
Redes neuronales en el trading: Segmentación periódica adaptativa (LightGTS)

Introducción
La previsión mediante series temporales ha sido durante mucho tiempo una herramienta clave en numerosos campos, desde la energía y el transporte hasta la sanidad y la educación. Pero precisamente en el sector financiero es donde el valor de cada segundo se puede medir en dinero, donde la precisión de las previsiones cobra una importancia crucial. Aquí no hay margen de error: el más mínimo fallo en el modelo y la estrategia entra en números rojos.
Los enfoques tradicionales, ya sean estadísticos o de aprendizaje profundo, suelen basarse en el principio de un problema, un modelo. Estas soluciones funcionan bien en entornos aislados, pero en la práctica, los mercados financieros se comportan de manera impredecible: los cambios en la volatilidad, la escala, los ciclos y los modos de mercado ponen en entredicho la eficacia de los modelos rígidamente vinculados.
En este contexto, aparecen los denominados modelos fundacionales de series temporales (Time Series Foundation Models — TSFM). Se entrenan con enormes conjuntos de datos heterogéneos, basándose en la universalidad y la escalabilidad. Sin embargo, la realidad es que dichos modelos requieren recursos informáticos colosales, y el aumento de la precisión no siempre justifica los costos. Existen decenas de millones de parámetros, pero en la práctica, la universalidad con frecuencia se pierde en los detalles.
La peculiaridad de las series temporales reside en su ritmo. A diferencia del texto, donde un token supone una palabra, la escala y la frecuencia son importantes aquí. Algunos datos llegan una vez por hora, otros, cada 15 minutos. Otros presentan estacionalidad diaria o semanal, otros trimestral o anual. Todo esto afecta al llamado periodo interno, un patrón repetitivo en los datos que es fundamental para una buena previsión. Además, cuando cambia la escala, cambia la duración del ciclo, y si el modelo no puede hacer frente a esto, su capacidad de generalización disminuye drásticamente.
El problema es que la mayoría de los modelos existentes usan una tokenización fija. Simplemente dividen los datos en fragmentos de igual longitud, sin considerar la escala y la estructura de los periodos. Esto provoca que algunos tokens se sobrecarguen de datos, mientras que otros se encuentran casi vacíos. La información se vuelve borrosa y los patrones repetitivos se ven interrumpidos. Esto se nota especialmente cuando se aplica a otra escala un modelo entrenado en una escala: la precisión de la predicción disminuye, lo cual requiere un aumento en el número de parámetros, lo que significa que el tiempo y el coste de entrenamiento aumentan.
Los autores del artículo "LightGTS: A Lightweight General Time Series Forecasting Model" decidieron no recurrir a la fuerza bruta, sino adoptar un enfoque más razonable, aprovechando las propiedades naturales de las series temporales: la invariancia de escala y la periodicidad. El resultado de su trabajo fue el framework LightGTS: ligero, eficiente y diseñado específicamente para tareas de previsión de series temporales en el mundo real. Su idea clave no es luchar contra las distintas escalas, sino adaptarse a ellas.
En lugar de dividir rígidamente en fragmentos idénticos, propusieron utilizar la tokenización periódica. El propio modelo divide de manera adaptativa los datos en secciones cuya longitud corresponde a un ciclo completo. Esto le permite captar patrones holísticos independientemente de la escala, ya sea un gráfico diario o uno de un minuto. La semántica dentro de un token permanece inalterada, lo cual significa que la representación de características se vuelve estable y transferible entre diferentes tareas.
El sistema usa para la predicción la decodificación paralela: el último token del codificador se utiliza como punto de partida, y todos los valores futuros se forman inmediatamente a partir de él. Esto no solo reduce el tiempo y la acumulación de errores (a diferencia de los enfoques autorregresivos por pasos), sino que también permite un mejor aprovechamiento de la estructura de la propia serie. El último elemento clave contiene la esencia de la historia y está directamente vinculado al futuro, lo cual hace que la predicción sea lógica y estructuralmente sólida.
Además, los autores del framework LightGTS abandonaron la proyección fija de características. En su lugar, se usa una capa flexible que puede adaptarse a diferentes duraciones de ciclo y a múltiples fuentes de datos. Esto resulta especialmente relevante en aplicaciones financieras, donde una sola cartera puede contener tanto datos bursátiles por hora como datos macroeconómicos diarios.
Los resultados hablan por sí solos. El modelo LightGTS muestra una precisión líder en la industria con menos de 5 millones de parámetros. Esto supone entre 10 y 100 veces menos que otros modelos TSFM, lo que se traduce en menos tiempo de capacitación, menores costos de infraestructura y una mayor probabilidad de implementar el modelo en un sistema de negociación real o en una plataforma analítica.
El algoritmo LightGTS
Imaginemos un problema típico de previsión en los mercados financieros. Tenemos una serie temporal multivariable; por ejemplo, cotizaciones, volúmenes, indicadores y otras señales de mercado. La llamaremos Xt={xi,t-L:t}i=1,C, donde cada x i es una observación en un canal separado durante los últimos L pasos temporales. Existen numerosos canales C de este tipo: desde uno hasta docenas. Esta será nuestra ventana al pasado, el segmento deslizante de la historia que estamos analizando.
Nuestro objetivo consiste en mirar F pasos hacia el futuro y predecir los valores de Ŷt={ŷi,t:t+F}i=1,C. Y para evaluar la precisión en el proceso de aprendizaje, también tendremos datos reales: Yt={yi,t:t+F}i=1,C. Todo esto encaja en el esquema de pronóstico clásico.
Y ahora viene lo divertido. El modelo se entrena en dos etapas. En primer lugar, se realiza un amplio preentrenamiento con series temporales heterogéneas procedentes de diferentes fuentes. Podría tratarse de datos históricos sobre acciones, divisas, indicadores económicos, el clima, o cualquier cosa que presente dependencias temporales. A continuación, procedemos al ajuste fino del modelo para una tarea específica.
Un punto interesante: no es necesario reentrenar el modelo; bastará con probarlo en una muestra de prueba si inicialmente se ha entrenado de forma bastante universal. Esto resulta especialmente importante en el contexto del trading algorítmico: no siempre es posible entrenar un modelo para cada instrumento, especialmente en tiempo real.
¿Qué hace que el modelo LightGTS sea único? Todo comienza con la tokenización periódica: una verdadera regla mágica que se adapta al ritmo de la propia serie. Los autores del framework proponen dividir la secuencia en parches periódicos: segmentos de datos que corresponden a un ciclo completo (por ejemplo, diario o semanal). Esta operación se denomina Adaptive Periodical Patching (Parcheo Periódico Adaptativo). Esta tiene en cuenta la escala y la estructura de la serie temporal y crea segmentos que se ajustan perfectamente a las repeticiones del comportamiento del mercado.
Para describir el método, vamos a analizar un caso sencillo: una serie temporal unidimensional. En la práctica, todo se adapta fácilmente a datos multidimensionales: cada canal se procesa simplemente por separado, sin perder la estructura.
Imaginemos que estamos trabajando con un conjunto de series temporales procedentes de fuentes distintas: activos financieros, mercados, marcos temporales. Cada serie tiene su propio ritmo interno, el llamado periodo natural. Esto podría ser, por ejemplo, un ciclo de negociación diario, la volatilidad semanal o una tendencia estacional. Para trabajar eficazmente con este tipo de series, el primer paso consiste en determinar la duración de este periodo, es decir, cuántos puntos temporales de los datos analizados constituyen un ciclo completo.
Si disponemos de información previa sobre la frecuencia de los datos (por ejemplo, si llegan una vez por hora o una vez por minuto), entonces será fácil determinar la duración del ciclo: digamos, para un periodo diario y datos por hora, esto es de 24 puntos. Pero si no hay datos de frecuencia, el análisis espectral vendrá al rescate, incluyendo la transformada rápida de Fourier (FFT), que ayuda a detectar las frecuencias dominantes en la serie. Precisamente ellas reflejan los patrones repetitivos —los ciclos— que son tan importantes para pronosticar la dinámica del mercado.
Una vez que se determina la duración del ciclo, denotada por P, toda la serie temporal se divide cuidadosamente en fragmentos consecutivos y no superpuestos, exactamente de acuerdo con estos periodos. Cada uno de estos fragmentos o parches contiene P puntos y abarca un ciclo completo. El número de estos parches es simplemente L dividido por P redondeado hacia abajo, donde L es la longitud de la serie original.
Este paso parece sencillo a primera vista, pero en realidad abre el modelo a un nivel completamente nuevo de estructura semántica. Ahora, distintos marcos temporales, frecuencias y fuentes se interpretan en un único espacio sincronizado periódicamente. Esto elimina el ruido derivado de las diferencias en la escala de los datos y permite que el modelo aprenda a identificar patrones que realmente se repiten de ciclo en ciclo, en lugar de simplemente ajustarse a la volatilidad local.
Precisamente este método de segmentación permite aprender de diversas fuentes. A pesar de la diferencia en las frecuencias, todas se reducen a una forma comparable, donde el periodo es la unidad clave de información. Esto significa que el modelo puede extraer y generalizar señales de mercado recurrentes, lo cual resulta fundamental para realizar pronósticos fiables en un entorno de negociación en tiempo real.
Una vez que la serie temporal se ha dividido en segmentos cíclicos, cada uno de los cuales abarca un ciclo completo de la serie temporal, debemos pasar adecuadamente estos segmentos a una representación vectorial. Aquí es donde comienza la magia de la capa de proyección, pero, al igual que en la propia vida, el diablo está en los detalles.
Una solución ingenua consiste en usar una matriz de proyección fija que transforme cada parche en un token. ¿Problema? Los diferentes datos financieros tienen distintas duraciones de ciclo: un ciclo diario en velas de un minuto es de 1440 puntos, mientras que un ciclo semanal en velas de una hora es de solo 120. Como resultado, el tamaño de los parches de entrada varía, mientras que una matriz fija simplemente no puede gestionarlo: o bien trunca los datos o requiere que todo se convierta a un tamaño común. La interpolación simple sin duda ayuda: simplemente puedes estirar o comprimir los datos. Pero existe un inconveniente: este tipo de operaciones distorsionan el significado. Obtenemos tokens bien alineados pero vacíos que significan poco para el modelo.
Para evitar dichas distorsiones, se introduce una capa de proyección flexible (Flex Projection Layer). Su tarea no consiste simplemente en comprimir un fragmento a una dimensión fija, sino en hacerlo de tal forma que la semántica de los datos permanezca inalterada. En otras palabras, los tokens producidos a partir de un segmento de longitud 96 deberían ser equivalentes a los que habrían surgido de un segmento de longitud 144 si ambos reflejan el mismo ciclo de mercado.
¿Cómo funciona a nivel técnico? Digamos que tenemos unos pesos de proyección θ entrenados para un parche de longitud P. Queremos adaptarlos a un nuevo parche de longitud P′, de modo que el producto de datos y pesos (y por lo tanto tokens) permanezca lo más cercano posible. La interpolación simple no funcionará aquí, pues es demasiado imprecisa. Por lo tanto, se usa una transformación lineal con adaptación de pesos a través de una matriz pseudoinversa, un método conocido en métodos numéricos y análisis de regresión.
Este mecanismo se llama flex-resize y resuelve un problema de optimización: encontrar nuevos pesos θ′ que, al transformar nuevos parches, produzcan un resultado lo más parecido posible al anterior, según la norma de Frobenius, si hablamos de forma matemática. Aquí se introduce el coeficiente δ, que considera la diferencia de varianzas entre el parche original y el interpolado, lo que permite mantener la estabilidad estadística de las proyecciones. La fórmula resultante para flex-resize parece bastante sólida, pero en esencia supone una forma ingeniosa de hacer que la matriz de pesos sea flexible y adaptable.
Dentro de la implementación de Flex Projection Layer, se utilizan dos matrices de parámetros, una para la entrada y otra para la salida, cada una diseñada para un tamaño de parche de referencia (por ejemplo, 96). Durante la pasada directa del modelo, estas matrices se ajustan a la longitud deseada del parche actual utilizando la misma transformación δ⁻¹(A)+. Después de esto, los parches se proyectan fácilmente en el espacio latente del modelo: los tokens están listos y mantienen toda la estructura del ciclo de mercado original.
Por ello, ya sea que el modelo esté analizando la tendencia semanal utilizando gráficos de velas diarias o realizando scalping en gráficos de minutos, siempre trabaja con datos en una vista única y coherente. Esto elimina los conflictos entre distintas escalas y permite un uso eficiente de pesos preentrenados sin necesidad de volver a entrenarlas desde cero. Y en el contexto de los mercados financieros, donde los datos provienen de fuentes distintas y con diferentes frecuencias, dicha flexibilidad no es un lujo, sino una necesidad.
La arquitectura del framework LightGTS, similar al Transformer clásico, utiliza un Codificador y un Decodificador, cada uno de los cuales incluye módulos de atención multi-cabeza y capas totalmente conectadas (Feed-Forward Networks). Sin embargo, hay un detalle clave: los módulos de atención usan codificación posicional rotacional (RoPE), que permite tener en cuenta no solo las posiciones absolutas sino también las relativas de los tokens. Esto resulta especialmente relevante en el caso de las series temporales, donde no solo es importante el orden sino también la distancia entre los puntos.
Después de que los parches periódicos se hayan traducido en los tokens mediante Flex Projection, se forma una secuencia de tokens 𝐗ₑ = {𝐱ₑ₁, 𝐱ₑ₂, …, 𝐱ₑₙ}, donde cada 𝐱ₑᵢ es la representación vectorial del i-ésimo parche. Al procesar esta secuencia, el Codificador impone una estructura posicional mediante RoPE: los tokens no solo recuerdan su posición, sino que también tienen en cuenta su desplazamiento relativo entre sí.
Específicamente, para cada token, los vectores de consulta (Query) y clave (Key) se calculan utilizando las matrices entrenables 𝐖 Q y 𝐖 K. A continuación, al par de vectores (𝐱ₑᵢ, 𝐱ₑⱼ), que representan las posiciones i y j, se les impone una matriz de rotación 𝐑i−j, que codifica exactamente la diferencia en sus posiciones. La medida de similitud resultante entre los tokens i y j se calcula usando la fórmula:
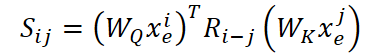
Cuanto mayor sea este valor, más atención prestará el token i al token j. Todos estos valores se normalizan usando la función SoftMax y se utilizan para la suma ponderada de los vectores value obtenidos a través de otra matriz entrenable 𝐖 V.
Es esta atención la que determina para cada token, a cuál de sus vecinos debe mirar y con qué intensidad. Tras recibir atención, cada token es procesado posteriormente por una unidad totalmente conectada, la Feed-Forward Network, que extrae características ocultas y enriquece la representación.
Como resultado, la salida del Codificador es un espacio latente, donde cada vector 𝐞 ⱼ contiene no solo la información local del parche, sino también el contexto de todos los demás tokens, considerando sus posiciones relativas en la serie temporal. Este mecanismo permite que el modelo comprenda la estructura, el ritmo y los patrones repetitivos de los datos, lo cual resulta fundamental para las series temporales financieras, donde lo que importa no es tanto el dato en sí, sino su entorno.
Como hemos mencionado antes, la aplicación periódica de parches ayuda a extraer ciclos recurrentes de las series temporales. Pero para sacar el máximo partido a esta información a la hora de generar una previsión, el modelo usa un nuevo enfoque: la decodificación paralela periódica. A diferencia del enfoque autorregresivo clásico, donde la previsión se construye paso a paso, aquí se utiliza una estrategia no autorregresiva que permite procesar todo el segmento futuro a la vez.
La idea clave es simple pero elegante: el último token 𝐞ₙ del espacio latente de salida del Codificador contiene información comprimida sobre toda la secuencia precedente, incluida su periodicidad interna. Por lo tanto, la tomamos, la clonamos K veces (donde K = F/P, es decir, una predicción de cuántos ciclos se necesitan) y obtenemos la matriz 𝐇, que será la entrada al decodificador.
Sin embargo, debemos considerar que la influencia del último token en la predicción se debilita a medida que avanzamos en el tiempo. Por consiguiente, se aplica una función de ponderación ω(j)=1/eʲ a cada vector clonado 𝐡 ⱼ, que disminuye exponencialmente su contribución con la distancia al momento actual. Los tokens ponderados obtenidos ω(j)·𝐡ⱼ se suministran al decodificador simultáneamente, lo cual constituye la esencia de la arquitectura paralela del decodificador.
La salida del decodificador es una matriz 𝐙, los tokens predichos que corresponden a ciclos futuros. Para traducir dichos tokens a valores de series temporales acostumbrados, el modelo utiliza una retroproyección mediante el mecanismo Flex-resize ya conocido, aplicándolo esta vez a los parámetros del decodificador θ d.
De esta forma, el modelo genera todo el segmento de pronóstico 𝐘̂ de una sola vez, sin la acumulación de errores y retrasos típicos de los pronósticos paso a paso. Esto no solo acelera los cálculos, sino que también preserva mejor la periodicidad, ya que esta se incorporó en la etapa de tokenización y ahora se aplica a toda la arquitectura, desde el Codificador hasta la salida final.
Bajo el capó, LightGTS funciona a la perfección: con ritmo, precisión y sin desperdicios innecesarios. Mediante el uso de la tokenización periódica y la decodificación paralela, el modelo evita los inconvenientes clásicos de la excesiva complejidad y la escasa portabilidad.
Según la práctica establecida en el campo de la previsión de series temporales, los autores del framework LightGTS utilizan el error cuadrático medio (Mean Squared Error (MSE) clásico como función de pérdida. Este mide la desviación entre los valores previstos y los datos reales observados, sirviendo como criterio objetivo para la calidad del pronóstico.
A continuación le presentamos la visualización del framework LightGTS por parte del autor.

Implementación con MQL5
Tras un examen detallado de los aspectos teóricos del framework LightGTS, ahora pasamos a la parte práctica de nuestro artículo. En esta sección presentaremos nuestra propia visión para la implementación de los componentes clave del modelo utilizando MQL5, teniendo en cuenta las particularidades de las series temporales financieras y las limitaciones de la plataforma.
Comenzaremos, tal vez, con uno de los elementos básicos y a la vez más interesantes: el parcheo periódico adaptativo. Precisamente con este mecanismo comienza el proceso de transformación de una serie temporal en una estructura conveniente para su procesamiento por un transformador. Eso sí, nos esperan algunos desafíos importantes.
Uno de ellos es el cambio dinámico del tamaño del parche, ya lo mencionan los autores del framework original. Este artículo propone una forma elegante de resolver dicho problema mediante la interpolación lineal de pesos. Sin embargo, en la práctica, solo aborda una parte del problema.
Al fin y al cabo, si el tamaño del parche cambia, su número también cambiará, de forma dinámica e impredecible. Y esto ya introduce una complejidad adicional en la arquitectura del modelo, sobre todo cuando este se implementa en un lenguaje fuertemente tipado como MQL5. Los ciclos y matrices clásicos requieren un control preciso del tamaño en todas las etapas, lo cual significa que deberemos no solo adaptar la dimensionalidad de los datos de entrada, sino también desarrollar un mecanismo para dividir de forma adaptativa la serie temporal en un número variable de segmentos, manteniendo su periodicidad y coherencia con la historia de observaciones.
Lamentablemente, las soluciones arquitectónicas que usamos no nos permiten usar las dimensionalidades dinámicas de los tensores de entrada o salida durante la ejecución de las operaciones. Por lo tanto, necesitamos un enfoque distinto y más pragmático que garantice tamaños de búfer fijos al tiempo que mantenga la capacidad de trabajar con un número variable de tokens.
Una opción posible es crear un búfer con capacidad deliberadamente excesiva, diseñado para albergar el mayor número posible de tokens. Si el número real de tokens es menor, las celdas adicionales se restablecerán a cero. Este enfoque ofrece cierta flexibilidad para trabajar con distintas cantidades de parches; sin embargo, dicha flexibilidad conlleva un consumo innecesario de memoria, una parte significativa de la cual permanece sin utilizar.
Además, no debemos olvidar la principal vulnerabilidad de la arquitectura del Transformer: la complejidad cuadrática de la atención con respecto a la longitud de la secuencia. Cuantos más tokens suministremos como entrada, más tiempo y recursos se requerirán para ejecutar los bloques de atención. En otras palabras, la asignación excesiva de tokens no solo es ineficiente en cuanto al uso de la memoria, sino que también perjudica directamente el rendimiento computacional del modelo, sobre todo en condiciones de tiempo real o al procesar grandes cantidades de datos de mercado de alta frecuencia.
Por consiguiente, será necesario un enfoque alternativo y más flexible. En este sentido, merece atención el concepto de parches periódicos no superpuestos propuesto por los autores del framework LightGTS, en el que cada segmento de la serie temporal corresponde a un ciclo completo. Esto resulta bastante lógico: una serie temporal suele contener componentes periódicos claramente definidos, y el análisis por separado de cada periodo nos permite extraer características semánticamente puras.
Sin embargo, le proponemos abordar el problema desde un ángulo diferente. ¿Qué sucedería si abandonáramos el requisito estricto de que los parches no se superpongan? En lugar de ello, podemos fijar el número deseado de parches en la salida y ajustar la longitud de superposición entre ventanas adyacentes en función de la periodicidad de la secuencia original.
Este enfoque ofrece varias ventajas. En primer lugar, nos permite garantizar un número constante de parches independientemente de la ciclicidad inicial de la serie temporal analizada. Y esto resulta muy cómodo al diseñar una arquitectura fija. En segundo lugar, la superposición flexible nos permite lograr una cobertura completa de la estructura de datos cíclica sin truncarla ni perder información entre los límites de las ventanas. Y finalmente, esto permite un control más preciso sobre la resolución de la representación semántica sin comprometer la compacidad del tensor de salida.
En pocas palabras, le proponemos sacrificar el rigor de un parche por ciclo a cambio de una densidad de representación controlada, al tiempo que preservamos el volumen de salida general y aumentamos la robustez del modelo ante cambios en la longitud de la secuencia de entrada.
A mi parecer, el concepto es claro. Ahora es el momento de pasar a la implementación práctica. El primer paso consiste en determinar la periodicidad de la serie temporal analizada. Para ello, utilizaremos un método clásico y de eficacia probada basado en la Transformada Rápida de Fourier (Fast Fourier Transform — FFT).
La esencia del método es simple: analizamos el espectro de amplitudes de los componentes de frecuencia de la serie temporal y encontramos la frecuencia con la energía más alta. Es este ciclo el que, por regla general, se corresponde con el ciclo dominante en los datos. El periodo, a su vez, se calcula como la magnitud inversa de la frecuencia detectada.
¿Por qué elegimos la FFT? En primer lugar, es un algoritmo rápido y eficiente incluso al trabajar con grandes cantidades de datos. En segundo lugar, nos permite identificar dependencias periódicas ocultas que a veces son imposibles de determinar visualmente. Por último, la FFT resulta útil porque permite trabajar en condiciones en las que no existe información previa sobre las características de frecuencia de la serie temporal, lo que suele ocurrir con los datos reales de negociación.
Y, por supuesto, una ventaja adicional es la disponibilidad de una implementación de una FFT lista para usar en nuestra biblioteca. Permítame recordarle que la utilizamos como parte de nuestro trabajo en el framework FITS.
La implementación de la FFT en nuestra biblioteca retorna las partes real e imaginaria del espectro, lo cual resulta totalmente coherente con la forma clásica de representar el resultado de la transformada rápida de Fourier. Sin embargo, esta información por sí sola aún no responde a la pregunta de qué frecuencia domina la señal y determina la estructura de las oscilaciones.
Para evitar sobrecargar la CPU y mantener la eficiencia paralela, vamos a implementar un kernel que determina la frecuencia dominante para cada secuencia unitaria directamente en el contexto OpenCL. Cada flujo recibe su espectro, calcula la energía de todos los componentes de frecuencia y selecciona el que tiene la amplitud máxima. Sería como escuchar una melodía compleja y reconocer al instante el ritmo subyacente que le da estructura. Este enfoque resulta especialmente importante al trabajar con series temporales multimodales, donde cada variable puede tener su propia frecuencia característica.
Implementaremos el algoritmo dentro del kernel OpenCL MainFreq, que trabaja con matrices de componentes espectrales reales e imaginarias. Y como resultado, retorna un array que contiene los índices de las frecuencias más pronunciadas para cada secuencia.
__kernel void MainFreq(__global const float* freq_r, __global const float* freq_im, __global float *main_freq, int dimension ) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension;
En el cuerpo del kernel, primero identificamos cada flujo de operaciones en un espacio de tareas unidimensional. El índice resultante indica el número único de la secuencia unitaria analizada. Y según lo que hemos obtenido, determinamos directamente el desplazamiento en los arrays de espectro para procesar únicamente nuestra propia secuencia.
A continuación, inicializamos variables para almacenar la amplitud máxima (energía) y el índice correspondiente.
float max_f = 0; float max_id = 0; float energy;
Con esto finaliza el trabajo preparatorio; a continuación organizamos el ciclo a lo largo del espectro, comenzando por el primer armónico.
for(int i = 1; i < dimension; i++) { float2 freq = (float2)(freq_r[shift + i], freq_im[shift + i]); energy = ComplexAbs(freq); if(max_f < energy) { max_f = energy; max_id = i + 1; } }
Omitimos intencionadamente la frecuencia cero (componente DC ), ya que no contiene información sobre la periodicidad, sino que refleja el componente constante de la señal.
En cada iteración, formamos un número complejo a partir de las partes real e imaginaria. El módulo de este número representa la fuerza de expresión de la frecuencia correspondiente. Si la energía encontrada supera el máximo actual, actualizamos los valores.
Finalmente, tras completar el recorrido de todo el espectro, escribimos el resultado en el búfer de datos global.
main_freq[n] = max_id; }
El algoritmo opera como un director de orquesta experimentado, supervisando cuidadosamente cada instrumento de la orquesta y determinando quién interpreta la parte principal. No nos limitamos a encontrar la frecuencia, sino que calculamos el periodo más pronunciado de la señal, que luego se usa para construir de forma adaptativa parches en el modelo. Y dado que cada serie (en condiciones multimodales) se procesa de manera independiente, obtenemos un sistema escalable, flexible y completamente autónomo para determinar la periodicidad local.
Cabe destacar también que el algoritmo propuesto es completamente determinista, no contiene parámetros entrenables y no requiere costos de entrenamiento. Se basa exclusivamente en la naturaleza física del espectro: la amplitud de los componentes de frecuencia se estima directamente, sin usar estadísticas, regresiones ni ponderaciones adaptativas. Esto hace que el método resulte transparente, robusto y particularmente útil en la etapa de preprocesamiento de datos, cuando es fundamental evitar la introducción de desplazamientos debidos al subajuste o al sobreajuste. En otras palabras, aquí se emplean matemáticas puras e imparciales, en lugar de suposiciones probabilísticas, lo que resulta especialmente importante al analizar series temporales de mercados volátiles.
La siguiente etapa de nuestro trabajo consistirá en la implementación directa del algoritmo de parcheo adaptativo con cambio dinámico del tamaño del segmento. Pero, como comprenderá, esto no se puede explicar en pocas palabras. La implementación requiere de nuestra atención a muchos detalles técnicos, y el tamaño del artículo actual ya es bastante grande. Por ello, siguiendo la mejor tradición de las series de suspense, proponemos hacer una breve pausa y continuar la discusión sobre la implementación de los enfoques propuestos en el próximo artículo.
En él, analizaremos paso a paso cómo implementar un mecanismo para la generación dinámica de parches considerando la duración variable del ciclo, manteniendo al mismo tiempo un número estable de tokens de salida. Asimismo, tendremos en cuenta las posibles compensaciones entre la flexibilidad arquitectónica y la eficiencia computacional.
Conclusión
En este artículo, hemos analizado con detalle los fundamentos teóricos del framework LightGTS, centrándonos en sus componentes clave: el parcheo periódico, la proyección flexible de tokens y el mecanismo de decodificación paralela. Además, hemos analizado cómo la arquitectura maneja series temporales multimodales y se adapta a diferentes periodos sin necesidad de volver a entrenar el modelo. Hemos prestado especial atención a los aspectos técnicos del cálculo de la frecuencia dominante mediante la transformada rápida de Fourier.
También hemos abordado las limitaciones prácticas de la asignación dinámica de memoria y el recuento variable de tokens, y hemos propuesto soluciones alternativas basadas en parches superpuestos y una longitud fija del vector de salida. Este enfoque no solo mejora la compatibilidad con la arquitectura Transformer, sino que también permite un uso más eficiente de los recursos, evitando un consumo excesivo de memoria y la degradación del rendimiento.
El material presentado sirve como base sólida para la posterior implementación de la versión completa del parcheo adaptativo y su integración en la arquitectura predictiva. En el próximo artículo, continuaremos por este camino, centrándonos en implementaciones específicas de segmentación adaptativa de series temporales y la integración de los tokens resultantes en el modelo entrenado.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 2 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18596
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso