Características del Wizard MQL5 que debe conocer (Parte 60): Aprendizaje por inferencia (Wasserstein-VAE) con patrones de media móvil y oscilador estocástico
Introducción
Al examinar los patrones generados al combinar la media móvil (MA) y el oscilador estocástico, hemos recurrido al aprendizaje automático como medio para sistematizar nuestro enfoque. En el aprendizaje automático existen principalmente tres métodos para entrenar redes neuronales: el aprendizaje supervisado, el aprendizaje por refuerzo y la inferencia. Partiendo de la base de que cada uno de estos métodos de aprendizaje puede utilizarse en diferentes etapas del desarrollo del modelo o la red, hemos argumentado que un modelo puede enriquecerse incorporando todos ellos.
Breve resumen
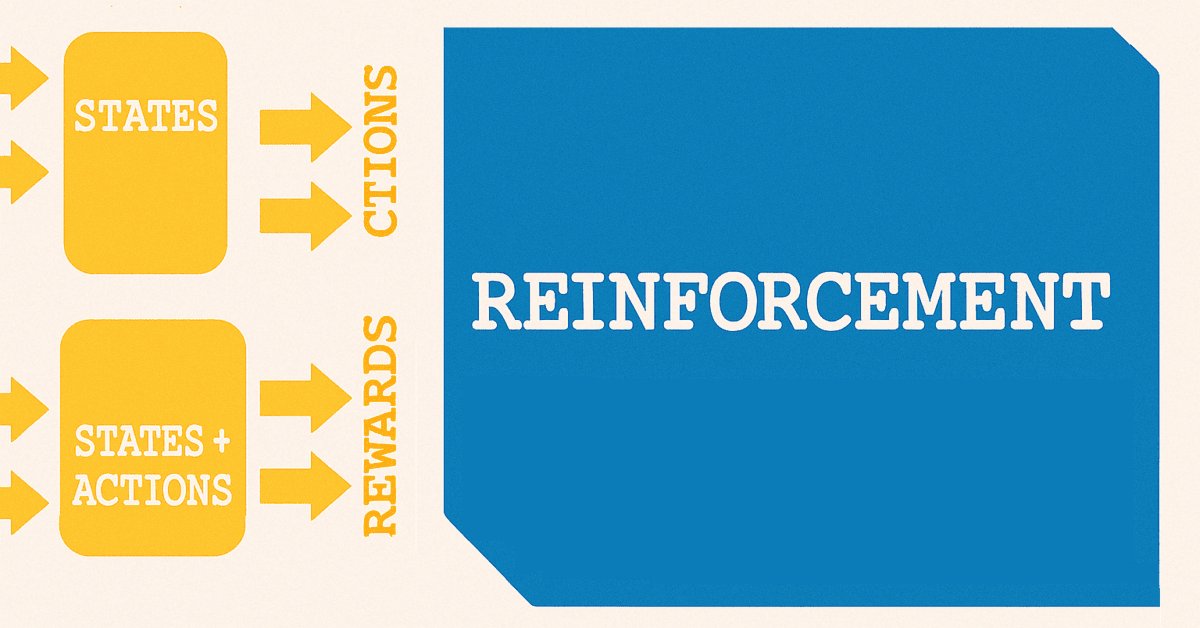
A modo de breve resumen, en nuestro anterior artículo sobre el aprendizaje supervisado se trataba de asignar características a estados. Las características son los patrones de los indicadores, tanto de la media móvil como del oscilador estocástico. Los estados son previsiones de variaciones de precios que se producen con retraso respecto a los patrones de nuestro indicador y que son pronosticadas por nuestro modelo o red. El sencillo diagrama que se muestra a continuación ayuda a ilustrarlo.

El uso del término «states» para predecir las variaciones de precios es fortuito, ya que pasamos del aprendizaje supervisado al aprendizaje por refuerzo. Tal y como se establece en el aprendizaje por refuerzo, los estados constituyen un punto de partida fundamental para el proceso de entrenamiento, que se asemeja en gran medida al diagrama que se muestra a continuación.

Existen diversas variantes del aprendizaje por refuerzo en función del algoritmo utilizado, pero la mayoría, en principio, utilizan dos redes. La primera es una política que se muestra como la red superior de las dos que aparecen en el diagrama anterior, y la otra es la red de valor, representada como la inferior.
El refuerzo puede ser el único método de entrenamiento para un modelo o un sistema, pero en el artículo anterior sostuvimos que podría utilizarse más en modelos desplegados en producción. Una vez hecho esto, el equilibrio entre exploración y explotación cobraría mayor relevancia a la hora de garantizar que un modelo ya entrenado se adapte a los entornos de mercado cambiantes. Pero, más allá de eso, vimos cómo las decisiones de apostar por el largo o el corto pueden analizarse más a fondo a la hora de seleccionar el tipo de acción necesaria para un estado previsto.
Inferencia
Esto nos lleva, pues, a la inferencia, o lo que también se conoce como aprendizaje no supervisado. ¿Cuál es el objetivo de la inferencia? Cuando empecé a pensar en esto, opinaba que nos permitía tomar redes o modelos entrenados para una situación determinada y, con algunos ajustes y optimizaciones menores, aplicarlos en un contexto diferente. Para los traders, esto significa entrenar un modelo para el par EUR/USD y, a continuación, con ligeros ajustes, aplicar ese conocimiento, por ejemplo, al par EUR/JPY. Sin embargo, como la mayoría de los traders pueden atestiguar, incluso desarrollar un asesor experto que no sea de arbitraje y que pueda operar con más de un instrumento a la vez es un proceso complicado con un perfil de relación riesgo-recompensa problemático.
Y, además, el coste computacional que supone entrenar diferentes modelos para múltiples pares de divisas ya no es tan elevado como lo era antes. Esto se debe, en gran parte, a que las GPU son más rápidas y al uso generalizado de la infraestructura en la nube, que pone todo esto al alcance de tantos usuarios. Por lo tanto, en teoría, esta situación debería dar lugar a la creación de muchos modelos. Aunque los costes de almacenamiento también están disminuyendo, sobre todo si se tiene en cuenta que los grandes modelos con millones de parámetros se almacenan ahora como si fueran archivos informáticos normales, creo que la inferencia mediante codificadores justifica que este conocimiento se comprima y sea «más fácil de almacenar».
Ahora bien, dado que la necesidad de disponer de más espacio de almacenamiento o de un tipo especial es prácticamente inexistente, teniendo en cuenta lo barato que resulta, uno podría descartar fácilmente esta opción. Esto es especialmente cierto si se tiene en cuenta que, con un modelo de aprendizaje supervisado ya entrenado y un sistema de aprendizaje por refuerzo en funcionamiento para mantenerlo al día, ¿qué aportaría la inferencia? Bueno, nosotros sostenemos que no todos los datos se presentan en forma de series temporales continuas.
Si se tienen en cuenta casos de datos históricos antiguos que podrían guardar cierta similitud con acontecimientos actuales o en curso, la inferencia puede ayudar a relacionarlos minimizando al mismo tiempo el ruido de fondo. Por «relacionarlos» nos referimos a la configuración que se muestra en el siguiente diagrama:

Así pues, en una situación en la que se dispone de características para los datos históricos, a continuación mostramos cómo, mediante un enfoque no supervisado (en este caso, regresión lineal), podemos inferir los respectivos estados, acciones y recompensas. Todo esto se debe a que hemos entrenado un modelo de codificador automático variacional para asociar características-estados-acciones-recompensas (FSAR) a una capa oculta a la que denominamos «codificaciones». Con los conjuntos de datos de FSAR y las codificaciones, ajustamos un modelo de regresión lineal que nos ayuda a completar los datos que faltan en un conjunto de datos de FSAR. Esta es la aplicación principal que vamos a analizar en este artículo.
Sin embargo, si uno da un paso atrás y analiza el proceso de aprendizaje supervisado y el de aprendizaje por refuerzo, queda claro que, con el paso del tiempo, surge la necesidad de integrar de forma más completa los conocimientos adquiridos. Y aunque una opción podría ser realizar otra ronda de aprendizaje supervisado durante este periodo más largo y luego aplicar el aprendizaje por refuerzo, el aprendizaje por inferencia debería ser una alternativa más escalable y holística.
En resumen, la inferencia consiste en estimar variables ocultas a partir de datos observados. En los modelos bayesianos, por lo general, la inferencia es el proceso de calcular la distribución a posteriori de las variables ocultas a partir de los conjuntos de datos de la capa visible. Por lo tanto, desde el punto de vista matemático, se puede definir formalmente de la siguiente manera:

Donde:
- z es la variable latente o las codificaciones,
- x son los datos observados, que en nuestro caso son el FSAR,
- p(z|x) es la distribución a posteriori (lo que queremos averiguar) o la probabilidad de observar z dado que se ha observado x,
- p(x|z) es la verosimilitud o probabilidad de observar x cuando se da z
- p(z) es la distribución a priori,
- p(x) es la evidencia.
P(x) suele ser intratable o difícil de calcular.
¿Por qué es difícil? El denominador, p(x), implica integrar sobre todas las variables latentes posibles:

Por lo general, esto resulta computacionalmente inabarcable en dimensiones elevadas, es decir, a medida que aumenta el tamaño de la variable latente.
¿Cómo pueden ayudar entonces los VAE? Los VAE convierten el problema de la inferencia aproximada en una tarea de optimización. Esto se consigue mediante la introducción de una red de codificación/inferencia y una red de decodificación/generación. El codificador responde a la pregunta q(z|x), que es una aproximación aprendida de la distribución posterior; mientras que la red decodificadora aborda p(x|z), que es una reconstrucción de los datos (en nuestro caso, FSAR) a partir del código latente (codificaciones).
Sin embargo, la innovación clave de la VAE radica en que, en lugar de calcular el posterior con exactitud, la VAE se optimiza para la optimización del límite inferior de la evidencia (ELBO). El ELBO es la función objetivo que se utiliza para entrenar las VAE, ya que permite aproximarse a la distribución real de los datos al tiempo que garantiza que el modelo aprenda representaciones latentes significativas y reduzca el ruido. Esta es la idea clave:

Como ya se ha mencionado anteriormente, calcular p(x) es muy difícil y un problema intratable; sin embargo, demostrar que p(x) —y, por ende, log p(x)— es mayor que un valor dado es factible y un problema tratable. Dado que nuestro objetivo es maximizar p(x), al maximizar o elevar el límite inferior, acabamos elevando también p(x). VAE aprende a inferir la estructura latente a partir de los datos y se entrena de extremo a extremo mediante el método de descenso de gradientes. De este modo, muestra tanto la inferencia amortizada como el modelado generativo en un único marco.
¿Por qué es VAE un elemento fundamental de la filosofía de la inferencia? Porque la VAE aprende a realizar inferencias a través del codificador. Esto significa que, en lugar de resolver el problema de inferencia cada vez que hay un nuevo conjunto de datos, se utiliza un codificador compartido. Esto también se conoce como «inferencia amortizada». Se trata de una herramienta excelente para sopesar la relación entre fidelidad y regularidad, pero también para comprender, en general, cómo las variables latentes representan la estructura generativa.
En este artículo aplicamos el VAE utilizando la distancia de Wasserstein en lugar de la divergencia KL tradicional a la hora de comparar distribuciones. Las razones para ello son principalmente de carácter exploratorio, ya que en futuros artículos podríamos analizar la divergencia de KL. Sin embargo, se ha argumentado que la divergencia KL limita en exceso el espacio latente, lo que a su vez puede provocar un colapso de la distribución a posteriori. En segundo lugar, se sostiene que la distancia de Wasserstein es una métrica más flexible para comparar distribuciones, especialmente en situaciones en las que las distribuciones en cuestión tienen poco o ningún solapamiento.
La idea fundamental de la distancia de Wasserstein consiste en cuantificar el coste de transformar una distribución de probabilidad en otra. Por ello, también se conoce como distancia de transporte de tierra (Earth Mover’s Distance, EMD). Se expresa mediante la siguiente ecuación:

Donde:
-
P: Distribución real de los datos (por ejemplo, distribución gaussiana a priori p(z)).
-
Q: Distribución aproximada (por ejemplo, la salida del codificador q(z∣x)).
-
γ: Una distribución conjunta (acoplamiento) sobre P y Q.
-
Γ(P,Q): Conjunto de todos los acoplamientos posibles entre P y Q.
-
∥x−y∥: Métrica de distancia (por ejemplo, distancia euclidiana).
-
inf: Ínfimo (es decir, la mayor cota inferior, o el menor coste de transporte posible)
Por lo tanto, Wasserstein calcula la cantidad mínima de trabajo necesaria para mover la masa Q para que coincida con P. El VAE de Wasserstein es importante porque produce muestras más nítidas y tiene representaciones latentes más expresivas. Generalmente se considera que es más estable cuando se entrena bajo ciertas condiciones.
Existen principalmente dos implementaciones comunes del VAE de Wasserstein. WVAE-MMD y WVAE-GAN. El primero utiliza la Discrepancia Máxima Media para comparar p(z) y q(z). Es el método que utilizaremos en este artículo. Como nota al margen, este último, WVAE-GAN, utiliza una función de pérdida adversaria para alinear las distribuciones latentes. También podríamos analizar esta implementación en futuros artículos. La discrepancia máxima-media se describe mediante la siguiente ecuación:

Donde:
-
P: Prior verdadero (por ejemplo, p(z)=N(0,I)).
-
Q: Distribución del codificador (por ejemplo, q(z∣x)).
-
k(⋅,⋅): Función kernel (por ejemplo, RBF gaussiana).
-
x,x′: Dos muestras independientes de P.
-
y,y′: Dos muestras independientes de Q.
Implementación de VAE
Comenzamos implementando nuestros modelos/redes en Python, principalmente porque es más conveniente entrenarlos aquí que en MQL5 puro. En MQL5 existen soluciones alternativas que implican el uso de OpenCL y que pueden reducir la brecha de rendimiento; sin embargo, aún no las hemos analizado en esta serie. Implementamos una clase VAE de Wasserstein de la siguiente manera en Python:
class WassersteinVAEUnsupervised(nn.Module): def __init__(self, feature_dim, encoding_dim, k_neighbors=5): super().__init__() self.encoding_dim = encoding_dim self.k_neighbors = k_neighbors # Feature encoder self.feature_encoder = nn.Sequential( nn.Linear(feature_dim, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU(), nn.Linear(128, encoding_dim * 2) # mean and logvar ) # Buffer for storing training references self.register_buffer('ref_encoding', torch.zeros(1, encoding_dim)) self.register_buffer('ref_states', torch.zeros(1, 1)) self.register_buffer('ref_actions', torch.zeros(1, 1)) self.register_buffer('ref_rewards', torch.zeros(1, 1)) self._references_loaded = False def encode(self, features): h = self.feature_encoder(features) z_mean, z_logvar = torch.chunk(h, 2, dim=1) return z_mean, z_logvar def reparameterize(self, mean, logvar): std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return mean + eps * std def update_references(self, encoding_vectors, states, actions, rewards): """Store reference data for unsupervised prediction""" self.ref_encoding = encoding_vectors.detach().clone() self.ref_states = states.detach().clone().unsqueeze(-1) self.ref_actions = actions.detach().clone().unsqueeze(-1) self.ref_rewards = rewards.detach().clone().unsqueeze(-1) self._references_loaded = True def knn_predict(self, z, ref_values): # z shape: [batch_size, encoding_dim] # ref_values shape: [ref_size, 1] or [ref_size] # Ensure ref_values is properly shaped ref_values = ref_values.view(-1) # Flatten to [ref_size] # Calculate distances between z and reference encodings distances = torch.cdist(z, self.ref_encoding) # [batch_size, ref_size] # Get top-k nearest neighbors _, indices = torch.topk(distances, k=self.k_neighbors, largest=False) # [batch_size, k] # Gather corresponding reference values neighbor_values = torch.gather( ref_values.unsqueeze(0).expand(indices.size(0), -1), # [batch_size, ref_size] 1, indices ) # [batch_size, k] # Average the nearest values predictions = neighbor_values.mean(dim=1, keepdim=True) # [batch_size, 1] return predictions def gaussian_predict(self, z, ref_values): # Input validation assert z.dim() == 2, "z must be 2D [batch, encoding]" assert ref_values.dim() == 2, "ref_values must be 2D" # Calculate distances (Euclidean) distances = torch.cdist(z, self.ref_encoding) # [batch, ref_size] # Convert to similarities (Gaussian weights) weights = torch.softmax(-distances, dim=1) # [batch, ref_size] # Prepare reference values ref_values = ref_values.squeeze(-1) if ref_values.size(1) == 1 else ref_values ref_values = ref_values.unsqueeze(0) if ref_values.dim() == 1 else ref_values # Ensure proper shapes ref_values = ref_values.view(-1, 1) # Force [792, 1] shape # Calculate distances distances = torch.cdist(z, self.ref_encoding) # [batch_size, 792] # Convert to weights weights = torch.softmax(-distances, dim=1) # [batch_size, 792] # Matrix multiplication Weighted combination predictions = torch.matmul(weights, ref_values) # [batch, 1] return predictions.unsqueeze(-1) if predictions.dim() == 1 else predictions def linear_predict(self, z, ref_values): """Linear regression prediction using normal equations""" # Add bias term X = torch.cat([self.ref_encoding, torch.ones_like(self.ref_encoding[:, :1])], dim=1) y = ref_values # Compute closed-form solution XtX = torch.matmul(X.T, X) Xty = torch.matmul(X.T, y) theta = torch.linalg.solve(XtX, Xty) # Predict with new z values X_new = torch.cat([z, torch.ones_like(z[:, :1])], dim=1) return torch.matmul(X_new, theta) def predict_from_encoding(self, z): if not self._references_loaded: raise RuntimeError("Reference data not loaded") # Validate reference shapes self.ref_states = self.ref_states.view(-1, 1) self.ref_actions = self.ref_actions.view(-1, 1) self.ref_rewards = self.ref_rewards.view(-1, 1) states = self.knn_predict(z, self.ref_states) actions = self.gaussian_predict(z, self.ref_actions) rewards = self.linear_predict(z, self.ref_rewards) return states, actions, rewards def forward(self, features, states=None, actions=None, rewards=None): z_mean, z_logvar = self.encode(features) z = self.reparameterize(z_mean, z_logvar) if states is not None and actions is not None and rewards is not None: return { 'z': z, 'z_mean': z_mean, 'z_logvar': z_logvar } else: pred_states, pred_actions, pred_rewards = self.predict_from_encoding(z) return { 'states': pred_states, 'actions': pred_actions, 'rewards': pred_rewards }
Nuestra implementación de Wasserstein VAE descrita anteriormente consta principalmente de cuatro elementos. Un codificador de características, un búfer de referencia, métodos de predicción y un paso hacia adelante de modo dual. El codificador de características es una MLP de 3 capas cuya función es comprimir las entradas en parámetros del espacio latente (de z, z-media y z-logvar). Los búferes de referencia almacenan las entradas del modelo preentrenado, que incluyen características, estados, acciones y recompensas, junto con sus respectivas codificaciones. Los métodos de predicción enumerados sirven para pronosticar estados, acciones y recompensas para un conjunto de datos incompleto que se presenta únicamente con características. Estos métodos son K-NN, ponderación gaussiana y regresión lineal. Trabajan dentro del espacio latente mapeando las codificaciones a los puntos de datos faltantes de estados-acciones-recompensas. El paso hacia adelante de modo dual gestiona tanto el entrenamiento como la inferencia.
Los componentes funcionales clave son el proceso de codificación, el sistema de referencia, los mecanismos de predicción y el flujo de inferencia. En el proceso de codificación, las características de entrada (estados, acciones y recompensas) pasan a través de la red del codificador. La salida divide estas entradas en una "codificación" de z, z-media y z-log-varianza. Además, en este proceso, el truco de reparametrización nos permite tener un muestreo diferenciable. El sistema de referencia almacena las salidas "congeladas" con sus respectivos pares de entrada FSAR. Requiere una inicialización explícita a través de la función update_references().
Los tres mecanismos de predicción están orientados a pronosticar estados, acciones o recompensas. Nuestro modelo parte de la base de que las características siempre están disponibles como parte del conjunto de datos FSAR; sin embargo, hay ocasiones en las que solo podría faltar el SAR (estados-acciones-recompensas). El algoritmo de agrupamiento KNN mapea los estados, la regresión de procesos gaussianos mapea las acciones y la regresión lineal mapea las recompensas. Por lo tanto, el flujo de inferencia codifica nuestras características de entrada en el espacio latente, selecciona el método de predicción para cada tipo de entrada en función de los emparejamientos mencionados anteriormente y, a continuación, devuelve las estimaciones de estado/acción/recompensa correspondientes.
Sin embargo, se podrían introducir algunas mejoras en nuestro enfoque anterior. Estas se pueden clasificar a grandes rasgos en 3 categorías. Mejoras arquitectónicas, perfeccionamiento de la formación o simplemente mayor robustez. Las mejoras en la arquitectura podrían incluir: agregar normalización espectral para garantizar la continuidad de Lipschitz; implementar una temperatura ajustable para la ponderación del proceso gaussiano; incluir la gestión de memoria de referencia (FIFO/poda); y agregar muestreo de Montecarlo para la estimación de la incertidumbre. El proceso de entrenamiento también se puede mejorar introduciendo una penalización de gradiente para las restricciones de Wasserstein; añadiendo regularización del espacio latente (términos MMD/cobertura); implementando la selección adaptativa del método de predicción; y añadiendo ponderación de conjunto a los métodos de predicción.
Las mejoras en la robustez son un tanto ambiguas, sin embargo, se podrían realizar esfuerzos con: capacidad de detección fuera de distribución; sistema de puntuación de calidad de referencia; ajuste dinámico del tamaño del vecindario; y escalado de ruido dependiente de la entrada.
Implementación de MMD-Loss
La forma del VAE de Wasserstein que estamos implementando es la MMD-Loss y sus dos funciones de pérdida que utilizamos para el VAE se presentan a continuación:
def mmd_loss(y_true, y_pred, kernel_mul=2.0, kernel_num=5): """ MMD loss using Gaussian RBF kernel. Args: y_true: Ground truth samples (shape: [batch_size, dim]) y_pred: Predicted samples (shape: [batch_size, dim]) kernel_mul: Multiplier for kernel bandwidths kernel_num: Number of kernels to use Returns: MMD loss (scalar) """ batch_size = y_true.size(0) # Combine real and predicted samples xx = y_true yy = y_pred xy = torch.cat([xx, yy], dim=0) # Compute pairwise distances distances = torch.cdist(xy, xy, p=2) # Compute MMD using multiple RBF kernels loss = 0.0 for sigma in [kernel_mul ** k for k in range(-kernel_num, kernel_num + 1)]: if sigma == 0: continue kernel_val = torch.exp(-distances ** 2 / (2 * sigma ** 2)) k_xx = kernel_val[:batch_size, :batch_size] k_yy = kernel_val[batch_size:, batch_size:] k_xy = kernel_val[:batch_size, batch_size:] # MMD formula: E[k(x,x)] + E[k(y,y)] - 2*E[k(x,y)] loss += (k_xx.mean() + k_yy.mean() - 2 * k_xy.mean()) return loss / (2 * kernel_num) def compute_loss(predictions, batch): # Ensure shapes match (squeeze if needed) pred_states = predictions['states'].squeeze(-1) # [B, 1] → [B] pred_actions = predictions['actions'].squeeze(-1) pred_rewards = predictions['rewards'].squeeze(-1) # MMD Loss (distributional matching) mmd_state = mmd_loss(batch['states'], pred_states) mmd_action = mmd_loss(batch['actions'], pred_actions) mmd_reward = mmd_loss(batch['rewards'], pred_rewards) # Combine losses (adjust weights as needed) total_loss = mmd_state + mmd_action + mmd_reward return { 'loss': total_loss, 'mmd_state': mmd_state, 'mmd_action': mmd_action, 'mmd_reward': mmd_reward }
Los parámetros de entrada de la función MMD-Loss son y_true e y_pred. Representan una comparación entre las muestras reales y las generadas. Su alineación dimensional es importante para poder realizar una comparación. Las entradas kernel_mul/ kernel_num controlan los anchos de banda del núcleo RBF y, por lo tanto, afectan la sensibilidad a diversas escalas de las diferencias de distribución.
La combinación de muestras, xy, reúne muestras reales y generadas para calcular todas las distancias entre pares en una sola operación. Esto optimiza el uso de la memoria y garantiza cálculos de distancia consistentes. El cálculo de la distancia utiliza p=2 (distancia euclidiana), que es el estándar para MMD. Esta elección influye directamente en la sensibilidad a las diferencias de distribución. La operación 'cdist' es fundamental desde el punto de vista matemático, ya que MMD se basa en comparaciones por pares.
El enfoque multi-núcleo utiliza anchos de banda espaciados geométricamente (kernel_mul^k) para comprender las características de la distribución multiescala. Esto evita el escenario sigma=0, que produce divisiones por cero. Cada núcleo contribuye por igual a la pérdida final mediante el cálculo del promedio. El cálculo MMD utiliza la fórmula principal (k_xx + k_yy - 2k_xy) que cuantifica las discrepancias entre distribuciones. Las operaciones de media proporcionan estimaciones de expectativa a partir de muestras finitas, y la normalización por recuento de núcleos hace que la escala de pérdida sea consistente en diferentes configuraciones.
Se podrían realizar mejoras a este MMD con la selección del núcleo, donde: se puede implementar la selección adaptativa del ancho de banda en función de las estadísticas de la muestra; se pueden realizar experimentos con núcleos que no sean RBF para establecer qué núcleos son los más adecuados para qué tipos de datos; se puede implementar la determinación automática de la relevancia para los anchos de banda. La estabilidad numérica también puede introducirse mediante: la adición de un pequeño épsilon al denominador para mayor estabilidad; la implementación de cálculos en el dominio logarítmico para valores de núcleo muy pequeños; y el recorte de valores de distancia extremos para evitar el desbordamiento. Otras medidas pueden abarcar la eficiencia computacional y la integración de VAE.
Hay mucho otro código que debemos usar para ejecutar esta inferencia que no estamos destacando explícitamente aquí. Cabe destacar, sin embargo, que la generación de los datos de entrada de FASR proviene de la ejecución del código de los dos artículos anteriores sobre el oscilador estocástico y la media móvil. El artículo sobre aprendizaje supervisado nos proporciona las características y los componentes de estado de la entrada de nuestro VAE, mientras que el código del artículo sobre aprendizaje por refuerzo nos proporciona las acciones y las recompensas.
Implementación de regresión lineal
Para utilizar nuestro modelo de inferencia, nos basamos únicamente en las funciones de regresión que mapean la capa latente a las entradas faltantes y no en la red VAE. Esto contrasta con lo que hemos estado haciendo en los artículos anteriores, donde teníamos que exportar la red que habíamos entrenado como un archivo ONNX.
La razón por la que esto es así es que estamos interesados en completar el conjunto de datos de entrada para un VAE que hemos entrenado.
De ahora en adelante, solo disponemos de datos de características. Así pues, la pregunta se centra en cuáles son los estados, las acciones y las recompensas para estas características. Para responder a esta pregunta, al inicializar nuestro Asesor Experto necesitamos entrenar un modelo de regresión lineal con conjuntos de datos de pares para las codificaciones de características, las codificaciones de estados, las codificaciones de acciones y las codificaciones de recompensas. Una vez entrenado (o ajustado) nuestro modelo de regresión lineal, para cualquier nuevo punto de datos de características, lo asignaríamos a una codificación y, a continuación, usaríamos esta codificación dentro del mismo modelo para volver a asignarla a estados, acciones y recompensas.
Este proceso de ajuste para obtener las conexiones de codificación utiliza aprendizaje no supervisado. Nuestra regresión lineal se implementa de la siguiente manera en MQL5:
//+------------------------------------------------------------------+ // Linear Regressor (unchanged from previous implementation) | //+------------------------------------------------------------------+ class LinearRegressor { private: vector m_coefficients; double m_intercept; matrix m_coefficients_2d; vector m_intercept_2d; public: void Fit(const matrix &X, const vector &y) { int n = (int)X.Rows(); int p = (int)X.Cols(); matrix X_with_bias(n, p + 1); for(int i = 0; i < n; i++) { for(int j = 0; j < p; j++) X_with_bias[i][j] = X[i][j]; X_with_bias[i][p] = 1.0; } matrix Xt = X_with_bias.Transpose(); matrix XtX = Xt.MatMul(X_with_bias); matrix XtX_inv = XtX.Inv(); vector y_col = y; y_col.Resize(n, 1); vector beta = XtX_inv.MatMul(Xt.MatMul(y_col)); m_coefficients = beta; m_coefficients.Resize(p); m_intercept = beta[p]; } void Fit2d(const matrix &X, const matrix &Y) { int n = (int)X.Rows(); // Number of samples int p = (int)X.Cols(); // Number of input features int k = (int)Y.Cols(); // Number of output encodings // Add bias term (column of 1s) to X matrix X_with_bias(n, p + 1); for(int i = 0; i < n; i++) { for(int j = 0; j < p; j++) X_with_bias[i][j] = X[i][j]; X_with_bias[i][p] = 1.0; } // Calculate coefficients using normal equation: (X'X)^-1 X'Y matrix Xt = X_with_bias.Transpose(); matrix XtX = Xt.MatMul(X_with_bias); matrix XtX_inv = XtX.Inv(); matrix beta = XtX_inv.MatMul(Xt.MatMul(Y)); // Split coefficients and intercept m_coefficients_2d.Resize(p, k); // Coefficients for each output encodings m_intercept_2d.Resize(k); // Intercept for each input feature for(int j = 0; j < p; j++) { for(int d = 0; d < k; d++) { m_coefficients_2d[j][d] = beta[j][d]; } } for(int d = 0; d < k; d++) { m_intercept_2d[d] = beta[p][d]; } } double Predict(const vector &x) { return m_intercept + m_coefficients.Dot(x); } vector Predict2d(const vector &X) const { int p = (int)X.Size(); // Number of input features int k = (int)m_intercept_2d.Size(); // Number of output encodings vector predictions(k); // vector to store predictions for(int d = 0; d < k; d++) { // Initialize with intercept for this output dimension predictions[d] = m_intercept_2d[d]; // Add contribution from each feature for(int j = 0; j < p; j++) { predictions[d] += m_coefficients_2d[j][d] * X[j]; } } return predictions; } };
La estructura central mantiene un almacenamiento de coeficientes separado para 1D (para las variables m_coefficients/m_intercept) y 2D (para las variables m_coefficients_2d/m_intercept_2d). El álgebra matricial se utiliza para mejorar la eficiencia en operaciones por lotes. Implementa variantes de regresión tanto de salida única como de salida múltiple. Sus métodos de ajuste utilizan la ecuación normal resolviendo directamente (X'X)^- 1X'y. Corrige el sesgo añadiendo una columna de 1s a las características de entrada. La especialización 2D por parte de la clase también permite manejar múltiples salidas simultáneamente mediante operaciones matriciales.
Los métodos de predicción utilizan una implementación de producto escalar, que sirve como una combinación lineal eficiente de entradas y ponderaciones. El manejo de dimensiones se procesa correctamente tanto para escenarios de salida única como de salida múltiple, y la gestión de memoria preasigna el vector de resultados para mayor eficiencia. Utilizamos una clase pseudo Wasserstein VAE para llamar e implementar nuestras predicciones de estado, acciones y recompensas. Esto se codifica en MQL5 de la siguiente manera:
//+------------------------------------------------------------------+ // Wasserstein VAE Predictors Implementation (unchanged) | //+------------------------------------------------------------------+ class WassersteinVAEPredictors { private: LinearRegressor m_feature_predictor; LinearRegressor m_state_predictor; LinearRegressor m_action_predictor; LinearRegressor m_reward_predictor; bool m_predictors_trained; public: WassersteinVAEPredictors() : m_predictors_trained(false) {} void FitPredictors(const matrix &features, const vector &states, const vector &actions, const vector &rewards, const matrix &encodings) { m_feature_predictor.Fit2d(features, encodings); m_state_predictor.Fit(encodings, states); m_action_predictor.Fit(encodings, actions); m_reward_predictor.Fit(encodings, rewards); m_predictors_trained = true; } void PredictFromFeatures(const vector &y, vector &z) { if(!m_predictors_trained) { Print("Error: Predictors not trained yet"); return; } z = m_feature_predictor.Predict2d(y); } void PredictFromEncodings(const vector &z, double &state, double &action, double &reward) { if(!m_predictors_trained) { Print("Error: Predictors not trained yet"); return; } state = m_state_predictor.Predict(z); action = m_action_predictor.Predict(z); reward = m_reward_predictor.Predict(z); } };
Además, dentro de nuestra clase de señal personalizada, ahora dependemos de una función 'Infer' para procesar nuestros pronósticos. Esto es lo siguiente:
//+------------------------------------------------------------------+ //| Inference Learning Forward Pass. | //+------------------------------------------------------------------+ vector CSignal_WVAE::Infer(int Index, ENUM_POSITION_TYPE T) { vectorf _f = Get(Index, m_time.GetData(X()), m_close, m_ma, m_ma_lag, m_sto); vector _features; _features.Init(_f.Size()); _features.Fill(0.0); for(int i = 0; i < int(_f.Size()); i++) { _features[i] = _f[i]; } // Make a prediction vector _encodings; _encodings.Init(__ENCODINGS); _encodings.Fill(0.0); double _state = 0.0, _action = 0.0, _reward = 0.0; if(Index == 1) { m_vae_1.PredictFromFeatures(_features, _encodings); m_vae_1.PredictFromEncodings(_encodings, _state, _action, _reward); } else if(Index == 2) { m_vae_2.PredictFromFeatures(_features, _encodings); m_vae_2.PredictFromEncodings(_encodings, _state, _action, _reward); } else if(Index == 5) { m_vae_5.PredictFromFeatures(_features, _encodings); m_vae_5.PredictFromEncodings(_encodings, _state, _action, _reward); } vector _inference; _inference.Init(3); _inference[0] = _state; _inference[1] = _action; _inference[2] = _reward; // if(T == POSITION_TYPE_BUY) { if(_state > 0.5) { _inference[0] -= 0.5; _inference[0] *= 2.0; if(_action < 0.0) { _inference[0] = 0.0; } } else { _inference[0] = 0.0; } } else if(T == POSITION_TYPE_SELL) { if(_state < 0.5) { _inference[0] -= 0.5; _inference[0] *= -2.0; if(_action > 0.0) { _inference[0] = 0.0; } } else { _inference[0] = 0.0; } } return(_inference); }
Para los nuevos lectores, aquí y aquí encontrarán guías sobre cómo crear un asesor experto con el Asistente de MQL5 (Wizard MQL5). En el artículo anterior, de los 10 patrones con los que comenzamos, solo los patrones 1, 2 y 5 pudieron avanzar caminando. Por lo tanto, nuestras funciones de condición larga y condición corta para este Asesor Experto solo procesan estos tres patrones. Estamos pronosticando 3 valores. Estados, acciones y recompensas. Los estados están limitados al rango de 0 a 1. Las acciones también están limitadas a un rango similar, mientras que las recompensas se encuentran en el rango de -1 a +1. Cualquier persona con cierta experiencia en el entrenamiento y uso de redes neuronales sabrá que las salidas de prueba o implementación de las redes neuronales después del entrenamiento con objetivos que respetan los límites establecidos, no siempre se encuentran dentro de los límites esperados. A menudo se requiere algún tipo de normalización posterior a la ejecución.
Aquí no realizamos ninguna normalización, sino que simplemente lo señalamos al lector como algo que debe tener en cuenta al implementar una red neuronal entrenada en un entorno de producción. Cargamos dos años de datos diarios de precios de EUR/USD en Python para entrenar un VAE que nos proporciona un conjunto de datos que empareja características, estados, acciones y recompensas con codificaciones. Este conjunto de datos, a su vez, se ajusta a modelos de regresión lineal que luego utilizamos para representar estados, acciones y recompensas cuando se presentan características. De los datos cargados, que se procesan mediante el módulo de Python de MetaTrader 5, el 80% se utiliza para el entrenamiento, y el 20% restante se destina a las pruebas.
El período de datos abarca desde el 1 de enero de 2023 hasta el 1 de enero de 2025. Así pues, un avance sería aproximadamente los 5 meses anteriores al 1 de enero de 2025. Realizamos pruebas durante un período ligeramente más largo, los 6 meses anteriores, es decir, del 1 de julio de 2024 al 1 de enero de 2025, y se nos presentan los siguientes informes:
Para el patrón 1:


Para el patrón 2:


Para el patrón 5:


Al parecer, solo los patrones 1 y 5 son capaces de aprovechar la inferencia basada en un breve período de entrenamiento/prueba de 2 años.
Conclusión
Concluimos nuestro análisis de los patrones de media móvil y oscilador estocástico que se aprovechan con el aprendizaje automático explorando el caso de uso del aprendizaje por inferencia. Hemos presentado una posible ruta de implementación para el aprendizaje por inferencia basada en el argumento de que, una vez que se ha completado el aprendizaje supervisado y también se ha implementado el aprendizaje por refuerzo en un entorno de prueba real, sigue siendo necesario un enfoque más holístico para recopilar y "almacenar" todo el conocimiento del aprendizaje supervisado y del aprendizaje por refuerzo. Creo que el aprendizaje por inferencia está bien preparado y es idóneo para desempeñar este papel, especialmente porque su método de aprendizaje no es una duplicación de lo que ya hemos utilizado con el aprendizaje supervisado y el aprendizaje por refuerzo.
| Nombre | Descripción |
|---|---|
| wz_60.mq5 | Asistente de ensamblado Asesor experto incluido en el encabezado para mostrar los archivos de ensamblaje necesarios. |
| SignalWZ_60.mqh | Archivo de clase de señal. |
| 60_vae_1.onnx | Modelo VAE ONNX para el patrón 1, no necesario para Expert Advisor. |
| 60_vae_2.onnx | Modelo VAE ONNX para el patrón 2, ídem. |
| 60_vae_5.onnx | Modelo VAE ONNX para el patrón 5, ídem. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17818
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso