : public CStrategy { private: //-- Частота, с которой происходит запись CTimeSeries m_equity_list; double m_prev_equity; public: CEquityListener(void); virtual void OnEvent(const MarketEvent& event); void GetEquityArray(double &array[]); }; //+------------------------------------------------------------------+ //| Установка частоты по умолчанию | //+------------------------------------------------------------------+ CEquityListener::CEquityListener(void) : m_prev_equity(EMPTY_VALUE) { } //+------------------------------------------------------------------+ //| Осуществляет сбор эквити портфеля, отслеживая все возможные | //| события | //+------------------------------------------------------------------+ void CEquityListener::OnEvent(const MarketEvent &event) { if(!IsTrackEvents(event)) return; double equity = AccountInfoDouble(ACCOUNT_EQUITY); if(equity != m_prev_equity) { m_equity_list.Add(TimeCurrent(), equity); m_prev_equity = equity; } } //+------------------------------------------------------------------+ //| Возвращает эквити в виде массива double | //+------------------------------------------------------------------+ void CEquityListener::GetEquityArray(double &array[]) { m_equity_list.ToDoubleArray(0, array); }
Собственно, сам агент состоит из двух методов: переопределенного OnEvent и метода возврата значений equity. Наиболее интересен здесь класс CTimeSeries, который впервые появился в составе CStrategy. Он представляет собой простую таблицу, данные в которую добавляются в формате: дата, значение, номер колонки. Все значения хранятся в отсортированном по времени состоянии, а доступ к нужной дате осуществляется через бинарный поиск, что существенно ускоряет работу с коллекцией. Метод OnEvent проверяет, является ли текущее событие открытием нового бара, и если это так, то просто запоминает новое значение эквити.
R^2 реагирует на ситуацию, когда сделок нет в течение длительного времени. В такие моменты будут записываться значения эквити, в которых нет изменений. На графике equity образуется так называемая "лесенка". Чтобы этого избежать, в методе делается сравнение с предыдущим значением. Если значения совпадают — запись пропускается. Таким образом, в список попадают только изменения в эквити.
Интегрируем этот класс в движок CStrategy. Интеграцию будем производить сверху, на уровне CStrategyList. Это подходящий модуль для расчета пользовательской статистики. Пользовательских статистик может быть несколько, поэтому введем перечисление, определяющее возможные типы статистики:
//+------------------------------------------------------------------+ //| Определяет тип пользовательского критерия рассчитываемого | //| после оптимизации. | //+------------------------------------------------------------------+ enum ENUM_CUSTOM_TYPE { CUSTOM_NONE, // Пользовательский критерий не рассчитывается CUSTOM_R2_BALANCE, // R^2, рассчитанный на балансе стратегии CUSTOM_R2_EQUITY, // R^2, рассчитанный на equity стратегии };
Из перечисления видно, что у пользовательского критерия оптимизации есть три типа: R-квадрат, рассчитанный по результатам сделок, R-квадрат, рассчитанный на данных equity и отсутствие расчета статистики.
Добавить возможность конфигурирования типа пользовательского расчета. Для этого снабдим класс CStrategyList дополнительными методами SetCustomOptimaze*:
//+------------------------------------------------------------------+ //| Устанавливает R^2 в качестве критерия оптимизации. Коэффициент | //| рассчитывается для совершенных сделок. | //+------------------------------------------------------------------+ void CStrategyList::SetCustomOptimizeR2Balance(ENUM_CORR_TYPE corr_type) { m_custom_type = CUSTOM_R2_BALANCE; m_corr_type = corr_type; } //+------------------------------------------------------------------+ //| Устанавливает R^2 в качестве критерия оптимизации. Коэффициент | //| рассчитывается на запомненной эквити. | //+------------------------------------------------------------------+ void CStrategyList::SetCustomOptimizeR2Equity(ENUM_CORR_TYPE corr_type) { m_custom_type = CUSTOM_R2_EQUITY; m_corr_type = corr_type; }
Каждый из этих методов устанавливает свою настройку внутренней переменной ENUM_CUSTOM_TYPE m_custom_type и второй параметр, равный типу корреляции ENUM_CORR_TYPE:
//+------------------------------------------------------------------+ //| Тип корреляции | //+------------------------------------------------------------------+ enum ENUM_CORR_TYPE { CORR_PEARSON, // Корреляция Пирсона CORR_SPEARMAN // Ранговая корреляция Спирсена };
Об этом дополнительном параметре необходимо сказать отдельно. Дело в том, что R^2 — не что иное, как корреляция между графиком и его линейной моделью. Однако сам тип корреляции может различаться. Используем математическую библиотеку AlgLib. Она поддерживает два метода расчета корреляции: по Пирсону и по Спирману. Формула Пирсона классическая и хорошо подходит для однородных, нормально распределенных данных. Ранговая корреляция Спирмана более устойчива к ценовым выбросам, которые часто встречаются на рынке. Поэтому наш расчет будет позволять работать с каждым вариантом расчета R2.
Теперь, когда все данные подготовлены, приступим к непосредственному расчету R^2. Вынесем его в отдельные функции:
//+------------------------------------------------------------------+ //| Возвращает оценку R^2, рассчитанную на основе баланса стратегии | //+------------------------------------------------------------------+ double CustomR2Balance(ENUM_CORR_TYPE corr_type = CORR_PEARSON); //+------------------------------------------------------------------+ //| Возвращает оценку R^2, рассчитанную на основе equity стратегии | //| Значения equity передается в качестве массива equity | //+------------------------------------------------------------------+ double CustomR2Equity(double& equity[], ENUM_CORR_TYPE corr_type = CORR_PEARSON);
Они будут располагаться в отдельном файле RSquare.mqh. Расчет выполнен в виде функций, чтобы любой пользователь мог легко и быстро подключить этот режим расчета в свой проект. При этом использовать CStrategy не нужно. Например, чтобы рассчитать R^2 в своем эксперте, достаточно переопределить системную функцию OnTester:
double OnTester() { return CustomR2Balance(); }
Конечно, когда потребуется вычислить эквити стратегии, пользователю не применяющему CStrategy, придется сделать это самостоятельно.
Последнее, что нам осталось выполнить в CStrategyList, — определить метод OnTester:
//+------------------------------------------------------------------+ //| Добавляет мониторинг equity | //+------------------------------------------------------------------+ double CStrategyList::OnTester(void) { switch(m_custom_type) { case CUSTOM_NONE: return 0.0; case CUSTOM_R2_BALANCE: return CustomR2Balance(m_corr_type); case CUSTOM_R2_EQUITY: { double equity[]; m_equity_exp.GetEquityArray(equity); return CustomR2Equity(equity, m_corr_type); } } return 0.0; }
Теперь рассмотрим реализацию функций CustomR2Equity и CustomR2Balance.
Расчет коэффициента детерминации R^2 с помощью AlgLib
Реализуем коэффициент детерминации R^2 с помощью AlgLib — кроссплатформенной библиотеки численного анализа. С ее помощью можно рассчитать разнообразные статистические критерии, от простых до самых продвинутых.
Перечислим шаги расчета коэффициента.
- Получим значения equity и сконвертируем их в матрицу M[x, y], где x — номер измерения, y — значение эквити.
- Для полученной матрицы рассчитаем коэффициенты a и b уравнения линейной регрессии.
- Сгенерируем значения линейной регрессии для каждого X и поместим их в массив.
- Найдем коэффициент корреляции линейной регрессии и значений equity, используя одну из двух формул корреляции.
- Рассчитаем R^2 и его знак.
- Вернем нормализованное значение R^2 вызывающей функции.
Эти шаги выполняет функция CustomR2Equity. Ее исходный код представлен ниже:
//+------------------------------------------------------------------+ //| Возвращает оценку R^2, рассчитанную на основе equity стратегии | //| Значения equity передается в качестве массива equity | //+------------------------------------------------------------------+ double CustomR2Equity(double& equity[], ENUM_CORR_TYPE corr_type = CORR_PEARSON) { int total = ArraySize(equity); if(total == 0) return 0.0; //-- Заполняем матрицу Y - значение equity, X - порядковый номер значения CMatrixDouble xy(total, 2); for(int i = 0; i < total; i++) { xy[i].Set(0, i); xy[i].Set(1, equity[i]); } //-- Находим коэффициенты a и b линейной модели y = a*x + b; int retcode = 0; double a, b; CLinReg::LRLine(xy, total, retcode, a, b); //-- Генерируем значения линейной регрессии для каждого X; double estimate[]; ArrayResize(estimate, total); for(int x = 0; x < total; x++) estimate[x] = x*a+b; //-- Находим коэффициент корреляции значений с их же линейной регрессией double corr = 0.0; if(corr_type == CORR_PEARSON) corr = CAlglib::PearsonCorr2(equity, estimate); else corr = CAlglib::SpearmanCorr2(equity, estimate); //-- Находим R^2 и его знак double r2 = MathPow(corr, 2.0); int sign = 1; if(equity[0] > equity[total-1]) sign = -1; r2 *= sign; //-- Возвращаем нормализованную оценку R^2, с точностью до сотых return NormalizeDouble(r2,2); }
Данный код обращается к трем статистическим методам: CAlgLib::LRLine, CAlglib::PearsonCorr2 и CAlglib::SpearmanCorr2. Основной из них — конечно же, CAlgLib::LRLine, непосредственно рассчитывающий коэффициенты линейной регрессии.
Теперь опишем вторую функцию расчета R^2: CustomR2Balance. Как видно из названия, функция рассчитывает этот показатель на основе совершенных сделок. Вся ее работа заключается в формировании массива double, содержащего динамику баланса, для чего перебираются все исторические сделки:
//+------------------------------------------------------------------+ //| Возвращает оценку R^2, рассчитанную на основе баланса стратегии | //+------------------------------------------------------------------+ double CustomR2Balance(ENUM_CORR_TYPE corr_type = CORR_PEARSON) { HistorySelect(0, TimeCurrent()); double deals_equity[]; double sum_profit = 0.0; int current = 0; int total = HistoryDealsTotal(); for(int i = 0; i < total; i++) { ulong ticket = HistoryDealGetTicket(i); double profit = HistoryDealGetDouble(ticket, DEAL_PROFIT); if(profit == 0.0) continue; if(ArraySize(deals_equity) <= current) ArrayResize(deals_equity, current+16); sum_profit += profit; deals_equity[current] = sum_profit; current++; } ArrayResize(deals_equity, current); return CustomR2Equity(deals_equity, corr_type); }
После того, как массив сформирован, он передается на вход уже знакомой нам функции CustomR2Equity. В самом деле, функция CustomR2Equity универсальна, она рассчитывает значение R^2 для любых данных, содержащихся в массиве equity[], будь то динамика баланса или значения нереализованной прибыли.
Нашим последним шагом будет небольшое изменение в коде советника CImpulse, а именно — переопределение системного события OnTester:
//+------------------------------------------------------------------+ //| Tester event | //+------------------------------------------------------------------+ double OnTester() { Manager.SetCustomOptimizeR2Balance(CORR_PEARSON); return Manager.OnTester(); }
В этой функции устанавливается тип пользовательского параметра, а затем возвращается его значение.
Теперь мы можем видеть наш расчетный коэффициент в действии. После запуска бэктеста стартегии CImpulse наш параметр появится в отчете:
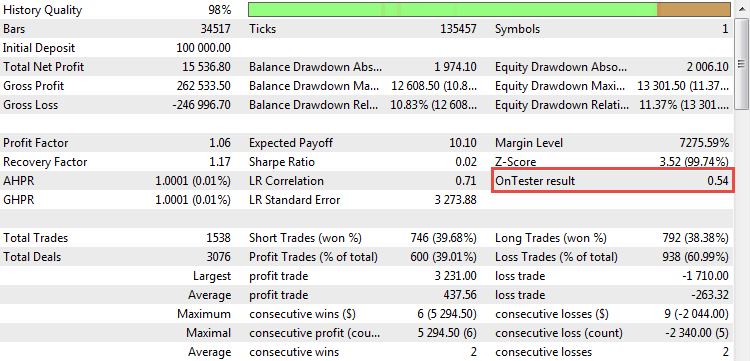
Рис. 21. Значение R^2 в качестве пользовательского критерия оптимизации
Использование параметра R-квадрат на практике
Теперь, когда R-квадрат встроен в качестве пользовательского критерия оптимизации, настало время опробовать его на практике. Для этого оптимизируем CImpulse на таймфрейме М15 валютной пары EURUSD. Получившийся отчет оптимизации сохраним в файл Excel, и уже на основе полученных статистик сравним несколько прогонов, выбранных по различным критериям.
Полный список параметров оптимизации приведен ниже:
- Символ: EURUSD
- Таймфрейм: 1H
- Период: 2015.01.03 - 2017.10.10
Диапазон параметров эксперта указан в таблице:
| Параметр | Старт | Шаг | Стоп | Кол-во шагов |
|---|---|---|---|---|
| PeriodMA | 15 | 5 | 200 | 38 |
| StopPercent | 0.1 | 0.05 | 1.0 | 19 |
После проведения оптимизации было получено оптимизационное облако, состоящее из 722 вариантов:
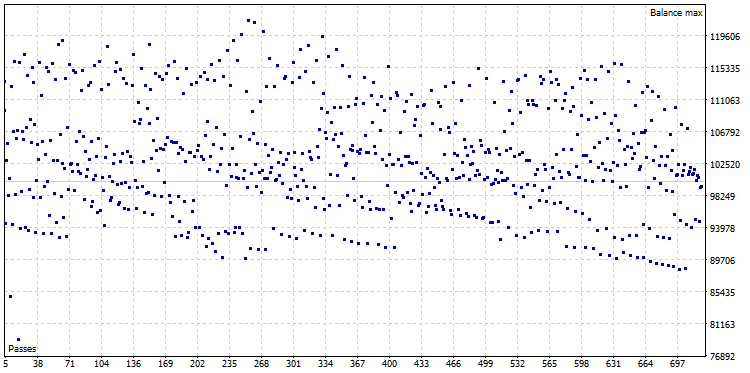
Рис. 22. Оптимизационное облако CImpulse, символ - EURUSD, таймфрейм - 1H
Выберем прогон, чья прибыль максимальна, и отобразим его график баланса:
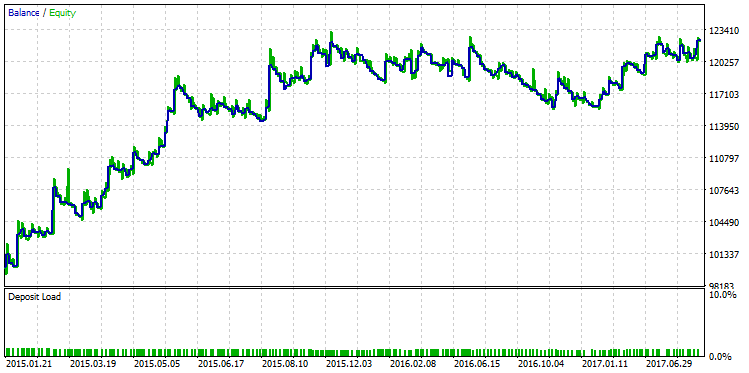
Рис. 23. График баланса стратегии, выбранной по критерию максимальной прибыли
Теперь найдем лучший прогон по параметру R-квадрат. Для этого сохраним прогоны оптимизации в XML-файл. Если на компьютере установлен Microsoft Excel, то файл откроется в нем автоматически. Мы будем работать с сортировкой и фильтрами, поэтому выделим заголовок таблицы и нажмем одноименную кнопку (Главная -> Сортировка и фильтр -> Фильтр), после чего появится возможность гибкого отображения столбцов. Отсортируем прогоны по пользовательскому критерию оптимизации:
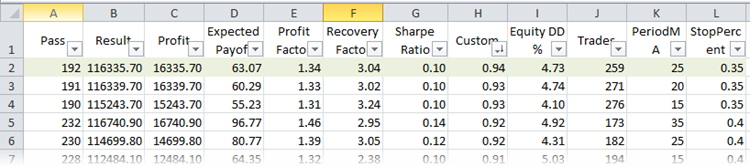
Рис. 24. Прогоны оптимизаций в Microsoft Exce, отсортированные по R-квадрат
Первая строка в таблице будет иметь лучший R-квадрат из всей выборки. Она помечена зеленым цветом на рисунке выше. В тестере стратегий набор этих параметров выдает следующий вид графика баланса:
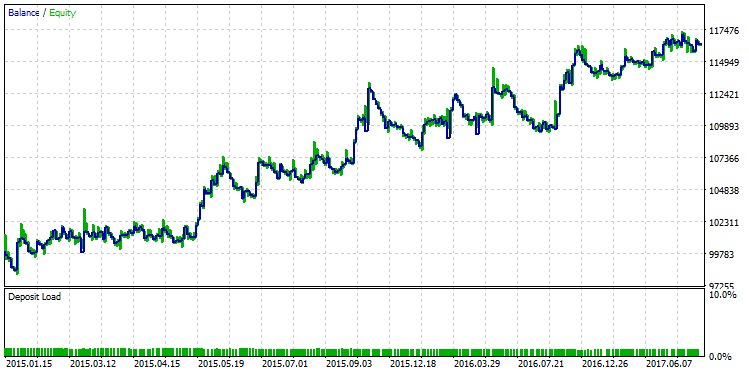
Рис. 25. График баланса стратегии, выбранной по критерию максимального R-квадрат.
Разницу в качестве между этими двумя линиями баланса видно невооруженным глазом. В то время как прогон с максимальной прибылью "надломился" в декабре 2015 года, другой вариант, с максимальным R^2, продолжил устойчивый рост.
Зачастую R^2 зависит от количества сделок, и на малых выборках, как правило, может завышать свои показания. В этом отношении R-квадрат коррелирует с ProfitFactor. На некоторых видах стратегий, высокий показатель ProfitFactor идет рука об руку с высоким значением R^2. Однако это не всегда так. В качестве иллюстрации подберем из выборки контрпример, демонстрирующий разницу между R^2 и ProfitFactor. На рисунке ниже представлен прогон стратегии, имеющий один из самых высоких показателей ProfitFactor, равный 2.98:
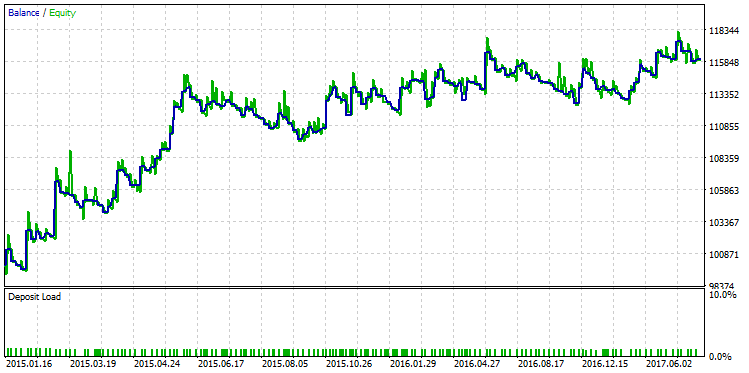
Рис. 26. Прогон стратегии, чей ProfitFactor равен 2.98
На графике видно, что, хотя стратегия и показывает уверенный рост, качество кривой баланса стратегии все равно ниже, чем вариант с максимальным показателем R-квадрат.
Преимущества и ограничения в использовании
Каждая статистическая метрика имеет свои преимущества и недостатки. R-квадрат в этом плане не исключение. В таблице ниже представлены его слабые стороны и решения, которые могут их нивелировать:
| Недостатки | Решение |
|---|---|
| Зависит от количества сделок. Завышает показатели при малом количестве сделок. | Расчет показателя R^2 на значениях equity стратегии частично решает эту проблему. |
| Коррелирует с уже существующими метриками эффективности стратегии, в частности — коррелирует с профит-фактором и чистой прибылью стратегии. | Корреляция не равна 100%. В зависимости от особенностей стратегии, R-квадрат может не коррелировать с любой другой метрикой вовсе, либо коррелировать с ней, но слабо. |
| Для расчета требуются сложные математические вычисления. | Алгоритм реализуется с помощью библиотеки AlgLib, которой и делегируется вся сложность. |
| Применим исключительно для оценки линейных процессов, или систем, торгующих фиксированным лотом. | Не применять для торговых систем, использующих систему капитализации (мани-менеджемент). |
Опишем проблему применения R^2 к нелинейным системам (например, к ТС с динамическим лотом) более развернуто.
Повторюсь, что первостепенная задача каждого трейдера — максимизация прибыли. Необходимое условие для этого — применение различных систем капитализации. Система капитализации — это преобразование линейного процесса в нелинейный — например, в экспоненциальный. Но после такого преобразования большая часть статистических параметров теряет свой смысл. Например, для капитализированных систем бессмысленен параметр "итоговая прибыль", ведь даже незначительное смещение временного отрезка тестирования или изменение параметра стратегии на сотую долю процента может изменить итоговый результат в десятки или даже сотни раз.
Теряют смысл и другие параметры стратегии — такие как профит-фактор, математическое ожидание, наибольший убыток/прибыль и другие. Не исключение в этом смысле и R-квадрат. Созданный для линейной оценки ровности кривой баланса, он становится бессилен в оценке нелинейных процессов. Поэтому любую стратегию надо тестировать в линейном виде, а уже потом добавлять к выбранному варианту систему капитализации. Нелинейные системы лучше оценивать с помощью специальных статистических метрик (таких,как, к примеру, GHPR), или же рассчитывать доходность в годовых процентах.
Заключение
- Стандартные статистические параметры оценки торговых систем имеют известные недостатки, которые необходимо учитывать.
- Из стандартных метрик MetaTrader 5 только LR Correlation призвана оценивать гладкость кривизны баланса стратегии. Однако ее значения часто завышаются.
- R-квадрат — одна из немногих метрик, рассчитывающих гладкость кривой как линии баланса, так и незафиксированной прибыли стратегии. При этом R-квадрат лишен недостатков LR Correlation.
- Для расчета R-квадрат применяется математическая библиотека AlgLib. Сам расчет имеет несколько модификаций и подробно описан в соответствующем примере.
- Пользовательский критерий оптимизации можно встроить в торговый эксперт так, чтобы все эксперты получали возможность расчета этой метрики автоматически, без своего участия. Как это сделать, описано на примере встраивания R-квадрат в торговый движок CStrategy.
- С помощью аналогичного встраивания можно рассчитать дополнительные данные, необходимые для расчета пользовательской статистики. Для R-квадрат такими данными являются данные о незафиксированной прибыли стратегии (equity). Запоминанием динамики незафиксированной прибыли занимается торговый движок CStrategy.
- Коэффициент детерминации позволяет выбрать стратегии с равномерным ростом баланса/equity. При этом процесс выбора, основанный на других параметрах, может пропустить подобные варианты.
- R-квадрат, как и любая другая статистическая метрика, имеет недостатки, которые необходимо учитывать для работы с этим показателем.
Таким образом, можно с уверенностью сказать, что коэффициент детерминации R-квадрат — важное дополнение к уже существующему набору метрик тестирования MetaTrader 5. Он позволяет оценить гладкость кривой линии баланса стратегии, что само по себе является нетривиальным показателем. R-квадрат прост в использовании: его диапазон значений фиксирован и находится в пределах от -1.0 до +1.0, сигнализируя об отрицательной тенденции баланса стратегии (значения близкие к -1.0), отсутствию тенденции (значения близкие к 0.0) и положительном тренде (значения стремящиеся к +1.0). Благодаря всем этим свойствам, надежности и простоте, R-квадрат может быть рекомендован к использованию при построении прибыльной торговой системы.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Индикатор NRTR и торговые модули на его основе для Мастера MQL5
Индикатор NRTR и торговые модули на его основе для Мастера MQL5
 Кроссплатформенный торговый советник: Пользовательские стопы, Безубыток и Трейлинг
Кроссплатформенный торговый советник: Пользовательские стопы, Безубыток и Трейлинг
 Оценка риска в последовательности сделок с одним активом. Продолжение
Оценка риска в последовательности сделок с одним активом. Продолжение
 Мини-эмулятор рынка, или Ручной тестер стратегий
Мини-эмулятор рынка, или Ручной тестер стратегий
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здесь много информации, объясняющей причины и ваш код, и я ценю это. Вот версия Tl;dr для тех из нас, для кого большая часть этого не укладывается в голове:
1. Добавьте инклуды
2. И OnTester:
Вот и все, чтобы реализовать его на основе баланса.
Если ваш советник использует CStrategy (как это делают советники-мастера), то добавьте тот же инклуд, и вы сможете переключиться на эквити следующим образом:
Что я еще НЕ понял и надеюсь, что кто-то сможет мне помочь, так это то, что нужно сделать, чтобы реализовать слушателя эквити в собственном советнике, который не основан на CStrategy. Все, о чем говорится в статье, это:
И я в полной растерянности, как это сделать.Исправил ошибки. Архив прилагаю.
Спасибо, обновил в статье.
Они должны быть очень похожи... сравнение находится в моем длинном неорганизованном списке дел!
Нормализуйте объем: возьмите прибыль и разделите на размер лота.
Или разделите баланс[0] на баланс[1], чтобы получить доходность, и рассчитайте r^2 для кривой доходности