
Detección y clasificación de patrones fractales mediante aprendizaje automático
Introducción
En el primer artículo, examinamos con detalle los aspectos fundamentales de la teoría del mercado multifractal. En él, hablamos de que los gráficos de precios son capaces de formar ciertas estructuras repetitivas bajo la influencia de información externa que los organiza. Los participantes del mercado crean un sistema dinámico complejo que posee elementos de memoria que adoptan la forma de ciertas simetrías (patrones) del mercado. Dichos patrones pueden evolucionar con el tiempo o repetirse. Gracias a la autosimilitud de las estructuras de mercado fractales, los patrones pueden expresarse en diferentes escalas temporales.
Este artículo ofrecerá un enfoque original para la búsqueda y clasificación de patrones fractales. El estudio se realizará en Python, con la posibilidad de exportar los modelos finales a la plataforma MetaTrader 5 en el formato ONNX.
Antes de comenzar, asegúrese de haber instalado todos los paquetes y módulos necesarios. Algunos de los módulos importados ya se incluyen en el apéndice del artículo.
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from bots.botlibs.export_lib import export_model_to_ONNX
Implementación de la función de búsqueda de patrones fractales
En este artículo, le proponemos un enfoque sencillo para encontrar estructuras de mercado multifractales simétricas mediante correlación. Podemos explorar patrones fractales y multifractales que son invariantes a la escala, es decir, tienen diferentes tamaños. Para ello, debemos implementar una búsqueda de patrones mediante correlación en diferentes escalas temporales que se especificarán en la configuración. A continuación le mostramos una función que calcula la correlación en una ventana deslizante considerando la longitud variable de los patrones.
@njit def calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size): n = len(data) min_w = max(2, min_window_size) max_w = max(min_w, max_window_size) num_correlations = max(0, n - min_w + 1) if num_correlations == 0: return np.zeros(0, dtype=np.float64), np.zeros(0, dtype=np.int64) correlations = np.zeros(num_correlations, dtype=np.float64) best_window_sizes = np.full(num_correlations, -1, dtype=np.int64) for i in range(num_correlations): max_abs_corr_for_i = -1.0 best_corr_for_i = 0.0 current_best_w = -1 current_max_w = min(max_w, n - i) start_w = min_w if start_w % 2 != 0: start_w += 1 for w in range(start_w, current_max_w + 1, 2): if w < 2 or i + w > n: continue half_window = w // 2 window = data[i : i + w] first_half = window[:half_window] second_half = (window[half_window:] * -1)[::-1] std1 = np.std(first_half) std2 = np.std(second_half) if std1 > 1e-9 and std2 > 1e-9: mean1 = np.mean(first_half) mean2 = np.mean(second_half) cov = np.mean((first_half - mean1) * (second_half - mean2)) corr = cov / (std1 * std2) if abs(corr) > max_abs_corr_for_i: max_abs_corr_for_i = abs(corr) best_corr_for_i =corr current_best_w = w correlations[i] = best_corr_for_i best_window_sizes[i] = current_best_w return correlations, best_window_sizes
Para acelerar un ciclo con cálculos similares (los ciclos son lentos en Python), utilizamos el decorador @njit, que acelera los cálculos utilizando el paquete Numba.
La función acepta como entrada un frame de datos con los precios de cierre, así como los tamaños mínimo y máximo de "ventana" para los patrones. Por ejemplo, queremos calcular la correlación para patrones cuya longitud sea de entre 100 y 200 barras. A continuación, configuramos los ajustes correspondientes, tras lo cual, para cada nuevo punto de referencia y para cada longitud de patrón dada, comprobamos la correlación entre su parte izquierda y su parte derecha invertida simétricamente. La inversión de la parte derecha está resaltada en amarillo. Esto es muy importante porque buscamos simetría en los datos.
Los valores de las mejores correlaciones absolutas para cada punto de partida se escriben en el array correlations[]. El tamaño de la ventana (longitud del patrón) que se correspondiente con la mejor correlación se escribe en otro array best_window_sizes[]. De este modo, la función retorna los valores máximos de correlación y el patrón correspondiente para cada punto de partida.
Inspección visual de los patrones encontrados
Una vez calculados todos los patrones, podemos evaluar de forma visual la corrección de nuestro algoritmo. Para ello, le proponemos otra función que mostrará los mejores patrones encontrados según el coeficiente de correlación de Pearson absoluto más alto.
def plot_best_n_patterns(data, min_window_size, max_window_size, n_best): # 1. Calculate correlations and best window sizes corrs, window_sizes = calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size) # 2. Find N best patterns # Assuming -1 in window_sizes means invalid/not found by the calculation logic valid_calc_mask = window_sizes != -1 if not np.any(valid_calc_mask): print("No suitable patterns found (all window sizes were marked as -1 by calculation).") return filtered_corrs = corrs[valid_calc_mask] filtered_window_sizes = window_sizes[valid_calc_mask] original_indices_all = np.arange(len(corrs)) filtered_start_indices = original_indices_all[valid_calc_mask] if len(filtered_corrs) == 0: print("No suitable patterns found after filtering out -1 window_sizes.") return # Sort by absolute correlation value in descending order sorted_indices_of_filtered = np.argsort(np.abs(filtered_corrs))[::-1] # Determine how many of the top patterns to consider num_to_consider = min(n_best, len(sorted_indices_of_filtered)) if num_to_consider == 0: print("No patterns to plot (either n_best is too small, or no patterns passed the initial filter).") return # Pre-filter these top candidates to find those actually plottable (even window size >= 2) patterns_to_plot_details = [] for i in range(num_to_consider): idx_in_filtered_arrays = sorted_indices_of_filtered[i] # Index within the already filtered (by valid_calc_mask) arrays w_best_candidate = filtered_window_sizes[idx_in_filtered_arrays] actual_data_start_index = filtered_start_indices[idx_in_filtered_arrays] correlation_value = filtered_corrs[idx_in_filtered_arrays] # Check if the window size is valid for plotting (even and sufficiently large) if w_best_candidate >= 2 and w_best_candidate % 2 == 0 : patterns_to_plot_details.append({ "original_rank_in_consider_list": i, # Rank among the num_to_consider items "data_start_index": actual_data_start_index, "correlation": correlation_value, "window_size": int(w_best_candidate) # Ensure it's int }) else: print(f"Info: Top candidate (originally rank {i+1} among considered, " f"Start Index: {actual_data_start_index}) " f"skipped due to invalid window size for plotting: {w_best_candidate} (must be even and >= 2).") num_actually_plotted = len(patterns_to_plot_details) fig, ax = plt.subplots(1, 1, figsize=(10, 5)) # Single axes for combined plot title_fontsize = 12 label_fontsize = 10 legend_fontsize = 8 tick_labelsize = 9 if num_actually_plotted == 0: # This message is shown if, out of the top 'num_to_consider' patterns, none had a valid window size for plotting. print("No patterns with valid window sizes (even, >=2) found among the top candidates to display on the chart.") ax.text(0.5, 0.5, "No valid patterns to display on the chart.", horizontalalignment='center', verticalalignment='center', transform=ax.transAxes, fontsize=title_fontsize, color='red') ax.set_xticks([]) ax.set_yticks([]) fig.suptitle(f"Symmetric Patterns Overlaid", fontsize=title_fontsize) # Generic title else: # Generate distinct colors for each pattern that will actually be plotted plot_colors = plt.cm.viridis(np.linspace(0, 1, num_actually_plotted)) for plot_idx, pattern_info in enumerate(patterns_to_plot_details): actual_data_start_index = pattern_info["data_start_index"] correlation_value = pattern_info["correlation"] w_best = pattern_info["window_size"] half_window = w_best // 2 # Ensure indices are within data bounds if actual_data_start_index + w_best > len(data): print(f"Warning: Pattern P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}) extends beyond data length {len(data)}. Skipping.") continue left_part_data = data[actual_data_start_index : actual_data_start_index + half_window] right_part_data = data[actual_data_start_index + half_window : actual_data_start_index + w_best] x_indices = np.arange(w_best) # X-axis relative to pattern start current_color = plot_colors[plot_idx] # Plot left part ax.plot(x_indices[:half_window], left_part_data, color=current_color, linestyle='-', label=f"P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}, C:{correlation_value:.2f})") # Plot right part ax.plot(x_indices[half_window:], right_part_data, color=current_color, linestyle='--') # Add a vertical line to mark the split point for this pattern ax.axvline(x=half_window - 0.5, color=current_color, linestyle=':', linewidth=1, alpha=0.6) ax.set_xlabel("Index within Pattern Window", fontsize=label_fontsize) ax.set_ylabel("Data Value", fontsize=label_fontsize) ax.tick_params(axis='both', which='major', labelsize=tick_labelsize) ax.grid(True) ax.legend(fontsize=legend_fontsize, loc='best') # Add a text note to explain line styles fig.text(0.99, 0.01, 'Solid: Left Part, Dashed: Right Part (Original)', horizontalalignment='right', verticalalignment='bottom', fontsize=legend_fontsize - 1, color='dimgray', transform=fig.transFigure) fig.suptitle(f"Top {num_actually_plotted} Symmetric Patterns Overlaid", fontsize=title_fontsize) plt.tight_layout(rect=[0, 0.03, 1, 0.96]) # Adjust rect for suptitle and fig.text plt.show()
Esta función es bastante extensa en cuanto al tamaño del código, pero la mayor parte del código se dedica a ordenar y visualizar los patrones. Primero, se calculan los patrones en sí, y luego se ordenan según los valores del coeficiente de correlación. A continuación, se determina la posición de cada patrón en la historia de cotizaciones y se envía para su visualización. El resultado de esta función se muestra a continuación.
En la primera imagen vemos un patrón seleccionado que posee la correlación absoluta más alta. Se asemeja a un determinado pico, local o global, que simboliza un cambio de tendencia. La línea vertical punteada indica la división de la serie en dos partes de igual longitud. El lado derecho de la serie se invierte, lo cual significa que todos los valores se multiplican por -1 y luego se invierten. Posteriormente, se calcula la correlación entre las secciones izquierda y derecha. Los gráficos no muestran los lados derechos invertidos, sino la serie original de cotizaciones.
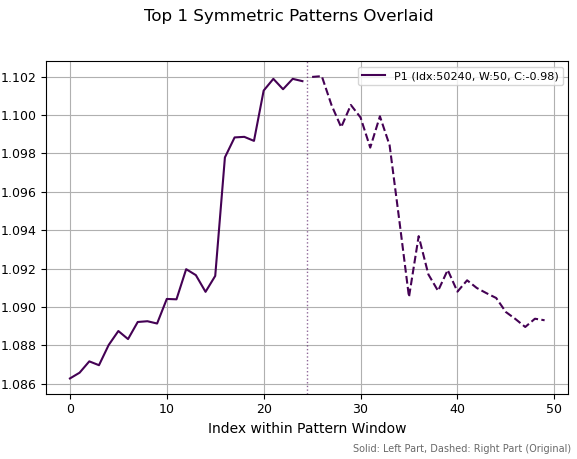
Figura 1. El mejor patrón con un periodo de 50 y una correlación de -0,98.
En la segunda figura hemos mostrado los cinco mejores patrones con un periodo de 50. Tres de ellos parecen ser máximos, dos parecen mínimos y uno parece una continuación de la tendencia alcista. La escala de la izquierda muestra los niveles de precios históricos con los que se corresponden estos patrones.
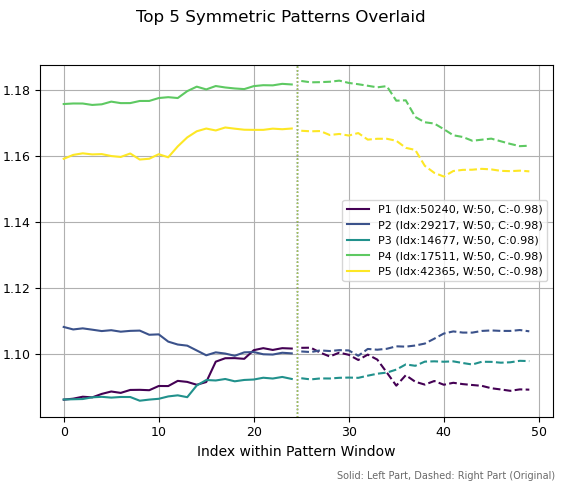
Fig. 2. Los cinco mejores patrones de 50 periodos
Si aumentamos los periodos del patrón a 150 barras, se observan estructuras completamente distintas. Se han encontrado tres patrones similares (arriba). Esto se debe a que un pequeño cambio en la historia ha dado como resultado el descubrimiento de la misma estructura. Los otros dos patrones han resultado diferentes entre sí.
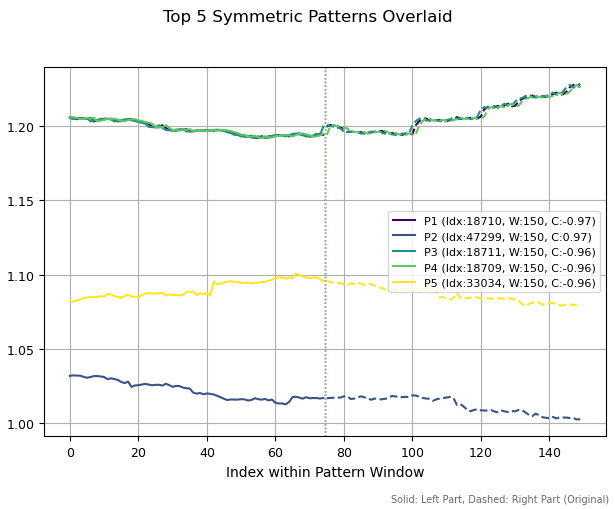
Fig. 3. Los cinco patrones principales con un periodo de 150
Si aumentamos la ventana de cálculo de patrones a 250, los mismos patrones han vuelto a figurar entre los mejores, pero con un ligero cambio en la historia. También podemos observar algunos patrones de inversión, ya que sus correlaciones son negativas.
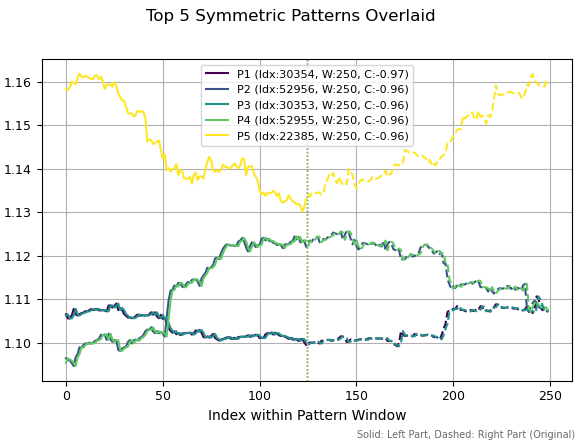
Figura 4. Los cinco patrones principales con un periodo de 250
Estas ilustraciones muestran una amplia variedad de estructuras de mercado autoafines (autosimilares). En teoría, dicha diversidad solo puede estar limitada por la duración de la serie estudiada. En este caso, resulta bastante difícil determinar qué patrón específico tendrá potencial predictivo y cuál no. Estudiar cada una de estas estructuras individualmente nos llevaría meses. El aprendizaje automático puede ayudarnos en este caso, dado que nos permite clasificar todos los patrones a la vez.
Es muy posible que la búsqueda de estructuras mediante correlación no sea lo ideal, y que debamos considerar otros métodos de estimación más precisos, pero este enfoque es un buen punto de partida para futuras investigaciones y resulta intuitivo. Ahora necesitamos averiguar cómo analizar estos fractales de mercado y construir un sistema comercial basado en ellos utilizando el aprendizaje automático.
Etiquetado de operaciones basado en estructuras simétricas
La función de búsqueda de estructuras simétricas es, en cierto sentido, una función de minería de datos en la que establecemos criterios claros sobre lo que buscamos en los mismos: estructuras fractales autosimilares. A continuación, la información recibida debe recopilarse y clasificarse. Pero ni siquiera esto resultará suficiente, porque tendremos que encontrar una manera de marcar las transacciones basándonos en estos datos, que es lo que haremos en esta sección.
Le propongo el siguiente método para marcar las transacciones para su posterior clasificación. No es la única posible, pero refleja la comprensión del autor sobre cómo se puede implementar. Creo que será necesario realizar más investigaciones sobre este tema, pero por ahora nos limitaremos al método de marcado existente.
@njit def generate_future_outcome_labels_for_patterns( close_data_len, # Total length of the original close_data correlations_at_window_start, # Correlation array window_sizes_at_window_start, # Array of window sizes source_close_data, # Full close_data array correlation_threshold, min_future_horizon, # Minimum horizon for determining the future price max_future_horizon, # Maximum horizon markup_points # "Markup" for determining a significant price change ): labels = np.full(close_data_len, 2.0, dtype=np.float64) # 2.0: no signal/neutral/no pattern num_potential_windows = len(correlations_at_window_start) for idx_window_start in range(num_potential_windows): corr_value = correlations_at_window_start[idx_window_start] w = window_sizes_at_window_start[idx_window_start] # Condition 1: The correlation should be strong enough if abs(corr_value) < correlation_threshold: continue # Condition 2: A valid window should be found if w < 2: continue # The point in time (index) when the correlation pattern is fully formed signal_time_idx = idx_window_start + w - 1 if signal_time_idx >= close_data_len: # Theoretically, this should not happen continue # Array for storing labels for the entire pattern (both left and right parts) pattern_labels = [] # Calculate individual marks for all points of the pattern for point_idx in range(idx_window_start, signal_time_idx + 1): # Current price for this particular point current_price = source_close_data[point_idx] # Define the forecast horizon current_horizon = min_future_horizon if max_future_horizon > min_future_horizon: current_horizon = random.randint(min_future_horizon, max_future_horizon) # Index of future price relative to the current point future_price_idx = point_idx + current_horizon if future_price_idx >= close_data_len: continue future_price = source_close_data[future_price_idx] # Define a label for the current point current_label = 2.0 # Neutral by default if future_price > current_price + markup_points: current_label = 0.0 # Price increased elif future_price < current_price - markup_points: current_label = 1.0 # Price fell # Add the label to the array if it is not neutral if current_label != 2.0: pattern_labels.append(current_label) # If there are no significant marks in the pattern, move on to the next pattern if len(pattern_labels) == 0: continue # Calculate the average mark for all points of the pattern avg_label = 0.0 for l in pattern_labels: avg_label += l avg_label /= len(pattern_labels) # Define a common label for the entire pattern pattern_label = 0.0 if avg_label < 0.5 else 1.0 # Assign this label to all points of the pattern for i in range(idx_window_start, signal_time_idx + 1): labels[i] = pattern_label return labels
La función generate_future_outcome_labels_for_patterns() implementa la siguiente funcionalidad:
- La entrada consta del array original de precios, un array de correlaciones y un array de longitudes de patrón que corresponden a las correlaciones más grandes para un punto de datos en particular. La función también admite un horizonte de previsión mínimo y máximo, expresado en barras.
- Inicialmente, todas las operaciones se marcan como 2.0 (no negociar).
- El ciclo comprueba el valor de correlación para cada punto de la serie temporal. Si este supera el umbral de correlación, dicha observación se someterá a un procesamiento adicional; de lo contrario, la etiqueta para este ejemplo permanecerá en 2.0.
- Luego, a lo largo de toda la extensión del patrón, determinada mediante la correlación máxima, las operaciones se calcularán según los cambios de precio futuros. Para cada punto: si el precio ha subido, entonces esta será la etiqueta 0 - comprar; si el precio ha bajado, entonces esta será la etiqueta 1 - vender. Después se calcula el valor promedio de todas las operaciones y se asigna una calificación promedio a cada observación del patrón actual.
En este enfoque subyace la filosofía de que las estructuras altamente correlacionadas tienen "memoria" de sus condiciones iniciales y exhiben cierto grado de regularidad. Esto significa que las observaciones dentro de ellas se predicen mejor, pero para evitar el sobreajuste, colocaremos una etiqueta promedio en cada observación. Por el contrario, las observaciones dentro de estructuras de baja correlación se pronosticarán mal porque tienen menos regularidad.
En consecuencia, aplicaremos el siguiente principio: un modelo determinará la calidad del patrón (si merece la pena negociar en ese momento o no), mientras que el otro modelo determinará la dirección de la operación. El aprendizaje automático se encargará de aproximar todos los patrones y direcciones comerciales posibles.
A continuación, necesitaremos otra función de orquestación, que se llamará directamente para etiquetar las transacciones.
Función-etiquetadora final basada en patrones fractales
Ahora es momento de juntarlo todo y escribir un etiquetador de transacciones listo para usar.
def get_fractal_pattern_labels_from_future_outcome( dataset, min_window_size=6, max_window_size=60, correlation_threshold=0.7, min_future_horizon=5, max_future_horizon=5, markup_points=0.00010, ): if 'close' not in dataset.columns: raise ValueError("Dataset must contain a 'close' column.") close_data = dataset['close'].values n_data = len(close_data) if min_window_size < 2: min_window_size = 2 if max_window_size < min_window_size: max_window_size = min_window_size if min_future_horizon <= 0: raise ValueError("min_future_horizon must be > 0") if max_future_horizon < min_future_horizon: raise ValueError("max_future_horizon must be >= min_future_horizon") correlations_at_start, best_window_sizes_at_start = calculate_symmetric_correlation_dynamic( close_data, min_window_size, max_window_size, ) labels = generate_future_outcome_labels_for_patterns( n_data, correlations_at_start, best_window_sizes_at_start, close_data, correlation_threshold, min_future_horizon, max_future_horizon, markup_points ) result_df = dataset.copy() result_df['labels'] = pd.Series(labels, index=dataset.index) return result_df
La función get_fractal_pattern_labels_from_future_outcome() se llama directamente para etiquetar su conjunto de datos:
- a la entrada se suministra un frame de datos que debe contener una columna "close" con los precios de cierre, así como características (opcional);
- se establece la longitud mínima y máxima de los patrones que se utilizarán para marcar las transacciones;
- se establece un umbral de correlación que permite ajustar la "precisión" de los patrones implicados en el marcado;
- también se debe especificar el tiempo mínimo y máximo de mantenimiento de la posición (en barras) para marcar las operaciones;
- de manera opcional, se puede configurar el marcado.
Esta función toma un conjunto de datos de precios de cierre y etiqueta las operaciones basándose en patrones fractales, añadiendo una columna "labels" con las etiquetas marcadas.
Entrenamiento de un modelo de aprendizaje automático basado en etiquetado fractal
Ahora todo está listo para los experimentos y podemos entrenar los modelos. Como datos de origen, hemos usado las cotizaciones horarias del EUR/USD desde 2010 hasta la actualidad.
Como características hemos decidido utilizar las desviaciones estándar en ventanas deslizantes de diferentes periodos:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
A continuación, debemos configurar correctamente los hiperparámetros del modelo:
# set hyper parameters hyper_params = { 'symbol': 'EURUSD_H1', 'export_path': '/Users/dmitrievsky/Library//drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/', 'model_number': 0, 'markup': 0.00010, 'stop_loss': 0.00500, 'take_profit': 0.00500, 'periods': [i for i in range(15, 300, 30)], 'backward': datetime(2010, 1, 1), 'forward': datetime(2024, 1, 1), }
- El stop-loss y el take-profit son iguales y equivalen a 500 puntos de cinco dígitos;
- A continuación, debemos especificar la ruta para exportar los modelos entrenados a su carpeta;
- Así hemos establecido los periodos de las características (desviaciones estándar) en el rango de 15 a 300, con un paso de 30 (hay 10 características en total);
- El periodo de entrenamiento va de 2010 a 2024; el resto corresponde a datos fuera de la muestra de entrenamiento.
El ciclo de entrenamiento principal nos permite entrenar varios modelos a la vez, y también permite iterar sobre los hiperparámetros:
# fit the models models = [] for i in range(10): print('Learn ' + str(i) + ' model') dataset = get_features(get_prices()) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() data = get_fractal_pattern_labels_from_future_outcome(data, 100, 100, 0.9, 15, 25, 0.00010) models.append(fit_final_models(data))
En este proceso, primero obtenemos los precios y las características, y luego determinamos el periodo temporal en el que se entrenará el modelo.
A la función get_fractal_pattern_labels_from_future_outcome() le transmitimos los siguientes parámetros :
- el frame de datos original con los precios y características
- la ventana mínima para calcular la correlación
- la ventana máxima para calcular la correlación
- el umbral del coeficiente de correlación para los patrones; el valor predeterminado es 0,9
- el horizonte de pronóstico mínimo en barras
- el horizonte máximo de pronóstico en barras
- el margen de beneficio en puntos
Los datos etiquetados se introducen a continuación en una función que entrena dos clasificadores:
def fit_final_models(dataset: pd.DataFrame) -> list: feature_columns = dataset.columns[1:-1] # 1. Data for the main model # Filter the dataset: only those examples where 'labels' are equal to 0 or 1 are used for the main model. main_model_df = dataset[dataset['labels'].isin([0, 1])].copy() X = main_model_df[feature_columns] y = main_model_df['labels'].astype('int16') # 2. Data for the meta model X_meta = dataset[feature_columns] # Modify labels for the meta model: if 'labels' contains 1 or 0, then the new label is 1, if 2, then 0. y_meta = dataset['labels'].apply(lambda label_val: 1 if label_val in [0, 1] else 0).astype('int16') # For the main model train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) # For the meta model train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # Train the main model model = CatBoostClassifier(iterations=1000, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', ) # Check if the samples are empty after splitting (unlikely if X is large enough) if not train_X.empty and not test_X.empty: model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) elif not train_X.empty: # If the test sample is empty, but the training sample exists print("Warning: The test sample (test_X) for the main model is empty. The model is trained without eval_set.") model.fit(train_X, train_y, early_stopping_rounds=15, plot=False) # use_best_model may not work correctly without eval_set else: # If the training set is empty print("Error: The training set (train_X) for the main model is empty. The model cannot be trained.") # In this case, test_model will most likely throw an error later. # Return R2=-1 and the untrained model, the meta model will also not make sense without the main one. print("R2 is fixed at -1.0, models are not trained.") return [-1.0, model, None] # model - instance, but not trained # Meta model training meta_model = CatBoostClassifier(iterations=1000, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', ) if not train_X_m.empty and not test_X_m.empty: meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=25, plot=False) elif not train_X_m.empty: print("Warning: The test sample (test_X_m) for the meta model is empty. The meta model is trained without eval_set.") meta_model.fit(train_X_m, train_y_m, early_stopping_rounds=25, plot=False) else: print("Error: The training set (train_X_m) for the meta model is empty. The meta model cannot be trained.") print("R2 fixed as -1.0.") return [-1.0, model, meta_model] # meta_model - instance, but not trained data_for_test = get_features(get_prices()) R2 = test_model(data_for_test, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 fixed as -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
Los puntos que merecen especial atención están resaltados en negrita. Hemos entrenado el modelo principal para predecir solo 0 o 1 etiqueta, mientras que el metamodelo adicional predice si se debe negociar o no.
Pruebas y resultados finales
Para empezar, debemos mencionar que solo hemos probado el algoritmo con un par de divisas: el EUR/USD. Hemos logrado seleccionar un tamaño de ventana de fractales financieros que funciona mejor con datos nuevos. Este es igual a 100. Los parámetros óptimos del algoritmo ya están especificados en el código, por lo que el lector podrá reproducir el resultado por sí mismo.
El gráfico de saldo para los datos de entrenamiento y prueba tiene este aspecto:
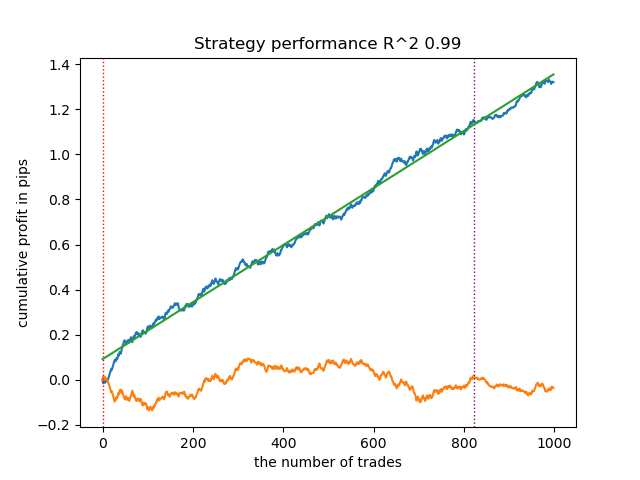
Figura 5. Probamos un algoritmo basado en marcado fractal
Existe una relación directa entre el umbral de correlación y los resultados de las operaciones con datos nuevos. Por ejemplo, para un umbral de 0,7, el gráfico de saldo ya indica un claro sobreajuste. Esto refleja el hecho de que una correlación débil entre dos partes de una serie temporal provoca una dependencia débil. La dependencia débil, a su vez, no permite la correcta clasificación de los patrones fiables, porque están mezclados con patrones poco fiables.
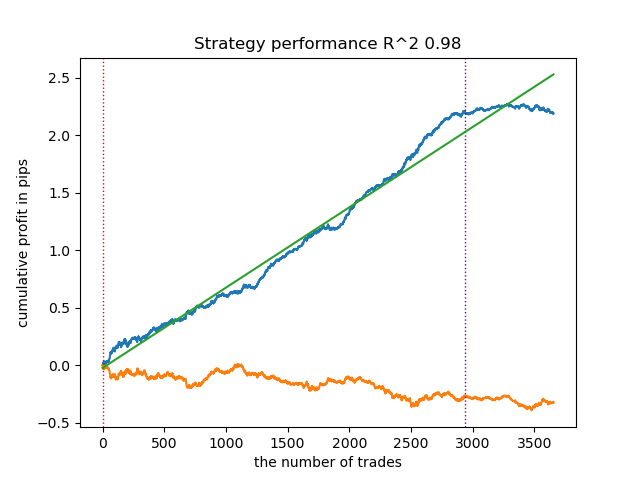
Figura 6. Probando el algoritmo con un umbral de 0.7
Parece que la identificación correcta de patrones es algo fundamental. Necesitamos más investigaciones y conocimientos sobre la mejor manera de organizar la búsqueda de estructuras fractales.
La calidad y la cantidad de características también influyen en los resultados de la clasificación. Si usamos incrementos en lugar de desviaciones estándar, el gráfico de saldos tendrá un aspecto diferente.
También debemos analizar y criticar razonablemente el método de etiquetado de transacciones según los patrones encontrados.
El análisis de errores de los modelos CatBoost muestra que los modelos se entrenan con un bajo nivel de error:
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.9700523560209424, 'Logloss': 0.17002244404784328} >>> models[-1][2].get_best_score()['validation'] {'Logloss': 0.25629795409043277, 'F1': 0.8455473098330242} >>>
Exportación y prueba de modelos en el terminal Meta Trader 5
Para exportar modelos, debemos llamar a la función:
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Tras exportar y compilar el asesor, hemos obtenido los siguientes resultados:
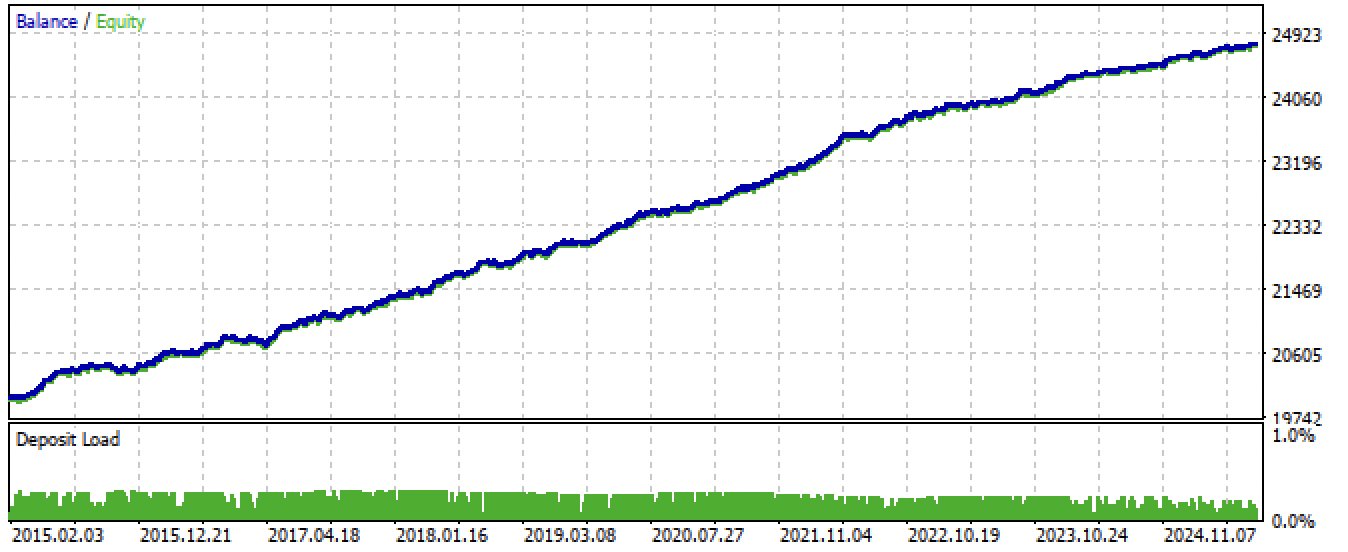
Figura 7. Prueba al asesor durante todo el periodo.
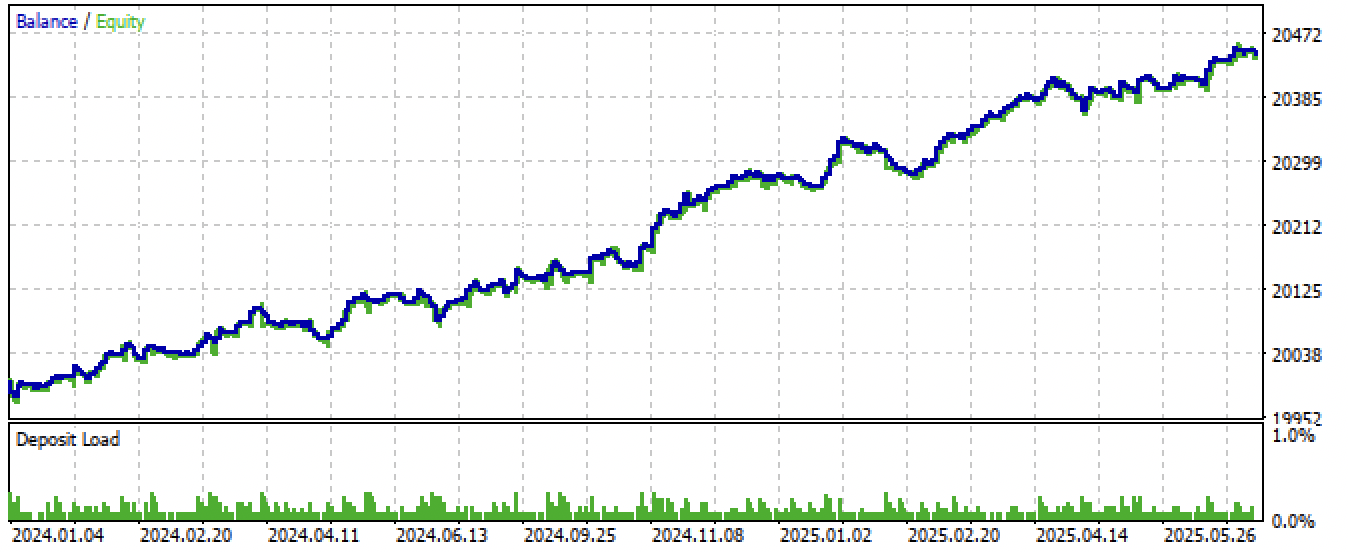
Figura 8. Prueba del asesor con nuevos datos
Conclusión
En este artículo, hemos abordado el fascinante tema del análisis fractal y la previsión de mercado mediante el aprendizaje automático. Estos serán solo los primeros pasos para explorar las diversas estructuras fractales que se forman en los gráficos de precios financieros.
Cabe señalar que las búsquedas de correlación pueden no reflejar completamente las relaciones entre las series de precios pasadas y futuras, y este tema requiere de una investigación más profunda. Por ejemplo, el análisis de regresión puede resultar más apropiado que el análisis de correlación. Al mismo tiempo, el algoritmo actual es capaz de mostrar buenas capacidades predictivas cuando se configura correctamente, lo que confirma la presencia de estructuras fractales autosimilares en las series temporales financieras.
El archivo Python files.zip contiene los siguientes archivos para desarrollar en el entorno Python:
| Nombre del archivo | Descripción |
|---|---|
| fractal patterns.py | Script básico para el entrenamiento de modelos |
| labeling_lib.py | Módulo actualizado con marcadores de transacciones |
| tester_lib.py | Simulador personalizado actualizado para estrategias basadas en aprendizaje automático |
| export_lib.py | Módulo de exportación de modelos al terminal |
| EURUSD_H1.csv | Archivo con las cotizaciones exportadas desde el terminal MetaTrader 5 |
El archivo MQL5 files.zip contiene archivos para el terminal MetaTrader 5:
| Nombre del archivo | Descripción |
|---|---|
| fractal trader.ex5 | Bot compilado a partir de este artículo |
| fractal trader.mq5 | Bot fuente del artículo |
| carpeta Include//Trend following | Asimismo, encontrará los modelos ONNX y el archivo de encabezado para conectarse al bot |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18566
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
No hablo sólo de este artículo. No es un mal artículo, dentro de lo que cabe. Es sobre otra cosa.
"Todavía no he descubierto cómo tener en cuenta la variabilidad de los fractales a lo largo del tiempo" - mientras tanto, este es un parámetro clave que determina la eficacia de cualquier previsión.
Y no es sólo tu problema, es un problema global - cambio de todos los coeficientes con variables con el tiempo.
Para comprender la esencia del problema, hay que ir más allá, replantearse los conceptos iniciales. Por ejemplo, la mayoría de los fractales no son autosimilares, 1 dólar en 2000 no es igual a 1 dólar en 2025 (es decir, 1 no es igual a 1).
Se pueden dar muchos más ejemplos, en la sociedad (economía) prevalece la distribución de Pareto, no la de Gauss, por lo que la mayoría de los métodos estadísticos no son aplicables al análisis de mercados, etc.
El éxito de Simons sugiere que existe una solución al problema, pero hay que buscarla en otra parte.
Parece tener razón sobre el arbitraje. Muchas estrategias de arbitraje también dejan de funcionar con el tiempo.
Creo que se refiere al arbitraje. Muchas estrategias de arbitraje también dejan de funcionar con el tiempo.
Tiene espacios multidimensionales.
Tiene espacios multidimensionales.
¿De Hilbert?
En general, casi no hay información detallada sobre los métodos de trabajo de Simons, y es comprensible. Pero se sabe que duplicaba su capital cada año, y que al final de su vida su fortuna se estimaba en más de 20.000 millones.
Pero no se trata de él, sino de la posibilidad misma de encontrar una fórmula. Espacios multidimensionales es la terminología actual para las ideas pitagóricas. Es un tema muy profundo. La multifractalidad también puede verse como un análogo primitivo del espacio multidimensional, donde los vértices y los grafos son proyecciones sobre un grafo de movimientos ocultos. Si el tema te interesa, puedo compartir mis consideraciones - desarrollos, pero es mejor en correspondencia individual.
En general, casi no hay información detallada sobre los métodos de trabajo de Simons, y es comprensible. Pero se sabe que duplicaba su capital cada año, y al final de su vida su fortuna se estimaba en más de 20.000 millones.
Pero no se trata de él, sino de la posibilidad misma de encontrar una fórmula. Espacios multidimensionales es la terminología actual para las ideas pitagóricas. Es un tema muy profundo. La multifractalidad también puede verse como un análogo primitivo del espacio multidimensional, donde los vértices y los grafos son proyecciones sobre un grafo de movimientos ocultos. Si el tema te interesa, puedo compartir mis consideraciones - desarrollos, pero es mejor en correspondencia individual.
Parece que el artículo anterior acaba de describir la formación de atractores ocultos (autoorganización) bajo la influencia de condiciones externas, que pueden definirse a través del espacio multidimensional de características.